GAPI:GPU加速的移動對象并行索引方法*
2017-11-16 06:23:28車慶首李傳文鄧慶緒
計算機與生活 2017年11期
車慶首,李傳文+,張 軼,鄧慶緒
1.東北大學(xué) 計算機科學(xué)與工程學(xué)院,沈陽 110004
2.東北大學(xué) 中荷生命與信息學(xué)院,沈陽 110004
GAPI:GPU加速的移動對象并行索引方法*
車慶首1,李傳文1+,張 軼2,鄧慶緒1
1.東北大學(xué) 計算機科學(xué)與工程學(xué)院,沈陽 110004
2.東北大學(xué) 中荷生命與信息學(xué)院,沈陽 110004
為減少加鎖操作對移動對象數(shù)據(jù)庫并行性能的影響并提高其吞吐量,提出一種由GPU加速的網(wǎng)格結(jié)合四叉樹的索引方法。采用由GPU對出入節(jié)點對象進(jìn)行計數(shù)并持續(xù)計算節(jié)點拆分/合并條件的方式,在不影響CPU計算能力的前提下,將存在性能瓶頸的網(wǎng)格節(jié)點轉(zhuǎn)化為四叉樹,從而減少對象數(shù)據(jù)更新時加鎖操作造成的其他線程等待時間。該方法結(jié)構(gòu)簡單且更適用于對象不均勻分布的場景,避免了現(xiàn)有索引方式或在熱點區(qū)域存在性能瓶頸,或需花費大量計算資源進(jìn)行結(jié)構(gòu)平衡等缺點。實驗結(jié)果表明,該方法與現(xiàn)有移動對象索引方式相比具有數(shù)據(jù)吞吐量大、響應(yīng)速度快等特點,在移動對象空間分布不均勻的場景下其優(yōu)勢更為明顯。
移動對象索引;動態(tài)網(wǎng)格索引;空間數(shù)據(jù)庫;GPU加速
1 引言
隨著移動計算、基于位置的服務(wù)、GIS等應(yīng)用的不斷發(fā)展,移動對象數(shù)據(jù)庫(moving object database,MOD)受到了國內(nèi)外研究人員越來越多的關(guān)注[1]。移動對象數(shù)據(jù)庫旨在對移動對象提供實時的數(shù)據(jù)更新和查詢服務(wù)支持,其主要目標(biāo)是在滿足一定時間精度和空間精度的前提下為用戶提供一定范圍內(nèi)移動對象的查詢結(jié)果。例如在打車應(yīng)用中,手機用戶和出租車都是移動對象,為用戶推薦一定距離內(nèi)的出租車就是一種典型的移動對象查詢操作[2]。
對于海量的移動對象數(shù)據(jù),傳統(tǒng)的單線程空間數(shù)據(jù)管理方式在效率上已難以滿足實際應(yīng)用需求。而類似Hadoop、Spark等大數(shù)據(jù)處理平臺雖然對于處理海量數(shù)據(jù)具有優(yōu)勢,但是由于這些平臺大都是分布式搭建,平臺節(jié)點之間相互通信所需的時間代價使其無法滿足空間移動數(shù)據(jù)管理的實時性要求。因此,目前移動對象管理一般采用單機多線程的方式實現(xiàn)。
由于對象位置變化頻率高,為提高IO效率,存儲移動對象的數(shù)據(jù)結(jié)構(gòu)往往采用內(nèi)存數(shù)據(jù)庫的方式[3]。因此,單機多線程移動對象管理的性能瓶頸不再是IO操作,而變成了多個線程之間相互協(xié)調(diào)造成的延時,其中最主要的是線程對數(shù)據(jù)結(jié)構(gòu)的加鎖操作對其他線程造成的影響。如何減少加鎖操作對其他線程的影響是移動對象管理的研究重點。
目前移動對象索引結(jié)構(gòu)有兩大類:基于網(wǎng)格的索引[4]和基于樹的索引[5]。基于網(wǎng)格的索引將空間劃分成一致大小的均勻網(wǎng)格,而基于樹的索引以其葉節(jié)點對空間進(jìn)行覆蓋。移動對象進(jìn)出網(wǎng)格或葉節(jié)點時需要對網(wǎng)格或葉節(jié)點加鎖,此時其他線程對此網(wǎng)格或葉節(jié)點的更新操作都需要等待。
基于網(wǎng)格的索引方式結(jié)構(gòu)簡單,易于實現(xiàn),但不適用于移動對象分布不均勻的應(yīng)用場景。移動對象負(fù)載不均問題普遍存在,如交通監(jiān)控應(yīng)用中,熱點地區(qū)相對于普通地區(qū),或者早晚高峰時相對于其他時段,移動對象在空間和時間上的負(fù)載就存在明顯不均。而基于樹的索引雖然能使每個葉節(jié)點包含的移動對象數(shù)大體一致,但實驗結(jié)果顯示其性能不如基于網(wǎng)格的索引方式好[6]。
由于只有對象進(jìn)出葉節(jié)點時需要對節(jié)點鎖定,樹狀索引中葉節(jié)點的劃分不應(yīng)以其中移動對象總數(shù)為標(biāo)準(zhǔn),而應(yīng)以單位時間內(nèi)出入葉節(jié)點的對象數(shù)目為劃分標(biāo)準(zhǔn)。然而對出入對象的計數(shù)涉及到頻繁鎖定計數(shù)器的原子操作,而且根據(jù)不斷變化的計數(shù)結(jié)果判斷是否需要對葉節(jié)點進(jìn)行拆分或合并相鄰葉節(jié)點都需要持續(xù)進(jìn)行大量計算,這些操作都會嚴(yán)重影響移動對象數(shù)據(jù)更新效率,因此現(xiàn)有的研究沒有采用出入對象計數(shù)對葉節(jié)點進(jìn)行劃分的索引方法[7]。
鑒于此,本文提出了一種采用GPU加速的移動對象并行索引方法(GPU accelerated parallel indexing method for spatial moving objects,GAPI),采用網(wǎng)格結(jié)合四叉樹結(jié)構(gòu),將葉節(jié)點出入對象的計數(shù)以及葉節(jié)點是否需要拆分或合并的判斷交由GPU處理。這種方式只占用極少量CPU計算資源,實現(xiàn)了在不影響數(shù)據(jù)更新和查詢效率的前提下使索引結(jié)構(gòu)不斷優(yōu)化的目的。實驗結(jié)果表明,該索引方法在移動對象更新方面的性能明顯優(yōu)于現(xiàn)有的最好方法。
2 GAPI索引結(jié)構(gòu)
2.1 問題定義
給定空間平面S,移動對象集O={o1,o2,…,on},其中任一對象,為oi的唯一標(biāo)識,為其位置,為最近一次更新時間。查詢操作集Q={q1,q2,…,qe},其中任一查詢請求qj={xmin,ymin,xmax,ymax,tq},前4項定義了一個矩形查詢框,tq為查詢開始的時間。移動對象數(shù)據(jù)庫的目的就是當(dāng)Q中查詢qj到達(dá)時,將位于查詢框中的移動對象返回給用戶。
這種查詢方式稱為范圍查詢(range query),由于其他種類的查詢?nèi)鏺NN(knearest neighbor)查詢等都可以被轉(zhuǎn)化為一系列的范圍查詢,本文只需討論索引結(jié)構(gòu)對此種查詢的支持。
2.2 索引結(jié)構(gòu)
移動對象數(shù)據(jù)庫的主要工作是不斷更新移動對象的位置及根據(jù)查詢需求返回結(jié)果。因此,移動對象索引結(jié)構(gòu)須高效地滿足兩項基本條件:
可采用基于哈希表的輔助索引方式實現(xiàn)對條件(1)的支持。
定義1(輔助索引,auxiliary index)輔助索引采用哈希表H根據(jù)值對所有空間對象進(jìn)行索引,H中保存形如的鍵-值對,其中p_bkt為oi在混合索引(參見定義2)中所處桶的內(nèi)存空間位置,idx代表其在桶中的相對位置。
圖1展示了一個輔助索引的示例。由哈希表的性質(zhì)可知,利用輔助索引可在常數(shù)時間內(nèi)根據(jù)找到內(nèi)存中oi的存儲位置。
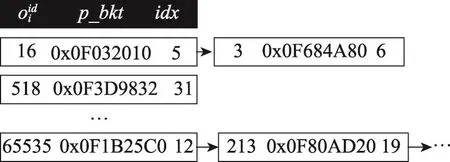
Fig.1 Example of auxiliary index圖1 輔助索引示例
基于網(wǎng)格的索引和基于樹的索引在滿足條件(2)方面各有優(yōu)缺點。
基于樹的索引方式減少了熱點地區(qū)對象擁塞的情況,然而每次由對oi的查找需要從樹根節(jié)點到一系列中間節(jié)點直至葉節(jié)點的多次查詢,降低了查詢效率。對整體效率影響更大的是,樹狀索引需要不斷調(diào)整結(jié)構(gòu)以適應(yīng)移動對象的分布,計算葉節(jié)點是否需要調(diào)整以及調(diào)整操作本身都會消耗大量計算資源。
本文提出一種網(wǎng)格結(jié)合四叉樹的混合索引方式,避免了上述兩種方式的缺點。
定義2(混合索引,hybrid index)混合索引P將空間平面S劃分為Gnum=2ρ×2ρ個網(wǎng)格,每個網(wǎng)格可以根據(jù)條件在網(wǎng)格節(jié)點與四叉樹兩種形式間轉(zhuǎn)換。
混合索引的目標(biāo)是通過將熱點區(qū)域的網(wǎng)格轉(zhuǎn)變?yōu)樗牟鏄鋄8]的方式達(dá)到平衡每個單元格負(fù)載的目的。ρ為網(wǎng)格劃分參數(shù),采用文獻(xiàn)[9]給出的選擇條件:

