基于主題增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的用戶(hù)興趣識(shí)別
2018-01-12 07:20:26杜雨萌張偉男
計(jì)算機(jī)研究與發(fā)展 2018年1期
杜雨萌 張偉男 劉 挺
(哈爾濱工業(yè)大學(xué)社會(huì)計(jì)算與信息檢索研究中心 哈爾濱 150001)
(ymdu@ir.hit.edu.cn)
隨著移動(dòng)互聯(lián)網(wǎng)技術(shù)的發(fā)展及移動(dòng)終端的普及,Twitter、微博等社交類(lèi)應(yīng)用上聚集了大量的用戶(hù),每個(gè)用戶(hù)每天可以接收到成百上千條微博,從而導(dǎo)致信息過(guò)載,嚴(yán)重影響用戶(hù)的信息及知識(shí)獲取.自動(dòng)識(shí)別微博用戶(hù)的興趣,進(jìn)而根據(jù)用戶(hù)興趣來(lái)協(xié)助用戶(hù)組織及過(guò)濾信息,能夠有效解決信息過(guò)載的問(wèn)題.同時(shí),用戶(hù)興趣識(shí)別對(duì)于商品推薦、廣告定向投放等業(yè)務(wù)也有很大幫助.
已有研究中,Ramage等人[1]使用Labeled LDA主題模型對(duì)Twitter用戶(hù)進(jìn)行了興趣挖掘,這種方法將用戶(hù)的所有Tweets集合作為一個(gè)文檔,使用主題模型預(yù)測(cè)出文檔的主題分布,以此表示用戶(hù)的興趣主題分布.該方法的問(wèn)題在于,沒(méi)有區(qū)分用戶(hù)發(fā)布的Tweets中詞的權(quán)重,而現(xiàn)實(shí)中對(duì)一條Tweet或微博進(jìn)行分類(lèi)時(shí),其中的每個(gè)詞起到的作用是不一樣的,往往是少數(shù)幾個(gè)詞起到?jīng)Q定用戶(hù)興趣的作用.這就導(dǎo)致盡管一個(gè)用戶(hù)發(fā)表了很多自身興趣相關(guān)的微博,但由于表達(dá)興趣的詞周?chē)嬖诖罅吭肼曉~,使得Labeled LDA主題模型對(duì)用戶(hù)興趣詞的主題分配隨上下文而發(fā)生嚴(yán)重偏移,從而導(dǎo)致用戶(hù)興趣識(shí)別發(fā)生錯(cuò)誤.
針對(duì)上述問(wèn)題,本文首先通過(guò)對(duì)用戶(hù)的微博進(jìn)行逐條興趣分類(lèi),從而緩解噪聲詞對(duì)用戶(hù)興趣詞的影響;然后通過(guò)用戶(hù)微博的興趣類(lèi)別分布進(jìn)而識(shí)別用戶(hù)興趣.具體地,本文提出一種主題增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network, CNN)的興趣識(shí)別方法,結(jié)合了詞向量提供的連續(xù)語(yǔ)義特征和Labeled LDA模型提供的離散主題特征.在進(jìn)行用戶(hù)興趣識(shí)別時(shí),首先使用主題增強(qiáng)CNN對(duì)用戶(hù)的微博進(jìn)行逐條分類(lèi),之后根據(jù)用戶(hù)微博的興趣類(lèi)別分布,通過(guò)極大似然估計(jì)得到微博用戶(hù)的興趣.
1 主題增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)
1.1 背景介紹
1.1.1 Labeled LDA主題模型
1) 主題生成過(guò)程
Labeled LDA是一種描述帶標(biāo)簽的文檔的生成過(guò)程的概率圖模型[2].與傳統(tǒng)LDA模型[3]一樣,Labeled LDA認(rèn)為每篇文檔是一組主題的混合,文檔里的每個(gè)詞都由一個(gè)主題生成.與傳統(tǒng)LDA模型不同的是,Labeled LDA通過(guò)把主題模型中的主題限制在了與每篇文檔關(guān)聯(lián)的一個(gè)標(biāo)簽集合上,從而在模型中融入了監(jiān)督信息.Labeled LDA的圖模型如圖1所示:

Fig. 1 Graphical model of Labeled LDA圖1 Labeled LDA的圖模型
設(shè)每篇文檔d被表示為一個(gè)元組,該元組由一個(gè)詞索引列表w(d)=(w1,w2,…,wNd)和一個(gè)二元的標(biāo)簽出現(xiàn)/缺失指示器Λ(d)=(l1,l2,…,lK)構(gòu)成,其中每個(gè)wi∈{1,2,…,V},每個(gè)lk∈{0,1}.這里Nd表示文檔的長(zhǎng)度,V表示詞表的長(zhǎng)度,K表示語(yǔ)料庫(kù)中標(biāo)簽的數(shù)目.
令Labeled LDA模型中的主題數(shù)目等于語(yǔ)料庫(kù)中標(biāo)簽的數(shù)目,則生成過(guò)程如算法1所示:
算法1. Labeled LDA主題模型算法.
① For each topick∈{1,2,…,K}
② Generateβk=(βk,1,βk,2,…,βk,V)T~
Dir(·|η);
③ End for
④ For each documentd
⑤ For each topick∈{1,2,…,K}
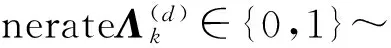
Bernoutlli(·|φk);
⑦ End for
⑧ End for
⑨ Generateα(d)=L(d)×α;
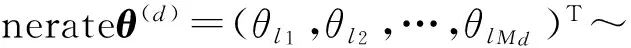
Dir(·|α(d)|);
Mult(·|θ(d)|);
Mult(·|βzi|);
在步驟①和步驟②中,從一個(gè)參數(shù)為η的Dirichlet先驗(yàn)分布抽取出每個(gè)主題k在詞表上的多項(xiàng)分布βk,即主題-詞分布.傳統(tǒng)的LDA模型中,接下來(lái)將為每一篇文檔,從一個(gè)參數(shù)為α的Dirichlet先驗(yàn)分布中抽取一個(gè)多項(xiàng)分布Λ(d),作為該文檔在K個(gè)主題上的主題分布,但在Labeled LDA中,把θ(d)限制在標(biāo)簽指示器Λ(d)顯示出現(xiàn)的那些標(biāo)簽所對(duì)應(yīng)的主題中.因?yàn)樵诜峙湮臋n中每個(gè)位置的主題時(shí)要參考θ(d),所以上述限制確保了分配的主題都來(lái)自于文檔的標(biāo)簽集合.

