基于任務發生關系的流程模型相似性度量
2017-11-08 01:42:38宋金鳳聞立杰王建民
計算機研究與發展 2017年4期
宋金鳳 聞立杰 王建民
(清華大學軟件學院 北京 100084)
(632230913@qq.com)
流程模型對于一個企業來說,具有十分重要的價值,它的作用不僅僅是對企業業務流程的具體刻畫,而且有利于企業對業務流程進行分析、驗證和優化[1].流程模型的管理包括模型分析、模型檢索和模型重用等方面[2].流程模型相似性度量在流程模型管理的各個方面都發揮著非常重要的作用.目前的流程模型相似性算法主要分為3類[2]:1)元素標簽映射的相似性度量;2)模型結構的相似性度量;3)行為語義的相似性度量.
元素標簽映射的相似性度量,是基于節點的成對標簽比較.它是通過定義2個模型的節點標簽之間的映射,從而計算出相似性.標簽匹配相似度等于匹配的節點數除以總節點數.為了檢測標簽的相似性,常常運用模式匹配算法[3]和本體匹配算法[4].Dijkman等人[5]在相似性度量方面做出了很多研究,提出了較多的相似性度量算法,最簡單的一種叫標簽對齊的相似性度量算法.Ehrig等人[6]提出了基于標簽語義的相似性度量方法.該類算法思路簡單、計算快速,但未對模型的拓撲結構和行為語義加以考慮,導致計算結果不夠精準.
結構相似性度量方法,是把模型看作一個圖,利用公共子圖同構和圖編輯距離對模型的相似性進行度量.圖編輯距離詳細定義了從一個圖轉換到另一個圖所需的最小原子級圖操作.Dijkman等人[7]提出了一種結構相似性度量方法,該方法定義了進行每一種編輯操作都必須付出相應代價,通過從一個模型到另一個模型的編輯距離,達到求出相似性的目的.基于上述算法,La Rosa等人[8]又提出了一種算法,結合了圖的編輯距離和活動匹配的方法.Li等人[9]提出了一種基于高級變更操作來計算模型相似性的方法,這種高級變更操作可以確保模型的完整性,并且使圖的編輯距離具有了高層語義上的特征.該類算法往往無法辨別行為相同或相近而結構有較大差異的模型對兒.
基于行為語義的相似性度量主要從模型的行為語義(如執行序列、任務關系)角度去考慮提取模型的行為關系,進而進行相似性的計算.Weidlich等人[10]提出了行為輪廓(behavioral profile,BP)算法的概念,行為輪廓主要是弱順序關系、嚴格順序關系、互斥關系、交叉關系等一系列關系的統稱.在行為輪廓概念定義的基礎上,作者提出了基于行為輪廓度量模型相似性的算法,即行為輪廓算法.該算法雖然可以在一定程度上高效提取行為關系,但是其粒度過粗,往往不能區分一些特殊結構,如互斥與循環、不可見任務等.Polyvyanyy等人[11]提出了4C(co-occurrence,conflict,causality,concurrency)算法,該算法提出了一系列關系的定義,包括共現關系、沖突關系、因果關系以及并發關系,統稱為4C關系,但由于關系過多且復雜,導致了其不易于計算和理解.Zha等人[12]提出了一種變遷毗鄰關系(transition adjacent relations,TAR)算法,但該算法只考慮到了變遷的緊鄰關系而忽略了變遷間接影響的關系,因此導致自由選擇結構與非自由選擇結構可能產生相同的結果.Wang等人[13]提出基于主變遷序列(principal transition sequences,PTS)的相似性計算方法,該算法可以有效處理循環結構,但是在并發分支較多的情況下會導致空間爆炸問題.汪抒浩等人[14]提出了SSDT算法(shortest succession distance between tasks),該算法定義了任務最短跟隨距離,并在此基礎上定義過程模型的任務最短跟隨距離矩陣,將2個過程模型的對應距離矩陣進行同維化后可以進行相似性計算.Dijkman等人[5]提出一種用因果足跡(casual footprints,CF)計算相似性的方法,該算法的主要思路是把過程模型用向量表示,但是由于向量中有過多的冗余信息,因此高維度的向量導致計算非常低效.
因此,鄭州市必須優化城市發展規劃,提供完善的城市創新基礎設施,對標國際一流創新型城市各項指標,著力解決短板問題,與國內外知名研發機構建立產學研用創新平臺,依托平臺培養人才、聯合創新和布局“鄭州智造”產業,加快鄭州高新技術產業的價值鏈攀升。
針對BP算法和4C算法的不足,本文提出了新的行為相似性度量方法TOR(task occurrence relations),即基于任務發生關系的流程模型相似性算法.首先定義了完全前綴展開中的前驅、公共前驅、最近公共前驅等一系列概念,并且設計了節點編號算法、最近公共前驅求解算法,提出了任務間3種發生關系,即因果、并行和互斥,據此給出了相似性計算方法.TOR算法可以很好地處理不可見任務和非自由選擇結構,并且可以有效提取存在于任務間的多關系.
1 預備知識
1.1 Petri網
定義1. Petri網[15].Petri網是三元組N=(P,T,F),其中P和T是不相交的有限集合,P是所有庫所的集合,而T是所有變遷的集合,它們之間的連接關系用F表示,F?(P×T)∪(T×P).Petri網中所有的節點集合為X=P∪T,對于任意節點x∈X,x的前置集合為·x={y∈X|(y,x)∈F},同理x的后置集合為x·={y∈X|(x,y)∈F}.
定義2. Petri網系統[15].二元組S=(N,M0)是Petri網系統,其中N=(P,T,F)為Petri網,M0
⑦ for eachn∈node· do
定義3. 就緒[15].給定Petri網系統S=(N,M0),對于任意變遷t∈T,M是從M0可達的標識,當?p∈·t滿足M(p)≥1時,則稱t就緒,記為(N,M)[t〉.若S的任意可達標識M和庫所p都滿足M(p)≤n(n為任意正整數),則稱S是有界的.
定義4. 觸發[15].給定Petri網系統S=(N,M0),M是從M0可達的標識,若t∈T且(N,M)[t〉,則t可被觸發,并得到新的標識M′=M-·t+t·.
1.2 完全前綴展開技術
McMillan等人[16]最先提出了一種新技術來避免Petri網系統驗證中無限狀態造成的空間爆炸問題.他首先提出一種網展開的概念,即完全有限前綴,之后基于分支進程這一概念,對該理論進行了進一步闡述[17].該算法的創新之處在于:通過記錄已經存在的標記狀態,提出了截斷事件的概念(即如果一個標記狀態已經存在過,那么就對其之后的部分進行截斷),從而避免同一狀態重復出現多次的現象,確保了展開結構的簡潔性.因此,該算法有著較高的效率和比較小的展開規模,在解決Petri網狀態空間爆炸問題方面有著比較出色的表現.Esparza等人[18]對McMillan等人[16-17]的算法進行了改進,提出了一種新的規模更小的展開方法,即完全前綴展開.
下面對該完全前綴展開(complete prefix unfolding,CPU)技術的一些基本概念進行簡要的介紹,更多相關概念和示例詳見文獻[18].
⑩ addntostartNodes;
1)O是無環的,C為條件(即庫所)的集合,E為事件(即變遷)的集合,邊集G?(C×E)∪(E×C);
2) ?c∈C,滿足|·c|≤1,即任意條件的輸入都小于等于1;
3) 對于所有x∈C∪E,都有(x#x),即所有的元素都不能是自沖突的;
4) ?x∈C∪E滿足{y∈C∪E|yx}必須是有限的.
在給定出現網中,因果關系xy表示x與y之間為偏序關系,即存在從x到y的路徑,沖突關系x#y表示二者所在的不同路徑開始于某公共條件或庫所c,且從c到x的路徑與從c到y的路徑不相交.
