DPDK在國產申威處理器平臺上的應用與研究
2018-02-07 01:44:30何慧文
信息安全研究 2018年1期
明 旭 何慧文 陳 磊
(北京中科網威信息技術有限公司 北京 100094)(mingx@netpower.com.cn)
1 申威處理器與DPDK
處理器不自主,整個信息產業就是建筑在沙灘上的城堡.發展真正自主可控的處理器,對中國這樣一個正在崛起的大國而言,不僅意味著可以擁有更加安全可靠的信息基礎設施,更意味著在信息經濟時代掌控著事關國家經濟安全的重大技術話語權.
申威處理器是經過10多年的磨礪,凝結了無數科研人員的心血,獨立自主發展起來的國產處理器.10多年來,申威處理器從無到有,核心微結構持續升級,生產工藝不斷改進,先后研發了core1,core2,core2a,core3這4代處理器微結構,生產工藝也從最早的0.13 μm提高到了現在的28 nm.全部采用申威26010眾核處理器的“太湖之光”超級計算機,這2年來大放異彩,連續4次登頂世界超算TOP500,在“太湖之光”上運行的應用更是史無前例地連續2年獲得戈登貝爾獎[1].申威處理器在超算領域取得的巨大成就說明,和10多年前相比,申威處理器的性能、穩定性都實現了跨越式的提升,已經初步具備與當今國際先進處理器相抗衡的能力[2].
在網絡安全領域,圍繞申威多核處理器的自主可控安全生態從無到有,日漸發展,現在已經初具規模,已經有十幾家公司采用申威處理器推出了防火墻、網閘、入侵檢測、漏洞掃描、數據庫審計等各類網安產品[3].但這些產品與采用X86處理器的同類產品相比還是存在一些差距,主要體現在產品的性能上,其中的主要原因有2點:1)申威處理器單核性能與X86處理器相比還有50%左右的差距;2)X86等處理器的生態,經過幾十年發展,通過不斷的嘗試和探索,在與網安產品密切相關的網絡數據包處理技術方面,發展出了一系列較為成熟、高效的模型和框架,如:新浪的fastsocket,PowerPC的DPAA,Intel的DPDK.
1.1 網絡數據包處理框架與DPDK
在多核多線程處理器平臺上進行網絡數據包的處理,使用傳統的Linux內核協議棧會存在嚴重的性能瓶頸.對于如何提高網絡數據包處理的性能,業界有著比較統一的認識和建議:
1) 盡量不要讓不同的線程訪問臨界資源,因為互斥上鎖會降低系統的執行效率;理想情況是讓每個線程只訪問自己的資源和數據結構.
2) 線程數能少則少,因為線程在各個CPU核心上的調度會造成一定的切換開銷,并且造成Cache命中率的降低.
3) 優化數據包的進出路徑,盡可能減少數據的拷貝,特別是內核態和用戶態之間的數據拷貝.
在具體實踐中,綜合上述建議,有2個主要的優化策略可供選擇:1)依照上述建議不斷優化Linux內核協議棧[3],代表項目如新浪的FastSocket.FastSocket對協議棧的優化主要體現在單核處理性能的提升,相比傳統協議棧能夠提升20%~45%的性能;另外,在多核性能優化上也有著一定的性能提升.2)采用全新的架構設計,使數據處理的路徑繞過內核協議棧,代表項目如Intel的DPDK.
DPDK(Intel data plane development kit)是Intel提供的數據平面開發工具集[4],為IA(Intel architecture)處理器架構下用戶空間高效的數據包處理提供庫函數和驅動的支持.不同于Linux系統以通用性設計為目的,DPDK專注于網絡數據包的處理,針對X86處理器和網卡作了一系列的深度優化,從而提升數據包吞吐量[5].
DPDK不使用原有的內核協議棧,所有的應用需要使用DPDK提供的函數進行重新開發.但與使用內核協議棧相比,DPDK的優勢除了減少中斷次數和數據拷貝次數外,還使得相關應用獲得了協議棧的控制權,能夠通過定制降低協議棧復雜度.理論上,使用DPDK方案,應用的網絡數據包處理性能可以達到采用傳統Linux協議棧方案10倍以上.
1.2 DPDK應用在申威處理器平臺的意義
在處理器微架構設計上,國產申威處理器與國際主流商用處理器已經基本保持了一致, 如超標量、亂序執行、大容量Cache、雙訪存流水線等.而且由于申威處理器采用的指令集架構自身的特點,相比采用CISC架構的X86處理器,可以高效集成更多的處理器核心;但由于生產工藝相對不高,特別是處理器的訪存能力仍需進一步提升,使得申威處理器的單核性能仍存在相當的差距.
