面向國產(chǎn)異構(gòu)系統(tǒng)的HPL異構(gòu)協(xié)同設(shè)計*
2018-01-26 02:46:06甘新標(biāo)孫燎原雄成偉黃嘉昆
計算機(jī)工程與科學(xué) 2018年1期
關(guān)鍵詞:系統(tǒng)
甘新標(biāo),孫燎原,劉 杰,雄成偉,黃嘉昆
(1.國防科技大學(xué)計算機(jī)學(xué)院,湖南 長沙 410073;2.計算機(jī)軟件新技術(shù)國家重點實驗室(南京大學(xué)),江蘇 南京 210093;3.國防科技大學(xué)量子信息研究所兼高性能計算國家重點實驗室,湖南 長沙 410073)
1 引言
高性能計算是衡量國家科技能力的重要標(biāo)志,已廣泛應(yīng)用于大規(guī)模數(shù)值計算、武器裝備模擬仿真等領(lǐng)域。為了制衡和封鎖中國巨型機(jī)技術(shù)發(fā)展,美國商務(wù)部2015年2月18日發(fā)布芯片限售令,我國國家超級計算長沙中心、國家超級計算廣州中心、國家超級計算天津中心和國防科技大學(xué)4家機(jī)構(gòu)被列入美國芯片限售對象。幸運(yùn)的是,中國高性能處理器發(fā)展技術(shù)早有預(yù)案,國產(chǎn)加速器(China Accelerator)就是國防科技大學(xué)計算機(jī)學(xué)院自主研發(fā)的高性能加速器[1]。China Accelerator的軟件生態(tài)不同于GPU、MIC等比較成熟的加速器,其體系結(jié)構(gòu)和編程模型更是有別于傳統(tǒng)的CPU體系結(jié)構(gòu)和編程模式,開發(fā)高效的應(yīng)用程序?qū)⒚媾R體系結(jié)構(gòu)復(fù)雜、細(xì)節(jié)多,并行編程要求高、難度大,數(shù)據(jù)流動管理與分派繁瑣復(fù)雜,優(yōu)化困難等諸多挑戰(zhàn)。因此,面向國產(chǎn)異構(gòu)系統(tǒng)的HPL(High Performance Linpack)異構(gòu)協(xié)同設(shè)計可以為China Accelerator廣泛應(yīng)用于核爆模擬、天氣預(yù)報、地質(zhì)資源勘查等領(lǐng)域提供技術(shù)參考,加速China Accelerator的推廣應(yīng)用。
線性系統(tǒng)軟件包Linpack(Linear system package) 通過使用高斯消元法求解稠密一元N次線性代數(shù)方程組來評估高性能計算機(jī)的實際浮點性能,Linpack根據(jù)問題規(guī)模與優(yōu)化選擇的不同分為Linpack100、Linpack1000 以及HPL[2]。HPL采用高斯消元法求解N元一次稠密線性代數(shù)方程組來評估高性能計算機(jī)的浮點性能。高斯消元法首先將系數(shù)矩陣A通過分塊遞歸的LU分解,將其分解為一個下三角陣L與一個上三角陣U的乘積,然后將線性代數(shù)方程組Ax=b演算成Ux=L-1b形式,最后,通過上三角方程回代求得線性方程組的解[3 - 5]。HPL由于規(guī)模可變,成為目前最流行的用于測試高性能計算機(jī)浮點性能的測試基準(zhǔn)。當(dāng)HPL求解問題規(guī)模為N時,浮點計算次數(shù)為(2/3)N3+(3/2)N2,計算時間為T,HPL測試浮點性能值為(2/3)N3+(3/2)N2)/T,浮點計算性能測試結(jié)果是高性能機(jī)Top500排名的重要依據(jù)。
