基于學習的容器環境Spark性能監控與分析
2018-01-08 07:33:58皮艾迪周笑波
計算機應用 2017年12期
皮艾迪,喻 劍,周笑波
(1.同濟大學 計算機科學與技術系,上海 201804; 2.嵌入式系統與服務計算教育部重點實驗室(同濟大學),上海 201804)
基于學習的容器環境Spark性能監控與分析
皮艾迪1,2,喻 劍1,2,周笑波1,2*
(1.同濟大學 計算機科學與技術系,上海 201804; 2.嵌入式系統與服務計算教育部重點實驗室(同濟大學),上海 201804)
Spark計算框架被越來越多的企業用作大數據分析的框架,由于通常部署在分布式和云環境中因此增加了該系統的復雜性,對Spark框架的性能進行監控并查找導致性能下降的作業向來是非常困難的問題。針對此問題,提出并編寫了一種針對分布式容器環境中Spark性能的實時監控與分析方法。首先,通過在Spark中植入代碼和監控Docker容器中的API文件獲取并整合了作業運行時資源消耗信息;然后,基于Spark作業歷史信息,訓練了高斯混合模型(GMM);最后,使用訓練后的模型對Spark作業的運行時資源消耗信息進行分類并找出導致性能下降的作業。實驗結果表明,所提方法能檢測出90.2%的異常作業,且其對Spark作業性能的影響僅有4.7%。該方法能減輕查錯的工作量,幫助用戶更快地發現Spark的異常作業。
Spark;容器;分布式監控系統;高斯混合模型;機器學習
0 引言
隨著大數據與云計算技術的發展,眾多大數據存儲、計算框架在商業界和學術界得到廣泛的應用和研究。其中,Spark計算框架由于其具有強大的計算能力、分布式可拓展性和容錯能力成為新一代計算框架中研究的熱點。
然而,對部署在分布式環境中的計算框架進行性能監控和分析一直被視為一個非常困難的問題[1]。這是由于在分布式環境當中,可能導致系統性能下降的因素多種多樣,例如:用戶配置不當、硬件故障、資源分配不公平等。若將系統進一步部署到云環境中,那么同一主機上運行的其他虛擬機會進一步對系統性能造成影響。
目前,國內外的研究大致采用三種方法對系統進行監控:1)基于日志的工作流分析;2)事件因果關系追蹤;3)動態追蹤。
文獻[2-9]使用分析系統日志的方法定位系統中性能下降的作業。分析日志的方法能夠在很大程度上降低用戶的工作量,在系統故障時,也可運用這些結果來定位和排除故障;但該方法也有下述不足,由于被分析的日志或控制臺記錄的信息需要在分析之前指定,這就導致了記錄的信息量與分析效率之間的權衡問題。也就是說,若應用執行時記錄的信息過多,會導致應用程序效率下降;反之,則可能導致提供給分析引擎的數據不足,不能準確定位故障。
文獻[10-20]采用事件因果關系追蹤的方法。比起基于日志分析的追蹤技術,因果關系追蹤技術在監控系統時會追蹤系統中各事件的關系。在系統發生故障時,用戶最先排查到的故障原因可能只是故障的表層原因。原因追蹤技術可以追蹤導致故障的事物流,從而幫助用戶準確定位故障的根本原因。因此使用原因追蹤技術能更準確地定位故障原因。比起日志分析技術,效率更高。
文獻[21-23]中使用的動態追蹤方法能最大限度減少追蹤時對系統性能的影響。這是因為動態追蹤技術在用戶不開啟追蹤功能時,對系統性能的影響幾乎為零;而開啟追蹤時,用戶每一次需要追蹤的信息也往往只與系統中一小部分模塊有關。但在動態追蹤中,用戶對系統代碼有比較深入的了解,才能指定需要追蹤的系統模塊。這種方法不適合普通用戶。
此外,以上監控方法都沒有與云環境相結合。云平臺已在商業上廣泛地應用,如Microsoft Azure[24]和Amazon EC2[25]都是知名云平臺提供商,在云環境中運行的計算框架有更好的可拓展性與可伸縮性;與此同時,云環境中計算框架的性能特點也與傳統物理環境中的不盡相同。因此,以上方法不能準確地對云環境中的計算框架進行監控和分析。
