基于Spark的并行ALS協(xié)同過濾算法研究?
2017-12-18 06:21:49侯敬儒李英娜
計算機與數(shù)字工程 2017年11期
侯敬儒 吳 晟 李英娜
(昆明理工大學信息工程與自動化學院 昆明 650500)
基于Spark的并行ALS協(xié)同過濾算法研究?
侯敬儒 吳 晟 李英娜
(昆明理工大學信息工程與自動化學院 昆明 650500)
ALS(最小二乘法)協(xié)同過濾推薦算法是通過矩陣分解進行推薦,它通過綜合大量的用戶評分數(shù)據(jù)進行計算,并存儲計算過程中產(chǎn)生的大量特征矩陣。Hadoop的HA(高可用性)用來解決HDFS分布式文件系統(tǒng)的NameNode單點故障問題。Spark是一種基于內(nèi)存的新型分布式大數(shù)據(jù)計算框架,具有優(yōu)異的計算性能。文章基于QJM(Quorum Journal Manager)構(gòu)建了HA下的Hadoop大數(shù)據(jù)平臺,并在Spark計算框架基礎上研究使用ALS協(xié)同過濾算法,實現(xiàn)基于ALS協(xié)同過濾算法在Spark上的并行化運行;通過和基于Hadoop的MapReduce思想的ALS協(xié)同過濾算法在Netflix數(shù)據(jù)集上的比對實驗表明,基于Spark平臺的ALS協(xié)同過濾算法的并行化計算效率有明顯提升,并且更適合處理海量數(shù)據(jù)。
ALS;協(xié)同過濾;矩陣分解;High Available;Spark
1 引言
當前,整個世界已經(jīng)迎來了大數(shù)據(jù)時代,在新零售等新興業(yè)態(tài)形式下,互聯(lián)網(wǎng)用戶飛速增長以及互聯(lián)網(wǎng)科技迅猛發(fā)展,在以用戶為中心的信息生產(chǎn)模式下,互聯(lián)網(wǎng)信息爆炸式增長[1],不僅數(shù)據(jù)量越來越大,數(shù)據(jù)類型也越來越大,人們正面臨著嚴重的“信息過載”問題[2]。目前,解決該問題的技術(shù)主要分為兩類,第一類是信息檢索技術(shù)-搜索引擎,第二類是信息過濾技術(shù)-推薦系統(tǒng)[3]。區(qū)別在于搜索引擎依賴用戶對信息的準確描述,而推薦系統(tǒng)則是以用戶歷史行為和數(shù)據(jù)為基點,建立相關(guān)數(shù)據(jù)模型從而挖掘出用戶需求和興趣,從而以此為依據(jù)從海量的信息中為用戶篩選出用戶感興趣的信息。由此可見,在用戶需求不明確時,推薦系統(tǒng)的作用顯得尤為重要。
推薦系統(tǒng)中的協(xié)同過濾推薦技術(shù)簡單、高效,得到了業(yè)界廣泛的認同和應用。然而協(xié)同過濾技術(shù)也有缺點和不足,例如可擴展的問題、數(shù)據(jù)稀疏的問題、冷啟動的問題,這些問題往往會導致推薦系統(tǒng)的推薦質(zhì)量下降[4]。文章主要介紹的基于Spark的并行ALS協(xié)同過濾推薦算法模型中,通過一組隱性因子來預測缺失元素和表達用戶和商品。其所用的學習潛在因子的方法就是交替ALS最小二乘法。
2 HA(High Available)集群構(gòu)建
2.1 HA集群特點
