基于卷積神經網絡的人臉識別研究
2018-02-01 00:33:00解駿陳瑋
軟件導刊 2018年1期
關鍵詞:人臉識別
解駿+陳瑋


摘要:傳統的人臉識別多采用淺層結構提取人臉特征,這類方法提取人臉圖像能力有限,效果相對較差。針對上述缺陷,提出基于卷積神經網絡的高效識別人臉方法。該方法所設計的模型,結合了VGGNet模型的層次結構優勢并融合跨層次結構的上采樣特征,大大提高了人臉識別的準確性及識別精度。該模型在Caffe下訓練出樣本集后在MATLAB上得到了驗證。
關鍵詞:人臉識別;卷積神經網絡;Ubuntu Caffe;MATLAB
DOIDOI:10.11907/rjdk.172221
中圖分類號:TP301
文獻標識碼:A文章編號文章編號:16727800(2018)001002503
Abstract:Traditional face recognition uses shallow structure to extract facial features.This method has limited ability to extract face images, and the effect is relatively poor.With the development of cognitive science and brain science, an efficient face recognition method based on convolutional neural network is proposed.The proposed model combines the hierarchical structure of VGGNet model and combines the sampled features across hierarchical structures,after the model is trained under Caffe, the result is verified on MATLAB.This method greatly improves the accuracy of face recognition and improves the recognition accuracy.
Key Words:face recognition; convolutional neural network; Ubuntu Caffe; MATLAB
0引言
卷積神經網絡是近年發展起來的一種高效識別方法。20世紀60年代,Hubel和Wiesel在研究貓腦皮層中用于局部敏感和方向選擇的神經元時,發現其獨特的網絡結構可以有效降低反饋神經網絡的復雜性,繼而提出了卷積神經網絡(Convolutional Neural Networks,簡稱CNN)。現在,CNN已成為眾多科學領域的研究熱點之一,特別是在模式分類領域,由于該網絡避免了圖像前期復雜的預處理,可直接輸入原始圖像,因而得到了廣泛的應用[1]。K.Fukushima在1980年首次提出了新識別機制,隨后很多科研工作者對該網絡進行了改進[23]。
1神經網絡
1.1淺層網絡與深層網絡
淺層網絡通常也叫做傳統的神經網絡。神經網絡來源于嘗試尋找生物系統信息處理的數字表示(McCulloch and Pitts,1943;Widrow and Hoff,1960;Rosenblatt,1962;Rumelhart et al.,1986)。這個模型被廣泛使用,許多模型過分夸張地宣稱其具有生物的可信性[4]。然而,從模式識別的應用角度來說,模仿生物的真實性會帶來相當多的限制。因此,應著重研究作為統計模式識別的高效神經網絡,即多層感知器[5]。
1.2卷積神經網絡
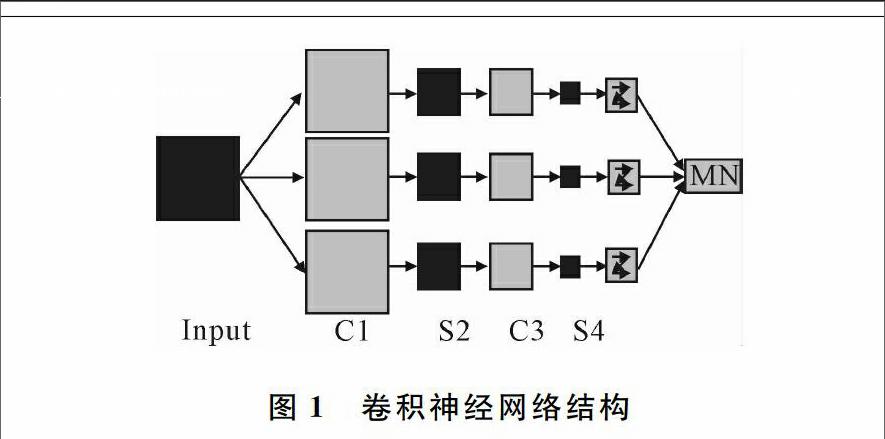
卷積神經網絡本質上是一個多層神經網絡,但不同于傳統的神經網絡,每一層上都會有許多的二維平面,并且這些二維平面都含有獨立的神經元,大致結構如圖1所示[6]。
圖1給定一副輸入圖像,C1層就是卷積神經網絡中非常特殊的卷積層。可以看到輸入圖像經過C1層得到了3張特征映射圖,這是因為在C1層上人為設定了3個不同的卷積核,每一張特征映射圖都對應于卷積核中的權重[79]。S2層是卷積神經網中常見的下采樣層,它通過一個固定窗口對特征圖像進行聚合統計,實現特征圖像分辨率的下采樣。同理,C3層獲取更抽象的特征圖,S4層繼續下采樣降低學習難度。最終網絡的最后一層或幾層設計成全連接層,目的是為了提取更少、更好的特征將其提供給分類器[1011]。
