基于高性能計算平臺的TensorFlow應用探索與實踐
2018-01-29 07:46:36王一超韋建文
實驗室研究與探索 2017年12期
王一超, 韋建文
(上海交通大學 網絡信息中心, 上海 200240)
0 引 言
深度學習作為近年來興起的一種機器學習方法[1],可大幅提升包括圖像識別在內的諸多模式識別問題的準確率。同時,該方法經由GPU大規模并行計算的助推,已經大幅縮短了其模型的訓練時間,成為了學術與工業界炙手可熱的機器學習方法[2-3]。當前,利用深度學習提升圖像和語音識別精度的軟件產品層出不窮,并且已大量應用于安防、人機交互、語音輸入法等實際場景。在科研領域,越來越多的科學家也意識到了可以嘗試利用深度學習替代傳統的機器學習方法[4],提高模式識別或分類問題的精度[5]。在這一大背景下,為支撐校內高水平科研用戶的需要,在校高性能計算平臺上結合高性能計算軟件棧的特點,部署了多款支持深度學習的軟件框架,包括CNTK、MXnet、TensorFlow等。同時,在目前的交大超算平臺上,利用TensorFlow框架下的圖像識別模型訓練,與最新的NVIDIA Minsky高性能工作站進行了性能對比測試,以驗證平臺對于深度學習應用的支持效果。
1 高性能計算平臺
為應對校內各院系用戶對計算需求的大幅增加,上海交通大學于2012年初成立校級高性能計算中心,掛靠校網絡信息中心,為全校提供高性能計算的公共服務。該校級高性能計算平臺于2013年建成并上線服務超算集群π,2013年6月世界排名158,國內高校第一,上海地區第一[6]。
1.1 硬件環境
π集群采用異構計算設計,計算資源由Intel至強多核處理器和NVIDIA GPU加速卡組成,經過2輪升級之后,目前整機的理論計算峰值性能為343TFlops,聚合存儲能力達4PB,為國內高校領先的大規模GPU異構計算集群,具體硬件配置如表1所示。
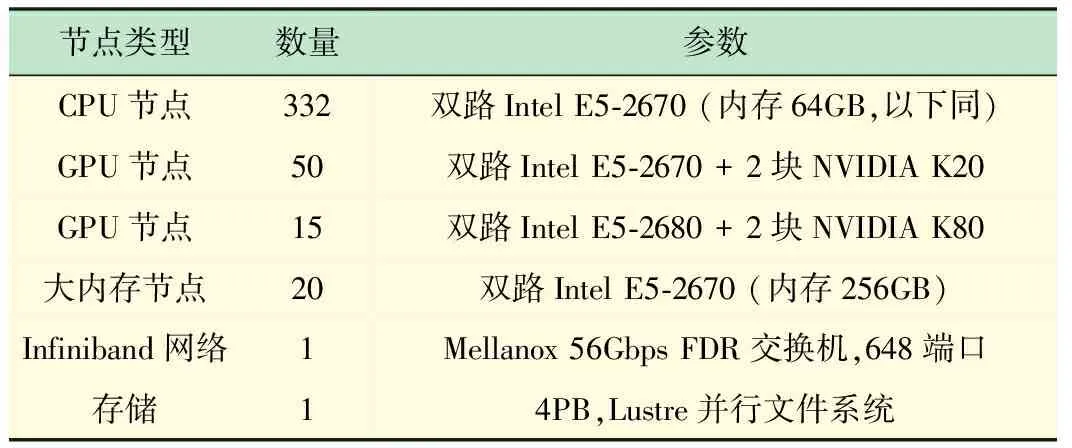
表1 π集群硬件配置
2016年發布的NVIDIA Pascal架構是目前最先進的GPU加速卡架構,相較于2013年建設集群時所采用的Kepler架構,不僅提升了浮點數運算能力和內存訪問帶寬,更支持了適應目前深度學習應用特點的半精度浮點數計算(即FP16)[7]。NVIDIA P100加速卡的半精度浮點數運算性能約為K80的單精度浮點數運算性能的逾3倍,由于深度學習對于精度要求較低,半精度即可勝任,所以現已在集群的GPU節點上部署測試P100加速卡。