對此,本文提出一種對運行在虛擬環境中Spark[26]的性能進行監控的系統和分析的方法,并實現了一套監控與分析系統。本文中,Spark被部署在Docker[27]虛擬化容器中以模擬云環境。Docker容器為Spark作業提供了良好的資源隔離。本監控系統通過在Spark中植入代碼和讀取Docker系統文件,以監控Spark作業運行時的資源消耗情況。使用植入代碼的方式能夠更準確地提供Spark的運行時狀態信息,如正在執行的作業、執行階段以及資源消耗情況。由于不同類型作業對資源的消耗會呈現相應的特點,本文利用這些特點,采用高斯混合模型(Gaussian Mixture Model, GMM),對采集到的信息進行分析,并從中找出異常信息以及其對應的Spark作業。實驗結果表明,本監控系統異常檢測的有效性為90.2%;與此同時,其對Spark性能的影響僅為4.7%。
本文方法的優勢主要有以下兩方面:1)本文方法可對作業資源消耗情況進行實時分析并向用戶反饋異常作業。目前許多監控系統,如Ganglia[28],可以對集群中的主機進行實時監控;但由于集群可被多個用戶共享,同一時間內可能有多個作業運行,因此該種方式不能獲取每一個作業的資源消耗情況。另外一些研究,如文獻[11],可實時重建作業執行過程中的事件流,但其工作沒有涉及對作業性能的分析與反饋。
2)本文方法將監控與Docker容器相結合,從而更準確地獲取作業每個階段的資源消耗信息。監控軟件大多針對集群中的主機節點,即使在單用戶環境,操作系統中的后臺進程也會影響監控的準確性。雖然目前已有針對Docker的監控軟件出現,用戶仍然需要手動將資源消耗情況與作業各個階段相對應。
1 相關理論
1.1 Spark框架
Spark是一個開源的通用計算框架。由于高效的計算能力、易編程性、可拓展性和良好的容錯性,Spark在越來越多的企業中得到廣泛的應用[29]。
Spark使用彈性分布式數據集(Resilient Distributed Datasets, RDD)作為內存存儲機制。由于數據以RDD的形式存儲在內存當中,Spark的計算性能比起上一代Hadoop框架提升了10倍以上,對部分迭代型作業的性能提升甚至在100倍以上。RDD也為Spark提供了良好的容錯性能,通過對父RDD的計算,一個損壞或丟失的RDD可以被快速重建。
Spark由一個負責調度作業的Master節點和多個負責執行作業的Worker節點組成。每個Worker節點可根據自身資源數量啟動一定數量的Executor。Executor是Spark中分配資源和執行任務的單位。其使用的資源數量,如CPU個數和內存用量,可由用戶指定。Spark可使用YARN作為底層的資源調度器。Spark on YARN的整體構架如圖1所示。
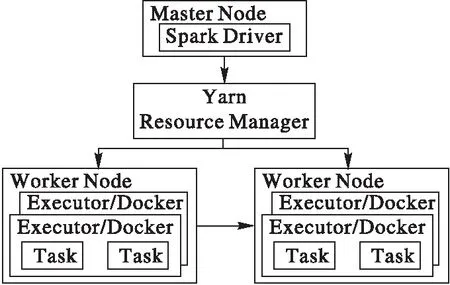
圖1 Spark架構Fig. 1 Architecture of Spark
1.2 Docker容器及優點
Docker是一個開源的Linux軟件容器,能提供輕量級的虛擬化環境。Docker使用cgroup技術,能對單個操作系統上進程間的CPU、內存、網絡流量、文件系統等進行隔離。相比于傳統虛擬化技術,Docker的優勢如下:1)Docker不需要Hypervisor,直接運行在操作系統之上,能在數秒之內啟動。2)Docker在為軟件提供資源隔離的同時,自身基本不消耗系統資源。同一物理主機上能同時運行的Docker實例可達上千個,極大提高了系統資源的利用率。3)Docker中可集成軟件運行時需要的所有依賴庫,實現了軟件的“一次配置,多地運行”,增強了軟件的可移植性。
在本文中,Spark的Executor運行在Docker容器中。Docker為每個Executor分配資源,并為Executor與其他系統進程之間實現資源隔離。由于Executor運行時的網絡流量和磁盤讀寫率不能從Spark內部獲取,本監控系統通過監控Docker的API文件,以獲取這些性能指標。
1.3 高斯混合模型及EM求解算法
同一Spark作業在集群中多次執行,正常情況下其具有相似的資源消耗特征。例如,k-means作業會占用大量CPU資源和少量網絡I/O資源。但由于Spark作業在不同配置的集群中資源消耗情況不相同,用戶不能將同一套分析參數應用于不同的集群。即使在同一集群中,用戶也很難對大量作業的資源消耗情況進行量化,從而進一步標記分類。此外,若要實現在線異常檢測,則要求算法的實時性。為滿足以上需求,選用高斯混合模型(GMM)作為異常檢測方法。高斯混合模型能適應不同集群,根據歷史作業自動訓練參數;并且,訓練后的高斯混合模型能夠在O(n)時間內將作業分類以檢測異常。
