文本情緒分析綜述
2018-01-12 07:19:42林海倫王偉平
計(jì)算機(jī)研究與發(fā)展 2018年1期
李 然 林 政 林海倫 王偉平 孟 丹
1(信息內(nèi)容安全技術(shù)國(guó)家工程實(shí)驗(yàn)室(中國(guó)科學(xué)院信息工程研究所) 北京 100093)
2(中國(guó)科學(xué)院大學(xué)網(wǎng)絡(luò)空間安全學(xué)院 北京 100049)
(liran@iie.ac.cn)
隨著社交媒體的迅猛發(fā)展,Twitter、微博、MSN、微信等社交網(wǎng)絡(luò)正逐漸地改變著人們的生活.越來(lái)越多的人愿意在社交網(wǎng)絡(luò)上表達(dá)自己的態(tài)度和情感,而不僅僅是被動(dòng)地瀏覽和接收信息.對(duì)微博等文字中的情緒進(jìn)行分析可以使人們獲得更多關(guān)于內(nèi)心世界的知識(shí).因此,文本情緒分析技術(shù)可幫助研究機(jī)構(gòu)、信息咨詢組織和政府決策部門掌握社會(huì)情緒動(dòng)態(tài),這種需求極大地促進(jìn)了情緒分析技術(shù)的發(fā)展.
近年來(lái),文本情緒分析也漸漸引起了工業(yè)界和學(xué)術(shù)界的研究興趣.在早期的工作中,研究重點(diǎn)主要集中在基于正負(fù)類的情感分析和對(duì)情感文本進(jìn)行正面、負(fù)面、中性方面的分析.然而,基于二分類的情感分析難以充分表達(dá)人類復(fù)雜的內(nèi)心世界,不僅忽視了用戶所表達(dá)的細(xì)微情緒變化,同時(shí)也難以較全面地涵蓋用戶的心理狀態(tài),這都加速了對(duì)基于多分類的細(xì)粒度情緒分析的需求.
情緒分析又稱細(xì)粒度類別的情感分析,反之,情感分析也可以看作是二分類的情緒分析.情緒分析是在現(xiàn)有粗粒度的二分類分析工作的基礎(chǔ)上,從人類的心理學(xué)角度出發(fā),多維度地描述人的情緒態(tài)度.比如“卑劣”是個(gè)負(fù)面的詞語(yǔ),而它更精確的注釋是憎恨和厭惡.由于情緒分析對(duì)于快速掌握大眾情緒的走向、預(yù)測(cè)熱點(diǎn)事件甚至是民眾的需求都有很重要的作用.研究者們的研究重點(diǎn)也逐漸從單一的文本正負(fù)情感分析轉(zhuǎn)變?yōu)楦蛹?xì)粒度的情緒分析.
1 背景知識(shí)
情緒,是多種感覺(jué)、思想、行為綜合產(chǎn)生的生理和心理狀態(tài),是對(duì)外界刺激所產(chǎn)生的生理反應(yīng),如喜愛(ài)、悲傷、氣憤等.“情緒”在《辭海》中的定義為:從人對(duì)事物的態(tài)度中產(chǎn)生的體驗(yàn).與“情感”一詞常通用,但有區(qū)別.情緒與人的自然性需要相聯(lián)系,具有情景性、暫時(shí)性和明顯的外部表現(xiàn);情感與人的社會(huì)性需要相聯(lián)系,具有穩(wěn)定性、持久性,不一定有明顯的外部表現(xiàn).情感的產(chǎn)生伴隨著情緒反應(yīng),而情緒的變化也受情感的控制.通常能滿足人某種需要的對(duì)象,會(huì)引起正向的情緒體驗(yàn),如滿意、喜悅、愉快等;反之則引起負(fù)向的情緒體驗(yàn),如不滿、憂愁、恐懼等.因此也可以看出情感是多種情緒的綜合表現(xiàn),而情緒是情感的具體組成.因?yàn)榍榫w是人天性中的一個(gè)重要元素,所以它在心理學(xué)和行為科學(xué)中一直有著廣泛的研究.由于自然語(yǔ)言的復(fù)雜性和人類情緒的多變性、敏感性,不同領(lǐng)域的研究對(duì)情緒類別的劃分也有不小的差異.雖然目前學(xué)術(shù)界對(duì)情緒的分類還沒(méi)有達(dá)成共識(shí),但國(guó)內(nèi)外學(xué)者已經(jīng)對(duì)情緒分類做了較為深入的研究,并提出了不同的情緒集理論.
1.1 情緒分類理論
我國(guó)很早就開(kāi)始對(duì)情緒分類開(kāi)展研究,據(jù)《禮記》記載,人的情緒有“七情”的分法,即為喜怒哀懼愛(ài)惡欲;《白虎通》中情緒可以分為“六情”,即喜怒哀樂(lè)愛(ài)惡;在此基礎(chǔ)上,現(xiàn)代心理學(xué)家林傳鼎[1]根據(jù)《說(shuō)文》將情緒分為18類,即安靜、喜悅、撫愛(ài)、恨怒、驚駭、哀憐、恐懼、悲痛、慚愧、憂愁、忿急、煩悶、恭敬、憎惡、驕慢、貪欲、嫉妒、恥辱.
在現(xiàn)代心理學(xué)起源和繁盛的西方,研究者們對(duì)情緒集理論也有著豐富的成果.法國(guó)的哲學(xué)家笛卡兒(Descartes)在其著作《論情緒》中認(rèn)為,人的原始情緒分為詫異(surprise)、愛(ài)悅(happy)、憎惡(hate)、欲望(desire)、歡樂(lè)(joy)和悲哀(sorrow),其他的情緒都是這6種原始情緒的分支或者組合.此后,美國(guó)心理學(xué)家Ekman[2]提出一個(gè)基礎(chǔ)情緒理論,其認(rèn)為基本情緒包括高興(joy)、悲傷(sadness)、憤怒(anger)、恐懼(fear)、厭惡(disgust)和詫異(surprise),因?yàn)檫@6種情緒可以依靠面部表情和生理過(guò)程(如增加心率和流汗)辨別,所以這些情緒被認(rèn)為比其他的更基本.
在此基礎(chǔ)上,美國(guó)心理學(xué)家Plutchik[3]基于進(jìn)化規(guī)則的綜合理論,提出了一種多維度的情緒模型,模型定義了8種基本雙向情緒,包括Ekman的6種情緒以及信任(trust)、期望(anticipation).可以分為4對(duì)雙向組合:高興與悲傷(joy vs. sadness)、憤怒與恐懼(anger vs. fear)、信任與厭惡(trust vs. disgust)、詫異與期望(surprise vs. anticipation).圖1顯示了Plutchik模型的情緒類別在“情緒輪”上的排序,其中顏色的深淺代表這種情緒的飽和度,離圓心的遠(yuǎn)近代表情緒的強(qiáng)度.每種情緒都可以進(jìn)一步分為3度.例如滿足是較小程度的高興,是一種不飽和狀態(tài);狂喜是強(qiáng)烈的高興,是飽和狀態(tài).此外,Plutchik還提出一種假設(shè),2種相鄰近的基本情緒組合會(huì)產(chǎn)生一種復(fù)合的情緒.例如樂(lè)觀是由高興和期望的組合;此外,一些外在的刺激也可以產(chǎn)生復(fù)合情緒,若同時(shí)觸發(fā)了高興和信任,人們會(huì)表現(xiàn)出愛(ài)的情緒.

Fig. 1 Plutchik’s wheel of emotions圖1 Plutchik提出的情緒輪
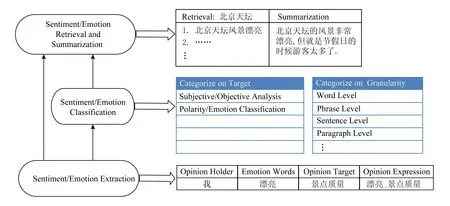
Fig.2 Research framework of sentiment/emotion analysis圖2 情感/情緒分析的研究框架
另一種在多項(xiàng)研究[4-5]中被采用的人類情緒識(shí)別模型是美國(guó)心理學(xué)家Ortony等人[6]提出的OCC (Ortony Clore Collins)情緒模型,該模型基于人對(duì)各種情況的情緒反應(yīng)制定了22種情緒類別,主要用于模擬一般情況下的情緒.
此外,從分層的角度出發(fā),英國(guó)心理學(xué)家Parrott[7]提出了一種基于樹(shù)結(jié)構(gòu)的情緒分類模型,該模型由6種基本情緒組成,分別為:愛(ài)(love)、高興(joy)、詫異(surprise)、憤怒(anger)、悲傷(sadness)和恐懼(fear),并根據(jù)基本情緒構(gòu)建了一個(gè)3層的樹(shù)結(jié)構(gòu).分類模型的第1層由6種基本情緒構(gòu)成,第2層、第3層都改善了上一層的粒度.Parrot模型可以識(shí)別出100多種情緒,并在樹(shù)結(jié)構(gòu)化列表中將抽象的情緒概念化,被認(rèn)為是最微妙的情緒分類.
隨著社交網(wǎng)絡(luò)的發(fā)展,微博等社交媒介已成為人們的主流聯(lián)絡(luò)工具.人們樂(lè)于在微博等社交網(wǎng)絡(luò)上抒發(fā)自己的感情、表達(dá)自己的觀點(diǎn).這些包含喜、怒、哀、樂(lè)等個(gè)人情緒的網(wǎng)絡(luò)文本成為了情緒分析的重要資源,研究機(jī)構(gòu)、信息咨詢組織和政府決策部門可以根據(jù)情緒分析來(lái)構(gòu)建用戶的個(gè)人肖像,分析用戶的性格特點(diǎn);利用人們對(duì)公共事件、社會(huì)現(xiàn)象的態(tài)度,掌握事態(tài)的演變,從而更好地監(jiān)測(cè)和控制事件進(jìn)展.
1.2 文本情緒分析應(yīng)用
由于研究者們?cè)缙诘墓ぷ髦饕性诙诸惖那楦蟹治錾希涑晒^為成熟,形成了體系化的研究框架.情緒與情感的分析任務(wù)相似,可以借鑒并歸納出一個(gè)適用于情感/情緒的通用研究框架,其自底向上包含抽取、分類、檢索與歸納等多項(xiàng)研究任務(wù)[8].如圖2所示,情感/情緒信息抽取主要包括觀點(diǎn)持有者識(shí)別、情感和情緒詞抽取、評(píng)價(jià)對(duì)象抽取等,這些方法是整個(gè)研究框架的基石;情感/情緒分類則建立在情感/情緒信息抽取的基礎(chǔ)上,對(duì)帶有情感/情緒的文本進(jìn)行正負(fù)類極性判定,或進(jìn)行細(xì)粒度的情緒分類.此外,情感/情緒分類還可按照不同的層級(jí)粒度細(xì)分為詞級(jí)、短語(yǔ)級(jí)、句子級(jí)和篇章級(jí).情感/情緒分類的上層研究綜合利用前2層的分析結(jié)果,為不同領(lǐng)域的應(yīng)用提供服務(wù),主要包括情感/情緒的歸納與檢索等.文本情緒分析已經(jīng)在各個(gè)領(lǐng)域得到應(yīng)用并具有良好的應(yīng)用前景.
1.2.1 輿情監(jiān)控
輿情分析,就是通過(guò)收集和整理民眾態(tài)度,發(fā)現(xiàn)相關(guān)的意見(jiàn)傾向,從而客觀反映出輿情狀態(tài).從古代的“防民之口甚于防川”,到現(xiàn)在的網(wǎng)絡(luò)時(shí)代,“每個(gè)人都有了自己的麥克風(fēng)”.互聯(lián)網(wǎng)為社情民意的表達(dá)提供了平臺(tái),體現(xiàn)用戶意愿、評(píng)論和態(tài)度的網(wǎng)絡(luò)輿情也愈發(fā)受到重視.所謂網(wǎng)絡(luò)輿情[9],就是對(duì)社會(huì)熱門問(wèn)題持有不同看法的網(wǎng)絡(luò)輿論,是社會(huì)輿論的一種表現(xiàn)形式,也是公眾通過(guò)互聯(lián)網(wǎng)對(duì)現(xiàn)實(shí)生活中某些熱點(diǎn)、焦點(diǎn)問(wèn)題發(fā)表具有較強(qiáng)影響力、傾向性的言論和觀點(diǎn).網(wǎng)絡(luò)輿情的2個(gè)重要特點(diǎn)就是網(wǎng)絡(luò)非理性情緒和群體極化.
許多非理性的情緒,如仇富、仇官、反權(quán)力、反市場(chǎng)等,借助暴力性和娛樂(lè)化的網(wǎng)絡(luò)表達(dá)強(qiáng)化,使人們變得更加情緒化和極端化.網(wǎng)民的非理性情緒,對(duì)社會(huì)存在潛在威脅,值得警醒.另一種特征“群體極化”是由美國(guó)教授Cass Robert Sunstein提出的,就是“起初團(tuán)隊(duì)成員擁有某種方面的潛在傾向,在討論之后,人們朝著所傾向的方向繼續(xù)移動(dòng),最后形成極端的觀點(diǎn)”.例如最初群體中成員的意見(jiàn)都比較保守,在經(jīng)過(guò)了群體的商議后,決策就會(huì)更加保守;相反,若個(gè)體成員意見(jiàn)傾向于冒險(xiǎn)化,則經(jīng)商議后的群體決策就可能會(huì)更趨向于冒險(xiǎn).
社會(huì)的安全管理需要不斷關(guān)注網(wǎng)絡(luò)輿情動(dòng)向,并及時(shí)正確引導(dǎo)網(wǎng)絡(luò)輿論方向,保證社會(huì)的長(zhǎng)治久安.然而,各種渠道得到的信息龐雜,只靠人工方法進(jìn)行甄別無(wú)法應(yīng)對(duì)海量信息.因此,研發(fā)精確有效的情緒分析系統(tǒng),實(shí)現(xiàn)對(duì)輿情信息的自動(dòng)處理,對(duì)維持社會(huì)穩(wěn)定有著非常重要的意義.
1.2.2 商業(yè)決策
隨著互聯(lián)網(wǎng)的發(fā)展,網(wǎng)購(gòu)在生活中愈發(fā)普及,人們通過(guò)C2C(如淘寶網(wǎng)、易趣網(wǎng)等)和B2C(如京東網(wǎng)、亞馬遜等)形式的電子商務(wù)購(gòu)買商品后,寫(xiě)下對(duì)商品的評(píng)論.其他消費(fèi)者通過(guò)這些評(píng)論可以了解商品質(zhì)量、售前售后服務(wù),并且直接影響他們的購(gòu)買決定.同時(shí),生產(chǎn)商通過(guò)分析在線評(píng)論信息和情緒特征,可以獲得消費(fèi)者的行為特點(diǎn),預(yù)測(cè)消費(fèi)者偏好的變化趨勢(shì).此外,銷售商還可以通過(guò)分析消費(fèi)者的對(duì)商品或售前售后服務(wù)的心理狀態(tài),獲得促銷對(duì)消費(fèi)者情緒的影響,為改善營(yíng)銷行為提供決策基礎(chǔ),從而獲得競(jìng)爭(zhēng)優(yōu)勢(shì).
1.2.3 觀點(diǎn)搜索
隨著信息時(shí)代的到來(lái),網(wǎng)絡(luò)數(shù)據(jù)呈現(xiàn)出爆炸式的增長(zhǎng),激發(fā)了用戶從互聯(lián)網(wǎng)海量信息中搜索有效信息的需求.在搜索過(guò)程中同時(shí)考慮搜索關(guān)鍵字和用戶的情感訴求,可以使搜索變得更加便捷、準(zhǔn)確和智能.情緒檢索技術(shù)是解決該問(wèn)題的重要方法之一,其任務(wù)是從海量文本信息中查詢文本所蘊(yùn)含的觀點(diǎn),并根據(jù)主題相關(guān)度和觀點(diǎn)傾向性對(duì)結(jié)果進(jìn)行排序.情緒檢索返回的結(jié)果需要同時(shí)滿足主題相關(guān)性和情感傾向性,情感傾向性既可以是文本帶有的情感傾向,也可以是指定情感傾向的文本.因此,情緒信息檢索是比情緒分類更加復(fù)雜的任務(wù).