高校場館的運營管理對提高大學生體質健康水平、促進公眾健身參與和營造健康向上氛圍發揮著至關重要的作用,如何提高高校場館運營的綜合效益,使其真正與使用需求掛鉤,與城市生活、產業發展緊密相連已成為重要的理論和實踐命題。高校體育場館的運營困境,源于長期以來缺乏真正科學理性的綜合策劃和可行性研究,研究通過對高校運營管理的現實基礎和綜合環境分析,提出發展參考路徑,以期增強復合經營能力,拓展服務領域,延伸配套服務,建立適宜我國國情的高校場館發展方式。
定義6. 分支進程[18].對于網系統S=(N,M0),其中N=(P,T,F),出現網為O=(C,E,G),則π=(O,h)為S的一個分支進程,當且僅當滿足如下條件:
1)h為一個映射:C∪E|→P∪T,同時h(C)?P且h(E)?T;
⑤ whilestartNodes.size()>0 do
3)h使得Min(O)和M0之間為雙射,Min(O)表示根據偏序關系得到的C∪E中的所有最小元素集合;
把好加工關。按工藝流程規范操作,并做好以下幾點:不使用腐敗變質、含有毒有害物質的食品原料,不得回收餐廚廢棄物;嚴格實行“生熟分開”,避免食品受到各種致病菌的污染;需要熟制加工的食品要做到“燒熟煮透”,其中心溫度不得低于70℃,以保證殺滅食品中的有害微生物和有毒成分,對半成品和剩余食品進行二次烹調加工時,中心溫度亦不能低于70℃;制定詳細的清洗消毒制度及操作規程,嚴格實施清洗消毒程序;對高風險食品按規定程序進行留樣。
4) 對于所有e,f∈E,當h(e)=h(f)且·e=·f時,則必須滿足e=f.
定義7. 配置[18].S=(N,M0)是Petri網系統,其中N=(P,T,F),π=(O,h)是S的一個分支進程,其中O=(C,E,G),分支進程π的某個配置C′是一組事件,滿足如下關系:
1) ?e1∈C′,e2e1?e2∈C′,即C′是因果關系的事件組成的閉包;
2) ?e1,e2∈C′滿足(e1#e2),即e1和e2不沖突.
其中,任意事件e∈E的局部配置指的是,滿足條件xe∨x=e的所有事件x的集合,記作[e].
定義8. 割集[18].對于π=(O,h)的某有窮配置C′,Cut(C′)=(Min(O)∪C′·)·C′被稱為一個割集.
定義9. 充分關系[19].充分關系是在局部配置上的嚴格偏序關系,對于任意2個事件e,f∈E,如果有[e]?[f],那么[e][f],且通過有窮擴展得以保持(即如果[e][f]且Mark([e])=Mark([f]),則對于[e]的所有有窮擴展[e]⊕E,存在同構變換使得[e]⊕E[f]⊕則意味著e和f之間為充分關系.
根據《意見》要求,各高校對創新創業教育理論和實踐都進行了有益的探索,如開發就業創業課程體系、制定學分轉換政策、搭建創新創業實踐平臺、建立創客空間等,為大學生進行個性化指導和持續性幫扶,并取得了一定的成績。在校創業學生可以享受到專業導師指導、固定場地保障、濃厚創業氛圍等有利條件。可一旦畢業,這些學生即將面臨優厚待遇“失效”的窘境。這也使學生的創業面臨更多困難,高校不能充分發揮“扶上馬,送一程”的責任。這時就需要社區創客空間發揮其服務終身學習、致力創新創業繼續教育的優勢。
其中,Mark(C)表示從原網的初始標識開始,依次觸發配置C中的每個事件,最終得到可達標識.
定義10. 截斷事件、截斷條件[18].對于π=(O,h)中的一個事件e∈E,如果有一個對應事件f∈E,滿足Mark([e])=Mark([f]),并且[f][e],那么e就是截斷事件,f是其對應事件,記作f=corr(e).此時,e·被稱作截斷條件集合.通常來說,對于任意截斷條件c∈e·,滿足c·=?,即其后的事件均被截斷了.
定義11. 完全前綴展開[18].對于有界的網系統S=(N,M0),其分支進程π=(O,h)是S基于截斷技術得到的前綴展開,則π是完全的當且僅當對于S中的每個可達標識M,都存在π的一個配置C,使得:
1)Mark(C)=M,即M在π中得以表達;
2) 對于M下就緒的每個變遷t,都存在一個事件e,滿足e?C且h(e)=t且C∪{e}構成一個配置.
例1. 如圖1(a)所示的Petri網,圖1(b)為其完全前綴展開,也是該網的一個分支進程,其中:局部配置[A]={A},[C]={A,C},[E]={A,B,C,E},而割集Cut([A])={P1,P2},Cut([C])={P41},Cut([E])={P5};針對C與D組成的互斥結構,事件D為截斷事件,其對應事件corr(D)=C,而P42為截斷事件,其對應條件為P41;針對H和I構成的循環結構,事件I為截斷事件,其對應事件corr(I)=F,而P72為截斷條件,P71為對應條件,這是由于Mark([F])=Mark([I])且[F]={A,B,C,E,F}[I]={A,B,C,E,F,H,I}.
2 基于任務間發生關系的模型相似性度量算法
基于任務間發生關系的模型相似性度量算法TOR的主要步驟如下:
1) 基于完全前綴展開.首先把給定的Petri網模型進行完全前綴展開,這樣可以保持流程模型的所有標識及任務間發生關系,便于后續提取流程模型的行為特征.
2) 節點遍歷編號.逐層廣度優先遍歷得到的完全前綴展開,對其節點按照遍歷的層次編號,并存儲節點和其對應的編號.
3) 求出任務發生關系.根據最近公共前驅算法求出每2個任務的最近公共前驅并作相應的存儲,從而進一步求出任務發生關系.根據求出的最近公共前驅以及特殊結構的處理方式,確定任務之間的發生關系.
浩亭正從物理連接向數字連接的變革中轉變,產品設計理念上就要圍繞新的方向,包括模塊化、標準化和數字化。對此,浩亭電氣與浩亭信息技術軟件開發行政總裁烏弗·格拉夫(Uwe Graff)先生解釋說,“在模塊化方面,Smart Han連接器是浩亭模塊化產品的典型代表,可靈活搭配,以響應交通和機械領域的客戶需求,可顯著縮短基礎連接的現場時間;數字化的代表性產品就是MICA,這是一個數字化采集平臺,可對狀態環境進行現場數據采集,還有RFID產品也是擴展數字連接的產品線之一,關鍵是要貼近客戶實現技術落地。”
4) 模型相似性計算.在相應的任務間關系集合的基礎上,通過關系集合之間的加權相似性計算出模型之間的相似性.
2.1 任務發生關系相關定義
本節主要介紹圍繞任務發生關系的一系列定義,包括完全前綴展開圖中任意2個節點的前驅、公共前驅、最近公共前驅以及任務發生關系.
定義12. 路徑.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).a,b∈C∪E,有一條路徑從a到b,即存在一條從a到b的有向通路.
例2. 在圖1(b)中,A經過P1到B,則A到B可達,即存在一條從A到B的路徑.
在對商品的包裝進行責任追究時,主要的問題是對經濟損失如何計量。當侵權事件發生時,責任一方要對受害者進行賠償,賠償的數目應合理,這是在處理現實事件時首先應考慮的問題。按照我國的處罰慣例,不會采取懲罰性的措施,只是通過一定的補償將損失降到最小。
指一物鏡處在工作狀態,用轉換器轉至另一物鏡時,視野中心的偏移量。如用10×物鏡調焦后,以其中心為基準,再轉換至40×物鏡時,中心位移不得超過該視場半徑的2/3,以40×物鏡為基準,轉換至100×物鏡時,中心位移不得超過該視場半徑的3/4。
為了計算任務間發生的關系,需要對CPU節點的前驅、公共前驅以及最近公共前驅進行定義.