(1)
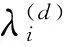
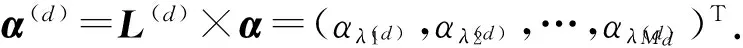
2) 學(xué)習(xí)和預(yù)測(cè)
Labeled LDA對(duì)用戶(hù)打好標(biāo)簽的文檔進(jìn)行學(xué)習(xí)和預(yù)測(cè)的過(guò)程與傳統(tǒng)的LDA模型的學(xué)習(xí)和預(yù)測(cè)過(guò)程是相似的.區(qū)別只在于:Labeled LDA將每篇文檔用以獲取主題分布的先驗(yàn)Dirichlet分布的參數(shù)α(d)限制在了文檔的標(biāo)簽集合λ(d)上.因此在訓(xùn)練時(shí),像LDA模型一樣使用Gibbs采樣,文檔d里位置i的主題為j的概率為
P(zi=j|z|)∝×,
(2)
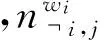
在從訓(xùn)練集中學(xué)習(xí)出多項(xiàng)分布β,即主題-詞分布后,就可以使用Gibbs采樣對(duì)打好標(biāo)簽的新文檔進(jìn)行主題預(yù)測(cè).
3) 基于Labeled LDA主題模型的用戶(hù)興趣識(shí)別
Ramage等人[1]使用Labeled LDA主題模型對(duì)Twitter用戶(hù)進(jìn)行了興趣識(shí)別,方法是:將興趣主題設(shè)置為L(zhǎng)abeled LDA模型中使用的主題,將用戶(hù)的Tweets集合作為一篇文檔,之后使用Labeled LDA主題模型計(jì)算用戶(hù)的Tweets文檔的主題分布,獲得的主題分布即為用戶(hù)的興趣主題分布.
1.1.2 基于卷積神經(jīng)網(wǎng)絡(luò)的句子分類(lèi)器
CNN是計(jì)算機(jī)圖像領(lǐng)域發(fā)明的一種前饋神經(jīng)網(wǎng)絡(luò),在圖像識(shí)別、影像分析等應(yīng)用中表現(xiàn)出色[4-6].隨后,CNN在自然語(yǔ)言處理領(lǐng)域的句法分析[7]、查詢(xún)檢索[8]、句子建模[9]等工作上都取得了良好的效果.Kim[10]使用單層卷積層的CNN實(shí)現(xiàn)了一個(gè)句子分類(lèi)器,該模型結(jié)構(gòu)如圖2所示:
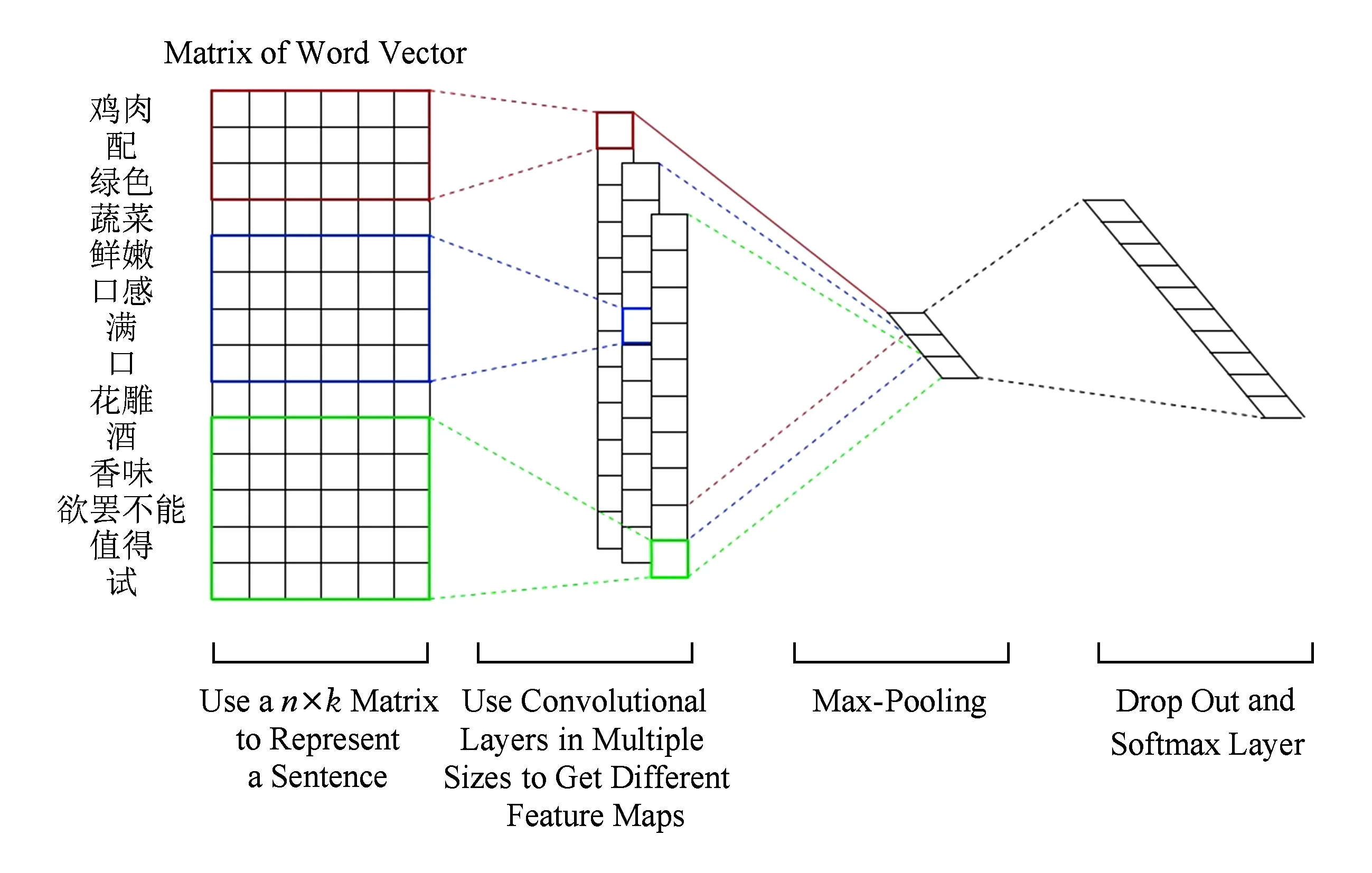
Fig. 2 Model architecture of CNN sentence classifier圖2 卷積神經(jīng)網(wǎng)絡(luò)句子分類(lèi)器的模型結(jié)構(gòu)
模型的輸入是一個(gè)n×k的詞向量矩陣,設(shè)xi∈k是句子里第i個(gè)詞對(duì)應(yīng)的詞向量.一個(gè)長(zhǎng)度為n的句子,可以表示為
x1:n=x1⊕x2⊕…⊕xn,
(3)
令xi:i+j表示xi,xi+1,…,xi+j詞的連接,一個(gè)卷積操作是指使用過(guò)濾器(filter)w∈hk,從一個(gè)包含h個(gè)詞的窗口生成一個(gè)新的特征.設(shè)ci是從窗口xi:i+h-1生成的特征:
ci=f(w·xi:i+h-1+b),
(4)
其中,b是偏置,f是一個(gè)非線(xiàn)性函數(shù).這個(gè)過(guò)濾器在句子的所有詞窗口x1:h,x2:h+1,…,xn-h+1:n上都生成新的特征,就得到了一個(gè)特征映射(feature map)
c=(c1,c2,…,cn-h+1),
(5)
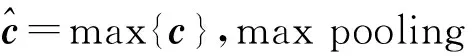
模型中會(huì)使用多個(gè)filter,所以會(huì)產(chǎn)生多個(gè)feature map以及多次max pooling操作.之后將max pooling操作后的結(jié)果作為特征向量輸入到softmax層,最終softmax層輸出句子在不同類(lèi)別上的概率分布.
