基于改進Elman神經網絡的語音情感識別技術研究?
2017-12-18 06:22:43王穎
計算機與數字工程 2017年11期
王 穎
(東北石油大學計算機與信息技術學院 大慶 163000)
基于改進Elman神經網絡的語音情感識別技術研究?
王 穎
(東北石油大學計算機與信息技術學院 大慶 163000)
語音情感特征從時間粒度的角度可分為全局統計特征和瞬時特征。針對語音情感的動態特性,提出一種改進Elman神經網絡模型實現語音情感識別。網絡模型將全局特征信號與時序信號作為輸入,并根據輸入信號特征自動修改網絡結構,不僅實現全局特征信號與時序信號的融合,還提供系統整體識別率。
語音情感特征;改進Elman神經網絡;全局特征信號;時序特征信號
1 引言
語音情感識別研究的開展距今已有30余年的歷史,在此期間,它得到了世界范圍內相關研究者們的廣泛關注,也取得了一些令人矚目的成績,如其在遠程網絡教學、醫療輔助、反恐偵測和客戶服務等領域的應用得到廣泛認可。尤其將人工智能應用于語音情感識別領域后,更是取得了不俗的成績[1]。在此期間也針對語音情感識別提出了許多新型的神經網絡模型,如韓文靜等提出的GCElman和何亮提出的IN-GABP在語音情感識別方面都取得了較好的成績[2~6]。
在取得以上成績的同時也面臨著諸多問題的考驗與挑戰,如網絡模型訓練時間和訓練樣本的選取。尤其對于作為輸入的語音情感特征信號的選取將直接決定識別的成功幾率[7]。在此之前一些網絡模型均只單獨針對短時時序特征信號進行識別或語段特征信號進行識別,本文在前人的基礎上進行學習和研究,并對傳統的Elman神經網絡進行優化,提出一種優化的Elman神經網絡模型,可根據輸入特征信號自動修改網絡模型結構,一方面能夠將全局統計特征和時序特征進行有效的融合,另一方面能夠有效的提高系統的整體識別率[8~12]。
2 改進Elman神經網絡模型
2.1 改進Elman神經網絡模型
Elman神經網絡較傳統動態神經網絡除包含輸入、輸出和隱含層外還包含一個連接層,負責記憶前一時刻的輸出,基于此特性,Elman神經網絡被應用在在語音情感識別領域[13]。
當以語句情感征作為輸入時,基于Elman神經網絡的結構特點,根據連接層記錄的前一時刻的輸出,結合當前時刻的輸出語音情感識別和分析取得較好的成績。但當輸入為語段情感特征時,傳統Elman神經網絡退化為MLP網絡,失去其連接層的延時算子特性。因此有學者提出了基于全局特征的Elman神經網絡模型,如OHF Elman神經網絡模型[14]和GCElman神經網絡模型等[15]。但大多數適用于全局時序特征的網絡模型均增加了網絡模型結構復雜度,以時間為代價來換取識別準確度,但當識別信號為基于語句的時序信號時,此類網絡模型雖增加了網絡訓練時間卻并沒有換來識別精度的顯著提高,比較浪費資源甚至容易陷入局部極小值導致無法收斂[16]。
