基于卷積神經(jīng)網(wǎng)絡(luò)的監(jiān)控場(chǎng)景下行人屬性識(shí)別
2018-02-09 17:54:36胡誠(chéng)陳亮張勛孫韶媛
現(xiàn)代計(jì)算機(jī) 2018年1期
關(guān)鍵詞:模型
胡誠(chéng),陳亮,張勛,孫韶媛
(1.東華大學(xué)信息科學(xué)與技術(shù)學(xué)院,上海 201620;2.東華大學(xué)數(shù)字化紡織服裝技術(shù)教育部工程研究中心,上海 201620)
0 引言
行人視覺(jué)屬性識(shí)別,由于它的高層的語(yǔ)義信息,可以建立人的底層特征和高層認(rèn)知的聯(lián)系。因此在計(jì)算機(jī)視覺(jué)領(lǐng)域是一個(gè)很熱門(mén)的研究方向。并且在很多的領(lǐng)域也取得了成功。例如:圖片檢索、目標(biāo)檢測(cè)、人臉識(shí)別。近些年,隨著平安城市的概念的提出,數(shù)以萬(wàn)計(jì)的監(jiān)控?cái)z像頭裝在了城市的各個(gè)角落,保護(hù)著人們的安全。因此,監(jiān)控場(chǎng)景下的行人視覺(jué)屬性的識(shí)別具有重要的研究?jī)r(jià)值,并且它也在智能視頻監(jiān)控和智能商業(yè)視頻有很大的市場(chǎng)前景。
當(dāng)前大多數(shù)的行人屬性識(shí)別研究主要在兩個(gè)應(yīng)用場(chǎng)景:自然場(chǎng)景和監(jiān)控場(chǎng)景。自然場(chǎng)景下的屬性識(shí)別研究較多,在目標(biāo)識(shí)別、人臉識(shí)別等研究方向上也取得了很好的成績(jī)。例如,自然場(chǎng)景下的屬性識(shí)別的研究最早是Ferriari[1]提出。在他的論文中,提出了概率生成模型去學(xué)習(xí)低層次的視覺(jué)屬性,例如:條紋和斑點(diǎn)。Zhang[2]提出了姿態(tài)對(duì)齊神經(jīng)網(wǎng)絡(luò),在沒(méi)有約束的場(chǎng)景下,對(duì)圖片進(jìn)行像年齡、性別和表情這些屬性的識(shí)別。在自然場(chǎng)景下用于行人屬性識(shí)別研究的樣本圖片的分辨率都很高。然而監(jiān)控場(chǎng)景下的行人樣本的圖片分辨率較低,并且很模糊。像行人戴眼鏡這樣的細(xì)粒度的屬性是很難識(shí)別出來(lái)的。主要是在真實(shí)的監(jiān)控場(chǎng)景中,是遠(yuǎn)距離拍攝行人的,很少能拍攝的到近距離的清晰的人臉和身體。監(jiān)控場(chǎng)景下的遠(yuǎn)距離拍攝也容易受到一些不可控的因素的影響。例如,光照強(qiáng)度的變化(例如白天和夜晚,室內(nèi)和室外),監(jiān)控?cái)z像頭不同的拍攝角度行人姿態(tài)的不同的變化,現(xiàn)實(shí)環(huán)境中物體的遮擋等等。因此,使用遠(yuǎn)距離拍攝的臉部或者行人身體的視覺(jué)信息來(lái)進(jìn)行屬性識(shí)別,這對(duì)監(jiān)控場(chǎng)景下的行人屬性識(shí)別的研究工作帶來(lái)挑戰(zhàn)。
由于上述的種種問(wèn)題,國(guó)內(nèi)外對(duì)于監(jiān)控場(chǎng)景下的行人屬性識(shí)別的研究工作還是比較少。Layne[3]是第一個(gè)通過(guò)使用支持向量機(jī)(SVM)去識(shí)別像背包、性別這樣的行人屬性,然后通過(guò)這些行人屬性信息來(lái)輔助行人的重識(shí)別。為了解決混合場(chǎng)景下的屬性識(shí)別問(wèn)題,Zhu[4]引入了APis數(shù)據(jù)庫(kù),并用Boosting算法去識(shí)別屬性。