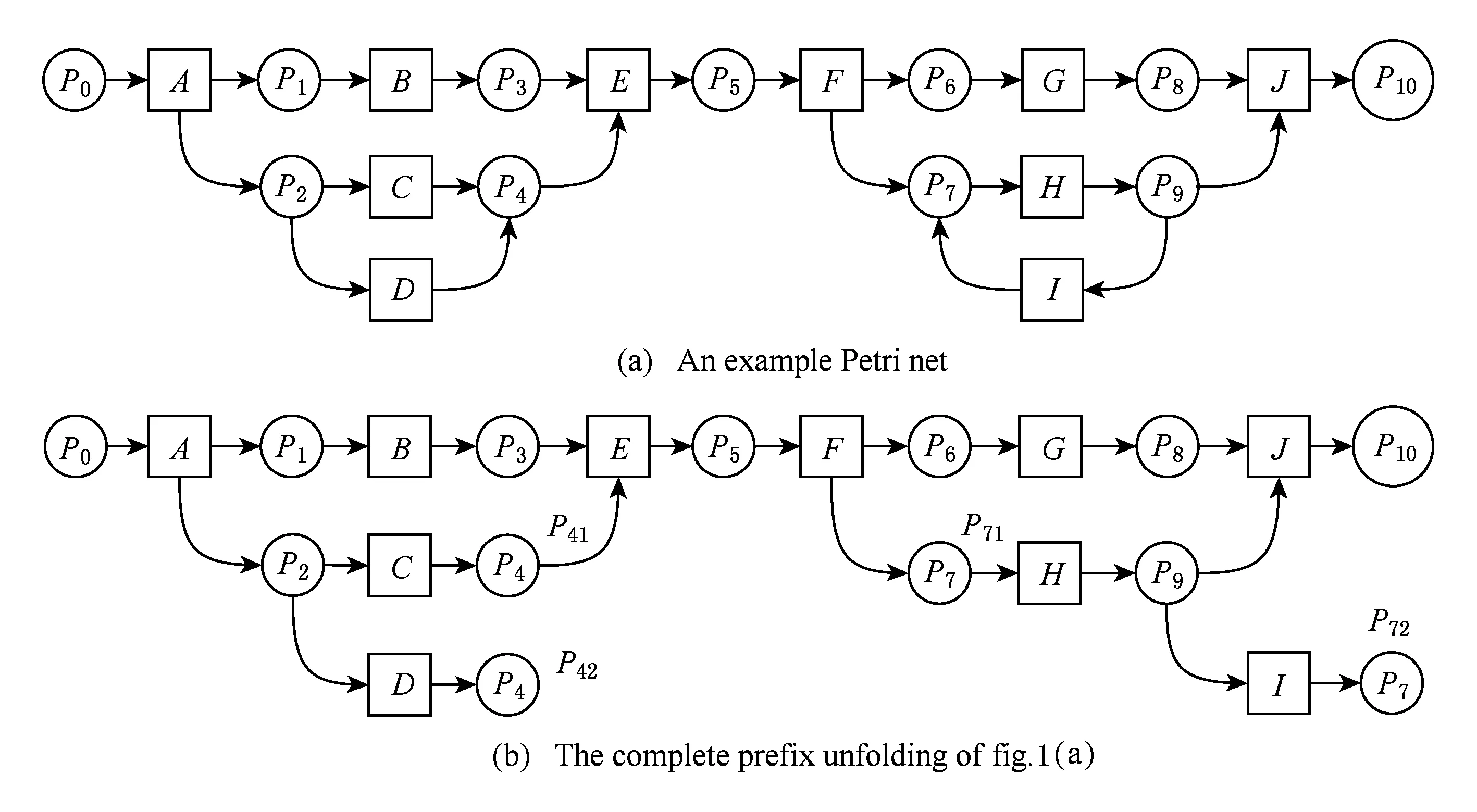
Fig. 1 An example for task occurrence relations圖1 任務發生關系示例
定義13. 前驅.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).從p到e存在一條路徑,其中p∈C∪E,e∈E,那么p是e的一個前驅,記為p∈pre(e),pre(e)表示e的所有前驅節點集合.特別地,有e∈pre(e).
對于截斷存在的情況,如果有一條路徑從c到e,并且c,c′∈C,e∈E,如果有c=corr(c′),那么認為有一條路徑從c′到e,且所有c′的前驅節點也是e的前驅,即?p∈pre(c′),有p∈pre(e).
例3. 在圖1(b)中,有一條路徑從B到E,B是E的前驅.同樣地,有一條路徑從C到E,那么C也是E的前驅.特別地,D雖然沒有直接到E的路徑,但是可以通過截斷條件P42跳轉到P41后使得從D到E有路徑相連,所以D也是E的前驅.同理,有一條路徑從G到J,G是J的前驅;有一條路徑從H到J,H也是J的前驅.雖然沒有直接從I到J的路徑,但是,可以通過截斷條件P72跳轉到P71后使得從I到J有路徑相連,因此,I也是J的前驅.
定義14. 公共前驅.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).對任意e1,e2∈E,如果存在cp∈C∪E,并且有cp∈pre(e1)∩pre(e2),那么cp就是e1,e2的公共前驅,記作cp∈cmPre(e1,e2).
定義15. 最近公共前驅.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).對任意e1,e2∈E和lcp∈cmPre(e1,e2),若不存在lcp′∈cmPre(e1,e2),滿足lcp′≠lcp而且lcp∈pre(lcp′),那么lcp是e1和e2的最近公共前驅,記為lcp∈lcPre(e1,e2).
例4. 在圖1(b)中,節點A既是B的前驅,也是C的前驅,則A是B和C的公共前驅.雖然A也是C和D的公共前驅,但P2才是C和D的最近公共前驅.
定義16. 因果關系.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).e1,e2∈E,t1,t2∈T,h(e1)=t1且h(e2)=t2,則t1和t2存在因果關系,當且僅當e1∈lcPre(e1,e2)(記作t1→t2或t2←t1,即逆序關系)或者e2∈lcPre(e1,e2)(記作t2→t1或t1←t2).
當日平均氣溫穩定回升到2~3℃時,小麥開始返青和恢復生長。日平均氣溫達到8~10℃時,小麥進入光照階段,是小穗分化時期,也是提高成穗率的關鍵時段。此時,日平均氣溫>16℃,不利于長大穗,并要求適宜溫度持續時間長,同時要有充足的光照和適宜的土壤水分條件。
定義17. 并行關系.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).e1,e2∈E,t1,t2∈T,h(e1)=t1且h(e2)=t2,則t1和t2存在并行關系,當且僅當存在e∈E,使得e≠e1且e≠e2且e∈lcPre(e1,e2),記作t1‖t2或者t2‖t1.
定義18. 互斥關系.π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G).e1,e2∈E,t1,t2∈T,h(e1)=t1且h(e2)=t2,則t1和t2存在互斥關系,當且僅當存在c∈C,使得c∈lcPre(e1,e2),記作t1#t2或者t2#t1.
例5. 在圖1(b)中,A和E存在因果關系,B和C存在并行關系,C和D存在互斥關系;而對于I和J,由于lcPre(I,J)={P9},二者之間存在明顯的互斥關系.
通過大量的研究表明中醫藥對功能性便秘的治療有較好的效果[6],主要是通過潤滑腸道,增加腸道運動,調節腸道神經遞質和胃腸道激素的分泌。還通過調養肝臟之氣血來治療便秘[7],國內外通過研究腸道微生態與功能性便秘的關系,也為便秘的治療提供新的途徑[8]。叢麗敏[9]等觀察益生菌干預大鼠動物模型便秘的效果,證明有一定效果。
定義19. 任務發生關系.S=(N,M0)是有界系統,π=(O,h)是其包含截斷事件的CPU,任務發生關系集合TOR={←,→,‖,#},統稱為S的任務發生關系.
以上定義了與任務發生關系有關的一系列定義,基于上述定義才可以進行后續的模型相似性計算.
2.2 任務發生關系計算
本節介紹任務發生關系的計算方法,包括節點編號算法、最近公共前驅算法以及任務發生關系的確定.
節點編號算法(其偽代碼如算法1所示)主要是通過遍歷CPU,確定每個節點的層級編號,是后續高效計算任意2節點最近公共前驅的基礎.
