三角形的并行枚舉算法
2018-01-08 07:33:47王卓,索勃,潘巍
計算機應用 2017年12期
王 卓,索 勃,潘 巍
(西北工業大學 計算機學院,西安 710129)
三角形的并行枚舉算法
王 卓,索 勃,潘 巍*
(西北工業大學 計算機學院,西安 710129)
經典GT算法是三角形并行枚舉算法的MapReduce實現,然而該算法只能枚舉全圖的三角形結構,對部分頂點構成的三角形結構無法直接進行枚舉。針對此問題,提出一種直接枚舉部分頂點構成三角形結構的并行算法。首先,通過分析被選點的分布,給出被選點構成三角形的所有組合集合;然后,通過對該集合的篩選,實現對部分點構成三角形結構的直接枚舉;最后,將該算法在Spark系統實現,以實現該算法的高效性和廣泛性。在人工生成數據集和真實數據集上與GT算法進行對比實驗,實驗結果表明,所提改進算法的運行時間只有GT算法運行時間的1/3,在Spark上的運行時間僅是Hadoop上運行時間的1/7。該算法可用于更高效地直接生成圖中任意點所構成的三角形數據集。
三角形枚舉;大規模圖數據;MapReduce;部分點枚舉;Spark
0 引言
在密集圖的應用分析中,研究頂點之間的關系是圖分析的熱點,而對三角形關系的研究又是重要的研究方向。
在圖論的研究中,三角形關系是復雜社會網絡分析中常見的結構[1]。如在社交網絡關系中,通過分析三角性關系可以確定節點之間的聯系程度;在角色行為識別中,通過分析三角形關系可以判斷角色之間的地位。三角關系的一個重要應用是在枚舉圖的極大團(Maximal Clique)過程中[2],即將一跳(one-top,即與被選點直接相鄰的點構成的集合)數據轉換為三角形結構。
研究者已提出很多算法[3-5]實現一跳數據集向三角形數據集的轉換,但伴隨著數據量的增大,傳統的單機算法已無法快速地處理大規模圖數據。隨著MapReduce并行計算框架的普及,很多研究已開始使用MapReduce框架進行圖數據的處理[6-7],并且已有研究者實現了MapReduce框架下將一跳數據集向三角形數據集轉換的GT(Graph Twiddling)算法[8]。GT算法通過兩輪MapReduce 任務來完成數據結構的轉換,該算法可以很高效地將整個原圖的一跳形式處理成三角形結構,但卻無法直接生產部分點的三角形結構。同時,該算法是圖上迭代計算,在MapReduce計算框架下,由于需要將中間結果寫回磁盤,將造成很大的讀寫瓶頸。
基于以上兩個問題,本文首先提出可直接枚舉部分點三角形結構的改進GT算法,該算法經過兩輪MapReduce任務:第一輪為查詢點的篩選,第二輪為查詢點三角形結構的生成;同時,將改進算法在Spark系統上實現,以實現該算法高效迭代的特性。本文的主要工作如下:
1) 改進GT算法,使該算法可以直接生產部分點的三角形結構;同時,在三角形的篩選過程中,提出按照最小度數點進行切分的優化思想,以提高枚舉效率。
2) 將改進算法在Spark系統實現,避免因MapReduce框架下需要將中間結果寫回磁盤的瓶頸,以提高迭代計算效率。
3) 通過合成數據集和真實數據集驗證該算法的高效性,與改進前相比,具有至少3倍的運行效率提升。
1 相關技術
本章介紹與本文研究密切相關的兩個概念:三角形結構和MapReduce計算框架。
1.1 三角形結構
設無向圖G=(V,E),其中:V是頂點的集合,|V|是頂點的總數;E是邊的集合,|E|是邊的總數。
定義1 三角形結構。給定一個無向圖G=(V,E),{u,v,w}∈V,若三個頂點滿足以下關系{u,v},{w,v},{u,w}∈E,則稱三個頂點構成了一個三角形結構,記為△uvw。
1.2 MapReduce計算框架