針對以上問題,本文提出一種新的改進Elman神經網絡模型。改進Elman神經網絡模型包括輸入層、隱含層、輸出層以及兩個連接層。網絡模型結構如圖1所示。其中輸入層包括兩部分:全局控制信號和時序信號。兩個連接層:連接層1為隱含層的延時算子,負責記憶隱含層前一時刻的輸出;承接層2為輸出層的延時算子,負責記憶輸出層前一時刻的輸出。兩個連接層分別構造了各自的自反饋回路,并通過各自的自反饋增益因子實現系統動態回溯系統當前狀態前一時刻的信息甚至更為先前時刻的信息。改進Elman神經網絡模型較傳統Elman網絡模型在輸入層增加了特征信號的輸入,當特征信號為全局特征信號時,網絡的連接層1負責記憶隱含層的前一時刻輸出,連接層2負責記憶輸出層的前一時刻輸出,并與當前時刻的輸入一起反饋到網絡模型中,能夠有效提高基于語段的全局特征信號的識別。當特征信號為時序信號特征時,根據特征信號系數網絡模型將自動刪除連接層2,僅依靠前一時刻隱含層的輸出與當前時刻輸出對基于語句的特征信號進行識別,以減少網絡運行時間。

圖1 改進Elman神經網絡
2.2 改進Elman神經網絡數學模型
改進Elman網絡數據模型:
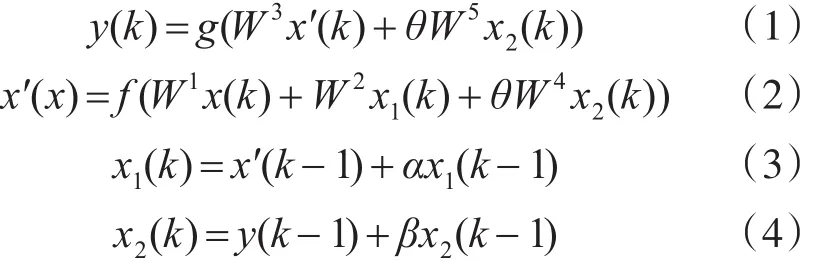
其中W1、W2、W3、W4、W5分別為輸入層至隱含層,連接層1至隱含層,隱含層至輸出層,連接層2至隱含層,連接層2至輸出層的連接權值;x1(k)和x2(k)分別為連接層1和連接層2的輸出;α(0≤α≤1)和 β(0≤β≤1)為連接層1和連接層2的子反饋增益因子;θ(θ∈{0,1})為輸入信號特征系數,當輸入信號為全局統計特征時為1,當輸入為時序特征信號時為0;f(·)為隱含層神經元的傳遞函數,本文采用Sigmoid函數,g(·)為輸出層神經元的激活函數,本文采用線性函數。
2.3 改進Elman神經網絡算法
改進Elman網絡采用動態BP算法對權值進行修正,設第k步系統的實際輸出為 y(k),定義誤差函數為
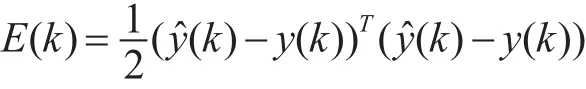
分別計算E(k)對連接權限值的偏導數,并使其等于0,可得到改進后的Elman網絡學習算法
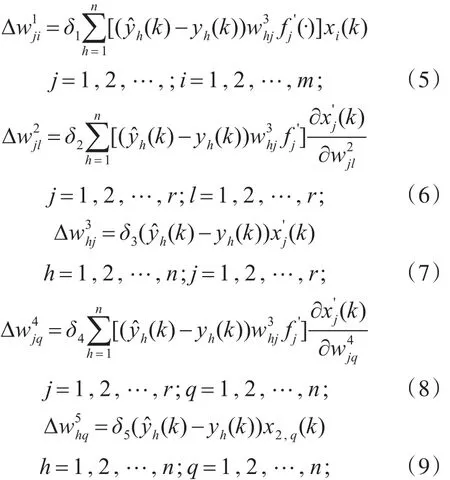
上式中:

其中 δ1、δ2、δ3、δ4、δ5分別為W1、W2、W3、W4、W5的學習步長;m、n、r分別為輸入層、輸出層、隱含層神經元的個數。式(10)和式(11)構成了梯度的動態遞推關系,因而可以實現對高階系統的有效辨識。
3 基于改進Elman網絡語音情感識別網絡模型訓練