一個成熟的企業(yè)級HA集群,在任何時間,只有一個NameNode處于活動狀態(tài),而另一個在備份狀態(tài),活動狀態(tài)的NameNode會響應集群中所有的客戶端,同時備份的只是作為一個副本,保證在必要的時候提供一個快速的轉(zhuǎn)移[5]。
為了使備份的節(jié)點和活動的節(jié)點保持一致,兩個節(jié)點通過一個特殊的守護線程相連,這個線程叫做“JournalNodes”(JNs)。當活動狀態(tài)的節(jié)點(Active NameNode)因為新的分布式應用而修改命名空間(NameSpace),它均會通過線程JNs記錄日志,備用的節(jié)點可以監(jiān)控edit日志的變化,并且通過JNs讀取到變化。備份節(jié)點查看edits可以擁有專門的namespace。在故障轉(zhuǎn)移的時候備份節(jié)點將在切換至活動狀態(tài)前確認它從JNs讀取到的所有edits。這個確認的目的是為了保證NameSpace的狀態(tài)和遷移之前是完全同步的。為了提供一個快速的轉(zhuǎn)移,備份NameNode要求保存著最新的block在集群當中的信息。為了能夠得到這個,DataNode都被配置了所有的NameNode的地址,并且發(fā)送block的地址信息和心跳給兩個node。
2.2 HA集群配置
2.2.1 基于QJM(Quorum Journal Manager)配置HA集群原理
QJM是基于Paxos算法的,如果配置2N+1臺JournalNode組成的集群,則最多能容忍N臺機器down機。QJM的體系結(jié)構(gòu)如圖1所示。
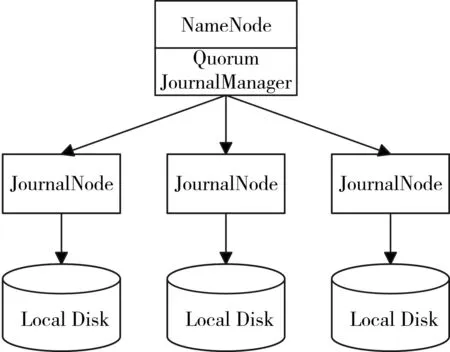
圖1 QJM體系結(jié)構(gòu)
用QJM的方式實現(xiàn)HA的主要好處有以下幾
點:
1)不再需要單獨配置Fencing實現(xiàn),因為QJM本身內(nèi)置了Fencing的功能。
2)不存在單點故障。
3)系統(tǒng)健壯性的程度是可配置的。
4)存儲日志的JournalNode不會因為其中一臺的延遲而影響整體的延遲,也不會因為JournalNode的數(shù)量增多而影響性能。
圖2所示為該實驗環(huán)境下由3個計算節(jié)點,2個控制節(jié)點組成的HA集群的拓撲結(jié)構(gòu)圖例,各個節(jié)點之間使用局域網(wǎng)連接。
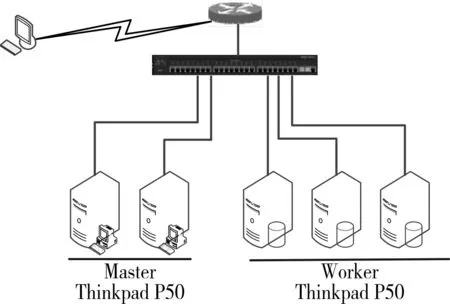
圖2 集群拓撲結(jié)構(gòu)
2.2.2 環(huán)境配置說明
ZooKeeper是提供一致性服務的軟件,它的功能包括:配置維護、名字服務、分布式同步、組服務等[6~7]。該實驗環(huán)境中使用Zookeeper保證Master節(jié)點down機之后能夠快速切換到StandByMaster,繼續(xù)為集群提供服務,從而使得整個集群正常工作,同時,也修復down機的Master。該環(huán)境部署的HA下的大數(shù)據(jù)實驗平臺由5臺機器構(gòu)成,包括2個Master節(jié)點和3個Worker節(jié)點,節(jié)點之間局域網(wǎng)連接。
