利用集成分類器進行稀有類分類
2017-12-13 11:50:46范夢瑤
科技與創新 2017年24期
范夢瑤
(上海市地震局應急救援保障中心,上海 200062)
利用集成分類器進行稀有類分類
范夢瑤
(上海市地震局應急救援保障中心,上海 200062)
現實生活中存在很多稀有類的例子,也就是我們所說的非平衡類數據,即數據中的一類樣本在數量上遠多于另一類。占少數類的數據往往具有顯著意義,例如癌癥檢測,它可以有效識別癌癥患者,對醫生做出正確的診斷有實際意義。常用的分類方法一般會產生偏向多數類的結果,因而對于少數類數據來說,預測的性能會很差。在分析了非平衡類數據分類問題的基礎上,簡要研究了利用集成分類器進行稀有類分類的相關內容,以期為日后相關工作的順利進行提供參考。
集成分類器;數據庫;非平衡類數據;召回率
1 背景闡述
數據庫中蘊藏大量信息,對數據的有效分析可以幫助人們做出明智的決定。數據挖掘的分類方法被應用于多個領域,典型應用有識別信用卡交易欺詐、預測視頻設備故障以及對視頻傳輸信號的分類、從衛星圖像檢測油井噴發和電信領域客戶的流失預測等。統計學、機器學習、神經網絡、破壞矩陣等領域的研究者提出了很多分類方法。在現實世界的數據分類中,通常情況下,數據集中標號不同的兩類樣本的數量是不等的,甚至有著極大的差別,即數據集中的兩類是高度傾斜的或者說是非平衡的。這個問題可以描述為從一個分布極不平衡的數據集中標識出那些具有顯著意義卻很少發生的實例。例如,在網絡入侵中,一個計算機通過猜測一個密碼或打開一個ftp數據連接進行遠程攻擊。雖然這種網絡行為是不常見的,但識別并分析出這種行為對網絡安全的影響是很有必要的。從實例中不難看出,稀有類實例數目很少,較難提供完備的信息,常用的分類方法在分類稀有類時往往失效,這就使得分類稀有類問題變得更具有挑戰性。
本文既研究基于處理訓練數據集的集成學習算法,也研究基于處理輸入特征的集成學習算法。基于處理訓練數據集是采用取樣技術選取不同的訓練數據,然后利用這些訓練數據生成集成中的個體。這樣做的目的是通過選取不同的數據集來獲得個體間的差異。提升(AdaBoost)和裝袋(Bagging)是基于處理數據的典型方法。
基于處理特征是通過輸入特征的子集來形成每個訓練集,子集隨機選擇或由領域專家建議。隨機森林(Random Forest)和旋轉森林(Rotation Forest)是處理輸入特征的組合方法,它們都使用決策樹作為基分類器。本文在分析非平衡類數據分類問題的基礎上,利用上述4種集成分類算法進行稀有類分類,得出實驗結論并進行比較。
2 稀有類分類
通常情況下,數據分類的應用會遇到數據不平衡的問題,即數據中的一類樣本在數量上遠多于另一類,例如病患分類和欺詐檢測問題等。其中,少數樣本具有巨大的影響力和價值,這是我們主要關心的對象,稱為正類,另一類則稱為負類。正類樣本與負類樣本可能數量上相差極大,這就為訓練非平衡類數據帶來了挑戰。常用的分類方法一般會產生偏向多數類的結果,因而對于正類來說,預測的性能會很差。
2.1 影響稀有類分類的特征
通常數據集中標號不同的兩類樣本的數量是不等的,甚至有極大的差別。與不平衡類問題相關的例子很多,通過衛星圖像檢測油井噴發的數據集就是非平衡數據的一個好例子。數據顯示,937張衛星圖像中只有41張包含浮油,我們可以說包含浮油的圖像是少數類樣本。然而,有時候少數類樣本才是我們首要關心的。由于數量上的嚴重傾斜,使用分類算法對非平衡的數據集進行分類時,其性能往往不盡如人意。不平衡類問題分類是數據挖掘中的難點問題,主要表現在以下5個方面。
2.1.1 不當的評估度量
評估度量在數據挖掘中至關重要,如果評估度量不能充分評估少數類樣本,則分類算法就可能對少數類樣本處理不當。其中,分類的準確率是指被正確分類的樣本占數據集樣本總數的比例,是分類任務中最常用的評估度量,它在度量少數類時的缺點是顯而易見的。
2.1.2 缺少數據
缺少數據,是指既存在絕對缺少,又存在相對缺少。非平衡數據挖掘的根本問題是,正類數據數量比較少,以至于在少數類內部難以發現規律。有時候,樣本在絕對數量上并不少,但是,相對于其他類的樣本來說所占的比例很小。
2.1.3 數據分裂
許多數據挖掘算法采用將最初的問題分解得越來越小的方法,這樣做出現的結果就是樣本空間被分解為越來越小的部分。數據規律只能在每個單獨的數據塊中找到,這些數據塊卻只包含了較少的數據,一些跨越數據塊的規律可能因此丟失,這就是數據分裂問題。這個問題在對少數類樣本進行分類時尤為突出。
2.1.4 不當的歸納偏移
將特定樣本一般化或歸納分類器,都需要一種額外的偏移。數據挖掘系統的偏移對其性能來說是至關重要的。據了解,許多訓練系統就是利用偏移來實現分類器的通用化,避免過度擬合的。但是,這種偏移可能會使數據挖掘系統訓練少數類樣本的能力大打折扣,產生不好的影響。
2.1.5 噪聲
少數類樣本數量比較少,少量的噪聲就可以影響被訓練的子概念,這樣訓練系統就不能區分特殊樣本和噪聲。如果訓練系統減小其通用性,就會得到不希望得到的結果,即將噪聲數據也包含進來。因此,噪聲數據的存在使防止過度擬合技術成為必需技術之一,但是,這樣就導致一些“真”的少數類樣本沒有被訓練。由此可以看出,噪聲數據對少數類樣本的影響大于普通類。
2.2 可選度量
可選度量,即稀有類分類的評估標準。常用的分類算法的評估標準包括預測的準確率、可規模性和可解釋性等。對于普通類來說,我們通常使用分類器的總準確率來評價分類效果。但是,在稀有類分類問題中,我們更關注稀少目標類的正確分類率。然而對于稀有類分類問題來說,由于關注的焦點不同,僅用準確率是不合適的。所以,在評價稀有類分類時,還應該采用其他的評價標準。通常情況下,我們使用召回率(Recall)即TPrate、精確率(Precision)即PPvalue和F-度量(F-measure)來評估稀有類分類。
召回率公式為:

