文本分類中TF IDF權重計算方法改進
2018-02-12 12:24:56隗中杰
軟件導刊 2018年12期
隗中杰
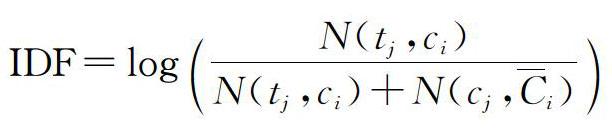


摘要:TF?IDF是文本分類中計算特征權重的經典方法,但其本身并未考慮特征詞在文檔集合中的分布情況,從而導致類別區分度不大。通過計算特征詞類內密度與特征詞在樣本中均勻分布時整體平均密度的比值對IDF函數進行改進。實驗結果表明,改進后的TF?IDF考慮了特征詞內分布與在整體文檔集中的分布,提升了對類別的區分能力,有效改善了文本分類效果。
關鍵詞:文本分類;密度;TF?IDF;特征權重;分布
Improvement of TF?IDF Weight Calculation Method in Text Classification
WEI Zhong?jie
(Information Technology and Network Security, People's Public Security University of China,Beijing 100038,China)
Abstract:TF?IDF is a classical method for calculating feature weight calculation in text classification, but it does not consider the distribution of feature words in the document collection itself, which results in less classification. In this paper, the IDF function is improved by calculating the ratio of the intra?class density of the feature words to the overall average density of the feature words evenly distributed in the sample. Experiments show that the improved TF?IDF considers the intra?class distribution of feature words and the distribution of the overall document set, which improves the ability to distinguish categories and effectively improves the text classification effect.
Key Words:text classification; density; TF?IDF; feature weight; distribution
0?引言
隨著信息技術的發展與大數據時代的到來,每天都會產生海量數據,信息量呈幾何級數增長,而文本數據在其中占據著非常重要的部分。因此,如何對相關數據進行有效處理以便于人們加以利用,文本分類是至關重要的。文本分類是指將未分類的文檔,通過分析文檔內容將其歸類為已知的某一個或某幾個類別[1]。文本分類通常需要經過文本預處理、特征選擇、文本向量化、分類4個步驟。本文將對經典方法TF?IDF進行改進,并通過實驗證明改進TF?IDF算法的有效性與可行性。
1?國內外研究現狀
TF?IDF是使用最為廣泛的文本特征權重計算方法[2],對其進行改進更是文本分類與聚類領域的研究重點。在國外,Forman[3]通過統計比較類分布的顯著性,對IDF進行二元正態分割;Lan等[4]提出TF?RF算法,用相關性頻率替代IDF。在國內,張玉芳等[5]將IDF計算改為IDF=log?N(t?j,c?i)N(t?j,c?i)+N(c?j,C?i),其中N(t?j,Ci)為類C?i中包含特征詞t?j的個數,N(t?j,C?i)為非類C?i包含特征t?j?的個數。該方法將類內與類間特征簡潔地體現在對IDF的改進中,從而一定程度上改善了傳統TF?IDF的缺陷;申劍博[6]通過調和類內均勻分布與類間比重,提出TF?DFI?DFO算法;覃世安[7]利用文檔中詞出現的概率替代詞頻,對IDF進行了優化;趙小華[8]通過CHI統計值對TF?IDF進行修正,提出TF?IDF?CHI算法,之后路永和等[9]將CHI值取自然對數,以改善其權重影響過大的問題,并提出TW?TF?IDF算法;馬瑩等[10]考慮特征詞之間的近義關系,結合語義相似度改進詞頻信息,從而改進了TF?IDF算法。此外,還有一些學者利用文檔長度與特征詞長度等信息對傳統方法進行改進[11?12]。本文通過特征詞類內聚集程度與文檔集中的平均密度改進TF?IDF方法,既考慮到特征詞的類內分布,又考慮到特征項在整體文檔集中的分布,從而有效解決了傳統TF?IDF算法類別區分能力較低的問題,提高了文本分類精度。
2?文本分類步驟
2.1?文本預處理
文本預處理主要步驟為分詞[13]與去停用詞。分詞即利用分詞算法將文本切分成字、詞、短語的過程,分詞精度對后續應用模塊影響很大,是語言處理最核心的任務。中文分詞任務是在詞與詞之間添加間隔符,并盡可能保證分詞準確性。分詞后的語料中包含大量無意義詞,例如人稱代詞、介詞、副詞等,這些詞稱為停用詞,對文本分類并無實質性幫助,反而會使特征空間過大,影響分類速度與精度。因此,在文本分類時,應將停用詞從特征集中去掉,以提高文本分類效率。