MapReduce計算模型是將計算分為Map和Reduce兩個階段。在Map階段,由用戶定義的map函數將輸入的每條元組轉換為〈key,value〉形式,然后按照partition函數對key進行分區,并將各分區Shuffle到Reduce端,且嚴格保證分區和Reducer是一一對應的關系。當各Reducer獲取分配給各自分區的全部數據后開始執行用戶定義的reduce函數,并輸出結果。
影響Reducer執行效率的關鍵是partition函數的定義,合理的partition函數可以實現各Reducer運行過程中的均衡性,反之會出現數據傾斜,嚴重影響執行效率。對于數據的分配均衡問題,文獻[9]已進行了探討并提出了相應的策略。該問題的避免可以通過定義partition函數或定義map函數等方法優化,因此,在設計MapReduce算法時應該考慮該數據傾斜的問題。
MapReduce在處理迭代計算時,有兩處磁盤操作,map函數后和reduce函數的結果輸出,因此MapReduce在處理圖的迭代計算時存在數據傳輸的瓶頸問題。針對該問題,已有i2MapReduce[10]方法可進行高效的迭代計算,同時Spark系統更是被廣泛應用的圖處理平臺。
2 GT算法
本章介紹基于MapReduce編程模型的GT算法。
GT算法將三角形的枚舉過程分為兩個MapReduce任務:第一,合并公共點;第二,判斷合并后的公共點集合中是否存在三角形結構。
第一輪MapReduce任務:map函數將同一節點的所有鄰接點進行匯總,并傳到一個Reducer上處理。reduce函數將與該點相連,且編號大于該點的所有頂點進行笛卡爾積運算,并將結果輸出。
第二輪MapReduce任務:map函數將原圖和第一輪Reduce端的輸出結果合并,即邊作為key值輸出。reduce函數判斷第一輪笛卡爾積所構成的邊集合中,是否存在原圖中的邊。若在原圖中存在該邊,則說明該邊的兩個頂點與生成該邊的點,即第一輪中reduce函數key所表示的頂點,構成了一個三角形結構。
根據對GT算法的描述可知,在第一輪Reduce階段,需要進行笛卡爾積操作,度數較大的點會產生大量的中間結果。GT算法在處理時,將原圖以一跳的形式表示,并滿足第一個頂點編號的值小于第二個頂點編號的值,同時,將度數小的頂點作為key值,然后再進行分區,從而達到減少中間結果的目的。
GT算法不能直接枚舉出部分點所構成的三角形結構。由于第一輪map函數是按照度數或者頂點編號進行劃分的,因此在枚舉部分點構成的三角形結構時,當被選點出現在value中,就無法獲得被選點的完整鄰接點集合,從而導致查詢的結果不完整。因此,若使用GT算法來枚舉部分點的三角形結構,首先需要枚舉出原圖的所有三角形,然后從全圖的三角形集合中篩選出包含被選點的結構。由此可見,這樣將造成大量的不相關計算。
3 PGT算法
本章介紹可直接枚舉部分頂點構成三角形結構的改進GT算法,本文稱為PGT(Parts-of-vertex for GT)算法。
3.1 算法描述
要解決GT算法直接枚舉部分點構成三角形結構的問題,就需要解決如何在劃分過程中保持數據的完整性問題,因此首先需要統計出被選點劃分后的分布情況。由于MapReduce模型采用〈key,value〉對處理數據的特點,在數據劃分后被選點只會現在兩個集合中:第一是在key中,如圖 1(a)所示的第一層頂點編號為A的頂點(被選點);第二個是在value中,如圖 1(b)所示的第二層頂點編號為B的頂點(被選點)。因此,要保證數據的完整性需要同時將兩種情況進行分析。
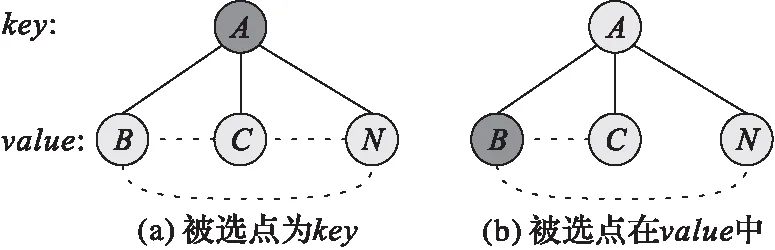
圖 1 被選點的分布Fig. 1 Distribution of candidate vertexes