精確率公式為:
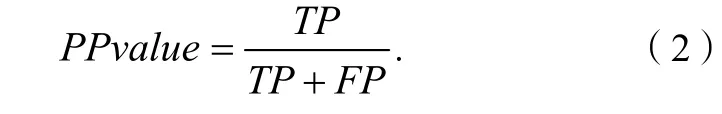
F-度量(F-measure)可定義為:
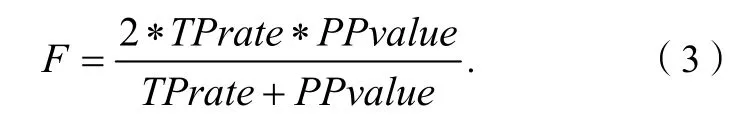
式(1)(2)(3)中:TP為真正類個數;FP為假正類個數;FN為假負類個數。
總的來說,召回率(Recall)和精確率(Precision)是信息檢索和數據挖掘中常用的評價指標,許多系統同時考慮這兩者,它們在分類器評測方面所作的貢獻是很重要的。
2.3 稀有類分類的研究意義
在實際應用中,稀有類分類問題是非常常見的。有些問題的原始數據分布就存在不平衡的情況,比如通過衛星雷達圖片檢測海面石油油污,檢測信用卡非法交易,醫學數據檢測,發掘基因序列中編碼信息和地震應急基礎數據分類等。這些問題都以稀有類的信息為關注焦點,例如,在信用卡非法交易記錄的檢測過程中,非法交易記錄是檢測的目標。但是,訓練數據中包含大量正常的信用卡交易記錄,只有很少一部分是非法交易記錄,使用一般的模式分類方法,非法交易記錄的檢測率很低。再比如,地震應急基礎數據是開展應急工作的基礎,是地震應急指揮技術系統的重要內容。基礎數據包括歷史地震災害、強震目錄、物資儲備、道路交通等,它們屬于非平衡類數據,其準確性直接影響震時分析和救災指揮的順利進行。因此,平時做好收集分類工作是十分重要的。以上種種情況都需要采用能夠適應稀有類分類問題的分類器進行分類,而常用的分類器往往不能勝任這項工作。所以說,稀有類分類問題與每個人的生活息息相關,做好這項研究有利于社會的平衡與和諧發展。
3 比較實驗
文中使用的實驗模擬工具為weka實驗平臺。
為了比較4個學習算法的性能,筆者選用weka平臺中的3個不平衡數據集進行測試。這3個數據集分別為視頻信號故障數據集(video_signal_failure)、強震數據集(strong_earthquake)和網絡侵入數據集(network_intrusion)。這些數據集的特征如表1所示。
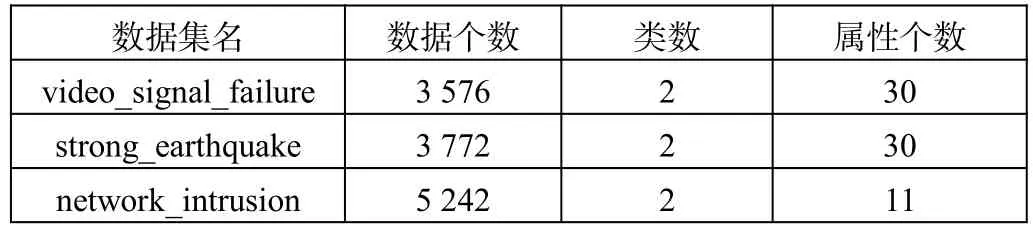
表1 數據集的特征
3.1 實驗過程及數據
為了驗證基于數據技術和基于特征集的集成學習算法的性能,對這3個數據集(video_signal_failure,strong_earthquake和network_intrusion)使用集成學習算法(AdaBoost、 Bagging、 Rotation Forest、Random Forest)進行分類實驗研究,同時,選擇決策樹(Random Tree)作為基分類器。簡單地說,實驗過程就是比較使用集成分類器與僅使用Random Tree做分類器在分類結果上的差異。其中,稀有類都用“*”標明。具體實驗步驟如下:①在weka軟件的classifier中選擇分類器Random Tree進行試驗。實驗數據如表2所示。②在classifier中依次選擇AdaBoost、Bagging、Rotation Forest、Random Forest做分類器,同時,選擇 Random Tree作為基分類器進行實驗。實驗數據如表3所示。③修改實驗數據集為strong_earthquake,再從classifier中選擇Random Tree作為分類器開始實驗。實驗數據如表4所示。④依次更改 classifier為 AdaBoost、Bagging、Rotation Forest、Random Forest,同時,在每個分類器中選擇Random Tree作為基分類器開始實驗。實驗結果如表5所示。⑤返回第③步,選擇數據集network_intrusion,選擇分類器Random Tree開始實驗。實驗結果如表6所示。⑥具體步驟同實驗步驟④一樣,實驗數據如表7所示。至此,實驗結束。
3.2 實驗結果及分析
對3個數據集使用集成分類器(AdaBoost、Bagging、Rotation Forest、Random Forest)進行分類(算法中的其他參數設置采用了weka系統中的默認值),分類前均選擇Random Tree作為基分類器。實驗結果分別記錄每個類的3組度量數據,即召回率(Recall)、精確率(Precision)和F-度量。
觀察實驗中的分類結果可以看出,4種集成學習算法的分類性能都要優于使用Random Tree單獨分類,也就是說,使用集成分類器分類稀有類的效果遠遠好于不使用集成分類器進行稀有類分類。同時,相比之下,基于處理輸入特征得出的度量數據要高于基于處理數據得出的。另外,在使用Random Tree做基分類器的時候,Bagging、Rotation Forest和Random Forest的精確率(Precision)比AdaBoost好,說明分類更準確。

