基于并行隊列的眾核平臺入侵檢測系統
2017-11-08 10:21:53陸遙余翔湛
智能計算機與應用 2017年5期
陸遙+余翔湛
摘要: 本文通過分析和總結以Suricata為代表的現有的主流并行化入侵檢測系統的體系結構,并對Suricata的3種工作方式結合現有tilera系列硬件平臺的硬件特點進行了理論分析。提出了眾核入侵檢測系統的設計要點。并設計了一種基于非統一內存訪問與內存池的入侵檢測結構。該結構將傳統的流水線模式與并發模式相結合,在盡可能少地進行核間通訊的前提下,最大程度地提升了單核的內存使用效率和cache命中率。同時使用共享內存池進一步提高了讀寫密集情況下的內存使用效率,使用改進的無鎖通訊隊列保證了核間通訊的效率,使得該架構在眾核平臺具有很高的實用性,其主要模塊的設計思想也具有一定程度上的可移植性。本文最終設計并實現了一個高效的基于眾核平臺的入侵檢測系統。
關鍵詞:入侵檢測系統; 眾核; 流量識別; 并行計算
中圖分類號: TP393.08
文獻標志碼: A
文章編號: 2095-2163(2017)05-0082-05
Abstract: In view of the hardware characteristics of the existing tilera series hardware platform, the three kinds of working modes of Suricata are analyzed theoretically in this paper. The main points of the design of the system for the detection of the multicore intrusion are put forward.Based on the main point of the design, this paper proposes an intrusion detection architecture which has nonuniform memory access and large page memory pool. The structure combines the traditional pipelined mode with the concurrent mode, and improves the memory efficiency and cache hit rate of the single core to the greatest extent. At the same time, the use of shared memory pool further improves the memory efficiency of dense reading and writing, which makes the structure has very high practicability in the multicore platform, and the design of the main module also has a certain degree of portability. Consequently, this paper designs and implements an efficient intrusion detection system based on manycore platform.