1.2 我們的模型
本文提出一種基于主題增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的用戶(hù)興趣識(shí)別方法,是一種結(jié)合了連續(xù)的語(yǔ)義特征和離散的主題特征的方法, 模型框架如圖3所示:
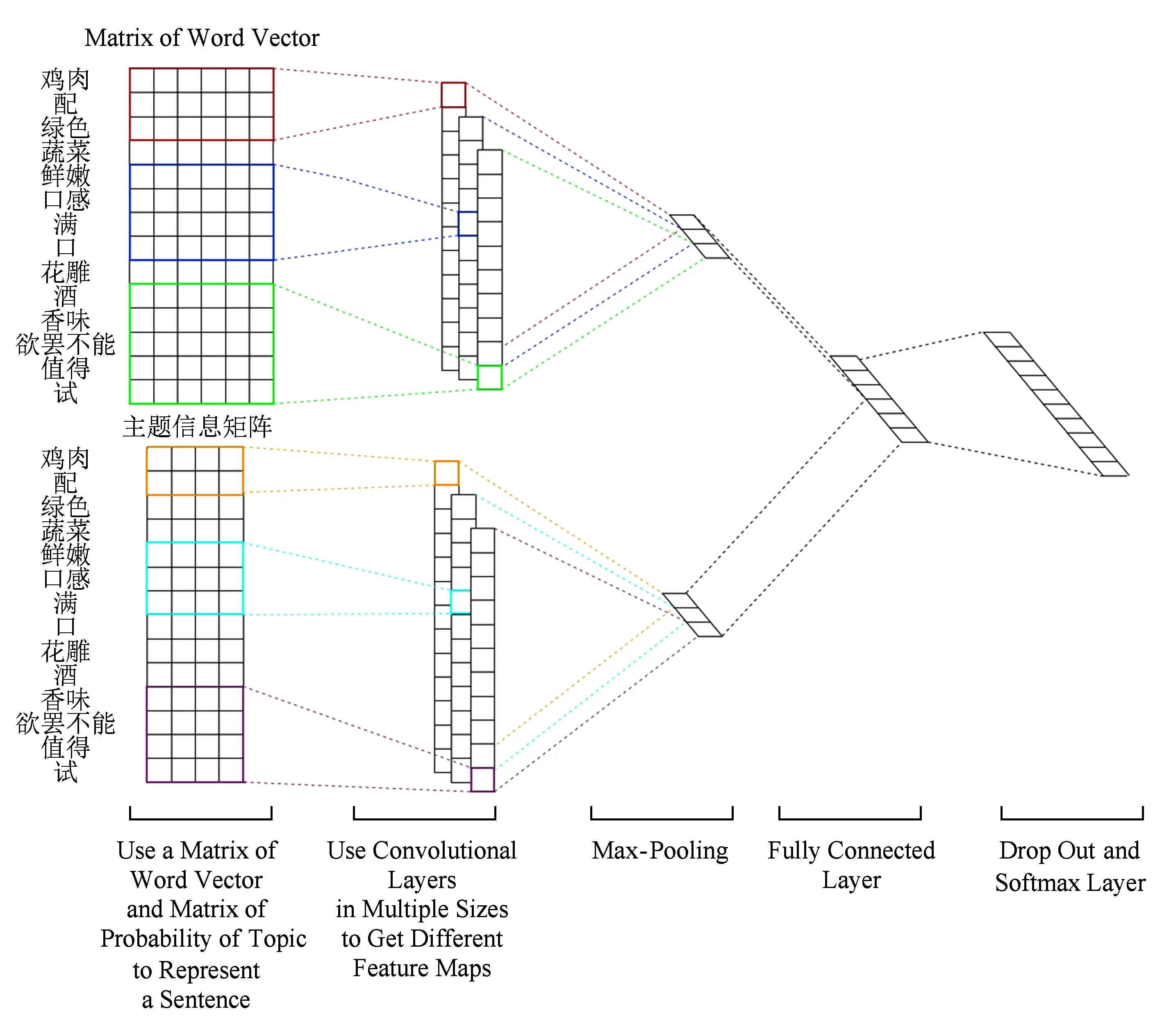
Fig. 3 Model architecture of topic augmented CNN圖3 主題增強(qiáng)CNN的模型結(jié)構(gòu)
模型的2個(gè)輸入分別是一條微博對(duì)應(yīng)的詞向量矩陣和主題信息矩陣.詞向量由預(yù)先訓(xùn)練好的word2vec模型獲得,對(duì)微博進(jìn)行填充(padding)后,將微博里的每個(gè)詞都轉(zhuǎn)換為對(duì)應(yīng)的詞向量,便得到該微博對(duì)應(yīng)的詞向量矩陣.我們?cè)O(shè)定了K個(gè)興趣主題,主題信息矩陣中的每一行的K維向量對(duì)應(yīng)微博中每個(gè)詞分配到各個(gè)興趣主題的概率.如果計(jì)算微博中第i個(gè)位置上的詞wi被分配為主題k的概率,首先是根據(jù)由主題模型獲得的第i個(gè)位置以外的位置的主題分配情況,可以估算出當(dāng)前位置i被分配為主題k的概率:
(6)
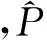

(7)
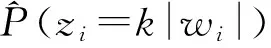

(8)
本文的模型是一個(gè)雙通道的CNN,2個(gè)通道的結(jié)構(gòu)相似.在每個(gè)通道的輸入矩陣上都添加了一個(gè)單層卷積層,對(duì)卷積后獲得的feature map執(zhí)行max pooling操作,然后將2個(gè)通道的池化操作后的結(jié)果合并輸入到一個(gè)全連接層,全連接層的輸出作為特征向量輸入到softmax層,最終softmax層輸出微博在不同興趣類(lèi)別上的概率分布.