Deng[5]構(gòu)建了最大的行人屬性數(shù)據(jù)庫(kù),在這個(gè)數(shù)據(jù)集的基礎(chǔ)上使用支持向量機(jī)和馬爾科夫隨機(jī)場(chǎng)去識(shí)別屬性。然而這些方法,都是使用人工提取行人特征。而人工提取特征需要依賴(lài)人的經(jīng)驗(yàn)。經(jīng)驗(yàn)的好壞決定了屬性特征識(shí)別的精確度。另外,這些方法也忽略了屬性特征之間的關(guān)聯(lián)。例如,長(zhǎng)頭發(fā)這個(gè)屬性特征是女性的可能性一定是高于男性的。所以頭發(fā)的長(zhǎng)度有助于提高行人的性別的屬性的識(shí)別精度。
受到卷積神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺(jué)領(lǐng)域上廣泛的應(yīng)用的啟發(fā)。本文提出了一種在監(jiān)控場(chǎng)景下基于卷積神經(jīng)網(wǎng)絡(luò)來(lái)識(shí)別行人屬性的方法。卷積神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過(guò)程中可以自動(dòng)提取行人特征。重新定義新的損失函數(shù),同時(shí)考慮所有行人屬性特征之間的聯(lián)系。與人工提取特征的方法相比,操作簡(jiǎn)單,有效地利用了行人屬性特征之間的聯(lián)系,提高了屬性的識(shí)別精度。
1 網(wǎng)絡(luò)結(jié)構(gòu)
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)研究中的新的領(lǐng)域。其目的是建立、模擬人腦進(jìn)行分析學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)。模擬人腦的機(jī)制來(lái)解釋數(shù)據(jù),例如圖像、語(yǔ)音等。
1.1 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks)是深度學(xué)習(xí)的一種,目前已成為語(yǔ)音識(shí)別和圖像識(shí)別領(lǐng)域的研究熱點(diǎn)。一個(gè)典型的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),主要由卷積層、激勵(lì)層、池化層、全連接層等疊加而成。由于卷積神經(jīng)網(wǎng)絡(luò)的局部感受野和權(quán)值共享的特點(diǎn),降低網(wǎng)絡(luò)參數(shù)選擇的復(fù)雜度。圖像可以直接作為網(wǎng)絡(luò)的輸入,避免了傳統(tǒng)圖像識(shí)別算法中的復(fù)雜的特征提取和數(shù)據(jù)重建的過(guò)程。
1.2 AlexNet卷積神經(jīng)網(wǎng)絡(luò)
Krizhevsky[6]等人提出了一種新型卷積神經(jīng)網(wǎng)絡(luò)(簡(jiǎn)稱(chēng)AlexNet)在2012年大規(guī)模視覺(jué)識(shí)別挑戰(zhàn)競(jìng)賽中,贏(yíng)得了第一名,Top-5錯(cuò)誤率為15.3%,比上一屆冠軍下降了10%。該網(wǎng)絡(luò)模型在圖片識(shí)別上十分出色。典型的AlexNet網(wǎng)絡(luò)結(jié)構(gòu)如表1所示。總共有8層,其前五層是卷積層,即卷積層1、卷積層2、卷積層3、卷積層4、卷積層5。卷積層的作用是進(jìn)行特征提取。后三層是全連接層,即全連接層6、全連接層7、全連接層8。全連接層的作用是連接所有的特征,將輸出值輸入給Softmax分類(lèi)器。每一層都采用ReLu函數(shù),能保證數(shù)據(jù)輸入與輸出是可微的。在第一個(gè)和第二個(gè)ReLu函數(shù)后是響應(yīng)歸一化和最大化池化操作,同時(shí)第五個(gè)卷積層后也是最大化池化操作。另外,全連接層8,也是輸出層,輸出1000個(gè)節(jié)點(diǎn),對(duì)應(yīng)1000個(gè)類(lèi)別,應(yīng)用Softmax回歸函數(shù)得到分類(lèi)值。