Keywords: identification detection system; manycore; flow recognition; concurrent computation
0引言
據統計,互聯網流量已達到每12個月即會增長一倍,超過了摩爾定律的速度[1]。相比于在未來一定時間將持續快速增長的網絡帶寬,單一處理器的計算能力卻日趨瓶頸。相關人士認為未來芯片的迭代會變得更慢,其間隔可能會達到2.5~3年。目前英特爾最新一代處理器已采用14 nm工藝,正在逐步接近現有處理器架構的物理極限。若按現在的速度繼續發展,到21世紀20年代中期,晶體管的尺寸將僅有單個分子大小,晶體管也將變得非常不穩定,若沒有新的技術突破,摩爾定律將會徹底終結。同時,由于單純提升主頻而帶來的發熱等問題,基于單核、多核處理器的普通網絡報文捕獲平臺的計算性能已經成為大規模網絡防火墻、寬帶網絡入侵檢測系統以及高性能路由等網絡工程的性能瓶頸。對于現在乃至未來更大規模的高速網絡,如何突破普通報文捕獲平臺的性能瓶頸,研究和實現面向大規模寬帶網絡的高性能網絡數據捕獲技術,對并行處理、網絡安全、高性能路由器等諸多領域都有著非常重要的意義。
作為突破單核、多核性能瓶頸的手段之一,眾核處理器作為擁有強大并行處理能力的新一代處理器,成為有效解決以上問題的手段之一。目前的眾核處理器可集成數十至幾百個核,每個核是一個執行單元,對整個數據包或其中的一個子任務進行處理。現代高性能并行處理系統通常采用超標量流水線結構,數據包處理劃分成多個并行子任務集,每個子任務集是由眾核處理器中的若干個核并行執行,子任務集到核資源集的映射由運行時系統完成[2]。隨著技術發展和需求推動,未來處理器將集成幾百甚至上千個核,這類處理器系統一般稱為眾核處理器系統。眾核處理器核數的增加保證了計算和數據處理能力持續提高,然而如何使這種硬件能力轉變成應用性能的提升,是眾核時代面臨的嚴峻挑戰之一。
本文基于美國Tilera公司的TILE-Gx系列處理器進行眾核平臺數據包捕獲系統的設計。成立于2004年的Tilera是一家致力于開發通用型多核心處理器的新興無晶圓半導體業者。該公司的Tile處理器架構源自于Agarwal博士早從1990年代起在麻省理工學院(MIT)研發的多重處理器叢集技術。其TILE-Gx系列處理器是世界上第一款100核心以上的處理器,采用網格化多核架構,通過iMesh網絡實現眾多處理器核互聯,將單芯片處理能力提高了數十到數百倍,在外接2塊Intel萬兆網卡的情況下可以滿足在重要網絡出入口上進行高速捕包的硬件性能需求[3]。endprint
該平臺具有36個計算核心,64-bit VLIW超長指令字架構并支持64位指令集和40位物理尋址空間,每個通用目的處理核心都有自己的32 KB一級指令緩存、32 KB一級數據緩存、256 KB二級緩存切換開關,共享三級緩存,并集成了智能NIC硬件,用于網絡流量的預處理、負載均衡、緩沖管理。TILE-Gx系列采用臺積電40 nm工藝制造,37.5×37.5 mm BGA封裝,主頻為1.2 GHz,所有計算核心共享雙通道內存訪問控制,可提供3個PCI-E 2.0 x8、2個千兆和2個萬兆以太網端口、3個USB 2.0端口,典型功耗48 W,平均每個核心不到0.5 W[4]。配合萬兆網絡接口探討此類眾核硬件系統的高速捕包系統架構。
