Hadoop負載樹任務調度算法
2018-02-12 12:24:56朱潔顧燁君柳飛李思成劉瑞
軟件導刊 2018年12期
朱潔 顧燁君 柳飛 李思成 劉瑞

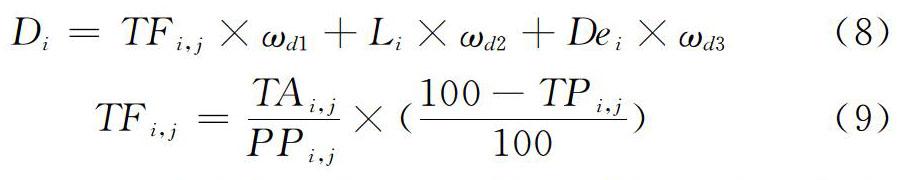

摘要:針對現有異構任務調度算法存在負載不均衡、數據本地性問題,提出基于樹結構的負載樹任務調度算法。該算法通過量化節點計算能力構造節點集最小堆,利用堆排序生成計算能力逆序樹,并依據節點負載率將逆序樹調整為左節點優先的負載樹,為任務計算包含完成時間、負載率、延遲因子的決策值,最終完成任務與樹節點的匹配。實驗結果表明,取不同負載率與延遲權值比時,該算法的任務執行效率均能獲得一定程度提高。該算法可利用樹結構的調度優勢,在獲得更高集群負載均衡度時,有效縮短作業集執行時間。
關鍵詞:Hadoop;負載樹;任務調度;負載均衡;數據本地性
Hadoop Load Tree Task Scheduling Algorithm
ZHU Jie1,2, GU Ye?jun?LIU Fei?LI Si?cheng?LIU Rui?1
(1.School of Information Engineering, Nanjing Xiaozhuang University;
2.Key Laboratory of Trusted Cloud Computing and Big Data Analysis, Nanjing 211171, China)
Abstract:Aiming at the problems of the load imbalance and data locality of existing heterogeneous tasks scheduling algorithm, an load tree task scheduling algorithm was proposed. Firstly, the computation capacities of nodes were calculated to build the minimum heap of the node set. The reverse tree was constructed after heap sort. Secondly, the reverse tree was adjusted to the left?node preferential load tree through the load rate of nodes. Finally, the decision values of nodes consist of complete time factor, load rate factor and delay factor were calculated to match tasks and nodes. The experimental results showed that the tasks execution efficiency of the proposed algorithm was improved when different factor proportions of load rate and delay were defined. The proposed algorithm can utilize the scheduling advantage of the tree structure and reduce the job set execution time effectively while achieving the higher cluster load balance degree.
Key Words:Hadoop; load tree; task scheduling; load balance; data locality
0?引言