為滿足互聯(lián)網(wǎng)用戶日益增長(zhǎng)的搜索需求,2006年國(guó)際文本檢索會(huì)議(Text Retrieval Evaluation Conference,TREC)首次引入博客檢索(blog track)任務(wù).Mishne[10]在LiveJournal blogs上標(biāo)注了37種情緒類別,并利用頻率統(tǒng)計(jì)、博客長(zhǎng)度、語(yǔ)義特征等方法實(shí)現(xiàn)了對(duì)博客的情緒分類,為情緒檢索提供了基礎(chǔ).此外,在圖書(shū)、隨筆等長(zhǎng)文本觀點(diǎn)搜索任務(wù)中,Mohammad[11]提出一種基于情緒詞密度的觀點(diǎn)搜索方法.該方法利用谷歌書(shū)庫(kù)定義的情緒實(shí)體與共現(xiàn)詞之間的關(guān)聯(lián),發(fā)現(xiàn)了童話和小說(shuō)之間情緒詞密度的區(qū)別,并可按照情緒類別組織文本集,提高了長(zhǎng)文本的搜索性能.此外,該方法還支持對(duì)文本中所含情緒的可視化展示與追蹤.
1.2.4 信息預(yù)測(cè)
隨著越來(lái)越多的人熱衷于參與到微博等網(wǎng)絡(luò)互動(dòng)中,微博對(duì)人們的生活也帶來(lái)了巨大的影響.情緒分析技術(shù)可以通過(guò)對(duì)微博上的新聞、評(píng)論等信息進(jìn)行分析,預(yù)測(cè)事件的發(fā)展趨勢(shì),其主要的應(yīng)用方向包括3個(gè)方面:
1) 金融預(yù)測(cè)
情緒分析在金融中的巨大應(yīng)用潛力引起了研究者們的興趣.美國(guó)印第安納大學(xué)和英國(guó)曼徹斯特大學(xué)的學(xué)者發(fā)現(xiàn)了一個(gè)有趣的現(xiàn)象[12]:Twitter可以從一定程度上預(yù)測(cè)3~4天后的股市變化.他們通過(guò)OpinionFinder方法將人的情緒分為正面和負(fù)面2種模式,再利用GPOMS(Google profile of mood)將情緒分為更加細(xì)致的類別,包括:冷靜(calm)、警惕(alert)、確信(sure)、活力(vital)、友善(kind)和幸福(happy)6類.若將其中的“冷靜”情緒指數(shù)后移3天,竟與道瓊斯工業(yè)平均指數(shù)(DJIA)驚人的相似.研究者們推測(cè):在股票市場(chǎng)中,微博上對(duì)某支股票的議論可以影響投資者的行為,從而進(jìn)一步影響股市變化的趨勢(shì).Devitt等人[13]通過(guò)對(duì)金融文本所表達(dá)的情感極性判斷,也實(shí)現(xiàn)了在一定程度上預(yù)測(cè)市場(chǎng)交易、股票價(jià)格和公司收益波動(dòng)性的未來(lái)走勢(shì).
2) 選情預(yù)測(cè)
情緒分析在選情預(yù)測(cè)中也扮演著重要的角色.在美國(guó)大選期間,Tumasjan等人[14]通過(guò)挖掘和分析民眾在Twitter上對(duì)各競(jìng)選團(tuán)隊(duì)的評(píng)論,制定針對(duì)搖擺州(美國(guó)大選中的一個(gè)專有名詞,指競(jìng)選雙方勢(shì)均力敵,都無(wú)明顯優(yōu)勢(shì)的州)的特定宣傳政策,從而提高己方的民意支持率.此后,Kim等人[15]通過(guò)對(duì)網(wǎng)絡(luò)新聞的分析,以81.68%的準(zhǔn)確率成功預(yù)測(cè)出美國(guó)大選花落誰(shuí)家.此外,在2011年意大利議會(huì)選舉和2012年法國(guó)總統(tǒng)大選過(guò)程中,Ceron等人[16]用情緒分析計(jì)算出政治領(lǐng)導(dǎo)候選人的Twitter支持率.
3) 其他預(yù)測(cè)
情緒分析還可用于對(duì)政策性事件的民意預(yù)測(cè),如延遲退休的年齡等,為國(guó)家相關(guān)政策的制定提供輔助支撐.此外,情緒分析還可以應(yīng)用到疫情、地震等自然災(zāi)害的判斷和預(yù)測(cè).
隨著信息預(yù)測(cè)的應(yīng)用內(nèi)容越來(lái)越豐富,情緒分析技術(shù)愈發(fā)受到重視.情緒分析技術(shù)通過(guò)分析互聯(lián)網(wǎng)新聞、博客等信息源,可以較為準(zhǔn)確地預(yù)測(cè)某一事件的未來(lái)走勢(shì),無(wú)論是政治經(jīng)濟(jì)領(lǐng)域還是日常生活中都具有重大意義.
1.2.5 情緒管理
用戶在微博、社區(qū)和論壇中的社交活動(dòng)都是現(xiàn)實(shí)生活對(duì)網(wǎng)絡(luò)社會(huì)的映射,這些社交網(wǎng)站中儲(chǔ)存了大量的用戶個(gè)人言論.由于用戶的情緒與其所關(guān)注的話題通常具有較強(qiáng)的連續(xù)性,分析用戶發(fā)布的言論可以較為準(zhǔn)確地獲得人們的生活狀態(tài)和性格特點(diǎn).Golder等人[17]通過(guò)研究Twitter用戶在晝夜和不同季節(jié)所展現(xiàn)的情緒節(jié)奏,包括用戶在工作、睡覺(jué)等不同時(shí)間段內(nèi)表現(xiàn)的情緒,繪制出心情曲線,從而了解人們的精神狀態(tài).此后,Kim等人[18]通過(guò)研究也發(fā)現(xiàn)人們的情緒在6點(diǎn)、11點(diǎn)、16點(diǎn)和20點(diǎn)達(dá)到了高峰,并總結(jié)了用戶一天中的情緒總體走向.利用這些研究成果,公司可以了解員工的工作狀態(tài),從而更有效地制定工作計(jì)劃.此外,Zhou等人[19]對(duì)不同行業(yè)名人的微博進(jìn)行分析,統(tǒng)計(jì)名人發(fā)布微博中各類情緒的比例,可以分析出不同名人的性格、關(guān)注點(diǎn)和個(gè)人喜好.隨著時(shí)代的進(jìn)步和社會(huì)的發(fā)展,人們對(duì)自我關(guān)注的需求不斷提高.通過(guò)對(duì)用戶進(jìn)行情緒分析可以讓用戶更加了解自我,從而找到更加適合自己的方式去學(xué)習(xí)、工作和生活,情緒管理領(lǐng)域也將擁有更廣闊的應(yīng)用市場(chǎng).
隨著應(yīng)用的發(fā)展與需求的變化,文本情感/情緒分析研究任務(wù)更加繁重,基于正負(fù)二分類的情感分析作為多分類情緒分析的前期準(zhǔn)備和一種特例,其成熟的研究框架和流程值得研究與借鑒.
2 情感分析
文本情感分析不同于文本挖掘和文本分類,文本中所蘊(yùn)含的情感本身具有抽象性,難以根據(jù)字面信息直接進(jìn)行處理.情感分析的主要任務(wù)[8]包括:情感信息抽取、情感分類、情感檢索與歸納.
2.1 情感信息抽取
情感信息抽取的目標(biāo)是抽取文本中有價(jià)值的情感信息,找出文本中傾向性單元的要素[20],包括識(shí)別情感表達(dá)者、評(píng)價(jià)對(duì)象以及情感觀點(diǎn)等有價(jià)值的任務(wù).
2.1.1 情感表達(dá)者的識(shí)別
情感表達(dá)者就是抽取觀點(diǎn)的持有者,即觀點(diǎn)、評(píng)論的隸屬者.Kim等人[21]提出了一種基于語(yǔ)義角色的觀點(diǎn)持有者識(shí)別方法.該方法通過(guò)目標(biāo)詞、短語(yǔ)類型、解析樹(shù)路徑等特征和最大熵分類器識(shí)別出情感表達(dá)者.在FrameNet數(shù)據(jù)集的實(shí)驗(yàn)中,該方法的效果優(yōu)于貝葉斯分類器,其F值可達(dá)78.7%.
此后,為解決不同領(lǐng)域觀點(diǎn)持有者抽取的適應(yīng)性問(wèn)題,Carstens等人[22]提出了一種基于多模型的觀點(diǎn)持有者識(shí)別系統(tǒng).該系統(tǒng)通過(guò)提取交叉領(lǐng)域不同方法的共同點(diǎn),從而提高了系統(tǒng)的通用性.在實(shí)驗(yàn)中,該方法相較于支持向量機(jī)(support vector machine, SVM),準(zhǔn)確率提高了5.6%.
2.1.2 評(píng)價(jià)對(duì)象的抽取
評(píng)價(jià)對(duì)象是指文本所描述的對(duì)象,同時(shí)也是承載情感表達(dá)者所抒發(fā)情感的載體.Eirinaki等人[23]提出了一種基于形容詞評(píng)分的抽取方法,該方法從被形容詞描述的名詞中提取評(píng)價(jià)對(duì)象.在吸塵器、相機(jī)和DVD播放器3類評(píng)價(jià)對(duì)象的樣本中,該方法的識(shí)別準(zhǔn)確率可達(dá)87%.
Yu等人[24]提出了一種基于統(tǒng)計(jì)學(xué)和句法規(guī)則的抽取方法,該方法通過(guò)評(píng)價(jià)對(duì)象出現(xiàn)的相對(duì)頻率找出候選評(píng)價(jià)對(duì)象,并將大于預(yù)設(shè)閾值的對(duì)象作為最終的結(jié)果.在淘寶和騰訊拍拍的評(píng)論數(shù)據(jù)集上,該方法的F值可達(dá)84.02%.
此后,戴敏等人[25]提出了一種基于條件隨機(jī)場(chǎng)的抽取模型,通過(guò)加入句法特征來(lái)提高評(píng)價(jià)對(duì)象抽取的性能.在德國(guó)城市服務(wù)評(píng)論數(shù)據(jù)集(Darmstadt service review corpus, DSRC)語(yǔ)料庫(kù)的實(shí)驗(yàn)中,其F值達(dá)到62.57%.為提高評(píng)價(jià)對(duì)象的識(shí)別效果,宋暉等人[26]提出一種基于模糊匹配和半監(jiān)督的抽取評(píng)價(jià)對(duì)象方法.該方法通過(guò)手工標(biāo)記樣本獲取種子詞規(guī)則集,利用句法結(jié)構(gòu)和詞性等特征提取評(píng)價(jià)對(duì)象.在京東商品評(píng)論數(shù)據(jù)集中,該方法F值可達(dá)79.34%.此外,還有一些研究者利用依存句法分析來(lái)抽取評(píng)價(jià)對(duì)象[27-28].
2.1.3 情感詞的抽取
情感詞是帶有情感傾向性的詞語(yǔ),目前情感詞的抽取主要分為基于情感詞典和基于規(guī)則的方法.
基于詞典的評(píng)價(jià)詞語(yǔ)抽取方法是通過(guò)分析詞語(yǔ)間的詞義聯(lián)系以獲取評(píng)價(jià)詞語(yǔ).Li等人[29]通過(guò)抽取語(yǔ)料中的形容詞和副詞,并與WordNet詞表比對(duì)選出情感詞.在電影評(píng)論數(shù)據(jù)集的實(shí)驗(yàn)中,該方法準(zhǔn)確率可達(dá)77.17%.
基于規(guī)則的方法主要由用戶事先制定分類規(guī)則,方法主要包括專家標(biāo)注、專業(yè)詞典、統(tǒng)計(jì)方法等.王昌厚等人[30]提出一種基于模式的種子式自擴(kuò)張(bootstrapping)方法,利用種子詞與漢語(yǔ)副詞的搭配方式,通過(guò)多次迭代來(lái)進(jìn)行情感詞抽取.實(shí)驗(yàn)表明,當(dāng)該方法迭代約100次時(shí)準(zhǔn)確率最高,約90%.
情感信息抽取是情感分析的基礎(chǔ)任務(wù),可對(duì)情感文本中有價(jià)值的情感信息進(jìn)行抽取,為上層的情感分類和情感檢索與歸納任務(wù)提供了支撐.
2.2 情感分類
情感分類又稱情感傾向性分析,其任務(wù)是識(shí)別指定文本的主觀性觀點(diǎn),并判斷文本情感的正負(fù)傾向性,主要包括基于詞典和規(guī)則的方法和基于機(jī)器學(xué)習(xí)的方法.
2.2.1 基于詞典和規(guī)則的情感分類方法
情感詞典作為一種重要的情感分類方法,能夠體現(xiàn)文本的非結(jié)構(gòu)化特征.Paltoglou等人[31]采用基于情感詞典的情緒分類方法.該方法利用否定詞、大寫(xiě)字母、情感增強(qiáng)減弱、情感極性等多種語(yǔ)言學(xué)預(yù)測(cè)函數(shù),對(duì)微博進(jìn)行情感分類.在Twitter,MySpace,Digg等社交媒體的實(shí)驗(yàn)中,該方法準(zhǔn)確率可達(dá)86.5%.此后,Qiu等人[32]提出一種基于句法分析和情感詞典相結(jié)合的情感分類方法,該方法利用情感詞典從廣告上下文中識(shí)別情感句,根據(jù)主題和關(guān)鍵字提取消費(fèi)者的態(tài)度.在automotiveforums.com論壇語(yǔ)料庫(kù)實(shí)驗(yàn)中,該方法準(zhǔn)確率為55%.在此基礎(chǔ)上,Jiang等人[33]擴(kuò)充了情感詞典特征和主題相關(guān)特征,在Twitter語(yǔ)料分類實(shí)驗(yàn)中,準(zhǔn)確率可達(dá)85.6%.
在中文情感分類的研究中,Wan[34]利用機(jī)器翻譯技術(shù)將中文商品評(píng)論翻譯成英文評(píng)論,再利用英文情感分析資源對(duì)翻譯后的評(píng)論進(jìn)行情感極性分類.在中文it168.com網(wǎng)站語(yǔ)料庫(kù)實(shí)驗(yàn)中,該方法準(zhǔn)確率可達(dá)81.3%.此后,Wei等人[35]通過(guò)引入多語(yǔ)言模型,利用結(jié)構(gòu)一致學(xué)習(xí)算法(structural corres-pondence learning, SCL)減少機(jī)器翻譯的噪聲,充分利用了已有的中英文情感語(yǔ)料.在使用文獻(xiàn)[34]的語(yǔ)料庫(kù)時(shí),該方法準(zhǔn)確率可達(dá)85.4%.
為應(yīng)對(duì)海量無(wú)標(biāo)記數(shù)據(jù)情感分類的挑戰(zhàn),研究者們開(kāi)展基于規(guī)則的情感分類的研究.Turney[36]提出一種基于互信息(pointwise mutual information, PMI)的情感分類方法,該方法在提取文本詞性的基礎(chǔ)上,根據(jù)預(yù)定義的規(guī)則選取形容詞、副詞的搭配,對(duì)文本所有搭配的互信息差求和,判斷情感類別.對(duì)情感分類的平均準(zhǔn)確率可達(dá)74.39%.
針對(duì)文獻(xiàn)[36]受限于較依賴種子褒/貶義詞集合的問(wèn)題,Zagibalov等人[37]通過(guò)分析文本中的否定詞和狀語(yǔ)信息并引入迭代機(jī)制,使無(wú)監(jiān)督學(xué)習(xí)情感分類的準(zhǔn)確率達(dá)到了82.72%.
由于某些情感詞在不同的領(lǐng)域或語(yǔ)境中有不同的情感極性,Jo等人[38]提出一種基于“主題-句子”關(guān)系的情感分類方法.該方法在情感詞上同時(shí)標(biāo)記主題和情感2種標(biāo)簽,并利用句子的主題標(biāo)簽采樣代替詞的主題標(biāo)簽采樣,縮小詞與詞之間的主題聯(lián)系.由于基于主題的模型有著其他方法難以替代的優(yōu)點(diǎn),受到了廣大研究者們的關(guān)注[39-41].
隨著互聯(lián)網(wǎng)中新詞的不斷涌現(xiàn),基于詞典和規(guī)則的分類方法在分類時(shí)靈活度不高,難以應(yīng)對(duì)不斷變化的詞形詞意,為提高情感分類的準(zhǔn)確率,研究者們開(kāi)展了基于機(jī)器學(xué)習(xí)的情感分析方法.
2.2.2 基于機(jī)器學(xué)習(xí)的情感分類方法
隨著機(jī)器學(xué)習(xí)技術(shù)不斷創(chuàng)新,開(kāi)拓的新領(lǐng)域無(wú)處不在,文本情感分析一直是機(jī)器學(xué)習(xí)研究的活躍領(lǐng)域之一.