高斯混合模型是機器學習中常用的非監督學習算法。它使用多個高斯概率密度函數來描述變量分布,不僅能將變量分類,還能計算出變量屬于每一個類別的概率。對于觀察樣本X={x1,x2,…,xN}和由K個高斯概率密度函數組成的高斯混合模型,每個高斯概率密度函數稱為一個組件(component)。樣本xi(1≤i≤N) 是D維向量,它屬于第j個組件的概率為:
(1)
其中,μj與Σj分別為第j個組件的期望向量與協方差矩陣。
高斯混合模型需要優化的對數似然函數表示為:
(2)
使用EM算法可求出高斯混合模型的參數。EM算法的求解過程如下:
根據先驗知識,初始化每個組件的期望μj和協方差矩陣Σj。然后重復以下E-步和M-步,直到式(2)收斂:
E-步:
M-步:
πj=Nj/N

在EM算法中,E-步估算數據由每個組件生成的概率,M-步利用E-步的結果,估算每個高斯分布函數的參數值。每次E-步和M-步迭代完成后,利用M-步的結果,可重新計算對數似然函數式(2)。
不同Spark作業的資源消耗情況雖然不盡相同,但各自也具有一定的特點,如CPU密集型作業和I/O密集型作業。利用高斯混合模型,可根據Spark作業的資源消耗情況將其分類。由于高斯混合模型中包含樣本屬于每一個分類的概率,異常的Spark作業可以通過設置閾值檢測到。
2 監控系統設計
在本文方法中,通過在Spark的Executor模塊植入代碼和讀取Docker文件,實現了對Spark的運行時信息的監控。使用植入代碼的方式,可以高效準確地從Spark內部獲取到其運行時信息,如作業、階段的開始和結束時間等。獲取到的Spark和Docker監控信息被傳遞給監控系統,由監控系統進行整合并存儲到數據庫。監控系統通過使用Spark歷史作業信息訓練高斯混合模型。當新作業提交時,監控系統會在作業運行的同時分析作業的性能指標,并向用戶報告運行異常的作業。本文監控系統的架構如圖2所示,其中灰色部分為本文的主要工作。①用戶首先提交作業到Spark Master節點;②Master節點向運行在Work節點上的Executor分配任務;③植入在Executor中的監控管理器向監控系統注冊任務并實時報告任務資源使用情況;④Docker監控器收集并報告Docker資源使用情況;⑤整合后的信息整存儲到數據庫;⑥整合后的信息送到數據分析模塊;⑦分析模塊向用戶反饋異常的作業和階段。
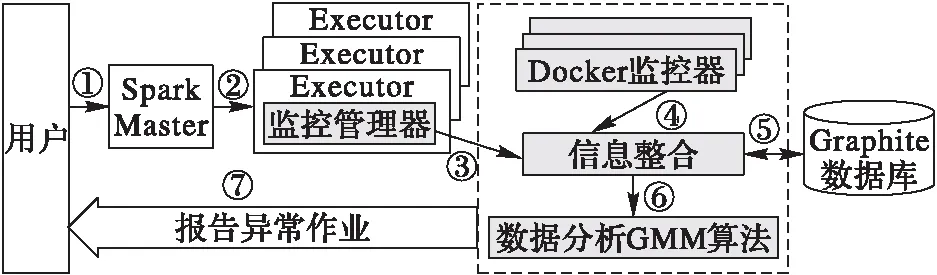
圖2 監控系統架構Fig. 2 Architecture of the monitoring system
2.1 Spark代碼植入
在Spark中植入代碼時,必須權衡代碼抓取信息的能力和其對Spark性能的影響。具體來說,若植入的代碼不足,則不能抓取到足夠的Spark運行時信息;反之,則可能導致Spark運行性能下降。4.3節的實驗結果說明植入代碼和監控系統對Spark作業的影響在合理范圍以內。
Spark的Executor維護一個線程池,其中的所有任務都執行在這個線程池中,每個任務占用一個線程。通過累加Executor中所有任務線程的CPU使用率,可以計算出該Executor此時的CPU用量的總和。
Spark任務的內存由存儲內存(storage memory)和執行內存(execution memory)兩部分組成。其中,存儲內存是指任務的輸入數據占用的內存。植入的代碼通過監控該輸入數據對象的大小以獲取存儲內存。另一方面,執行內存是指任務執行過程中,洗牌(shuffle)、聚合(aggregate)和連接(join)操作產生的中間數據結構占用的內存。Spark內部維護了一個記錄當前執行內存消耗情況的數據結構。通過讀取解析該數據結構,可以實時獲取Spark的執行內存用量。
本監控系統中,向Spark框架內部新加入一個監控管理器模塊(TracingManager),以獲取Spark內部運行時信息。監控管理器的主要功能包括向監控系統:1)注冊任務;2)注銷任務;3)周期性報告任務CPU使用率:4)周期性報告任務內存使用量。監控管理器周期性報告的時間間隔為τ,且可由用戶指定。由于任務網絡傳輸速率和磁盤讀寫速率不能從Spark內部準確地獲取,本文將在2.2節中介紹從Docker中獲取這兩種信息的方法。在Spark中植入的主要方法及其功能如表1所示。