DPDK的出現給國產申威處理器在網絡應用上揚長避短帶來了重大機會.首先,DPDK使用大頁緩存技術、內存池和無鎖環形緩存管理等技術來提高內存訪問效率;同時,利用PMD支持,提供應用空間下驅動程序的支持,減少了報文的內存間拷貝.這些技術都使得申威處理器訪存能力不足的問題得到了相當程度的彌補.另外,DPDK廣泛采用處理器核親和技術,把各項處理作業分配到特定的處理器核上分別處理,從而發揮各個處理器核的潛能.這又使得申威處理器核多的優勢得到較為充分地發揮.
結合申威處理器的自身特點,將DPDK高效地移植到申威處理器平臺上,可以大幅提高申威處理器平臺的網絡處理能力,在網絡數據包處理方面進一步縮小和X86等處理器之間的差距,可以為在申威處理器平臺上實現多種高速網絡應用提供有效的技術支撐,從而拓寬國產申威處理器在網絡設備、網絡安全設備、存儲設備、高性能服務器等產品領域的應用,同時也可以為DPDK向其他自主國產處理器上的移植提供有價值的參考.
2 DPDK概覽
從字面解釋上看,DPDK是專注于數據平面軟件開發的套件;本質上,它是一組可以從用戶空間調用的軟件庫,提供了一種開銷更小的方法來代替傳統的Linux系統調用,使得應用程序可以繞過內核直接和底層硬件交互.
網絡數據包不再通過內核,而是直接走DPDK的專有路徑,從網卡直接到達用戶空間,交由用戶處理,從而將繁重的數據包過濾、數據包轉發工作從內核態轉至用戶態.
另外,DPDK實現了多核“無鎖”并行結構,使多處理器核心可以高效并行工作,并充分發揮速度越來越快的IO接口的能力,從而最大限度上提高網絡數據包處理效率.
使用DPDK,將不能再用原來的Linux內核協議棧,而且所有的應用都需要基于DPDK提供的函數庫進行重構.但由于網卡等設備的驅動程序都運行在用戶層,不容易崩潰,調試方便,可以大幅降低高性能網絡數據處理程序開發、調試的難度[6].
2.1 DPDK架構
從總體架構圖(圖1)我們可以看出,DPDK將全部功能都從內核態搬到了用戶態[7].
1) EAL(environment abstraction layer)即環境抽象層,為應用提供了一個通用接口,隱藏了與底層庫與設備打交道的相關細節.EAL實現了DPDK運行的初始化工作,包括基于大頁表的內存分配、多核親和性設置、原子操作和鎖操作,將PCI設備地址映射到用戶空間,方便應用程序訪問.
2) Buffer Manager API通過預先從EAL上分配固定大小的多個內存對象,避免了在運行過程中動態進行內存分配和回收來提高效率,常常用作數據包緩沖來使用.
3) Queue Manager API以高效的方式實現了無鎖的FIFO環形隊列,適合與一個生產者多個消費者、一個消費者多個生產者模型來避免等待,并且支持批量無鎖的操作.
4) Flow Classification API通過Intel SSE基于多元組實現了高效的hash算法,以便快速地將數據包進行分類處理.該API一般用于路由查找過程中的最長前綴匹配,應用中根據Flow五元組來標記不同用戶的場景也可以使用.
5) PMD則實現了Intel 1GbE,10GbE和40GbE網卡下基于輪詢收發包的工作模式,大大加速網卡收發包性能.
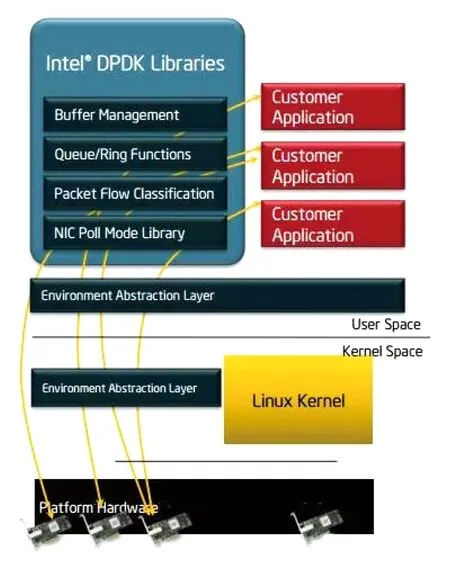
圖1 DPDK總體架構圖
2.2 DPDK關鍵技術
DPDK之所以可以提供高性能的數據處理能力,在于它從驅動、內存、線程、Cache等各個方面所做的綜合性的深度優化,這些優化主要包括:
1) 使用大頁內存,降低Cache miss,提高命中率,進而提升處理器訪問內存的速度;
2) 使用PMD技術,將報文直接拷貝到用戶態進行處理;
3) 通過CPU親和性綁定網卡和線程到固定的CPU核,減少處理器核間任務切換的開銷;
4) 使用無鎖隊列,減少資源競爭.