本文的用戶(hù)興趣識(shí)別方法如下:設(shè)主題類(lèi)別體系為C={c1,c2,…,cM},給定某個(gè)用戶(hù)u,抽取其發(fā)布的微博文本集合W={w1,w2,…,wn},文本數(shù)目為n,使用本文提出的主題增強(qiáng)CNN作為分類(lèi)器進(jìn)行預(yù)測(cè),得到n條微博文本對(duì)應(yīng)的類(lèi)別列表L={l1,l2,…,ln},其中l(wèi)i∈C.在類(lèi)別列表上定義一個(gè)計(jì)數(shù)函數(shù)count(x,L)表示類(lèi)別x在L中出現(xiàn)的次數(shù),其中,x∈C.按照count(x,L)由高到低排序,選擇排序靠前的類(lèi)別表示用戶(hù)興趣.
2 實(shí)驗(yàn)及分析
2.1 興趣類(lèi)別體系
以類(lèi)別體系覆蓋面大、類(lèi)別間區(qū)分度大為原則,并參考相關(guān)文獻(xiàn)[11],本文設(shè)定了10個(gè)微博興趣類(lèi)別,分別為:體育、娛樂(lè)、汽車(chē)、財(cái)經(jīng)、時(shí)事/軍事、科技、健康/養(yǎng)生、旅游/攝影/美食、星座/時(shí)尚/語(yǔ)錄、校園/教育/職場(chǎng).
由于普通用戶(hù)所發(fā)的微博涵蓋的種類(lèi)比較多,包含較多的噪聲,因此我們?cè)讷@取訓(xùn)練數(shù)據(jù)時(shí)選取的是各個(gè)類(lèi)別下的微博認(rèn)證用戶(hù),且盡量選擇企業(yè)認(rèn)證用戶(hù).比如體育類(lèi),我們選取了“新浪體育”、“虎撲體育”等用戶(hù),從這些用戶(hù)的微博中抽取訓(xùn)練語(yǔ)料.
2.2 實(shí)驗(yàn)數(shù)據(jù)
爬取各個(gè)類(lèi)別的認(rèn)證用戶(hù)的微博,在對(duì)原始微博語(yǔ)料進(jìn)行必要的過(guò)濾后抽取出訓(xùn)練語(yǔ)料、驗(yàn)證語(yǔ)料和測(cè)試語(yǔ)料.訓(xùn)練集、驗(yàn)證集和測(cè)試集的微博文本數(shù)目如表1所示:
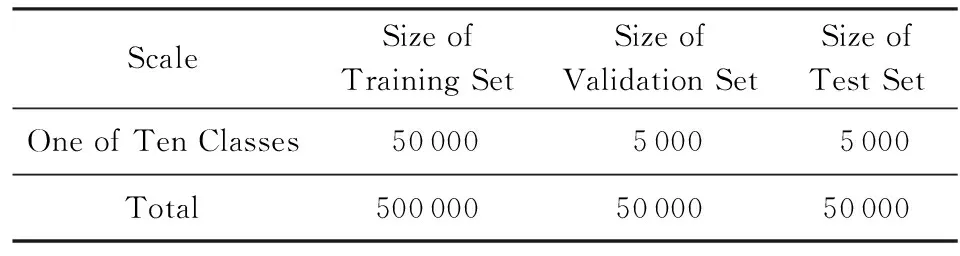
Table 1 Number of Microblog Text in Training Set,Validation Set and Test Set
此外,還需要訓(xùn)練一個(gè)Labeled LDA模型,以構(gòu)造微博的主題信息矩陣.訓(xùn)練集是每個(gè)興趣類(lèi)別為100 000條微博,將每個(gè)類(lèi)別下的微博合并為一個(gè)文檔,并打上相應(yīng)的類(lèi)別標(biāo)簽.比如體育類(lèi),將從“新浪體育”、“虎撲體育”等體育類(lèi)的用戶(hù)的微博中抽取出的微博合并為一個(gè)文檔,并且將該文檔的標(biāo)簽設(shè)為體育.
2.3 參數(shù)設(shè)定
本文模型中的詞向量長(zhǎng)度為100,padding的最大長(zhǎng)度參考微博的最大長(zhǎng)度設(shè)置為140,卷積層的激活函數(shù)選用RLU,在詞向量的通道里卷積層選擇了長(zhǎng)度為3,4,5的過(guò)濾器各100個(gè),在主題信息的通道里卷基層選擇了長(zhǎng)度為2,3,4的過(guò)濾器各100個(gè),在模型的倒數(shù)第2層全連接層的隱含神經(jīng)元數(shù)量為300個(gè),全連接層的激活函數(shù)為RLU,輸出設(shè)定為300維,在倒數(shù)第2層與最后1層的softmax層之間設(shè)定dropOutRate=0.5,在最后一層softmax層里使用了值為1的l2正則化項(xiàng).
2.4 評(píng)價(jià)方法
2.4.1 評(píng)價(jià)微博分類(lèi)效果
本文對(duì)微博分類(lèi)效果的評(píng)價(jià)標(biāo)準(zhǔn)采用準(zhǔn)確率(accuracy)、精確率P(precision)、召回率R(recall)以及F值.
2.4.2 評(píng)價(jià)用戶(hù)興趣識(shí)別效果
對(duì)用戶(hù)的微博逐條興趣分類(lèi)后,通過(guò)極大似然估計(jì)得到微博用戶(hù)的興趣,選擇數(shù)量最多的興趣類(lèi)別作為興趣識(shí)別結(jié)果.采集了400位微博測(cè)試用戶(hù)的數(shù)據(jù),根據(jù)用戶(hù)的標(biāo)簽、簡(jiǎn)介和微博內(nèi)容對(duì)用戶(hù)的興趣類(lèi)別進(jìn)行標(biāo)注.評(píng)價(jià)標(biāo)準(zhǔn)采用準(zhǔn)確率.
2.5 實(shí)驗(yàn)結(jié)果與分析
2.5.1 微博文本分類(lèi)效果
使用本文提出的主題增強(qiáng)CNN模型進(jìn)行微博文本分類(lèi),作為對(duì)比實(shí)驗(yàn),選擇了CNN句子分類(lèi)器[10]和在大規(guī)模中文語(yǔ)料分類(lèi)任務(wù)上表現(xiàn)出色的以bigram為特征的線(xiàn)性SVM[12].主題增強(qiáng)CNN、CNN和線(xiàn)性SVM在微博文本分類(lèi)上的準(zhǔn)確率分別為:80.8%,79.6%,80.4%.表2對(duì)比了3種方法在微博文本分類(lèi)上的精確率P、召回率R以及F值.