語音情感特征從時間粒度的角度可分為全局統計特征和瞬時特征。全局統計特征用來描述語音在語句時長內的韻律學變化,它表征的是語音超音段方面的信息,一般認為全局統計特征對情感區分度較大。瞬時時序特征,即語音特征,主要用來描述語音的頻譜特性,它在語音的內容識別領域被廣法運用,對語義的區分度較大。
本文提出Elman網絡模型可根據輸入信號類型在后臺自動修改網絡結構,以適應不同類型信號的語音情感分析。與傳統Elman神經網絡輸入信號不同,改進Elman神經網絡輸入層中包含全局控制信號和時序特征信號兩部分內容。訓練過程中當某一樣本的輸入為全局統計特征信號時,網絡模型可自動過濾掉基于語句的時序特征,只接受該樣本中基于語段的特征,并自動調整該樣本的網絡輸出向量,保證其為本樣本所屬的情感類別向量。
3.1 基于時序特征的語音情感識別
本文從基音頻率參數、共振峰參數和短時能量參數中選取了24個特征參數。其中1~8為基音頻率參數,包括:基頻最大值、基頻最小值、基頻變化范圍、基頻局部最小值分布、基頻的均值、基頻方差、基頻變化率的均值、基頻變化率的方差;9~14為共振峰參數,包括:第一、二、三共振峰均值及其對應共振峰方差。15~24為短時能量參數,包括:短時能量及其差分的均值、最大值、最小值、中值、方差。

表1 前10最佳特征
本文使用fisher準則對所選取的特征參數進行特征評價,并選出了前10個最佳特征。
識別結果如表2所示。

表2 最佳特征組合識別結果
3.2 基于語段特征的語音情感識別
為驗證時序特性對情感識別率的影響,本文分別選取24種情況的語段長度。從10幀/段開始至240幀/段,以10幀的步長增長。為了保證實驗過程中所使用的測試樣本的語段長度與訓練樣本的語段長度相同,便于對測試結果進行交叉驗證,根據語段的長度的情況,對應的選取了24組訓練樣本。
24組訓練樣本全部訓練完成后輸入測試樣本進行驗證。通過測試樣本得出的驗證結果如圖2所示。通過圖2可以看出,不同的語段長度情感識別的結果也不相同,當識別率到160幀/段時識別的準確度最高,可達到68.7%,由此可得出160幀/段為識別的最佳語段長度。
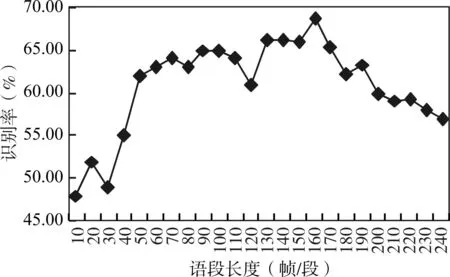
圖2 基于語段情感識別結果
4 實驗結果分析
上一節通過對網絡模型訓練及驗證得出圖3~圖6所示各類情感識別結果。如圖3所示,生氣情感的最佳識別語段長度為60幀/段,在該語段長度下,情感識別率可達到92.6%;如圖4所示,當語段長度為180幀/段時高興情感的識別率為最高,在該語段長度下,語音情感識別的識別率為58.3%;圖5中所示悲傷情感在語段長度為160幀/段時識別率達到最高,最高識別率為98.8%;圖6中所示驚奇的情感在語段長度為110幀/段時識別為75.7%,已達到該情感識別率的最高值。

圖3 生氣情感識別結果
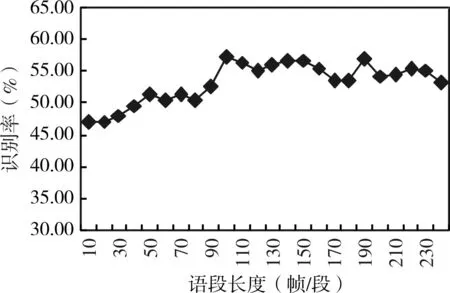
圖4 高興情感識別結果