Hadoop分布式計算平臺因其可靠、高效而廣泛應用于大數據處理。MapReduce是其實現分布式處理的計算模型,其中任務調度算法為作業任務匹配計算資源,通過獲得更短作業集執行時間提升平臺計算性能。傳統的先來先服務調度算法[1?2]、容量調度算法[3]與公平調度算法[4?5]及其改進主要應用于同構集群環境[6?7]。隨著集群應用發展,節點間配置差異使同構前提不再成立,設計適應異構環境的調度算法成為必要。針對異構環境的推測式執行機制通過為進度落后任務啟用備份任務以縮短任務執行時間,但其節點速度、任務進度恒定假設并不符合實際異構環境[8?9]。在此基礎上,改進最長近似結束時間(Longest Approximate Time to End,LATE)算法[10],定義備份任務數、慢節點與慢任務閾值,通過在出現資源空閑的快節點上啟用備份任務,有效縮短了落后任務的執行時間。但仍存在問題:①Hadoop分布式文件系統使用冗余存儲,任務數據不在本地時,移動數據的代價遠高于移動計算;②應用領域擴展、用戶需求多樣、計算節點資源異構與鏈路帶寬差異將導致集群負載不均衡,算法中并未涉及。
現有研究集中于對問題①的改進:文獻[11]提出允許任務放棄調度機會,等待調度到距離數據最近節點的延遲調度算法;文獻[12]使用任務進度探測方式區分快慢節點以提高推測執行效率;文獻[13]從總體性能考慮,通過網絡與負載狀況動態調整數據本地性;文獻[14]引入排隊論模型,利用單隊列多資源池服務窗口設計提高調度效率;文獻[15]采用預取任務輸入數據的方式減少作業響應時間。不少改進采用了智能調度算法,尋求多樣性搜索與集中性搜索平衡,雖然有效減少了任務執行時間,但容易陷入局部最優解,使任務聚集在最快的幾個節點上,延長了快節點上任務的排隊時間,使慢節點的資源得不到充分利用,降低了任務并行率,導致負載不均衡,影響了作業集執行時間。
針對問題②,需要在任務調度算法中充分考慮可能引起負載不均衡的因素,進而進行預處理與實時控制。已有云計算環境下動態負載均衡算法研究主要涉及任務完成時間、資源利用率、能源消耗、云系統性能等方面的改進。文獻[16]通過計算觸發條件中集群負載實現資源的彈性調度。文獻[17]建立成本函數模型,引入動態調節因子,改進蟻群算法用于降低任務成本,實現資源負載均衡。文獻[18]定義了任務完成時間成本的約束函數和負載均衡度函數,通過改進蟻群算法獲得全局最優解。文獻[19]采用禁忌搜索和貪心原則選擇任務交換,從而在優化任務調度初始解執行時間的同時改善負載均衡性能。文獻[20]通過虛擬機分組和任務選擇算法減少任務的遷移次數,提高負載均衡指標。
本文針對以上問題,借鑒樹結構調度優勢,提出負載樹算法(Load Tree Algorithm,LTA)。該算法通過基于計算能力的最小堆排序構建自平衡逆序樹,利用完成時間、負載率、時延因子將逆序樹調整為左節點優先的負載樹,實現任務與節點匹配。算法優先考慮數據本地性,充分利用樹索引優勢實現任務并行度與資源利用率之間的平衡,使異構環境任務調度趨于合理。
1?負載樹構造
異構集群中,不同計算能力會使同一任務在不同節點上的執行時間各有差異。首先,量化節點計算能力。設?n∈N為樹節點數,定義節點集P={P?i|i∈[0,n-1]},節點計算能力集P?cap={P?cap(i)|i∈[0,n-1]},節點資源集PR={(PRc?i, PRm?i)|i∈[0,n-1]},節點速率集PS={PS?i(j)|i∈[0,n-1], j∈[1,n?t]},n?t為節點P?i上已完成的任務數。為支持多資源類型,資源集值定義了處理器資源值PRc?i與內存資源值PRm?i,根據式(1)計算節點速率初始值PS?i(0),ω?r為資源權值。
集群運行后,通過任務歷史數據反饋更新節點速率,動態調整節點狀態。定義節點任務執行時間集TT={TT?i,j|i∈[0,n-1], j∈[1,n?t]},節點P?i當前速率PS?i(n?t)為已完成任務在單位時間內處理的任務數與資源量,通過式(2)計算。