該環(huán)境以Hadoop的HDFS為基礎存儲框架,主要以Spark為計算框架,Zookeeper統(tǒng)籌HA下的大數(shù)據(jù)平臺,管理整個集群配置。具體5個節(jié)點的具體功能如表1所示。
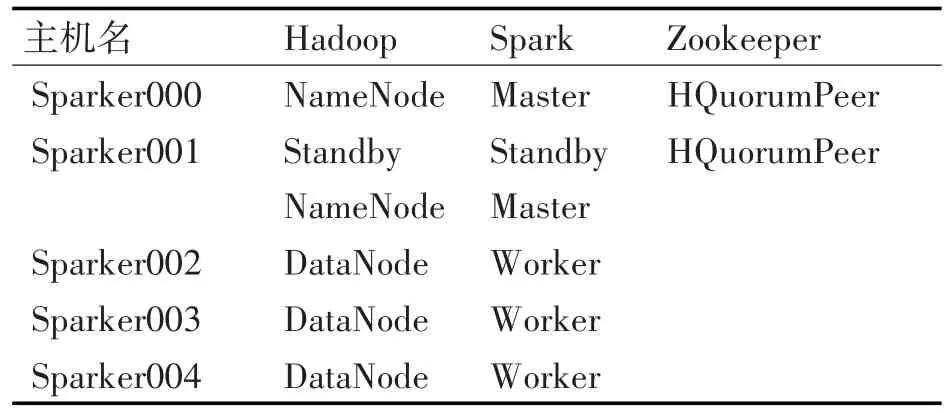
表1 節(jié)點功能
2.2.3 修改Zookeeper配置過程
1)確定Zookeeper的數(shù)據(jù)存放位置,并且設定server的端口,響應時間等:
vim zoo.cfg
dataDir=/home/sparker/zookeeper-3.4.5/data
server.1=sparker000:2888:3888
server.2=sparker001:2888:3888
server.3=sparker005:2888:3888
tickTime=2000
initLimit=5
syncLimit=2
clientPort=2181
2)新建data文件夾:
/home/sparker000/zookeeper/下新建 data文件夾,然后在該文件夾下新建文件,文件名為myid,向其中加入server.1/2/3中的值,此處填1。
3)將安裝完的Zookeeper分發(fā)到其他機器:
由于我們只在一臺機器上安裝了Zookeeper,所以需要將配置好的文件分發(fā)到其他的機器上,使用scp命令:
scp/-r/zookeeper-3.4.5 192.168.1.101:/home/sparker001/scp/-r/zookeeper-3.4.5 192.168.1.102:/home/sparker002/
修改101/102上中/data/myid的值。與server后面的值對應。在101中myid修改為2,在102中myid修改為3。
4)修改profile文件:
修改/etc/profile系統(tǒng)環(huán)境變量配置文件,加入zookeeper的環(huán)境變量
exportZOOKEEPER_HOME=/home/sparker000/zookeeper-3.4.5
exportPATH=$PATH:$ZOOKEEPER_HOME/bin
2.3 分布式計算框架-Spark
Apache Spark官方的定義為:Spark是一個通用的大規(guī)模數(shù)據(jù)快速處理引擎[8]。可以簡單理解為Spark就是一個大數(shù)據(jù)分布式處理框架[8]。相比于傳統(tǒng)的以Hadoop為基石的第一代大數(shù)據(jù)技術(shù)生態(tài)系統(tǒng)而言,Spark無論是性能還是方案的統(tǒng)一性都具有極為顯著的優(yōu)勢。在Spark中,數(shù)據(jù)集的劃分和任務的調(diào)度都是系統(tǒng)自動完成的,其工作流程如圖3所示。

圖3 Spark工作流程