表1 植入代碼的主要方法及說明Tab. 1 Main methods and explanations of embedding codes
2.2 獲取Docker信息
Spark作業啟動時的同時,會向監控系統注冊,注冊的信息包括作業啟動時間和使用Docker的標識。本監控系統通過該標識在操作系統中定位Docker容器,并啟動一個Docker監控器(DockerMonitor)。Docker監控器周期性讀取Docker的API文件以獲取在其中運行的Executor的網絡流量和磁盤使用率。
Docker關于網絡流量和磁盤讀寫的API文件中分別存儲Docker自啟動以來網絡流量和磁盤讀寫量的總和,若要獲取網絡傳輸率和磁盤讀寫速率則需要進一步計算。本監控系統使用以下公式計算Docker在某一時刻t的網絡傳輸(或接收)速率:
Net_Rate=(Total_Trafict-Total_Trafict-τ)/τ
類似地,磁盤讀取(或寫入)速率用以下公式計算:
Disk_Rate=(Total_Bytet-Total_Bytet-τ)/τ
其中:τ為監控系統每次讀取API文件的時間間隔;Total_Trafict和Total_Bytet分別表示Docker自啟動到時刻t,網絡傳輸(或接收)和與磁盤讀取(或寫入)字節數總和。
2.3 信息整合與存儲
為了獲取作業階段在某一時刻對所有資源的使用情況,本監控系統需要整合來自植入代碼和Docker監控器的信息。植入代碼和Docker監控器獲取的信息中除包含資源用量外,還有該條信息抓取時的時間戳和階段標識。例如,任務job_i的第j個階段stage_j在時刻t的CPU使用量為v,這條信息可表示為三元組[job_i.stage_j,v,t]。利用任務標識,可以唯一確定階段從屬的作業。經過整合之后,作業在時刻t對所有類型資源的使用情況表示為一個6維資源消耗向量:
M=(m1,m2,m3,m4,m5,m6)
其中:m1為CPU使用率;m2為內存用量;m3為磁盤讀取速率;m4為磁盤寫入速率;m5為網絡接收速率;m6為網絡傳輸速率。
為了能重復使用監控信息,需要將監控信息持久化。本監控系統使用Graphite[30]作為后臺數據庫。Graphite數據庫適用于存儲帶時間戳的數字信息,其每條數據由三元組[標識,數據的值,時間戳]組成,因此本監控系統可將整合后的信息三元組直接存儲到數據庫中。
2.4 模型訓練
在2.2節和2.3節中抓取的原始數據包含噪聲,并且資源消耗向量各維度的量綱不同,需要對數據進行預處理。在數據分析模塊檢測異常作業之前,還需要訓練高斯混合模型。
2.4.1 數據預處理
經過察看發現,作業的每個階段剛啟動時很短一段時間內,其資源消耗向量中的每一項值都為0。這是由于作業階段從向監控系統注冊到真正啟動執行需要一段準備時間。在數據預處理時,需要去除這些全零向量,以降低噪聲的干擾。
由于資源消耗向量各維度的量綱不同,為了使訓練的結果更準確,需要將數據標準化。本文選用離差標準化的方法,經過標準化后的樣本值都被映射到[0,1]。在資源消耗向量中,CPU使用率本身已在[0,1],而其他5項都需要進行標準化處理。離差標準化公式如下:
x*=(x-μ)/(xmax-xmin)
其中:x和x*分別為標準化前后的樣本值;μ為樣本方差;xmin和xmin分別為樣本中的最大值和最小值。
2.4.2 參數訓練
在訓練參數和檢測異常階段,本文都以主機節點作為單位,也就是說——經過訓練以后,每一臺主機節點擁有各自獨立的模型參數,并只檢查在該節點上運行的作業。當Spark部署在異構集群中(heterogeneous cluster)中時,不同硬件配置的主機節點會對作業的性能和資源消耗情況造成不同的影響。因此,不能使用同一套參數來檢測不同主機節點上的作業。各節點擁有各自獨立的模型參數使監控系統能很好地夠適應異構集群環境。
利用來自作業的歷史數據,在參數訓練階段EM算法會建立K個高斯分類的參數,每個分類代表具有某種特征的作業階段。由于EM算法對參數初值敏感,訓練模型的過程中需要使用不同初始參數值進行多次訓練,最后取使1.3節中式(2)最大的訓練結果作為模型參數。通過實驗發現,K=4時,監控系統可以在有效監測異常作業的同時兼顧Spark作業的運行性能。
2.5 異常檢測