由于支持China Accelerator的底層矩陣乘接口目前僅支持定制接口,為了提供一個通用的HPL測試環(huán)境,需要完成矩陣循環(huán)分布細(xì)致劃分與封裝dPEM(delicate Partition and Encapsulation on Matrix)。同時,為了充分發(fā)揮國產(chǎn)異構(gòu)系統(tǒng)的效率,設(shè)計了異構(gòu)協(xié)同矩陣乘調(diào)度算法OA4MM(Orchestrating Algorithm for Matrix Multiplication)。
2 面向CPU+China Accelerator的HPL設(shè)計
傳統(tǒng)HPL算法中,求解N×N矩陣將以塊為單位循環(huán)分布到所有CPU,由于矩陣采用了塊循環(huán)分布,在N較大時,各個處理器的計算量基本相當(dāng),對于同構(gòu)系統(tǒng),傳統(tǒng)的HPL一般可以獲得較高的系統(tǒng)性能。由于計算速度的差異,如果給異構(gòu)系統(tǒng)中每個處理器分配相同的計算量,那么計算速度快的加速器在完成計算后必須等待計算速度較慢的CPU進(jìn)行通信,必然降低異構(gòu)系統(tǒng)效率。因此,為了充分發(fā)揮異構(gòu)系統(tǒng)的效率,必須基于異構(gòu)系統(tǒng)結(jié)構(gòu)設(shè)計高效協(xié)同的HPL算法。由于矩陣乘更新操作占據(jù)了HPL求解絕大部分計算時間,因此高效協(xié)同的HPL算法設(shè)計將滿足CPU端矩陣乘更新計算時間TCPU與China Accelerator端矩陣乘更新計算時間TChina Accelerator在相同時間點完成各自的計算,避免不必要的通信等待。即:
其中,M、N、K分別為矩陣A(M,K)、B(K,N)、C(M,N)的緯度。
2.1 支持China Accelerator的矩陣乘定制接口封裝
China Accelerator由6個DSP超節(jié)點、1個CPU節(jié)點、1個IO節(jié)點、全局Cache、核間同步、4個存儲控制器MCU(Memory Control Unit)及IO設(shè)備構(gòu)成。其中,每個DSP超節(jié)點包含兩個飛騰―Matrix2000內(nèi)核,每個飛騰―Matrix2000內(nèi)核包含兩個計算核心,每個計算核心包含16個向量計算功能單元;全局Cache GC(Global Cache)采用分布式Cache,由多個子體(SubGC)構(gòu)成,每兩個SubGC連接一個存儲控制單元MCU;核間同步也采用分布式組織,由多個子體構(gòu)成。上述節(jié)點、SubGC、MCU由環(huán)形互連連接。 因此,China Accelerator是一款面向計算密集型應(yīng)用、能高效處理大量數(shù)據(jù)的高性能多向量體系結(jié)構(gòu)加速器,如圖1所示[1]。

Figure 1 China Accelerator體系結(jié)構(gòu)圖1 Architecture of China Accelerator
如圖1所示,China Accelerator體系結(jié)構(gòu)復(fù)雜、細(xì)節(jié)多,數(shù)據(jù)分派繁瑣。為了最大化國產(chǎn)加速器計算資源利用率和提高處理器的性能,支持China Accelerator的底層矩陣乘接口目前僅支持定制接口,即,支持國產(chǎn)加速器China Accelerator的矩陣乘接口僅支持特定規(guī)模的矩陣乘A(FT_m,K)×B(K,N),F(xiàn)T_m是FT-Matrix支持的矩陣乘中第一矩陣的行數(shù),K是FT-Matrix支持的矩陣乘中第一矩陣的列數(shù),也是第二矩陣的行數(shù),N是FT-Matrix支持的矩陣乘中第二矩陣的列數(shù),A(FT_m,K)×B(K,N)中對N、K沒有特殊限制,但是,F(xiàn)T_m只能是576的整數(shù)倍,并且必須大于或等于576×6。然而,支持通用CPU的基本線性代數(shù)庫矩陣乘接口是能支持任意規(guī)模的矩陣乘A(L,K)×B(K,N),即A(L,K)×B(K,N)中的L、K、N為任意的正整數(shù)。