1.2 軟件環境
π集群利用module管理面向用戶的全局軟件環境,我們在集群上安裝了諸多常用的開源軟件及完整的編譯環境,面向所有用戶開放使用。用戶僅需在自己賬號下加載相關軟件或者工具庫,即module load指令,便可使用所需要的軟件。這種配置方案節省了用戶對于軟件及編譯環境的部署學習時間,同時我們對于全局軟件環境的定期升級與維護,也保障了用戶始終能在優化后的軟件環境下運行計算作業,從而提升作業運行效率。
TensorFlow是由Google公司開發的一款支持不同深度學習應用的軟件框架,在這款基于Python的軟件框架上可以通過調用不同的程序接口,構建深度學習訓練所需的流圖,進行深度學習訓練。目前人工智能領域最著名的案例,圍棋軟件AlphaGo正是基于該框架開發的[8]。TensorFlow今年剛剛推出了其1.0版本,目前更新速度較快,故本文中采用基于源代碼的安裝部署方式,目的是在于能使用最新的軟件版本。以下將簡述一下在π集群上部署TensorFlow的實踐方法。
首先,用戶需要加載正確的全局軟件環境,包括完整的編譯工具和GPU所需的CUDA并行庫環境。
$ module purge
$ module load gcc/5.4 python/3.5 bazel cuda/8.0 cudnn/6.0
virtualenv是一款創建隔絕的Python環境的軟件工具,它通過創建一個包含所有必要的可執行文件的文件夾,來解決依賴、版本以及間接權限問題。用戶被允許在其HOME目錄下創建一個Python的虛擬環境,然后使用pip管理所需軟件包。
$ python3 virtualenv.py ~/python35-gcc
$ source ~/python35-gcc54/bin/activate
$ pip3 install numpy
用戶通過git將TensorFlow源代碼下載至其HOME目錄下,并更新至最新版本,進行下一步編譯和安裝
$ git clone https://github.com/tensorflow/tensorflow
$ cd tensorflow; git checkout r1.0
利用bazel編譯工具開啟編譯環境設置,在選項中,用戶需要選擇使用GPU,并指明CUDA和cuDNN的安裝路徑。
$ bazel build--config=opt--config=cuda //tensorflow/tools/pip_package:build_pip_package
