基于建構主義學習理論的個性化知識推薦模型
2018-01-12 07:20:02謝振平
計算機研究與發展 2018年1期
謝振平 金 晨 劉 淵
(江南大學數字媒體學院 江蘇無錫 214122)
(江蘇省媒體設計與軟件技術重點實驗室(江南大學) 江蘇無錫 214122)
(xiezhenping@hotmail.com)
近年來,隨著無線網絡和移動寬帶互聯網的快速發展,以及成熟的便攜式移動設備的大量涌現,在線學習已越來越成為一種重要的知識學習方式[1-2].在線學習具有學習資源廣泛、資源更新及時、學習方式便捷等特點.然而互聯網上的海量學習資源在給用戶帶來便捷學習的同時也造成了“認知過載”、“知識碎片化”等困惑[3].如何幫助不同學習者從海量的學習資源中找到個體所需的資源已成為一個巨大的挑戰,在其中引入個性化推薦技術是一個必然的選擇[3-10].
傳統個性化推薦的主要目標是通過分析用戶信息和項目信息,獲取用戶興趣偏好,從而為用戶推薦感興趣的項目,主要技術包括基于內容的推薦[11-12]、協同過濾推薦[13]、基于規則的推薦[14-15]等.這些技術在電子商務和社交媒體領域具有較高的適用性,并已取得了大量的成功應用;但在個性化知識推薦學習方面,相關研究與應用還較少,而直接使用現有推薦算法將面臨2個問題:
1) 推薦產生的知識序列缺乏連續性.分析人類知識學習過程可知,較好的系統性和連續性是個性化知識學習序列的基本要求,而現有的推薦方法在每次推薦新項目時通常考慮為獨立的過程,對于推薦結果序列的系統性和連續性較少關注.
2) 知識需求分析片面化.個性化知識推薦的目的是幫助用戶學習新知識,彌補知識缺陷,知識需求分析應主要依據用戶當前知識水平和目標知識體系.現有個性化推薦方法在分析用戶推薦需求時,缺少這方面的考慮,難以充分挖掘用戶的實際知識需求.
另一方面,建構主義學習理論[16-17]認為,人類知識學習本質上是一個知識建構過程,個體通過自身原有的知識經驗建構生成新的知識;如用戶在學習了知識A,B,C的基礎上能夠根據三者的內在邏輯結構建構理解新知識D.為此,本文提出一種基于建構學習理論的個性化知識推薦模型——建構推薦模型.建構推薦模型采用知識網絡建模用戶所需的知識系統,基于知識網絡的邊信息存儲知識間的建構關系,據此結合用戶已學知識內容,引入支撐度最大優先的隨機游走推薦算法,連續地推薦產生最佳知識學習序列.
1 背景技術
1.1 個性化推薦
基于內容的推薦[11-12](content-based recomm-endation, CBR)是最早被提出的一種推薦技術,算法通常包括3個步驟:1)為資源庫中每一個資源抽取特征項作為資源特征;2)分析用戶過去喜好的資源,從中學習出這些資源的特征作為用戶喜好特征;3)通過計算用戶喜好特征和候選資源特征的相似度,為用戶推薦相似度高的一組資源.CBR算法的優點是準確度高,不依賴大量的用戶群,新資源不存在冷啟動問題;缺點是特征抽取困難,局限于文本資源的推薦,并且很難挖掘用戶潛在興趣.
協同過濾推薦[13](collaborative filtering reco-mmendation, CFR)通常分為2類:基于用戶的協同過濾[18-20](user-based collaborative filtering, UBCF)和基于項目的協同過濾[21-22](item-based collaborative filtering, IBCF).基于用戶的協同過濾首先尋找與目標用戶有相似興趣的用戶,然后根據相似用戶對項目的評分來預測目標用戶對未知項目的評分,將評分高的項目推薦給目標用戶.基于項目的協同過濾則是根據用戶對項目的評分數據來分析項目之間的相似性,并將那些與用戶之前喜歡的項目相似度高的項目推薦給用戶.CFR算法的優點是適用性廣,主要依據用戶對資源的評分,與資源的形式無關,因此理論上CFR算法適用于任何資源的推薦.協同過濾推薦的缺點也很明顯,由于過分依賴用戶評分數據,導致新資源和新用戶存在冷啟動問題,并且通常用戶評分項目較少,導致用戶評分矩陣稀疏,造成相似性計算誤差大,影響最終推薦的準確度.
關聯規則的推薦[14-15](rule-based recommen-dation, RBR)關鍵在于挖掘不同資源項之間可能存在的價值關聯項,然后基于已有的關聯規則為用戶推薦可能感興趣的資源.關聯規則的挖掘一般分為2個步驟:1)通過分析用戶與資源項之間的歷史數據生成所有的頻繁項集;2)通過計算支持度、置信度、提升度來提取強關聯規則.RBR算法的主要不足之處在于:規則制定費時費力,規則一旦生成不能自動更新.
1.2 建構主義學習理論
建構主義[16-17]源自瑞士著名心理學家皮亞杰(Jean Piaget)創立的關于兒童認知發展理論,他堅持從內因和外因相互作用的觀點來研究兒童認知發展,他認為兒童是通過與周圍環境的不斷相互作用來逐步建構對外部環境的認識.他提出,知識并非單純地來自主體或者客體,而是在雙方相互作用的過程中生成的.主體獲得新經驗需要自身原有的經驗基礎,而新經驗的獲得又能使原有經驗得到更新和完善.從這一角度看,人類學習的本質是一個主動建構知識的過程,而不是被動地接受信息的過程.
明顯地,個性化知識推薦服務目標與建構主義學習理論有著天然的本質聯系,后者應能較好地指導個性化知識推薦方法的設計實現,使得用戶能更輕松且高效地獲得新知識.