其中,N表示空間中移動對象的總數(shù)量;CL表示葉節(jié)點的容量。
執(zhí)行時,動態(tài)判斷每個網(wǎng)格中的移動對象出入數(shù)量,將滿足拆分要求的網(wǎng)格轉(zhuǎn)化為四叉樹,將滿足合并要求的四叉樹轉(zhuǎn)化回網(wǎng)格。在各四叉樹內(nèi)部也根據(jù)條件對其葉節(jié)點進(jìn)行拆分、合并操作。
圖2展示了一個混合索引的示例。圖中右半部分上層是一個被劃分為Gnum=2ρ×2ρ個網(wǎng)格的平面S,其中黑色的網(wǎng)格代表被轉(zhuǎn)換為四叉樹的熱點網(wǎng)格。下面幾層表示的是各級四叉樹節(jié)點對應(yīng)的空間區(qū)域,其中黑色節(jié)點代表更進(jìn)一步被細(xì)分的區(qū)域。圖中左半部分顯示的是其中一棵放大的四叉樹,其上方顯示了這棵四叉樹對其所在網(wǎng)格的劃分。可以看出,轉(zhuǎn)換為四叉樹后,區(qū)域得到了更精細(xì)的劃分。
每個網(wǎng)格節(jié)點ci只包含一個pbucket指針,指向一個桶鏈表Li,該鏈表包含一系列存放固定數(shù)目的屬于該節(jié)點的所有移動對象的桶。每個四叉樹節(jié)點ξi表示為ξi={pbucket,pc1,pc2,pc3,pc4},其中pc1、pc2、pc3、pc4分別為指向以當(dāng)前節(jié)點為父節(jié)點的4個象限中的子節(jié)點的指針。
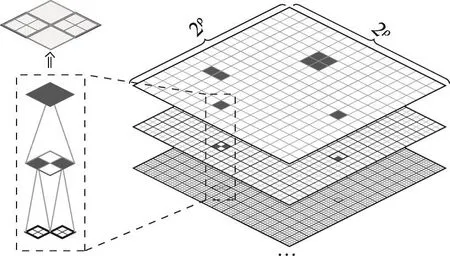
Fig.2 Example of hybrid index圖2 混合索引示例
2.3 節(jié)點拆合條件
由于對網(wǎng)格的拆合(拆分/合并)操作與對四叉樹葉節(jié)點的拆合操作本質(zhì)相同,在討論拆合條件時網(wǎng)格與葉節(jié)點將被統(tǒng)稱為節(jié)點。
當(dāng)對象在節(jié)點c內(nèi)部移動時,只需鎖定對象自身以對其位置進(jìn)行更新,不涉及鎖定節(jié)點的問題。而當(dāng)移動對象出入節(jié)點c時,則需在c對應(yīng)的某個桶中對此對象的信息進(jìn)行添加或刪除,此時必須鎖定c以避免不同線程同時對c進(jìn)行的更新操作可能造成的數(shù)據(jù)沖突。此時,所有其他線程對節(jié)點c的更新操作都需要暫停等待。單位時間內(nèi)移動對象出入c的數(shù)量nc越多,同時等待的線程就越多。更新操作所需的總時間φc為操作實際執(zhí)行時間ncτ(其中τ為每次更新操作的執(zhí)行時間)與等待時間ψc之和,因此更新操作總時間與節(jié)點單位時間內(nèi)移動對象出入數(shù)量存在正相關(guān)關(guān)系。
通過拆分節(jié)點可以減少節(jié)點內(nèi)同時等待的線程數(shù)量。然而,將一個節(jié)點c拆分為 4 個節(jié)點c1、c2、c3、c4后,原來屬于節(jié)點c內(nèi)的對象移動就有可能變成不同節(jié)點之間的移動,增加了出入節(jié)點移動對象的總數(shù)量,即