用戶最終將基于以上操作編譯而成的基于pip的TensorFlow安裝包安裝到用戶本地的python目錄下。打開Python后,即可正常使用TensorFlow。
2 深度學習應用
深度學習中的卷積神經網絡是由一個或多個卷積層和頂端的全連通層組成,同時也包括關聯權重和池化層[9]。這種網絡數學上就是許多卷積運算和矩陣運算的組合,而卷積運算通過一定的數學手段也可以通過矩陣運算完成。這些操作和GPU本來能做的那些圖形點的矩陣運算是一樣的。因此深度學習就可以非常恰當地用GPU進行加速了。
目前,交大高性能計算平臺上的深度學習計算需求主要來自于語音識別和圖像處理,計算機系和醫學圖像處理的團隊對于在集群上利用GPU跑深度學習作業。當前他們的應用占了GPU應用的11%,僅次于傳統科學計算領域的軟件Amber,與GPU版本的Gromacs和Lammps相當(見圖1)。
目前在π集群上使用最多的開源深度學習框架是Google公司開發的TensorFlow。TensorFlow是一個使用數據流圖進行數值計算的開源軟件庫。數據流圖中的節點表示數學運算, 數據流圖中的邊表示節點之間互聯的多維數據數組[11]。而目前在圖像識別領域使用最多的訓練模型Inception,即如圖2示例,是一個13層的網絡模型。本文基于以上現狀,在π集群上基于TensorFlow框架針對Inception模型進行測試實驗[12],用以驗證目前高性能計算集群對于深度學習應用的支持情況。
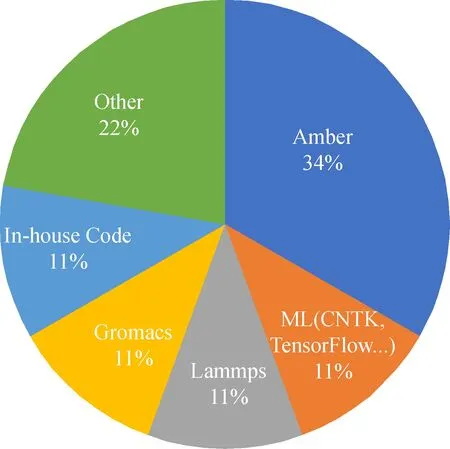
圖1 π集群GPU應用利用率占比[10]
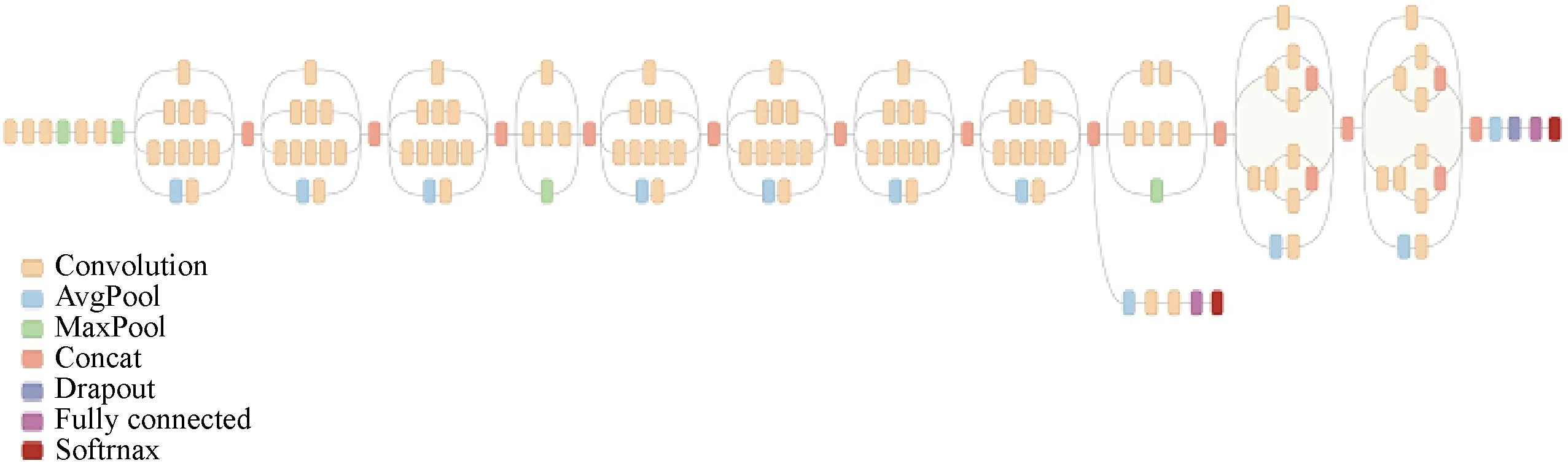
圖2 TensorFlow框架下Inception模型的數據流圖
3 性能分析
為分析深度學習應用在π集群上的實際性能,本文針對基于TensorFlow架構的Inception-V3模型進行訓練性能的測試,圖像測試集采用大規模數據集ImageNet,該數據集大小約1.5 TB,由逾22 000個種類和超過1 500萬張圖片組成。目前,國際上公認最具權威性的ImageNet國際計算機視覺挑戰賽(ILSVRC)正是基于該數據集進行圖像識別準確率的比拼的[13]。由于數據集體量較大,我們將ImageNet數據集下載并保存至π集群的并行文件系統上,以方便跨界點及多用戶的共同訪問。