2.2?特征選擇
特征選擇[14]是指從一組特征中依據某個評估函數挑選出一些最具代表性的特征。特征選擇主要方法[15]包括文檔頻率(DF,Document Frequency)、信息增益(IG,Information Gain)、互信息(MI,Mutual Information)、χ?2統計量(CHI,Chi-square)、期望交叉熵(ECE,Expected Cross Entropy)等。其中χ?2統計量經過實驗驗證有著較好效果,因此本文在后續實驗中通過?χ?2統計量進行特征選擇。χ?2?統計方法是度量詞條與文檔類別之間相關程度的統計測試方法,其基本思想是通過觀察實際值與理論值之間偏差確定理論正確性,計算方程如下:
其中,N表示整個語料文檔總數,t為詞條,c為類別。A表示類別c中包含詞條t的文檔數,B表示非類別c中包含詞條t的文檔數,C表示類別c中不包含詞條t的數量,D表示非類別c中不包含詞條t的文檔數。
2.3?文本向量化
向量空間模型VSM[16]是應用最廣泛的文本表示模型,通過特征權重反映特征詞對文檔貢獻大小、對該文本內容標識能力及區分其它文本的能力,TF?IDF則是計算特征權重的方法之一。
2.4?文本分類
文本分類算法是指通過已知類別樣本得到分類器,再通過分類器對未知類別樣本進行自動分類。常見文本分類方法有KNN算法[17]、支持向量機(SVM)算法[18]、樸素貝葉斯算法、決策樹算法等。已有研究結果表明,SVM算法分類效果較好[19?21],因此本文選取SVM算法進行分類器訓練。
3?TF?IDF算法改進
3.1?傳統TF?IDF算法
TF?IDF是應用最廣泛的權值計算方法。TF指詞頻(Term Frequency),代表一個詞或詞組在文檔中出現的頻率,IDF指逆文檔頻率(Inverse Document?Frequence),反映詞語在整個文檔集中的重要性,其思想為整個文檔集合中包含某個詞或詞組的文檔數越多,代表該詞或詞組對文本貢獻越低。TF與IDF常用公式如式(2)、式(3)所示。
其中?N(t?i,d)表示特征詞條t?i在文檔d中出現次數,S表示文檔d總詞條數。
其中N表示總文檔數,N(t?i)表示文檔集中包含詞條的文檔數。
上式中,N(t?i)=N(t?i,C?j )+N(t?i,C?j),其中N(t?i,C?j )為特征詞t?i在類C?j中的文檔個數,N(t?i,C?j )為非類C?j中包含特征詞t?i的文檔個數,當N(t?i,C?j )增加時,N(t?i)?也隨之增加,IDF值則會減少,最終權重值也會減少,意味著該特征詞不能很好地將該類文檔與其它類別文檔加以區分,類別區分能力較弱。但是根據實際文本分類進行判斷,如果某一詞項在某一類中出現次數越多,越能代表該類文檔,特征權重也越高,且區別于其它類別的能力越強。因此,傳統IDF不能很好地反映特征詞分布情況,權值大小僅是由整個語料中包含特征項的文檔個數決定的,導致傳統TF?IDF的類別區分能力不足。
3.2?TF?IDF改進
現有某一語料,其類別集合為S={C?1,C?2,C?3,…,C?n},n為類別數目,特征詞集合為T={t?1,t?2,t_3,…,t?j },j為特征詞數目。本文提出的改進算法思想是:首先,假設特征詞t在整個語料中均勻分布,可求得特征詞t的分布密度ρ?t;其次,求出特征詞t對于類C?i的分布密度ρ?ti;最后,通過計算ρ?ti與ρ?t之間比值,便可得到類C?i中特征詞t的聚集程度c。c值越大,說明特征詞t在類C?i中聚集程度越高,反之亦然。基于以上思想,?對IDF進行以下改進:
其中,?N(t?j,C?i)表示類C?i中包含特征詞t?j的文本數目,N(t?j,C?i)表示類C?i中不包含特征詞t?j的數目,N(t?j,C?i)表示非類C?i中包含特征t?j的數目,N?為訓練集中的文檔總數。調整后的IDF′考慮到詞條加入的類別信息,從而克服了傳統TF?IDF存在的問題。
將公式進行如下驗證:類C?i中出現特征詞t?j的文檔數N(t?j,C?i)與特征詞t?j對于類C?i的特征權重應呈正相關。N(t?j,C?i )+N(t?j ,C?i) = N(C?i)與N都是一個常數。因此,上述公式可簡化為求N(t?j,C?i)與N(t?j,C?i)N(t?j,C?i)+N(t?j,C?i)的相關性。
其中,N(t?j,C?i)增加時,N(t?j,C?i)N(t?j,C?i)+N(t?j,C?i)的值也隨之增加,所以兩者正相關。因此,N(t?j,C?i)與特征權重呈正相關,即特征詞在某類中出現頻率越高,其相應特征權重越大。同理可證明,N(t?j,C?i)與特征權重負相關,即非類C?i中包含特征詞t?j的文檔越多,則特征詞t?j對于類C?i的?權重越小,符合對傳統TF?IDF改進的要求,因此可用于特征權重計算。
4?實驗結果及分析
4.1?實驗環境與實驗數據集
本文文本分類算法通過python語言加以實現,并在Windows10環境下進行測試,內存為8G。實驗數據來自搜狗實驗室搜集的9個類別新聞語料,包括財經、互聯網、健康、教育、軍事、旅游、體育、文化、招聘。本文在每類中隨機挑選1 000篇文章進行訓練與測試,訓練集與測試集比例為4∶1。
4.2?評價指標
本文采取準確率?P、召回率R、F1值及宏平均F1值對分類效果進行評估。分類結果有以下4種情況:①屬于類C的樣本被正確分類到類C的數目,記為TP;②不屬于類C的樣本被分類到類C的數目,記為FN;③屬于類C的樣本被錯誤分類到其它類,記為TN;④不屬于類C且被正確分到其它類,記為FP。
準確率即為預測該類樣本準確性,計算公式如下:
召回率即為預測正確的類別樣本對于樣本集中該類別樣本的覆蓋程度,公式為:
F1值用來調和準確率和召回率,計算公式如下:
宏平均F1值可用來評價整個分類器分類效果的優劣,其值為各類F1值的算術平均值。
4.3?實驗結果
本文實驗首先對文檔集合進行預處理,并使用統計量進行特征選擇,取每個類別值排名前100的關鍵詞組成特征集合。兩種算法通過SVM進行分類,實驗結果如圖1與表2所示。
從表2與圖1可以看出,改進TF?IDF相比于傳統TF?IDF,分類效果有著顯著提升。由圖1可以看出,各個類別的?F1?值均有所提升,其中“文化”一類提升最為明顯,提升了6.18%,并且宏平均?F1?值由84.50%提升到87.16%。實驗結果表明,改進后的TF?IDF方法對于提高文本分類效果是可行的。
5?結語
針對傳統TF?IDF不能體現特征詞分布情況以及類別區分能力不足的缺點,本文通過特征詞類內密度與特征詞均勻分布時的密度之比(聚集程度)對IDF進行改進。實驗結果證明,改進的TF?IDF算法分類效果優于傳統TF?IDF算法。文本分類中,特征詞提取也是其中的關鍵一環,因此在接下來研究中,將會對特征詞選擇與提取進行改進,以進一步提升文本分類效果。
參考文獻:
[1]?SEBASTIANI F. Machine learning in automated text categorization[J]. ACM Computing Surveys (CSUR), 2002, 34(1):1?47.
[2]?施聰鶯,徐朝軍,楊曉江.TFIDF算法研究綜述[J].計算機應用,2009,29(S1):167?170,180.
[3]?FORMAN G. BNS feature scaling: an improved representation over TF?IDF for SVM text classification[C].Proceedings of the 17th ACM Conference on Information and Knowledge Management. USA, California: ACM, 2008:263?270.
[4]?LAN M,TAN C L,LOW H B,et al.A comprehensive comparative study on term weighting schemes for text categorization with support vector machines[C].Special Interest Tracks and Posters of the 14th International Conference on World Wide Web,ACM,2005: 1032?1033.
[5]?張玉芳,彭時名,呂佳.基于文本分類TF?IDF方法的改進與應用[J].計算機工程,2006(19):76?78.
[6]?申劍博.改進的TF?IDF中文本特征詞加權算法研究[J].軟件導刊,2015,14(4):67?69.
[7]?覃世安,李法運.文本分類中TF?IDF方法的改進研究[J].現代圖書情報技術,2013(10):27?30.
[8]?趙小華.KNN文本分類中特征詞權重算法的研究[D].太原:太原理工大學,2010.
[9]?路永和,李焰鋒.改進TF?IDF算法的文本特征項權值計算方法[J].圖書情報工作,2013,57(3):90?95.
[10]?馬瑩,趙輝,李萬龍,等. 結合改進的CHI統計方法的TF?IDF算法優化[J]. 計算機應用研究,2019 (9):1?6.
[11]?賀科達,朱錚濤,程昱.基于改進TF?IDF算法的文本分類方法研究[J].廣東工業大學學報,2016,33(5):49?53.
[12]?楊彬,韓慶文,雷敏,等.基于改進的TF?IDF權重的短文本分類算法[J].重慶理工大學學報,2016,30(12):108?113.
[13]?梁喜濤,顧磊.中文分詞與詞性標注研究[J].計算機技術與發展,2015,25(2):175?180.
[14]?毛勇,周曉波,夏錚,等.特征選擇算法研究綜述[J].模式識別與人工智能,2007,20(2):211?218.
[15]?陳晨. 文本分類中基于k?means的特征選擇算法研究[D].西安:西安電子科技大學,2014.
[16]?SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J]. Communications of the Acm, 1974, 18(11):613?620.
[17]?COVER T, HART P E. Nearest neighbor pattern classification[J]. Information Theory, IEEE Transactions on, 1967,13(1):21?27.
[18]?丁世飛,齊丙娟,譚紅艷.支持向量機理論與算法研究綜述[J].電子科技大學學報,2011,40(1):2?10.
[19]?劉懷亮,張治國,馬志輝,等.基于SVM與KNN的中文文本分類比較實證研究[J].情報理論與實踐,2008,31(6):941?944.
[20]?馬建斌,李瀅,滕桂法,等.KNN和SVM算法在中文文本自動分類技術上的比較研究[J].河北農業大學學報,2008(3):120?123.
[21]?盧葦,彭雅.幾種常用文本分類算法性能比較與分析[J].湖南大學學報:自然科學版,2007(6):67?69.