在卷積神經網絡中,圖1的C層作為特征提取層,該層上輸出的每一個神經元與上一層中的局部相連,其值就是上一層中的特征映射值。這樣的局部特征只要提取出來,它相對于其它特征的空間位置關系也會確定下來。S層是特征值下采樣層,對C層輸出的特征映射圖中的特征值進行聚合統計[78]。在卷積神經網絡中C層和S層的共同作用下,輸入圖像的特征映射結果具有位移不變性。
由于一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數,降低了網絡參數選擇的復雜度。卷積神經網絡中的每一個特征提取層(C層)都緊跟一個用來求局部平均與二次提取的計算層(S層),這種特有的兩次特征提取結構,使網絡在識別時對輸入樣本有較高的畸變容忍能力[1213]。
2深度學習框架—Caffe
Caffe支持命令行、python和MATLAB接口,核心語言是C++,它是一種操作簡單、執行效率高的深度學習框架,可在CPU和GPU之間無縫切換,其創始人是賈楊清。Caffe問世至今,由于它在使用上簡潔方便,執行上效率高效,實現上有著清晰的分層網絡定義,具有較強的可讀性、可移植性和結構化等特點,使其在深度學習領域廣受青睞。
2.1Caffe特點endprint
(1)模塊化。模塊化設計可達到對網絡層、損失函數以及數據格式進行獨立擴展。
(2)表示和實現分離。一般利用Protocol Buffer語言將Caffe的模型定義寫進配置文件,采用任意有向無環圖進行構思。Caffe支持網絡架構,可依據網絡需要自動調節程序或系統所占內存。通過調用某個函數,實現CPU和GPU的切換。
(3)測試覆蓋。在Caffe中,任意一個單一的模塊都有一個相對應的測試。
(4)Caffe同時提供Python和MATLAB接口。本實驗最后需要在Caffe提供MATLAB接口,然后在MATLAB上實現驗證結果。
(5)預訓練參考模型。對于視覺項目,Caffe有針對性地提供了一系列參考模型,這些模型僅用于非商業或學術領域,它們的License不是BSD。
2.2Caffe架構
(1)數據存儲。Caffe通過“Blobs”方式存儲數據,即利用四維數組方式存儲與傳遞數據。采用Blobs方式會有一個統一的內存接口,專門用來操作批量圖像(以及其它數據)或更新參數。而Models則以Google Protocol Buffers的方式在磁盤中存儲,若有大型數據則存儲在LevelDB數據庫中[13]。
(2)網絡層。Caffe層以一個或多個Blobs輸入,隨即計算出一個或多個Blobs輸出。網絡是一個整體的操作,而層有兩個主要職責:①前向傳播,需要輸入并產生輸出;②反向傳播,獲得梯度并將它作為輸出,再以參數和輸入計算出梯度。Caffe提供了一套完整的層類模型,這些層類模型既簡單也實用。
(3)網絡運行方式。Caffe保存全部的有向無環層圖,以保證訓練樣本準確無誤地進行前向傳播及反向傳播。Caffe作為一個終端到終端的機器學習系統,起始于數據層,終止于loss層。借助某個單一開關,使其網絡在CPU與GPU上有效運行。此外在CPU或GPU上,層于層之間結果相同。
(4)訓練網絡。Caffe在執行一個訓練時,憑借的是高效、精確的隨機梯度下降算法。在Caffe模型中,微調作為一個標準的方法,適用于已存在的模型或新的架構及數據。當執行新任務時,Caffe即微調舊的模型權重,再依據開發人員需求,將新的權重參數初始化,最終達到縮短訓練時間、提高模型精度的要求。
3實驗環境和結果分析
3.1實驗目的
本實驗在Caffe上調用改進的VGGNet網絡模型訓練樣本集,然后在MATLAB上輸入一個樣本照片,通過MatCaffe接口在MATLAB上調用Caffe訓練好的樣本集,從而識別輸入樣本對應樣本集中的哪個人、相似度多少。
圖2為VGGNet網絡結構模型,在fc1和fc2后加入了dropout算法,通過一定的概率屏蔽部分神經元,從而防止隨著網絡深度的增加出現過擬合問題。同時通過修改每個神經元的非線性激活函數,為relu加快網絡的訓練時間。通過加入改進后的算法得到了更好的訓練曲線,減少了大量的訓練時間。
3.2實驗環境及數據
本文在Ubuntu64位系統下調用Caffe框架和MATLAB實驗,樣本圖片基于AR人臉庫數據,加上實際人臉采樣數據,通過MATLAB把所有圖片轉換成大小為224×224的jpg格式文件,部分如圖3所示。
3.3結果分析
在Caffe框架上通過改進的VGGNet模型,將訓練樣本完成為二進制文件存儲,如圖4所示,從左到右依次為訓練迭代第40次和訓練完成輸出結果的二進制文件以及文件內容。