因此,為了減少φ需要對節(jié)點進(jìn)行適度的拆分,只有當(dāng)式(3)滿足時:

對節(jié)點進(jìn)行拆分才有利于提高更新性能。反之,當(dāng)已 拆 分 的 4 個 節(jié) 點c1、c2、c3、c4滿 足 條 件時,則需將其合并成一個節(jié)點。
本節(jié)將定量分析φ與n的關(guān)系。首先討論移動對象每增加一個更新操作對總等待時間的影響。
引理1設(shè)每個對象出入節(jié)點所需的更新操作執(zhí)行時間為τ,當(dāng)單位時間內(nèi)出入節(jié)點的移動對象數(shù)量為nc(nc>1)時,記此nc個移動對象出入信息更新所需的總等待時間的期望值為ψ(nc),則nc+1個移動對象更新的等待時間的期望值ψ(nc+1)可表示為:
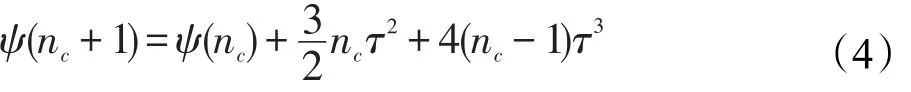
證明 假設(shè)節(jié)點c單位時間內(nèi)有nc個對象出入,那么第nc+1個對象進(jìn)出單元格需要等待nc個對象更新完成,記為:
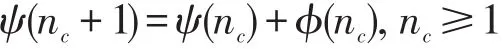
其中,?(nc)為等待時間與移動對象數(shù)量之間的關(guān)聯(lián)函數(shù)。nc個對象之間存在著更新等待時間重合與不重合的情況。所謂更新等待時間重合是指某個對象的更新開始時間點出現(xiàn)在另一個對象正在執(zhí)行更新操作的時間段內(nèi);更新等待時間不重合是指某個對象的更新開始時間點出現(xiàn)在另一個對象更新開始點往前推遲τ的時間點前,這樣保證了兩個對象更新不用相互等待。關(guān)聯(lián)函數(shù)?(nc)的意義就是對象更新之間重合與不重合的聯(lián)系。
當(dāng)nc個對象之間不重合時,記p1′為第n+1個對象落入對象執(zhí)行時間段內(nèi)的概率,p1″為落入某個對象更新時間點前τ的時間點前的概率。
p1′=nc,此時的等待時間是函數(shù)τ在[0,τ]上的積分,即:
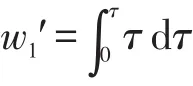
p1″=nc×τ,此時的等待時間是常量1在[0,τ]上的積分,即:
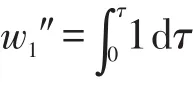
nc個對象之間不重合的等待時間w1可表為:
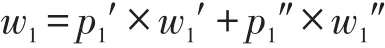
當(dāng)nc個對象之間存在重合,重合部分時間就需要往后順延,記重合部分的等待時間為w2,對象的執(zhí)行時間為τ,每個對象可重合的時間段往前推延τ,因此可重合的時間段ot=2τ。
兩個對象重合往后順延的時間記為w2′,w2′是關(guān)于可重合的時間段ot在[0,τ]上的積分:
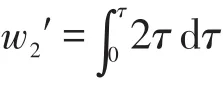
nc個對象之間只存在nc-1個重合時間段,nc個重合對象之間往后順延的時間為:
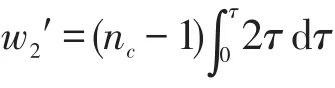
由兩個對象之間重合的概念可知,每個對象可重合的時間段記為ot=2τ,兩個對象之間的重合概率就為:

nc個對象之間重合的等待時間w2可表示為:
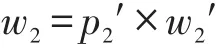
?(nc)=w1+w2,將上述式子帶入,可得:
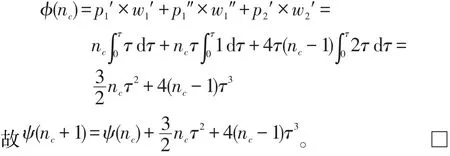
由引理1可推出等待時間ψ(n)的封閉形式。
引理2設(shè)節(jié)點單位時間出入的移動對象數(shù)量為n,每個對象的更新執(zhí)行時間為τ,則此n次更新操作的總等待時間ψ(n)為:
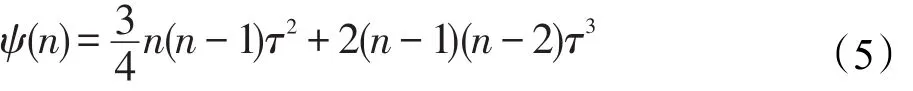
證明 由引理1可知,移動對象的更新等待時間與移動對象的數(shù)量與對象的更新時間點有關(guān),將式(4)遞歸展開:
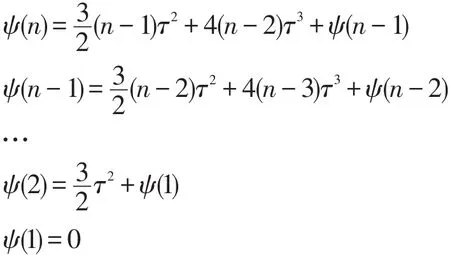
將ψ(1)ψ(2)…ψ(n)依次帶入,可得:
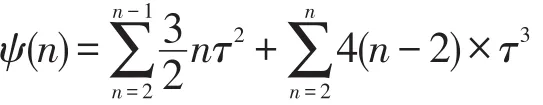
因此引理得證。 □
引理2描述了對象更新等待時間與對象更新數(shù)量的關(guān)系,而更新的總時間φ為更新等待時間ψ與實際執(zhí)行時間nτ之和。
定理1設(shè)節(jié)點單位時間內(nèi)移動對象出入數(shù)量為n,每個對象的更新執(zhí)行時間為τ,則節(jié)點在單位時間內(nèi)包括等待其他線程的總更新時間φ(n)可表示為:
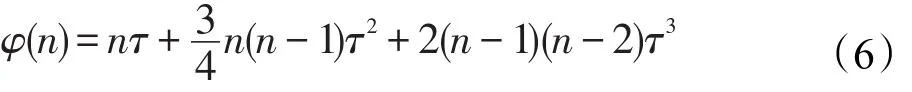
證明 將式(5)代入φ(n)=nτ+ψ(n)可證。 □
3 數(shù)據(jù)結(jié)構(gòu)與算法
本章采用類C++的偽代碼對GAPI索引結(jié)構(gòu)進(jìn)行描述。GAPI索引結(jié)構(gòu)分為輔助索引和混合索引兩部分,其中輔助索引H采用哈希表,即形式為unordered_map<int,pair<Bucket*,int>>的結(jié)構(gòu)保存鍵-值對。混合索引采用二維數(shù)組結(jié)合四叉樹(QuadTree)的形式。接下來重點討論混合索引數(shù)據(jù)結(jié)構(gòu)以及與其相關(guān)的算法。
混合索引數(shù)據(jù)結(jié)構(gòu)包括網(wǎng)格索引及QuadTree索引兩部分,其主要目的是根據(jù)定理1給出的條件平衡每個單元格的更新負(fù)載,將對象數(shù)量少的單元格合并,降低對四叉樹的查詢成本;將對象數(shù)量較大的單元格拆分,減少更新等待時間。
由2.3節(jié)可知,持續(xù)比較節(jié)點c的總執(zhí)行時間φc與其4個子節(jié)點的總執(zhí)行時間φc1+φc2+φc3+φc4的關(guān)系是決定一個節(jié)點拆分或者合并的關(guān)鍵。由于這些比較操作需消耗大量的計算資源,GAPI索引方法把這些操作放在GPU運行。對移動對象出入節(jié)點的計數(shù)工作雖不需太多計算,但每次增加計數(shù)值都需要鎖定計數(shù)器,對整體并行性能也會造成嚴(yán)重影響,因此計數(shù)操作也需要放在GPU運行。
本章將從CPU和GPU兩方面對GAPI索引算法進(jìn)行介紹。所有算法都基于統(tǒng)一的存儲于主存的數(shù)據(jù)結(jié)構(gòu),GPU運算所需的數(shù)據(jù)只在使用時由主存復(fù)制到顯存中,得到計算結(jié)果后再由顯存復(fù)制回主存。
3.1 數(shù)據(jù)結(jié)構(gòu)
混合索引中網(wǎng)格索引采用二維數(shù)組實現(xiàn):
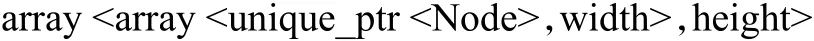
其中,width和height分別表示網(wǎng)格列數(shù)和行數(shù);Node類是Cell和QuadTree的父類。Cell代表一個網(wǎng)格,其中僅包含一個 unique_ptr<Bucket>類型的指針,而QuadTree代表一棵四叉樹:

Cell或QuadTree中的對象用桶鏈表結(jié)構(gòu)存儲。桶用來存儲葉節(jié)點上的移動對象,桶的大小固定,每個葉節(jié)點下的桶數(shù)量由移動對象的數(shù)量決定。插入對象時如果桶滿,則新建一個桶;刪除對象時如果桶變空,則刪除桶。桶結(jié)構(gòu)如下:

其中Site類保存移動對象數(shù)據(jù),包括id、x、y以及更新時間tu。由Site類包含的內(nèi)容可以推斷,其一個對象的數(shù)據(jù)至少需要占用128位(在32位機上4個int值)內(nèi)存空間,如果不采用保護措施,并行讀寫Site類時不同線程之間可能產(chǎn)生訪問沖突。傳統(tǒng)的避免訪問沖突的方法是在讀寫Site對象時對其加鎖。由于Site類是GAPI索引中使用最頻繁的類,為了避免加鎖對性能造成的影響,將Site類中的4個數(shù)據(jù)合并為一個_m128i類型的對象,采用Intel MMX指令集[10]中的_mm_load_si128和_mm_set_epi32操作對其中內(nèi)容進(jìn)行讀寫,并采用_mm_extract_epi32提取相應(yīng)的數(shù)據(jù)。采用這種方式,GAPI索引就能在不加鎖的前提下正確地并行讀寫Site數(shù)據(jù)。
GAPI索引中還維護兩個list<Node*>類型的列表split_candicates和merge_candidates,分別保存需要被GPU計算是否需要拆分或合并的節(jié)點。
3.2 CPU算法
隨著對象持續(xù)的更新,四叉樹的結(jié)構(gòu)也隨之變化。對象的插入算法根據(jù)坐標(biāo)將其插入到合適的節(jié)點上。刪除算法根據(jù)對象id找到所在桶,將其刪除。單元格的劃分與合并是平衡四叉樹的關(guān)鍵操作,只有滿足拆合條件的單元格才能進(jìn)行劃分與合并。
3.2.1 空間對象插入算法
算法1對象o插入葉節(jié)點add_to_leaf

對象移動過程中,隨著位置的變化,對象會不斷地在各個節(jié)點間移動,算法1的主要目的是將一個對象插入葉子節(jié)點。其思想是根據(jù)對象的位置查找該對象應(yīng)該被插入的葉節(jié)點,判斷該節(jié)點的桶狀態(tài)。如果桶未滿,直接插入桶,如果桶滿,則新建一個桶n_bucket,將新建的桶插入到當(dāng)前節(jié)點的桶列表。然后再把對象oi插入桶,并且桶存放的對象數(shù)量加1。
3.2.2 空間對象刪除算法
算法2從葉節(jié)點刪除對象oremove_from_leaf

當(dāng)移動對象位置更新時,不再屬于當(dāng)前葉節(jié)點范圍的對象需要被插入到其新的所屬葉節(jié)點中,并從當(dāng)前節(jié)點刪除。
3.2.3 單元格劃分算法
算法3單元格劃分split

根據(jù)2.3節(jié)中的節(jié)點拆/合條件可知,當(dāng)葉節(jié)點滿足φc>φc1
+φc2+φc3
+φc4
條件時,QuadTree索引結(jié)構(gòu)應(yīng)將葉節(jié)點s_node劃分為4個子網(wǎng)格,子網(wǎng)格的劃分按照上、下、左、右均分原則進(jìn)行,其中x_middle=(left+right)/2,y_middle=(floor+ceiling)/2,如第1~2行所示。劃分完成后,所有孩子的父節(jié)點均設(shè)置為當(dāng)前葉節(jié)點,將被劃分節(jié)點s_node中的所有對象移動到對應(yīng)孩子的桶里。如果被劃分節(jié)點的父親在該節(jié)點未劃分之前屬于split_candidates列表,則將其從拆分候選列表split_candidates里刪除,之后將當(dāng)前節(jié)點加入split_candidates列表。
3.2.4 單元格合并算法
算法4單元格合并merge

如算法4所示,當(dāng)節(jié)點滿足合并條件時,將該節(jié)點的所有孩子的桶鏈接起來并賦給當(dāng)前節(jié)點的桶。調(diào)整當(dāng)前節(jié)點的桶鏈,刪除空桶。如果當(dāng)前節(jié)點屬于merge_candidates列表,則將當(dāng)前節(jié)點m_node從merge_candidates里刪除。合并后,如果當(dāng)前節(jié)點的父節(jié)點屬于merge_candidates列表,則將當(dāng)前節(jié)點的父節(jié)點m_node.parent加入merge_candidates列表。
3.3 GPU算法
GPU由于邏輯運算能力較CPU弱,不適用于進(jìn)行較多的邏輯判斷,而較適用于大量的數(shù)據(jù)運算。與CPU不同,GPU采用的是單指令多數(shù)據(jù)(single instruction multiply data,SIMD)的工作方式,可以在多組數(shù)據(jù)上同時執(zhí)行同樣的一條指令,從而達(dá)到提高并行執(zhí)行效率的目的[11]。因此,GAPI索引中交給GPU的工作主要由涉及到大數(shù)據(jù)量計算的兩部分構(gòu)成:(1)對出入節(jié)點的移動對象進(jìn)行計數(shù);(2)判斷節(jié)點是否需要拆分或合并。
這兩部分操作都涉及到GAPI索引中維護的兩個list<Node*>類型的列表split_candidates和merge_candidates。
3.3.1 計數(shù)算法
本小節(jié)以單位時間內(nèi)對對象移入節(jié)點進(jìn)行計數(shù)的操作對計數(shù)算法進(jìn)行說明。若該操作運行于CPU,則通常會根據(jù)CPU并行[12]能力開啟若干線程,分別執(zhí)行如下流程。
算法5基于CPU的計數(shù)算法CPU_count

其中update_info_list中存儲了系統(tǒng)接收到的一系列對象移動數(shù)據(jù),包括對象id,原位置及新位置等信息,每個CPU線程處理update_info_list中的一部分。在由get_location計算出對象移入的節(jié)點后,第3行對移入的節(jié)點計數(shù)器進(jìn)行遞增。注意,為了保證對計數(shù)器并行讀寫的正確性,在遞增時必須對計數(shù)器進(jìn)行鎖定。
與CPU不同,由于GPU[13]普遍具有上千個流處理器,可以使每個流處理器[14]維護固定數(shù)目的若干節(jié)點的計數(shù)器。由于每個計數(shù)器只可能由固定的某一個流處理器訪問,計數(shù)器遞增時不需要加鎖。算法6演示了每個流處理器負(fù)責(zé)m×n個節(jié)點的操作流程。
算法6基于GPU的計數(shù)算法GPU_count