其中,Driver是用戶編寫的Spark程序(用戶編寫的數(shù)據(jù)處理邏輯),這個邏輯中包含用戶創(chuàng)建的SparkContext。SparkContext是用戶邏輯與Spark集群主要的交互接口,它會和Cluster Manager交互,包括向它申請計算資源等。Cluster Manager負責集群的資源管理和調(diào)度,現(xiàn)在支持Standalone、Apache Mesos和Hadoop的Yarn。工作節(jié)點(Worker Node)是集群中可以執(zhí)行計算任務的節(jié)點。Executor是在一個工作節(jié)點(Worker Node)上為某分布式應用程序啟動的一個負責運行任務的進程,并且負責將所需要的數(shù)據(jù)存在內(nèi)存或者磁盤上。每個應用都有各自獨立的Executor,計算最終在計算節(jié)點的Executor中執(zhí)行[9]。
3 基于Spark的ALS協(xié)同過濾算法研究
3.1 ALS協(xié)同過濾算法
基于矩陣分解模型的協(xié)同過濾推薦算法主要有:SVD(奇異值分解)和ALS[10]。下面就ALS算法理論做一個介紹。
對于Sm×n矩陣,ALS主要是找到2個低維矩陣Xm×k和Yn×k來近似逼近 Sm×n,即:

其中Sm×n表示用戶對產(chǎn)品的偏好評分矩陣,Xm×k代表用戶對隱含特征的偏好矩陣,Yn×k表示產(chǎn)品所包含的隱含特征矩陣。通常取k?min(m,n),也就是相當于降維了。
為了找到使矩陣X和Y盡可能地無限接近S,需要最小化平方誤差損失函數(shù):
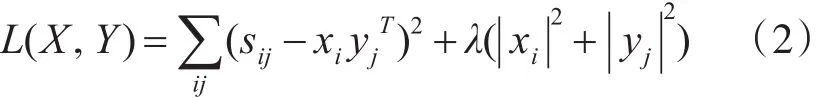
其中 Xi表示用戶i的偏好的隱含特征向量,yj表示商品 j包含的隱含特征向量,sij表示用戶i對商品 j的偏好評分,xiyjT是用戶i對商品 j偏好評分的近似,λ表示正則化項的系數(shù)。其求解方法如下:
先固定Y,將誤差損失函數(shù)L(X,Y)對 Xi求偏導,并另導數(shù)=0,得到:
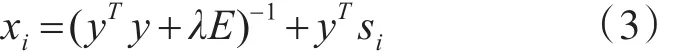
同理固定X,可得:
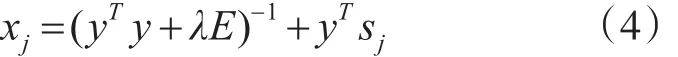
其中 xi是S的第i行,xj是S的第 j列,E是k×k的單位矩陣。
其迭代步驟是:首先隨機初始化Y,利用式(3)更新得到 X,然后利用式(4)更新Y,直到RMSE(均方根誤差)變化很小或者到達最大迭代次數(shù)為止[11]。其RMSE的計算公式如下:
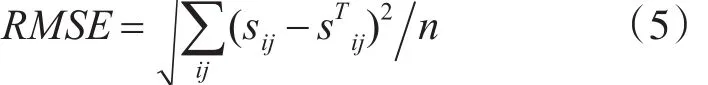
8)While iter<setValue//依據(jù)設定的次數(shù)迭代計算
9)Update user//更新User的因子矩陣
10)RDD[(Int,Array[Array[Double]])]?
11)Update item//更新Item的因子矩陣
12)End while
3.2 基于Spark的ALS協(xié)同過濾算法并行化實現(xiàn)
輸入:評分數(shù)據(jù)
輸出:矩陣分解模型
算法基本邏輯步驟如下:
1)var partitionNum//設置分區(qū)數(shù)
2)var sc=new SparkContext()
3)讀入數(shù)據(jù)生成
Ratings:RDD[Rating],Ratings是序列
<user:Int,Item:Int,rating:Double>
4)依據(jù)用戶設置或者默認的并行化數(shù)生成RatingsOfUserBlock、RatingsOfItemBlock的