1) 有監(jiān)督學(xué)習(xí)的情感分類方法
有監(jiān)督學(xué)習(xí)方法認(rèn)為情感分類是一個(gè)針對(duì)標(biāo)記訓(xùn)練文檔的標(biāo)準(zhǔn)模式分類問(wèn)題.Pang等人[42]首次將有監(jiān)督學(xué)習(xí)方法應(yīng)用到情感分類中.通過(guò)對(duì)比一元特征、二元特征、形容詞打分、位置等多種特征和特征權(quán)值選擇策略,并著重比較了SVM、樸素貝葉斯和最大熵等算法的分類效果.在電影評(píng)論領(lǐng)域,一元特征與SVM組合效果最好,準(zhǔn)確率可達(dá)82.9%.
此后,Dong等人[43]提出一種基于自適應(yīng)遞歸神經(jīng)網(wǎng)絡(luò)的情感分類方法,該方法通過(guò)上下文和句法規(guī)則對(duì)詞的情感標(biāo)記進(jìn)行自適應(yīng)傳播,實(shí)現(xiàn)了目標(biāo)依賴的情感分類.在Twitter樣本集的實(shí)驗(yàn)中,該方法的準(zhǔn)確率比SVM高,可達(dá)66.3%.
Tang等人[44]設(shè)計(jì)了一種基于消息級(jí)微博情感分析的深度學(xué)習(xí)系統(tǒng).該系統(tǒng)通過(guò)將特定情感詞向量(sentiment-specific word embedding)與手工選擇的表情符號(hào)、語(yǔ)義詞典等特征相結(jié)合,并利用SVM進(jìn)行情感分類.該系統(tǒng)在Twitter情感語(yǔ)料庫(kù)上的準(zhǔn)確率可達(dá)87.61%.
隨著大數(shù)據(jù)時(shí)代的到來(lái),通過(guò)各種途徑采集到的數(shù)據(jù)大多是無(wú)標(biāo)記的,這成為了研究的瓶頸.為了在基于詞典和規(guī)則方法的省力省時(shí)和有監(jiān)督學(xué)習(xí)方法的高準(zhǔn)確率優(yōu)勢(shì)之間取得平衡,研究者們開(kāi)展了半監(jiān)督學(xué)習(xí)情感分類方法的研究.
2) 半監(jiān)督學(xué)習(xí)的情感分類方法
半監(jiān)督學(xué)習(xí)分類方法可以利用少量已標(biāo)注的樣本和對(duì)大量未標(biāo)注樣本進(jìn)行訓(xùn)練和分類.Tan等人[45]提出了一種基于半監(jiān)督特征提取的情感分類系統(tǒng),該系統(tǒng)融合譜聚類、主動(dòng)學(xué)習(xí)、遷移學(xué)習(xí)等不同方法提取情緒特征,應(yīng)用遷移學(xué)習(xí)的方法完成整個(gè)情感分析系統(tǒng)的構(gòu)建.在搜狐學(xué)習(xí)評(píng)論、搜狐股票評(píng)論和中關(guān)村電腦評(píng)論語(yǔ)料庫(kù)的實(shí)驗(yàn)中,該方法的最小F值可達(dá)82.62%.
此后,Ortigosa等人[46]將態(tài)度分析應(yīng)用到半監(jiān)督學(xué)習(xí)情感分類方法中,將文本發(fā)布者的態(tài)度主觀性、情感極性和影響力等指標(biāo)進(jìn)行優(yōu)化與合并,對(duì)語(yǔ)料中的情感進(jìn)行分類.該方法在人造數(shù)據(jù)集的實(shí)驗(yàn)中,情感分類準(zhǔn)確率為54%.
在遞歸自編碼的基礎(chǔ)上加入了情感類別的標(biāo)記信息,Socher等人[47]提出了一種遞歸自編碼半監(jiān)督學(xué)習(xí)情感分析模型.該模型在構(gòu)建短語(yǔ)向量表示時(shí),可以更大程度地保留情感信息,提高了預(yù)測(cè)情感的準(zhǔn)確率,可達(dá)86.4%.
通過(guò)將先驗(yàn)知識(shí)嵌入到學(xué)習(xí)結(jié)構(gòu)中,Zhou等人[48]提出一種基于模糊深度置信網(wǎng)絡(luò)的半監(jiān)督學(xué)習(xí)情感分類方法.該方法不僅繼承了深度置信網(wǎng)絡(luò)強(qiáng)大的抽象能力,還具備對(duì)情感數(shù)據(jù)的模糊分類能力.在影評(píng)、DVD評(píng)論等5類語(yǔ)料庫(kù)的實(shí)驗(yàn)中,其準(zhǔn)確率可達(dá)到79.4%.
在跨語(yǔ)言分類的任務(wù)中,傳統(tǒng)的情感分析方法很難直接應(yīng)用.He等人[49]提出有監(jiān)督學(xué)習(xí)與空間轉(zhuǎn)移相結(jié)合的方法,該方法主要思想是利用目標(biāo)語(yǔ)言的內(nèi)在情緒知識(shí),補(bǔ)充轉(zhuǎn)移過(guò)程中丟失的信息.在圖書(shū)、DVD、音樂(lè)等不同商品評(píng)論的語(yǔ)料庫(kù)實(shí)驗(yàn)中,該方法的準(zhǔn)確率可達(dá)82%.
為方便對(duì)不同情感分析方法的效果進(jìn)行比較,本文將使用相同公開(kāi)數(shù)據(jù)集的方法及其準(zhǔn)確率進(jìn)行了匯總,包括斯坦福情感樹(shù)庫(kù)(Stanford sentiment treebank, SSTb)[50-53]、斯坦福Twitter情感語(yǔ)料庫(kù)(Stanford Twitter sentiment corpus, STS)[50,54-57]、IMDb影評(píng)[58-62]等,具體性能對(duì)比如表1所示:

Table 1 The Performance Comparison of Sentiment Analysis
2.3 情感摘要和檢索
情感摘要任務(wù)是對(duì)帶有情感的文本數(shù)據(jù)進(jìn)行濃縮、提煉,從而產(chǎn)生文本所表達(dá)的關(guān)于情感意見(jiàn)的摘要.Stoyanov等人[63]提出了一種基于細(xì)粒度觀點(diǎn)信息情感摘要的生成方法.通過(guò)將描述同一個(gè)實(shí)體的評(píng)論關(guān)聯(lián)起來(lái),收集現(xiàn)實(shí)世界中所有識(shí)別到的觀點(diǎn)屬性,并最終合成一個(gè)完整的情感摘要.Ku等人[64]提出一種基于文本的觀點(diǎn)提取、摘要和跟蹤方法.該方法通過(guò)對(duì)詞語(yǔ)、句子、篇章級(jí)別的觀點(diǎn)抽取,將主題與觀點(diǎn)信息總結(jié)為情感摘要.在新聞和博客語(yǔ)料庫(kù)的實(shí)驗(yàn)中,該情感摘要提取方法的F值分別可達(dá)到47.97%和32.58%.
情感檢索任務(wù)最早由Hurst等人[65]提出,他們歸納了情感檢索2個(gè)主要任務(wù):①檢索和查詢相關(guān)觀點(diǎn)的文檔或者句子;②根據(jù)主題相關(guān)性和觀點(diǎn)傾向性對(duì)檢索出的文檔或句子進(jìn)行排序.在此基礎(chǔ)上,Zhang等人[66]提出了一種基于詞典的觀點(diǎn)檢索方法.該方法利用一個(gè)二次方程將主題相關(guān)性和觀點(diǎn)抽取結(jié)合起來(lái).該方法在TREC博客數(shù)據(jù)集的實(shí)驗(yàn)中,檢索結(jié)果提升了40.3%.
情感檢索將傳統(tǒng)的信息檢索技術(shù)和情感分析技術(shù)相融合,而如何更好地融合二者以獲得理想的情感檢索結(jié)果是近期和未來(lái)要關(guān)注的.
多分類情緒分析作為正負(fù)二分類情感分析的延伸,也遵循情感/情緒研究框架.相比情感分析,情緒分析現(xiàn)有的工作還比較少.由于現(xiàn)有的文本情緒分析任務(wù)中的情緒抽取任務(wù)基本與情感抽取相同,不少方法可以直接應(yīng)用到情緒分析中來(lái).此外,現(xiàn)有情緒分析工作主要集中在情緒分類的研究上,目前尚無(wú)針對(duì)情緒摘要和檢索的研究.
3 情緒分析
文本情緒分類任務(wù)主要指通過(guò)提取文本內(nèi)容中的情緒要素,將文本劃分到一個(gè)或多個(gè)預(yù)定義的情緒類別中,通過(guò)判定文本中所表達(dá)的情緒類別,實(shí)現(xiàn)對(duì)文本發(fā)布者情緒的監(jiān)控、預(yù)測(cè)和管理.目前,情緒分類方法主要包括:基于詞典和規(guī)則的方法、基于機(jī)器學(xué)習(xí)的方法、復(fù)合方法以及其他方法.
3.1 基于詞典和規(guī)則的情緒分類方法
基于詞典和規(guī)則的方法能體現(xiàn)文本的非結(jié)構(gòu)化特征,易于理解和解釋.此外,該方法處理速度快且精度較高,在相對(duì)短的時(shí)間內(nèi)能夠?qū)Υ笮蛿?shù)據(jù)源做出可行且效果良好的結(jié)果.
3.1.1 基于詞典的情緒分類方法
基于詞典的方法主要利用情緒詞典資源,將語(yǔ)料庫(kù)中的情緒表達(dá)關(guān)鍵字提取出來(lái),并藉此對(duì)語(yǔ)料進(jìn)行情緒分類.在早期的研究中,Ma等人[67]提出了一種基于詞典的情緒分類方法,并將其應(yīng)用到即時(shí)通訊系統(tǒng)上.該方法首先利用關(guān)鍵字識(shí)別出文本中情緒相關(guān)的內(nèi)容,再利用句法特征檢測(cè)其中的情緒意義,并通過(guò)文本消息中的情緒對(duì)系統(tǒng)中的語(yǔ)音合成、手勢(shì)等功能進(jìn)行調(diào)整,幫助用戶更好地與遠(yuǎn)距離用戶溝通.在此基礎(chǔ)上,Aman等人[68]提出一種基于情緒強(qiáng)度知識(shí)的分類方法,該方法除使用情緒詞典之外,還增加了情緒強(qiáng)度知識(shí)庫(kù).該方法在博客語(yǔ)料的情緒分類任務(wù)中,其準(zhǔn)確率可達(dá)66%以上.
由于情緒詞典中的情感詞有較大程度的領(lǐng)域依賴性、時(shí)間依賴性和語(yǔ)言依賴性,同一詞匯在不同的領(lǐng)域、時(shí)間和語(yǔ)言環(huán)境中可能會(huì)表達(dá)完全不同的情緒,然而傳統(tǒng)方法在構(gòu)建情緒詞典時(shí)并未考慮詞典的應(yīng)用環(huán)境因素,甚至無(wú)法應(yīng)用到其他語(yǔ)種.因此,在跨領(lǐng)域、跨時(shí)間、跨語(yǔ)言的文本情緒分類任務(wù)中效果并不理想.
為解決領(lǐng)域依賴性的問(wèn)題,Yang等人[69]提出一種基于特定領(lǐng)域情緒詞典分類的方法.該方法利用情緒感知LDA(emotion-aware LDA,EaLDA)模型,為預(yù)定義的情緒構(gòu)建特定領(lǐng)域的情緒詞典.EaLDA模型使用一組領(lǐng)域無(wú)關(guān)的最小種子詞作為先驗(yàn)知識(shí),來(lái)發(fā)現(xiàn)特定領(lǐng)域的詞典.在SemEval-2007數(shù)據(jù)集的綜合實(shí)驗(yàn)中,該方法可以有效輔助文本情緒分類任務(wù),其中對(duì)最難辨別的Disgust類別,其F1值可達(dá)10.52%,其他分類如Sadness可達(dá)36.85%.
為挖掘時(shí)間依賴性對(duì)情緒分類的影響,Golder等人[17]利用情緒詞典對(duì)全球不同地域、不同文化背景博主所發(fā)表的Twitter進(jìn)行統(tǒng)計(jì),分析了數(shù)百萬(wàn)篇公開(kāi)Twitter中所表達(dá)的情緒,并明確地識(shí)別出人們的情緒會(huì)隨著季節(jié)、星期、晝夜呈現(xiàn)出周期性變化的模式.
解決情緒詞典語(yǔ)言依賴性問(wèn)題最常用的方法是構(gòu)建本語(yǔ)言的情緒詞典,因此,很多研究者們開(kāi)展了構(gòu)建中文情緒詞典的研究工作.
對(duì)于中文及其他語(yǔ)料資源匱乏的語(yǔ)言,難以獲得用于構(gòu)建本語(yǔ)言情緒詞典的語(yǔ)料素材.為解決該問(wèn)題,Xu等人[70]提出一種基于英文情緒詞典WordNet-Affect自動(dòng)構(gòu)建中文情緒詞典的方法.該方法首先將英文情緒詞典中所有的英文單詞都翻譯成中文;再借助中文同義詞詞典《同義詞詞林》將每個(gè)情緒類別構(gòu)建一個(gè)雙語(yǔ)無(wú)向圖,并提出一個(gè)圖算法用以過(guò)濾翻譯過(guò)程中引入的非情緒詞,以獲得種子情緒詞集;最終通過(guò)同義詞擴(kuò)大表示類似情緒的詞匯量,從而獲得數(shù)量大、質(zhì)量高的中文情緒詞典.圖3展示了Anger情緒的部分雙語(yǔ)圖,圖3中將多個(gè)同義詞作為邊添加到Anger情緒節(jié)點(diǎn)上.例如n#05588321的字母部分是該詞條的詞性(part of speech,POS),數(shù)字部分是同義詞集的ID.該方法在中文語(yǔ)料的6種情緒anger,disgust,fear,joy,sadness,surprise分類實(shí)驗(yàn)中,準(zhǔn)確率可達(dá)77.08%以上.

Fig. 3 A partial bilingual graph of “Anger”圖3 Anger的部分雙語(yǔ)圖
文獻(xiàn)[70]主要解決語(yǔ)料庫(kù)資源嚴(yán)重不足條件下構(gòu)建情緒詞典的問(wèn)題,但由于不同語(yǔ)言不同文化中詞匯所表達(dá)的情緒存在差異,對(duì)情緒分類的準(zhǔn)確率存在影響,為此一些研究者開(kāi)始研究利用少量種子詞構(gòu)建情緒詞典的方法.Song等人[71]提出一種基于異構(gòu)圖的情緒詞典分類方法,該方法利用種子詞和表情符號(hào)構(gòu)建情緒詞典,并使用隨機(jī)游走算法強(qiáng)化對(duì)情緒分布的評(píng)估效果.在新浪微博真實(shí)數(shù)據(jù)的實(shí)驗(yàn)中,利用該方法構(gòu)建的情緒詞典對(duì)7種情緒anger,disgust,fear,happiness,like,sadness,surprise分類的準(zhǔn)確率可達(dá)54.1%.
此外,傳統(tǒng)的情緒詞典方法還存在詞典中情緒詞固定,難以及時(shí)捕捉新詞、變形詞的缺陷.為此,Wu等人[72]提出一種基于數(shù)據(jù)驅(qū)動(dòng)的微博專用情緒詞典分類方法.該方法設(shè)計(jì)了一個(gè)包含3種詞典的情緒知識(shí)統(tǒng)一框架.為了提高情緒詞的覆蓋率,該方法還支持將檢測(cè)到的情緒新詞加入到詞典中,不斷擴(kuò)展情緒詞典的樣本集.在新浪微博數(shù)據(jù)集的實(shí)驗(yàn)中,該方法準(zhǔn)確率可達(dá)58.04%.
影響情緒詞典方法分類準(zhǔn)確率的主要因素包括情緒詞典的覆蓋率和標(biāo)注的準(zhǔn)確率,目前的情緒詞典在這2個(gè)方面仍有不足,一些研究者利用互聯(lián)網(wǎng)的便利,通過(guò)網(wǎng)民的幫助構(gòu)建了一個(gè)高質(zhì)量情緒詞典.Staiano等人[73]提出一種基于“眾包”的情緒分類方法,該方法利用大規(guī)模“眾包”方式建立情緒注釋與新聞文章之間的聯(lián)系.使用分布語(yǔ)義自動(dòng)構(gòu)建高質(zhì)量、高精度的情緒詞典.在rappler.com新聞消息數(shù)據(jù)集的實(shí)驗(yàn)中,該方法較好地完成了fear,anger,surprise,joy,sadness 這5類情緒的分類任務(wù),其中對(duì)fear的分類效果最好,準(zhǔn)確率可達(dá)56%,surprise效果最差,準(zhǔn)確率為25%.