由此可以看出,該平臺具有典型眾核平臺所具有的特點,即單核計算能力相比傳統單核處理器較弱,相比于已經具有單核4.2 GHz,6 MB三級緩存的最新一代英特爾酷睿i7-7700處理器,單核頻率僅有1.2 GHz且只獨占256 KB二級緩存的Tilera-GX36處理器在性能上明顯較差。然而其具有的36核iMesh網絡在大規模并行計算上可以彌補其單核性能的不足。同時其平均每個核心不到0.5 W的功耗也在實用性上更勝一籌。
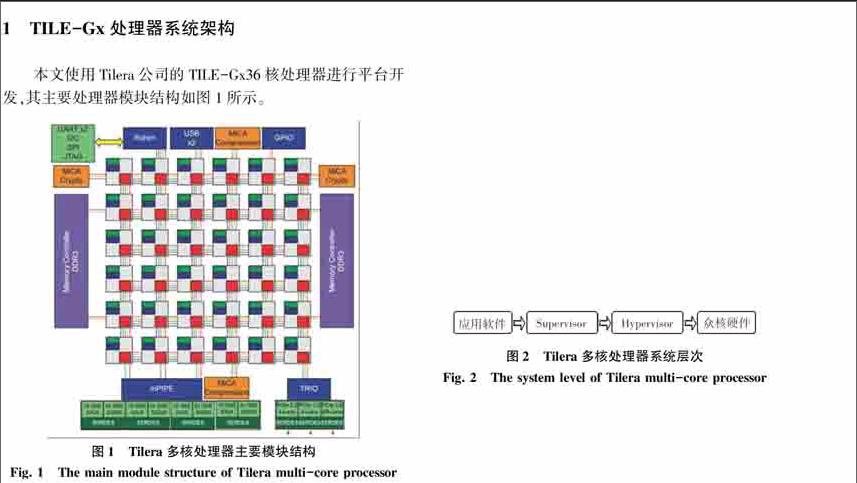
在系統方面,其系統結構如圖2所示,由Hypervisor層、Supervisor層和應用軟件層三層構成。在此,針對各層的功能概述可作闡釋解析如下。
首先,Hypervisor層是硬件驅動程序層,管理內核間、內核與IO控制器間的通信,提供—個底層的虛擬內存系統;每—個內核上都運行—個單獨的Hypervisor實例。
其次,Supervisor層是SMP Linux操作系統,通過Hypervisor管理硬件資源,為用戶應用程序和庫提供系統命令、IO設備、進程和虛擬內存分配等高級別服務;這一層允許多進程/多線程的應用來提升多核的性能。
最后,應用軟件層是軟件體系的最上層,該層程序代碼通過操作系統調度、管理硬件資源,實現各種具體應用功能[5]。同時,應用軟件層除了和x86架構一樣支持C實時庫、NetlO庫等標準庫之外,還支持Tilera多核組件庫等專用庫。因此在本質上,使用Tilera眾核處理器的服務器依然具備標準的硬件、底層驅動、操作系統、應用軟件的層級結構。
2基于眾核平臺的入侵檢測系統模型
2.1現有x86架構主流入侵檢測系統架構分析
人們將即時監視網絡中的流量傳輸,對可疑傳輸進行報警,并在特定情況下采取主動反制措施的網絡安全設備稱為入侵檢測系統(Intrusion Detection System,IDS)。由定義可以看出在設計上雖然主要行使檢測功能,但仍屬于主動安全防護技術的一種,這使得IDS區別于其他網絡安全設備。
按照IETF的定義,一個入侵檢測系統可以分為以下4個組件:
1)事件產生器(Event generators)。功能目的是從整個計算環境中獲得事件,并向系統的其他部分提供此事件。
2)事件分析器(Event analyzers)。可經過分析得到數據,并產生分析結果。
3)響應單元(Response units)。就是對分析結果作出反應的功能單元,可以作出切斷連接、改變文件屬性等強烈反應,也可以只是簡單的報警。
4)事件數據庫(Event databases)。 是存放各種中間和最終數據的地方的統稱,既可以是復雜的數據庫,也可以是簡單的文本文件[6]。
在目前的眾多的IDS中,由開放信息安全基金會開發的Suricata應用最為廣泛,對多線程與分布式計算支持較好,穩定性較高的系統之一。Suricata通過libpcap、netmap、af-packet等工具獲取報文,數據接收模塊為從網卡的接收隊列中接收數據包,并將封裝在Packet結構中,然后放入下一個緩沖區。解碼模塊對緩沖區中數據包進行解碼,主要是對數據包頭部信息進行分析并保存在Packet結構中,再交由流重組TCP模塊對數據包進行TCP流重組。重組完成的TCP流由協議插件模塊檢測是否包含入侵行為,再由Verdict模塊經過內核對數據包進行接收或丟棄的判斷處理。最后通過應答模塊調用libnet對要執行阻斷操作的數據包進行相應的阻斷處理。