Spark作業內部的不同階段對資源消耗的情況不盡相同。例如,作業的第一個階段通常會從磁盤讀取數據,從而造成很大的磁盤I/O開銷;而中間階段通常會在節點間傳輸數據,從而造成網絡I/O開銷。因此,本監控系統以作業階段作為異常檢測的單位。
定義1 異常階段是指在一段時間T內,有αT/τ條作業性能消耗向量屬于每個分類的概率都不超過σ的階段。其中:τ為抓取數據的時間間隔;α和σ均為實驗測出的閾值,0 ≤α,σ≤ 1。
定義1中規定,只有當作業階段中長時間出現不能分類的性能消耗向量時,才將該作業階段劃分為異常作業。這避免了系統資源短時間波動引起的誤判。
監控系統會在Spark作業運行的同時將檢測到的異常作業階段反饋給用戶。
3 系統實現
本監控系統由植入Spark的代碼和外部守護進程兩部分組成。在Spark中植入了約500行Java代碼和約100行Scala代碼,植入代碼包括修改后的Executor和新加入的監控管理器模塊(TracingManager)。修改后的Executor在任務啟動和完成時向監控管理器報告;監控管理器利用Java提供的API獲取Spark作業的CPU使用率和輸入數據對象大小,并與外部守護進程通信。
守護進程用大約3 600行Java代碼編寫。守護進程的主要功能包括:1)記錄正在運行的Spark作業;2)實時獲取Docker資源用量;3)實時分析資源用量并報告異常作業;4)將數據存儲到數據庫。植入代碼和守護進程間使用Apache Thrift[31]協議通信。本文選用Graphite作為后臺數據庫。Graphite作為企業級時間序列數據庫,適用于存儲帶時間戳的監控數據。
4 實驗結果與分析
本文針對監控系統對Spark性能的影響和異常檢測的有效性設計了兩組實驗,并與其他監控分析工具進行對比。
在性能分析實驗中,部分其他工具采用離線分析模式(即當作業完成之后,工具再對作業日志進行分析),無法獲取其對作業性能的直接影響;因此,該實驗選取Whodunit[10]、Gist[18]和Stitch[8]等在線監控工具進行對比。
在有效性分析實驗中,部分其他工具僅僅向用戶反饋帶時間戳的事件流,而異常檢測需要由用戶完成,因此該實驗選取可反饋異常信息的工具Iprof[7]進行對比。由于Iprof是離線分析工具,本文不比較其對作業性能的影響。
4.1 實驗環境
為了測試監控系統的性能,本文用9臺小型服務器搭建了Spark on YARN分布式環境,1臺作為Master節點,8臺作為Worker節點。9臺服務器的配置均為Intel Core i7- 2600 @ 3.4 GHz 8核CPU、8 GB內存、500 GB/7 200 rpm;服務器間用千兆網絡連接。操作系統版本為Ubuntu Server 16.04。基于Spark-2.1.0版本植入代碼,使用cluster模式運行在hadoop-2.7.3版本上。Docker鏡像版本為sequenceiq/hadoop-docker-2.4.0。Graphite數據庫版本為0.10,部署在Master節點上。
測試數據選用標準測試集HiBench-6.0[32]的5個作業:wordcount、terasort、k-means、baye和pagerank,每個作業數據量及說明如表2所示。

表2 測試數據的作業名稱、數據量及說明Tab. 2 Name, data volume and description of jobs for test
4.2 性能分析
監控系統對Spark性能的影響應在合理范圍以內,以保證Spark作業正常運行。為此,本文對比了Spark單獨運行和Spark與監控系統同時運行時的性能,實驗結果如圖3所示。實驗表明,監控系統僅使作業的執行時間增加了平均4.7%。對于非CPU密集型作業,如wordcount和terasort,監控系統對作業性能的影響不到5%。本文方法與其他監控系統對作業性能影響的對比如表3所示。由表3可以看出,本文方法對作業性能的影響與Whodunit和Gist大致相當,且優于Stitch。
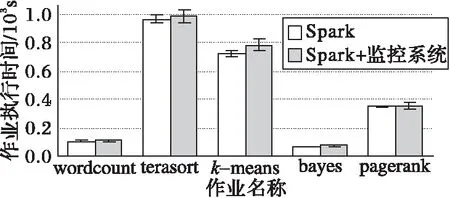
圖3 Spark單獨運行和與監控系統同時運行性能對比Fig. 3 Performance comparison of Spark-alone and Spark with monitoring system