因此,傳統(tǒng)的HPL矩陣乘調(diào)度方法不再適合于面向China Accelerator的HPL矩陣乘調(diào)度優(yōu)化,國產(chǎn)China Accelerator迫切需要一種適用于定制接口的異構(gòu)矩陣乘調(diào)度優(yōu)化方法,將國產(chǎn)加速器僅支持定制接口的異構(gòu)矩陣乘封裝為類似CPU支持的通用矩陣乘,并且,最大化矩陣塊循環(huán)分布計算效率,提升國產(chǎn)異構(gòu)系統(tǒng)效率。CPU + China Accelerator異構(gòu)系統(tǒng)的高效協(xié)同矩陣乘計算更新劃分如圖2所示。
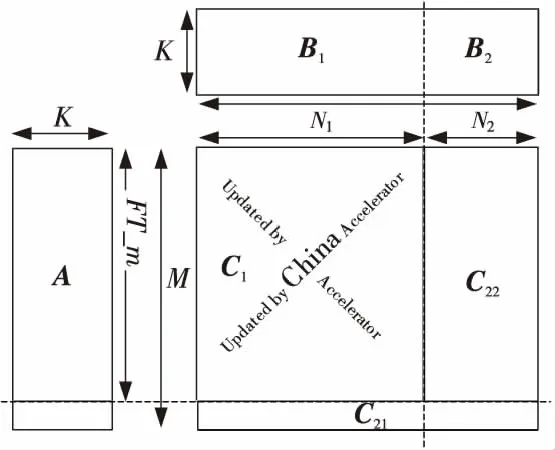
Figure 2 Matrix multiplication between CPU and China Accelerator with coordination圖2 協(xié)同矩陣乘更新
如圖2所示,由于China Accelerator目前支持的矩陣乘接口為定制接口,高效協(xié)同的矩陣乘更新算法中,CPU不僅要負(fù)責(zé)邊緣非規(guī)則的矩陣乘計算,還必須與China Accelerator協(xié)同完成規(guī)則的矩陣乘更新操作。
2.2 異構(gòu)協(xié)同矩陣乘調(diào)度算法
面向異構(gòu)系統(tǒng)的矩陣乘調(diào)度可分為靜態(tài)劃分調(diào)度SdS(Static dispatch Strategy)和動態(tài)調(diào)度dSd(dynamic Schedule dispatch)。面向CPU+GPU的天河1A異構(gòu)系統(tǒng)中,矩陣乘調(diào)度以靜態(tài)調(diào)度為主,即,探索最優(yōu)GPU端矩陣乘劃分比例,如公式(2)所示。
其中,Gaccelerator為加速器GPU端矩陣乘更新時間,GCPU為CPU端矩陣乘更新時間。
在天河1A異構(gòu)系統(tǒng)中,GPU端負(fù)責(zé)計算更新的矩陣子塊大小預(yù)先已經(jīng)確定[6,7],通過將CPU與GPU之間的數(shù)據(jù)傳輸時間隱藏于計算過程中來優(yōu)化提升異構(gòu)系統(tǒng)效率;與天河1A異構(gòu)系統(tǒng)不同,面向CPU+MIC的天河二號異構(gòu)系統(tǒng)中,矩陣乘調(diào)度算法以基于隊列緩沖的動態(tài)調(diào)度為主[8,9],即,當(dāng)前矩陣乘更新操作是分派至CPU還是MIC取決于任務(wù)計算隊列的狀態(tài),以最大限度實現(xiàn)異構(gòu)系統(tǒng)均衡,提高異構(gòu)系統(tǒng)效率。
面向CPU+China Accelerator的HPL異構(gòu)設(shè)計中,若采用類似天河1A的靜態(tài)劃分策略SdS,由于面向China Accelerator的底層數(shù)學(xué)庫矩陣乘接口限制,只有滿足接口規(guī)范要求的矩陣乘計算才能夠調(diào)度到China Accelerator上加速,大部分的矩陣乘計算只能在CPU端完成更新操作;若采用基于隊列緩沖的天河二號異構(gòu)系統(tǒng)HPL矩陣乘更新動態(tài)調(diào)度方法dSd,將產(chǎn)生冗余的隊列狀態(tài)查詢和計算任務(wù)請求等待。這是因為部分矩陣乘接口明顯不符合China Accelerator內(nèi)置的定制接口,但是,仍然需要監(jiān)控隊列狀態(tài)并試圖發(fā)送計算任務(wù)請求。