Fig. 2 Term extraction process圖2 術語抽取流程
2 模型框架
本文將建構主義學習理論引入到知識推薦系統中,提出一種新的個性化知識推薦方法——建構推薦模型,其中主要考慮2個問題:1)如何表示用戶當前知識經驗;2)如何基于已有的知識經驗推出下一時刻最適合建構學習的新知識.本文考慮基于知識網絡圖覆蓋的形式幫助用戶逐步建構學習來完善自身的知識,并提出知識的可學習支撐度來評估用戶對新知識的可學習建構優先級.
設計考慮的建構推薦模型如圖1所示,主要由2部分構成:知識網絡模塊和建構推薦模塊.知識網絡[23-24]是一個具有節點間互聯關系的知識環境,節點代表知識單元,邊表示知識單元之間的相關關系.知識網絡的構建包括:知識術語抽取、詞向量模型以及通過語義距離的約束生成知識網絡.這樣,用戶知識背景可認為是知識網絡的一個子結構,表示用戶已學習的知識子系統.模型框架的另一個核心是建構推薦模塊,主要任務是通過知識網絡建立用戶已有知識與需求知識間的邏輯關聯,并分析用戶知識需求,為用戶推薦最具建構學習價值的新知識.

Fig. 1 Framework of the proposed constructive recommendation model圖1 建構推薦模型框架
2.1 知識網絡模塊
建構推薦模型的知識網絡構建過程包含3個步驟:1)通過術語抽取技術自動識別領域知識術語;2)采用詞向量工具為每個知識術語訓練生成一個實數向量;3)通過獲取的實數向量計算知識術語之間的語義關系,從而建立知識之間的結構關聯.
2.1.1 知識術語抽取
知識術語抽取的主要任務是從特定領域的文本語料中自動識別完整獨立的知識術語,每一個知識術語表示一個知識概念.知識術語抽取具體流程如圖2所示:首先獲取特定領域的一定量的文本語料,通過分詞、去除停用詞進行語料預處理,將預處理的字串重新組合生成候選術語;然后通過信息熵和詞頻分布篩選候選術語[25].其中,信息熵[26]用于計算候選術語在語料中左右邊界的穩定性,以判斷相應術語的獨立成詞程度;詞頻分布通過計算候選術語的詞頻來區分普通詞和領域術語,通常地,領域術語在相關領域出現的頻率較高,在不相關領域出現的頻率較低[25].實際中,可結合信息熵和詞頻為每個候選術語生成一個綜合權重,按權重大小排序,選取權重大的前T個候選術語作為最終知識術語.
2.1.2 詞向量模型
詞向量模型是神經網絡在自然語言處理領域應用的產物,最早由Hinton于1986年提出.詞向量的核心思想是通過文本語料訓練,將每個詞映射成一個高維的實數向量,然后通過計算向量之間的距離可直觀描述詞與詞之間存在的語義關系.目前詞向量已經廣泛應用在文本情感分類[27]、情感新詞發現[28]、詞義消歧[29]等自然語言處理領域.
本文采用Word2Vec工具[30-32]訓練詞向量.Word2Vec中包含2個重要模型:CBOW模型和Skip-gram模型[30-31].這2個模型的區別在于:前者是在已知上下文的基礎上預測當前詞;而后者是在已知當前詞的基礎上預測上下文.每個模型均有2套框架,分別基于Hierarchical Softmax和Negative Sampling來設計實現.與Hierarchical Softmax相比,Negative Sampling不使用復雜的Huffman樹,而是利用相對簡單的隨機負采樣,能提高訓練速度并改善詞向量的質量.綜合地,本文采用基于Negative Sampling的CBOW模型來訓練詞向量.如圖3所示,CBOW模型包括輸入層、投影層和輸出層,工作原理是通過輸入上下文n個詞來預測當前詞Wt出現的概率.本文實驗中設置n=4,輸入經過術語識別的分詞語料,最終為每個術語訓練生成一個200維的實數向量.

Fig. 3 CBOW term vector model圖3 詞向量模型示意圖
2.1.3 知識網絡構建
基于獲得的每個知識術語所對應的詞向量,可通過詞向量間的數學運算來計算知識之間可能存在的知識關系,并將有效的知識關系進行存儲,最終建立一個完整的知識網絡.
建構推薦模型的知識網絡構建流程如圖4所示,知識網絡構建遵循近鄰優先原則,即知識庫中T個知識分別尋找語義距離最近的M個知識為其近鄰知識,并進行記憶存儲構成知識關系,則總的邊關系數量為T×M個.通常,M值太小會丟失必要的近鄰知識關系,降低知識網絡的整體連通性,無法有效表達目標知識系統;而M值過大只會增加知識網絡冗余度,并且增加推薦計算效率,對知識網絡的整體連通性提升價值有限.結合小世界網絡理論和實驗分析,本文考慮M=10.

Fig. 4 Knowledge network building process of constructive recommendation model圖4 建構推薦模型的知識網絡構建流程
圖5所示為一個建構推薦模型的知識網絡結構實例,圓點表示知識,有向邊表示近鄰知識關系.