4.3 有效性分析
為了檢驗監控系統對異常作業的檢測的有效性,在有其他作業干擾的情況下運行HiBench Spark測試作業集,并將結果與Iprof[7]對比。本文規定,一個作業階段的執行時間若比無干擾時慢20%或以上則為異常作業階段。干擾作業來自HiBench的Hadoop MapReduce測試作業集,在Spark作業運行的同時隨機選取執行。
實驗中,每個Spark作業在有干擾的情況下重復多次執行。首先人工檢測Spark作業的異常階段,然后與監控系統反饋的異常階段對比,以驗證監控系統的有效性。在2.5節中,本文給出了異常作業的定義。經過實驗發現,定義中的閾值取α=0.6、σ=0.4時,監控系統可以較好地檢測出異常作業階段。表4為有效性測試的實驗結果。從表4中可看出,監控系統對異常階段檢測的整體有效率為90.2%。本文監控系統與Iprof異常檢測有效性分別為90.2%、73.0%。

表3 不同系統對作業性能影響的對比Tab. 3 Comparison of effects of different systems on job performance

表4 監控系統檢測異常階段的有效性Tab. 4 Effectiveness of detecting abnormal phase of monitoring system
5 結語
本文針對分布式系統性能監控及診斷困難的問題,提出并編寫了一套用于Spark作業性能監控與分析的系統。該系統基于高斯混合模型,能夠實時監控Spark作業的資源消耗情況,并向用戶反饋性能受到干擾的作業。隨后,用戶可采取進一步的措施以調整Spark作業,使其恢復正常運行。實驗結果表明該系統在有效檢測異常作業的同時對作業性能造成的影響很小。
進一步的研究可從以下三個方向展開:1)優化異常檢測算法,使其具有更強的自動檢測能力;2)進一步分析并找出使作業性能下降的瓶頸資源;3)利用資源消耗信息進行作業調度,最大化利用集群資源。
References)
[1] SAMBASIVAN R R, SHAFER I, SIGELMAN B H, et al. Principled workflow-centric tracing of distributed systems [C]// SoCC 2016: Proceeding of the 2016 Seventh ACM symposium on Cloud Computing. New York: ACM, 2016: 401-414.
[2] KAVULYA S P, DANIELS S, JOSHI K, et al. Draco: statistical diagnosis of chronic problems in large distributed systems [C]// DSN 2012: Proceedings of the 2012 42nd Annual IEEE/IFIP International Conference on Dependable System and Networks. Washington, DC: IEEE Computer Society, 2012: 1-12.
[3] SAMBASIVAN R R, ZHENG A X, DE ROSA M, et al. Diagnosing performance changes by comparing request flows [C]// NSDI’11: Proceeding of the 2011 8th USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2011: 43-56.
[4] NAGARAJ K, KILLIAN C, NEVILLE J. Structured comparative analysis of systems logs to diagnose performance problems [C]// NSDI 2012: Proceedings of the 2012 9th USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 353-366.