算法1. 節點編號算法generateLevel.
輸入: 有界系統S=(N,M0),π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G);
輸出:Map(node,level).*每個節點node及其對應編號level的散列表Map*
① 查找π中所有源節點并放入隊列startNodes;
四是人大發揮了越來越大的監督作用,各省都建立了省政府向人大匯報環境保護工作的機制,既包括在政府工作報告中匯報,也包括政府向地方人大常委會專門匯報,但是形式重于實質,少有問責的現象,如對于專門匯報方面,大多數情況是,政府的代表先在常委會全會上匯報,然后由人大常委會分組討論,提出意見,但是并不付諸于全會表決,監督作用有限;人大的監督在人大的信息公開方面不全面不系統,還有很大的提升空間。在市縣層面,一些領導人的認識不到位,仍然有一些政府沒有建立向地方人大常委會專門匯報環境保護工作的機制。這和《環境保護法》修改時規定不具體有關。
② for eachv∈startNodesdo
③Map.put(v,1);
④ end for
2) 對于所有e∈E,·e和·h(e)之間是雙射,e·和h(e)·之間是雙射,即h保留了變遷的外延;
⑥ 從startNodes中取出第1個元素,其編號為level;
是Petri網的初始標識,M0:P→,是自然數集合.
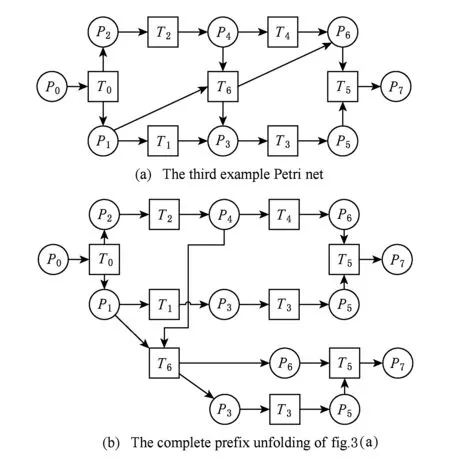
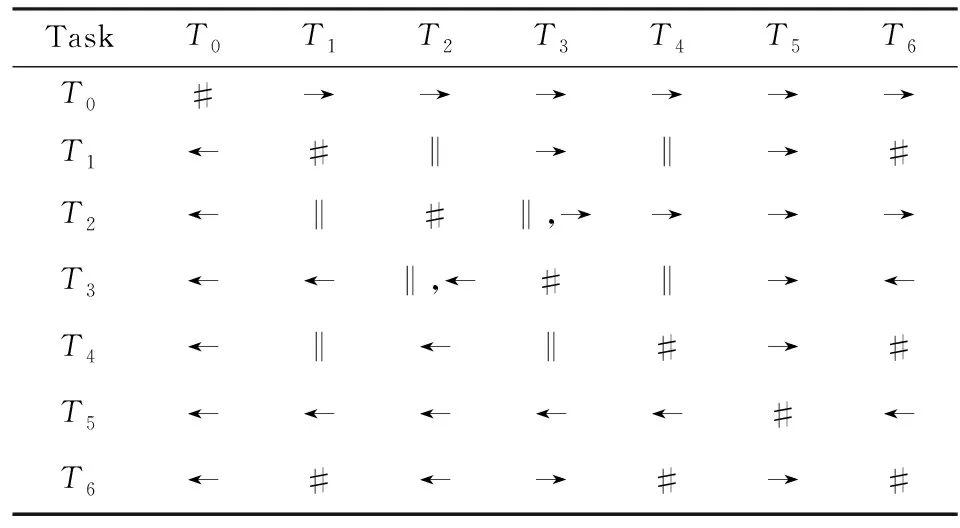
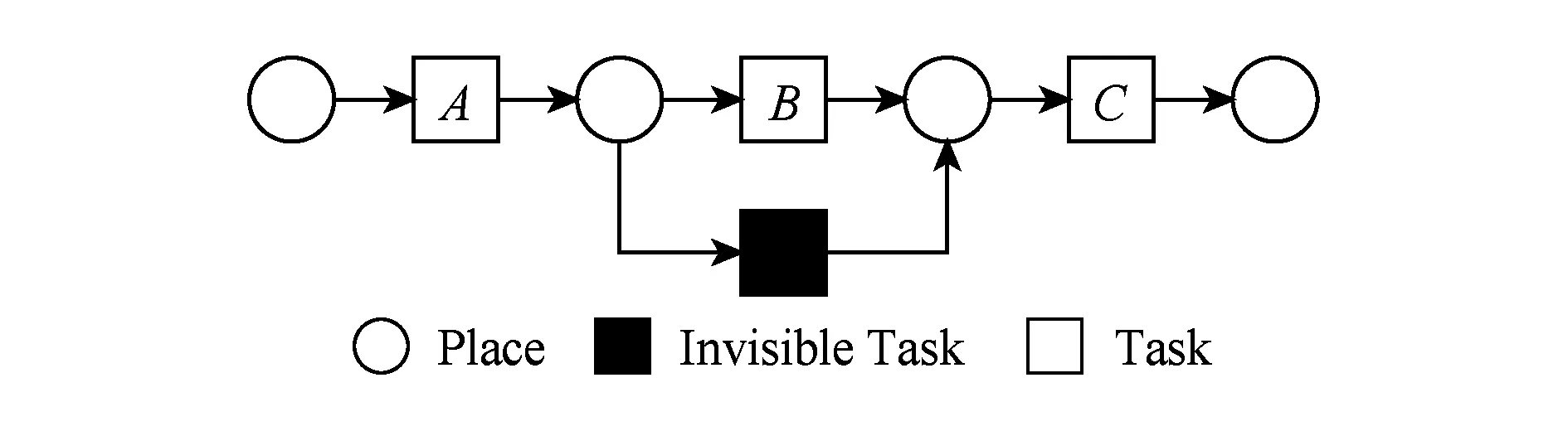
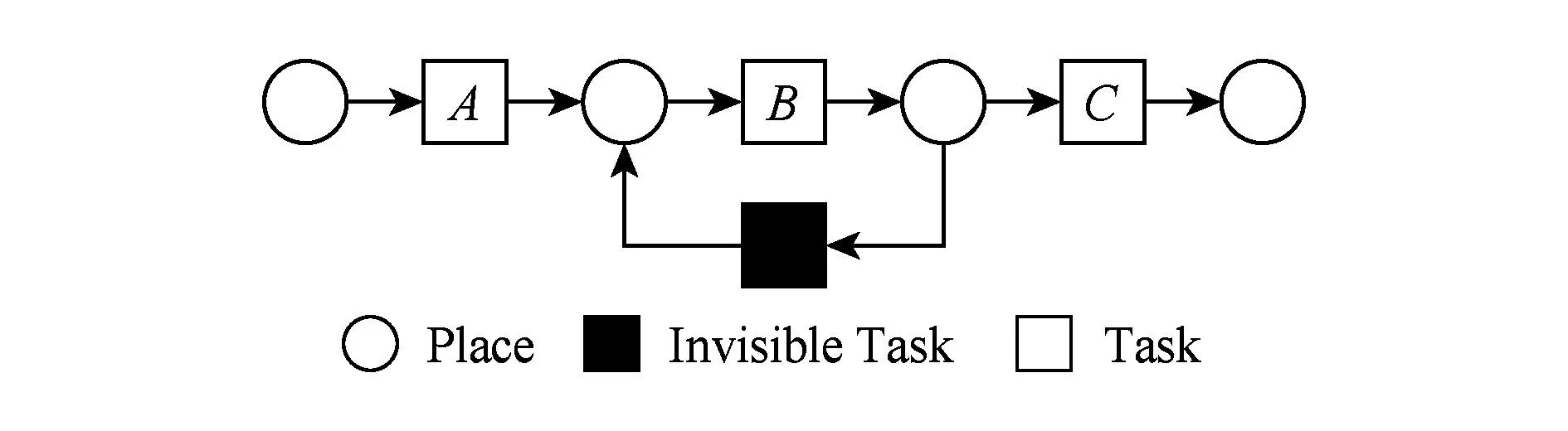
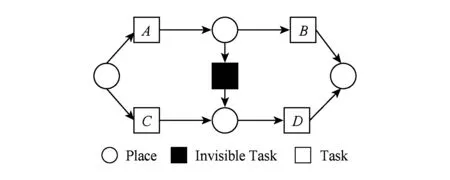
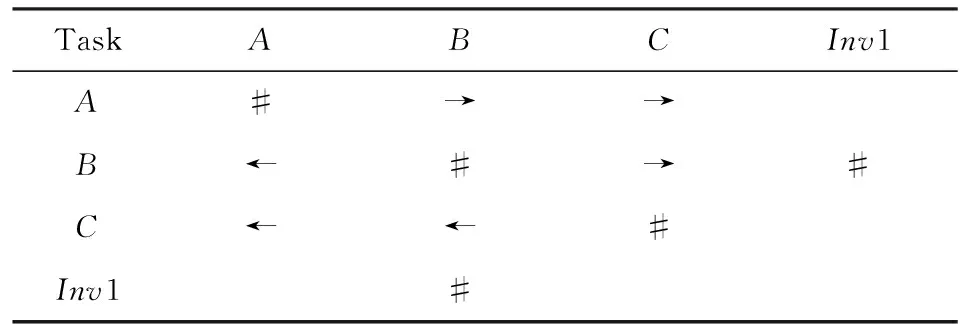
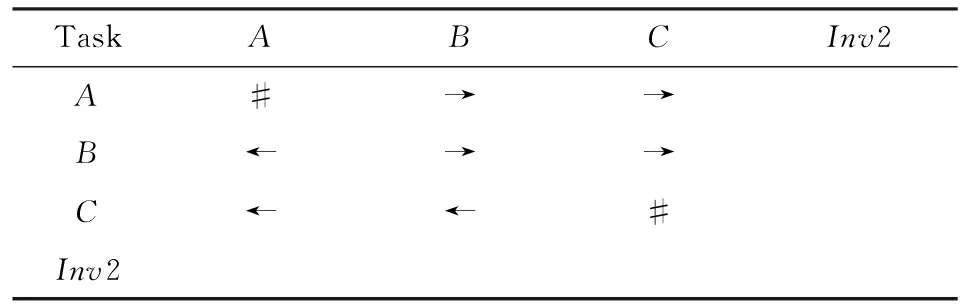
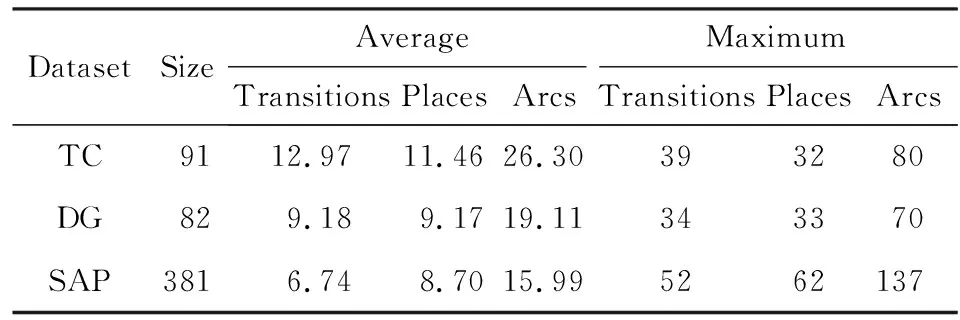
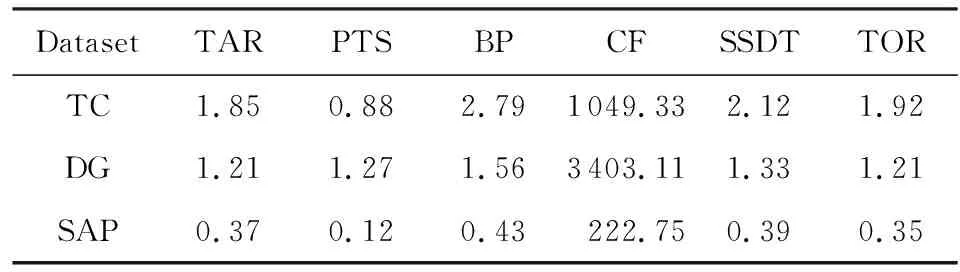
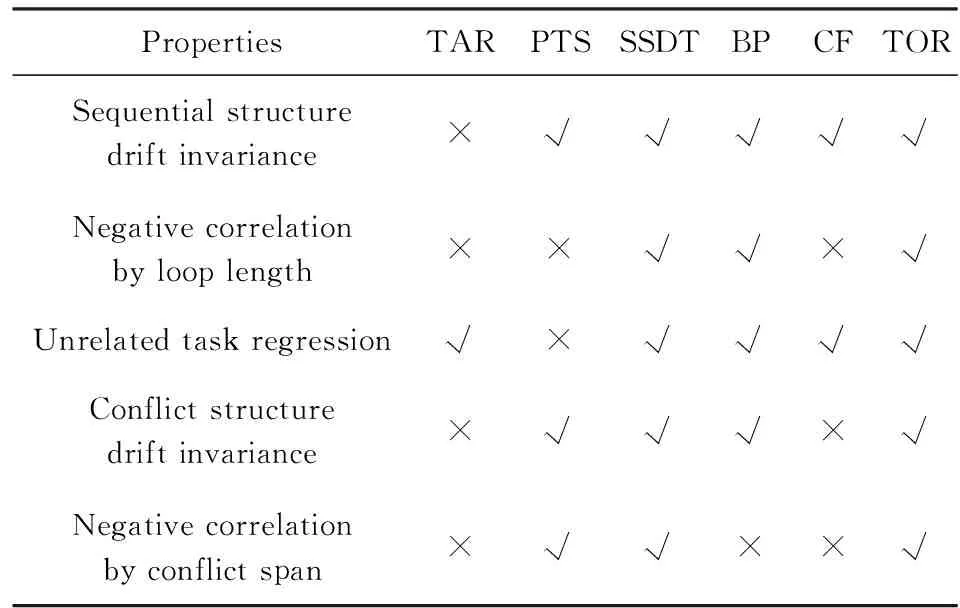
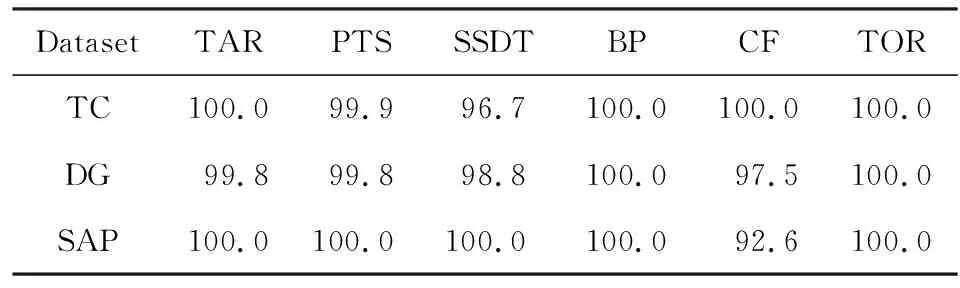
⑧ ifn?MaporMap.get(n) ⑨Map.put(n,level+1); 定義5. 出現網[18].出現網為一類特殊的Petri網O=(C,E,G),當且僅當滿足如下條件: 綜上所述,該工程地質特點為擬建場地人工填土層厚度較大,為2.40~2.80m,土質雜亂,填墊年限小于10年,不能作為持力層使用。下部④1層黏土土質一般,強度尚可,但厚度較薄,其下分布厚層淤泥質黏土(地層編號⑥2),土質軟,壓縮性高,為淺基礎軟弱下臥層,故本工程采用樁承臺基礎。樁型選用混凝土C80級PHC預應力高強混凝土管樁,樁端持力層為⑨1粉質黏土層,樁長27m。承臺埋深為-2.55m,承臺高度950mm,承臺頂標高為-1.60m。 Arzberg在 1920 年末與Hermann Gretsch大師合作推出新系列“1382”而名垂千史,該系列產品從1931 年便炙手可熱,有一位評論家給“1382”極高的評價,稱之“實用、樸實,簡潔的風格比膚淺的時尚更具經典意義”。 應該說,無論哪一種“生理性水腫”都與疾病無太大關聯,但是我們依舊可以通過改善生活習慣來減緩甚至避免。大家應當保持樂觀情緒,堅持適當鍛煉以增強體質,提高適應能力;飲食應堅持低脂肪、低膽固醇,少糖、少鹽,多吃瓜果蔬菜和豆制品等;避免久坐久站,經常活動下肢;最后,保證良好的睡眠,起居有律。 節點編號算法的步驟簡介如下:1)取出全部首節點(一般有且僅有1個),編號為第1層;2)按照廣度優先的原則,不斷取出同一層次的后繼節點,按照同一層編號相同的原則進行編號.同時,由于節點可從不同路徑可達,因此必要時需要更新某節點及其后繼節點的編號,取較大的編號作為該節點最終的編號;如果遇到循環節點,則不進行編號更新.遍歷的同時,把節點和其對應的編號信息存儲在散列表Map中,當所有節點遍歷完成后,算法結束.針對圖2(a)所示Petri網的CPU圖應用節點編號算法,所得結果如圖2(b)所示. Fig. 2 An example for Algorithm 2圖2 算法2步驟舉例 最近公共前驅可以在一定程度上反映任務之間的發生關系,函數computeLCP主要用于完成CPU中2節點最近公共前驅的計算,其偽代碼如算法2所示,其主要思路如下: 1) 把事件e1和事件e2分別放入事件數組array1和array2中(行①~②). 