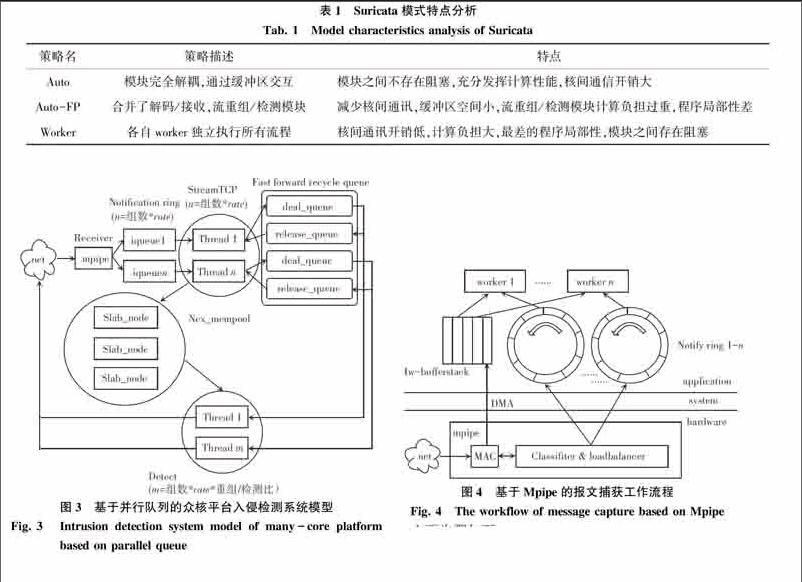
策略名策略描述特點
Auto模塊完全解耦,通過緩沖區交互模塊之間不存在阻塞,充分發揮計算性能,核間通信開銷大
Auto-FP合并了解碼/接收,流重組/檢測模塊減少核間通訊,緩沖區空間小,流重組/檢測模塊計算負擔過重,程序局部性差
Worker各自worker獨立執行所有流程核間通訊開銷低,計算負擔大,最差的程序局部性,模塊之間存在阻塞
[HT5”SS][ST5”BZ][WT5”BZ][FL(2K2]
2.2現有x86架構主流入侵檢測系統架構分析
為了平衡系統核間通訊與程序局部性的開銷,最大化發揮眾核平臺的性能,本系統提出一種基于并行隊列的處理模型。該模型采用將模塊分組并行的方式,組內采用流水線模式處理數據,組間獨立并行運行,系統流程圖如圖3所示。
該系統依然按照傳統入侵檢測系統的工作流程設計,劃分為3個主要模塊:數據接收模塊、流重組模塊與檢測模塊。架構采用了基于并行隊列的分布式數據流模型,其主要流程為數據接收模塊完成Tilera硬件api的調用,通過Mpipe進行數據包的解碼與負載均衡,將來自旁路監聽的網絡端口的數據包解析至ip層后直接拷貝至數據流保存在iqueue中并完成后續模塊的硬件綁定與任務派生和相關初始化工作。流重組模塊基于Rafal Wojtczuk的網絡入侵檢測接口Libnids完成tcp流重組與syn表的維護工作,再將數據包還原成數據流寫入內存池,并將各內存池所需的描述符結構與緩存數據按照各自對應的檢測模塊通過改進的無鎖循環消息隊列分發到相應的處理隊列中,進而回收釋放隊列中的內存池資源。最后由檢測模塊從內存池中獲取內容,并調用相應的插件完成解析與響應工作,將相應句柄放入釋放隊列中。endprint
總體上,該系統結構上與autoFP模式有一定的相似之處,其主要不同之處為數據接收模塊使用與硬件交互的Mpipe模塊完成對數據包的零拷貝緩存、解析、負載均衡分發操作,最終的結果通過iqueue環形隊列進行緩存,又直接使用單獨的內存池完成對共享內存的管理,并在傳輸層按照一定的比值對所對應的檢測模塊進行流分發,在模塊間通訊策略上采用了改進的無鎖循環隊列Fast forward recycle queue。而且由單純以CPU的倍數決定的并發模型改為按照計算核心的物理空間進行分組同時使用了核心綁定。
3基于眾核平臺的入侵檢測關鍵技術
3.1基于Mpipe的高性能數據捕獲平臺設計
為了解決傳統網絡數據包捕獲平臺中的性能瓶頸,需要結合新的硬件平臺對于數據捕獲流程進行優化,減少數據拷貝,數據同步的過程。對于數據包接收、完整性校驗、負載均衡等所有網絡應用均會用到的,原本由系統層面完成的工作,盡可能以新硬件的形式整合進網絡接口中。而對于用戶層空間,則保留對于不同應用程序的接口以對應不同的需求。