盡管AlexNet網(wǎng)絡(luò)模型在圖像識(shí)別上表現(xiàn)很出色,但是卻存在兩方面的問(wèn)題:第一,該網(wǎng)絡(luò)模型目前應(yīng)用的場(chǎng)景是自然場(chǎng)景,圖片樣本的分辨率高。第二,AlexNet處理的圖片識(shí)別問(wèn)題都是單標(biāo)簽分類(lèi)問(wèn)題。即卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的時(shí)候,輸入給網(wǎng)絡(luò)是一張圖片和對(duì)應(yīng)的單個(gè)標(biāo)簽。真實(shí)監(jiān)控場(chǎng)景中,每一個(gè)行人樣本圖片中有性別、頭發(fā)、上下身衣服類(lèi)型和顏色等多種屬性。所以,AlexNet網(wǎng)絡(luò)模型無(wú)法直接解決行人屬性識(shí)別問(wèn)題。
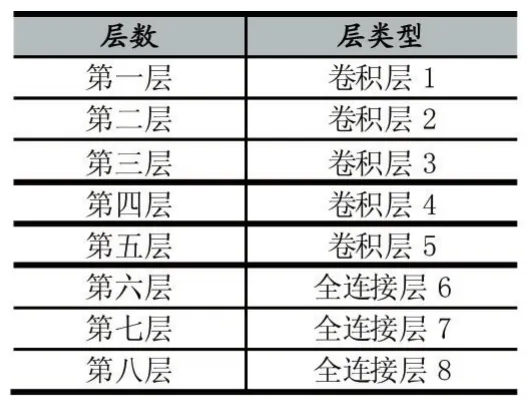
表1 AlexNet卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
1.3 行人屬性識(shí)別模型
假設(shè)行人樣本中有N張圖片,每張圖片標(biāo)注了L個(gè)行人屬性。比如性別、頭發(fā)長(zhǎng)度、年齡等。每張行人圖片可以表示xi,i∈[1,2…,N]。每張圖片xi對(duì)應(yīng)的行人屬性標(biāo)簽向量為yi。每個(gè)標(biāo)簽向量yi對(duì)應(yīng)的屬性值為如果yil=1,表明這個(gè)訓(xùn)練樣本xi有這個(gè)屬性;yil=0,表明這個(gè)訓(xùn)練樣本xi沒(méi)有這個(gè)屬性。
本文提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)的行人屬性識(shí)別模型(如圖1)。該模型是基于A(yíng)lexNet網(wǎng)絡(luò)模型微調(diào)的。基本網(wǎng)絡(luò)結(jié)構(gòu)與AlexNet相同,層數(shù)也是8層(前五層是卷積層,后三層是全連接層)。在模型訓(xùn)練階段,本文模型的輸入是一張行人圖片和對(duì)應(yīng)的行人屬性標(biāo)簽向量。測(cè)試階段,模型的輸出是對(duì)行人樣本圖片預(yù)測(cè)的屬性類(lèi)別。
通常,屬性之間是有關(guān)聯(lián)的。而大多數(shù)的屬性識(shí)別方法會(huì)把每一個(gè)屬性獨(dú)立起來(lái),忽略了屬性之間的關(guān)聯(lián)信息。例如頭發(fā)的長(zhǎng)度可以提高性別的識(shí)別精度。為了更好地利用屬性之間的關(guān)聯(lián),提高行人屬性的識(shí)別精度。本文重新提出了一種新的損失函數(shù),這樣本文的模型在訓(xùn)練過(guò)程中可以同時(shí)學(xué)習(xí)所有的行人屬性。損失函數(shù)(loss fuction)PLOSS如下所示。
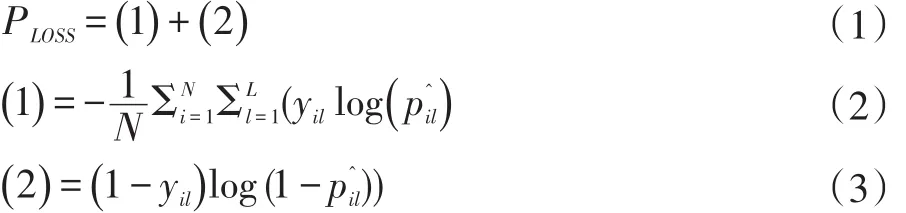
表示是行人樣本x的第l個(gè)屬性的概率。y是iil真實(shí)屬性標(biāo)簽,表示行人樣本xi有沒(méi)有第l個(gè)屬性。
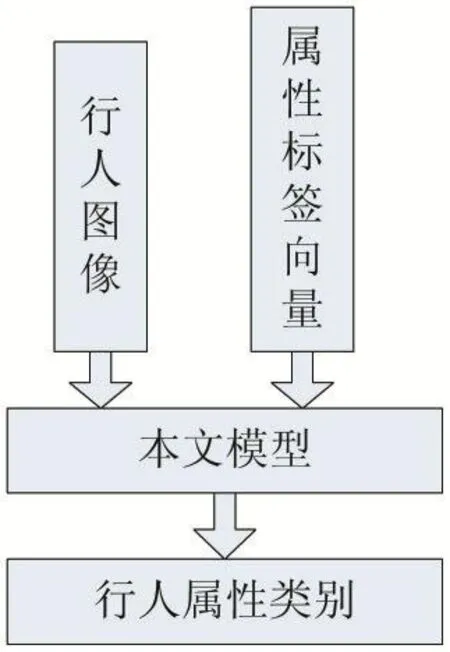