2) 遍歷array1求出編號最大的節點,記這個節點為node1,記最大編號為max1;同理,遍歷array2求出編號最大的節點node2,記最大編號為max2(行④~⑦). 3) 比較max1和max2.若max1>max2,則node1向前回溯一步;否則node2向前回溯一步(行⑧~). 4) 不斷重復思路2和思路3,直到找到公共前驅節點為止(行③~). 5) 返回公共前驅節點,這些公共節點就是e1,e2的最近公共前驅(行). 算法2. 最近公共前驅算法computeLCP. 輸入: 有界系統S=(N,M0),π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G);e1∈E,e2∈E;存儲CPU節點編號結果的散列表Map; 輸出: 最近公共前驅數組lcpSet. ① adde1toarray1; ② adde2toarray2; ③ whilearray1∩array2=? do ④ getnode1fromarray1with the max number; ⑤max1=Map.get(node1); ⑥ getnode2fromarray2with the max number; ⑦max2=Map.get(node2); ⑧ ifmax1>max2then ⑨stepBackward(node1,array1); ⑩ else 回溯一步算法stepBackward(其偽代碼如算法3所示)的主要思想是從startNode節點開始,向前回溯一步,同時更新數組array,把startNode的所有前驅節點加入數組array中,并把startNode節點從數組中移除. 算法3. 回溯一步算法stepBackward. 輸入: 有界系統S=(N,M0),π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G);startNode∈C∪E;存儲待遍歷節點的數組array. ① for eachn∈·startNodedo ② addntoarray; ③ end for ④ ifstartNode∈Cthen ⑤ for eachc∈Cdo ⑥ ifstartNode=corr(c) then ⑦ addctoarray; ⑧ end if ⑨ end for ⑩ end if 下面用一個具體的流程模型來說明2節點最近公共前驅的求解過程. 例6. 以圖2(a)中的流程模型為例,求解其CPU中事件T2和T8的最近公共前驅的計算過程如下: 1) 將該模型進行完全前綴展開,并用編號算法對所有進行編號,得到的CPU如圖2(b)所示; 2) 把T8放入array1中,把T2放入array2中,此時array1中節點的最大編號max1=8,array2中節點的最大編號max2=6,由于max1>max2,應該從T8向前回溯一步,調用函數stepBackward,此時array1更新為{P9},array2不變,仍為{T2}; 3) 此時max1=7,max2=6,由于max1>max2,應該從P9向前回溯一步,調用函數stepBackward,此時array1更新為{T7}; 4) 此時max1=6,max2=6,由于max1=max2,T2向前回溯一步,調用函數stepBackward,此時array2更新為{P3}; 5) 此時max1=6,max2=5,由于max1>max2,應該從T7向前回溯一步,調用函數stepBackward,此時array1更新為{P2}; 6) 此時max1=5,max2=5,由于max1=max2,應該從P3向前回溯一步,調用函數stepBackward,此時array2更新為{T1}; 7) 此時max1=5,max2=4,由于max1>max2,應該從P2向前回溯一步,調用函數stepBackward,此時array1更新為{T1}; 8) 到此為止,已經找到最近公共前驅集合{T1},算法結束. 根據求出的事件間最近公共前驅集合以及之前對于任務發生關系的定義,可以確定任意2個給定任務間的發生關系,對應算法的偽代碼如算法4所示. 算法4. 任務發生關系的確定算法computeTOR. 