其中threadIdx是內(nèi)置的由系統(tǒng)自動設(shè)置的流處理器index值,count數(shù)組是流處理器的本地數(shù)組,保存了由其負(fù)責(zé)的節(jié)點計數(shù)器。第3行判斷節(jié)點是否屬于該流處理器負(fù)責(zé)的節(jié)點,如果屬于該流處理器則遞增對應(yīng)的計數(shù)器(第4行)。
GAPI索引系統(tǒng)不但對列表split_candidates和列表merge_candidates中的所有節(jié)點都要調(diào)用GPU_count對出入節(jié)點的對象數(shù)進(jìn)行記錄,還會對列表split_candidates中每個節(jié)點可能劃分的4個子節(jié)點以及merge_candidates中4個相鄰節(jié)點可能合并的父節(jié)點也調(diào)用GPU_count進(jìn)行計數(shù)。
3.3.2 拆合判斷算法
以拆分判斷算法為例,由于GAPI索引系統(tǒng)已經(jīng)對split_candidates列表中的任一節(jié)點c以及其可能拆分成的 4 個子節(jié)點c1、c2、c3、c4都進(jìn)行了計數(shù),只需將split_candidates列表中節(jié)點分配到各個流處理器上,然后將式(6)代入式(3)進(jìn)行判斷即可。
4 仿真實驗與結(jié)果分析
本章將GAPI索引結(jié)構(gòu)與目前最先進(jìn)的PGrid[4]索引結(jié)構(gòu)進(jìn)行對比。
實驗仿真環(huán)境為Win10系統(tǒng),Intel Xeon E5-2620 v3六核CPU×2,NVIDIA Quadro K2200 GPU。實驗代碼由C++及CUDA Toolkit 7.5實現(xiàn),空間對象數(shù)據(jù)由基于Brinkhoff[15]算法的開源移動對象生成工具M(jìn)OTO(http://moto.sourceforge.net)生成。實驗參數(shù)如表1所示。
圖3給出了更新/查詢比對吞吐量影響的實驗結(jié)果。隨著更新/查詢比的升高,兩種索引結(jié)構(gòu)的吞吐量都呈上升趨勢,其中GAPI的吞吐量在大部分情況下都要高于PGrid,而僅在更新/查詢比較小的情況低于PGrid。這是因為GAPI主要優(yōu)化的是更新操作,通過GPU輔助拆分、合并四叉樹的形式減少了并行更新時的線程等待時間,所以平均更新時間優(yōu)于PGrid。由于對四叉樹結(jié)構(gòu)的查詢需要由根節(jié)點到葉節(jié)點進(jìn)行多次查詢,GAPI索引的查詢時間一般會高于PGrid。
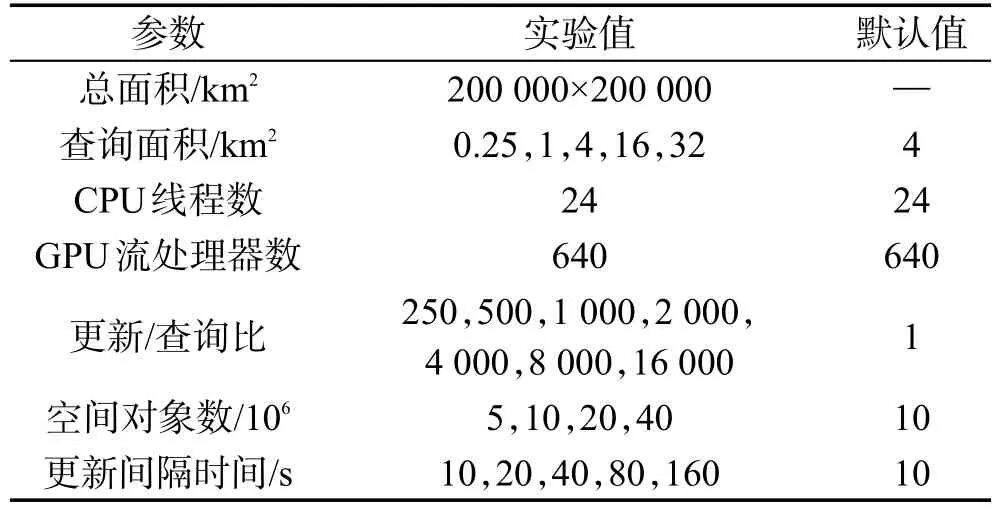
Table 1 Experiment parameters表1 實驗參數(shù)