不同于天河1A異構(gòu)系統(tǒng)中矩陣乘調(diào)度靜態(tài)劃分策略和天河二號異構(gòu)系統(tǒng)中基于隊列緩沖的矩陣乘更新動態(tài)調(diào)度方法,基于China Accelerator體系結(jié)構(gòu)和軟件生態(tài),設(shè)計了一種異構(gòu)協(xié)同矩陣乘調(diào)度算法OA4MM,以提高國產(chǎn)異構(gòu)系統(tǒng)的效率。OA4MM調(diào)度方法屬于一種基于天河1A和天河二號的動靜融合協(xié)同矩陣乘均衡調(diào)度算法,OA4MM在矩陣乘靜態(tài)劃分的基礎(chǔ)上引入動態(tài)調(diào)度策略,最小化動態(tài)調(diào)度中冗余的隊列狀態(tài)查詢和計算任務(wù)請求等待,同時,最大限度劃分矩陣乘更新調(diào)度至China Accelerator端加速,算法流程如圖3所示。

Figure 3 OA4MM調(diào)度算法流程圖3 Flow chart of OA4MM
3 實驗結(jié)果與分析
3.1 CPU+China Accelerator驗證系統(tǒng)
針對CPU+China Accelerator驗證系統(tǒng)結(jié)構(gòu),系統(tǒng)設(shè)計的基于China Accelerator的計算刀片,靈活支持增添基于China Accelerator的加速子板,滿足計算刀片能靈活可配、按需構(gòu)建的用戶需求。加速子板(包含4個China Accelerator)通過PCIE與計算刀片相連,并通過計算刀片上的高速網(wǎng)卡NIO(Network Input and Output)接入高速互連網(wǎng)絡(luò),實現(xiàn)計算結(jié)點間的互連。
CPU+China Accelerator驗證系統(tǒng)由16個計算結(jié)點組成,如圖4所示。單結(jié)點主要配置如表1所示。
3.2 矩陣分塊對性能影響
由于China Accelerator目前僅支持特定規(guī)模的矩陣乘A(FT_m,K)×B(K,N),國產(chǎn)加速器底層支持的矩陣乘接口規(guī)范中對N、K沒有特殊限制,但是,F(xiàn)T_m只能是576的整數(shù)倍,并且必須大于或等于576×6,為了充分利用China Accelerator強(qiáng)大的計算資源,調(diào)度至國產(chǎn)加速器上進(jìn)行加速計算的矩陣塊大小必然影響國產(chǎn)加速器的計算資源利用率和PCIE帶寬的占有率,因此,矩陣分塊大小將嚴(yán)重影響面向CPU+China Accelerator異構(gòu)系統(tǒng)的HPL性能,其詳細(xì)測試結(jié)果如圖5所示。
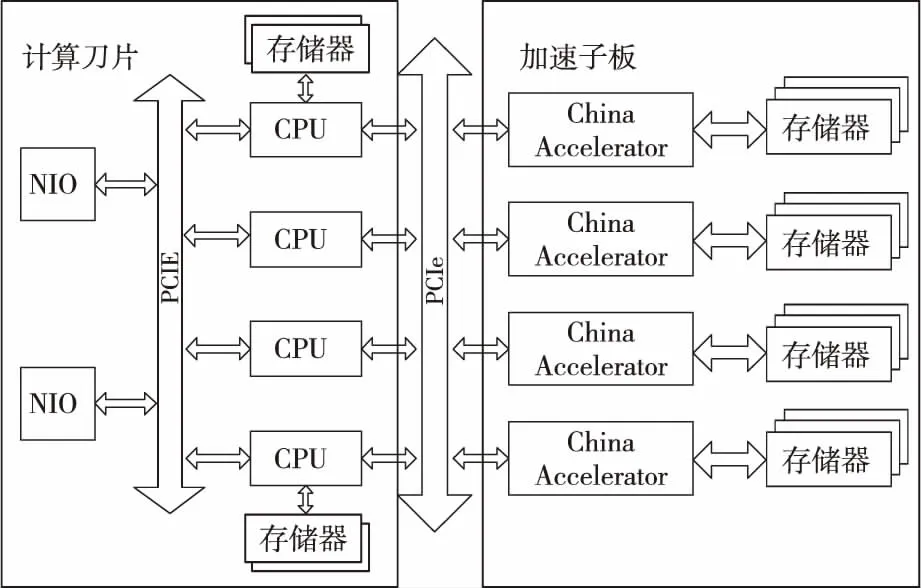
Figure 4 Architecture of node in experimental systems equipped with CPU and China Accelerator圖4 CPU+China Accelerator單結(jié)點驗證系統(tǒng)
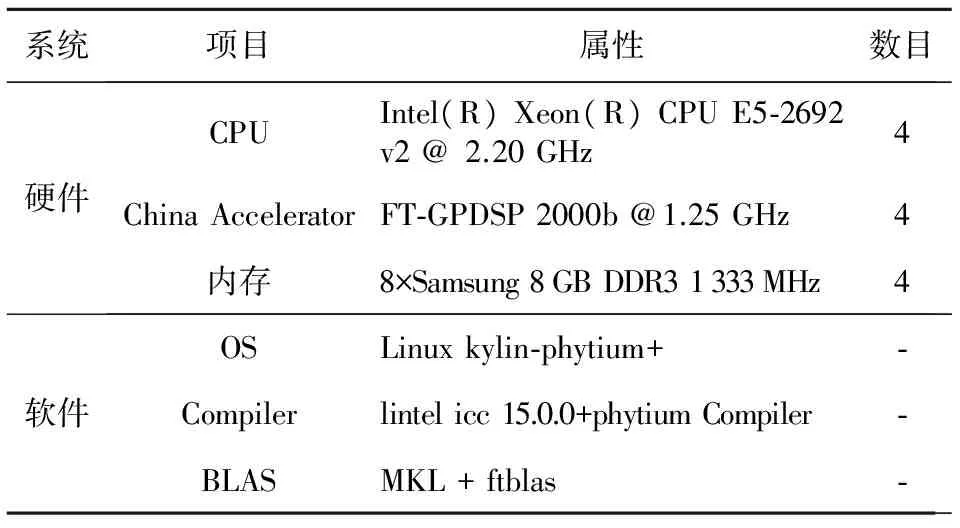
系統(tǒng)項目屬性數(shù)目硬件CPUIntel(R)Xeon(R)CPUE5?2692v2@2.20GHz4ChinaAcceleratorFT?GPDSP2000b@1.25GHz4內(nèi)存8×Samsung8GBDDR31333MHz4軟件OSLinuxkylin?phytium+?Compilerlintelicc15.0.0+phytiumCompiler?BLASMKL+ftblas?

Figure 5 Performance evaluation on matrix block圖5 矩陣分塊的性能影響