Fig. 5 An example of knowledge network structure of constructive recommendation model圖5 建構推薦模型的知識網絡結構實例
上述方法構建的知識網絡具有3個特征:
1) 近鄰關系是單向的,即若b是a的近鄰知識,a不一定是b的近鄰知識.
2)a的所有近鄰知識總數為a的入度,近鄰知識包含a的知識總數為a的出度,任何一個知識節點的入度固定為M,出度則不固定.
3) 知識網絡中任意2個知識節點a,b間的連接關系有4種情況:兩者互為近鄰知識關系;兩者無直接近鄰關系;一方是另一方的近鄰知識,但反之則不是.
此外,一個良好的知識網絡在不考慮連接邊的方向性時應該具有較強的全連通性.
2.2 建構推薦模塊
建構推薦的主要任務是結合知識網絡分析用戶知識需求,從而為用戶生成語義連續的推薦序列.建構推薦模塊主要包括候選推薦知識提取和候選知識排序輸出2個部分.候選推薦知識考慮從最近學習知識序列的關聯知識中提取不超過N個的未學知識;候選知識排序輸出推薦引入支撐度指標作為排序量.為此,首先引入關于支撐知識的定義.
定義1. 知識支撐關系.設知識b與a存在近鄰關系,且設b是a的top-M近鄰,記作a←b,則稱b是a的支撐知識,也稱a是b的外延知識.
進一步,可設知識a的所有支撐知識構成的集合為a的支撐知識集,記為Sa.如圖6所示,知識t的支撐知識集為St.

Fig. 6 An example of knowledge network substructure圖6 知識網絡子結構示例
進一步引入支撐度概念,表示用戶當前已學知識對新知識的直接可建構程度.例如“營養素”的支撐知識集為“蛋白質”、“脂肪”、“碳水化合物”、“維生素”、“纖維素”等,用戶對支撐知識的掌握體現了建構理解“營養素”的能力,本文引入支撐度概念量化描述這種能力.任一知識t相對于用戶當前狀態的支撐度記為Wsp(t),具體定義如下:

(1)

(2)

3 模型實現
3.1 建構主義推薦策略
建構主義學習理論的核心在于建構認知,學習者通過已掌握知識建構獲得新知識.相應地,引入如圖7所示的建構推薦策略.同樣地,圖7中實心圓點表示已學知識,線條圓點表示候選知識,空心圓點表示其他知識;實線表示已經建構的知識關系,虛線表示未建構學習的知識關系.
圖7(a)表示一次知識推薦的開始狀態,圖7(b)(c)(d)分別表示候選推薦知識選擇、候選知識推薦排序以及推薦知識學習后的更新結果.圖7(a)中有2個知識為已學知識,其他均為未學知識,它們之間基于知識網絡關系構成一個整體.
如圖7(b)所示,候選推薦知識選擇考慮從已學知識的直接相關但還未學的知識中選取,其中直接相關知識包括支撐知識和外延知識.候選知識選擇按2個優先次序進行選取:最近學習知識的關聯知識為第1優先選擇,而同一已學知識的不同關聯知識則按最短距離優先選擇.同時考慮實際應用需要,引入最大候選知識容量參數N,即每次按上述方法選擇的最大候選知識項數不超過N.
如圖7(c)所示,候選知識推薦排序對所有已選擇的候選知識項按未學知識的支撐度從大到小排序,并優先推薦給出支撐度較大的候選項作為推薦結果.不失一般性,可考慮推薦結果為排序結果的top-K輸出,即輸出排序靠前的K個候選知識項作為推薦選項,供用戶選擇.
最后,如圖7(d)所示,用戶選擇一個推薦項(圖中為用戶選擇了排序第1的知識項)進行學習后形成了新的已學知識狀態(同圖7(a)相似的狀態結構).