如圖 1(a)所示,被選點在key集合中。在該結構中,value集合中的頂點是key的鄰接點集合,如圖中實線所示。在該結構中若存在三角形,一定是value中的某兩個頂點存在一條邊,即如圖中虛線所示。因此,對于這種情況,需要將value集合中的所有頂點進行笛卡爾積運算,即構建出一條新邊,并通過下一輪MapReduce任務判斷該邊是否在原圖中存在,若存在,則該點(key)與相連的兩點(value中的頂點)構成了三角形結構。
如圖 1(b)所示,被選點出現在value中。出現這種情況的原因是:為了減少笛卡爾積集合的大小,在劃分時是以兩個點的度數為標準,即度數小的點為key,因此導致被選點會出現在value中的現象。在此種結構中,同樣value集合中的點是key點的鄰接點,然而只需要枚舉包含有被選點的集合。因此,此時只需要將被選點從value中取出,然后將該點和value中的其他點進行笛卡爾積運算,構建出一條新邊,如圖 1(b)中虛線所示。同樣,通過下一輪MapReduce任務判斷該邊是否在原圖中存在,若存在,則該點(value中的被選點)和相連的兩個點(key頂點和在value中與被選點相連的頂點)構成了三角形結構。
3.2 算法實現
算法1 PGT算法的MapReduce實現。
輸入 集合key,集合value,被選點構成的集合Cand;
輸出 候選邊集Edge。
1)
ifkeyinCand
//被選點在key集合中
2)
forvtovalue
//遍歷value集合,求笛卡爾積
3)
Edge←v×{value-v}
4)
Write(Edge,key)
//輸出,并標注是在key集合中
5)
endfor
6)
endif
7)
else
8)
forntovalue
//被選點在value集合中
9)
ifninCand
10)
Edge←n×{value-n}
11)
Write(Edge,n)
//輸出,并標注是在value集合中
12)
endif
13)
endfor
14)
endelse
算法1可分為兩部分:第一部分從1)~6)行,是對被選點在key中情況的處理,第二部分從7)~14)行,是對被選點在value中的處理。由于在第二輪MapReduce任務中,需要將被選點進行聚合,所以在輸出時,需要標明被選點的編號,即如算法1第4)行和第11)行所示。由算法1描述可知,該算法的復雜度為O(n)。
算法2 PGT算法的Spark實現。
輸入 集合key,集合value,被選點構成的集合Cand;
輸出 三角形邊集edges。
1)
defPGT(key: Int,value:Set[Int],Cand:Set[Int])={
2)
if (Cand.contains(key)) {
3)
for (v←value){
//遍歷value集合
4)
valnotV=value-v
5)
valedges=notV.map(v2 => {
6)
(v,v2)
// 對value中的點求笛卡爾積
7)
})
8)
(edges,key)
//第一種情況的輸出
9)
}
//end for
10)
}
//end if
11)
else {
12)
for (n←value) {
13)
if (Cand.contains(n)){
//被選點在value中
14)
valnotN=value-n
//除去本點后求笛卡爾積
15)
valedges=notN.map(n2=> {
16)
(n,n2)
//第二種情況的輸出
17)
}
18)
(edges,n)
19)
}
//end if
20)
}
//end for
21)
}
//end else
22)
}
//end function