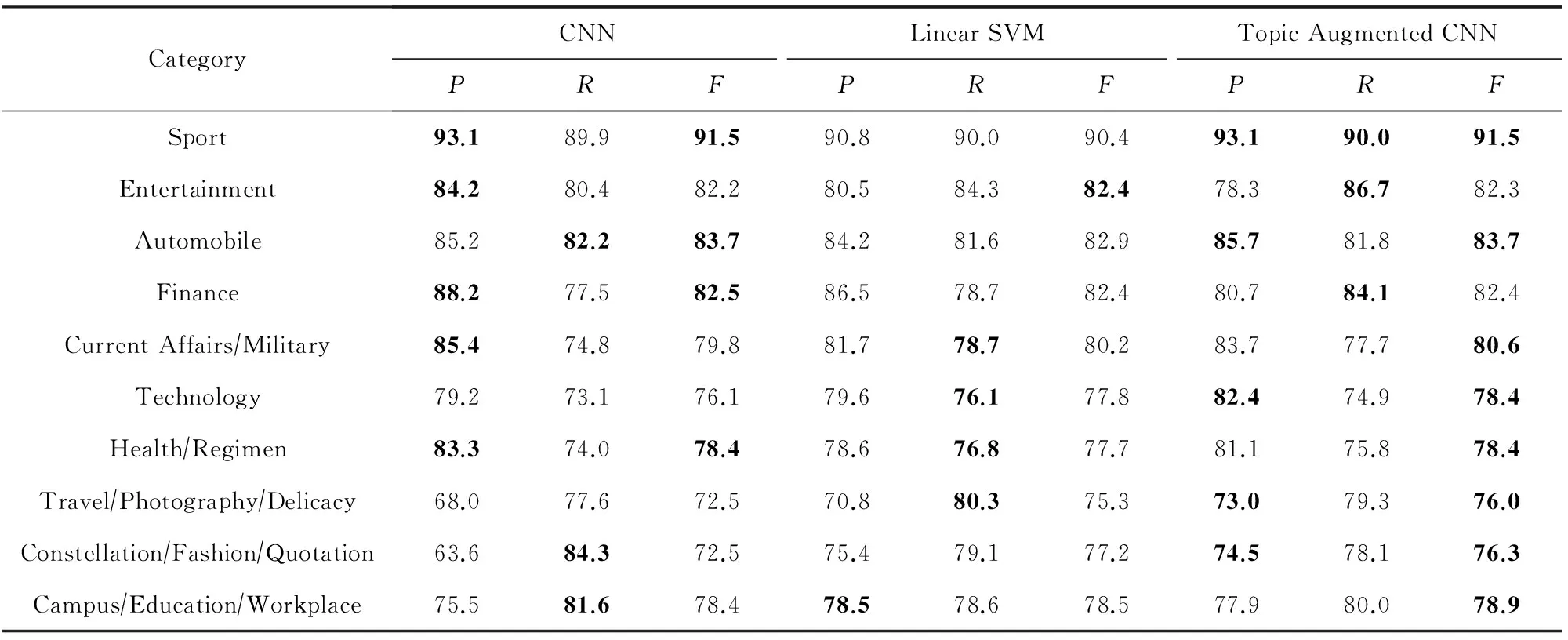
Table 2 Precision, Recall and F value Comparison of Microblog Text Classification表2 微博文本分類(lèi)精確率、召回率、F值對(duì)比 %
2.5.2 實(shí)例分析
從實(shí)驗(yàn)結(jié)果可以看出,主題增強(qiáng)CNN在微博文本分類(lèi)上取得了最好的效果.與 CNN相比,主題增強(qiáng)CNN加入了微博里每個(gè)詞被分配到各個(gè)主題的概率,在CNN分類(lèi)效果較差的旅游攝影美食和星座時(shí)尚語(yǔ)錄類(lèi)別上取得了較大提升,整體上獲得了更高的準(zhǔn)確率.
實(shí)例1. 圖4中顯示的是1條旅游/攝影/美食類(lèi)微博.
預(yù)處理后,這條微博為“日本 料理 驚聞 原 綠川 老師 著 更 自立 便 友人 前 拜訪(fǎng) 品嘗 客人 大部 份 客人 喜歡 坐 壽司 臺(tái)前 海鮮 想 吃 口 吃 出 照料 功力”.CNN將其誤分類(lèi)為校園/教育/職場(chǎng)類(lèi),原因是預(yù)處理后的文本中包含了“老師”、“自立”、“友人”、“功力”,這些和教育/校園相關(guān)的詞在只使用詞向量的情況下出現(xiàn)了誤分類(lèi).

Fig. 4 A travel/photography/delicacy microblog圖4 一條旅游/攝影/美食類(lèi)微博

Fig. 5 Image of topic information matrix of microblog used in example 1圖5 實(shí)例1中使用的微波的主題信息矩陣的圖像
將這條微博的主題信息矩陣圖像化,其中橫坐標(biāo)是該微博預(yù)處理后包含的詞,縱坐標(biāo)是主題類(lèi)別,圖5中顏色的冷暖程度表示一個(gè)詞被分配為一個(gè)主題的概率,概率與顏色的對(duì)應(yīng)關(guān)系如圖5中右側(cè)的圖例所示,概率由小至大對(duì)應(yīng)于顏色由冷色變?yōu)榕?
圖5縱坐標(biāo)是旅游/攝影/美食的行明顯亮于其他行,經(jīng)統(tǒng)計(jì),該微博的30個(gè)詞中被分配為旅游/攝影/美食類(lèi)上的概率超過(guò)30%的詞有22個(gè),而被分配為校園/教育/職場(chǎng)主題上的概率大于30%的詞只有2個(gè).由此可見(jiàn),這條微博的主題信息對(duì)其被正確分類(lèi)起到了重要作用.
實(shí)例2. 圖6中顯示的是一條星座/時(shí)尚/語(yǔ)錄類(lèi)微博.