表2 數據集video_signal_failure(Random Tree)

表3 數據集video_signal_failure

表4 數據集strong_earthquake(Random Tree)

表5 數據集strong_earthquake

表6 數據集network_intrusion(Random Tree)

表7 數據集network_intrusion
4 結束語
集成學習是機器學習的研究熱點之一,它既要研究基于數據技術的集成學習方法,又要研究基于處理輸入特征的學習方法。研究表明,對那些含有大量冗余特征的數據集,集成學習算法的分類效果更好。本文通過對比3種度量數據,針對3個不平衡的標準數據集分析研究了基于數據和基于特征的集成學習算法。同時,為了統一起點,設置Random Tree作為基分類器。
結果表明,集成分類器分類稀有類的效果遠遠好于不使用集成分類器進行稀有類分類,而且Bagging、Rotation Forest和Random Forest這3個分類器的分類精確率更高。
[1]Han J,Kanber M.數據挖掘:概念與技術[M].范明,孟小峰,譯.北京:機械工業出版社,2001.
[2]Yanmin,Mobamed S.Kamel,Andrew K.C.Wong,et al.Cost-sensitive boosting for classification of imbalanced data[J].Patter Recognition,2007(10):3358-3378.
[3]Agarwal R,Joshi M V.Pnrule:A new Framework for Learning Classifier Models in Data Mining(A Case-Study in Network Intrusion Detection)[C]//In Proc.of the First SIAM Conference on Data Mining,2001.
[4]Ian H,Frank W E.Data Mining:Practical Machine Learning Tools and Techniques[M].2nd ed.San Francisco:Morgan Kaufmann,2005.
[5]張勇,陳婧,范夢瑤.跨網段視頻會議互聯互通的設計與實現[J].科技與創新,2017(17):30-31.
[6]Fan H,Ramamohanarao K.A Bayesian Approach to use Emerging Patterns for Classification[C]//In Proc of 14th Australasian Database Conference.Adelaide:Australian Computer Society,Inc,2003:39-48.
[7]Liu Chenglin.Classifier Combination Based on Confidence Transformation[J].Pattern Recognition,2005, 38(1):11-28.
[8]Aksela M,Laaksonen J.Using Diversity of Errors for Selecting Members of a Committee Classifier[J].Pattern Recognition,2006,39(4):608-623.
[9]劉艷霞,職為梅,楊亮.稀有類分類問題研究[J].微型機與應用,2005,24(6):54-56.
范夢瑤(1988—),女,主要從事地震應急方面的工作。
〔編輯:白潔〕
TP301.6
A
10.15913/j.cnki.kjycx.2017.24.046
2095-6835(2017)24-0046-04
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