以576×6的程序性能為基準(zhǔn),不同矩陣分塊大小的加速比如圖5所示。隨著矩陣分塊逐漸增大,程序性能顯著上升至拐點后開始平穩(wěn)回落,這是因為當(dāng)矩陣分塊較小時,頻繁的數(shù)據(jù)傳輸嚴(yán)重影響程序性能,當(dāng)程序性能達(dá)到局部最高點后,加速器端的存儲資源就成為制約程序性能的關(guān)鍵。
3.3 OA4MM算法驗證
為了充分驗證OA4MM算法的高效性,面向CPU+China Accelerator的HPL設(shè)計配置了類似天河1A的靜態(tài)劃分策略SdS、基于隊列緩沖的天河二號的動態(tài)調(diào)度方法dSd以及高效協(xié)同矩陣乘調(diào)度算法OA4MM,以探索CPU+China Accelerator異構(gòu)系統(tǒng)的效率,上述三種異構(gòu)調(diào)度方法的實測性能比較如圖6所示,其中OA4MM的算法性能是在FT_m=576×30 時,即,最佳矩陣分塊情況下的測試性能。

Figure 6 Performance evaluation with OA4MM and SdS/dSd圖6 OA4MM與SdS/dSd的性能評估
由圖6可知,高效協(xié)同矩陣乘調(diào)度算法OA4MM較天河1A異構(gòu)系統(tǒng)中的靜態(tài)劃分策略SdS性能提升幅度隨著計算結(jié)點數(shù)目和矩陣規(guī)模的增加逐漸明顯;同時,在CPU+China Accelerator異構(gòu)系統(tǒng)中,隨著計算結(jié)點數(shù)目和矩陣規(guī)模的增加,OA4MM性能較天河1A的靜態(tài)劃分策略SdS和天河二號的動態(tài)調(diào)度方法dSd均有明顯提升,全系統(tǒng)HPL性能提升近10%。
4 結(jié)束語
鑒于HPL參數(shù)配置優(yōu)化實驗在諸多文獻(xiàn)中已有詳細(xì)研究,面向國產(chǎn)異構(gòu)系統(tǒng)的HPL異構(gòu)協(xié)同設(shè)計將遵循China Accelerator矩陣乘接口規(guī)范,提出了dPEM方法對China Accelerator支持的底層數(shù)學(xué)庫定制接口進(jìn)行封裝,屏蔽了定制接口限制,提供一個友好的HPL測試環(huán)境。為了最大限度發(fā)揮國產(chǎn)加速器的性能,提出了OA4MM調(diào)度算法。實驗結(jié)果驗證了dPEM的有效性和OA4MM算法的高效性,全系統(tǒng)HPL測試性能較傳統(tǒng)的異構(gòu)矩陣乘調(diào)度方法提升近10%,提高了基于國產(chǎn)加速器的異構(gòu)系統(tǒng)效率,未來的工作將對OA4MM算法進(jìn)行形式化描述和論證,并嘗試將OA4MM調(diào)度算法應(yīng)用至由GPU、MIC構(gòu)建的異構(gòu)實驗系統(tǒng)中。
[1] Lu Yu-tong. Applications leveraging supercomputing systems[R].ISC’2015,2015.
[2] Dongarra J J, Luszczek P,Petitet A.The linpack benchmark: Past,present,and future[J].Concurrency and Computation: Practice and Experience,2003,15(9): 803-820.
[3] Zhang Wen-li, Chen Ming-yu,Fan Jian-ping.Emulation and forecast of HPL test performance [J]. Journal of Computer Research and Development,2006,43(3):557-562.(in Chinese)