算法2由兩部分組成:第一部分從1)~10)行,是對被選點在key中情況的處理,第二部分從11)~22)行,是對被選點在value中的處理。函數PGT()是Spark中reduce函數的參數,即實現對三角形的篩選工作,不同于MapReduce的輸出,Spark的輸出可存儲在內存中,以實現迭代計算的高效性。
4 實驗結果及分析
本章通過兩部分實驗驗證GPT算法的高效性,實驗是在兩個人工生成數據集和兩個真實數據集上進行,通過隨機選點的方法比較兩個算法的運行時間。
4.1 實驗環境
本文的所有實驗在11個節點的集群上進行,其中包含1個Master節點負責任務的調度和集群管理, 10個Worker節點負責存儲數據和計算。每個節點的系統配置為:16 核主頻為 2.20 GHz 的AMD 處理器,16 GB 的 RAM 和 1 TB的硬盤,節點之間通過1 Gb的網絡連接,各節點用的是 64 位Ubuntu Linux12.01,部署的是Hadoop-1.2.1版本和Spark-1.6.1。
配置Hadoop,設置每個節點有10個Map slots和6個Reduce slots,采用默認的Hash分區函數,其他配置設置為默認值。為增強實驗的說服力,同一組實驗運行5次,取5次結果的平均值作為最終結果。
4.2 實驗數據
對于兩種數據源作去重和格式化處理,并將數據處理為1-跳的形式。實驗數據分為合成數據和真實數據,合成數據通過GTgraph[11]生成,包含DARPA HPCS SSCA (SSCA)和Recursive Matrix (R-MAT)數據,SSCA的參數設置:頂點數為220,極大團的大小為100;R-MAT設置頂點數為104,邊與頂點的比值為1 000。真實數據包含兩種SOCIAL NETWORKS[12]數據,數據的分布情況如表1所示。
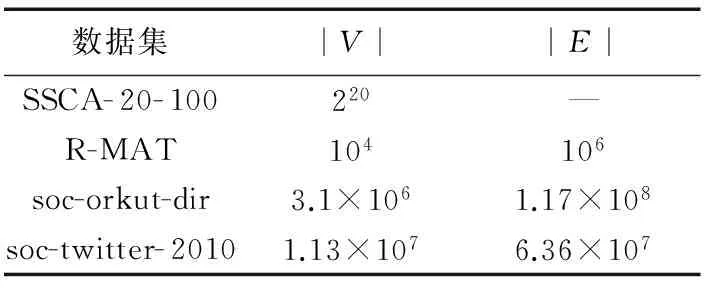
表 1 實驗數據Tab. 1 Experimental data
4.3 對比實驗
本節在合成數據集和真實數據集上比較兩種算法的運行時間。實驗采用隨機選點,驗證選點個數的不同對兩種算法運行時間的影響。由于GT算法首先需要將一跳數據集全部轉換為三角形數據集,這部分需要兩輪MapReduce任務完成,經過5次測試,這部分的平均時間為3 200 s。由于是處理部分點,在對比實驗部分,不將這部分的時間計算在內;因此運行時間的統計分別為:GT算法為從全部三角形數據集中讀取部分點的時間,PGT算法為從一跳數據集直接生產部分點的三角形數據集的時間。
圖2(a)、(b)分別是兩種算法在合成數據集SSCA和R-MAT上的實驗,圖2(c)、(d)分別是兩種算法在真實數據集Orkut和Twitter上的實驗。通過結果可以發現,GT算法和PGT算法都有很好的穩定性,而從運行時間上來看,在SSCA和R-MAT數據集上,GT算法的運行時間是PGT算法的3倍和4倍。隨著輸入數據量的增大,在真實數據集Orkut和Twitter上,GT算法的運行時間都是PGT算法運行時間的11倍。由此可見PGT算法在運行效率上有很大的提升。
4.4 Spark性能實驗
由于GT算法本身只有MapReduce實現,因此本節給出PGT算法在Hadoop和Spark系統上運行的對比實驗,使用的數據集為圖2(d)的Twitter數據集,對比實驗如圖3所示。
從圖3結果可以看出,Spark系統在運行時間上比Hadoop系統有近7倍的性能提升,這主要因為Spark在迭代過程中未將結果寫入磁盤,從而減少了對磁盤的讀寫操作。
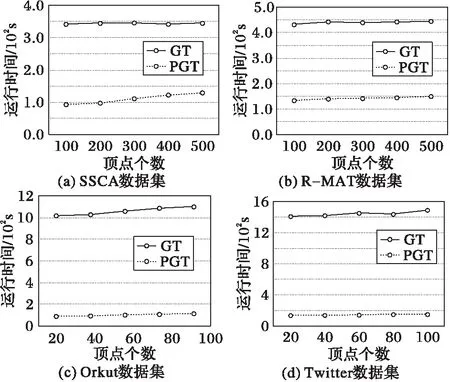
圖2 GT和PGT算法在不同數據集上的運行時間對比Fig. 2 Runtime contrast of GT and PGT on different datasets