[5] OLINER A J, KULKARNI A V, AIKEN A. Using correlated surprise to infer shared influence [C]// DSN 2010: Proceedings of the 2010 IEEE/IFIP International Conference on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2010: 191-200.
[6] XU W, HUANG L, FOX A, et al. Detecting large-scale system problems by mining console logs [C]// SOSP’09: Proceedings of the 2009 ACM SIGOPS 22nd Symposium on Operating Systems. New York: ACM, 2009: 117-132.
[7] ZHAO X, ZHANG Y, LION D, et al. Iprof: a non-intrusive request flow profiler for distributed systems [C]// OSDI 2014: Proceedings of the 2014 11th USENIX Conference on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2014: 629-644.
[8] ZHAO X, RODRIGUES K, LUO Y, et al. Non-intrusive performance profiling for entire software stacks based on the flow reconstruction principle [C]// OSDI 2016: Proceedings of the 2016 12th USENIX Symposium on Operating System Design and Implementation. Berkeley, CA: USENIX Association, 2016: 603-618.
[9] 劉海寶,蔡皖東,許俊杰,等.分布式網絡行為監控系統設計與實現[J].微電子學與計算機,2006,23(3):76-79. (LIU H B, CAI W D, XU J J, et al. Design and implement of distributed network behavior monitoring system [J]. Microelectronics & Computer, 2006, 23(3): 76-79.)
[10] CHANDA A, COX A L, ZWAENEPOEL W. Whodunit: transactional profiling for multi-tier applications [C]// EuroSys 2007: Proceedings of the 2007 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems. New York: ACM, 2007: 17-30.
[11] BARHAM P, DONNELLY A, ISAACS R, et al. Using magpie for request extraction and workload modelling [C]// OSDI 2004: Proceedings of the 2004 6th USENIX Symposium on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2004: 259-272.
[12] CHEN M Y, ACCARDI A, KICIMAN E, et al. Path-based failure and evolution management [C]// NSDI 2004: Proceedings of the 1st USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2004: 23-36.
[13] REYNOLDS P, KILLIAN C E, WIENER J L, et al. Pip: detecting the unexpected in distributed systems [C]// NSDI 2006: Proceedings of the 2006 3rd USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2006: 115-128.
[14] THERESKA E, SALMON B, STRUNK J, et al. Stardust: tracking activity in a distributed storage system [C]// Proceedings of the 2006 Joint International Conference on Measurement and Modeling of Computer Systems. New York: ACM, 2006: 3-14.
[15] FONSECA R, PORTER G, KATZ R H, et al. X-trace: a pervasive network tracing framework [C]// NSDI 2007: Proceedings of the 2007 4th USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2007: 20-33.
[16] MACE J, BODIK P, FONSECA R, et al. Retro: targeted resource management in multi-tenant distributed systems [C]// NSDI 2015: Proceedings of the 2015 12th USENIX Conference on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2015: 589-603.
[17] SIGELMAN B H, BARROSO L A, BURROWS M, et al. Dapper, a large-scale distributed systems tracing infrastructure, GoogleTechnical Report dapper- 2010- 1 [R]. Mountain View: Google, 2010: 29.
[18] KASIKCI B, SCHUBERT B, PEREIRA C, et al. Failure sketching: a technique for automated root cause diagnosis of in-production failures [C]// SOSP 2015: Proceeding of the 25th ACM Symposium on Operating Systems Principles. New York: ACM, 2015:344-360.
[19] 樓樺.服務器監控系統的實現[D].鄭州: 鄭州大學,2004:25-28.(LOU H. Implementation of server’s monitoring system [D]. Zhengzhou: Zhengzhou University, 2004: 25-28.)
[20] 和榮,肖海力.基于Nagios的監控平臺的設計與實現[J].科研信息化技術與應用,2014,5(5):77-85.(HE R, XIAO H L. A monitor platform based on Nagios [J]. E-Science Technology & Application, 2014, 5(5): 77-85.)
[21] CANTRILL B M, SHAPIRO M W, LEVENTHAL A H. Dynamic instrumentation of production systems [C]// USENIX 2004: Proceedings of the 2004 USENIX Annual Technical Conference. Berkeley, CA: USENIX Association, 2004: 15-28.
[22] ERLINGSSON U, PEINADO M, PETER S, et al. Fay: extensible distributed tracing from kernels to clusters[J]. ACM Transactions on Computer Systems, 2012, 30(4): Article No. 13.