Fig. 7 The diagram of constructive recommendation strategy圖7 建構推薦策略過程示意圖
3.2 建構推薦算法描述
基于上述建構主義推薦策略,進一步對建構推薦算法過程進行具體描述.算法輸入為用戶初始背景知識,然后連續地推薦給出用戶最具學習價值的top-K個學習知識項,用戶選擇其中一個知識學習后形成新的背景知識,如此不斷迭代,用戶知識得到漸進增長.
算法1. 個性化知識學習的建構推薦算法.
輸入:用戶初始背景知識U={t1,t2,…,tL}.
過程:
①Cn={c,Wsp|Cn=?},i=1;
② while |Cn| ③C=getCandNeib(ti); ④ ifisempty(C)==TRUE then ⑤i=i+1; ⑥ else ⑦ 根據式(1)計算Wsp(c)|c∈C,addToCn(c,Wsp(c)),i=i+1; ⑧ end if ⑨ end while ⑩ 根據支撐度Wsp對Cn降序排序; 算法1中,Cn={c,Wsp}表示當前候選知識項集合,getCandNeib()表示獲取某個知識節點的未學習且不在Cn中的最近直接相關知識(包括支撐知識和外延知識),addToCn()表示將一個新的候選知識和相應的支撐度值構成的元素項加入當前候選知識項集合Cn,步驟⑩中的排序操作表示對Cn中的項按每個項的支撐度值從大到小排序. 在建構推薦模型中,若將模型中的候選項排序指標“支撐度最大優先”替換為“距離最小優先”,則相應的模型將等價于某種基于內容的個性化推薦模型.由此,知識網絡上的基于內容相似的個性化推薦模型同樣可直接用于個性化學習知識推薦,本文也將此方法作為參照,在實驗研究中進行比較分析.另一方面,相比于協同過濾推薦算法,建構推薦模型由于直接基于知識網絡進行用戶知識需求分析,避免了冷啟動問題和用戶歷史數據稀疏的問題. 進一步分析本文中模型的復雜度.假設在建構推薦算法中,已學習知識數為T,候選知識項集合容量為N,則算法主要時間復雜度體現在步驟③和步驟⑦,每執行1次語句認為檢索1次數據庫,步驟③表示獲取某個知識節點未學習的最近直接相關知識,最大循環次數為T,步驟⑦表示計算候選知識支撐度,最大循環次數為N,則算法的時間復雜度可表示為O(T+N).相對地,最大相似度優先排序推薦算法與建構推薦算法相比無需執行步驟⑦,則時間復雜度應為O(T).雖然如此,通常在檢索產生N個候選樣本時,所需的實際檢索次數要遠小于T,本文實驗部分顯示的結果為大部分情況下均小于5.如此,檢索計算復雜度分別約為O(5+N)和O(5),新算法的計算復雜度同樣是實用可接受的. 此外,雖然與電子商務和社交網絡中的傳統個性化推薦目標具有較大差別,但個性化知識推薦的核心需求仍是發現并給出用戶最需要的信息內容.本文受建構主義學習理論啟發,提出的建構推薦模型給出了一種思想上直觀、算法上可行的新型個性化推薦方法,是對現有個性化推薦方法的有益補充,理論上也能拓展應用于傳統的電子商務和社交網絡領域. 考慮個性化知識推薦的特點及當前研究現狀,本文考慮以飲食健康知識學習為實驗對象,對建構推薦模型進行性能分析. 1) 我們使用八爪魚采集器*http://www.bazhuayu.com/從中國食品科技網*http://www.tech-food.com/和39健康網*http://food.39.net/抓取“健康知識”、“膳食營養”、“飲食誤區”等主題的14 600篇飲食相關科普文章,共計約2 000萬字,作為語料素材.經過語料預處理和術語抽取技術識別獲得1 000條飲食知識術語,部分術語抽取結果如表1所示,其中綜合權重為2.1.1節中所述的基于信息熵和詞頻生成的術語權重. Table 1 Part of Healthy Diets Knowledge Terms表1 獲取的部分健康飲食術語 2) 利用抽取的知識術語篩選文本語料,去除不包含知識術語的句子,用經過篩選的文本語料訓練得到知識術語詞向量,并通過計算知識術語間的歐氏距離作為不同術語詞間的語義距離.表2給出了部分健康飲食知識術語間的語義距離值.直觀分析可以發現,“牛奶”與“豆奶”、“奶制品”的語義距離明顯小于與“水果”、“蔬菜”的語義距離,這一結果與術語的實際語義相一致,也表明本文所訓練生成的健康飲食知識術語詞向量具有較高的合理性. Table 2 Semantic Distance of Some Healthy Diet Knowledge Terms 3) 基于建構推薦模型的知識網絡構建方法生成含有1 000個健康飲食知識術語的知識網絡,圖8給出了相應的知識網絡中語義距離的分布情況,距離值主要落在區間[0.0312,3.1215]內,分布形狀呈現一定的規則性. Fig. 8 Semantic distance distribution among network nodes of our knowledge network圖8 知識網絡節點間語義距離分布 為了對比研究建構推薦模型的性能,我們引入基于最大相似度優先排序的推薦Similarity_Rec方法和隨機推薦Random_Rec方法作為參照,類似地記建構推薦方法為Support_Rec.基于最大相似度優先排序的推薦指候選推薦知識按相似度最大優先排序,選擇相似度最大的top-K個知識作為推薦輸出.隨機推薦指每次從候選推薦知識中等概率隨機選擇K個知識作為推薦輸出. 從個性化知識推薦的目標需求出發,我們引入學習效率和學習知識序列關聯度2個性能指標.學習效率表示用戶在連續選擇學習一段時間后,學習獲得的總知識量與學習的知識數間的相對比值.在學習相同個數的知識前提下,學習獲得的知識量越多則學習效率越高.學習知識序列關聯度表示用戶在推薦給出的學習知識中連續選擇的知識間的相關程度,基于學習的一般認知,學習知識序列間的相關程度越高則越有利于新知識的快速掌握. 為此,首先引入知識網絡上的知識量定義. 定義2. 一個知識網絡或其一個子網絡的知識量由2部分構成:知識節點的自身知識量以及知識節點間的關系知識量,其中記知識節點a的知識量為KI(a),知識節點a與b間的關聯知識量為KI(a,b),具體定義如下: 1)KI(a)根據知識內涵先驗給出(本文研究中默認取KI(a)=1); 2) 若a與b間存在直接近鄰關系,即其中至少有一個知識節點為另一個知識節點的支撐知識,則KI(a,b)由式(3)定義,否則KI(a,b)=0. (3) 其中,dab表示a與b間語義距離;尺度參數σ與式(2)中定義相同,且可取相同值,本文研究中經實驗比較均取σ=1.上述定義在考慮知識系統的總知識量時,不僅關注知識本體的知識量,也關注知識間的語義關系知識價值.其中,2個語義距離較近的直接相關聯知識節點間的關系知識量較小,即若兩者的信息差異度小,則建構形成的關系知識量也小. 基于定義2,可對知識網絡中的任意已學知識子網給出學習效率定義: (4) 其中,Ucur={t1,t2,…,tL}表示已學知識子網的知識節點集,Uall為整體知識網絡所含的知識節點集,KIall為整個知識子網的總知識量,有: (5) 根據上述學習效率定義,個體在學習某個知識系統的過程中所選擇的不同知識學習序列將對應不同的學習效率.而在現實學習中,我們通常希望高效快速地掌握一個知識系統的信息內涵,即通過學習有限個節點知識,掌握知識系統中較多的知識信息.