總體上,基于情緒詞典的分類方法能體現(xiàn)出文本的非結(jié)構(gòu)化特征,在詞典中情感詞覆蓋率和標(biāo)注準(zhǔn)確率較高的情況下,分類效果比較理想.然而,該類方法依賴領(lǐng)域、時(shí)間、語(yǔ)言等方面的背景知識(shí),且難以及時(shí)捕捉新詞、變形詞,使如何構(gòu)造高質(zhì)量的情緒詞典成為其難點(diǎn).
3.1.2 基于規(guī)則的情緒分類方法
除了情緒詞典,還有一類基于規(guī)則的情緒分類方法,可以快速實(shí)現(xiàn)對(duì)情緒語(yǔ)料的分類.在早期的工作中,Strapparava等人[74]提出了一種基于語(yǔ)義規(guī)則的情緒分類方法,該方法利用隱形語(yǔ)義算法(latent semantic analysis, LSA)計(jì)算通用語(yǔ)義詞和情緒詞的語(yǔ)義相似度,再根據(jù)語(yǔ)義相似度對(duì)新聞標(biāo)題進(jìn)行分類.該方法在Times,BBC,CNN等新聞?wù)Z料的情緒分類任務(wù)中,準(zhǔn)確率可達(dá)38.28%.
由于網(wǎng)絡(luò)中的非正式文本比較多,文獻(xiàn)[74]在對(duì)不規(guī)范文本的情緒分類任務(wù)中表現(xiàn)并不理想.為解決該問(wèn)題,Neviarouskaya等人[75]首先對(duì)網(wǎng)絡(luò)文本中非正式縮寫(xiě)、情緒圖標(biāo)以及語(yǔ)法錯(cuò)誤等不規(guī)范文本進(jìn)行了預(yù)處理,再利用基于語(yǔ)義規(guī)則的方法分階段處理每個(gè)句子,最終將目標(biāo)語(yǔ)料中的情緒分為9類interest,joy,surprise,anger,sadness,fear,disgust,guilt,shame,其架構(gòu)如圖4所示.在包括日記博客、童話和新聞標(biāo)題等不同領(lǐng)域的數(shù)據(jù)集中,該方法情緒分類的準(zhǔn)確率可達(dá)72.6%.此外,該方法在具有復(fù)雜句子的環(huán)境中也具有較好的分類效果.

Fig. 4 The emotion analysis architecture based on semantic圖4 基于語(yǔ)義規(guī)則的情緒分析架構(gòu)
對(duì)于句子級(jí)情緒分析,現(xiàn)有的基于情緒詞典的方法表現(xiàn)并不理想,因?yàn)槠洳⑽纯紤]文本順序和篇章結(jié)構(gòu).Wen等人[76]提出一種利用類序列規(guī)則情緒分類的方法,將指定文本中的情緒分為7類anger,disgust,fear,happiness,like,sadness,surprise.該方法首先分別利用情緒詞典和機(jī)器學(xué)習(xí)方法獲得句子的2個(gè)潛在情緒標(biāo)簽,并將每個(gè)微博文本看作一個(gè)數(shù)據(jù)序列,再?gòu)臄?shù)據(jù)集中挖掘文本的類規(guī)則序列,最后根據(jù)規(guī)則的特性對(duì)微博進(jìn)行情緒分類.在2013年新浪微博的情緒分析評(píng)測(cè)任務(wù)中,該方法對(duì)7種情緒的分類準(zhǔn)確率均達(dá)到41.33%以上.
通過(guò)分析社會(huì)媒體中公眾情緒的成因,可以利用情緒與起因事件的關(guān)聯(lián)關(guān)系來(lái)提高情緒分類的準(zhǔn)確率.傳統(tǒng)的情緒分類方法主要基于統(tǒng)計(jì)手段,沒(méi)有考慮到引起情緒的觸發(fā)事件.Lee等人[77]提出一種基于文本驅(qū)動(dòng)的情緒成因檢測(cè)方法.該方法通過(guò)對(duì)中文語(yǔ)料庫(kù)數(shù)據(jù)的分析,確定了7種語(yǔ)言線索,包括原因事件的位置、體驗(yàn)者情緒關(guān)鍵詞的位置、使役動(dòng)詞、動(dòng)作詞、認(rèn)知標(biāo)記、連接詞和介詞,并據(jù)此歸納出語(yǔ)言規(guī)則來(lái)檢測(cè)情緒的成因.
在此基礎(chǔ)上,部分研究者將基于規(guī)則的方法與事件成因相結(jié)合,從而實(shí)現(xiàn)對(duì)媒體文本的情緒分類.Li等人[78]提出一種結(jié)合語(yǔ)義規(guī)則和事件觸發(fā)理論的情緒分類方法.該方法根據(jù)社會(huì)學(xué)以及其他領(lǐng)域的知識(shí)和理論,從推斷和提取情感的原因入手進(jìn)行分析.通過(guò)構(gòu)造一個(gè)基于語(yǔ)義規(guī)則的系統(tǒng),自動(dòng)檢測(cè)并抽取每個(gè)博客語(yǔ)料中情緒的起因事件.再利用起因事件訓(xùn)練分類器對(duì)語(yǔ)料庫(kù)進(jìn)行情緒分類.在新浪微博的實(shí)驗(yàn)中,該方法在加入了原因事件后,對(duì)6個(gè)情緒類別anger,disgust,fear,happiness,sadness,surprise的分類準(zhǔn)確率均有所提高.例如,Happiness從85.41%提升至87.36%,Surprise從71.71%提升至72.52%等.
此后,Gao等人[79]結(jié)合情緒起因事件,提出一種基于規(guī)則的情緒分析系統(tǒng).該系統(tǒng)從事件的結(jié)果、代理的行為和對(duì)象的性質(zhì)中分析產(chǎn)生情緒的原因事件,并根據(jù)這些事件挖掘其中的基本情緒、復(fù)合情緒(滿意、感激、悔恨和憤怒)和擴(kuò)展情緒(信任、失望、憐憫等)的關(guān)聯(lián)規(guī)則,通過(guò)抽取的情緒規(guī)則對(duì)中文微博進(jìn)行分類.在對(duì)新浪微博語(yǔ)料中實(shí)驗(yàn),分類準(zhǔn)確率可達(dá)82.50%.
綜上,雖然基于規(guī)則的情緒方法可以在較短時(shí)間內(nèi)獲得分類結(jié)果,且可以加入事前起因等其他規(guī)則來(lái)提高情緒分類的準(zhǔn)確率,但在數(shù)據(jù)量較大時(shí),規(guī)則的維護(hù)比較復(fù)雜,且不易擴(kuò)展.
3.2 基于機(jī)器學(xué)習(xí)的情緒分類方法
在大數(shù)據(jù)時(shí)代的背景下,捕獲文本數(shù)據(jù)并從中萃取有價(jià)值的情緒信息是基于機(jī)器學(xué)習(xí)情緒分類方法的主要任務(wù),該方法主要包括有監(jiān)督和半監(jiān)督方法.
3.2.1 有監(jiān)督學(xué)習(xí)情緒分類方法
在有監(jiān)督學(xué)習(xí)的過(guò)程中,只需要給定輸入情緒樣本集,即可推演出目標(biāo)情緒分類的可能結(jié)果.有監(jiān)督學(xué)習(xí)相對(duì)比較簡(jiǎn)單,針對(duì)不同的情緒分類任務(wù)可分為單標(biāo)簽和多標(biāo)簽情緒分類方法.
特征選取是否合適是影響有監(jiān)督學(xué)習(xí)分類效果的一個(gè)主要因素,現(xiàn)有方法中用于情緒分類的特征主要包括詞級(jí)、句子級(jí)和篇章級(jí)特征.其中,詞級(jí)特征主要包括詞頻(例如詞袋特征)、詞性(例如名詞、動(dòng)詞、連接詞)、語(yǔ)義(例如詞向量的相似度)、表情符號(hào)及其組合等.
在早期的研究中,為了使得語(yǔ)音合成技術(shù)TTS(text-to-speech)朗讀時(shí)語(yǔ)調(diào)更自然,研究者們需要挖掘出童話故事中所蘊(yùn)含的情緒.Alm等人[80]提出一種將SVM與SNoW (sparse network of winnows)架構(gòu)結(jié)合的文本情緒預(yù)測(cè)方法.該方法通過(guò)選取故事首句、特定的連接詞等30種特征將22篇格林童話劃分為happy,sad,fearful,angry,disgusted,surprised,non-emotion這7類,其中surprised又細(xì)化為正向Su+和負(fù)向Su-.實(shí)驗(yàn)通過(guò)對(duì)比SVM、樸素貝葉斯等基準(zhǔn)分類器,結(jié)果顯示將SVM與SNoW架構(gòu)結(jié)合的方法效果最好,其準(zhǔn)確率可達(dá)到69.37%.
相較于童話故事、博客等長(zhǎng)文本語(yǔ)料,社交網(wǎng)絡(luò)信息通常是簡(jiǎn)短的,如微博、即時(shí)消息、新聞標(biāo)題等.短文本受字?jǐn)?shù)的限制,呈現(xiàn)出特征稀疏、內(nèi)容簡(jiǎn)短、表述直接等特點(diǎn),這使得以往的情緒分類方法在面向短文本語(yǔ)料時(shí),難以保證其分類效果.面向短文本的情緒分析[81]是近幾年最熱門的研究方向之一.
在微博環(huán)境中,表情符號(hào)被廣泛用來(lái)表達(dá)不同的情緒,社交網(wǎng)絡(luò)運(yùn)營(yíng)商也為用戶提供了豐富的情緒圖標(biāo),方便用戶表達(dá)對(duì)事物的情緒.因此,表情符號(hào)也被視為情緒分類的重要信號(hào).此外,表情符號(hào)具有其他詞語(yǔ)所不具備的獨(dú)立性,在大多數(shù)話題、領(lǐng)域、時(shí)間段中,表情符號(hào)所代表的情緒基本保持不變,因此,很多研究者都將表情符號(hào)作為其特征中的一個(gè)重要組成部分.
Read[82]提出一種基于表情符號(hào)的情緒分類方法.該方法從語(yǔ)料庫(kù)中抽取指定情緒符號(hào)的文本集合,把所得的樣本集作為訓(xùn)練數(shù)據(jù)來(lái)實(shí)現(xiàn)情緒分類.該方法在包含金融主題、并購(gòu)主題以及2個(gè)主題混合的數(shù)據(jù)集上進(jìn)行測(cè)試,證明了表情符號(hào)特征的主題獨(dú)立性,其分類準(zhǔn)確率可達(dá)70%.
在此基礎(chǔ)上,Zhao等人[83]建立一個(gè)基于表情符號(hào)與詞袋相結(jié)合的情緒分類系統(tǒng)Moodlens,該系統(tǒng)避免了使用傳統(tǒng)關(guān)鍵字的方法,在1 000多個(gè)表情符號(hào)中手工選取95個(gè)記作E,并將這95個(gè)表情符號(hào)映射到憤怒、厭惡、開(kāi)心和悲傷(angry,disgusting,joyful,sadness)4個(gè)類別.實(shí)驗(yàn)將收集到的7 000多萬(wàn)條微博數(shù)據(jù)中所包含E中表情符號(hào)的350萬(wàn)微博作為測(cè)試集,記作T.對(duì)T中每一條微博,Moodlens將其轉(zhuǎn)化為一個(gè)詞序列{wi},wi是一個(gè)詞,i是該詞在T中的位置.
在Moodlens系統(tǒng)中,用簡(jiǎn)單的樸素貝葉斯法構(gòu)建分類器,僅需少量的訓(xùn)練時(shí)間即可得到分類結(jié)果.從標(biāo)記的微博中可以獲得單詞wi屬于情緒類別cj的先驗(yàn)概率:
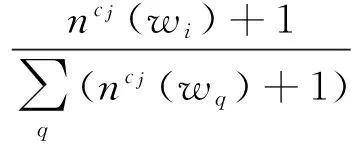
(1)
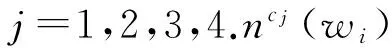
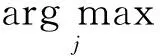
(2)
其中,P(cj)是cj的先驗(yàn)概率.文獻(xiàn)[83]中使用標(biāo)準(zhǔn)詞袋作為特征,設(shè)置訓(xùn)練集與總微博數(shù)據(jù)集的比例ft=0.9,P(cj)=0.25,從而得到一個(gè)樸素貝葉斯分類器.Moodlens還實(shí)現(xiàn)了增量學(xué)習(xí)的方法,可以解決情緒轉(zhuǎn)變以及新詞的問(wèn)題.應(yīng)用該系統(tǒng)可以有效地檢測(cè)異常事件.最后,通過(guò)使用高效的貝葉斯分類器,Moodlens可以實(shí)現(xiàn)在線實(shí)時(shí)情緒監(jiān)控.使用該系統(tǒng)對(duì)實(shí)時(shí)新浪微博數(shù)據(jù)進(jìn)行測(cè)試,其準(zhǔn)確率可達(dá)64.3%.
此后,Ouyang等人[84]提出了一種基于卷積神經(jīng)網(wǎng)絡(luò)的情緒分類架構(gòu).該架構(gòu)使用Google word2vec方法從文本中提取詞向量,并將其作為卷積神經(jīng)網(wǎng)絡(luò)的輸入.通過(guò)一個(gè)基于3對(duì)卷積層和池化層的卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)對(duì)影評(píng)語(yǔ)料進(jìn)行情緒分類.在電影評(píng)論語(yǔ)料庫(kù)(rottentomatoes.com)的實(shí)驗(yàn)中,將該架構(gòu)與遞歸神經(jīng)網(wǎng)絡(luò)和矩陣向量遞歸神經(jīng)網(wǎng)絡(luò)等其他的神經(jīng)網(wǎng)絡(luò)模型對(duì)比,該方案在5類情緒分類任務(wù)中表現(xiàn)良好,準(zhǔn)確率達(dá)到45.4%.
詞級(jí)特征可以將大多數(shù)信息表示成詞向量形式,并且可以較方便地衡量2個(gè)詞之間的相似度,在情緒分類任務(wù)中具有難以替代的作用.然而,句子中的詞語(yǔ)并非詞匯的堆砌,不同的句法會(huì)帶來(lái)完全不同的情緒表達(dá),詞級(jí)特征缺乏對(duì)文本語(yǔ)料整體上的考慮,在復(fù)雜句式中對(duì)情緒的分類并不理想.
隨著深度學(xué)習(xí)方法的興起,許多研究者開(kāi)始將其應(yīng)用于文本情緒分析工作中.通過(guò)構(gòu)建多隱層的模型,深度學(xué)習(xí)可以提取更深層的句子級(jí)特征,從而提高文本分類的準(zhǔn)確率.Santos等人[85]提出一種基于字符到句子的卷積神經(jīng)網(wǎng)絡(luò)情緒分類方法(character to sentence convolutional neural network, CharSCNN),該方法利用一個(gè)含有雙卷積層的神經(jīng)網(wǎng)絡(luò),從字符、詞和句子級(jí)別的信息中分別抽取特征.該方法在斯坦福影評(píng)情感樹(shù)庫(kù)(SSTb)的5種情緒分類任務(wù)中,平均準(zhǔn)確率可達(dá)48.3%.
此外,部分研究者將遞歸神經(jīng)網(wǎng)絡(luò)也引入到情緒分類的工作中.由于普通的遞歸神經(jīng)網(wǎng)絡(luò)缺乏層級(jí)表示能力,Irsoy等人[86]提出了一種基于深度遞歸神經(jīng)網(wǎng)絡(luò)的情緒分類方法.該方法將3個(gè)遞歸層疊加,利用非線性遞歸信息構(gòu)成一個(gè)樹(shù)型結(jié)構(gòu),遞歸計(jì)算每個(gè)節(jié)點(diǎn)的貢獻(xiàn)值.該方法在斯坦福情感樹(shù)庫(kù)(SSTb)上的5種情緒分類任務(wù)中,分類效果略優(yōu)于文獻(xiàn)[85],平均準(zhǔn)確率可達(dá)49.8%.
句子級(jí)特征在表達(dá)整體情緒時(shí)的優(yōu)秀表現(xiàn),引發(fā)了研究者們向更高級(jí)情緒特征的思考,一些研究者們開(kāi)始著手研究篇章級(jí)的情緒特征.Kang等人[87]從情緒空間的角度對(duì)情緒表達(dá)的作用進(jìn)行了分析.該方法利用在中文情緒語(yǔ)料(Ren-CECPs)中抽取的8種情緒標(biāo)記:exception,joy,love,surprise,anxiety,sorrow,anger,hate構(gòu)成8維情緒空間.根據(jù)這8種情緒所構(gòu)成的矩陣空間描述情感成分(詞,詞匯),將這些情緒成分通過(guò)內(nèi)積的形式構(gòu)成更高級(jí)(句子,篇章)的情緒矩陣,利用SVM對(duì)中文語(yǔ)料(Ren-CECPs)進(jìn)行情緒分類.在中文博客9類情緒分類的實(shí)驗(yàn)中,該方法的F值可達(dá)39.24%.