3.1 測試環境
為了能和目前主流的深度學習專用工作站進行性能對比,本次實驗不僅只在π集群的GPU測試節點(搭載了NVIDIA P100加速卡[14])上進行,我們還在同樣搭載了NVIDIA P100加速卡且支持NVLink高速互聯技術的IBM Minsky測試機上做了同樣的訓練測試。
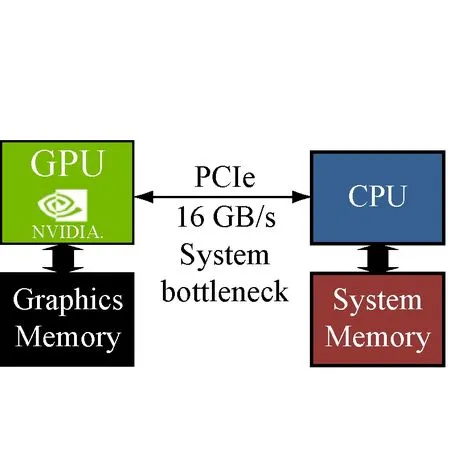
如圖3所示,NVLink高速互聯技術相較于異構計算中常用的PCIe互聯,訪存帶寬可以取得5倍的提升,從而緩解由主存與GPU顯存之間傳輸效率低造成的性能瓶頸。具體的測試平臺軟硬件環境配置如表2所示。
3.2 性能結果對比
本文使用了ImageNet數據集訓練Inception-V3圖像識別模型,依次進行了1~4塊GPU卡的訓練測試,為保證負載的平均,batch值也相應做了調整,實驗輸入如表3所示。
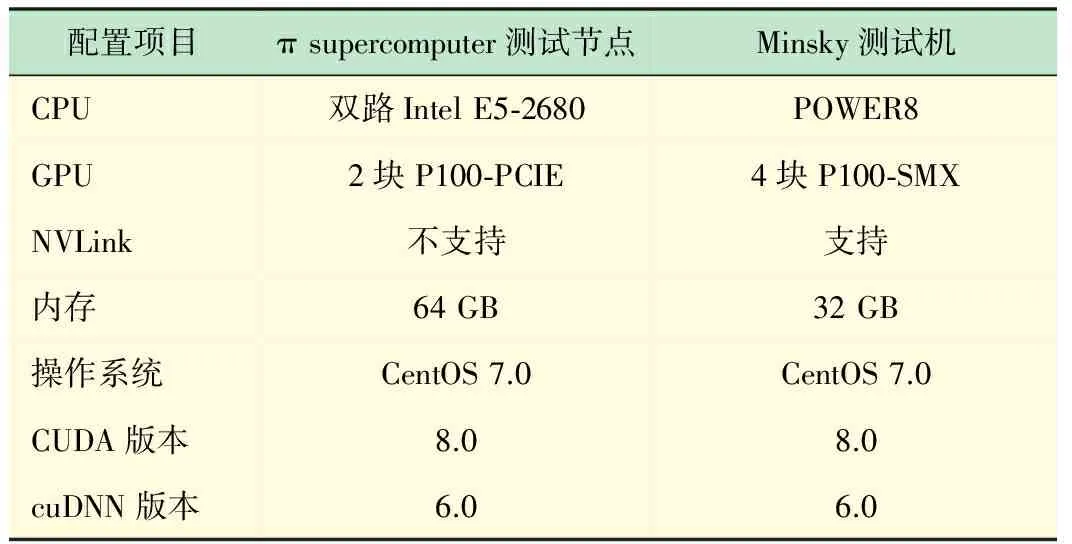
配置項目πsupercomputer測試節點Minsky測試機CPU雙路IntelE5?2680POWER8GPU2塊P100?PCIE4塊P100?SMXNVLink不支持支持內存64GB32GB操作系統CentOS7.0CentOS7.0CUDA版本8.08.0cuDNN版本6.06.0
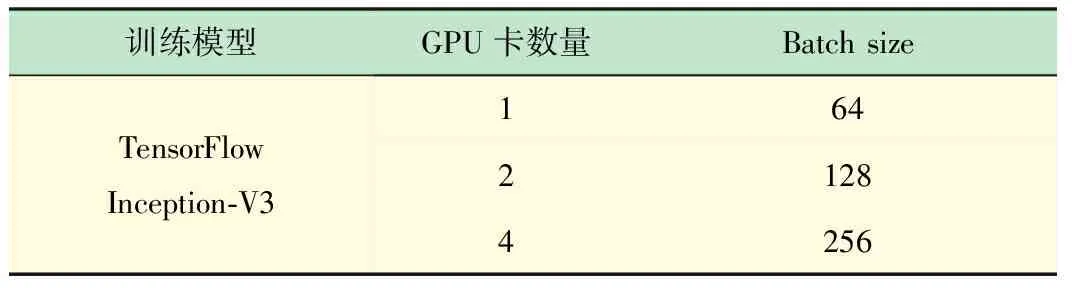
表3 深度學習應用測試輸入
實驗結果如圖4所示,Minsky測試機相對于目前π集群的GPU單節點的1和2卡的性能非常接近,性能差在12%以內。而由于目前集群環境下的TensorFlow尚不支持分布式GPU節點并行,故無法在此情況下做相應對比測試,圖4中展示了Minsky在4卡運行時的性能,相對之前的結果而言,呈線性增長。
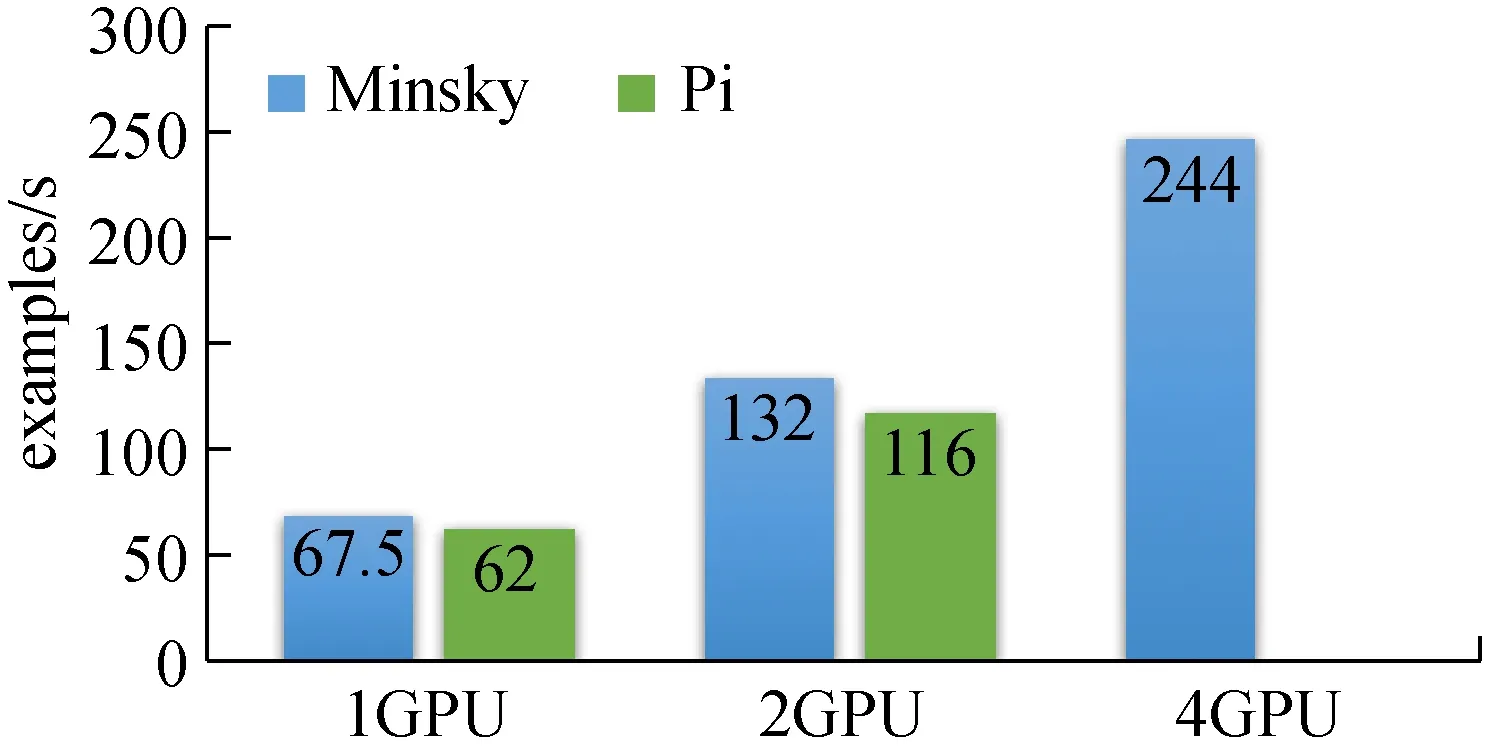
圖4 利用TensorFlow在Minsky和π集群上訓練Inception-V3模型的性能對比
造成π集群節點與Minsky測試機上性能差異的原因主要有2點:①Minsky上配備的NVLink高速互聯技術,提供了5倍于π測試節點上基于PCIe技術的傳輸帶寬。從而使得數據在從主存傳輸至GPU設備內存的時間明顯降低了,在1和2卡的實驗中提升了性能;②Minsky測試機集成了4塊P100-SMX GPU卡,該款加速卡相較于采用同樣硬件架構的P100-PCIE版本,其核心的主頻更高,因此計算能力有約16%的提升[15]。