每有任務完成,更新節點速率。節點計算能力通過式(3)計算,其中ω?c為計算能力因子權值。
利用堆結構在構造優先級隊列時的高效性,通過最小堆構造逆序樹。首先,按序構造完全二叉樹,并自底向頂逐步調整為符合定義1的最小堆。
定義1?P?cap(i)≤P?cap(2i+1)∧P?cap(i)≤P?cap(2i+2)?(i∈[0,|(n-2)/2|])
完全二叉樹從最后一個非葉子節點?P?|n/2|到根節點P?0,依次調用下滑調整算法比較本輪父節點與左右孩子節點的P?cap值。逐步將P?cap值最小的節點上浮為堆頂節點,得到初始最小堆。調用堆排序算法將初始最小堆調整為逆序樹,其特征為:①下標i為奇數時,節點為左孩子,i為偶數時,節點為右孩子;②采用層次遍歷,得到節點計算能力逆序值集;③具有n個節點的逆序樹深度k=|?log?2n|+1。堆排序過程在最壞情況下時間復雜度為O(n?log?2n)?。
基于節點負載率動態調整逆序樹,利用節點計算能力,實現資源調度平衡。定義節點負載率集為?L={L?i|i∈[0,n-1]}。負載率計算涉及節點性能狀態,進而影響任務分配,利用處理器與內存資源值完成計算。定義節點已用資源量集為PRa={(PRac?i, PRam?i)|i∈[0,n-1]},負載率計算如式(4)所示。
負載率升高可能導致節點性能下降,還需進一步判別節點速率。若節點速率同時出現下降,則可判別節點性能下降。節點速率下降條件式為?PS?i(n?t)>PS?i(n?t+1)?,將式(2)代入其中,推導可得條件式(5)。
逆序樹調整為負載樹后,需要對樹節點的負載均衡度進行判定。判定時,若將負載率相近但計算能力不同的節點視為同等均衡度,將會降低強節點的資源利用率。因此,判定還需考慮節點計算能力的影響。設節點均衡度集?DB={DB?i|i∈[0,n-1]},計算如式(6)所示。
節點均衡度集的標準差用于描述集群均衡度,計算如式(7)所示。
σ值正常范圍在[0,1]內,值越小,集群均衡度越高。負載樹算法側重于比較均衡效果,通過條件式DB?i>DB判別節點過載。
改善逆序樹負載不均衡與弱節點資源利用率低的問題,可以通過在復制的逆序樹中引入負載率因子構造動態負載樹實現。負載樹須符合定義2,同層節點中負載更輕的節點將成為左孩子。
定義2?L?2i+1≤L?2i+2?(i=0,1,…,|(n-2)/2|)
節點上每有任務分配或完成,若其父節點不符合定義2,則交換同層節點。定義節點P?i上任務預計完成時間集為TF={TF?i,j|i∈[0,n-1], j∈[1,n?p]},n?p為節點并行任務數閾值。根據式(8)計算根節點與左孩子節點的決策值D?i,以優先選擇計算能力更強、完成時間更短、負載更輕、延遲更短的節點。其中,w?d為決策值因子權值。TF?i,j的計算如式(9)所示。
其中,PP={PP?i,j|i∈[0,n-1], j∈[1,n?p]}為任務已完成的進度比例集;任務進度比例采用傳統任務調度算法規定;TA={TA?i,j|i∈[0,n-1], j∈[1,n?p]}為任務已運行時間集;TP?i,j為任務優先級,優先級越高,決策值越小,越早獲得執行。
2?基于負載樹的任務調度算法
負載樹算法構造可動態調整的集群節點負載樹,通過比較左節點決策值為任務選擇執行節點,算法流程如圖1所示。
算法適應負載率變化,支持拓撲改變、節點性能變化等情況。通過式(5)判別出有節點性能下降時,為保持逆序樹相對穩定,將該節點標記為不參與調度。若此節點為左節點,則判斷同層右節點是否過載,若過載,則僅標記;若不過載,則交換兩節點。若此節點為右節點,則僅標記。該節點上每有任務完成,即判別性能是否恢復,若恢復,則撤銷標記,節點重新參與調度。當拓撲變化或節點計算能力變化時,須調整逆序樹,進行負載樹再構造。對于集群拓撲異構與可擴展支持,增強了負載樹算法的適應性。
3?實驗結果與分析