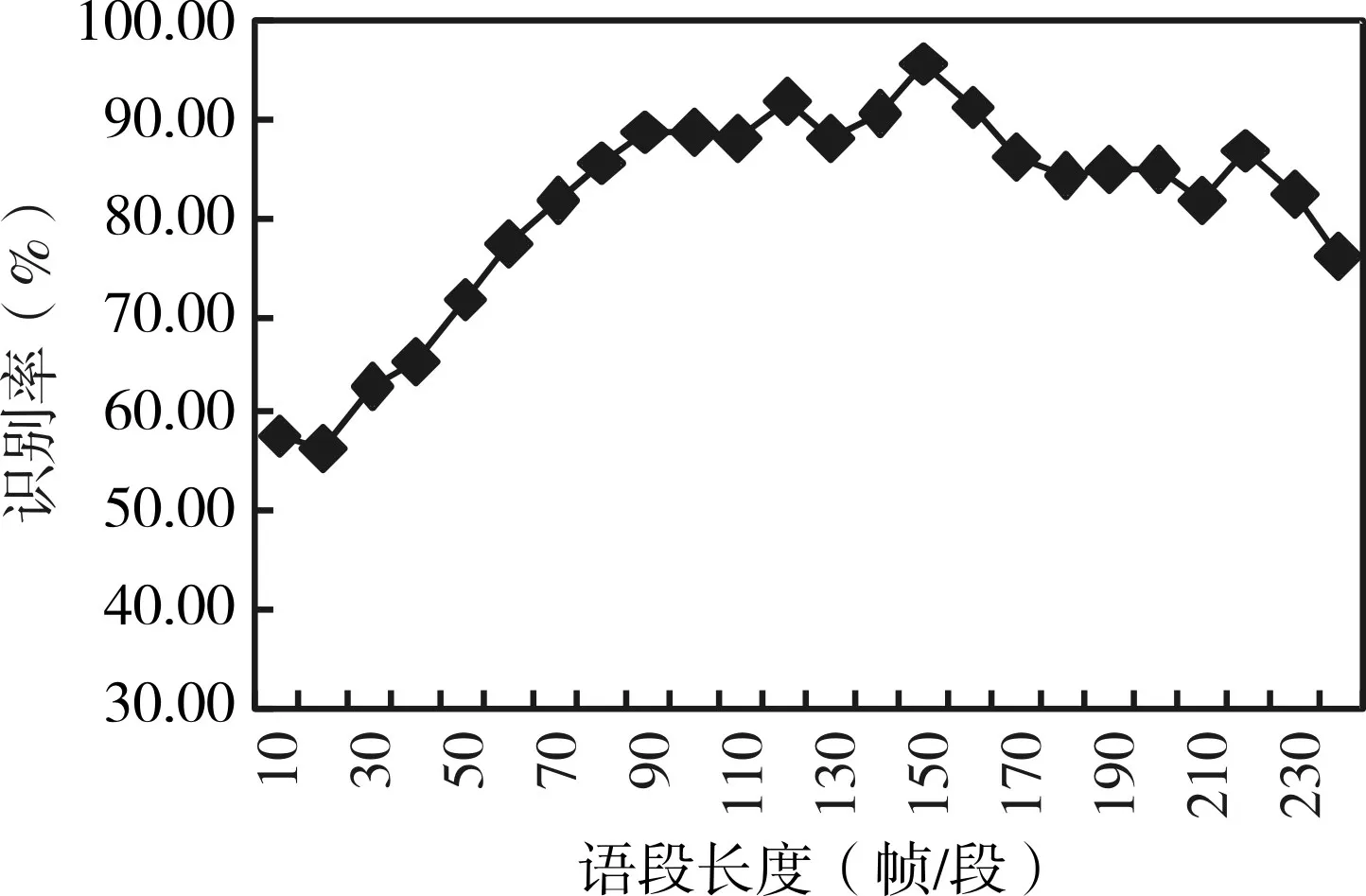
圖5 悲傷情感識別結果

圖6 驚訝情感識別結果
圖2 和圖3到圖6所示的實驗結果表明:語段的長度對情感識別率有較大的影響。而全局統計特征在一定程度能夠使某類情感的識別率達到最高,但并不能保證使系統的平均識別率達到最優。平均識別率在語段長度小于160幀/段時整體呈現上升趨勢,當語段長度等于160幀/段時達到最高,語段長度大于160幀/段時開始呈現下降趨勢。并且每種情感的最佳識別語段長度各不相同,高興和悲傷的最佳語段相對較長,生氣和驚奇相對較短,據此推測人耳對不同類別情感的敏感段長也不同。另外通過比較4類情感的識別率,發現在目前使用的情感特征和識別模型基礎上,悲傷類情感最容易被識別,相反對高興類情感的識別性能差強人意。
5 結語
本文提出一種改進的Elman神經網絡結構,并將其應用于語音情感識別領域,通過仿真實驗取得了較好的識別效果。實驗證明改進的Elman神經網絡模型能夠有效地對全局統計特征和時序特征進行融合,在保證網絡訓練不陷入局部極小值而導致無法收斂的情況下能有效提高系統的整體識別率。
[1]Kennedy J,Eberhart R C.Particle swarms optimization[C]//Proceedings of IEEE International Conference on Neural Networks,USA,1995:1942-1948.
[2]Ammar W,Nirod C,Tan K.Solving shortest path problem usingparticle swarm optimization[J].Soft Computing,2008,8(4):1643-1653.
[3] Marcio S,Evaristo C.Nonlinear parameter estimation through particle swarm optimization[J].Chemical Engineering Science,2008,63(6):1542-1552.
[4]C.J.Lin,S.J.Hong.The Design of Neuro-fuzzy Networks Using Particle Swarm Optimization and Recursive Singular Value Decomposition[J].Neurocomputing,2007,71(1-3):297-310.
[5]T.Souda,A.Silva,A.Neves.Particle Swarm based Data Mining Algorithms for classification task[J].Parallel Computing,2004,(30):767-783.