RatingsOfUserBlock:Rating<u,p,R>—→——map<u,u,p,r>
RatingsOfItemBlock:Rating<u,p,R><p,p,u,r>
5)生成基于User或者Item的InLinkRDD(內(nèi)連接信息)和OutLinkRDD(外連接信息)
6)將內(nèi)外連接信息cache到內(nèi)存中,減少磁盤I/O
7)初始化用戶-項目因子矩陣
4 實驗結(jié)果分析
4.1 實驗數(shù)據(jù)集
本實驗采用Netflix發(fā)布的電影評分數(shù)據(jù)集(TrainingSet、ProbeSetQualifyingSet)。該數(shù)據(jù)集包括用戶數(shù):480189,電影數(shù):17770,評分數(shù):103297638。其中,評分值都是整數(shù)值(1~5之間),分數(shù)越高則客戶對相應電影的評分就越高。本實驗分為兩組,第一組使用整個數(shù)據(jù)集(665MB)為DataSet1;第二組隨機抽取5000萬條數(shù)據(jù)(330MB)作為DataSet2。將DataSet1、DataSet2分別分成兩部分,其中90%歸為訓練數(shù)據(jù)集,10%歸為測試數(shù)據(jù)集。
4.2 結(jié)果分析
文中分別做了兩組實驗,即基于ALS的協(xié)同過濾算法分別在基于Hadoop的MapReduce集群上和基于RDD的Spark集群上并行化實現(xiàn)。基于ALS的協(xié)同過濾算法模型中有兩個參數(shù):特征個數(shù)(復數(shù)范圍內(nèi),矩陣的階數(shù)和特征值個數(shù)是對應的)、迭代次數(shù)Iteration。
在第一組實驗中,數(shù)據(jù)集采用DataSet1,設定默認特征個數(shù)為20,Iteration迭代次數(shù)依次為1、10、20、30、40、50,分別在集群上的實驗結(jié)果如圖4所示。
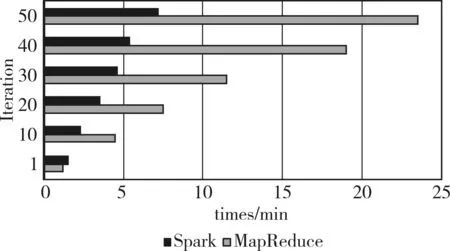
圖4 DataSet1
由圖4可以看出,隨著Iteration的增加,基于ALS的協(xié)同過濾算法分別在兩種集群上的運行時間比例也在增加,當?shù)螖?shù)Iteration增加為50時,比例為3.3。由圖4可知,當?shù)螖?shù)設置為1次時,ALS協(xié)同過濾算法在基于Hadoop的MapReduce集群上運行時間比在基于內(nèi)存的Spark集群上的運行時間短,原因是ALS協(xié)同過濾算法在基于內(nèi)存的集群上的第一次迭代與基于Hadoop的MapReduce一樣,需要創(chuàng)建新job,所以在基于內(nèi)存的Spark集群上實現(xiàn)第一次迭代時運行速度比較慢。據(jù)之前分析,對基于Hadoop的MapReduce實現(xiàn)方式,每迭代一次就需要創(chuàng)建一個新的分布式job,如果迭代次數(shù)越多,需要執(zhí)行的分布式job數(shù)量就越多。所以,隨著迭代次數(shù)的增加,基于內(nèi)存的Spark集群上的實現(xiàn)方式無需建立新的分布式job的優(yōu)勢得以發(fā)揮,該算法運算效率也提高的更明顯。