下面簡要介紹DPDK的這幾項關鍵技術[8]:
1) 使用大頁內存(hugepage)提高內存訪問效率.
TLB(translation look-side buffer) Cache是CPU中單獨的一塊高速緩存,為了實現虛擬地址到物理地址的轉換,Linux首先要查找TLB Cache來進行快速映射.如果在查找時TLB沒有命中,就會觸發一次缺頁中斷,處理器就需要到內存中去訪問多級頁表,才能最終得到物理地址,從而導致極大的處理器開銷.
Linux默認頁大小為4 KB,在程序使用大內存時,需要大量的頁表表項才能保證不出現TLB不命中的情況.而TLB Cache的大小是很有限的,一般只能容納100條頁表表項,只有使用hugepage才能確保TLB Cache的全命中.
為此,DPDK缺省提供了2 MB和1 GB這2種方式的hugepage支持.測試表明使用大頁表比使用4 KB的頁表性能提高10%~15%
2) 使用PMD(poll mode drivers),將網絡數據包處理工作全部遷移到用戶態,并以全輪詢的模式進行處理.
NAPI明顯改善了傳統Linux系統的包處理能力,但由于收發包仍然以系統中斷為基礎,首先是從中斷發生到應用感知,還要經過很長的軟件處理路徑;另外,數據包在內核態和用戶態之間的拷貝也難以避免.總之,對內核協議棧進行改良的NAPI等機制還是不能充分發揮底層硬件的能力,不能真正釋放出其網絡數據包處理的能力.
DPDK針對Intel網卡實現了基于全輪詢方式的PMD驅動,該驅動由API、用戶空間運行的驅動程序構成,使用無中斷方式直接操作網卡的接收和發送隊列.PMD驅動從網卡上接收到數據包后,會直接通過DMA方式傳輸到預分配的內存中,同時更新無鎖環形隊列中的數據包指針,不斷輪詢的應用程序很快就能感知收到數據包,并在預分配的內存地址上直接處理數據包,這個過程非常簡潔.
另外,由于整個處理過程都在用戶空間完成,自然規避了報文在核心態和用戶態之間的拷貝[9].
目前PMD驅動支持Intel的大部分1 G,10 G和40 G的網卡.
3) 利用Linux親和性支持,避免線程在不同核間的切換.
在單個處理器核上,多線程可以提高各應用的并發運行程度,從而提高CPU的整體利用率;但線程的創建和銷毀都有開銷,還會引入上下文切換、訪存沖突、Cache失效等諸多消耗性能的因素.在CPU多核時代,可以通過仔細規劃線程在CPU不同核上的分布,達到既保持應用的高速并發運行,又減少線程切換開銷的目的[10].
DPDK就利用了Linux線程的CPU親和性,將特定任務綁定到只在某個CPU核上運行,從而避免線程在不同核間的頻繁切換,減少Cache miss和Cache write back等性能損失.
DPDK運行在用戶態,但線程的調度仍然依賴內核.作為更進一步的優化,DPDK使用了限定某些核不參與Linux系統調度的技術手段,使特定的任務線程(如網絡收發包線程)可以獨占CPU核.這對網絡數據包的全輪詢處理起到了重要的支撐作用.
4) 提供無鎖環形緩沖區管理和緩存池,提高內存訪問效率.
當前的多核處理器特別是服務器處理器通常提供4個、8個甚至更多的CPU核,在諸多高并發應用中,多個CPU核之間訪問內存等資源時產生的鎖競爭有時會比數據拷貝、上下文切換更加傷害系統的性能.因此,在多核環境下,如果能夠把重要的數據結構從鎖的保護下遷移到無鎖機制中,可以極大地提升應用軟件的性能.
DPDK基于無鎖環形緩沖的原理,實現了一套無鎖環形緩沖區隊列管理API,支持單生產者入列單生產者出列、多生產者入列多生產者出列的操作,很大程度上提高了內存訪問的效率[11].
另外,DPDK提供的緩存池,可以將多個收發包集中到一個Cache line,進一步提升了Cache利用率.