Fig.3 Effect of throughput on update/query ratio圖3 更新/查詢比對吞吐量的影響
圖4給出了查詢區(qū)域面積對吞吐量影響的實驗結(jié)果。由圖可知,在所有情況下,GAPI都優(yōu)于PGrid。隨著查詢區(qū)域面積的增大,整體吞吐量不斷下降。這是因為查詢操作占用了越來越多的計算資源。
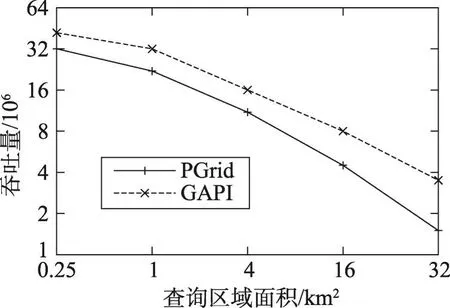
Fig.4 Effect of throughput on size of queried area圖4 查詢區(qū)域面積對吞吐量的影響
圖5給出了更新間隔時間對吞吐量影響的實驗結(jié)果。更新間隔時間越長,對象移動出當(dāng)前節(jié)點的概率就越大。在更新間隔時間逐漸加大導(dǎo)致PGrid吞吐量急劇下降時,由于GAPI能夠根據(jù)運行時的實際情況動態(tài)地調(diào)整節(jié)點,GAPI的吞吐量能夠保持穩(wěn)定。從圖5中還可以看出,在所有情況下GAPI的吞吐量都要優(yōu)于PGrid。
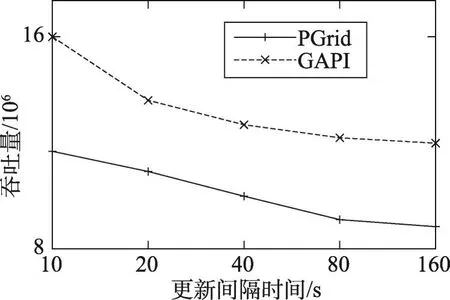
Fig.5 Effect of throughput on interval between updating圖5 更新時間間隔對吞吐量的影響
圖6給出了移動對象數(shù)對吞吐量影響的實驗結(jié)果。隨著移動對象數(shù)的增多,兩種索引的吞吐量都逐漸下降。這是因為移動對象數(shù)越多,同一節(jié)點中多個線程同時更新的概率就越大,需要進(jìn)行等待的線程就越多。然而隨著移動對象數(shù)的增多,GAPI的吞吐量下降速度明顯慢于PGrid。這是因為GAPI能夠根據(jù)實際運行情況動態(tài)地將節(jié)點拆分,從而降低了節(jié)點當(dāng)中對象的數(shù)量,減少了需要等待的線程數(shù)量,進(jìn)而提高了并行更新效率。
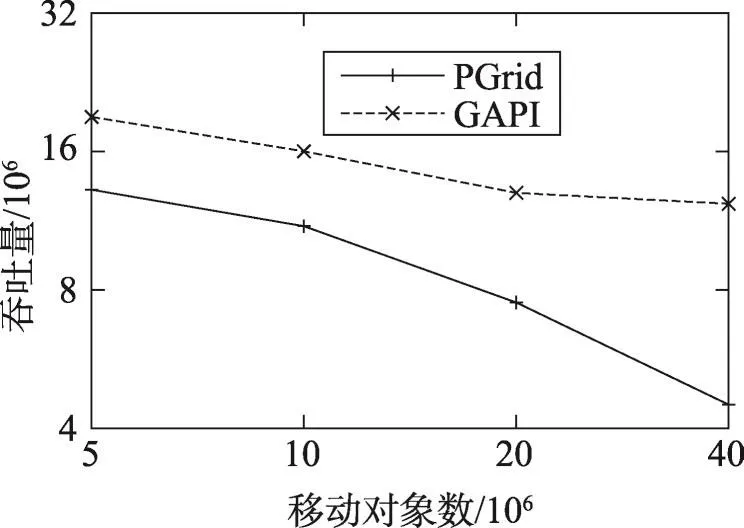
Fig.6 Effect of throughput on number of moving objects圖6 移動對象數(shù)量對吞吐量的影響
5 結(jié)束語
本文在網(wǎng)格索引的基礎(chǔ)上,提出了一種結(jié)合四叉樹并采用GPU加速的混合索引方式,避免了基于樹的索引和基于網(wǎng)格的索引的缺點。并通過實驗得出了以下結(jié)論:
(1)GAPI索引將平衡索引結(jié)構(gòu)的計算工作交由GPU處理,充分利用GPU能快速運算大量數(shù)據(jù)的優(yōu)勢,盡可能地減少了CPU的計算負(fù)載,從而大大提高了索引優(yōu)化效率。
(2)GAPI索引結(jié)構(gòu)以單位時間內(nèi)出入葉節(jié)點的對象數(shù)目為劃分標(biāo)準(zhǔn),與傳統(tǒng)的以葉節(jié)點存儲數(shù)量為劃分標(biāo)準(zhǔn)的動態(tài)索引結(jié)構(gòu)相比,GAPI索引結(jié)構(gòu)具有更好的平衡熱點區(qū)域更新負(fù)載的能力,在移動對象更新方面的性能明顯優(yōu)于現(xiàn)有方法。
[1]Huang Y K.Indexing and querying moving objects with uncertain speed and direction in spatiotemporal databases[J].Journal of Geographical Systems,2014,16(2):139-160.
[2]Nguyen T,He Zhen,Zhang Rui,et al.Boosting moving object indexing through velocity partitioning[J].Proceedings of the VLDB Endowment,2012,5(9):860-871.
[3]?idlauskas D,?altenis S,Jensen C S.Processing of extreme moving-object update and query workloads in main memory[J].The VLDB Journal,2014,23(5):817-841.
[4]?idlauskas D,?altenis S,Jensen C S.Parallel main-memory indexing for moving-object query and update workloads[C]//Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data,Scottsdale,USA,May 20-24,2012.New York:ACM,2012:37-48.
[5]Yiu M L,Tao Yufei,Mamoulis N.The B dual-tree:indexing moving objects by space filling curves in the dual space[J].The VLDB Journal,2008,17(3):379-400.
[6]?idlauskas D,?altenis S,Christiansen C W,et al.Trees or grids?:indexing moving objects in main memory[C]//Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems,Seattle,USA,Nov 4-6,2009.NewYork:ACM,2009:236-245.
[7]Nguyen-Dinh L V,Aref W G,Mokbel M.Spatio-temporal access methods:part 2(2003—2010)[J].IEEE Data Engineering Bulletin,2010,33(2):46-55.
[8]Tang Jine,Zhou Zhangbing,Ning Ke,et al.A novel spatial indexing mechanism leveraging dynamic quad-tree regional division[C]//LNEE 210:Proceeding of the 2012 International Conference on Information Technology and Software Engineering,Beijing,Dec 8-10,2012.Berlin,Heidelberg:Springer,2013:909-917.
[9]Chen Su,Ooi B C,Tan K L,et al.ST2B-tree:a self-tunable spatio-temporal B+-tree index for moving objects[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,Vancouver,Canada,Jun 10-12,2008.New York:ACM,2008:29-42.
[10]Peleg A,Wilkie S,Weiser U.Intel MMX for multimedia PCs[J].Communications of theACM,1997,40(1):24-38.
[11]Cook S.CUDA programming:a developer's guide to parallel computing with GPUs[M].San Francisco,USA:Morgan Kaufmann Publishers Inc,2012:354-388.
[12]Husted N,Myers S,Shelat A,et al.GPU and CPU parallelization of honest-but-curious secure two-party computation[C]//Proceedings of the 29th Annual Computer Security Applications Conference,New Orleans,USA,Dec 9-13,2013.New York:ACM,2013:169-178.
[13]Lettich F,Orlando S,Silvestri C.Processing streams of spatialk-NN queries and position updates on manycore CPUs[C]//Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems,Seattle,USA,Nov 3-6,2015.New York:ACM,2015:26.
[14]Tsakalozos K,Tsangaris M,Delis A.Using the graphics processor unit to realize data streaming operations[C]//Proceedings of the 6th Middleware Doctoral Symposium,Urbana Champaign,USA,Nov 30-Dec 4,2009.New York:ACM,2009:3.
[15]Sarma A D,Gollapudi S,Najork M,et al.A sketch-based distance oracle for Web-scale graphs[C]//Proceedings of the 3rd International Conference on Web Search and Web Data Mining,New York,Feb 4-6,2010.New York:ACM,2010:401-410.
2016-08,Accepted 2016-10.
GAPI:GPUAccelerated Parallel Method for Indexing Moving Objects*
CHE Qingshou1,LI Chuanwen1+,ZHANG Yi2,DENG Qingxu1
1.School of Computer Science and Engineering,Northeastern University,Shenyang 110004,China
2.Sino-Dutch Biomedical and Information Engineering School,Northeastern University,Shenyang 110004,China
+Corresponding author:E-mail:lichuanwen@mail.neu.edu.cn
In order to eliminate the parallel performance impact caused by locking operations and improve the throughput of moving object databases,this paper proposes a GPU accelerated indexing method,based on a grid data structure,combined with quad-trees.By using GPU to count object movements and keep deciding whether a particular node should be split or child nodes of a common father should be merged,bottle necked nodes can be translated to quad-tree without interfering CPU,hence waiting time of other threads caused by locking operations raised by object data updating can be reduced.The method is simple while more adaptive to scenarios where the distribution of moving objects is skewed.It also avoids the shortcomings of existing methods that have performance bottle neck on hot area,or spend plenty of calculation resources on structure balancing.The experimental results suggest that,compared with existing indexing methods,the proposed method shows higher throughput and lower response time.The advantage is more significant under skewed distribution of moving objects.
moving object indexing;dynamic grid indexing;spatial database;GPU accelerated
10.3778/j.issn.1673-9418.1608038
*The National Natural Science Foundation of China under Grant No.61300021(國家自然科學(xué)基金);the Fundamental Research Funds for the Central Universities of China under Grant Nos.N140404008,L1519003(中央高校基本科研業(yè)務(wù)費專項資金).
CNKI網(wǎng)絡(luò)優(yōu)先出版:2016-10-19,http://www.cnki.net/kcms/detail/11.5602.TP.20161019.1458.004.html
CHE Qingshou,LI Chuanwen,ZHANG Yi,et al.GAPI:GPU accelerated parallel method for indexing moving objects.Journal of Frontiers of Computer Science and Technology,2017,11(11):1713-1722.
A
TP391