本文設計了基于Tilera公司的Mpipe (Multi-core programmable intelligent packet engine)網絡接口的高性能捕包平臺。數據的捕獲、數據校驗、負載均衡等操作均通過Mpipe高性能網絡接口完成,Mpipe是基于Tilera平臺的一套高性能網絡接口,理論上可實現40 Gbps線速數據流的分類轉發。通過該平臺可以實現在Tilera眾核服務器設備中從物理網絡接口到用戶空間的直接寫入,并使用專用硬件完成數據包的完整性校驗與負載均衡,極大簡化了數據捕獲的流程[7]。同時使用無鎖環形隊列實現了用戶層與硬件網絡接口的高效無鎖通訊,在通訊內容上采用基于描述符的消息傳遞機制,減少了數據拷貝的開銷。主要的數據捕獲流程如圖4所示。
主要步驟如下:
1)Mpipe對捕獲的數據包進行特征提取,并由專用硬件剝離完成以太包頭部、計算校驗和等操作。
2)發起DMA請求,由網卡通過DMA將接收到的數據包從網卡緩沖區寫入內核緩沖區。
3)使用生成的描述符按照一定的規則寫入對應用戶空間的Notify ring中。
4)worker通過notify ring獲取描述符,訪問緩沖區,完成上層操作。
3.2改進的無鎖隊列核間通信技術
一般情況下,為了保證數據不被多個線程同時讀寫會采用同步鎖以確保同步性,然而這會使得大量線程阻塞在臨界區,造成性能的急劇下降。Lamport算法已經證明,在順序一致性模型下,單生產者、單消費者隊列的鎖可以去掉,從而形成一個并發無鎖隊列[8]。因此并行程序的一致性問題最好通過算法的方式實現進程的順序一致性從而避免沖突。
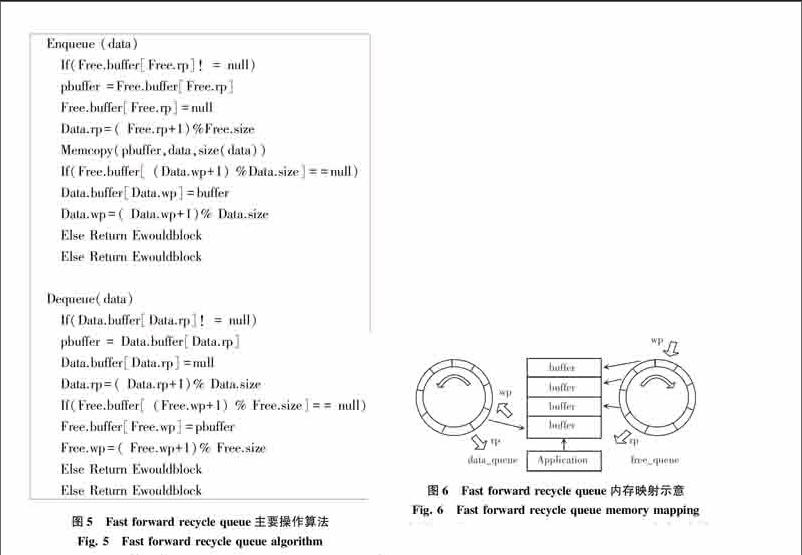
在固定尺寸的循環隊列中,由于不存在同步鎖帶來的延遲,系統核間通信的開銷將重新回到內存的讀寫與分配中。在經典的無鎖隊列Lamports queue和Fast forward queue中,由于指針指向空間的動態變化,每次環形隊列的讀寫都會伴隨一次空間的申請釋放操作。如果想要進一步減少核間通訊的開銷,必將從減少核間通訊時內存的申請與釋放操作入手。本系統基于經典的無鎖隊列算法,參照下文中內存池的內存塊回收思想提出了無鎖回收隊列算法(Fast forward recycle queue),算法主要操作如圖5所示。
[
無鎖回收隊列算法使用2個Fast forwards CLF Queue分別作為Data queue與Free queue,分別用來保存已使用空間和未使用空間。在隊列初始化時,將為Free queue的每一個元素預分配一部分空間。當有數據需要通過隊列傳輸時,將首先從Free隊列中申請需要的空間,并直接使用該部分的內存空間保存傳輸結果。當讀寫完畢進入傳輸環節后,將該空間指針pbuffer寫入data隊列,這樣接收端可以直接通過pbuffer訪問數據。當數據訪問完成后指針從Data queue中取出重新進入Free queue等待下一次申請。相比于Lamports queue,該方法所使用的Data.rp和Free.wp變量為接收端私有,Free.rp和data.wp變量為發送端私有,從而避免了因為共享變量產生的cache顛簸問題。相比于普通的Fast forwards CLF Queue,無鎖回收隊列算法主要的區別在于內存區塊的映射方式,具體的內存區塊映射方式如圖6所示。
由圖6可見,Fast forward recycle queue與標準的Fast forward不同之處主要區別在于其擁有2個隊列,隊列中僅保存buffer指針,而實際的buffer空間是由data_queue與free_queue共享的。當應用程序申請隊列空間時可以直接使用申請的buffer空間作為自身共享緩存,同時通信完成后該區域也并不釋放,只是將指針歸還到free_queue中,當下一次buffer被申請時數據將直接覆蓋寫入該內存塊。由于一般類型的數據結構大多都有內建的邊界控制或同時傳輸緩存區尺寸的描述符,因此無需考慮此處的數據污染問題。通過該方式可以實現僅在系統啟動時完成一次內存申請,之后便可直接讀寫重復利用空間。