3 DPDK移植申威處器平臺難點要點分析
DPDK是Intel專門為X86處理器定制的,將DPDK移植到申威處理器平臺上肯定會面臨諸多的技術挑戰.為此,我們對申威處理器及其指令集以及DPDK本身都進行了較為深入的技術預研,從而在移植可行性、移植難度、所需資源上給后續的工程化研制提供評估基礎.
本節首先介紹我們在先期研究中發現的移植上可能存在的一些技術難點,然后介紹我們應對這些難點的策略,最后,介紹我們在預研中總結出的,基于國產申威處理器進行高性能網絡數據處理功能(包括但不限于DPDK)的研發的一些要點,希望能讓在國產申威處理器上研發各類網絡產品的同行有所借鑒.
第4節將介紹我們基于SW411硬件平臺,初步移植DPDK并搭建的防火墻原型機,主要用于驗證在類似DPDK的全用戶態輪詢模式下,網絡數據包收發系統的性能是否會有質的提升,從而為使用基于非X86架構的國產處理器研發高性能的網絡產品和網絡安全產品提供一定的實踐支撐.
3.1 移植難點
通過預研,我們認為將DPDK移植到申威平臺上的技術難點主要有3個:
1) DPDK無協議棧
DPDK不能再使用原有的內核協議棧,相關功能都需要依照DPDK提供的函數庫進行重構開發.理論上,需要在用戶態實現Linux內核協議棧的大部分功能,這可能會導致所需的時間成本和人力成本難以接受[12].
2) 申威沒有專門的CAS指令
在X86處理器上運行的DPDK大量使用CAS(compare and swap)指令,為在多核間實現高效的數據同步發揮了極其重要的作用.基于RISC架構的申威自主指令集采用的是LoadStore型指令系統,沒有專門的CAS指令.這為移植工作帶來了很大的麻煩和風險.
3) 申威SIMD支持與Intel SIMD指令集不完全兼容
SIMD(Single Instruction Multiple Data)意為單指令多數據[13],以特定寬度(如64 b)為一個數據單元,多數據指的就是多個可以獨立操作的數據單元,SIMD指的就是單個指令可以同時作用到多個數據單元.
實現SIMD需要處理器硬件的支持,處理器需要集成專門的SIMD寄存器.Intel處理器提供了128 b的XMM寄存器或者256 b的YMM寄存器,也稱為SIMD擴展部件.
申威處理器也提供SIMD支持,但申威指令集中的SIMD指令與Intel的SIMD指令對應性不強,移植中有大量相關代碼需要手工修改,對移植工作是一個重大挑戰.
3.2 難點解決策略
針對預研中發現的幾個難點,我們結合以往的研發經驗,反復嘗試,基本都找到了比較滿意的解決途徑.
1) 構建“慢速路徑+快速路徑”的處理構架
針對DPDK無協議棧的問題,通用解決辦法一般有2種:1)自己開發;2)使用開源協議棧與DPDK適配.自己開發工作量太大,而我們評估了幾個開源協議棧,其成熟度和穩定性都和Linux協議棧相去甚遠,而且適配的工作量也不小.
為此,我們結合網絡數據包處理的特點,設計了一個穩定、高效的框架,其基本原理在于:路由的確定、過濾規則的匹配在一個會話流的第1個數據包就可以決定[14].因此,可以基于DPDK構建一個“慢速路徑+快速路徑”的處理框架,在網絡會話的建立、撤銷等階段,仍將數據包交由Linux內核協議棧處理;會話成功建立后的后續數據包直接交由基于DPDK的上層應用處理.這樣,只有極少量的數據包在“耗時”的慢速路徑上流轉,大部分數據包將通過在快速路徑上建立的流表快速轉發.