建立集群,測試負載樹算法效果。選取6臺計算機構建異構環境,其中3臺配置處理器四核3.0GHz、內存8GB,3臺減配為處理器雙核2.4GHz、內存2GB,在CentOS上部署Hadoop。4個節點連接同一交換機,通過路由器連接其余2個節點,并通過修改鏈路帶寬值模擬為遠程節點。作業集由不同資源需求量、數據量的典型作業WordCount、TeraSort、Grep組合構成。作業數100,3種作業各占約1/3,且每種作業數據量由少到多比例為3∶4∶3,作業以隨機順序提交。通過實驗獲取負載樹算法在異構集群中采用不同負載率與時延權值時的作業集執行時間,并與LATE算法進行對比。
算法固定完成時間因子權值,調整負載率與時延權值比例。實驗1-3中負載率與延遲權值依次為(0.35,0.35)、(0.5,0.2)、(0.2,0.5)。實驗4中負載率與延遲權值為(0.4,0.3)時,作業集執行時間最短。作業集執行時間對比如圖2所示。
實驗結果中,當負載與延遲權值相當時,調度效果較好。其中,實驗1、實驗4中負載樹算法比LATE算法的作業集執行時間分別縮短了30.53%、33.1%。在延遲權值較小的實驗2中,負載樹算法比LATE算法的作業集執行時間縮短了17.88%,調度效果一般。在延遲權值較大的實驗3中,負載樹算法使作業集執行時間縮短了23.59%。因此,負載率與延遲因子均需有所考慮,且比例應相當。圖3給出了實驗1-4的均衡度標準差,其中實驗2的負載均衡效果最為明顯。
實驗分析:
(1)任務完成時間受節點性能參數影響,完成時間因子可使任務優先選擇計算能力強的節點,縮短任務執行時間。通過前期實驗發現,該因子權值大時,任務將集中于高性能節點,加重了強節點負載,使弱節點空閑;反之,任務將被均勻分配,雖然優先分配到負載輕、具有本地數據的節點,但任務執行時間仍相對較長。傳統算法使任務趨向于在強節點執行,而少考慮負載的影響。因此,實驗設計固定完成時間因子權值,弱化節點性能對任務執行效率的影響,主要分析負載均衡策略與數據本地性的調度效果。
(2)實驗結果表明集群均衡度與負載率因子權值關系密切,均衡度標準差與負載率權值正相關,與算法設計相符。
(3)集群中不具有本地數據的節點需要耗費較多網絡延遲獲取數據備份。延遲因子的使用在于為任務找到更快獲得數據備份的節點。從實驗結果看,延遲因子權值小時,任務被分配到遠程節點的幾率增加,增加的延遲影響了任務執行時間;延遲因子權值大時,任務很少被分配到遠程節點,從而使任務集中于高帶寬鏈路節點,增加了該節點的負載,使遠程節點利用率降低,影響并行度,使均衡度下降;在負載與延遲比例相當時,作業集獲得了較好的執行時間。
因此,在固定完成時間因子前提下,集群執行效果的主導為負載率因子。延遲因子作為補充,在權值比例合適時,能較好地與負載率因子協同,獲得更好的調度效果。
4?結語
本文分析了現有異構任務調度算法存在負載不均衡、數據本地性問題,研究已有動態負載均衡算法性能改進方法,對在任務調度中引入負載均衡策略進行探討,提出了借助樹結構提高任務調度效率的負載樹算法。首先量化節點計算能力,并據此構造節點集最小堆,堆排序后形成計算能力逆序樹。通過節點資源使用情況計算負載率,將逆序樹調整為負載樹,并據此定義節點性能判別式與節點集均衡度標準差。通過任務完成時間、負載率、延遲因子計算決策值后,為任務確定執行節點。算法中樹結構具有自平衡能力,逆序樹可根據拓撲及節點計算能力變化動態調整,負載樹也可根據節點負載率變化及時調整。通過實驗選取不同負載率與延遲權值的作業集執行時間進行比較,并與LATE算法執行結果對比。實驗結果表明,負載樹算法能有效縮短作業集執行時間,在取得適合的因子權值比時,可進一步提升調度效率并使集群擁有較好的負載均衡度。
負載樹算法在并行效率與負載均衡間提供了協同調度途徑,但算法主要側重在節點選擇上,進一步研究工作是融入任務端優化策略,使節點與任務選擇共同作用于調度算法,并研究權值比例的自動取值實現。
參考文獻:
[1]?WIKIPEDIA. Apache hadoop [EB/OL]. http://en.wikipedia.org/wiki/Apache_Hadoop.