輸入: 有界系統S=(N,M0),π=(O,h)是其包含截斷事件的CPU,其中N=(P,T,F),O=(C,E,G);t1,t2∈T; 輸出: 任務發生關系集合TOR. ① for eache1∈E∧h(e1)=t1do ② for eache2∈E∧h(e2)=t2do ③lcp=computeLCP(e1,e2).get(0); ④ iflcp=e1then ⑤TOR.add(t1,t2,→); ⑥ else iflcp=e2then ⑦TOR.add(t1,t2,←); ⑧ else iflcp∈Ethen ⑨TOR.add(t1,t2,‖); ⑩TOR.add(t2,t1,‖); 通過該算法,可以基于CPU中任意2個事件間的最近公共前驅,確定流程模型中每對兒任務之間的發生關系,進一步可以求出流程模型的任務發生關系矩陣. 通過2.1節和2.2節介紹的算法和定義,已經可以確定模型的關系矩陣,基于關系矩陣可以計算過程模型的相似性.相似性計算主要思路為:首先分別介紹并行關系、互斥關系以及因果關系的權重和相似度;然后用權重乘以對應的關系相似度,從而得出整個模型的相似性. 并行關系、互斥關系以及因果關系的權重分別用如下公式計算,其中P,Q為給定的2個流程模型,P‖,P#,P→,P←分別為P的并行關系、互斥關系、因果關系和逆序關系集合.對于模型Q,亦有對應的關系集合. w1為并行關系的權重,其計算為 (1) w2為互斥關系的權重,其計算為 (2) w3為因果關系的權重,其計算為 (3) 在上述權值計算公式中,借鑒了Weidlich等人[10]在BP算法中的思路,直接采用各類二元關系個數在所有二元關系總數中的比重,認為并行關系、互斥關系和因果關系具有相同的重要性,這些權值支持用戶自定義. 根據Jaccard系數,并行關系、互斥關系以及因果關系的相似性分別用如下公式計算.本文假定前任務名稱、發生關系、后任務名稱分別相同,為判定關系集合中元素相同的標準,如T1#T2≠T1#T3. 對于并行關系的相似性,用P模型和Q模型所有并行關系的交集元素數除以P模型和Q模型所有并行關系的并集元素數: (4) 對于互斥關系的相似性,用P模型和Q模型所有互斥關系的交集元素數除以P模型和Q模型所有互斥關系的并集元素數: (5) 對于因果關系的相似性,用P模型和Q模型所有因果關系的交集元素數除以P模型和Q模型所有因果關系的并集元素數: (6) 2個模型P和Q的相似性為并行關系的權重乘以并行關系相似性、互斥關系的權重乘以互斥關系的相似性、因果關系的相似性乘以因果關系的權重這三者的累加和,其計算為 sim(P,Q)=w1×sim‖(P,Q)+ (7) 圖3展示了包含多關系的典型實例,同時該例也體現了TOR算法對非自由選擇結構的有效處理.圖3(a)為Petri網表達的原模型,圖3(b)是其對應的CPU.在一個分支進程里,T2和T3是并行關系,在另一分支進程里面,T2和T3是因果關系,這2種關系都是有效的.在算法的設計中已充分考慮了不同分支進程的情況,因此,在關系的提取過程中,這2種關系都會被提取出來,對應的任務發生關系矩陣如表1所示. Fig. 3 An example for multiple occurrence relations between tasks圖3 任務間多發生關系實例 Table 1 TOR Matrix of the Process Model in Fig.3表1 圖3中模型的任務發生關系矩陣 Notes: →means causality; ←means inverse causality; #means conflict; ‖means concurrency. 在實際業務過程模型中會出現一種特殊的任務,稱作不可見任務[19],即空標簽任務,這種任務的存在會影響模型的行為.然而,現有的模型相似性算法大多忽略了不可見任務的處理,本文給出其具體處理方法.主要處理3種類型的不可見任務,分別是SKIP類型、REDO類型以及SWITCH類型.SKIP類型不可見任務用于跳過某些任務,如圖4所示;REDO類型用于重復執行某些任務,如圖5所示;SWITCH類型不可見任務,用于在過程模型的不同可選分支間進行執行順序切換,如圖6所示.關于不可見任務的詳細分類,讀者可參閱文獻[19]. 對于SKIP類型的不可見任務,可以看出在圖4所示模型中,不可見任務(稱其為Inv1)跳過了任務B,也就是該不可見任務的存在,導致了B被跳過.換個角度來說,該不可見任務和B是互斥關系,二者不能同時執行.在處理這一類不可見任務的時候,只需要考慮該不可見任務與其跳過范圍內的可見任務的互斥關系即可.確定這個范圍,就需要通過該不可見任務的輸入輸出邊來確定其作用范圍.也就是說,在SKIP類型的不可見任務處理時,不可見任務只參與互斥關系的計算,在圖4中體現為B#Inv1.