其原理圖如圖2所示:
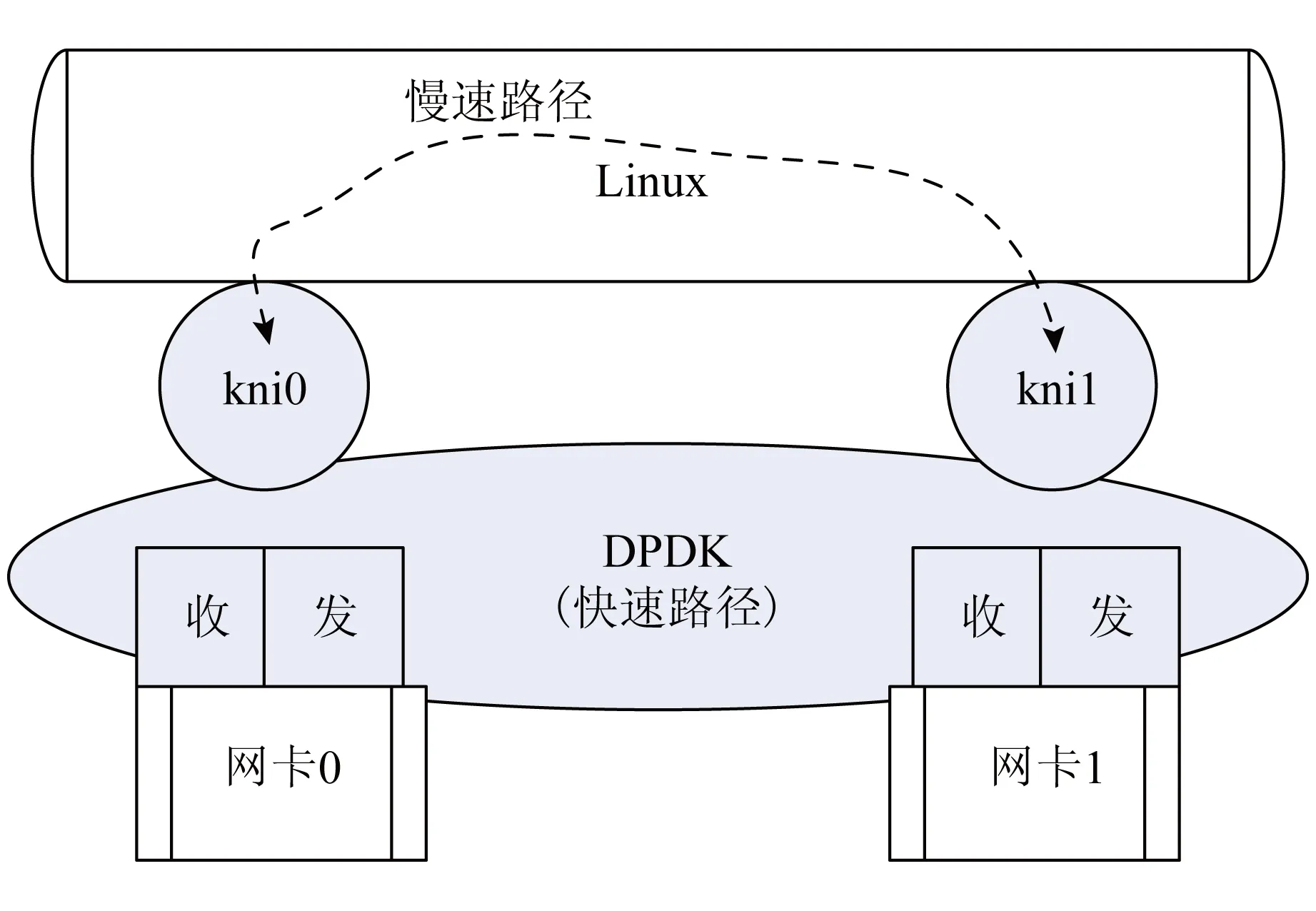
圖2 DPDK+Linux協議棧的快速、慢速處理結構
構建“慢速路徑+快速路徑”的處理構架的主要難點在于,要在用戶態下實現與內核協議棧相匹配的、用于會話控制、會話狀態記錄的數據結構,并讓相關的會話記錄和會話狀態的改變保持實時的同步.另外,對于數據包7層以上協議數據的分析,要盡量保證在會話流起始的一個或者幾個數據包中完成判斷[15].
2) 高效模擬CAS指令
在申威指令集不提供CAS指令的情況下,用申威指令模擬實現一個功能完全一致的CAS函數,可以最大程度上減少代碼移植的工作量.
在實際移植工作中我們反復實驗,最終確定了用11條申威匯編指令組成的最優CAS模擬,經過實際測試,效果令人滿意,不但功能滿足要求,性能表現也足夠優異.
3) 封裝申威SIMD
SIMD技術廣泛應用于通用處理器,為提升程序性能提供了硬件支持.實際工程經驗顯示,如能充分發掘程序中的并行性,進行基于SIMD的優化,可以使應用的性能得到50%~70%的提升.DPDK中就大量使用了SIMD進行各類并行化數據處理.
申威指令集也提供了對SIMD的支持,而且出于超算的需要,技術上成熟、高效——通過使用申威的SIMD擴展指令系統,可以完成256 b的8倍字整數數據的單指令存取,將8~64 b的待運算數據合并為一個256 b的超長數據,然后使用一條指令完成傳統多條指令才能完成的運算.