在第二組實驗中,數(shù)據(jù)集采用DataSet2,設定默認特征個數(shù)為20,Iteration迭代次數(shù)依次為1,10,20,30,40,50,分別在集群上的實驗結(jié)果如圖5所示。
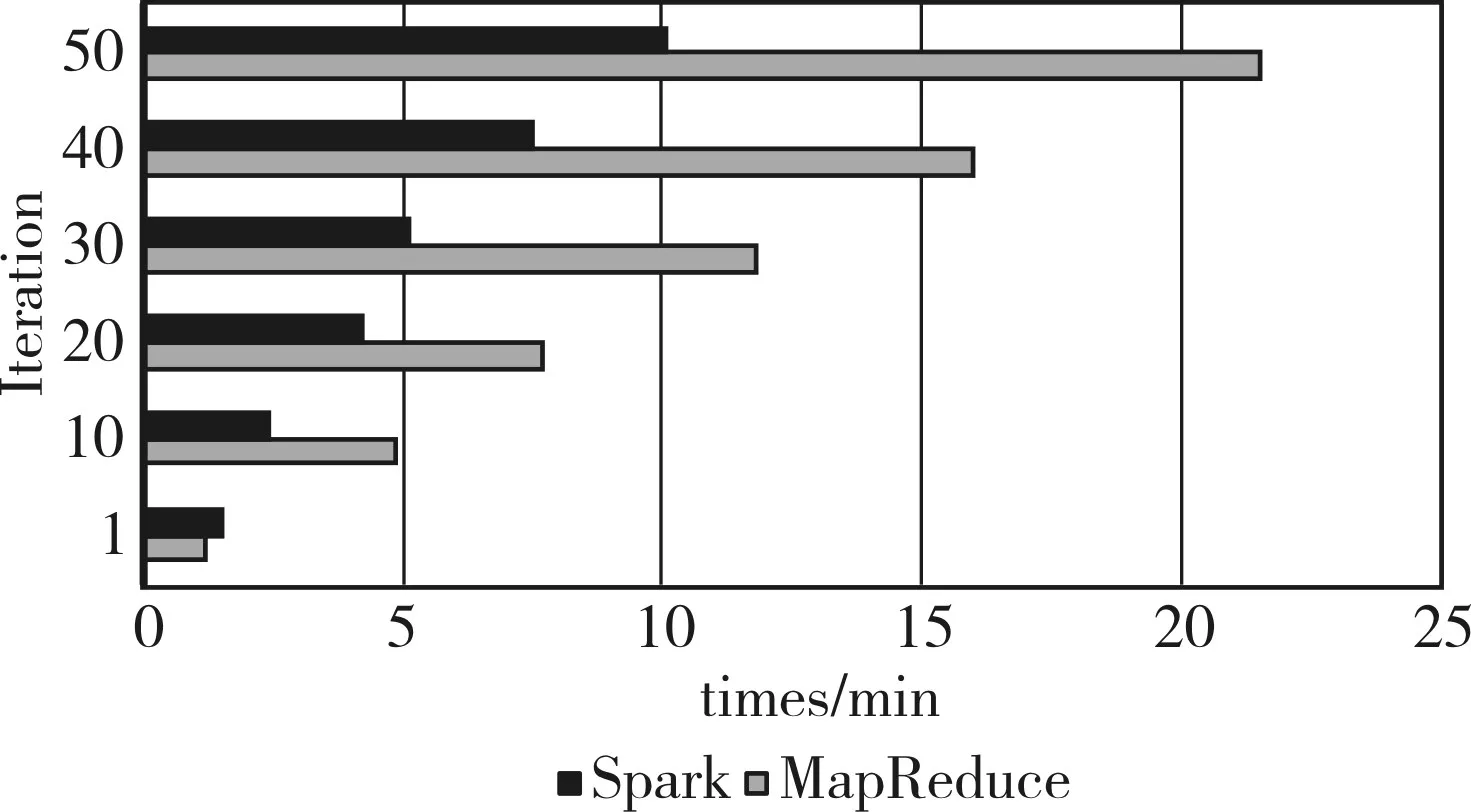
圖5 DataSet2
由圖5可以看出,同第一組實驗,隨著Iteration的增加,基于ALS的協(xié)同過濾算法分別在兩種集群上的運行時間比例也在增加,當?shù)螖?shù)Iteration增加為50時,比例為2∶1。據(jù)之前分析可知,數(shù)據(jù)集越大創(chuàng)建新的分布式job所需要的時間就越久,基于內(nèi)存的Spark集群實現(xiàn)方式比基于Hadoop的MapReduce實現(xiàn)方式優(yōu)勢更加明顯,而第二組實驗數(shù)據(jù)集DataSet2比第一組實驗數(shù)據(jù)集DataSet1小,故第二組實驗比第一組實驗運行效率提高的比例小。
通過以上兩組實驗,可以看出當數(shù)據(jù)集越大,算法設置的迭代次數(shù)Iteration越多,并行ALS協(xié)同過濾算法在基于內(nèi)存的Spark集群上的運算效率提高的就越多。
5 結(jié)語
文章構(gòu)建了基于QJM的HA下的大數(shù)據(jù)平臺,并通過對基于ALS即交替最小二乘法的協(xié)同過濾算法進行研究,將基于ALS的協(xié)同過濾算法分別在基于Hadoop的MapReduce和基于內(nèi)存的Spark上并行化實現(xiàn),在Netflix數(shù)據(jù)集上進行實驗,結(jié)果表明通過在基于內(nèi)存的Spark集群上提高了基于ALS協(xié)同過濾算法的分布式計算效率。
由于實驗數(shù)據(jù)量還不夠大,還不能看出基于內(nèi)存的Spark對計算效率的顯著提升,據(jù)之前的原理分析可知,如果數(shù)據(jù)量越大,基于內(nèi)存的Spark計算效率的提升就會越明顯。Spark作為基于內(nèi)存的分布式數(shù)據(jù)處理框架,接下來需要展開的研究如下:1)智能化ALS模型訓練參數(shù)的選擇,幫助我們自動選擇最優(yōu)參數(shù);2)基于Spark Streaming的ALS協(xié)同過濾算法研究。
[1]鄧鵬,李枚毅,何誠.Namenode單點故障解決方案研究[J].計算機工程,2012,38(21):40-44.DENG Peng,LI Meiyi,HE Cheng.Research on Namenode Single Point of Fault Solution[J].Computer Engineering,2012,38(21):40-44.
[2]楊帆.Hadoop平臺高可用性方案的設計與實現(xiàn)[D].北京:北京郵電大學,2012.YANG Fan.Design and Implementation of High Availability Solution for Hadoop[D].Beijing:Beijing University Of Posts And Telecommunications,2012.