圖1 本文的屬性識(shí)別模型
2 實(shí)驗(yàn)
2.1 實(shí)驗(yàn)環(huán)境
本文算法采取的實(shí)驗(yàn)的軟硬件環(huán)境配置:操作系統(tǒng)是Ubuntu14.04,內(nèi)存是 8GB,CPU是Intel i5-6600,GPU是NVIDIA GTX1070,運(yùn)算平臺(tái)是CUDA8.0。使用深度學(xué)習(xí)的Caffe框架。Caffe是純粹的C++/CUDA架構(gòu),支持命令行、Python和MATLAB接口,可以直接在CPU和GPU之間無(wú)縫切換。
2.2 實(shí)驗(yàn)數(shù)據(jù)
本文的實(shí)驗(yàn)數(shù)據(jù)來(lái)源于合肥寰景信息技術(shù)有限公司與安徽大學(xué)聯(lián)合創(chuàng)辦的實(shí)驗(yàn)室在合肥市某地點(diǎn)抓拍的行人圖像,通過(guò)人工標(biāo)注得到每張行人圖像的標(biāo)注結(jié)果,以XML的形式保存。本文選取了19000張行人樣本。這些行人樣本都是監(jiān)控?cái)z像頭遠(yuǎn)距離拍攝,然后通過(guò)行人檢測(cè)算法剪切出來(lái)的,因此圖片的分辨率都不高。按照一個(gè)被大家廣泛采取的實(shí)驗(yàn)數(shù)據(jù)集劃分原則,我們把19000張圖片分成三部分:訓(xùn)練集,驗(yàn)證集,測(cè)試集。9500張用于訓(xùn)練,1900張用于驗(yàn)證,7600張用于測(cè)試。在網(wǎng)絡(luò)模型訓(xùn)練之前,將所有圖片的縮放到寬為256,高為256這樣的大小。另外,本文對(duì)每一張圖片都標(biāo)注了12個(gè)屬性標(biāo)簽:性別(男、女)、頭發(fā)長(zhǎng)度(長(zhǎng)發(fā)、短發(fā))、3種上身衣服類(lèi)型(T恤、襯衫、外套)、3種上身衣服顏色(黑色、白色、紅色、)、2種下身衣服的類(lèi)型(長(zhǎng)褲、長(zhǎng)裙)、2種下身衣服的顏色(黑色、白色)。并且每一個(gè)屬性標(biāo)簽都是二進(jìn)制標(biāo)簽,標(biāo)簽值分別為0或者1,0代表這個(gè)行人樣本沒(méi)有這個(gè)屬性,1代表這個(gè)行人有這個(gè)屬性。
2.3 實(shí)驗(yàn)參數(shù)設(shè)置
一般而言,卷積神經(jīng)網(wǎng)絡(luò)的最低層,可以學(xué)習(xí)到一些局部的顏色和紋理特征信息。利用這些特征信息,可以進(jìn)行大多數(shù)的物體的分類(lèi)識(shí)別。同時(shí),卷積神經(jīng)網(wǎng)絡(luò)的層數(shù)越多,可以學(xué)習(xí)到更高層次的語(yǔ)義信息,更豐富的細(xì)節(jié)信息。本文采取的卷積神經(jīng)網(wǎng)絡(luò)模型,是基于A(yíng)lexNet網(wǎng)絡(luò)模型來(lái)微調(diào)的,這樣可以更好的去學(xué)習(xí)到低層次和高層次的特征信息。另外,本文是在監(jiān)控場(chǎng)景下來(lái)進(jìn)行行人的屬性識(shí)別,而AlexNet是在自然場(chǎng)景下。所以為了使我們的網(wǎng)絡(luò)也適應(yīng)監(jiān)控場(chǎng)景,所以設(shè)置最初的學(xué)習(xí)率(base_lr)為0.001,權(quán)重衰減(weight decay)為0.005。總共迭代20000次,每迭代2000次,學(xué)習(xí)率降為原來(lái)的1/10。為了把屬性之間的聯(lián)系考慮起來(lái),采取公式(1)的損失函數(shù)。
2.4 實(shí)驗(yàn)流程