預(yù)處理后,這條微博為“熟知 米蘭 倫敦 愛(ài) 玩 愛(ài)鬧 巴黎 處心積慮 玩 段位 米蘭 精致 手工藝 陽(yáng)剛 男性 魅力 招牌”,其中“米蘭”、“巴黎”、“玩”等與旅游相關(guān)的詞,使用詞向量的CNN將其誤分類(lèi)為旅游/攝影/美食類(lèi).而該微博的主題信息矩陣的圖像如圖7所示:

Fig. 6 A constellation/fashion/quotations microblog圖6 一條星座/時(shí)尚/語(yǔ)錄類(lèi)微博
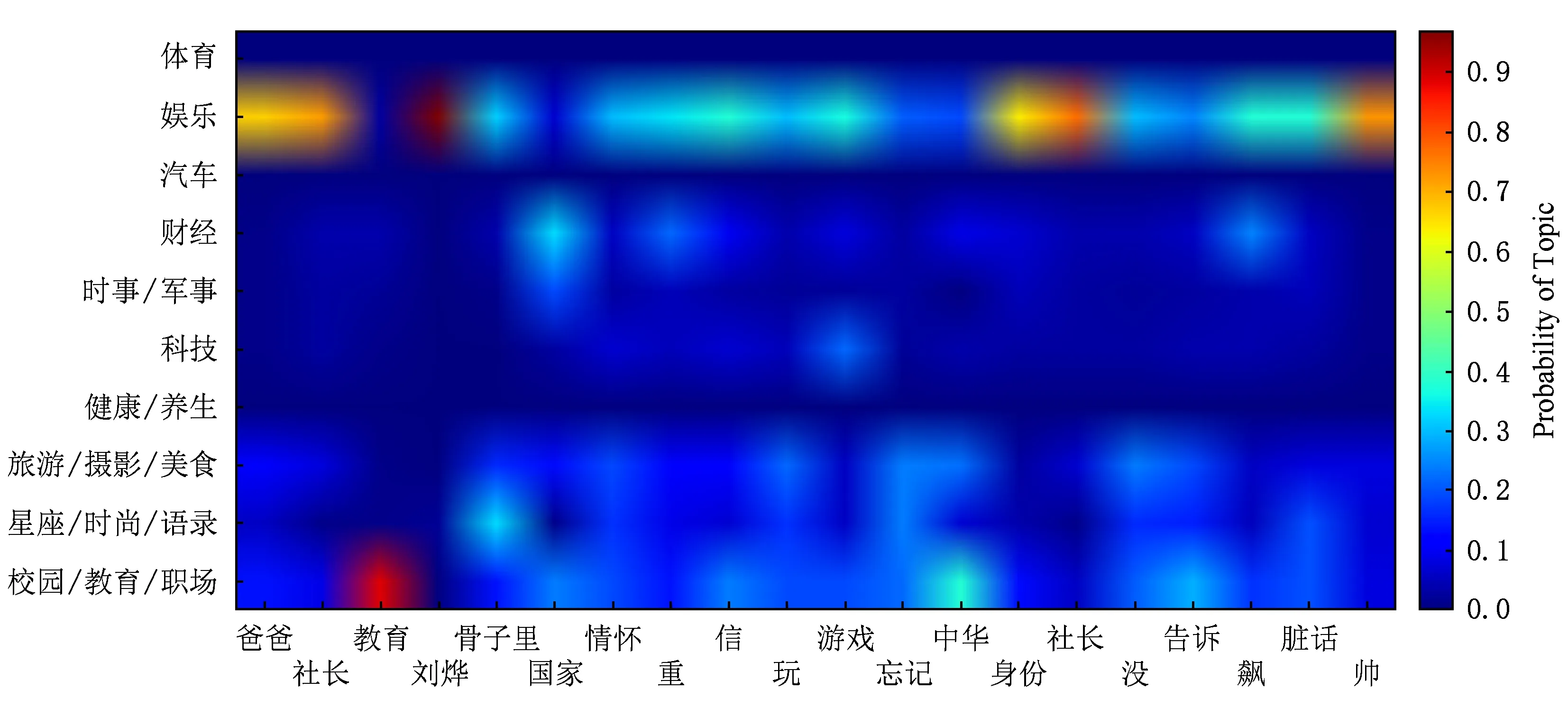
Fig. 7 Image of topic information matrix of microblog used in example 2圖7 實(shí)例2中使用的微波的主題信息矩陣的圖像
圖7中縱坐標(biāo)是星座/時(shí)尚/語(yǔ)錄的行顏色明顯亮于其他行,經(jīng)統(tǒng)計(jì),該微博中每個(gè)詞被分配為星座/時(shí)尚/語(yǔ)錄主題主題的概率都超過(guò)30%,但沒(méi)有一個(gè)詞被分配為旅游/攝影/美食主題的概率超過(guò)30%.可以看出主題信息對(duì)我們的模型正確分類(lèi)這條微博起到了重要作用.
與使用bigram特征的線(xiàn)性SVM相比,主題增強(qiáng)CNN利用主題信息,對(duì)于包含噪聲詞比較多的微博,可以分類(lèi)得更準(zhǔn)確.
實(shí)例3. 圖8中顯示的是一條娛樂(lè)類(lèi)微博.
預(yù)處理后,這條微博為“爸爸 社長(zhǎng) 教育 劉燁 骨子里 國(guó)家 情懷 重 信 玩 游戲 忘記 中華 身份 社長(zhǎng) 沒(méi) 告訴 飆 臟話(huà) 帥”,使用線(xiàn)性SVM將該微博誤分類(lèi)為校園/教育/職場(chǎng)類(lèi),因?yàn)椤鞍职?社長(zhǎng)”、“社長(zhǎng) 教育”、“玩 游戲”、“身份 社長(zhǎng)”這些bigram與校園/教育/職場(chǎng)類(lèi)體現(xiàn)出很強(qiáng)的相關(guān)性,所以使用bigram作為特征的線(xiàn)性SVM將其誤分類(lèi)到校園/教育/職場(chǎng)類(lèi).而該微博的主題信息矩陣圖像如圖9所示:

Fig. 9 Image of topic information matrix of microblog used in example 3圖9 實(shí)例3使用的微波 的主題信息矩陣的圖像
圖9中縱坐標(biāo)為娛樂(lè)的行明顯要亮于其他行,經(jīng)統(tǒng)計(jì),該微博20個(gè)詞中被分配為娛樂(lè)主題的概率超過(guò)30%的詞有15個(gè),而被分配為校園/教育/職場(chǎng)類(lèi)的概率超過(guò)30%的詞只有1個(gè).因此,主題信息對(duì)正確分類(lèi)這條微博起到重要作用.