4系統綜合性能評估
采用了基于并行隊列的系統整體性能評估方法測量系統整體吞吐量(Throughput)。其定義為:在沒有包丟失的情況下,設備能夠接受的最大速率,這是衡量入侵檢測系統性能的主要指標之一。
Tilera Gx36處理器擁有36個計算核心,使用2路NUMA完成內存訪問,本系統采用將計算核心鏡像劃分為2組的方式最大限度地使用內存控制器的帶寬。通過前一章節對于入侵檢測系統的模塊計算資源占用測量,可以得到計算量占比最大的分別為檢測和流重組模塊。因此各組均固定使用一個核心作為接收模塊完成數據接收與Mpipe調用,之后的其他核心均用作流重組/檢測模塊,其計算核心的比值作為重組/檢測比。在不同協議/流量環境,不同計算平臺上可能會存在不同的最優值,從而實現最佳的系統性能。本次實驗環境采用的是每組17個計算核心,出于方便分組考慮使用16個核心綁定流重組/檢測模塊,可采用的重組/檢測比為1/1、1/2、1/3、1/5、1/7,其中1/2為5組重組檢測比為1/2的核心與1組重組檢測比為1/1的核心,1/5為2組1/5的核心與1組1/3的核心,當重組檢測比不一致時存在的負載均衡問題,會結合檢測結果進行探討。endprint
將本系統部署于最高可達20 Gb/s以上日常流量的某網絡節點測試環境中進行測試,同樣使用隨機生成的1 000條http規則作為參照。經測量該實際流量的平均包尺寸為780 byte,其中http協議流量數據包占比約為72%。系統注冊插件為基于AC自動機的http關鍵字檢測模塊,配置有1 000條常用http關鍵字檢測規則。通過對不同重組/檢測比的系統吞吐量進行測量,并將其與Suricata運行模式中定義的Worker模式為標準的傳統并發式系統架構的吞吐量進行對比,同時并發架構未采用計算核心綁定、ncx_pool、無鎖回收隊列等本系統的改進點,系統總體性能如圖7所示,其中橫坐標為重組/檢測比中的分母,即1個重組模塊對應的檢測模塊個數,縱坐標為吞吐量Gb/s。
從圖7中可以看出,基于非統一內存的計算核心分配方案當重組/檢測比較低,即在流重組分配內核較多的情況下主要瓶頸在于檢測模塊,當重組檢測比為1/1時相當于只對應一個檢測模塊,其性能略低于未采用任何優化的并發模型,說明其架構性能要明顯弱于系統的并發模型。隨著重組/檢測比的不斷降低,系統吞吐量顯著提高,這也說明了由于測試流量中http流量占比較高,http關鍵字檢測的計算流程涉及到較為復雜的多模式匹配,同時http實際流量中包含了圖片等容量較大的信息,網絡流量數據的檢測開銷明顯大于流重組開銷。隨著檢測模塊的增加開始比達到1/3和1/5時系統性能達到最高值6.9 Gbps。之后隨著流重組模塊的減少,系統吞吐量出現了逐漸下降。