此后,Rao等人[88]提出一種基于主題的篇章級(jí)情緒分析方法.該方法通過(guò)潛在主題建模、多種情緒標(biāo)簽和眾多讀者共同標(biāo)記來(lái)生成主題的特征.其中最大熵的過(guò)度擬合問(wèn)題也通過(guò)將特征映射到概念空間得到緩解.在實(shí)際數(shù)據(jù)集(包括BBC論壇博客、頂客網(wǎng)的博客、MySpace評(píng)論、Runners World論壇的博客、Twitter微博以及YouTube的評(píng)論)的實(shí)驗(yàn)中,驗(yàn)證了該方法在長(zhǎng)文本和短文本情緒分類上同樣有效,準(zhǔn)確率可達(dá)86.06%.
另一種情緒分析問(wèn)題是因?yàn)槲谋菊Z(yǔ)料往往會(huì)涉及多個(gè)屬性,文本情緒分類可以僅僅看作是多標(biāo)簽分類任務(wù)中的一個(gè)屬性,結(jié)合情緒屬性和其他相關(guān)屬性,可以有效提高情緒分類的準(zhǔn)確率.Huang等人[89]提出了一個(gè)基于多任務(wù)的情緒分類方法.該方法在按照情緒分類的同時(shí)也進(jìn)行基于主題的分類,對(duì)于每個(gè)任務(wù)用多個(gè)標(biāo)簽進(jìn)行訓(xùn)練,有助于解決類歧義的問(wèn)題.對(duì)真實(shí)的Twitter數(shù)據(jù)試驗(yàn)中,該方法準(zhǔn)確率要高于樸素貝葉斯、SVM和最大熵模型,可達(dá)到74.4%.
此后,Zhang等人[90]結(jié)合了情緒與社會(huì)領(lǐng)域知識(shí)2個(gè)重要指標(biāo),提出了一種基于因子圖算法(factor graph)的情緒分類模型.該方法通過(guò)觀察帶注釋的Twitter數(shù)據(jù)集,歸納出影響用戶情緒的2個(gè)主要因素:情緒相關(guān)性和社會(huì)相關(guān)性.并將這2個(gè)因素作為特征,相較于決策樹(shù)、SVM和邏輯回歸等基準(zhǔn)方法,該方法使用因子圖算法取得了較好的分類效果,準(zhǔn)確率可達(dá)72%.
總體上,基于有監(jiān)督學(xué)習(xí)的方法在準(zhǔn)確率上優(yōu)于基于詞典和規(guī)則的方法,但對(duì)樣本數(shù)據(jù)的質(zhì)量要求較高,需要花費(fèi)巨大的時(shí)間成本和人力成本對(duì)語(yǔ)料進(jìn)行標(biāo)注,影響了該方法的推廣.
3.2.2 半監(jiān)督學(xué)習(xí)分類方法
隨著大數(shù)據(jù)時(shí)代的到來(lái),數(shù)據(jù)的采集變得比以往任何時(shí)候都容易,標(biāo)記數(shù)據(jù)卻成為了有監(jiān)督學(xué)習(xí)方法的瓶頸,半監(jiān)督學(xué)習(xí)方法可以充分利用大量的未標(biāo)記樣本改善分類器性能,在情緒分類任務(wù)中扮演著重要的角色,研究者們對(duì)此開(kāi)展了大量研究.
半監(jiān)督學(xué)習(xí)方法主要利用少量標(biāo)記數(shù)據(jù)對(duì)訓(xùn)練樣本進(jìn)行初始化,Sun等人[91]將表情符號(hào)與一元特征、二元特征結(jié)合起來(lái),提出了一種面向中文微博的半監(jiān)督情緒分類方法.該方法利用表情符號(hào)對(duì)未標(biāo)記數(shù)據(jù)進(jìn)行初始化,將語(yǔ)句中所含表情符號(hào)最多的一類標(biāo)記為該語(yǔ)句的情緒標(biāo)簽;再通過(guò)提取語(yǔ)句中詞語(yǔ)的一元特征與二元特征,用SVM與樸素貝葉斯分類器將微博中表達(dá)的情緒分為7種類別:樂(lè)、喜、悲、怒、恐、惡、驚.實(shí)驗(yàn)表明情緒自動(dòng)標(biāo)記的準(zhǔn)確率可達(dá)到88.7%,情緒分類中樸素貝葉斯分類器要優(yōu)于SVM,其精準(zhǔn)率和召回率都超過(guò)71%.
此后,Sintsova等人[92]提出一種基于多項(xiàng)貝葉斯的半監(jiān)督情緒分類方法.該方法首先將根據(jù)情緒詞典將未標(biāo)記的數(shù)據(jù)分為36個(gè)情緒類別,并根據(jù)每個(gè)文本中選出的最突出標(biāo)簽對(duì)標(biāo)注進(jìn)行改進(jìn);然后從文本中抽取n-grams特征并過(guò)濾無(wú)關(guān)信息;最后利用重新平衡的偽標(biāo)記數(shù)據(jù)和多項(xiàng)貝葉斯分類器對(duì)微博語(yǔ)料進(jìn)行分類.該方法在Twitter語(yǔ)料庫(kù)的實(shí)驗(yàn)中F1值可達(dá)到20.2%.
另一部分研究者將半監(jiān)督學(xué)習(xí)與Ekman,Plutchik等情緒分類體系相結(jié)合,利用心理學(xué)情緒分類知識(shí)對(duì)訓(xùn)練樣本進(jìn)行初始化.Purver等人[93]提出一種半監(jiān)督學(xué)習(xí)與Ekman分類體系相結(jié)合的情緒分類方法.該方法采用少量人工選取的標(biāo)簽(hashtag)和情感符(emoticon)來(lái)自動(dòng)標(biāo)注微博情緒,以省去大量手工標(biāo)注語(yǔ)料的過(guò)程.在Twitter語(yǔ)料的實(shí)驗(yàn)中,利用hashtag分類的準(zhǔn)確率可達(dá)67.4%以上,利用emoticon分類的準(zhǔn)確率可達(dá)75.2%以上.然而,該方法對(duì)恐懼、驚訝和憎惡(fear,surprise,disgust)3類情緒的區(qū)分度不高,因?yàn)橛?xùn)練語(yǔ)料中標(biāo)簽和情感符的意思含糊,對(duì)區(qū)分情緒起到了干擾.
在此基礎(chǔ)上,Suttles等人[94]也提出了一種基于離散二進(jìn)制半監(jiān)督學(xué)習(xí)的情緒分類方法.與文獻(xiàn)[93]的研究不同,該方法根據(jù)Plutchik的情緒輪進(jìn)行情緒分類,把固有的多層次情緒分類問(wèn)題轉(zhuǎn)換成一個(gè)含有4組對(duì)立情感的二進(jìn)制問(wèn)題,選取情感符號(hào)(emoticon)、標(biāo)簽以及表情符(emoji)作為參考進(jìn)行人工標(biāo)記.該方法首先提取不同類型的特定標(biāo)簽,并將表示相同情緒類別的標(biāo)簽進(jìn)行歸類,然后對(duì)比每個(gè)獨(dú)立的二元分類器的準(zhǔn)確性.在Twitter微博數(shù)據(jù)測(cè)試中,該方法的分類準(zhǔn)確率最高可達(dá)91%.
此后,Jiang等人[95]提出一種基于表情符號(hào)空間模型(emoticon space model)的半監(jiān)督情緒分類方法,該方法利用表情符號(hào)從未標(biāo)記的數(shù)據(jù)中構(gòu)建詞向量,通過(guò)將詞和微博映射到表情符號(hào)空間來(lái)確定微博的主觀性、極性和情緒.在中文微博基準(zhǔn)語(yǔ)料庫(kù)(NLP&&CC 2013)實(shí)驗(yàn)中,該方法的情緒分類準(zhǔn)確率優(yōu)于SVM及樸素貝葉斯,可達(dá)61.7%.
在文本情緒分類任務(wù)中,有很多情況下需要對(duì)讀者評(píng)論中的情緒進(jìn)行分析,而讀者評(píng)論又與源文本之間存在緊密的聯(lián)系.針對(duì)該現(xiàn)象,Li等人[96]提出一種基于雙視圖標(biāo)簽傳播的半監(jiān)督方法,對(duì)讀者評(píng)論中的情緒進(jìn)行分類.該方法先通過(guò)詞袋、二元特征提取文本中的情緒信息,再通過(guò)雙視圖提取文本之間的對(duì)應(yīng)關(guān)系.雙視圖依賴于2個(gè)圖關(guān)系:包括源文本之間的關(guān)系以及評(píng)論文本之間的關(guān)系.此外還將源文本與相應(yīng)評(píng)論文本之間的依賴關(guān)系集成到這2個(gè)圖中.最后在源文本和評(píng)論文本之間配置一個(gè)權(quán)重以處理評(píng)論文本中信息的不足.該方法在Yahoo Kimo News語(yǔ)料的情緒分類實(shí)驗(yàn)中,準(zhǔn)確率可達(dá)74.5%.
該類方法的優(yōu)點(diǎn)在于可以較方便地獲得大量的標(biāo)記數(shù)據(jù)用以訓(xùn)練樣本集,解決了有標(biāo)記數(shù)據(jù)集稀缺的問(wèn)題.然而,該類在第1次分類過(guò)程中分錯(cuò)的樣本,會(huì)影響到第2次分類的準(zhǔn)確率.
3.3 復(fù)合情緒分類方法
由于前2種分類方法的優(yōu)缺點(diǎn)都很明顯,一些研究者開(kāi)始考慮綜合2種方法,吸取各自方法的優(yōu)點(diǎn).這些復(fù)合分類方法主要分為2類,其中一類是將情緒分類任務(wù)分解成有無(wú)情緒、正負(fù)情感、細(xì)粒度情緒等子任務(wù),再分別針對(duì)不同子任務(wù)設(shè)計(jì)不同算法的層次情緒分類方法.
情緒分類中,類別之間不是互相獨(dú)立的,它們之間有一定層次關(guān)系.基于層次結(jié)構(gòu)的復(fù)合方法就是利用這種層次關(guān)系,提高情緒分類的準(zhǔn)確率.Ghazi等人[97]提出一種基于層次情緒分類的方法,該方法包含3層結(jié)構(gòu):1)第1層定義文本是否包含情感;2)第2層對(duì)第1層中有情感的文本進(jìn)行正負(fù)劃分;3)第3層將第2層的正類劃為happiness,負(fù)類細(xì)化為sadness,fear,anger,disgust,surprise.該方法有助于粗粒度到細(xì)粒度的分類,在格林童話上分類的準(zhǔn)確率可達(dá)60%以上.
在此基礎(chǔ)上,Esmin等人[98]提出一種面向短文本的層次情緒分類方法.該方法仍將第1層用來(lái)確定文本是否含有情緒;第2層對(duì)上一層有情緒的文本做極性分類,其中僅happiness是正類;第3層將負(fù)類分為sadness,fear,surprise,disgust,anger,最終利用Multiclass SVM分類器對(duì)微博語(yǔ)料進(jìn)行分析.在Twitter語(yǔ)料庫(kù)的情緒分類實(shí)驗(yàn)中,該方法的平均準(zhǔn)確率達(dá)63.2%.
此后,Xu等人[99]也用層級(jí)分類法對(duì)中文微博進(jìn)行了情緒分類,同時(shí)還將主成分分析法引入到情緒分類中,計(jì)算微博中主要情緒的比例.該方法采用4層結(jié)構(gòu),將情緒細(xì)分為19種類別.在新浪微博數(shù)據(jù)上進(jìn)行了4層實(shí)驗(yàn),其中第1層只采用平面型文本分類;第2層與第1層不同,采取了層級(jí)分類;第3層在第2層的基礎(chǔ)上加入了詞性特征;第4層在第3層的基礎(chǔ)上還加入了心理學(xué)情緒詞典.通過(guò)第1層對(duì)文本是否有情感信息的分類和第2層正、負(fù)情感的分類,將無(wú)關(guān)的文本剔除,使后續(xù)分類工作更加容易.在層級(jí)分類的實(shí)驗(yàn)中,第3層的分類準(zhǔn)確率可以達(dá)到90%左右,其4層層級(jí)結(jié)構(gòu)如圖5所示:

Fig. 5 Four-level hierarchy圖5 4層層級(jí)結(jié)構(gòu)
由于微博語(yǔ)料通常是隱式的、不平衡的,為解決該問(wèn)題,Zhang等人[100]提出了一種基于主題模型的層級(jí)情緒分類法.該方法先對(duì)微博語(yǔ)料進(jìn)行去除無(wú)關(guān)信息的預(yù)處理;然后根據(jù)主題模型進(jìn)行特征選擇,用選出的特征詞和情緒詞典構(gòu)成(情緒,情緒指示)關(guān)聯(lián),識(shí)別隱含的情緒;最后構(gòu)造一個(gè)樹(shù)結(jié)構(gòu)的層級(jí)分類器對(duì)微博進(jìn)行分類.該方法在新浪微博語(yǔ)料庫(kù)的情緒分類實(shí)驗(yàn)中,F(xiàn)值可達(dá)70%.
該類通過(guò)將情緒分類任務(wù)分解成較為有無(wú)情感檢測(cè)、情感分類、細(xì)粒度情緒等子任務(wù),利用更為成熟的主客觀檢測(cè)、情感分類的技術(shù)對(duì)樣本進(jìn)行預(yù)分類,從而降低情緒分類的難度.
另一類基于子類的復(fù)合方法是將語(yǔ)料庫(kù)先分為更細(xì)致的子類,再利用分好的子類對(duì)樣本進(jìn)行分析,從而獲得最終的情緒分類.Keshtkar等人[101]也提出了一種基于層次的心情分類方法.該方法對(duì)博客的心情進(jìn)行分類,總共分為132類,但是情緒與心情有所區(qū)別,情緒持續(xù)的時(shí)間比心情的要短,二者之間的層次結(jié)構(gòu)和分類任務(wù)并不相同.此后,劉寶芹等人[102]在文獻(xiàn)[101]的基礎(chǔ)上,根據(jù)Ekman的6類情緒理論中情感極性與情緒間的相互關(guān)系,為6類情緒建立了3層樹(shù)狀結(jié)構(gòu),并利用該結(jié)構(gòu)對(duì)不同話題微博的情緒進(jìn)行自動(dòng)分析.在新浪微博的情緒分類實(shí)驗(yàn)中,該方法比傳統(tǒng)的貝葉斯方法情緒識(shí)別精度更高,同時(shí)還降低了情緒數(shù)據(jù)分布不均衡對(duì)結(jié)果的影響,該方法在6種情緒分類任務(wù)中,平均精準(zhǔn)率可達(dá)70.6%.
此后,歐陽(yáng)純萍等人[103]提出一種基于情緒詞匯本體的多種有監(jiān)督學(xué)習(xí)復(fù)合方法.該方法使用樸素貝葉斯算法對(duì)微博是否有情緒進(jìn)行預(yù)分類,并根據(jù)分類結(jié)果對(duì)情緒進(jìn)行精確分析.該方法首先將情感詞匯本體庫(kù)的7種類別細(xì)分為21小類(快樂(lè)、安心、尊敬等),并把這21小類作為每條微博的最終特征,分別采用SVM和kNN(k-nearest neighbors)算法對(duì)預(yù)分類后的新浪微博數(shù)據(jù)集進(jìn)行細(xì)粒度情緒分類.在2013年CCF自然語(yǔ)言處理與中文計(jì)算機(jī)會(huì)議的中文微博情緒分析評(píng)測(cè)任務(wù)中,該方法相較于單純使用SVM和kNN分類器,其F值提高近11%,其對(duì)情緒判別的準(zhǔn)確率可達(dá)72.71%,表現(xiàn)優(yōu)于單一分類算法.
歸納上述3類方法,主要是針對(duì)極性或單一情緒標(biāo)簽分類,忽略了情緒標(biāo)簽在實(shí)例中多情緒共存的情況.因此,情緒分析與傳統(tǒng)的情感分析相比,從另一個(gè)維度還可以看作是一個(gè)多標(biāo)簽情緒分類問(wèn)題.
3.4 其他情緒分類方法
傳統(tǒng)的情緒分析方法很少認(rèn)為一個(gè)文本可以同時(shí)表達(dá)多種情緒,而事實(shí)中一條語(yǔ)料可能出現(xiàn)有多種情緒共存的情況.為了更準(zhǔn)確地把握文本中所表達(dá)的情緒信息,研究者們從另一個(gè)新的維度出發(fā),開(kāi)展了基于多標(biāo)簽情緒分類的研究.
