一種基于用戶交易行為的隱語義模型推薦算法*
2017-11-20 01:50:51梁婧文蔣朝惠
網絡安全與數據管理 2017年21期
梁婧文,蔣朝惠
(貴州大學 計算機科學與技術學院,貴州 貴陽 550025)
一種基于用戶交易行為的隱語義模型推薦算法*
梁婧文,蔣朝惠
(貴州大學 計算機科學與技術學院,貴州 貴陽550025)
通過分析目前推薦技術在電子商務系統中的應用優勢,并針對當前產品交易系統的無評分、產品量大和難以分類等現狀與問題,設計了一種基于用戶交易行為的隱語義模型推薦算法。該算法從用戶的隱式交易行為出發,采用隱語義模型推薦算法,構建用戶-產品興趣模型,并加入K均值算法劃分隱式特征聚類。實驗驗證表明,該算法在滿足用戶的個性化需求的同時,可提高電子商務系統的產品推薦效率。
推薦算法;用戶交易行為;隱語義模型;K均值算法
0 引言
電子商務網站是個性化推薦系統的一個重要應用領域,各種著名的電子商務網站,例如亞馬遜、淘寶、Netflix、京東等,都在各個方面使用到了個性化推薦,是個性化推薦技術最積極的應用者和推廣者。
在主流的電子商務系統中大都采用協同過濾(Collaborative Filtering,CF)推薦算法[1],該算法是基于用戶行為數據分析設計的,并且基于一種假設:用戶過去喜歡的在未來也同樣喜歡。最廣泛使用的協同過濾算法有:(1)基于鄰域(Neighborhood-based)的方法,包括基于用戶(User-based)和基于產品(Item-CF)的,通過分析與用戶之前喜好相似的產品或者推薦給用戶與他喜好相似的用戶所關注的產品來構成推薦模型;(2)隱語義模型(Latent Factor Model,LFM),使用某些隱含特征來關聯用戶興趣和產品,并據此構建推薦模型。
對于電子商務推薦系統來說,如何建立用戶的偏好模型是首要問題,但當前產品交易系統存在無評分、產品量大、難以分類等問題,同時對協同過濾算法中隱式反饋方面的研究也越來越廣泛。因此本文從用戶的隱式交易行為出發,設計了一種基于用戶交易行為的隱語義模型推薦算法(User Transaction Behavior for Latent Factor Model,UTB-LFM)。
1 相關工作
自Netflix Prize推薦系統大賽之后,研究者對隱式反饋信息和隱語義模型越來越關注,近幾年人們對LFM的應用與研究也越來越深入。2014年,YIN F L、CHAI J P[2]等人在數字電視節目的推薦中使用了隱式特征模型,通過對觀眾行為進行分析,確定觀眾興趣與觀看電視節目之間的關系,并據此為觀眾建議節目類型。CHEN C、ZHENG L[3]等人在LFM中加入偏置項,證明推薦的準確度較原始的LFM推薦模型有所提高。2015年,張玉連[4]等人提出了一種通過建立隱語義模型,分析用戶和論文的特征向量進行科技論文的推薦,獲得了較好的準確度。2016年,文獻[5]將用戶的某些屬性信息融合到LFM上,即使用戶歷史行為數據稀疏,也可根據用戶屬性來尋找鄰域用戶,解決了稀疏問題。
上述研究都涉及到用戶的隱式行為,隱式獲取用戶信息的方式主要包括:訪問用戶日志和挖掘、跟蹤用戶行為兩個方面。同時,隱語義模型以其基于用戶隱式行為設計的優勢,通過收集用戶隱式反饋信息來獲取用戶偏好的方式,已是目前信息提供服務領域關注的熱點之一,為推薦技術的發展奠定了理論基礎。因此,將隱語義模型推薦算法與電子商務系統結合,通過獲取用戶隱式的交易行為產生推薦,更加具有研究和應用前景。
2 基于用戶交易行為的隱語義模型
2.1隱語義模型
2006年,Koren提出了隱語義模型,簡稱LFM。從矩陣分解方法出發,假設用戶u對產品i的評分矩陣R可以分解為用戶特征矩陣P、產品特征矩陣Q,兩矩陣的乘積表示用戶-產品評分矩陣,如式(1)所示:
(1)
其中P∈Rf×m和Q∈Rf×n是兩個低維度矩陣。預測評分通過式(2)計算得到,其中puf=P(u,f),qif=Q(i,f):
(2)
為了求解該模型中各參數值,定義了損失函數如式(3)所示:
(3)
通過對上述損失函數求偏導數得到式(4)、式(5),利用隨機梯度下降法不斷迭代[4],即最小化損失函數求出P、Q中的參數,得遞推公式(6)和式(7):

(4)