通過以上數據可以看出,由于將內存局部性較強的流還原和檢測2個模塊拆分,并按照NUMA節點的計算核心分配情況進行了分組,同時加入了計算核心綁定,使用ncx_pool內存池等優化,系統的內存利用率得到了有效提升,有效提高了緩存利用率。主要體現在當系統以合適的重組/檢測比運行時吞吐量的明顯提升,相比于傳統的并行模式,在Tilera Gx36平臺下基于非統一內存的計算核心分配方案可以使系統吞吐量提升約50%。同時也應注意,在1/2、1/5處由于重組/檢測比會出現負載均衡問題,實際性能會低于該結構下的理論性能。尤其在1/2處可以看到曲線有1個明顯的下凹,此處是因為有1個組從1/2降低到了1/1,即通信隊列的緩存空間需求增加了1倍,此時可能會造成系統阻塞在緩存空間申請處,[LL]
從而影響了系統整體吞吐量。可以推測,隨著可用計算核心數量的增加,在實現核心均勻分配的情況下,相比于當下,1/2、1/5的重組檢測比的分配方式具有更高的性能。
5結束語
本文通過對傳統并行入侵檢測模型與現有Tilera系列硬件平臺的硬件特點進行分析,提出眾核平臺的并行化系統設計要點,并設計和實現了高速并行化入侵檢測系統。本文主要取得的研究成果如下:
1)分析和總結了以Suricata為代表的主流并行化入侵檢測系統的體系結構,并對Suricata的3種工作方式結合現有tilera系列硬件平臺的硬件特點進行了理論分析,提出了眾核入侵檢測系統的設計要點。
2)結合提出的系統設計要點,提出了一種基于并行隊列的入侵檢測結構。該結構將傳統的流水線模式與并發模式相結合,在盡可能少地進行核間通訊的前提下,最大程度地提升了單核的內存使用效率和cache命中率。同時使用改進的無鎖回收消息隊列和共享內存池進一步提高了讀寫密集情況下的內存使用效率,使得該架構在眾核平臺具有很高的實用性,其主要模塊的設計思想也具有一定程度上的可移植性。最終實現了一個高效的基于眾核平臺的入侵檢測系統。
3)完成了對系統整體在不同核心分配方案下相比于傳統并發模型的性能測試。實驗結果表明,本系統在眾核平臺的運行效率要明顯優于傳統的并行入侵檢測系統,體現出了非常高的系統資源使用效率。
參考文獻:
譚章熹,林闖,任豐源,等. 網絡處理器的分析與研究[J]. 軟件學報,2003,14(2): 253-267.
[2] 羅章琪,黃昆,張大方,等. 面向數據包處理的眾核處理器核資源分配方法[J]. 計算機研究與發展,2014,51(6):1159-1166.
[3] 陳遠知. 多核處理器的里程碑——TILE64[J]. 計算機工程與應用,2009,45(專刊):307-309.
[4] Tilera. Tile Processor Architecture Overview for the TILE-Gx Series, UG130[Z]. USA:Tilera Corporation,2012.
[5] 陳遠知,楊帆. Tilera多核處理器網絡應用研究[C]//第五屆信號和智能信息處理與應用學術會議. 北京:中國高科技產業化研究會,2011:98-100,120.
[6] 葉穎, 嚴毅. 基于通用入侵規范下網絡入侵檢測系統的實現[J] . 廣西大學學報(自然科學版),2005,30(Supp):55-57.
[7] Tilera. MDE mpipe Programmer's Guide, UG506[Z]. USA:Tilera Corporation,2013.
[8] [JP3]ADVE S V, GHARACHORLOO K. Shared memory consistency models: A tutorial[J]. Computer, 1996,29(12):66-76.endprint