例如給定2個知識序列,序列1:“蘋果、香蕉、西瓜、桃子、柑橘、獼猴桃、葡萄、草莓”;序列2:“蘋果、香蕉、西瓜、西紅柿、紅薯、黃瓜、青椒、胡蘿卜”.序列1中所有知識都圍繞水果主題;序列2中“蘋果、香蕉、西瓜”屬于水果,“西紅柿、紅薯、黃瓜”是介于水果和蔬菜之間的食物,“青椒、胡蘿卜”屬于蔬菜.雖然2個學習序列推薦了相同數量的知識,序列2的知識量顯然更多.根據式(4)的學習效率公式定義,較高的學習效率值也表示個體在學習等量的知識數后獲得了更高的知識量,兩者具有良好的一致性.這也表明,我們引入的學習效率性能指標具有較好的合理性. 進一步,對最新學習的知識t,引入學習知識序列關聯度定義: (6) 其中,Vt表示最近歷史學習的知識集,即學習t之前最近學習的一定數量的知識,本文取最近的前5條歷史知識;Ic(t,s)為t與s間是否存在直接關聯(存在t←s或s←t)的指示函數,是則Ic(t,s)=1,否則Ic(t,s)=0;函數Sim()定義同式(2). 綜合地,上面引入的學習效率和學習知識序列關聯度計算直接取決于已完成的知識學習歷史以及目標學習知識系統.此外,由于推薦算法不同而產生的任一不同知識學習過程點均可對應求得相應的學習效率和平均學習知識序列關聯度,據此可定量地評價不同個性化知識推薦方法的性能. 建構推薦模型有N和K兩個模型參數需要初始設定,分別表示每次推薦時選取的候選知識容量上限和推薦輸出時給出的用戶可選的知識項數.首先考慮取K=1,即每次只推薦輸出排序最高的1個候選知識項時,N在不同取值下3種對比算法的推薦性能情況.表3,4給出了相應的一組實驗結果,分別顯示了學習效率和學習知識序列關聯度.實驗中,N分別取10,20,30和不限(Inf),每次隨機選取1個初始知識,然后進行連續推薦模擬.表3中實驗結果為20次模擬的平均結果及相應的標準差.為了更直觀地表示,表3中不同已學知識比例時的學習效率值直接用已學知識量的比例間接表示. Table 3 Learning Efficiency Values Obtained by Three Recommendation Algorithms on Different N with K=1 Fig. 9 Typical learning efficiency curves of compared recommendation algorithms圖9 不同推薦算法的典型學習效率變化曲線 分析表3中的學習效率值可知,在相同N取值下,建構推薦算法在學習完不同知識比例情況下均取得了更好的學習效率.相比較而言,隨機推薦方法的學習效率要略好于基于最大相似度優先排序的推薦方法Similarity_Rec.雖然如此,結合表4結果可以看出,隨機推薦Random_Rec的平均學習知識序列關聯度要低于Similarity_Rec.對比不同N取值下的學習效率結果可知,對于本文所構建的知識網絡,建構推薦算法在N=20時表現出了最佳的學習效率,而另外2種算法在N=20時也表現出了較佳水平的學習效率.而對比表4結果也可以發現,雖然N取值較小時,平均的學習知識序列關聯度會增加,但N=20時已與N=10時的最好結果相接近,但要明顯好于更大的N取值.為此,進一步的實驗中將考慮取N=20時,分析不同K取值下的推薦算法性能. Table4KnowledgeSequenceCorrelationValuesObtainedbyThreeRecommendationAlgorithmsonDifferentN 表4不同N下的3種推薦算法的學習知識序列關聯度比較 NSupport_RecSimilarity_RecRandom_Rec100.830.700.66200.820.690.59300.760.660.51Inf0.610.100.08 綜合地,3種對比推薦算法中,建構推薦方法不僅具有更優的學習效率,且學習知識序列間的平均關聯度也較高,更符合用戶學習新知識的需要.圖9給出了一個典型情況下不同推薦算法隨著推薦知識增加的學習效率相對值變化曲線;圖10給出了相應的學習知識序列關聯度變化曲線,為了清晰展示不同曲線之間的差異,我們將原始知識關聯度數據進行約簡,每隔10個數據取1個平均值,圖10每條曲線實際展示了100個數據點. Fig.10 Typical value tendency curves of knowledge sequence correlation obtained by compared recommendation algorithms圖10 不同推薦算法的典型學習知識序列關聯度變化趨勢曲線 如圖9直觀顯示,3條變化曲線中,支撐度最大優先的建構推薦方法在學習等量的知識節點后,所獲得的知識量比例要高于另2種方法;而圖10中對應的知識序列關聯度變化曲線則表明,支撐度最大優先的建模推薦方法在學習經過一段時間后,學習知識序列間的關聯度開始增強,并明顯高于另2種方法.相對地,隨機推薦方法的學習知識序列關聯度從開始到結束無明顯變化,這一結果與經驗邏輯結果相一致,也間接表明了本文所定義的相關評價指標的合理性.對于相似度最近優先的推薦方法,其生成的學習知識序列關聯度開始較高,但隨后則表現不佳.這一結果表明:相似度最近優先的推薦方法在學習知識序列產生過程中,不能很好地兼顧知識系統的整體需求,每次過于簡單地選擇最相似的候選知識并非是一個有效的學習方式.這一結論可能也將有助于進一步發展傳統電子商務和社交網絡的個性化推薦技術,特別是基于內容相似性優先的推薦策略存在一定的局限性.而基于支撐度最大優先的建構推薦策略則可以提供一些非常有價值的思想借鑒. 進一步,我們考慮top-K推薦輸出策略中不同K值對算法性能的影響,根據前面實驗結果,固定平均最佳候選知識容量N=20.與上述實驗過程稍微不同,考慮每次為用戶輸出K個推薦知識項時,模擬用戶均勻隨機地選擇一個知識進行學習,這樣相同的初始背景知識也會產生非常多不同可能的學習知識序列.為此,實驗中對于同一初始知識模擬10次不同結果,同時隨機選擇了20個健康飲食知識術語作為初始背景知識.表5給出了相應的實驗結果,其中性能值為200次模擬運行的統計結果,隨機選擇的20個初始知識為:低熱量飲食、檳榔、柑橘、紫菜、羊肉串、辣味食物、山芋、牛奶、菊花茶、菌類、全谷物、酒釀、紅棗、高鹽食品、山銀花、西瓜、菜子油、抗癌食品、牛排、蘋果. 表5給出了Support_Rec和Similarity_Rec這2種算法的學習效率度量值.顯然地,對于Random_Rec,在上述模擬實驗中,不同K值在理論上是等價的,所以表5中沒有給出重復對比結果.同時K=1時,相應的結果即如表3結果所示.此外,實驗中考慮實際應用中,不給用戶造成過多的選擇障礙,K取值考慮在相對不大的個位數范圍內. Table 5 Learning Efficiency Values Obtained by Three Recommendation Algorithms on Different K with N=20 分析表5結果可知,對于Support_Rec,其隨著K值增大,性能會有所下降,而K=3與K=1時的性能結果相近.而對于Similarity_Rec,K值增大時,性能結果僅有微小的變化,據此,我們可以考慮在實際應用中取K=3.