Yang等人[104]提出了一種多標(biāo)簽情緒分類方法.該方法利用表情符號(hào)、標(biāo)點(diǎn)符號(hào)和小型詞典對(duì)數(shù)據(jù)進(jìn)行標(biāo)記,再用多標(biāo)簽情緒分類(multi-label emotion classification, MEC)算法對(duì)微博進(jìn)行分類.MEC算法同時(shí)考慮文本級(jí)和詞級(jí)信息,先用kNN收集特定微博的情緒信息,再利用樸素貝葉斯計(jì)算微博在詞語(yǔ)層面屬于任何一個(gè)情緒類別的概率,最后設(shè)置一個(gè)閾值抽取微博的情緒標(biāo)簽.準(zhǔn)確率最高83.6%.
此后,Buitinck等人[105]提出了一種面向影評(píng)的多標(biāo)簽情緒檢測(cè)系統(tǒng).該方法先通過(guò)詞袋和篇章特征將句子標(biāo)記為預(yù)設(shè)情緒標(biāo)簽集的一個(gè)子集,然后分別用one-vs.-rest SVM和RAKEL方法對(duì)文本進(jìn)行分類.在IMDB影評(píng)數(shù)據(jù)集的實(shí)驗(yàn)中,RAKEL分類器的表現(xiàn)最好,因?yàn)槎鄻?biāo)簽分類相較于單標(biāo)簽分類器,分類規(guī)則更加復(fù)雜,評(píng)價(jià)標(biāo)準(zhǔn)除準(zhǔn)確率外,常用的指標(biāo)還有漢明損失(hamming loss,HL)、平均精度(average precision,AP)、1-錯(cuò)誤率(one error,OE)等,其平均準(zhǔn)確率可達(dá)84.1%,HL為11.2%,AP為89.8%,OE為24.6%.
在此基礎(chǔ)上,Liu等人[106]提出了一種基于多標(biāo)簽的情緒分類方法.該方法利用DUTSD,NTUSD,Hownet這3個(gè)情緒詞典提取微博語(yǔ)料中的情緒特征和原始分割詞特征,通過(guò)與MLkNN (multi-labelk-nearest neighbors),BRkNN (binary relevancek-nearest neighbors)等使用kNN算法的基準(zhǔn)方法做對(duì)比,發(fā)現(xiàn)CLR (calibrated label ranking)分類效果最好,其平均準(zhǔn)確率可達(dá)65.5%,HL為16.7%,AP為76.6%,OE為37.3%.
因?yàn)橐粋€(gè)句子可能包含多種不同強(qiáng)度的情緒,有些情緒可以共存,而有些則不會(huì)同時(shí)出現(xiàn).根據(jù)這一特性,一些研究者在多標(biāo)簽情緒分析工作中加入了情緒強(qiáng)度分布的要素.Wang等人[107]提出了一種多標(biāo)簽情緒分類方法.該方法利用skip-gram語(yǔ)言模型訓(xùn)練詞匯情緒的分布式表達(dá),將微博語(yǔ)句降維成詞向量,并將二者作為卷積神經(jīng)網(wǎng)絡(luò)的輸入,最終使用基于CLR的多標(biāo)簽學(xué)習(xí)方法獲得每條微博的最終情緒標(biāo)簽排序,其流程如圖6所示:
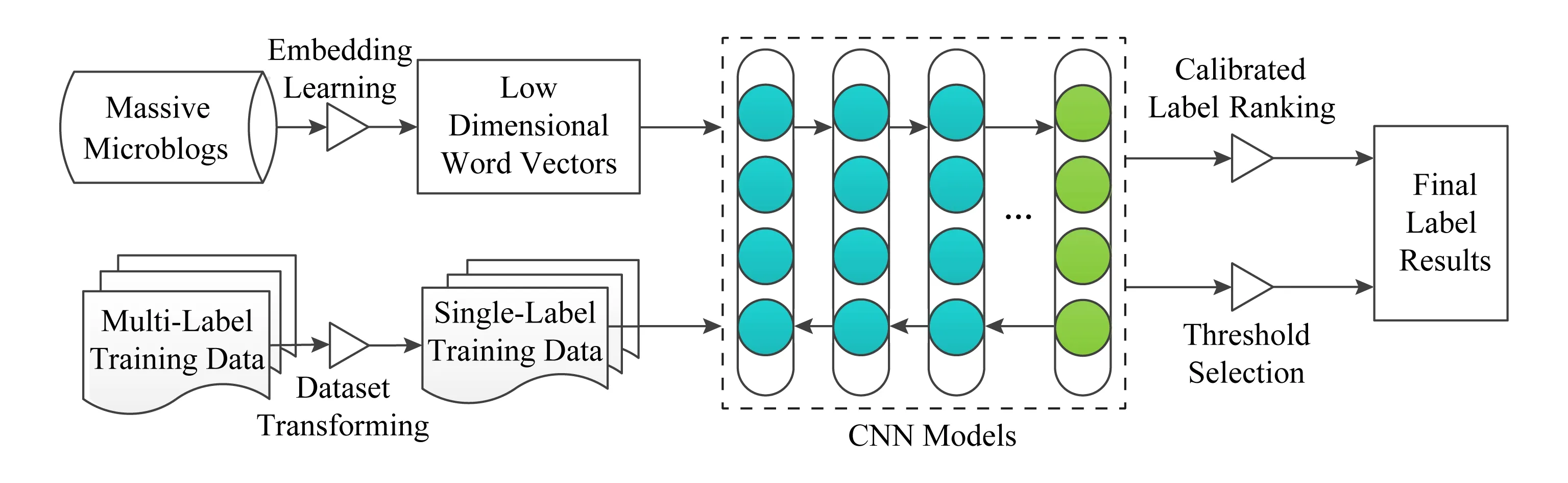
Fig. 6 Multi-label emotion classification based on CLR圖6 基于CLR的多標(biāo)簽情緒分類方法
該方法在NLPCC 2014情緒分析語(yǔ)料EACWT和Ren-CECPs語(yǔ)料的實(shí)驗(yàn)中,平均準(zhǔn)確率分別為75.56%和63.20%,HL分別為19.58%和31.64%,AP分別為75.56%和63.2%,OE為26.28%和43.52%.
針對(duì)現(xiàn)有語(yǔ)料庫(kù)中情緒類別不平衡的特征,Li等人[108]提出了一種基于最大熵(multi-label maxi-mum entropy, MME)短文本情緒分布檢測(cè)方法.該方法利用最大熵原理估計(jì)詞與社會(huì)情緒之間的關(guān)系,為了提高在新聞、微博等多種規(guī)模語(yǔ)料庫(kù)中的預(yù)測(cè)能力,引入了L-BFGS算法來(lái)緩解約束.該方法在Semeval,SSTweet,ISEAR這3個(gè)語(yǔ)料庫(kù)上的F1值分別為36.96%,90.30%,54.86%.
在此基礎(chǔ)上,Zhou等人[109]提出一種基于情緒分布學(xué)習(xí)的分類方法.該方法設(shè)計(jì)了一個(gè)從句子到情緒分布的映射函數(shù),用以描述多重情緒和它們各自的強(qiáng)度,并引入Plutchik情緒輪理論以提高情緒檢測(cè)的準(zhǔn)確率.該方法在中文博客Ren-CECPs語(yǔ)料庫(kù)的實(shí)驗(yàn)中,其平均準(zhǔn)確率可達(dá)66.54%,HL為17.72%,AP為64.10%,OE為52.39%.
由于篇章級(jí)語(yǔ)料上下文信息對(duì)情緒分布有著很大的影響,Xu等人[110]提出一種迭代多標(biāo)記的情緒分布檢測(cè)方法,該方法利用句子內(nèi)部特征(intra-sentence features)對(duì)句子進(jìn)行初始分類,結(jié)合上下文信息,根據(jù)初始分類結(jié)果與整篇微博情緒類別的轉(zhuǎn)移概率,綜合考慮轉(zhuǎn)移概率、ML-kNN和隨機(jī)多標(biāo)簽RAKEL(randomk-labelsets)這3種多標(biāo)簽分類器的分類結(jié)果,最終獲得該微博的情緒分布.在中文微博情緒分類數(shù)據(jù)集(包含14 000條微博、45 431個(gè)句子)的實(shí)驗(yàn)中,對(duì)7種情緒happiness,like,anger,sadness,fear,disgust,surprise分類的平均準(zhǔn)確率可達(dá)83.26%.
雖然基于多情緒標(biāo)簽的分類方法的復(fù)雜性和難度都比較高,且該研究方向才剛剛起步,但其應(yīng)用前景較好,將會(huì)成為一個(gè)新的研究熱點(diǎn).表2對(duì)4種主流的情緒分類方法進(jìn)行了概括和對(duì)比分析.
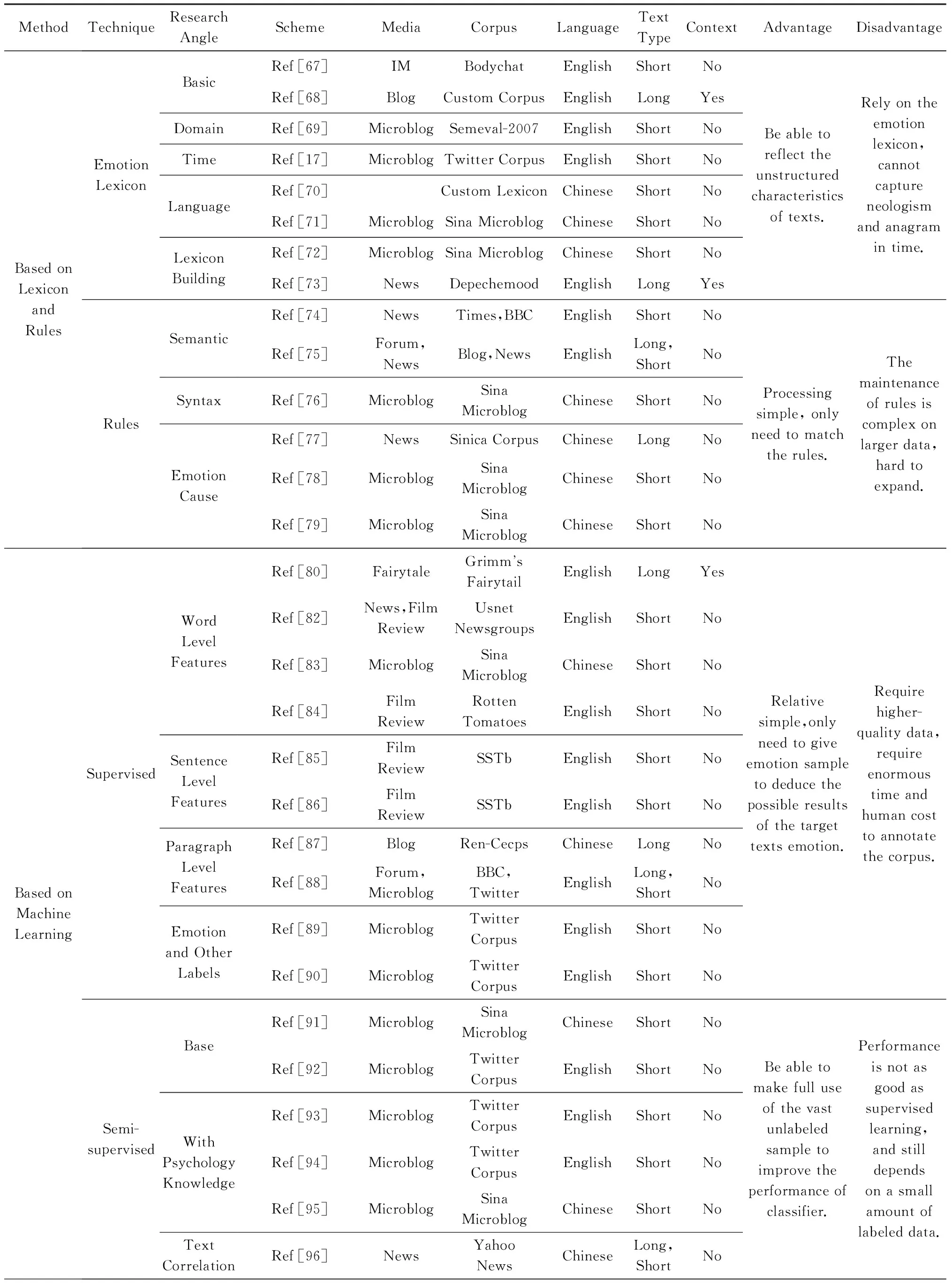
Table 2 Comparison of Emotion Analysis Methods

Table 2 (Continued)
4 研究展望
目前針對(duì)文本情緒分析的研究已經(jīng)取得了一定的成果,但該研究領(lǐng)域還處于一個(gè)相對(duì)年輕的階段.文本情緒分析技術(shù)在理論和應(yīng)用上都還存在一些挑戰(zhàn)以及新的方向需要進(jìn)一步研究探討.
4.1 面臨的挑戰(zhàn)
當(dāng)前文本情緒分析研究面臨來(lái)自多方面的挑戰(zhàn),主要包括:數(shù)據(jù)稀缺性,無(wú)論是情緒訓(xùn)練語(yǔ)料還是情緒詞典資源,都處于比較匱乏的階段;類別不平衡,收集到的樣本中情緒各類別的數(shù)量明顯存在差異;領(lǐng)域依賴性,情緒詞在不同領(lǐng)域的表達(dá)存在差異;語(yǔ)言不平衡,當(dāng)前大多數(shù)工作都基于英文語(yǔ)料,語(yǔ)言遷移存在困難.
1) 數(shù)據(jù)稀缺性
文本情緒分析主要包括基于情緒詞典和規(guī)則的方法、基于機(jī)器學(xué)習(xí)的方法.然而,無(wú)論是哪種方法,數(shù)據(jù)都很稀缺.在基于詞典的方法中,情緒詞典很難獲取資源,目前尚無(wú)公開(kāi)的情緒詞典可用.此外,即使有開(kāi)源的情緒詞典,由于網(wǎng)絡(luò)新詞層出不窮,需要不斷對(duì)情緒詞典進(jìn)行擴(kuò)充和更新;在基于機(jī)器學(xué)習(xí)的方法中,需要借助有情緒標(biāo)注的語(yǔ)料庫(kù)來(lái)提取特征并訓(xùn)練情緒分類器.然而情緒標(biāo)注語(yǔ)料本身也是稀缺資源,由于不同領(lǐng)域的情緒表達(dá)有不同特點(diǎn),通用的情緒訓(xùn)練語(yǔ)料無(wú)法滿足不同領(lǐng)域研究的需求.
2) 類別不平衡
情感分析的工作已經(jīng)開(kāi)展很多年,目前大多數(shù)工作都假設(shè)正負(fù)樣本是均衡的.情緒分析是在情感分析的基礎(chǔ)上進(jìn)行更細(xì)粒度的分類.然而,不同情緒的數(shù)據(jù)集規(guī)模往往不均衡,在實(shí)際收集的微博語(yǔ)料中,一些情緒類別的語(yǔ)料數(shù)量明顯多于另一些類別,例如表達(dá)喜歡的語(yǔ)料明顯多于表達(dá)害怕的.所以,適用于均衡分類的方法在面對(duì)不均衡數(shù)據(jù)時(shí)效果往往并不理想.樣本數(shù)據(jù)的不平衡分布會(huì)使機(jī)器學(xué)習(xí)方法在進(jìn)行分類時(shí)嚴(yán)重偏向于樣本多的類別,從而影響到分類的性能.
3) 領(lǐng)域依賴性
同一個(gè)詞在不同的領(lǐng)域背景下表達(dá)著不同的情緒,例如“不可預(yù)測(cè)”在電影評(píng)論領(lǐng)域是褒義的,在汽車評(píng)論領(lǐng)域則是貶義的.因此,在進(jìn)行情緒分析時(shí),應(yīng)該充分考慮情緒詞的領(lǐng)域依賴性.跨領(lǐng)域情緒分析是文本情緒分析的一個(gè)重要研究課題,跨領(lǐng)域情緒分析有很多問(wèn)題需要解決.例如,在一個(gè)領(lǐng)域的意見(jiàn)表達(dá),在另一個(gè)領(lǐng)域可能反轉(zhuǎn).此外,還應(yīng)該考慮不同領(lǐng)域情緒詞匯的差異.
4) 語(yǔ)言不平衡
現(xiàn)有情緒分析工作大多基于英文[111],雖然近些年對(duì)中文的情緒分析也有了一定的研究成果[83],但是基于情緒詞典或語(yǔ)義知識(shí)庫(kù)的工作都需依賴特定語(yǔ)種的外部資源,基于英文的情緒分析研究很難遷移到其他語(yǔ)言.此外,由于非英語(yǔ)的情緒分析訓(xùn)練集和測(cè)試集也相對(duì)匱乏,極大限制了非英語(yǔ)語(yǔ)種的情緒分析研究.