但申威指令集與Intel的SIMD指令集對應性不強,移植中有大量相關代碼需要手工修改,如不采取相關技術手段會導致移植工作繁瑣雜亂,并且給代碼以后的升級維護造成障礙.
我們仍然采用了和模擬CAS指令相類似的技術手段,通過一系列細致的分析和編程工作,對申威SIMD指令進行了較為徹底的封裝,使DPDK的代碼無需任何修改即可直接在申威處理器上運行,讓程序員從繁冗復雜的移植編碼工作中解脫出來,提高了移植工作的效率,并使得整個移植后的系統具備了較為良好的可擴展性.
3.3 技術要點
DPDK的本質是網絡數據處理的“最優工程實踐經驗”的總結,在移植工作中只知道照搬照抄是很難體會其思想內涵的.在本節內容中,我們嘗試不局限于DPDK,總結了幾點我們對基于國產申威處理器進行高性能網絡數據處理功能研發的一些“實踐經驗”,希望能讓在國產申威處理器上研發各類網絡產品的同行有所借鑒.
1) 網卡的多隊列機制和申威CPU多核的緊密結合
當前主流的千兆、萬兆網卡芯片都提供了內置的負載均衡算法,能夠將高速的網絡數據流分為多個數據隊列,這些數據隊列以內存硬件通道的形式展現在CPU的面前,CPU可以讓自己不同的核去訪問不同的通道,核之間對隊列的數據讀寫不會相互影響[16].
申威處理器相比X86處理器,可以高效集成更多的處理器核心,配以網卡的多隊列機制,理論上可以獲得更高的并發處理能力.
但是,如果對PCI-E總線的訪問不能做到高效,會導致并行數據流處理帶來的性能優勢部分損失.
這就需要深入理解和分析申威處理器的PCI-E總線接口芯片的工作原理,理解申威處理器PCI-E事務的基本數據包交換單元TLP(transaction layer packet)和網卡數據包之間的關系.在此基礎上,可以通過調整網卡驅動對數據包的封裝,使之與TLP更匹配,從而做到網卡芯片與申威多核之間的緊密結合[17].
另外,減少MMIO的訪問頻度也是提升PCI-E并行傳輸能力的關鍵點.
2) 內存的高效訪問
多個CPU核訪問同一段內存池甚至同一個環形緩存區時,因為每次讀寫時都要進行Compare-and-Set操作來保證期間數據未被其他核心修改,所以存取效率較低.需要研究的是在應用軟件中,通過包括DPDK支持在內的手段,盡量讓每個核只訪問自己的數據,從而使其所要處理的數據盡可能緩存在自己的Cache中.另外,盡量對環形緩存區進行塊讀寫操作,以減少訪問環形緩存區的次數[15].
3) 收發包批處理
收發包是一個相對復雜的軟件運算過程,其中主要包含緩存的分配與釋放、描述符的解析與構造,涉及多個數據結構的讀、寫訪問[18].
只要涉及比較多的數據訪問,就應盡量讓數據訪問都能在處理器緩存中完成( Cache hit),這是實現高性能網絡數據包處理的重要手段.反之,Cache miss會導致內存訪問,引人大量延遲,是性能殺手.
對收發包實現批處理是一項細致但物有所值的工作,其基本原理是把收發包復雜的處理過程進行分解,打散成不同的相對較小的處理階段,把相鄰的數據訪問、相似的數據運算集中處理.這樣就能盡可能減少對內存或者低一級的處理器緩存的訪問次數,用更少的訪問次數來完成更多次收發包運算所需要數據的讀或者寫.在這方面,我們還需要有更多的實踐經驗積累[19].
4) 針對小包的Cache預取機制優化
申威處理器的Cache line為128 B,Intel平臺的Cache line為64 B;對于64 B小包來說,一次Cache預取在Intel平臺下剛好完全使用,而申威會浪費一半的Cache資源.為了高效使用申威處理器的Cache,需要重新設定頻繁訪問的數據結構的Cache align(Cache對齊)為128 B,并修正數據包內存池,以便讓2個64 B小包連續存儲.這樣在進行數據包預取時,一個預取指令可以緩存2個小包,同時避免了寶貴的Cache資源的浪費,大大提升了申威處理器對小包的處理能力[20].
4 原型機簡介
我們研制的原型機主要用來驗證影響網絡數據包處理的核心問題——性能,在基于申威處理器的DPDK框架下是否可以得到大幅提升.原型機在整體結構和應用邏輯上的設計應該盡量簡潔,以方便發現整個系統在DPDK框架下的處理邏輯的性能瓶頸,從而針對相關瓶頸進行性能優化.