[4] Liu Gang, Zhang Heng,Zhang Dian,et al.Optimization of Linpack for Loongson 3B processor [J]. Journal of Shenzhen University (Science & Engineering),2014,31(3):286-292.(in Chinese)
[5] Liu Jie,Hu Qing-feng,Chi Li-hua,et al.Parallel performance analysis of high performance Linpack[C]∥Proc of 2004 National Conference on High Performance Computing,2004:1.(in Chinese)
[6] Yang Xue-jun, Liao Xiang-ke,Lu Kai,et al.The TianHe-1A supercomputer: Its hardware and software[J].Journal of Computer Science and Technology,2011,26(3): 344-351.
[7] Wang Q, Ohmura J, Shan A, et al.Parallel matrix-matrix multiplication based on HPL with a GPU-accelerated PC cluster[C]∥Proc of the 1st International Conference on Networking and Computing, 2010:243-248.
[8] Du Yun-fei,Yang Can-qun,Wang Feng,et al.Analysis and evaluation method for Linpack benchmark [J].Dongbei Daxue Xuebao/Journal of Northeastern University,2014,35: 102-107.
[9] Liu Fang-fang,Yang Chao,Liu Yi-qun,et al.Reducing communication overhead in the high performance conjugate gradient benchmark on Tianhe-2[C]∥Proc of the 13th International Symposium on Distributed Computing and Applications to Business,Engineering and Science,2014:13-18.
附中文參考文獻(xiàn):
[3] 張文力,陳明宇,樊建平,等.HPL測試性能仿真與預(yù)測[J].計算機(jī)研究與發(fā)展,2006,43(3):557-562.
[4] 劉剛,張恒,張滇,等.基于龍芯3B 處理器的Linpack 優(yōu)化實現(xiàn)[J].深圳大學(xué)學(xué)報(理工版),2014,31(3):286-292.
[5] 劉杰,胡慶豐,遲利華,等.高性能Linpack并行計算性能分析[C]∥全國高性能計算學(xué)術(shù)會議,2004:1.
猜你喜歡
工業(yè)設(shè)計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
知識經(jīng)濟(jì)·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(shù)(2016年6期)2016-04-20 06:21:32