綜上所示,在2013年建成的π超算上成功部署了TensorFlow深度學習框架,在將GPU節點上的GPU加速卡從原有的NVIDIA Kepler架構升級至最新的Pascal架構后。在實驗中,對比了其與2016年發布的Minsky測試機上Inception-V3模型的訓練性能,實驗結果顯示性能差異在12%以內。由此可見,當前的集群硬件條件可以支持深度學習應用在單節點上的運行,但在未來的建設中,仍有待進一步考察高密度GPU節點對提升深度學習應用性能的幫助。
4 結 語
在這一輪新的人工智能大潮中,人們利用深度學習方法大踏步提升人工智能應用預期的同時,也越來越認識到計算性能對于未來人工智能能發展的重要性。日本政府近期也提出了發展面向人工智能的超級計算機戰略。在高校一級的高性能計算平臺上,人工智能的研究需求也理應得到滿足,這就需要在已有的集群上更新軟硬件環境,幫助用戶更快地成功運行相關計算應用。本文分享了交大在高性能計算平臺上配置部署深度學習軟件框架,并實踐對比了其與目前最先進的GPU工作站的性能,證明了校級高性能計算平臺可以支撐深度學習用戶的計算需求,但在分布式深度學習上的性能還有待評估。因為與傳統的科學計算不同,深度學習應用由于極高的運算強度,對于多卡情況下的數據傳輸性能要求更高,故在工業界普遍采用單機多卡的高密度GPU節點方案[16],以提高其性能。在這一方面,在建設新一階段的超算集群時,也可以對類似的高密度節點性能進行調研,以評估其實際應用價值。
[1] 李 航. 統計學習方法[M].北京:清華大學出版社,2012.
[2] 余 凱, 賈 磊, 陳雨強, 等, 深度學習的昨天、今天和明天[J]. 計算機研究與發展, 2013, 50(9): 1799-1804.
[3] 張建明,詹智財,成科揚,等.深度學習的研究與發展[J]. 江蘇大學學報:自然科學版, 2015,36(2): 191-200.
[4] LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[5] 張煥龍, 胡士強, 楊國勝, 基于外觀模型學習的視頻目標跟蹤方法綜述[J]. 計算機研究與發展, 2015, 52(1): 177-190.
[6] 林新華, 顧一眾, 上海交通大學高性能計算建設的理念與實踐[J]. 華東師范大學學報(自然科學版),2015(S1): 298-303.