[3]黃強,沈奇威,李煒.Hadoop高可用解決方案研究[J].電信技術(shù),2015(11):16-19.HUANG Qiang,SHEN Qiwei,LI Wei.Research on High Availability Solution for Hadoop[J].Telecommunications Technology,2015(11):16-19.
[4]張宇,程久軍.基于MapReduce的矩陣分解推薦算法研究[J].計算機科學,2013,631-632(1):138-141.ZHANG Yu,CHENG Jiujun.Study on Recommendation Algorithm with Matrix Factorization Method Based on MapReduce[J].Computer Science,2013,631-632(1):138-141.
[5]劉青文.基于協(xié)同過濾的推薦算法研究[D].合肥:中國科學技術(shù)大學,2013.LIU Qingwen.Research on Recommender Systems based on Collaborative Filtering[D].Hefei:University of Science and Technology of China,2013.
[6]劉強.協(xié)同過濾推薦系統(tǒng)中的關(guān)鍵算法研究[D].杭州:浙江大學,2013.LIU Qiang.Study on key algorithms in Collaborative Filtering Recommender Systems[D].Hangzhou:Zhejiang University,2013.
[7]原默晗,唐晉韜,王挺.一種高效的分布式相似短文本聚類算法[J].計算機與數(shù)字工程,2016,44(5):895-900.YUAN Mohan,TANG Jintao,WANG Ting.An Efficient Distributed Similar Short Texts Clustering Algorithm[J].Computer&Digital Engineering,2016,44(5):895-900.
[8]孫遠帥.基于大數(shù)據(jù)的推薦算法研究[D].廈門:廈門大學,2014.SUN Yuanshuai.Recommendation Algorithms in the Big Data Era[D].Xiamen:Xiamen University,2014.
[9]鄧雄杰.基于Hadoop的推薦系統(tǒng)的設計與實現(xiàn)[D].廣州:華南理工大學,2013.DENG Xiongjie.The Design and Implementation of Recommendation System based on Hadoop[D].Guangzhou:South China University of Technology,2013.
[10]鄭鳳飛,黃文培,賈明正.基于Spark的矩陣分解推薦算法[J].計算機應用,2015,35(10):2781-2783.ZHENG Fengfei,HUANG Wenpei,JIA Mingzheng.Matrix factorization recommendation algorithm based on Spark[J].Journal of Computer Applications,2015,35(10):2781-2783.
[11]陳夢杰,陳勇旭,賈益斌,等.基于Hadoop的大數(shù)據(jù)查詢系統(tǒng)簡述[J].計算機與數(shù)字工程,2013,41(12):1939-1942.CHEN Mengjie,CHEN Yongxu,JIA Yibin,et al.A Brief Introduction Hadoop—based Big Data Query System[J].Computer& DigitalEngineering,2013,41(12) :1939-1942.
Research on Parallel Als Algorithm Based on Spark
HOU Jingru WU Sheng LI Yingna
(Kunming University of Science and Technology,School of Information Engineering and Automation,Kunming 650500)
ALS(least square)is a collaborative filtering recommendation algorithm recommended by matrix decomposition,it is calculated by a combination of a large number of user rating data,and stored the calculation process of a large number of characteristic matrix.Hadoop-HA(High Available)is used to solve the problem of the single point of failure of the NameNode.The Spark is a computing framework based on new type of large data come up with distributed memory,at the same time it has excellent computing performance.This study uses the QJM(Quorum Journal Manager)to construct the HA Hadoop big data platform.In this study,uses the ALS collaborative filtering algorithm with the spark coding Framework,at the same time,this study realizes the ALS collaborative filtering algorithm based on the Spark of parallel operation.Through the comparation experiments(the ALS collaborative filtering algorithm based on Hadoop graphs thought and the Netflix data set),the study based on Spark platform of parallel computation is more efficiency.It is more suitable for processing huge amounts of data.
ALS,collaborative filtering,Matrix decomposition,High Available,Spark
TP301
10.3969/j.issn.1672-9722.2017.11.024
Class Number TP301
2017年5月12日,
2017年6月14日
國家自然科學基金項目(編號:51467007)資助。
侯敬儒,男,碩士研究生,研究方向:數(shù)據(jù)挖掘與機器學習。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