將用于訓(xùn)練的9600張和用于驗(yàn)證的1900張及其對(duì)應(yīng)的屬性標(biāo)簽向量,作為本文的卷積神經(jīng)網(wǎng)絡(luò)模型的輸入數(shù)據(jù)。通過(guò)20000次的不斷迭代學(xué)習(xí),直至模型收斂并保存模型參數(shù)。模型訓(xùn)練完成的時(shí)間,根據(jù)訓(xùn)練模型的日志,大約耗時(shí)3個(gè)小時(shí)。然后用訓(xùn)練好的模型參數(shù)來(lái)對(duì)剩余的7600張測(cè)試圖片進(jìn)行預(yù)測(cè)。
2.5 實(shí)驗(yàn)指標(biāo)
對(duì)于屬性識(shí)別算法,大多數(shù)文獻(xiàn)都采取平均精度(mA)作為評(píng)判指標(biāo)。本文也采取平均精度作為本論文的屬性識(shí)別結(jié)果的評(píng)價(jià)指標(biāo)。對(duì)每一個(gè)行人屬性,分別計(jì)算正樣本和負(fù)樣本的分類(lèi)識(shí)別的精確度,然后把正樣本和負(fù)樣本的識(shí)別精確度的平均值來(lái)作為該屬性的最終的識(shí)別精度。平均精度會(huì)把所有的行人屬性的識(shí)別精度的平均值來(lái)作為本文論文算法的最后的識(shí)別率。
平均精度的計(jì)算方式,如下:
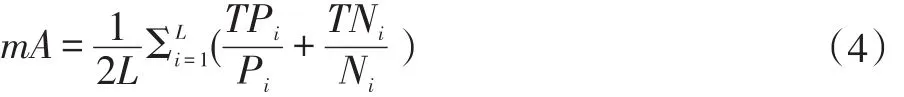
公式說(shuō)明:Pi表示測(cè)試樣本中第i個(gè)屬性的正標(biāo)簽的數(shù)目,TPi表示測(cè)試樣本中第i個(gè)屬性的正標(biāo)簽被預(yù)測(cè)正確的數(shù)目。Ni表示測(cè)試樣本中的第i個(gè)屬性的負(fù)標(biāo)簽的數(shù)目,TNi表示測(cè)試樣本中第i個(gè)屬性的負(fù)標(biāo)簽被正確預(yù)測(cè)的數(shù)目。L表示行人屬性總的數(shù)量。
2.6 實(shí)驗(yàn)結(jié)果分析
用訓(xùn)練好的模型,對(duì)行人樣本圖片進(jìn)行測(cè)試,實(shí)驗(yàn)結(jié)果如表2示。同時(shí)為了顯示本文算法的優(yōu)越性。用2.2小節(jié)中的實(shí)驗(yàn)數(shù)據(jù),也實(shí)驗(yàn)了文獻(xiàn)[5]的方法。該論文是采取人工提取特征,并且沒(méi)有考慮到屬性之間的相互聯(lián)系。從表3可以看出,本文提出的算法的平均精度明顯高于文獻(xiàn)[5]。行人屬性的識(shí)別精度都超過(guò)了80%以上。同時(shí)下身裙子、性別的識(shí)別精度都很高,因?yàn)閮烧呤怯新?lián)系的。生活中很常見(jiàn)穿裙子的女性,而不常見(jiàn)穿裙子的男性。這說(shuō)明考慮屬性的相互聯(lián)系,可以提高屬性的識(shí)別精度。另外,頭發(fā)”、“上.紅”這兩個(gè)屬性的識(shí)別精度不是很高。主要是行人樣本圖片中,有些行人戴了帽子,無(wú)法檢測(cè)到臉部區(qū)域的頭發(fā)長(zhǎng)度信息,導(dǎo)致檢測(cè)頭發(fā)的效果不佳。衣服顏色中某些衣服顏色的識(shí)別精度不高,比如上身紅色。主要是衣服顏色與行人佩戴的圍巾、背包顏色較近,在行人屬性標(biāo)注的時(shí)候,把它們都標(biāo)注在一個(gè)包圍框里,識(shí)別時(shí)產(chǎn)生了干擾,因而識(shí)別精度不高。
表中的上.T恤表示的是上身的衣服類(lèi)型是T恤。上.黑表示的是上身的衣服的顏色是黑色。
3 結(jié)語(yǔ)