這樣,既給用戶提供了一定的個性化選擇空間,又保證了用戶學習知識序列的高效性.同樣地,橫向比較看,基于支撐最大優先的推薦方法在不同K值條件下仍具有顯著的學習效率優勢.進一步顯示了本文提出的新模型的有益價值. 進一步,我們對不同算法推薦產生的知識術語實例序列進行研究分析,表6、表7給出了2組典型的模擬實驗結果,其中N=20,K=3,初始知識分別選取了較為常見的知識概念“蘋果”和“牛奶”. Table 6 Knowledge Sequence Example 1 Generated by Compared Recommendation Algorithms Table 7 Knowledge Sequence Example 2 Generated by Compared Recommendation Algorithms 從人工語義理解的角度分析表6、表7中術語知識可知,支撐度最大優先的建構推薦方法所產生的推薦知識序列的整體層次性和連續性要顯著優先其他2種方法.如表6中結果所示,Support_Rec產生的推薦知識序列首先從“蘋果”到“柑橘”一直圍繞“水果”主題,然后從“新鮮蔬菜”和“綠葉蔬菜”開始推薦“蔬菜類”知識.如表7中結果所示,Support_Rec產生的推薦知識序列首先“牛奶”到“奶油”都與“奶類”密切相關,然后從“白砂糖”到“糖精”屬于“糖類”相關知識,最后從“味精”到“沙拉醬”都屬于“調味品”.由此可見,Support_Rec產生的推薦知識序列在局部確實具有很強的關聯性,而當用戶對某一小類知識掌握到一定程度后又會有效地轉移推薦其他大類相關的節點知識.例如從“水果”到“蔬菜”、從“奶類”到“糖類”再到“調味品”.上述實驗結果確實是令人驚奇的,也進一步表明了本文所述建構推薦模型的有效性. 相比而言,其他2種對比方法所產生的推薦知識序列在人工語義角度不能找到明顯的層次性和連續性,序列知識間的語義跳躍性很大.從這一角度看,本文提出的支撐度最大優先的建構推薦過程能較好地契合人類知識的有序漸進理解過程,也將能有效地支持用戶的個性化知識學習,具有較高的實用價值. 為了進一步分析模型的實際推薦效果,我們邀請20位學生用戶開展了模擬實驗分析.實驗中由用戶自己設置初始知識,用戶每次從系統推薦的3個知識中選擇1個進行學習.結合前面實驗結果,我們主要模擬分析了N=20和K=3時Support_Rec和Similarity_Rec這2種算法的推薦性能和算法復雜度,實驗結果如表8和表9所示.對比表5和表8結果可知,真實用戶模擬測試結果與隨機模擬結果高度一致, 進一步顯示了本文模型的有效性和實用性. Table 8 Learning Efficiency Values Obtained by Two Recommendation Algorithms Table 9 Computational Efficiency Values Obtained by Two Recommendation Algorithms with N=20 and K=3 從表9結果可知,大部分情況下Support_Rec算法平均檢索次數比Similarity_Rec高約20次,與N=20的設定相關聯.而具體的平均檢索次數值表明,產生N=20個候選樣本所需的檢索次數大部分情況下均小于5,而Support_Rec算法相比Similarity_Rec需要增加約N次的支撐度計算所需數據檢索,故檢索計算復雜度平均要稍高一些,但仍維持在不大的常數水平,能夠滿足實用要求.此外需要指出的是,當已學知識比例達到90%時,由于知識網絡中未學習知識數量較少,需檢索較多的已學知識才能產生足量的候選相關知識. 為更好地適應網絡資源知識的個性化學習需要,解決現有推薦技術沒有重點關注推薦內容的整體性和序列關聯性問題,研究提出了一種基于建構主義學習理論的個性化知識推薦新方法——建構推薦模型.新模型使用知識網絡建模所期望學習的目標知識系統,并提出知識網絡上的候選知識可學支撐度最大優先的推薦策略.本文理論與實驗結果表明了建構推薦模型的合理性和有效性,并可作為當前基于內容的推薦和協同推薦方法的有益補充,其不僅僅可簡單易行地應用于個性化知識推薦領域,也可為傳統電子商務和社交網絡中個性化推薦技術提供思想啟發.雖然如此,針對不同實際應用場景,構建最為合理的知識網絡系統是一個需要考慮的關鍵問題,而為了避免推薦算法相續產生高度相似的推薦項,考慮引入額外的知識概念語義分析也可進一步提升建構推薦算法的實用價值[33]. [1] Salehi M. Application of implicit and explicit attribute based collaborative filtering and BIDE for learning resource recommendation[J]. Data & Knowledge Engineering, 2013, 87(9): 130-145 [2] Manouselis N, Vuorikari R, Van Assche F. Collaborative recommendation of e-learning resources: An experimental investigation[J]. Journal of Computer Assisted Learning, 2010, 26(4): 227-242 [3] Chen Yibo. Personalized knowledge service key technology based on linked data and user ontology[D]. Wuhan: Wuhan University, 2012 (in Chinese) (陳毅波. 基于關聯數據和用戶本體的個性化知識服務關鍵技術研[D]. 武漢: 武漢大學, 2012) [4] Parveen R, Jaiswal A K, Kant V. E-learning recommenda-tion systems—A survey[J]. Int Journal of Engineering Research and Development, 2012, 4(12): 10-12 [5] Khribi M K, Jemni M, Nasraoui O. Automatic recommenda-tions for e-learning personalization based on Web usage mining techniques and information retrieval[C] //Proc of the 8th Int Conf on Advanced Learning Technologies. Pisacaway, NJ: IEEE, 2008: 241-245 [6] Sikka R, Dhankhar A, Rana C. A survey paper on e-learning recommender system[J]. International Journal of Computer Applications, 2012, 47(9): 27-30 [8] Zhao Liang, Hu Naijing, Zhang Shouzhi. Algorithm design for personalization recommendation systems[J]. Journal of Computer Research and Development, 2002, 39(8): 986-991 (in Chinese) (趙亮, 胡乃靜, 張守志. 