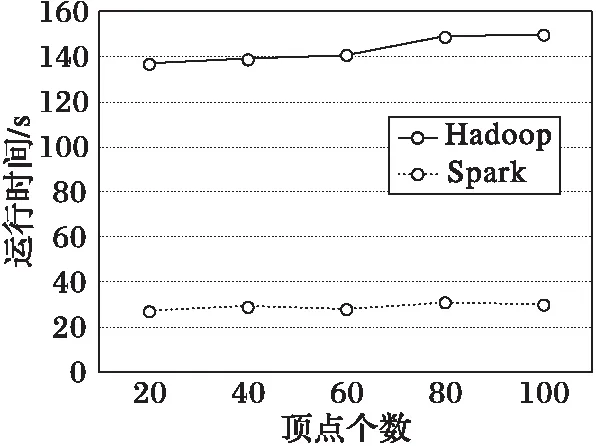
圖3 Spark與Hadoop上PGT算法運行時間對比Fig. 3 Runtime contrast of PGT algorithm on Spark and Hadoop
5 結語
本文提出一種改進的PGT算法,用于枚舉部分點的三角形結構,并給出算法的MapReduce實現和Spark實現方法。該算法與傳統算法相比,可以在三角形的生成過程中,只生成部分點的三角形結構,而避免對非篩選節點的三角形枚舉工作,并最后在合成數據集和真實數據集上,驗證該算法的高效性。三角形枚舉是圖數據研究中重要的應用,今后可通過本文的方法實現快速的三角形結構枚舉。
References)
[1] PARANJAPE A, BENSON A R, LESKOVEC J. Motifs in temporal networks [C]// Proceedings of the 2017 Tenth ACM International Conference on Web Search and Data Mining. New York: ACM, 2017: 601-610.
[2] WANG Z, CHEN Q, HOU B Y, et al. Parallelizing maximal clique andk-plex enumeration over graph data [J]. Journal of Parallel and Distributed Computing, 2017, 106: 79-91.
[3] COHEN J. Trusses: cohesive subgraphs for social network analysis [R]. Fort Meade, MD: National Security Agency, 2008.
[4] 金宏橋,董一鴻.大數據下圖三角計算的研究進展[J].電信科學,2016,32(6):153-162.(JIN H Q, DONG Y H. Research progress of triangle counting in big data [J]. Telecommunications Science, 2016, 32(6): 153-162.)
[5] SHAIK F, SUBRAMANYAM R, SOMAYAJULU D. Map-reduce based multiple sub-graph enumeration using dominating-set graph partition [J]. International Journal of Information Engineering and Electronic Business, 2017, 9(2): 36-44.
[6] QIN L, YU J X, CHANG L J, et al. Scalable big graph processing in MapReduce [C]// Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2014: 827-838.
[7] SALIHOGLU S, WIDOM J. GPS: a graph processing system [C]// Proceedings of the 25th International Conference on Scientific and Statistical Database Management. New York: ACM, 2013: Article No. 22.