(5)
puf=puf+α(qif-λpuf)
(6)
qif=qif+α(puf-λqif)
(7)
其中涉及的重要參數包括:α表示學習速率,λ表示正則化參數。迭代次數根據實際誤差情況進行調整。
由于實際的推薦系統有很多固定屬性與用戶、產品無關,而上述隱語義模型并沒有考慮這種影響,因此,又進一步得到另一種LFM模型的預測公式(8):
(8)
其中μ+bu+bi稱為偏置項,μ是訓練數據集中全部評分值的全局平均數,描述系統屬性對用戶的影響;bu是用戶偏置項,描述和產品無關的用戶習慣;bi是產品偏置項,描述與用戶無關的產品屬性。再根據隨機梯度下降法,得到式(9)~式(12)的遞推公式:
bu=bu+α(eui-λbu)
(9)
bi=bi+α(eui-λbi)
(10)
puk=puk+α(qik×eui-λpuk)
(11)
qik=qik+α(puk×eui-λqik)
(12)
2.2基于用戶交易行為的隱語義模型
構建用戶興趣模型的輸入數據總體分為用戶數據和產品數據,用戶數據又包括用戶自身的屬性數據、評分數據、行為模式數據等,用戶在產品交易時,有一些常見的情況,比如用戶不希望通過對產品評分來表達個人的喜好,或者該系統并沒有提供評分的功能,系統能夠獲得的僅僅是用戶的交易行為。此外,一個系統擁有的產品數量非常巨大,難以通過人為手段對產品進行分類,直接計算相似性效率較低,且推薦不夠準確。
針對上述問題,本文首先在交易數據中提取用戶有過購買行為的數據,“1”表示推測用戶喜歡該產品,“0”表示推測用戶不喜歡該產品或不知道該產品,使用二進制反饋數據,也可以說是表示為0-1數據[6],構建初始化的用戶-產品興趣度矩陣。
然后根據隱語義模型的思想,把用戶-產品興趣度矩陣分解為兩個低維度的矩陣P和Q,P是用戶-隱式特征矩陣,表示用戶對隱類的偏好程度,Q是隱式特征-產品矩陣,表示每個產品屬于隱類的概率,用P和Q兩個矩陣的乘積表示實際評分,這樣得到的預測評分會更接近實際評分。最后,利用式(3)、式(6)、式(7)得到P、Q特征矩陣。
采用上述方法構建基于用戶交易行為的隱語義模型,既解決人為分類產品導致的推薦不準確問題,又通過隱語義模型達到對用戶交易行為矩陣降維的目的。
3 算法設計
基于用戶交易行為的隱語義模型推薦算法(UTB-LFM)的流程如圖1所示。

圖1 UTB-LFM算法流程圖
UTB-LFM的具體流程如下:
(1)基于用戶交易記錄,有過購買行為的產品選為正樣本,設興趣度Rui=1,采集同等數量的負樣本,設興趣度為Rui=0,使用0、1初始化用戶-產品矩陣R;
(2)利用式(3)、式(6)、式(7)對矩陣R進行分解,得到針對隱類的用戶特征矩陣P和產品特征矩陣Q;
(3)對產品特征矩陣Q使用K均值聚類算法[7]進行聚類,得到K個小規模的產品特征矩陣;
(4)根據目標用戶的交易記錄,找到已購產品所屬類別,在相應類別中,根據產品的特征權值,計算產品之間的相似性,其中相似度計算使用余弦相似性度量方法,如式(13)所示[8]。產品i與產品j的相似度公式中的Ri,f和Rj,f分別表示產品i屬于f個隱式特征的權值和產品j屬于f個隱式特征的權值,選取的隱式特征個數用F表示。

(13)

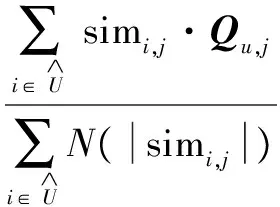
(14)
4 實驗數據及結果分析
4.1實驗環境及數據集
實驗使用MovieLens數據集,其中包括943個用戶和1 682個電影資源組成的100 KB的評分數據(1~5)。反復測試實驗誤差,選擇80%的實驗數據作為訓練數據,20%的實驗數據作為測試數據,表1是實驗運行環境。

表1 實驗環境表
4.2評價指標
推薦準確度是評價推薦算法最基本的指標之一,由于推薦系統的主要工作是根據用戶的偏好提供給他可能喜歡的產品,所以將準確度看作是用戶對推薦結果的認可程度。最常用的評價推薦準確度的方法是均方根誤差(Root Mean Square Error,RMSE)[9],準確度越高則該值越小。因此,本文使用RMSE來衡量推薦算法的準確度。此外,通過推薦運行時間對使用K均值聚類縮小查找范圍的效率進行評估。RMSE表達準確度如式(15),其中T為預測評分的總個數。

(15)
4.3結果分析
4.3.1推薦模型評估
采用RMSE比較本文設計的UTB-LFM、User-CF和Item-CF三種算法的預測準確性;并比較隱式特征F的不同值對推薦模型效果的影響。
(1)不同隱式特征個數F對應的RMSE
本文選擇α=0.006,λ=0.015進行實驗,在訓練集上迭代14次,并且學習速率按照每次迭代縮減0.9倍的速度遞減。實驗結果如圖2所示,其中User-CF算法選擇最優的鄰居數為80個。