[2]?ZAHARIA M. Job scheduling with the fair and capacity schedulers [EB/OL]. http://www.cs.berkeley.edu/~matei/talks/2009/hadoop_summit_fair_scheduler.pdf.
[3]?THE APACHE SOFTWARE FOUNDATION. Capacity scheduler guide [EB/OL]. http://hadoop.apache.org/docs/r1.2.1/capacity_scheduler.html.
[4]?ZAHARIA M, BORTHAKUR D, SARMA J S, et al. Job scheduling for multi-user MapReduce clusters[R]. Berkeley: EECS Department, University of California,?2009:1?16.
[5]?THE APACHE SOFTWARE FOUNDATION. Fair scheduler guide [EB/OL]. http://hadoop.apache.org/docs/r1.2.1/fair_scheduler.html.
[6]?范杰,彭艦,黎紅友.基于蟻群算法的云計算需求彈性算法[J].計算機應用,2011,31(1):1?7.
[7]?楊鏡,吳磊,武德安,等.云平臺下動態任務調度人工免疫算法[J].計算機應用,2014,34(2):351?356.
[8]?FISCHER M, SU X, YIN Y. Assigning tasks for efficiency in Hadoop: extended abstract[C]. Proceedings of the 22nd ACM Symposium on Parallelism in Algorithms and Architectures, 2010:30?39.
[9]?GE Y, WEI G. GA?based task scheduler for the cloud computing systems[C]. Proceedings of 2010 International Conference on Web Information Systems and Mining, 2010:181?186.
[10]?ZAHARIA M, KONWINSKI A, JOSEPH A D, et al. Improving MapReduce performance in heterogeneous environments[C].Proceedings of the 8th USENIX Symposium on Operating Systems Design Implementation,2008:29?42.
[11]?ZAHARIA M, BORTHAKUR D, SARMA J S, et al. Delay scheduling: a simple technique for achieving locality and fairness in cluster scheduling[C]. Proceedings of the 5th European Conference on Computer Systems,2010:265?278.
[12]?劉奎,劉向東,馬寶來,等.基于數據局部性的推測式Hadoop任務調度算法研究[J].計算機應用研究,2014,31(1):182?187.
[13]?THAWARI V W, BABAR S D, DHAWAS N A, et al. An efficient data locality driven task scheduling algorithm for cloud computing[J]. International Journal In Multidisciplinary and Academic Research, 2012,1(3):151?158.
[14]?馬莉,唐善成,王靜,等.云計算環境下的動態反饋作業調度算法[J].西安交通大學學報,2014,48(7):77?82.
[15]?XIE J, MENG F, WANG H, et al. Research on scheduling scheme for Hadoop clusters[C]. Proceedings of the Procedia Computer Science, 2013:49?52.
[16]?戴炳榮,李超,曠志光,等.基于多策略的私有云資源彈性調度方法[J].計算機應用,2017,37(S1):34?38.
[17]?張繼榮,陳琛.基于負載均衡的云計算資源分配算法[J].微電子學與計算機,2017,34(9):43?47.
[18]?葛君偉,郭強,方義秋.一種基于改進蟻群算法的多目標優化云計算任務調度策略[J].微電子學與計算機,2017,34(11):63?67.
[19]?孫凌宇,冷明,朱平,等.云計算環境下基于禁忌搜索的負載均衡任務調度優化算法[J].小型微型計算機系統,2015,36(9):1948?1952.
[20]?劉亞秋,孫新越,景維鵬.一種異構云環境下的負載均衡算法[J].計算機應用研究,2018(12):1?2.