[8] COHEN J. Graph twiddling in a MapReduce world [J]. Computing in Science & Engineering, 2009, 11(4): 29-41.
[9] 王卓,陳群,李戰懷,等.基于增量式分區策略的MapReduce數據均衡方法[J].計算機學報,2016,39(1):19-35.(WANG Z, CHEN Q, LI Z H, et al. An incremental partitioning strategy for data balance on MapReduce [J]. Chinese Journal of Computers, 2016, 39(1): 19-35.)
[10] ZHANG Y F, CHEN S M, WANG Q, et al. i2MapReduce: incremental MapReduce for mining evolving big data [J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(7): 1906-1919.
[11] BADER D A, MADDURI K. GTGraph: a synthetic graph generator suite [EB/OL]. [2017- 05- 06]. https://www.researchgate.net/publication/228993783_GTGraph_A_synthetic_graph_generator_suite.
[12] ROSSI R A, AHMED N K. The network data repository with interactive graph analytics and visualization [C]// Proceedings of the 2015 Twenty-Ninth AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2015: 4292-4293.
This work is partially supported by the Ministry of Science and Technology of China, National Key Research and Development Program (2016YFB1000703), the National High Technology Research and Development Program of China (863 Program) (2015AA015307), the Key Program of National Natural Science Foundation of China (61332006), the General Program of National Natural Science Foundation of China (61672432, 61472321), the National Natural Science Foundation of China for Young Scholars (61502390).
WANGZhuo, born in 1984, Ph. D. candidate. His research interests include graph data management, distributed computing platform.
SUOBo, born in 1987, Ph. D. candidate. His research interests include graph data management.
PANWei, born in 1978, Ph. D., associate professor. His research interests include memory computing.
Parallelalgorithmfortriangleenumeration
WANG Zhuo, SUO Bo, PAN Wei*
(SchoolofComputerScience,NorthwesternPolytechnicalUniversity,Xi’anShaanxi710129,China)
The classical Graph Twiddling (GT) algorithm is the MapReduce implementation of triangle parallel enumeration algorithm. However, the GT algorithm can only enumerate the triangle structure of whole graph and can not enumerate the triangle structure of candidate vertexes directly. To solve the problem, a parallel algorithm was proposed for directly enumerating the triangle structure of candidate vertexes. Firstly, the set of all the combinations of candidate vertexes for forming triangle was given by analyzing the distribution of candidate vertexes. Then, through the screening of the set, the triangle structure of candidate vertexes was directly enumerated. Finally, the proposed algorithm was implemented on Spark to achieve high efficiency and popularity. The contrast experiment was completed on artificial datasets and real datasets. The experimental results show that, compared with the GT algorithm, the running time of the proposed algorithm is only 1/3 of the running time of GT algorithm, and the running time on Spark is only 1/7 of the running time on Hadoop. The proposed algorithm can be used to generate the triangle dataset of any candidate vertex directly and efficiently.
triangle enumeration; large-scale graph data; MapReduce; candidate vertex enumeration; Spark
2017- 07- 04;
2017- 09- 05。
中國科技部國家重點研發計劃項目(2016YFB1000703);國家863重大項目(2015AA015307);國家自然科學基金重點項目(61332006);國家自然科學基金面上項目(61672432,61472321);國家自然科學基金青年項目(61502390)。
王卓 (1984—),男,河南濮陽人,博士研究生,CCF會員,主要研究方向:圖數據管理、分布式計算平臺; 索勃(1987—),男(滿族),遼寧錦州人,博士研究生,主要研究方向:圖數據管理; 潘巍(1978—),男,陜西西安人,副教授,博士,CCF會員,主要研究方向:內存計算。
1001- 9081(2017)12- 3397- 04
10.11772/j.issn.1001- 9081.2017.12.3397
(*通信作者電子郵箱wzhuo918@mail.nwpu.edu.cn)
TP311.131
A
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代企業(2015年9期)2015-02-28 18:56:50