圖2 不同F值在各推薦模型下測試的RMSE值
通過實驗發現,由于UTB-LFM中包括學習的過程,因此算法的RMSE較User-CF和Item-CF小,推薦的準確度高。同時隨著隱式特征個數F值的增加,UTB-LFM算法的準確度也隨之提高。而兩種基于鄰域的協同過濾推薦算法沒有引入隱式特征值,算法的準確度不會變化。
(2)不同學習速率和迭代次數對RMSE的影響
選擇隱式特征F值為200,通過改變學習速率和迭代次數,保證基本相近的RMSE值,實驗結果如表2所示。

表2 不同學習速率和迭代次數對RMSE值的影響
從表2得出,學習速率從0.005增加到0.01的過程中,保證準確度的前提下,迭代次數逐漸減少,構建模型時間變短。因此可以通過增加學習效率來減少算法迭代次數,提高效率。
4.3.2產生推薦時間評估
比較UTB-LFM、User-CF和Item-CF三種推薦算法的推薦運行時間,并驗證不同聚類數K值對UTB-LFM產生推薦運行時間的影響,實驗結果如圖3所示。

圖3 不同K值在各模型下的推薦運行時間
通過實驗比較發現,UTB-LFM算法的推薦時間比User-CF和Item-CF算法短,且隨著K值的增加推薦時間逐漸降低,提高了推薦效率。
5 結論
本文主要對隱語義模型推薦算法進行研究,并針對當前電子商務系統以及交易數據存在的問題,提出了一種基于用戶交易行為的隱語義模型推薦算法(UTB-LFM),該算法能夠在電子商務系統中通過獲取用戶的隱式交易行為,為用戶提供產品推薦。通過與基于用戶的協同過濾推薦算法和基于產品的協同過濾推薦算法的比較實驗,驗證了算法的準確性和推薦效率均有所提高。
[1] 馬小龍.基于協作過濾算法的電子商務個性化推薦系統的研究[J].微型機與應用,2014,33(15):13-15.
[2] YIN F L,CHAI J P,LI N,et al.Digital TV program recommendation system based on latent factor model[J].Applied Mechanics & Materials,2014(513-517):1692-1695.
[3] CHEN C,ZHENG L,THOMO A,et al.Comparing the staples in latent factor models for recommender systems[C].ACM Symposium on Applied Computing.ACM,2014: 91-96.
[4] 張玉連,袁偉.隱語義模型下的科技論文推薦[J].計算機應用與軟件,2015,32(2):37-40.
[5] 巫可.基于隱語義模型的個性化推薦算法的研究[D].廣州:廣東工業大學,2016.
[6] HAHSLER M.Recommenderlab: a framework for developing and testing recommendation algorithms[EB/OL].(2015-XX-XX)[2017-04-20].https://cran.r-project.org/web/packages/recommenderlab/vignettes/recommenderlab.pdf.
[7] 何佳知,謝穎華.基于密度的優化初始聚類中心K-means算法研究[J].微型機與應用,2015,34(19):17-19.
[8] 付芬,豆育升,韓鵬,等.基于隱式評分和相似度傳遞的學習資源推薦[J].計算機應用研究,2017,34(12):1-8.
[9] 程超,楊力,陳嘉鑫.融合語義關聯挖掘的文本情感分析算法研究[J].硅谷,2013,56(13):99-103.
Latent factor model recommendation algorithm based on user transaction behavior
Liang Jingwen,Jiang Chaohui
(College of Computer Science and Technology,Guizhou University,Guiyang 550025,China)
Through analysis of the application advantages of recommendation technology in e-commerce system,and in order to solve the present situation and problems of the product trading system without scoring,large volume of products and difficult classification,a latent factor model recommendation algorithm based on user transaction behavior was designed,which starts from the implicit user transaction behavior,and constructs the interest model between users and products,which uses latent factor model recommendation algorithm,and K-means algorithm is used to cluster implicit feature.The experimental results show that the algorithm meets the individual needs of users,and can improve the recommendation efficiency of e-commerce system.
recommendation algorithm; user transaction behavior; latent factor model; K-means algorithm
TP312
A
10.19358/j.issn.1674-7720.2017.21.005
梁婧文,蔣朝惠.一種基于用戶交易行為的隱語義模型推薦算法J.微型機與應用,2017,36(21):15-18,25.
貴州省基礎研究重大項目(黔科合JZ字[2014]2001-21)
2017-05-10)
梁婧文(1990-),女,碩士研究生,主要研究方向:數據庫與軟件工程。
蔣朝惠(1965-),通信作者,男,碩士,教授,主要研究方向:數據庫與軟件工程、網絡與信息安全。E-mail:jiangchaohui@126.com。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
創業家(2015年5期)2015-02-27 07:53:25