4.2 未來(lái)研究方向
當(dāng)不同媒體、不同形態(tài)的情緒信息“融合”在一起,會(huì)隨之產(chǎn)生“質(zhì)變”.與此同時(shí),領(lǐng)域自適應(yīng)、社交網(wǎng)絡(luò)分析和深度學(xué)習(xí)等技術(shù)的發(fā)展,也給文本情緒分析研究指出了新的研究方向.從技術(shù)的發(fā)展趨勢(shì)分析看,未來(lái)文本情緒分析的研究還需要關(guān)注如下4個(gè)方面.
1) 基于多媒體融合的情緒分析
傳統(tǒng)的情緒分析主要關(guān)注文本,然而圖片等多媒體通常可以比文本表達(dá)更明顯的情緒效果,即所謂的“一圖勝千言”.此外,另一種情緒信息表達(dá)的主要載體——語(yǔ)音,也可以很好地反映用戶的當(dāng)前情緒狀態(tài).因此,隨著圖像、音頻等不同類型社交網(wǎng)絡(luò)數(shù)據(jù)的不斷增長(zhǎng),各種類型的用戶數(shù)據(jù)相結(jié)合的研究將具有更好的應(yīng)用前景.
2) 基于領(lǐng)域自適應(yīng)的情緒分析
領(lǐng)域自適應(yīng)技術(shù)可以利用信息豐富的源域資源提升目標(biāo)或模型的性能.傳統(tǒng)情緒分析方法為了克服情緒詞本身具有的領(lǐng)域依賴性,刻意選擇領(lǐng)域無(wú)關(guān)的特征,如表情符號(hào).而領(lǐng)域自適應(yīng)的方法可以充分利用情緒詞在不同領(lǐng)域所表達(dá)的不同情緒,準(zhǔn)確、快速地識(shí)別文本情緒.因此,隨著不同領(lǐng)域情緒語(yǔ)料資源的積累,基于領(lǐng)域自適應(yīng)的情緒分析將逐漸成為一個(gè)新的研究熱點(diǎn).
3) 基于社交網(wǎng)絡(luò)分析的情緒分析
社交網(wǎng)絡(luò)的迅猛發(fā)展,產(chǎn)生了大量的用戶交互數(shù)據(jù),這些數(shù)據(jù)反應(yīng)了用戶的思想、情緒及社交關(guān)系.通過(guò)結(jié)合社交網(wǎng)絡(luò)的關(guān)系分析技術(shù),可以了解不同的社會(huì)群體是如何表達(dá)情緒以及情緒傾向.因此,研究基于社交網(wǎng)絡(luò)分析的情緒分析技術(shù)可以更好地掌握大眾情緒走向,為輿情分析、情緒管理等應(yīng)用提供支撐.
4) 基于深層語(yǔ)義的情緒分析
深度學(xué)習(xí)作為機(jī)器學(xué)習(xí)研究中的一個(gè)新領(lǐng)域,取得了很大的進(jìn)展.在自然語(yǔ)言處理的各項(xiàng)任務(wù)中,深度學(xué)習(xí)也有著許多可喜的成果.隨著計(jì)算能力不斷提高、數(shù)據(jù)量不斷增加,可以預(yù)測(cè)未來(lái)將涌現(xiàn)出更多優(yōu)秀的神經(jīng)網(wǎng)絡(luò)模型.該類方法將在自動(dòng)抽取情緒特征、減少人工標(biāo)記工作等方面做出巨大貢獻(xiàn).另外,在深度學(xué)習(xí)算法中加入一定的策略,可以更好地學(xué)習(xí)詞匯和句子的語(yǔ)義表達(dá),從而實(shí)現(xiàn)理解句子以及整個(gè)文檔的任務(wù).
在此基礎(chǔ)上,隨著互聯(lián)網(wǎng)+時(shí)代的到來(lái),涌現(xiàn)出大數(shù)據(jù)分析、特定主題挖掘、用戶畫(huà)像構(gòu)建和多語(yǔ)言協(xié)同等眾多新的應(yīng)用需求,也給文本情緒分析帶來(lái)了新的機(jī)遇.
1) 面向大數(shù)據(jù)的文本情緒分析
大數(shù)據(jù)技術(shù)的發(fā)展使數(shù)據(jù)的收集變得非常容易且成本低廉,對(duì)海量的信息數(shù)據(jù)進(jìn)行挖掘,可以獲得巨大的產(chǎn)品或服務(wù)價(jià)值.然而收集的數(shù)據(jù)大多以非結(jié)構(gòu)化文本形式存儲(chǔ),在對(duì)文本數(shù)據(jù)進(jìn)行情緒分析時(shí),傳統(tǒng)的概率潛在語(yǔ)義分析方法的時(shí)間復(fù)雜度和空間復(fù)雜度較高,難以滿足訓(xùn)練大規(guī)模數(shù)據(jù)的需求,需要提出面向大數(shù)據(jù)的文本情緒分析方法.
2) 面向特定主題的情緒分析
由于情緒表達(dá)在不同主題下有所不同,無(wú)論是采用有監(jiān)督還是無(wú)監(jiān)督的學(xué)習(xí)方法,情緒分析的準(zhǔn)確率在一定程度上受主題的影響.同樣的短語(yǔ)在不同的主題下,其語(yǔ)言規(guī)則、詞庫(kù)判斷標(biāo)準(zhǔn)都存在不同.現(xiàn)有針對(duì)主題差異的研究工作,在實(shí)際應(yīng)用中仍存在不少問(wèn)題.例如,當(dāng)主題差別過(guò)大時(shí),分析性能會(huì)明顯下降,需要對(duì)跨主題情緒分析的算法和相關(guān)問(wèn)題開(kāi)展進(jìn)一步研究.
3) 面向個(gè)性化的情緒分析
隨著互聯(lián)網(wǎng)+時(shí)代的到來(lái),用戶對(duì)各類應(yīng)用都提出了個(gè)性化的需求,而情緒是一種高度主觀的用戶行為特征,同樣的情緒詞匯根據(jù)不同的用戶歷史情緒變化也會(huì)產(chǎn)生不同的情緒含義及強(qiáng)度.因此,通過(guò)觀察用戶情緒變化曲線,為不同的用戶構(gòu)建情緒畫(huà)像,從而實(shí)現(xiàn)利用有限的信息對(duì)用戶情緒進(jìn)行個(gè)性化精準(zhǔn)分析.
4) 面向多語(yǔ)言的情緒分析
隨著文化交流的增加,多種語(yǔ)言的網(wǎng)絡(luò)信息相互影響與融合.現(xiàn)有工作主要針對(duì)單一語(yǔ)言,而在單一語(yǔ)言情緒分析中所收集到的語(yǔ)料資源與成果,無(wú)法在多語(yǔ)言的環(huán)境中直接使用;此外,不同語(yǔ)言情緒分析的語(yǔ)料資源也存在不均衡性,難以在跨語(yǔ)言的環(huán)境中直接使用.在解決情緒分析任務(wù)的基本問(wèn)題外,還需要考慮機(jī)器翻譯、多語(yǔ)言文本處理等工作,這都對(duì)多語(yǔ)言情緒分析提出了新的需求.
5 總 結(jié)
本文對(duì)文本情緒分析研究進(jìn)行了綜述,概括了情緒分類的心理學(xué)模型和情緒分析的應(yīng)用場(chǎng)景,重點(diǎn)對(duì)主流的情感/情緒分析方法進(jìn)行了介紹和對(duì)比,最后總結(jié)了現(xiàn)有工作主要存在的問(wèn)題,并對(duì)將來(lái)的研究工作進(jìn)行了展望.
文本情緒分析作為自然語(yǔ)言處理和文本挖掘中一個(gè)新興的研究方向,有著很廣泛的應(yīng)用前景.情感分析的研究已經(jīng)比較成熟,而情緒分析的研究尚處于起步階段,且國(guó)內(nèi)研究較少.
可以預(yù)見(jiàn),在未來(lái)的文本挖掘研究中,將會(huì)涌現(xiàn)大量情緒分析的相關(guān)工作.
[1] Lin Chuanding. Emotional problems in socialist psychology[J]. Science of Social Psychology, 2006, 21(83): 37-62 (in Chinese)
(林傳鼎. 社會(huì)主義心理學(xué)中的情緒問(wèn)題[J]. 社會(huì)心理科學(xué), 2006, 21(83): 37-62)
[2] Ekman P. An argument for basic emotions[J]. Cognition and Emotion, 1992, 6(3/4): 169-200
[3] Plutchik R. The nature of emotions[J]. Philosophical Studies, 2001, 89(4): 393-409
[4] Egges A, Kshirsagar S, Magnenat-Thalmann N. A model for personality and emotion simulation[C] //Proc of the 7th Int Conf on Knowledge-Based and Intelligent Information and Engineering Systems. Berlin: Springer, 2003: 453-461
[5] Zhao Jichun, Wang Zhiliang, Wang Chao. Study on emotion model building and virtual feeling robot[J]. Computer Engineering, 2007, 33(1): 212-215 (in Chinese)
(趙積春, 王志良, 王超. 情緒建模與情感虛擬人研究[J]. 計(jì)算機(jī)工程, 2007, 33(1): 212-215)
[6] Ortony A, Clore G, Collins A. The cognitive structure of emotions[J]. The Quarterly Review of Biology, 1990, 18(65): 2147-2153
[7] Parrott W G. Emotions in Social Psychology: Essential Readings[M]. Oxford, UK: Psychology Press, 2001
[8] Zhao Yanyan, Qin Bing, Liu Ting. Sentiment analysis[J]. Journal of Software, 2010, 21(8): 1834-1848 (in Chinese)
(趙妍妍, 秦兵, 劉挺. 文本情感分析[J]. 軟件學(xué)報(bào), 2010, 21(8): 1834-1848)
[9] Hao Yazhou, Zheng Qinghua, Chen Yanping, et al. Recognition of abnormal behavior based on data of public opinion on the Web[J]. Journal of Computer Research and Development, 2016, 53(3): 611-620 (in Chinese)
(郝亞洲, 鄭慶華, 陳艷平, 等. 面向網(wǎng)絡(luò)輿情數(shù)據(jù)的異常行為識(shí)別[J]. 計(jì)算機(jī)研究與發(fā)展, 2016, 53(3): 611-620)
[10] Mishne G. Experiments with mood classification in blog posts[C] //Proc of the 28th ACM SIGIR Workshop on Stylistic Analysis of Text for Information Access. New York: ACM, 2005: 321-327
[11] Mohammad S. From once upon a time to happily ever after: Tracking emotions in novels and fairy tales[C] //Proc of the 5th Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities. Stroudsburg, PA: ACL, 2011: 105-114
[12] Bollen J, Mao H, Zeng X. Twitter mood predicts the stock market[J]. Journal of Computational Science, 2011, 2(1): 1-8
[13] Devitt A, Ahmad K. Sentiment polarity identification in financial news: A cohesion-based approach[C] //Proc of the 45th Association of Computational Linguistics. Stroudsburg, PA: ACL, 2007: 25-27
[14] Tumasjan A, Sprenger T O, Sandner P G, et al. Predicting elections with Twitter: What 140 characters reveal about political sentiment[C] //Proc of the 4th Int AAAI Conf on Weblogs and Social Media. Menlo Park, CA: AAAI, 2010: 178-185
[15] Kim S M, Hovy E H. Crystal: Analyzing predictive opinions on the Web[C] //Proc of the 4th Joint Conf on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg, PA: ACL, 2007: 1056-1064
[16] Ceron A, Curini L, Iacus S M, et al. Every tweet counts? How sentiment analysis of social media can improve our knowledge of citizens’ political preferences with an application to Italy and France[J]. New Media and Society, 2014, 16(2): 340-358
[17] Golder S A, Macy M W. Diurnal and seasonal mood vary with work, sleep, and daylength across diverse cultures[J]. Science, 2011, 333(6051): 1878-1881
[18] Kim S, Lee J, Lebanon G, et al. Estimating temporal dynamics of human emotions[C] //Proc of the 29th Int AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 168-174
[19] Zhou Xinjie, Wan Xiaojun, Xiao Jianguo. Collective opinion target extraction in Chinese microblogs[C] //Proc of the 10th Conf on Empirical Methods on Natural Language Processing. Stroudsburg, PA: ACL, 2013: 1840-1850
[20] Huang Xuanjing, Zhang Qi, Wu Yuanbin. A survey on sentiment analysis[J]. Journal of Chinese Information Processing, 2011, 25(6): 118-127 (in Chinese)
(黃萱菁, 張奇, 吳苑斌. 文本情感傾向分析[J]. 中文信息學(xué)報(bào), 2011, 25(6): 118-127)
[21] Kim S M, Hovy E. Extracting opinions, opinion holders, and topics expressed in online news media text[C] //Proc of the 44th Workshop on Sentiment and Subjectivity in Text. Stroudsburg, PA: ACL, 2006: 1-8
[22] Carstens L, Toni F. Enhancing sentiment extraction from text by means of arguments[C] //Proc of the 2nd Int Workshop on Issues of Sentiment Discovery and Opinion Mining. New York: ACM, 2013: 1-9
[23] Eirinaki M, Pisal S, Singh J. Feature-based opinion mining and ranking[J]. Journal of Computer and System Sciences, 2012, 78(4): 1175-1184
[24] Yu Long, Duan Xiangchao, Tian Shengwei, et al. Topic extraction based on product reviews[J]. Journal of Computational Information Systems, 2013, 9(2): 773-780
[25] Dai Min, Wang Rongyang, Li Shoushan, et al. Opinion target extraction with syntactic features[J]. Journal of Chinese Information Processing , 2014, 28(4): 92-97 (in Chinese)
(戴敏, 王榮洋, 李壽山, 等. 基于句法特征的評(píng)價(jià)對(duì)象抽取方法研究[J]. 中文信息學(xué)報(bào), 2014, 28(4): 92-97)
[26] Song Hui, Shi Nansheng. Comment object extraction based on pattern matching and semi-supervised learning[J]. Computer Engineering, 2013, 39(10): 221-226 (in Chinese)
(宋暉, 史南勝. 基于模式匹配與半監(jiān)督學(xué)習(xí)的評(píng)價(jià)對(duì)象抽取[J]. 計(jì)算機(jī)工程, 2013, 39(10): 221-226)
[27] Ren Bin, Che Wanxiang, Liu Ting. Dependency parsing-based social media text mining—A case study in analysis of weibo users’ eating habits[J]. Journal of Chinese Information Processing, 2014, 28(6): 208-215 (in Chinese)
(任彬, 車萬(wàn)翔, 劉挺. 基于依存句法分析的社會(huì)媒體文本挖掘方法——以飲食習(xí)慣特色分析為例[J]. 中文信息學(xué)報(bào), 2014, 28(6): 208-215)
[28] Tao Xinzhu, Zhao Peng, Liu Tao. Extraction of evaluation collection of merging kernel sentence and dependency relation[J]. Computer Technology and Development, 2014, 24(1): 118-121 (in Chinese)
(陶新竹, 趙鵬, 劉濤. 融合核心句與依存關(guān)系的評(píng)價(jià)搭配抽取[J]. 計(jì)算機(jī)技術(shù)與發(fā)展, 2014, 24(1): 118-121)
[29] Li Gang, Liu Fei. Application of a clustering method on sentiment analysis[J]. Journal of Information Science, 2012, 38(2): 127-139
[30] Wang Changhou, Wang Fei. Extracting sentiment words using pattern based Bootstrapping method[J]. Computer Engineering and Applications, 2014, 50(1): 127-129 (in Chinese)
(王昌厚, 王菲. 使用基于模式的Bootstrapping方法抽取情感詞[J]. 計(jì)算機(jī)工程與應(yīng)用, 2014, 50(1): 127-129)
[31] Paltoglou G, Thelwall M. Twitter, MySpace, Digg: Unsupervised sentiment analysis in social media[J]. ACM Trans on Intelligent Systems and Technology, 2012, 3(4): 67-83
[32] Qiu Guang, He Xiaofei, Zhang Feng, et al. DASA: Dissatisfaction-oriented advertising based on sentiment analysis[J]. Expert Systems with Applications, 2010, 37(9): 6182-6191
[33] Jiang Long, Yu Mo, Zhou Ming, et al. Target-dependent Twitter sentiment classification[C] //Proc of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2011: 151-160
[34] Wan Xiaojun. Using bilingual knowledge and ensemble techniques for unsupervised Chinese sentiment analysis[C] //Proc of the 4th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2008: 553-561
[35] Wei Bin, Pal C. Cross Lingual adaptation: An experiment on sentiment classifications[C] //Proc of the 48th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2010: 258-262
[36] Turney P. Thumbs up or thumbs down?: Semantic orientation applied to unsupervised classification of reviews[C] //Proc of the 40th Annual Meeting on Association for Computational Linguistics. New York: ACM, 2002: 417-424
[37] Zagibalov T, Carroll J. Automatic seed word selection for unsupervised sentiment classification of Chinese text[C] //Proc of the 22nd Int Conf on Computational Linguistics, Vol 1. New York: ACM, 2008: 1073-1080
[38] Jo Y, Oh A. Aspect and sentiment unification model for online review analysis[C] //Proc of the 4th Int Conf on Web Search and Web Data Mining. New York: ACM, 2011: 815-824
[39] Thomas H. Probabilistic latent semantic analysis[J]. Computer Science, 2015, 25(4): 289-296
[40] Blei D, Ng A, Jordan M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022
[41] Hoffman M, Bach F, Blei D. Online learning for latent Dirichlet allocation[C] //Proc of the 24th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2010: 856-864
[42] Pang Bo, Lee L, Vaithyanathan S. Thumbs up?: Sentiment classification using machine learning techniques[C] //Proc of the 40th Association for Computational Linguistics Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2002: 79-86
[43] Dong Li, Wei Furu, Tan Chuanqi, et al. Adaptive recursive neural network for target-dependent Twitter sentiment classification[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 49-54
[44] Tang Duyu, Wei Furu, Qin Bing, et al. Coooolll: A deep learning system for Twitter sentiment classification[C] //Proc of the 8th Int Workshop on Semantic Evaluation. Stroudsburg, PA: ACL, 2014: 208-212
[45] Tan Songbo, Cheng Xueqi, Wang Yuefen, et al. Adapting Naive Bayes to domain adaptation for sentiment analysis[C] //Proc of the 31st European Conf on IR Research. Berlin: Springer, 2009: 337-349
[46] Ortigosa H, Rodríguez J, Alzate L, et al. Approaching sentiment analysis by using semi-supervised learning of multi-dimensional classifiers[J]. Neurocomputing, 2012, 92(3): 98-115
[47] Socher R, Pennington J, Huang E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C] //Proc of the 8th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2011: 151-161
[48] Zhou Shusen, Chen Qingcai, Wang Xiaolong. Fuzzy deep belief networks for semi-supervised sentiment classification[J]. Neurocomputing, 2014, 131(9): 312-322
[49] He Xiaonan, Zhang Hui, Chao Wenhan, et al. Semi-supervised learning on cross-lingual sentiment analysis with space transfer[C] //Proc of the 2nd Big Data Computing Service and Applications. Piscataway, NJ: IEEE, 2015: 371-377
[50] Santos C, Gattit M. Deep convolutional neural networks for sentiment analysis of short texts[C] //Proc of the 25th Int Conf on Computational Linguistics. New York: ACM, 2014: 69-78