在MATLAB上調用訓練好的模型輸入圖片,識別對應的模型里訓練好的人名,并給出相似度,如圖5所示。
基于卷積神經網絡的訓練準確率大大高于傳統人臉識別算法,而且受光照等外部條件影響較小,本文提出的改進的VGGNet網絡訓練出來的結果效率高達98%以上,而且訓練速度也較快。
4結語
本文基于深度學習的基礎框架(卷積神經網絡),對當前機器視覺在目標識別上出現的問題進行了研究。根據自然場景復雜多變的情況,設計了一個適合于這種高度變化的數據集上的一種深度卷積神經網絡架構,并利用其監督學習的特點完成了模型的訓練過程。
本文的網絡結構還有許多可以改進和優化的地方。隨著21世紀人工智能在機器視覺上的發展,深度學習將在目標識別的技術層面得到跨越,會出現更多的機器視覺產品。
參考文獻:
[1]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Science,2014(2):580587.
[2]HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2015,37(9):19041916.
[3]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for largescale image recognition[J]. Computer Science,2014(5):241256.
[4]SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2014,79(10):13371342.endprint
[5]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, realtime object detection[J]. Computer Science,2016(3):422430.
[6]LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[EB/OL]. http://www.cnblogs.com/zhangyd/p/6596913.html,2015.
[7]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems,2012,25(2):2029.
[8]REN S, HE K, GIRSHICK R, et al. Faster RCNN: towards realtime object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2016(6):110.
[9]UIJLINGS J R R, SANDE K E A V D. Selective search for object recognition[J]. International Journal of Computer Vision,2013,104(2):154171.
[10]CARREIRA J, RUI C, BATISTA J, et al. Semantic segmentation with secondorder pooling[J]. Lecture Notes in Computer Science,2012,7578(1):430443.
[11]DAN C C, GIUSTI A, GAMBARDELLA L M, et al. Deep neural networks segment neuronal membranes in electron microscopy Images[J]. Advances in Neural Information Processing Systems,2012(25):28522860.
[12]DAI J, HE K, SUN J. Convolutional feature masking for joint object and stuff segmentation[EB/OL]. http://www.taodocs.com/p41599543.html,2014.
[13]盧宏濤,張秦川.深度卷積神經網絡在計算機視覺中的應用研究綜述[J].數據采集與處理,2016,31(1):117.
(責任編輯:杜能鋼)endprint
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