2.5.3 用戶(hù)興趣識(shí)別效果

Fig. 11 A sport microblog圖11 一條體育類(lèi)微博
使用上述3個(gè)微博文本分類(lèi)器,對(duì)用戶(hù)的微博進(jìn)行逐條分類(lèi),之后根據(jù)用戶(hù)微博的興趣類(lèi)別分布,通過(guò)極大似然估計(jì)得到微博用戶(hù)的興趣.此外還增加了基于Labeled LDA主題模型的用戶(hù)興趣識(shí)別方法作為對(duì)比.使用Labeled LDA模型進(jìn)行興趣識(shí)別時(shí),把一個(gè)用戶(hù)的微博集合作為一篇文檔,之后使用Labeled LDA模型預(yù)測(cè)每個(gè)用戶(hù)的微博文檔的主題分布,選擇占據(jù)最高比例的主題作為興趣識(shí)別的結(jié)果.圖10顯示了上述4種方法對(duì)400名測(cè)試用戶(hù)的興趣識(shí)別效果.
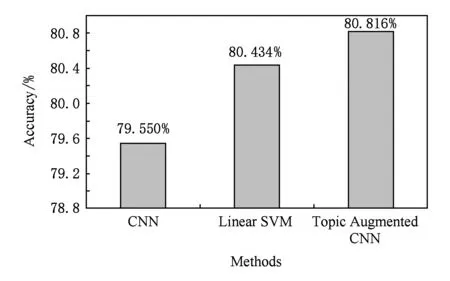
Fig. 10 Accuracy comparison of user interest recognition圖10 用戶(hù)興趣識(shí)別準(zhǔn)確率對(duì)比
可以看出在這4種方法中,主題增強(qiáng)CNN+MLE取得了最好的效果.主題增強(qiáng)CNN+MLE、線(xiàn)性SVM和CNN這3種方法的興趣識(shí)別效果和它們?cè)谖⒉┪谋痉诸?lèi)上的效果正相關(guān).Labeled LDA模型對(duì)文檔中的一個(gè)詞分配主題時(shí),是結(jié)合當(dāng)前位置以外的位置上的主題分配情況,以及訓(xùn)練好的Labeled LDA模型所提供的主題-詞分布來(lái)確定的,Labeled認(rèn)為每個(gè)詞的權(quán)重都是一樣的.然而在判斷一條微博的類(lèi)別時(shí),微博中每個(gè)詞的作用大小是不一樣的,往往是少數(shù)幾個(gè)詞起決定類(lèi)別的作用.
圖11所示是一條體育類(lèi)微博,雖然微博中多次出現(xiàn)“大學(xué)”和“理工”、“學(xué)院”這些教育相關(guān)的詞語(yǔ),但是“男籃”、“CUBA”這2個(gè)體育相關(guān)的詞起到了決定微博類(lèi)別的作用,所以分類(lèi)為體育類(lèi)微博.所以當(dāng)一個(gè)用戶(hù)發(fā)布很多自身興趣相關(guān)的微博,但表達(dá)興趣的詞周?chē)嬖诖罅吭肼曉~時(shí),Labeled LDA主題模型在對(duì)用戶(hù)興趣詞的主題分配會(huì)隨上下文而發(fā)生嚴(yán)重偏移,從而導(dǎo)致用戶(hù)興趣識(shí)別發(fā)生錯(cuò)誤.我們的方法通過(guò)對(duì)用戶(hù)的微博進(jìn)行逐條興趣分類(lèi)進(jìn)而獲得用戶(hù)的興趣,緩解了噪聲詞對(duì)用戶(hù)興趣詞的影響,取得了更好的效果.
3 相關(guān)工作
目前社會(huì)媒體上用戶(hù)興趣識(shí)別的方法主要有以下2類(lèi):
1) 基于用戶(hù)微博內(nèi)容的興趣識(shí)別.Michelson等人[13]通過(guò)檢測(cè)用戶(hù)在他們的Tweets中提到的實(shí)體來(lái)挖掘他們的興趣主題.Ramage 等人[1]將用戶(hù)的所有Tweets集合看作一篇文檔,然后使用Labeled LDA模型推斷用戶(hù)微博文檔上的興趣主題分布,在Twitter排序和推薦任務(wù)行取得很好的效果.Zhao等人[14]提出了一個(gè)Twitter-LDA模型,假設(shè)一條Tweet只包含一個(gè)主題,用來(lái)挖掘每條Tweet的主題;Xu等人[15]提出一種改進(jìn)的作者-主題(author-topic)模型——Twitter-user模型,對(duì)每一條Twitter,該模型使用一個(gè)隱變量(latent variable)去預(yù)測(cè)它是否同用戶(hù)的興趣相關(guān);Sasaki等人[16]提出了一個(gè)基于Twitter-LDA的改進(jìn)模型,可以估計(jì)每個(gè)用戶(hù)的所有Tweets中背景詞與主題詞之間的比例,并提出了一個(gè)新的概率主題模型主題追蹤模型(topic tracking model, TTM),可以獲取用戶(hù)興趣主題趨勢(shì)的動(dòng)態(tài)性進(jìn)行在線(xiàn)推理;Guo等人[17]提出一個(gè)面向時(shí)間戳的動(dòng)態(tài)主題模型,作者將每個(gè)主題下概率最高的詞看作是用戶(hù)的興趣,并且作者提出了一個(gè)基于密度的算法來(lái)選擇主題的數(shù)目.
2) 基于用戶(hù)的行為(關(guān)注、轉(zhuǎn)發(fā)等)的興趣識(shí)別.Abel 等人[18]對(duì)基于用戶(hù)在Twitter上的活動(dòng)推導(dǎo)出的用戶(hù)興趣信息的時(shí)間動(dòng)態(tài)性進(jìn)行了分析,并且把時(shí)間特性引入到用戶(hù)模型,定義了時(shí)間敏感的用戶(hù)模型;Jin等人[19]在Facebook上通過(guò)用戶(hù)的點(diǎn)贊(like)信息,挖掘用戶(hù)的興趣;Orlandi等人[20]提出一種通過(guò)分析社會(huì)網(wǎng)絡(luò)用戶(hù)發(fā)布的消息和諸如發(fā)表的評(píng)論、簽到的地點(diǎn)、喜歡的鏈接等,可以自動(dòng)抽取、聚合、表示用戶(hù)興趣的算法;Wang等人[21]提出一種基于連接關(guān)系二元圖的正則化框架(regularization framework)來(lái)提高用戶(hù)興趣主題挖掘的效果;Vosecky等人[22]提出一個(gè)協(xié)同的用戶(hù)主題模型,通過(guò)用戶(hù)的社會(huì)連接來(lái)全面地獲得用戶(hù)的偏好,也提出了一種雙層的用戶(hù)模型結(jié)構(gòu)以解決Twitter上主題多樣性的問(wèn)題,可以解決語(yǔ)義感知的查詢(xún)消岐,完成個(gè)性化的Twitter搜索;Bhattacharya 等人[23]使用一種基于社會(huì)標(biāo)注(social annotations )的方法,首先推斷出popular user擅長(zhǎng)的主題,進(jìn)而推測(cè)關(guān)注這些popular user的用戶(hù)的興趣主題;Zhao 等人[24]在不同行為(如發(fā)布、評(píng)論、點(diǎn)贊等)下用戶(hù)的興趣是不同的,作者首先構(gòu)建各個(gè)行為的user-topic矩陣,之后對(duì)每個(gè)user-topic矩陣進(jìn)行矩陣分解學(xué)習(xí)latent embedding,最后構(gòu)建用戶(hù)信息(user profile),對(duì)用戶(hù)在各個(gè)主題上的興趣進(jìn)行預(yù)測(cè).