個性化推薦算法設計[J]. 計算機研究與發展, 2002, 39(8): 986-991) [9] Huang Zhenhua, Zhang Jiawen, Tian Chunqi, et al. Survey on learning-to-rank based recommendation algorithms[J]. Journal of Software, 2016, 27(3): 691-713 (in Chinese) (黃震華, 張佳雯, 田春岐, 等. 基于排序學習的推薦算法研究綜述[J]. 軟件學報, 2016, 27(3): 691-713) [10] Gao Ming, Jin Cheqing, Qian Weining, et al. Real time and personalized recommendation on microblogging systems[J]. Chinese Journal of Computers, 2014, 37(4): 963-975 (in Chinese) (高明, 金澈清, 錢衛寧, 等. 面向微博系統的實時個性化推薦[J]. 計算機學報, 2014, 37(4): 963-975) [11] Pazzani M J, Billsus D. Content-Based Recommendation Systems[M]. Berlin: Springer, 2007: 325-341 [12] Ghauth K I, Abdullah N A. Learning materials recommendation using good learners’ ratings and content-based filtering[J]. Educational Technology Research and Development, 2010, 58(6): 711-727 [13] Leng Yajun, Lu Qing, Liang Changyong. Survy of recommendation based on collaborative filtering[J]. Pattern Recognition and Artificial Intelligence, 2014, 27(8): 720-734 (in Chinese) (冷亞軍, 陸青, 梁昌勇. 協同過濾推薦技術綜述[J]. 模式識別與人工智能, 2014, 27(8): 720-734) [14] Mobasher B, Dai Honghua, Luo Tao, et al. Effective personalization based on association rule discovery from Web usage data[C] //Proc of the 3rd Int Symp on Web Information and Data Management. New York: ACM, 2001: 9-15 [15] Lee C H, Kim Y H, Rhee P K. Web personalization expert with combining collaborative filtering and association rule mining technique[J]. Expert Systems with Applications, 2001, 21(3): 131-137 [16] Bodner G M. Constructivism: A theory of knowledge[J]. Journal of Chemical Education, 1985, 63(10): 873-878 [17] Siemens G. Connectivism: A learning theory for the digital age[J]. International Journal of Instructional Technology & Distance Learning, 2004, 2(s101): 3-10 [18] Zhao Zhidan, Shang Mingsheng. User-based collaborative-filtering recommendation algorithms on Hadoop[C] //Proc of the 3rd Int Conf on Knowledge Discovery and Data Mining, Pisacaway, NJ: IEEE, 2010: 478-481 [19] Rong Huigui, Huo Shengxu, Hu Chunhua, et al. User similarity-based collaborative filtering recommendation algorithm[J]. Journal on Communications, 2014, 35(2): 16-24 (in Chinese) (榮輝桂, 火生旭, 胡春華, 等. 基于用戶相似度的協同過濾推薦算法[J]. 通信學報, 2014, 35(2): 16-24) [20] Wang Peng, Wang Jingjing, Yu Nenghai. A kernel and user-based collaborative filtering recommendation algorithm[J]. Journal of Computer Research and Development, 2013, 50(7): 1444-1451 (in Chinese) (王鵬, 王晶晶, 俞能海. 基于核方法的User-Based協同過濾推薦算法[J]. 計算機研究與發展, 2013, 50(7): 1444-1451) [21] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C] //Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 285-295 [22] Deng Ailin, Zhu Yangyong, Shi Baile. A collaborative filtering recommendation algorithm based on item rating prediction[J]. Journal of Software, 2003, 14(9): 1621-1628 (in Chinese) (鄧愛林, 朱揚勇, 施伯樂. 基于項目評分預測的協同過濾推薦算法[J]. 