該模型的關系矩陣如表2所示. Fig. 4 An invisible task of SKIP type圖4 SKIP類型不可見任務 Fig. 5 An invisible task of REDO type圖5 REDO類型不可見任務 Fig. 6 An invisible task of SWITCH type圖6 SWITCH類型不可見任務 Table 2 TOR Matrix Involving an Invisible Task of SKIP Type表2 SKIP類型不可見任務的任務發生關系矩陣 Notes: →means causality; ←means inverse causality; #means conflict. 對于REDO類型的不可見任務,需要考慮任務間因果關系的變化.可以看出在圖5所示模型中,不可見任務(稱其為Inv2)和任務B構成了循環結構,導致了任務B可以重復執行.在處理這類不可見任務的時候,只需要考慮該不可見任務作用范圍內可見任務的因果關系即可.雖然有Inv2→B和B→Inv2,但是最終填寫矩陣的時候不考慮這2個依賴關系,而只考慮B→B.確定不可見任務的作用范圍時,同樣需要借助其輸入輸出邊.將這個范圍內的可見任務彼此之間的關系更新為正確的因果關系即可.該模型的關系矩陣如表3所示: Table 3 TOR Matrix Involving an Invisible Task of REDO Type表3 REDO類型不可見任務的任務發生關系矩陣 Notes: →means causality; ←means inverse causality; #means conflict. 對于SWITCH類型的不可見任務,可以看出在圖6所示模型中,不可見任務(稱之為Inv3)導致了A和D之間多了一條可達路徑.這種情況下,導致了A和D因果關系的產生.而不可見任務本身是不參與因果、并行和互斥3種關系中計算的.而該不可見任務的存在,使A和D之間多了一種因果關系.確定該不可見任務的作用范圍,只需檢測其導致了哪些任務從不可達變為可達(即因果關系).該模型的關系矩陣如表4所示: Table 4 TOR Matrix Involving an Invisible Task ofSWITCH Type Notes: →means causality; ←means inverse causality; #means conflict. 以上是對不可見任務造成影響的處理,通過這種方式可以很好地計算在不可見任務存在情況下的模型相似性,從而使結果更加合理和全面. 本文的實驗環境如下:MacBook Pro,Intel Dual Core i5 CPU@2.6 GHz,8 GB DDR3@1 600 MHz,操作系統為OS X 10.8.3,Java Development Kit 1.8,Java虛擬機最大內存設置為2 GB. 實驗所涉及的工業數據集主要包括3個: 1) 唐山軌道客車有限責任公司數據集(TC).本文實驗的工業數據集包含從TC收集的91個流程模型.TC是中國第1家軌道交通制造企業,具有100多年的悠久歷史,具有著超強的創新能力和研發能力,從動車組到中低速客車,從城軌車到特種車,有著完備的生產制造技術平臺,其設備通用度高并且注重流程規范. 2) 東方鍋爐股份有限公司數據集(DG).在本文實驗的工業數據集包含從DG收集的82個流程模型.DG是國資委下屬中國東方電氣集團子公司下屬公司,是一個熱力發電系統設備、核能系統設備、煤氣化設備等于一體的制造和服務供銷商,擁有鍋爐、核能發電、焊接、環境保護、材料、熱強、自動化控制等科研機構. 3) SAP參考過程模型數據集(SAP).本文實驗的工業數據集包含從SAP收集的流程381個模型.SAP是全球最大的企業資源規劃和智能化解決方案的提供商,其業務包括高科技企業資源規劃、消費品企業資源規劃、零售企業資源規劃、醫療企業資源規劃、金融企業資源規劃、公共事業企業資源規劃、化工企業資源規劃等. 表5列出了上述3個工業數據集的基本結構特征,可以看到每個模型集中的平均最大變遷數、平均最大庫所數和平均最大弧數. Table 5 The Basic Structural Features of ThreeIndustrial Datasets 下面通過對比TAR算法、PTS算法、BP算法、CF算法、SSDT算法及TOR算法在TC,DG,SAP這3個工業數據集上的運行時間,來評估TOR算法在實際工業數據集上的性能表現,具體實驗結果如表6所示: Table 6 Time Costs of Different Algorithms on theThree Industrial Datasets 可以看出CF算法的時間復雜度較高,時間消耗遠遠高于其他算法;TAR算法、PTS算法、BP算法、SSDT算法、TOR算法基本在一個數量級上;TOR算法略優于BP算法、SSDT算法,與TAR算法持平,略慢于PTS算法.