CHE Qingshou was born in 1992.He is an M.S.candidate at School of Computer Science and Engineering,Northeastern University.His research interests include spatial databases,system software and real time system,etc.
車慶首(1992—),男,云南西疇人,東北大學(xué)計算機科學(xué)與工程學(xué)院碩士研究生,主要研究領(lǐng)域為空間數(shù)據(jù)庫,系統(tǒng)軟件,實時系統(tǒng)等。

LI Chuanwen was born in 1982.He received the Ph.D.degree from Northeastern University in 2011.Now he is an associate professor at Northeastern University,and the member of CCF.His research interests include spatial data manage,location based service and complex event processing,etc.
李傳文(1982—),男,山東煙臺人,2011年于東北大學(xué)計算機軟件與理論專業(yè)獲得博士學(xué)位,現(xiàn)為東北大學(xué)副教授,CCF會員,主要研究領(lǐng)域為空間數(shù)據(jù)管理,位置服務(wù),復(fù)雜事件處理等。在VLDB、ICDE等國際會議發(fā)表多篇論文。

ZHANG Yi was born in 1982.He received the Ph.D.degree from Northeastern University in 2014.Now he is a lecturer at Northeastern University.His research interests include multi-core embedded operating system and highperformance software design,etc.
張軼(1982—),男,遼寧沈陽人,2014年于東北大學(xué)計算機軟件與理論專業(yè)獲得博士學(xué)位,現(xiàn)為東北大學(xué)講師,主要研究領(lǐng)域為多核嵌入式操作系統(tǒng),高性能軟件設(shè)計等。

DENG Qingxu was born in 1970.He is a professor and Ph.D.supervisor at Northeastern University,and the senior member of CCF.His research interests include multiprocessor real-time scheduling and reconfigurable computing,etc.
鄧慶緒(1970—),男,河南南陽人,博士,東北大學(xué)教授、博士生導(dǎo)師,CCF高級會員,主要研究領(lǐng)域為多處理器實時調(diào)度,可重構(gòu)計算等。承擔(dān)和完成3項信息領(lǐng)域國家863課題。