[7] GP100 Pascal Whitepaper [EB/OL]. https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdf
[8] Silver D, Huang A, Maddison C J,etal. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587):484-489.
[9] 周志華.機器學習[M].北京:清華大學出版社,2016.
[10] 上海交通大學高性能計算中心年度報告2016[EB/OL]. http://hpc.sjtu.edu.cn/report2016_170607.pdf.
[11] 黃文堅, 唐 源.TensorFlow實戰[M].北京:電子工業出版社,2017.
[12] Installing TensorFlow from Sources [EB/OL]. https://www.tensorflow.org/install/install_sources.
[13] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[14] Deep Learning Performance with P100 GPUs[EB/OL]. http://en.community.dell.com/techcenter/high-performance-computing/b/general_hpc/archive/2016/11/11/deep-learning-performance-with-p100-gpus.
[15] Inside Pascal: NVIDIA’s Newest Computing Platform [EB/OL]. https://devblogs.nvidia.com/parallelforall/inside-pascal/.
[16] 顧乃杰, 趙 增, 呂亞飛,等, 基于多GPU的深度神經網絡訓練算法[J]. 小型微型計算機系統,2015(5): 1042-1046.
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
新聞傳播(2015年10期)2015-07-18 11:05:40
創業家(2015年10期)2015-02-27 07:55:08
