基于聚類算法的視頻內容識別研究
2018-01-22 01:48:35陳雙全
電腦與電信 2017年11期
關鍵詞:內容
陳雙全
(武漢船舶職業技術學院電氣學院,湖北 武漢 430050)
1 引言
面對海量視頻上傳請求,有限的審核員配備條件,不可能讓審核員將視頻認真從頭看到尾,這就為不良人員提供了在正規視頻中插播非正規內容的機會。而機械識別效率和準確率仍然不能滿足工程應用的要求。因此本系統提出了針對視頻興趣度排列組合的K-MEANS改進聚類算法識別違規視頻,保證互聯網視頻內容的健康性。
2 視頻結構分析
從視頻數據形成的角度來看,按照形成過程首先視頻內容包含了多個視頻的圖像幀,由一連串圖像幀構成了一個鏡頭,再由多組鏡頭構成了一個場景,最后由多個場景片段組成視頻。在進行視頻結構化處理時,視頻流、場景分割、關鍵幀提取等都可以作為視頻內容數據分析的組成部分。由此可見,視頻內容識別有別于一般數據結構性的關聯關系,視頻內容非結構化特征更為明顯。
3 視頻內容檢索技術
3.1 鏡頭分割
對于一段視頻的內容識別要首先對其按照視頻拍攝時的鏡頭進行分割,無論是影片還是短視頻,都是由多個鏡頭組合而成,即使采用長鏡頭進行拍攝通常也不會大于10分鐘。所以,在對鏡頭進行分割時要從鏡頭切換點進行分割,將視頻劃分出若干個鏡頭的組成。鏡頭與鏡頭之間存在濾鏡的過渡,在分割時要準確把握濾鏡的切入點與切出點,由此進行平均分割以達到鏡頭分割的準確性。
3.2 關鍵幀提取
鏡頭分割完成后,每一個鏡頭都包含一連串的圖像幀,圖像幀以圖像片段的形式存在,通過幀的滾動實現圖像的連貫性播放。圖像幀作為視頻內容的基本組成單元,進行鏡頭圖像內容的聚類可采用有幀平均法和直方圖平均法進行關鍵幀的提取。有幀平均法是對一組連貫的圖像幀以圖像內容相似度聚類的平均值所屬關鍵幀圖像作為圖像內容進行識別,直方圖平均法是對鏡頭中圖像坐標像素數的平均值作為圖像內容進行識別進而得到關鍵幀的圖像。
3.3 視頻內容聚類
對提取出來的關鍵幀圖像按照圖像特征數據庫進行比對分析和聚類計算,圖像特征數據庫作為圖像內容識別的基礎,其包含了大量的非結構化圖像特征,可通過對圖像特征的累計不斷豐富圖像特征數據庫的內容,由此提高視頻內容識別的準確度。
4K-MEANS聚類改進算法
4.1 視頻內容識別算法
現有視頻內容識別算法主要包括:K均值模糊聚類算法和C均值模糊聚類算法。基于K均值聚類的視頻內容識別均值算法模型如下:(1)選取K個聚類中心作為視頻內容樣本的K均值聚類
(3)計算視頻內容樣本各聚類中心的新向量值:

式中nj為Sj所包含的樣本數。
K均值偽代碼如下:
設定聚類數目K,最大執行步驟tmax,一個很小的容忍誤差ε>0決定聚類中心起始位置Cj(0),0 實現原理是:設有視頻內容像素點X={x1,x2,…,xn} ,將它分為c類,uik為xk對第i類的隸屬度,用一個模糊隸屬度矩陣U={uik}∈Rcn表示分類結果,必須滿足: 通過最小化關于隸屬度矩陣U和聚類中心V的目函數Jm(U,V)來實現: 其中,U={uik}為滿足條件(1)的隸屬度矩陣,為c個聚類中心點集,m∈(1,+∞)為加權指數,當m=1時,模糊聚類就退化為硬C均值聚類。 第k個樣本到第i類中心的距離定義為: (1)初始化視頻內容樣本的聚類中心V={v1,v2,…,vc} ; (2)用隨機數的方式初始化視頻內容樣本的屬性度量矩陣; (3)計算C均值聚類算法的視頻內容樣本的隸屬度矩陣: 其中,A為p×p的正定矩陣,當A=I時,即為歐氏距離。 C均值聚類算法的聚類模型描述如下: (5)重復步驟三和四直至公式6的結果處于收斂狀態。 C均值聚類偽代碼如下: 輸入:總數K,尺度tmax,誤差ε>0,起始位置Cj(0),0 針對現有的K-MEANS算法在流媒體視頻中的聚類結果往往趨于孤立點的問題以及時間復雜度為O(n2)不利于對流媒體系統中大數據量的挖掘的問題,本文采用的是基于排列組合思想的K-MEANS聚類改進算法。 K-MEANS聚類改進算法的設計流程:For i=0;i if(e∈E){//如果待測元素e屬于極大聚類集合 本文對現有視頻內容識別算法進行分析,包括:K均值模糊聚類算法和C均值模糊聚類算法,提出了基于改進的K-均值聚類算法的視頻內容識別設計思想,并通過算法的設計流程完成對K-MEANS聚類改進解決流媒體視頻中的聚類結果趨于孤立點的問題以及時間復雜度為O(n2)不利于對流媒體系統中大數據量的挖掘的問題,該方法基于排列組合的K-MEANS聚類算法深層次挖掘策略的內在規則,對于更好地識別視頻內容有著較好的實現效果。 [1]徐勇.基于聚類算法的內容識別研究[J].電腦與電信,2016(11):39-41. [2]孟彩霞.大數據環境下不良網絡內容識別技術研究[J].軟件導刊,2015,14(11):19-21. [3]岳曉峰,龔青池.視頻流圖像字符識別算法的研究和實現[J].機械工程與自動化,2015(4):73-75.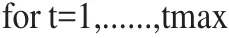

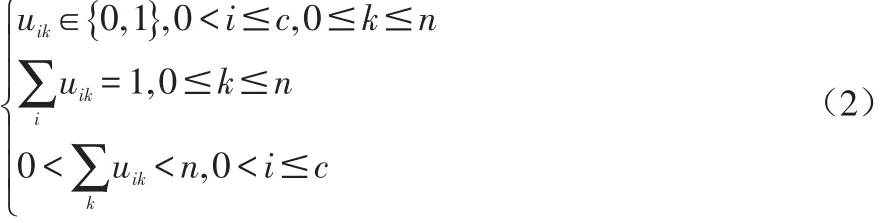
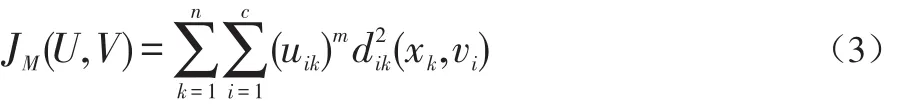
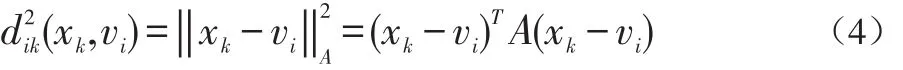


4.2 K-MEANS聚類改進算法設計

5 結語
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52科學大眾(2021年21期)2022-01-18 05:53:48科學大眾(2021年17期)2021-10-14 08:34:02科學大眾(2021年19期)2021-10-14 08:33:02科學大眾(2021年9期)2021-07-16 07:02:52科學大眾(2020年23期)2021-01-18 03:09:18科學大眾(2020年17期)2020-10-27 02:49:04中國現代醫藥雜志(2020年12期)2020-01-08 16:42:06中國現代醫藥雜志(2020年10期)2020-01-08 06:42:11臺聲(2016年2期)2016-09-16 01:06:53