[23] MACE J, ROELKE R, FONSECA R. Pivot tracing: dynamic causal monitoring for distributed systems [C]// SOSP 2015: Proceedings of the 2015 25th Symposium on Operating Systems Principles. New York: ACM, 2015: 378-393.
[24] Microsoft. Microsoft azure: cloud computing platform & services [EB/OL]. [2017- 04- 15]. https://azure.microsoft.com/en-us/?v=17.14.
[25] Amazon Web Service, Inc. Elastic Compute Cloud (EC2) — cloud server & hosting — AWS [EB/OL]. [2017- 04- 15]. https://aws.amazon.com/ec2/.
[26] Apache. Apache Spark: lightning-fast cluster computing [EB/OL]. [2017- 04- 15]. https://spark.apache.org/.
[27] Docker, Inc. Docker — Build, ship, and run [EB/OL]. [2017- 04- 15]. https://www.docker.com/.
[28] Ganglia. Ganglia monitoring system [EB/OL]. [2017- 04- 15]. http://ganglia.sourceforge.net/.
[29] YAN Y, GAO Y, CHEN Y, et al. TR-Spark: transient computing for big data analytics [C]// SoCC 2016: Proceeding of the 2016 Seventh ACM Symposium on Cloud Computing. New York: ACM, 2016: 484-496.
[30] Graphite. Graphite documentation [DB/OL]. [2017- 03- 14]. https://graphite.readthedocs.io/.
[31] Apache. Apache thrift — home [EB/OL]. [2017- 02- 17]. https://thrift.apache.org/.
[32] GitHub, Inc. Intel — Hadoop/Hibench [EB/OL]. [2017- 03- 30]. https://github.com/intel-hadoop/HiBench/.
PIAidi, born in 1993, M. S. candidate. His research interests include big data processing, cloud computing.
YUJian, born in 1975, Ph. D., lecturer. His research interests include Internet of things, big data processing.
ZHOUXiaobo, born in 1973, Ph. D., professor. His research interests include cloud computing, big data parallel processing, distributed system, data center.
Learning-basedperformancemonitoringandanalysisforSparkincontainerenvironments
PI Aidi1,2, YU Jian1,2, ZHOU Xiaobo1,2*
(1.DepartmentofComputerScienceandTechnology,TongjiUniversity,Shanghai201804,China;2.KeyLaboratoryofEmbeddedSystemandServiceComputing,MinistryofEducation(TongjiUniversity),Shanghai201804,China)
The Spark computing framework has been adopted as the framework for big data analysis by an increasing number of enterprises. However, the complexity of the system is increased due to the characteristic that it is typically deployed in distributed and cloud environments. Therefore, it is always considered to be difficult to monitor the performance of the Spark framework and finding jobs that lead to performance degradation. In order to solve this problem, a real-time monitoring and analysis method for Spark performance in distributed container environment was proposed and compiled. Firstly, the resource consumption information of jobs at runtime was acquired and integrated through the implantation of code in Spark and monitoring of Application Program Interface (API) files in Docker containers. Then, the Gaussian Mixture Model (GMM) was trained based on job history information of Spark. Finally, the trained model was used to classify the resource consumption information of Spark jobs at runtime and find jobs that led to performance degradation. The experimental results show that, the proposed method can detect 90.2% of the abnormal jobs and it only introduces 4.7% degradation to the performance of Spark jobs. The proposde method can lighten the burden of error checking and help users find the abnormal jobs of Spark in a shorter time.
Spark; container; distributed monitoring system; Gaussian Mixture Model (GMM); machine learning
2017- 05- 16;
2017- 07- 14。
皮艾迪(1993—),男,上海人,碩士研究生,主要研究方向:大數據處理、云計算; 喻劍(1975—),男,浙江義烏人,講師,博士,主要研究方向:物聯網、大數據處理; 周笑波(1973—),男,浙江臺州人,教授,博士生導師,博士,主要研究方向:云計算、大數據并行處理、分布式系統、數據中心。
1001- 9081(2017)12- 3586- 06
10.11772/j.issn.1001- 9081.2017.12.3586
(*通信作者電子郵箱xzhou@tongji.edu.cn)
TP393.06; TP18
A
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
故事大王(2016年7期)2016-09-22 17:30:08
中外會展(2014年4期)2014-11-27 07:46:46
兒童故事畫報(2013年3期)2013-06-24 05:40:30
小哥白尼·軍事科學畫報(2009年9期)2009-09-14 03:18:56