原型機的成果可用于快速評估SW-DPDK在申威平臺上的應用效果,相關測試參數和軟件構架可以指引后續更復雜的防火墻、路由器、VPN等其他商用安全產品研發的可行性分析與架構設計.
4.1 設計方案
以DPDK平臺為基礎開發平臺,搭建調度模塊、配置模塊、規則匹配模塊(含靜態路由匹配)、流匹配模塊、收包模塊、發包模塊和日志模塊.
圖3給出了這些模塊的邏輯關系:

圖3 模塊的邏輯關系圖
1) 調度模塊負責加載運行其他模塊;
2) 由人工(或者從存儲數據中)輸入ACL規則、靜態路由規則,這些規則通過規則邏輯進入規則匹配模塊;
3) 人工操作(添加、刪除、修改)的ACL規則、靜態路由規則會被日志模塊記錄;
4) 流匹配模塊是根據收到的數據包和ACL規則、靜態路由規則動態構建的;
5) 流匹配情況、規則匹配情況會被日志模塊記錄;
6) 收到數據包后先進行流匹配再進行規則匹配,允許通過的數據包會通過發模塊發出.
4.2 實施過程
原型機的研發工作分為移植、優化和應用3個階段:
1) 移植階段:
① 在SW411環境下重新編譯DPDK代碼;
② 初步優化匯編指令代碼,包括O3,RTC,CAS鎖等;
③ 實現轉發Demo:只做轉發,不做查表處理等工作,并初步測試、評估DPDK的能力.
2) 優化階段
① 在轉發Demo基礎上進行系列的匹配和優化工作,主要包括:內存訪問到chip的并行、盡量保證Cache的對齊和一致、申威處理器的SIMD功能應用、按照core分配內存、隊列HASH鎖等;
② 深度優化:交叉內存、Cache、SIMD;
③ 結構設計:網卡多隊列、多核并行.
3) 應用階段
① 面向邏輯處理完善系統功能,包括多核并行的表優化,使用SIMD進行查表等;
② 提供基于申威DPDK的防火墻原型機,進行性能對比測試.
4.3 性能對比
測試對象:SW411平臺通用型設備、基于DPDK技術加速的防火墻原型機.
測試條件:1對千兆口,100條流平均分配到多個處理器核,60 s時長,采用橋模式,默認全通配置,初始值100%.
測試標準:RFC2544吞吐、時延.
測試結果如表1所示.
測試結論:在基于SW411處理器的硬件平臺上應用DPDK框架后,64 B小包吞吐率提升12倍以上,1 518 B大包時延降低95%左右.因為已達到線速,小包吞吐率應該仍有進一步提升的空間,這將有賴于支持萬兆的原型機進行驗證.

表1 通用型設備和基于DPDK技術加速的防火墻原型機性能對比表
5 結束語
經過10多年的持續發展,國產申威處理器在性能、穩定性方面都取得了長足的進步,已經基本具備了與當今國際先進處理器相抗衡的能力.在網絡安全領域,已經有很多公司采用申威處理器推出了各類產品,但由于申威處理器單核性能的不足,以及缺少先進網絡數據包處理模型和框架的支撐,這些產品與采用X86處理器的同類產品相比,在產品性能等方面還存在一些差距.
DPDK等用戶態網絡數據包處理器框架的出現給國產申威處理器在網絡安全等產品的應用上帶來了揚長避短的機會,將DPDK之類的框架移植到申威平臺上可以發揮申威處理器的多核優勢.
本文分析了將DPDK移植到申威處理器平臺上存在的難點,并提出了應對這些難點的解決策略和關鍵技術.進一步,我們總結了幾點在國產申威處理器平臺上進行高性能網絡產品研發的實踐經驗.最后,介紹了我們基于申威411芯片,在移植DPDK的基礎上研發的防火墻原型機,驗證了在DPDK的全用戶態輪詢模式下,網絡數據包收發系統的性能取得的巨大提升,64 B小包的吞吐率從原始的7.2%提升到了100%線速.
最后,在此次移植工作的基礎上,我們對未來基于申威處理器平臺和用戶態數據包處理框架的網絡安全產品的研發作如下預測和展望:
1) 申威處理器的持續發展將使DPDK等框架發揮更大潛力
申威1621處理器是基于增強版的第三代“申威64”核心的國產高性能多核處理器,單芯片集成了16個64 b RISC結構的申威處理器核心.在指令集和微結構方面,申威1621處理器也提供更多的功能支持,如預取指令支持、NUMA支持和虛擬化支持等.