因此,TOR算法在實際工業數據集上運行性能表現良好. 汪抒浩等人[14]給出了流程模型行為相似性算法應當滿足的5個性質,這些性質一定程度上可以作為評估不同相似性算法的依據.利用這5個性質比較TOR算法與主流模型行為相似性算法,結果如表7所示: Table7TheSatisfactionofDifferentAlgorithmsontheFivePropertiesthataGoodSimilarityMeasureShouldHave 表7 各個算法針對流程模型相似度的5個性質滿足情況 Notes: √means satisfaction; ×means unsatisfaction. 可以看出,TAR算法只滿足一條性質,即互斥無關遞減性;PTS算法滿足3條性質,不滿足循環長度負相關性和互斥無關遞減性;BP算法滿足4條性質,不滿足互斥長度負相關性;而CF算法只滿足2條性質;只有SSDT算法和TOR算法滿足全部5條性質.由此可以看出,TOR算法的表現非常好,SSDT算法雖然也能滿足全部5條性質,但其性能上表現得有所欠缺,且計算相似性時需要先對SSDT矩陣做同維化處理. dist(M1,M2)≤dist(M1,M3)+dist(M2,M3); (8) dist(M1,M3)≤dist(M1,M2)+dist(M2,M3); (9) dist(M2,M3)≤dist(M1,M2)+dist(M1,M3). (10) (11) TAR算法、PTS算法、SSDT算法、BP算法、CF算法以及TOR算法的三角不等式滿足率如表8所示: Table 8 The Satisfaction Rate of Different Algorithmson the Triangle Inequality 可以看出并不是所有的算法都滿足三角不等式.TAR算法在DG數據集上不滿足三角不等式;PTS算法在DG和TC數據集上不滿足三角不等式;SSDT在TC和DG數據集上不滿足三角不等式;CF算法在DG以及SAP數據集上不滿足三角不等式;而BP算法和TOR算在3個數據集上均滿足三角不等式.而與BP算法相比,TOR算法具有能處理不可見任務、區分循環和并發造成的任務間行為差異等優點. 針對現有流程模型行為相似性算法的不足,本文提出了一種能準確提取模型行為關系而又高效的算法——基于任務發生關系的模型相似性度量算法TOR.TOR算法首先把給定Petri網模型進行完全前綴展開,以清晰地表達模型的行為特征;接著,通過遍歷對CPU圖中的節點進行編號,以便于后續關系的求解;然后,對兩兩節點求解最近公共前驅,以確定節點對應的任務間的發生關系;最后,通過相應的公式計算模型的相似性.在算法的適用性上,TOR算法可以有效區分并發和循環的行為差異,高效處理非自由選擇結構、不可見任務等復雜結構,TOR算法同時還可以有效地提取任務間多關系.基于來自3個企業的過程模型集的實驗表明,TOR算法具有很好的性能優勢,能滿足相似性度量算法的全部5個優良性質,且其對應距離滿足三角不等式. 在流程模型相似性算法評估方面,仍然缺乏一個權威的公認評估框架,在未來的工作中,將嘗試提出一個合理評價相似性算法優劣的評估框架.同時,在進一步改進TOR算法以提升性能的同時,嘗試將其應用于大量模型的索引方面.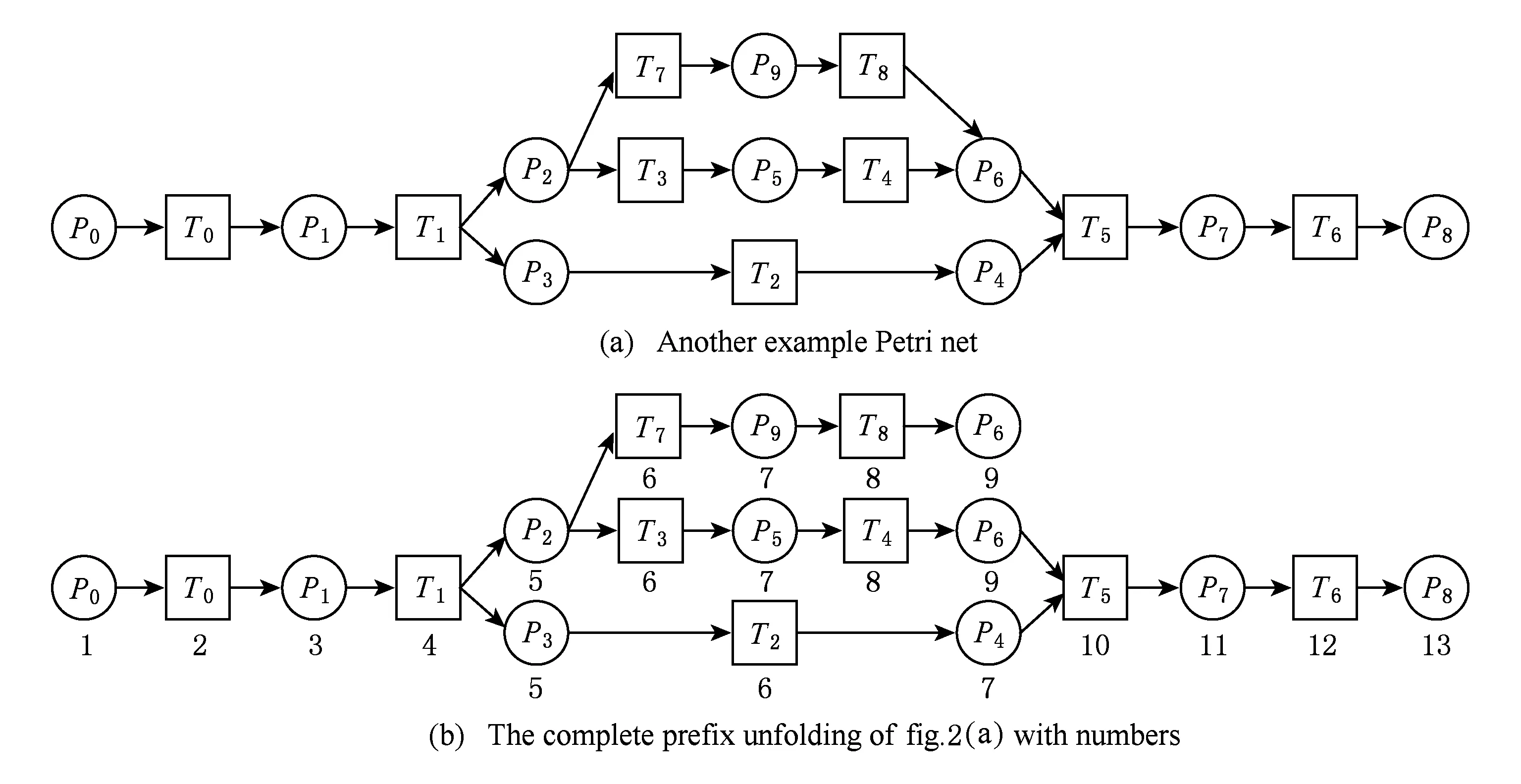
2.3 流程模型相似性計算
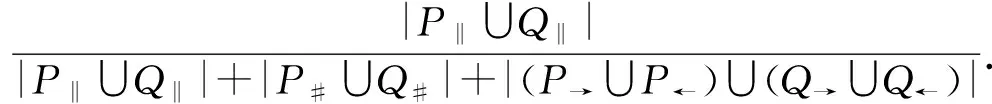
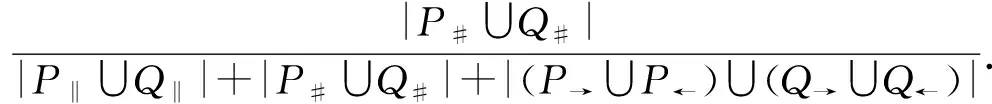
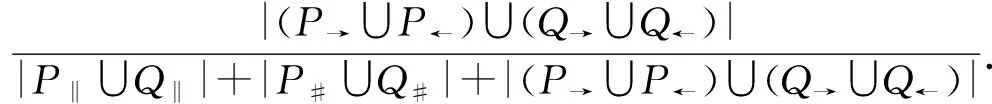
w2×sim#(P,Q)+w3×sim→(P,Q).2.4 任務間多發生關系處理
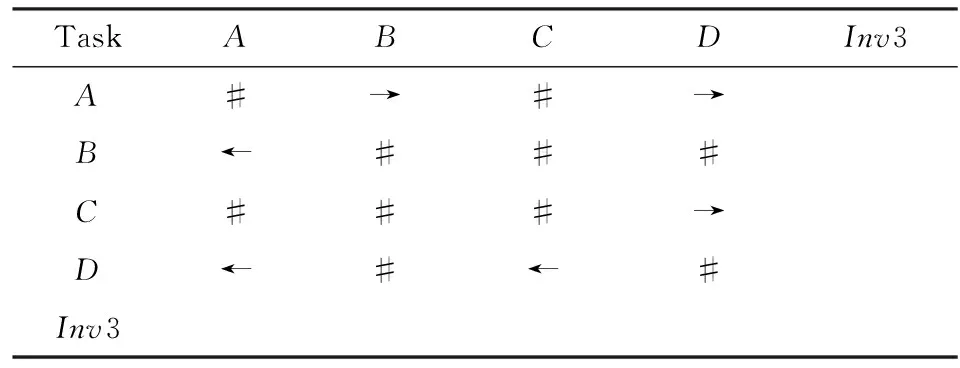
2.5 不可見任務處理
3 實驗設計與分析
4 總結與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
海峽姐妹(2020年9期)2021-01-04 01:35:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
山東青年(2016年1期)2016-02-28 14:25:25
核科學與工程(2015年4期)2015-09-26 11:59:03
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