[6]F.Sahin,M.?.Yavuz,Z.Arnavut,?.Uluyol.Fault Diagnosis for Airplane Engines Using Bayesian Networks and Distributed Particle Swarm Optimization[J].Parallel Computing,2007,33(2):124-143.
[7]Hyun K,Kim J H.Quantum-inspired evolutionary algorithm fora class of combinational optimization[J].IEEE Transactions on Evolutionary Computing,2002,6(6):580-593.
[8]Shi Yuhui,Eberhart R.A Modified Particle Swarm Optimizer[C]//Proc.of IEEE International Conference on Evolutionary omputation.Anchorage,Alaska,USA:[s.n.],2007.
[8]黃程韋,趙艷等.實用語音情感的特征分析與識別的研究[M].電子與信息學報,2011,33(1):312-317.HUANG Chengwei,ZHAO Yan,et al.Research on feature analysis and recognition of practical speech emotion[M].Journal of electronics and information,2011,33(1):312-317.
[9]林奕琳,韋崗,楊康才.語音情感識別的研究進展[J].電路與系統學報,2007,12(1):90-98.LIU Yilin,WEI Gang,YANG Kangcai.Research Progress of Speech Emotion Recognition[J].Journal of Cirouits and Systems,2007,12(1):90-98.
[10]郭鵬娟,蔣冬梅.基于基頻特征的情感語音識別研究[M].計算機應用研究,2007,24(10):2056-2058.LIN Yilin,WEI Gang,YANG Kangcai.Advances in speech emotion recognition[M].Journal of circuits and systems,2007,12(1):569-574.
[11]姜曉慶,田嵐,崔國輝.多語種情感語音的韻律特征分析和情感識別研究[J].聲學學報,2006,3(13):569-574.JIANG Xiaoqing,TIAN LAN,CUI Guohui.Prosodic feature analysis and emotion recognition of multilingual emotional speech[J].Journal of acoustics,2006,3(13):569-574.
[12]趙力,錢向民等.語音信號中的情感識別研究[J].軟件學報,2001,12(7):1036-1038.ZHAO Li,QIAN Xiangming,et al.Research on emotion recognition of speech signal[J].Journal of software,2001,12(7):1036-1038.
[13]余伶俐,周開軍,邱愛兵.基于Elman神經網絡的語音情感識別應用研究[J].計算機應用研究,2012,29(5):56-58.YU Lingli,ZHOU Kaijun,QIU Hong.Application Research of speech emotion recognition based on Elman neural network[J].Computer application research,2012,29(5):56-58.
[14]韓文靜.基于神經網絡的語音情感識別技術研究[D].哈爾濱工業大學,2007:339-345.HAN Wenjing.Research on speech emotion recognition technology based on neural network[D].Harbin Institute of Technology,2007:339-345.
[15]時小虎.Elman神經網絡與進化算法的若干理論研究及應用[D].長春:吉林大學,2006:789-794.SHI Xiaohu.Theoretical research and application of Elman neural network and evolutionary algorithm[D].Changchun:Jilin University,2006:789-794.
[16]趙志剛,常成.帶變異算子的自適應粒子群優化算法[J].計算機工程與應用,2011,47(17):42-44.ZHAO Zhigang,CHENG Chang.Adaptive particle swarm optimization with mutation operator[J].Computer engineering and applications,2011,47(17):42-44.
Study of Speech Emotion Recognition Based on Improved Elman Neural Network
WANG Ying
(College of Computer and Information Technology,Northeast Petrolem University,Daqing 163000)
Speech emotion features can be divided into the global statistical feature and instantaneous characteristics on the time granularity.According to the dynamic characteristics of speech emotion,this paper presents a realization of speech emotion recognition improved Elman neural network model.The improved Elman network receive global feature signal and the time sequence signal as input,and modify the network structure automatically according to the input signal characteristics.This new Elman network fuses the global feature of signal and the time sequence signal successfully,and enhances the discrimination of the whole system.
speech emotion features,improved Elman neural network,global feature signal,time sequence signal
TP389.1
10.3969/j.issn.1672-9722.2017.11.011
Class Number TP389.1
2017年5月6日,
2017年6月24日
王穎,女,碩士研究生,講師,研究方向:人工智能、情感計算。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中國生殖健康(2020年5期)2021-01-18 02:59:48
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2018年5期)2018-11-06 07:15:40
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