[51] Socher R, Perelygin A, Wu J, et al Recursive deep models for semantic compositionality over a sentiment treebank[C] //Proc of the 10th Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2013: 1631-1642
[52] Dong Li, Wei Furu, Zhou Ming, et al. Adaptive multi-compositionality for recursive neural models with applications to sentiment analysis[C] //Proc of the 28th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2014: 1537-1543
[53] Le Quoc V, Mikolov T. Distributed representations of sentences and documents[J]. Computer Science, 2014, 4: 1188-1196
[54] Saif H, He Yulan, Alani H. Semantic sentiment analysis of Twitter[C] //Proc of the 11th Int Semantic Web Conf. Berlin: Springer, 2012: 508-524
[55] He Yunchao, Yang Chinsheng, Yu Liangchih, et al. Sentiment classification of short texts based on semantic clustering[C] //Proc of the 2nd Int Conf on Orange Technologies. Piscataway, NJ: IEEE, 2015: 54-57
[56] Saif H, He Yulan, Fernandez M, et al. Semantic patterns for sentiment analysis of Twitter[C] //Proc of the 13th Int Semantic Web Conf. Berlin: Springer, 2014: 324-340
[57] Hassan S , He Y, Alani H. Alleviating data sparsity for Twitter sentiment analysis[C] //Proc of the 2nd Workshop on Making Sense of Microposts. New York: ACM, 2012: 2-9
[58] Mass A L, Daly R E, Pham P T, et al. Learning word vectors for sentiment analysis[C] //Proc of the 49th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2011: 142-150
[59] Dahl G, Adams R, Larochelle H. Training restricted boltzmann machines on word observations[C] //Proc of the 29th Int Conf on Machine Learning. New York: ACM, 2012: 679-686
[60] Wang Sida, Manning C. Baselines and bigrams: Simple, good sentiment and text classification[C] //Proc of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2012: 90-94
[61] Brychcin T, Habernal I. Unsupervised improving of sentiment analysis using global target context[C] //Proc of the 11th Int Conf Recent Advances in Natural Language Processing. Stroudsburg, PA: ACL, 2013: 122-128
[62] Dai A M, Le Q V. Semi-supervised sequence learning[C] //Proc of the 25th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 3079-3087
[63] Stoyanov V, Cardie C. Partially supervised coreference resolution for opinion summarization through structured rule learning[C] //Proc of the 3rd Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2006: 336-344
[64] Ku Lunwei, Liang Yuting, Chen Hsin Hsi. Opinion extraction, summarization and tracking in news and blog corpora[C] //Proc of the 21st AAAI Conf Spring Symp: Computational Approaches to Analyzing Weblogs. Menlo Park, CA: AAAI, 2006: 100-107
[65] Hurst M, Nigam K. Retrieving topical sentiments from online document collections[C] //Proc of the 5th Electronic Imaging Conf. Bellingham, WA: SPIE Press, 2004: 27-34
[66] Zhang Min, Ye Xingyao. A generation model to unify topic relevance and lexicon-based sentiment for opinion retrieval[C] //Proc of the 31st Annual Int ACM SIGIR Conf on Research and Development in Information Retrieval. New York: ACM, 2008: 411-418
[67] Ma Chunling, Osherenko A, Prendinger H, et al. A chat system based on emotion estimation from text and embodied conversational messengers[C] //Proc of the 4th Int Conf on Active Media Technology. Piscataway, NJ: IEEE, 2005: 546-548
[68] Aman S, Szpakowicz S. Identifying expressions of emotion in text[C] //Proc of the 10th Int Conf on Text, Speech and Dialogue. Berlin: Springer, 2007: 196-205
[69] Yang Min, Peng Baolin, Chen Zheng, et al. A topic model for building fine-grained domain-specific emotion lexicon[C] // Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 421-426
[70] Xu Jun, Xu Ruifeng, Zheng Yanzhen, et al. Chinese emotion lexicon developing via multi-lingual lexical resources integration[C] //Proc of the 14th Int Conf on Computational Linguistics and Intelligent Text Processing. Berlin: Springer, 2013: 174-182
[71] Song Kaisong, Feng Shi, Gao Wei, et al. Build emotion lexicon from microblogs by combining effects of seed words and emoticons in a heterogeneous graph[C] //Proc of the 26th ACM Conf on Hypertext and Social Media. New York: ACM, 2015: 283-292
[72] Wu Fangzhao, Huang Yongfeng, Song Yangqiu, et al. Towards building a high-quality microblog-specific Chinese sentiment lexicon[J]. Decision Support Systems, 2016, 87: 39-49
[73] Staiano J, Guerini M. DepecheMood: A lexicon for emotion analysis from crowd-annotated news[C] //Proc of the 52nd Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2014: 427-433
[74] Strapparava C, Mihalcea R. Learning to identify emotions in text[C] //Proc of the 23rd ACM Symp on Applied Computing. New York: ACM, 2008: 1556-1560
[75] Neviarouskaya A, Prendinger H, Ishizuka M. Affect analysis model: Novel rule-based approach to affect sensing from text[J]. Natural Language Engineering, 2011, 17(1): 95-135
[76] Wen Shiyang, Wan Xiaojun. Emotion classification in microblog texts using class sequential rules[C] //Proc of the 28th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2014: 187-193
[77] Lee S Y M, Chen Ying, Huang Churen. A text-driven rule-based system for emotion cause detection[C] //Proc of the 10th NAACL HLT Workshop on Computational Approaches to Analysis and Generation of Emotion in Text. Stroudsburg, PA: ACL, 2010: 45-53
[78] Li Weiyuan, Xu Hua. Text-based emotion classification using emotion cause extraction[J]. Expert Systems with Applications, 2014, 41(4): 1742-1749
[79] Gao Kai, Xu Hua, Wang Jiushuo. A rule-based approach to emotion cause detection for Chinese micro-blogs[J]. Expert Systems with Applications, 2015, 42(9): 4517-4528
[80] Alm C, Roth D, Sproat R. Emotions from text: Machine learning for text-based emotion prediction[C] //Proc of the 2nd Conf on Human Language Technology and on Empirical Methods in Natural Language Processing. New York: ACM, 2005: 579-586
[81] Cheng Xueqi, Yan Xiaohui, Lan Yanyan, et al. BTM: Topic modeling over short texts[J]. IEEE Trans on Knowledge and Data Engineering, 2014, 26(12): 2928-2941
[82] Read J. Using Emoticons to reduce dependency in machine learning techniques for sentiment classification[C] //Proc of the 43rd ACL Student Research Workshop. Stroudsburg, PA: ACL, 2005: 43-48
[83] Zhao Jichang, Dong Li, Wu Junjie, et al. Moodlens: An emoticon-based sentiment analysis system for Chinese tweets[C] //Proc of the 18th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2012: 1528-1531
[84] Ouyang Xi, Zhou Pan, Li Chenghua, et al. Sentiment analysis using convolutional neural network[C] //Proc of the 15th Int Conf on Computer and Information Technology; the 14th Int Conf on Ubiquitous Computing and Communications; the 13th Int Conf on Dependable, Autonomic and Secure Computing; the 13th Int Conf on Pervasive Intelligence and Computing. Piscataway, NJ: IEEE, 2015: 2359-2364
[85] Santos C, Gatti M. Deep Convolutional neural networks for sentiment analysis of short texts[C] //Proc of the 25th Int Conf on Computational Linguistics. New York: ACM, 2014: 69-78
[86] Irsoy O, Cardie C. Deep recursive neural networks for compositionality in language[C] //Proc of the 28th Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2096-2104
[87] Kang Xin, Ren Fuji, Wu Yunong. Bottom up: Exploring word emotions for Chinese sentence chief sentiment classification[C] //Proc of the 6th Natural Language Processing and Knowledge Engineering. Piscataway, NJ: IEEE, 2010: 1-5
[88] Rao Yanghui, Xie Haoran, Li Jun, et al. Social emotion classification of short text via topic-level maximum entropy model[J]. Information and Management, 2016, 53(8): 978-986
[89] Huang Shu, Peng Wei, Li Jingxuan, et al. Sentiment and topic analysis on social media: A multi-task multi-label classification approach[C] //Proc of the 5th Annual ACM Web Science Conf. New York: ACM, 2013: 172-181
[90] Zhang Xiao, Li Wenzhong, Lu Sanglu. Emotion detection in online social network based on multi-label learning[C] //Proc of the 22nd Int Conf on Database Systems for Advanced Applications. Berlin: Springer, 2017: 659-674
[91] Sun Xiao, Li Chengcheng, Ye Jiaqi. Chinese microblogging emotion classification based on support vector machine[C] //Proc of the 5th Int Conf on Computing, Communication and Networking Technologies. Piscataway, NJ: IEEE, 2014: 1-5
[92] Sintsova V, Musat C, Pu Pearl. Semi-supervised method for multi-category emotion recognition in tweets[C] //Proc of the 17th Int Conf on Data Mining Workshop. Piscataway, NJ: IEEE, 2014: 393-402
[93] Purver M, Battersby S. Experimenting with distant supervision for emotion classification[C] //Proc of the 13th Conf of the European Chapter of the Association for Computational Linguistics. New York: ACM, 2012: 482-491
[94] Suttles J, Ide N. Distant supervision for emotion classification with discrete binary values[C] //Proc of the 14th Int Conf on Intelligent Text Processing and Computational Linguistics. Berlin: Springer, 2013: 121-136
[95] Jiang Fei, Liu Yiqun, Luan Huanbo, et al. Microblog sentiment analysis with emoticon space model[J]. Journal of Computer Science and Technology, 2015, 30(5): 1120-1129
[96] Li Shoushan, Xu Jian, Zhang Dong, et al. Two-view label propagation to semi-supervised reader emotion classification[C] //Proc of the 26th Int Conf on Computational Linguistics. New York: ACM, 2016: 2647-2655
[97] Ghazi D, Inkpen D, Szpakowicz S. Hierarchical versus flat classification of emotions in text[C] //Proc of the 9th NAACL HLT Workshop on Computational Approaches to Analysis and Generation of Emotion in Text. Stroudsburg, PA: ACL, 2010: 140-146
[98] Esmin A A A, De Oliveira R L, Matwin S. Hierarchical classification approach to emotion recognition in Twitter[C] //Proc of the 11th Int Conf on Machine Learning and Applications. Piscataway, NJ: IEEE, 2012: 381-385
[99] Xu Hua, Yang Weiwei, Wang Jiushuo. Hierarchical emotion classification and emotion component analysis on Chinese micro-blog posts[J]. Expert Systems with Applications, 2015, 42(22): 8745-8752
[100] Zhang Fan, Xu Hua, Wang Jiushuo, et al. Grasp the implicit features: Hierarchical emotion classification based on topic model and SVM[C] //Proc of the 29th Int Joint Conf on Neural Networks. Piscataway, NJ: IEEE, 2016: 3592-3599
[101] Keshtkar F, Inkpen D. A hierarchical approach to mood classification in blogs[J]. Natural Language Engineering, 2011, 18(18): 61-81
[102] Liu Baoqin, Niu Yun. Multi-hierarchy emotion analysis of Chinese microblog[J]. Computer Technology and Development, 2015, 25(11): 23-26 (in Chinese)
(劉寶芹, 牛耘. 多層次中文微博情緒分析[J]. 計(jì)算機(jī)技術(shù)與發(fā)展, 2015, 25(11): 23-26)
[103] Ouyang Chunping, Yang Xiaohua, Lei Longyan, et al. Multi-strategy approach for fine-grained sentiment analysis of Chinese microblog[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2014, 50(1): 67-72 (in Chinese)
(歐陽(yáng)純萍, 陽(yáng)小華, 雷龍艷, 等. 多策略中文微博細(xì)粒度情緒分析研究[J]. 北京大學(xué)學(xué)報(bào): 自然科學(xué)版, 2014, 50(1): 67-72)
[104] Yang Jun, Jiang Lan, Wang Chongjun, et al. Multi-label emotion classification for tweets in weibo: Method and application[C] //Proc of the 26th Int Conf on Tools with Artificial Intelligence. Piscataway, NJ: IEEE, 2014: 424-428
[105] Buitinck L, Van Amerongen J, Tan E, et al. Multi-emotion detection in user-generated reviews[C] //Proc of the 37th European Conf on Information Retrieval. Berlin: Springer, 2015: 43-48
[106] Liu Shuhua, Chen Jiunhung. A multi-label classification based approach for sentiment classification[J]. Expert Systems with Applications, 2015, 42(3): 1083-1093
[107] Wang Yaqi, Feng Shi, Wang Daling, et al. Multi-label Chinese microblog emotion classification via convolutional neural network[C] //Proc of the 18th Asia-Pacific Web Conf. Berlin: Springer, 2016: 567-580
[108] Li Jun, Rao Yanghui, Jin Fengmei, et al. Multi-label maximum entropy model for social emotion classification over short text[J]. Neurocomputing, 2016, 210: 247-256
[109] Zhou Deyu, Zhang Xuan, Zhou Yin, et al. Emotion distribution learning from texts[C] //Proc of the 21st Conf on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2016: 638-647
[110] Xu Ruifeng, Wang Zhaoyu, Xu Jun, et al. An iterative emotion classification approach for microblogs[C] //Proc of the 16th Int Conf on Intelligent Text Processing and Computational Linguistics. Berlin: Springer, 2015: 104-113
[111] Janssens O, Slembrouck M, Verstockt S, et al. Real-time emotion classification of tweets[C] // Proc of the 5th IEEE/ACM Int Conf on Advances in Social Networks Analysis and Mining. New York: ACM, 2013: 1430-1431
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
風(fēng)流一代·青春(2018年2期)2018-02-26 15:27:06
風(fēng)流一代·青春(2017年6期)2018-02-14 19:28:55
風(fēng)流一代·青春(2017年5期)2018-02-14 09:32:37
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