我們初步評估,在申威1621的指令優化和16核支撐下,DPDK等框架的潛能可以得到進一步的發揮,將可以實現線速的萬兆防火墻產品.
2) DPDK等框架會促進申威處理器指令集與微架構的進一步提升
由于各種原因,申威處理器一直比較注重與超算相關的浮點運算等能力的提升,對網絡數據包處理能力的重視程度不高.有助于充分發揮申威多核優勢的DPDK等框架的出現,會提升申威多核服務器處理器對高性能網絡數據包處理領域的關注度.可以預見,申威處理器在指令集和微架構優化等關鍵技術上將會加大這方面的支持.我們非常期待CAS無鎖指令、類DDIO支持等功能在下一代申威服務器處理器中的出現.
3) 基于申威處理器和先進網絡數據包處理器框架的自主可控網絡安全生態建設將大有可為DPDK等先進數據包處理框架與申威處理器的結合,使得多種以網絡數據包處理為基礎支撐的自主可控網絡安全產品,如自主可控防火墻、自主可控VPN、自主可控IDSIPS、自主可控加密機等,可以在申威處理器平臺上達到較高的性能水平,滿足對使用非自主可控處理器的安全產品實施自主可控替代的要求,從而推動自主可控安全產品在軍隊、軍工、政府重要部門的應用,進一步推進我國自主可控安全生態的建設.
[1]賈迅, 胡向東, 尹飛. 申威處理器硬件數據預取技術的實現[J]. 計算機工程與科學, 2015, 37(11)
[2]陳左寧,王廣益, 胡蘇太, 等. 大數據安全與自主可控[J]. 科學通報, 2015, 60(5/6): 427-432
[3]沈昌祥. 可信計算專題綜述[J]. 計算機安全, 2006 (6): 2-4
[4]DPDK: Data plane development kit[OL]. [2017-12-15]. http://dpdk.org/
[5]Casoni M, Grazia C A, Patriciello N. On the performance of Linux Container with Netmap/VALE for networks virtualization[C] //Proc of the 19th IEEE Int Conf on Networks (ICON). Piscataway, NJ: IEEE, 2013: 1-6
[6]Stevens W R. TCP/IP詳解(卷1)——協議[M]. 北京: 機械工業出版社, 2011
[7]Rizzo L. Netmap: A novel framework for fast packet I/O[C] //Proc of the 2012 USENIX Conf on Annual Technical Conf. Berkeley, CA: USENIX Association, 2012: 9-9
[8]Wright G R, Stevens W R, et al. TCP/IP詳解(卷2)——實現[M]. 北京: 人民郵電出版社, 2010
[9]劉軍衛. 用戶態驅動框架的研究與實現[D]. 合肥: 中國科學技術大學, 2011
[10]卡耐基梅隴大學并行實驗室[OL]. [2017-12-15]. http://www.pdl.cmu.edu/
[11]DPDK技術白皮書[M]. 廣州: 中國電信股份有限公司廣州研究院. 2015年10月
[12]Morari A, Gioiosa R, Wisniewski R W, et al. Evaluating the impact of TLB misses on future HPC systems[C] //Proc of the 26th IEEE Int Parallel and Distributed Processing Symp. Los Alamitos, CA: IEEE Computer Society, 2012: 1010-1021
[13]Koka P, Mccracken M O, Schwetman H D, et al. Combining a remote TLB lookup and a subsequent Cache miss into a single coherence operation: US, US9003163[P]. 2015-04-07
[14]蔣苑青. 多處理器系統的線程調度策略研究[D]. 成都: 電子科技大學, 2012
[15]肖月振, 華蓓, 基于多核處理器的無鎖零拷貝數據包轉發框架[J]. 計算機工程, 2013, 39(12): 35-39
[16]周偉明. 多核計算與程序設計[M]. 武漢: 華中科技大學出版社, 2009
[17]童浩, 陳興蜀, 嚴宏. 改進及優化Linux網絡協議棧[J]. 電子科技大學學報, 2007, 36(S3): 1493-1496
[18]劉寶辰. 高性能數據包捕獲系統的研究與實現[D]. 上海: 上海交通大學, 2013
[19]Rizzo L, Lettieri G, Maffione V. Speeding up packet I/O in virtual machines[C] //Proc of Architectures for Networking and Communications Systems. Piscataway, NJ: IEEE, 2013: 47-58
[20]Rizzo L, Carbone M, Catalli G. Transparent acceleration of software packet forwarding using netmap[C] //Proc of IEEE INFOCOM 2012. Piscataway, NJ: IEEE, 2012: 2471-2479