本文提出了基于卷積神經(jīng)網(wǎng)絡(luò)的行人屬性識(shí)別算法來(lái)識(shí)別行人屬性。通過(guò)實(shí)驗(yàn)驗(yàn)證,該算法可以很好地完成行人多屬性識(shí)別任務(wù),具有良好的檢測(cè)效果。并且同傳統(tǒng)的方法相比,該算法還可以自動(dòng)學(xué)習(xí)特征,操作簡(jiǎn)單。但某些屬性,例如“頭發(fā)”、“上.紅”沒(méi)有達(dá)到預(yù)期的效果,原因是行人樣本中的有圍巾、背包、戴帽子這些干擾屬性,導(dǎo)致本文行人屬性識(shí)別模型識(shí)別時(shí)無(wú)法區(qū)分,識(shí)別到有效行人特征。在未來(lái)的工作中,希望該算法,提高這些屬性的識(shí)別精度。
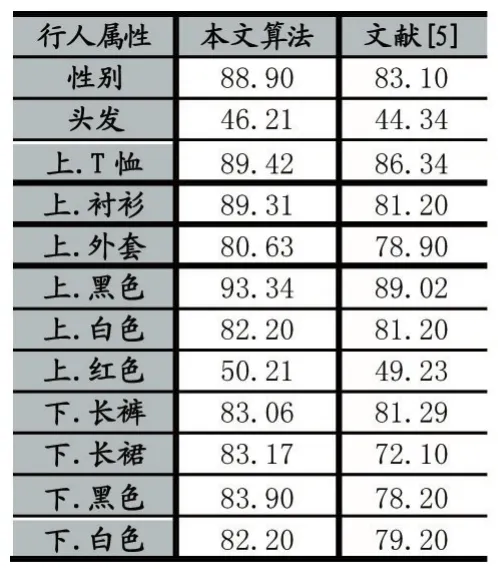
表2 不同算法的行人屬性識(shí)別率的比較
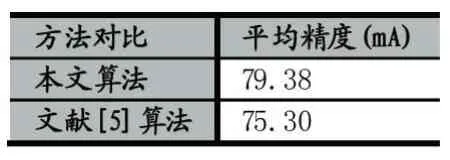
表3 本文算法與文獻(xiàn)[5]的平均精度的比較
[1]Ferrari V,Zisserman A.Learning Visual Attributes.[J].Advances in Neural Information Processing Systems,2007:433-440.
[2]Zhang N,Paluri M,Ranzato M,et al.PANDA:Pose Aligned Networks for Deep Attribute Modeling[C].Computer Vision and Pattern Recognition.IEEE,2014:1637-1644.
[3]Layne R,Hospedales T M,Gong S.Person Re-identification by Attributes[C]//BMVC.2012.
[4]Zhu J,Liao S,Lei Z,et al.Pedestrian Attribute Classification in Surveillance:Database and Evaluation[C].IEEE International Conference on Computer Vision Workshops.IEEE,2013:331-338.
[5]Deng Y,Luo P,Chen C L,et al.Pedestrian Attribute Recognition At Far Distance[C].ACM International Conference on Multimedia.ACM,2014:789-792.
[6]Krizhevsky A,Sutskever I,Hinton G E.ImageNet Classification with Deep Convolutional Neural Networks[C].International Conference on Neural Information Processing Systems.Curran Associates Inc.2012:1097-1105.
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19

- 現(xiàn)代計(jì)算機(jī)的其它文章
- 《無(wú)線(xiàn)傳感網(wǎng)絡(luò)》課程的教學(xué)模式研究與探索
- 應(yīng)用型本科高校電子類(lèi)專(zhuān)業(yè)創(chuàng)客教育實(shí)施路徑探析
- 新型智能導(dǎo)盲拐杖的設(shè)計(jì)
- 基于SQL Server的學(xué)校德育研究課題數(shù)據(jù)庫(kù)設(shè)計(jì)與應(yīng)用
- 校園全景導(dǎo)覽互動(dòng)投影系統(tǒng)
- 基于Hadoop-Streaming+LNMP的網(wǎng)站流量分析系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)