4 結(jié) 論
本文提出了一種基于主題增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的用戶(hù)興趣識(shí)別方法,通過(guò)構(gòu)建一個(gè)結(jié)合連續(xù)的語(yǔ)義特征和離散的主題特征的CNN作為微博文本分類(lèi)器,對(duì)用戶(hù)的微博進(jìn)行興趣分類(lèi),通過(guò)極大似然估計(jì)得到微博用戶(hù)的興趣.在400個(gè)微博用戶(hù)的測(cè)試集上,與Labeled LDA、使用詞向量的CNN和線(xiàn)性SVM這3種興趣識(shí)別方法進(jìn)行了比較,取得了最佳效果,準(zhǔn)確率到達(dá)了91.25%.實(shí)驗(yàn)結(jié)果將連續(xù)的語(yǔ)義特征和離散的主題特征結(jié)合將顯著提高用戶(hù)興趣識(shí)別的效果.
[1] Ramage D, Dumais S T, Liebling D J. Characterizing microblogs with topic models[C] //Proc of Int Conf on Weblogs & Social Media. Menlo Park, CA: AAAI, 2010: 130-137
[2] Ramage D, Hall D, Nallapati R, et al. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora[C] //Proc of Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2009: 248-256
[3] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022
[4] Schmidhuber J, Meier U, Ciresan D. Multi-column deep neural networks for image classification[C] //Proc of IEEE Conf on Computer Vision & Pattern Recognition. Piscataway, NJ: IEEE, 2012: 3642-3649
[5] An D, Meier U, Masci J. Flexible, high performance convolutional neural networks for image classification[C] //Proc of the Int Joint Conf on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 2011: 1237-1242
[6] Ji Shuiwang, Xu Wei, Yang Ming. 3D convolutional neural networks for human action recognition[J]. IEEE Trans on Pattern Analysis & Machine Intelligence, 2013, 35(1): 221-231
[7] Yih W T, He Xiaodong, Meek C. Semantic parsing for single-relation question answering[C] //Proc of Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 643-648
[8] Shen Yelong, He Xiaodong, Gao Jianfeng, et al. Learning semantic representations using convolutional neural networks for Web search[C] //Proc of Int Conf on World Wide Web Companion. New York: ACM, 2014: 373-374
[9] Kalchbrenner N, Grefenstette E, Blunsom P. A convolu-tional neural network for modelling sentences[OL]. 2014[2016-04-10]. https://arxiv.org/abs/1404.2188
[10] Kim Y. Convolutional neural networks for sentence classification[J/OL]. 2014 [2016-04-10]. https://arxiv.org/abs/1408.5882
[11] Xu Wei, Zhang Yu, Xie Yubin, et al. User interest recognition based on microblog classification[J]. Intelligent Computer and Applications, 2013, 3(4): 80-83 (in Chinese)
(宋巍, 張宇, 謝毓彬, 等. 基于微博分類(lèi)的用戶(hù)興趣識(shí)別[J]. 智能計(jì)算機(jī)與應(yīng)用, 2013, 3(4): 80-83)
[12] Li Jingyang, Sun Maosong, Zhang Xian. A comparison and semi-quantitative analysis of words and character-bigrams as features in Chinese text categorization [C] //Proc of the 21st Int Conf on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2006: 545-552
[13] Michelson M, Macskassy S A. Discovering users’ topics of interest on Twitter: A first look[C] //Proc of the Workshop on Analytics for Noisy Unstructured Text Data. New York: ACM, 2010: 73-80
[14] Zhao Xin, Jiang Jing, Weng Jianshu, et al. Comparing Twitter and traditional media using topic models[G] //LNCS 6611: Advances in Information Retrieval. Berlin: Springer, 2011: 338-349
[15] Xu Zhiheng, Ru Long, Xiang Liang, et al. Discovering user interest on Twitter with a modified author-topic model[C] //Proc of IEEE/WIC/ACM Int Conf on Web Intelligence. New York: ACM, 2011: 422-429
[16] Sasaki K, Yoshikawa T, Furuhashi T. Twitter-TTM: An efficient online topic modeling for Twitter considering dynamics of user interests and topic trends[C] //Proc of Int Symp on Soft Computing and Intelligent Systems. Piscataway, NJ: IEEE, 2014: 440-445
[17] Guo Hongjian, Chen Yifei. User interest detecting by text mining technology for microblog platform[J]. Arabian Journal for Science & Engineering, 2016, 41(8): 3177-3186
[18] Abel F, Gao Qi, Houben G J, et al. Analyzing temporal dynamics in Twitter profiles for personalized recommenda-tions in the social Web[C] //Proc of Int Web Science Conf. New York: ACM, 2011: 1-8
[19] Jin Xin, Wang Chi, Luo Jiebo, et al. LikeMiner: A system for mining the power of ‘like’ in social media networks[C] //Proc of ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2012: 753-756
[20] Orlandi F, Breslin J, Passant A. Aggregated, interoperable and multi-domain user profiles for the social Web[C] //Proc of Int Conf on Semantic Systems. New York: ACM, 2012: 41-48
[21] Wang J, Zhao W X, He Y, et al. Infer user interests via link structure regularization[J]. ACM Trans on Intelligent Systems & Technology, 2014, 5(2): 1-22
[22] Vosecky J, Leung W T, Ng W. Collaborative personalized Twitter search with topic-language models[C] //Proc of Special Interest Group on Information Retrieval. New York: ACM, 2014: 53-62
[23] Bhattacharya P, Zafar M B, Ganguly N, et al. Inferring user interests in the Twitter social network[C] //Proc of the 8th ACM Conf on Recommender Systems.New York: ACM, 2014: 357-360
[24] Zhao Zhe, Cheng Zhiyuan, Hong Lichan, et al. Improving user topic interest profiles by behavior factorization[C] //Proc of Int Conf on World Wide Web. New York: ACM, 2015: 1406-1416
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
商用汽車(chē)(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(chē)(2016年6期)2016-06-29 09:18:54