軟件學報, 2003, 14(9): 1621-1628) [23] Liu Xiang, Ma Feicheng, Wang Xiaoguang. Formation and process model of knowledge networks[J]. System Engineering Theory and Practice, 2013, 33(7): 1836-1844 (in Chinese) (劉向, 馬費成, 王曉光. 知識網絡的結構及過程模型[J]. 系統工程理論與實踐, 2013, 33(7): 1836-1844) [24] Liu Zhiyuan, Sun Maosong, Lin Yankai, et al. Knowledge representation learning : A review[J]. Journal of Computer Research and Development, 2016, 53(2): 247-261 (in Chinese) (劉知遠, 孫茂松, 林衍凱, 等. 知識表示學習研究進展[J]. 計算機研究與發展, 2016, 53(2): 247-261) [25] Li Lishuang. The research of term and relation acquisition methods for domain ontology learning[D]. Dalian: Dalian University of Technology, 2013 (in Chinese) (李麗雙. 領域本體學習中術語及關系抽取方法的研究[D]. 大連: 大連理工大學, 2013) [26] Ren He, Zeng Juanfang. A Chinese word extraction algorithm based on information entropy[J]. Journal of Chinese Information Processing, 2006, 20(5): 40-43 (in Chinese) (任禾, 曾雋芳. 一種基于信息熵的中文高頻詞抽取算法[J]. 中文信息學報, 2006, 20(5): 40-43) [27] Zhang Dongwen, Xu Hua, Su Zengcai, et al. Chinese comments sentiment classification based on word2vec and SVMperf[J]. Expert Systems with Applications, 2015, 42(4): 1857-1863 [28] Yang Yang, Liu Longfei, Wei Xianhui, et al. New methods for extracting emotional words based on distributed representation of words[J]. Journal of Shandong University: Natural Science, 2014, 49(11): 51-58 (in Chinese) (楊陽, 劉龍飛, 魏現輝,等. 基于詞向量的情感新詞發現方法[J]. 山東大學學報:理學版, 2014, 49(11): 51-58) [29] Tang Gongbo, Yu Dong, Xun Endong. An unsupervised word sense disambiguation method based on sememe vector in HowNet[J]. Journal of Chinese Information Processing, 2015, 29(6): 23-29 (in Chinese) (唐共波, 于東, 荀恩東. 基于知網義原詞向量表示的無監督詞義消歧方法[J]. 中文信息學報, 2015, 29(6): 23-29) [30] Mikolov T, Chen Kai, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL]. Ithaca, NY: Cornell University Library, 2013[2013-09-07]. https://arxiv.org/abs/1301.3781 [31] Mikolov T, Yih W, Zweig G. Linguistic regularities in continuous space word representations[C/OL] // Proc of the 2013 North American Chapter of ACL on Human Language Technologies. Atlanta, Georgia, USA: The Association for Computational Linguistics, 2013: 746-751.[2016-03-15]. http://www.aclweb.org/anthology/N13-1090 [32] Mikolov T, Sutskever I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality [C/OL] //Proc of the 2013 Int Conf on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS Foundation Inc, 2013: 3111-3119.[2016-03-15].http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf [33] Li Pohan, He Zhenying, Xiang Helin. A linkage clustering based query expansion algorithm[J]. Journal of Computer Research and Development, 2011, 48(Suppl 2): 197-204 (in Chinese) (李珀瀚, 何震瀛, 向河林. 一種基于鏈接聚類的查詢擴展算法[J]. 計算機研究與發展, 2011, 48(增刊2): 197-204)3.3 分析討論
4 實驗研究
4.1 實驗方案



4.2 評價指標


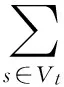
4.3 實驗結果與分析





4.4 模擬推薦實例分析


4.5 真實用戶模擬實驗


5 結束語

猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
阿來研究(2021年1期)2021-07-31 07:38:26
新世紀智能(高一語文)(2020年9期)2021-01-04 00:42:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
幼兒教育·父母孩子版(2016年12期)2017-05-24 13:11:53
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
