海空目標航跡數據清洗方法和流程研究
2017-10-25 11:37:10劉帥楊松常歌董亞卓
網絡空間安全 2017年8期
劉帥++楊松++常歌++董亞卓
摘 要:論文針對海空目標航跡數據的內容與特點,面向海空目標探測效能評估需求,提出了海空目標航跡數據清洗方法和流程,包括數據格式規范化處理、數據篩選、去離群點和航跡插值等。試驗證明,論文提出的數據清洗算法能夠優化數據格式,剔除原始數據中的錯誤、無效數據,增加樣本數量,從而為后續開展海空探測效能評估做好數據準備。
關鍵詞:海空目標航跡數據;數據清洗;算法
中圖分類號:TP391;E917 文獻標識碼:A
Abstract: Based on the contents and features of the sea and air target trace data, facing the requirements of effectiveness evaluations, this paper puts forward a method and process of the sea and air target trace data cleaning, including data formatting processing, data filtering and so on. The tests prove that the data cleaning algorithm proposed can optimize the data format, eliminate the wrong and invalid data, increase the sample numbers, and prepare the data for the subsequent effectiveness evaluations.
Key words: the sea and air target trace data; data cleaning; algorithm
1 引言
海空目標航跡數據是各海空目標探測系統、海空目標信息綜合處理系統、海空目標用戶系統之間生成和傳遞的海上、空中、水下目標的位置、屬性、狀態、時間等信息數據。當前,海軍承擔海空目標探測任務的裝備主要有各雷達站、觀通站、海上平臺、空中平臺、水下平臺等,這些平臺的使命任務是及時、準確地發現、定位、跟蹤各類海上、空中、水下目標,對目標進行初步識別,并將探測到的原始海空目標航跡數據上報至上級海空情綜合處理系統,海空情綜合處理系統對各平臺上報的海空目標航跡數據經多級融合處理和識別認證,形成最終的海空目標態勢產品,送往指揮所,輔助指揮員指揮決策。
因此,要對整個海空目標探測體系的目標探測質量、信息流轉效率、融合識別流程等進行分析評估,就離不開對海空目標探測數據的自動、準確的分析、處理和運算。當前,由于海空目標探測體系內包含的系統、平臺、裝備類型眾多,由多家單位承研承建,而在裝備論證之初對各裝備數據記錄的內容、格式、量綱等缺少統一要求和規范,因此,導致整個體系內采集的裝備原始數據存在很大程度的不統一、不規范、不完整等問題,同時還存在部分空數據項和錯誤數據項,因此,需要對原始的海空目標航跡數據進行清洗和規范化處理,去除無效的數據字段、增加標識字段、統一格式與量綱、剔除離群點和錯誤點,對稀疏航跡進行插值,以確保最終入庫參與運算的海空目標航跡數據格式統一、規范、準確,以便于后續的分析運算和裝備效能評估。
當前,國外對數據清洗的研究主要集中在四個方面:檢測并清除數據異常;檢測并清除近似重復數據;數據的集成;特定領域的數據清洗。國內的數據清洗技術研究主要集中在對數據質量需求很高的行業,他們以各自需求為牽引在特定領域展開相關研究[1,2]。
2 海空目標航跡數據內容及特點分析
各海空目標探測系統、海空目標綜合處理系統和海空目標用戶系統之間傳遞的海空目標航跡數據,主要包括信息字段:海空目標批號、情報源號、目標探測時間、目標經緯度位置、目標方位、目標距離、目標高度、目標類型、目標屬性等。原始的海空目標航跡數據有四個特點。
(1)數據規模大。由于海空目標態勢是動態變化的,海空目標航跡數據也在不斷更新,因此整個海空目標探測體系內流轉的數據量非常大,以方向級空情綜合處理系統為例,平均每秒鐘報文更新率在100條左右。
(2)多型裝備數據記錄格式不統一。由于在裝備論證之初,缺少對數據記錄內容、格式、量綱等的頂層規劃和統一要求,導致當前各裝備記錄的數據存在內容、格式等不統一、不規范的問題。
(3)存在大量復合字段。原始海空目標航跡數據中存在大量的復合數據字段,如“年+月+日”、“站號+批號”等,需要將這些數據記錄拆分成“年”、“月”、“日”、“站號”、“批號”這樣的單獨字段,以用于后續的處理、分析和運算。
(4)存在離群點和空字段。當前,由于海空裝備的探測能力有限,探測結果經常會出現錯誤的離群點,需要在掃描到這樣的離群點后,將離群信息記錄下來,并將相應的數據行刪除,離群點不參與后續運算。另外,采集的原始數據還存在部分空字段,即沒有探測到相應的目標屬性信息,需要在掃描到字段后,對相應的字段進行記錄和處理,以確保數據入庫的整齊性。
因此,海空目標航跡原始數據存在數據記錄格式不統一、存在復合字段、存在離群點和空字段等問題,需要建立一套統一的海空目標航跡數據格式規范,將所有裝備的原始數據按照規范的格式要求進行數據規范化處理,并按照數據后續運算要求,對數據進行篩選、去錯、插值等操作,以保證數據整齊入庫,便于后續評估運算。
3 數據格式規范化
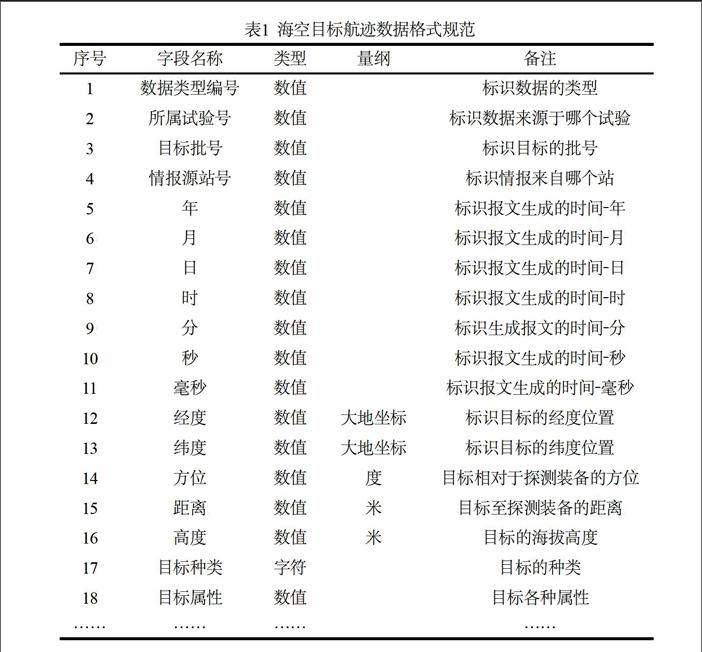
進行數據清洗的第一步是建立統一的海空目標航跡數據格式規范,將所有裝備記錄的海空目標航跡數據按照統一的內容、格式和量綱等要求集中存儲。經全面分析后續開展裝備效能評估的需要,建立海空目標航跡數據格式規范,如表1所示。endprint
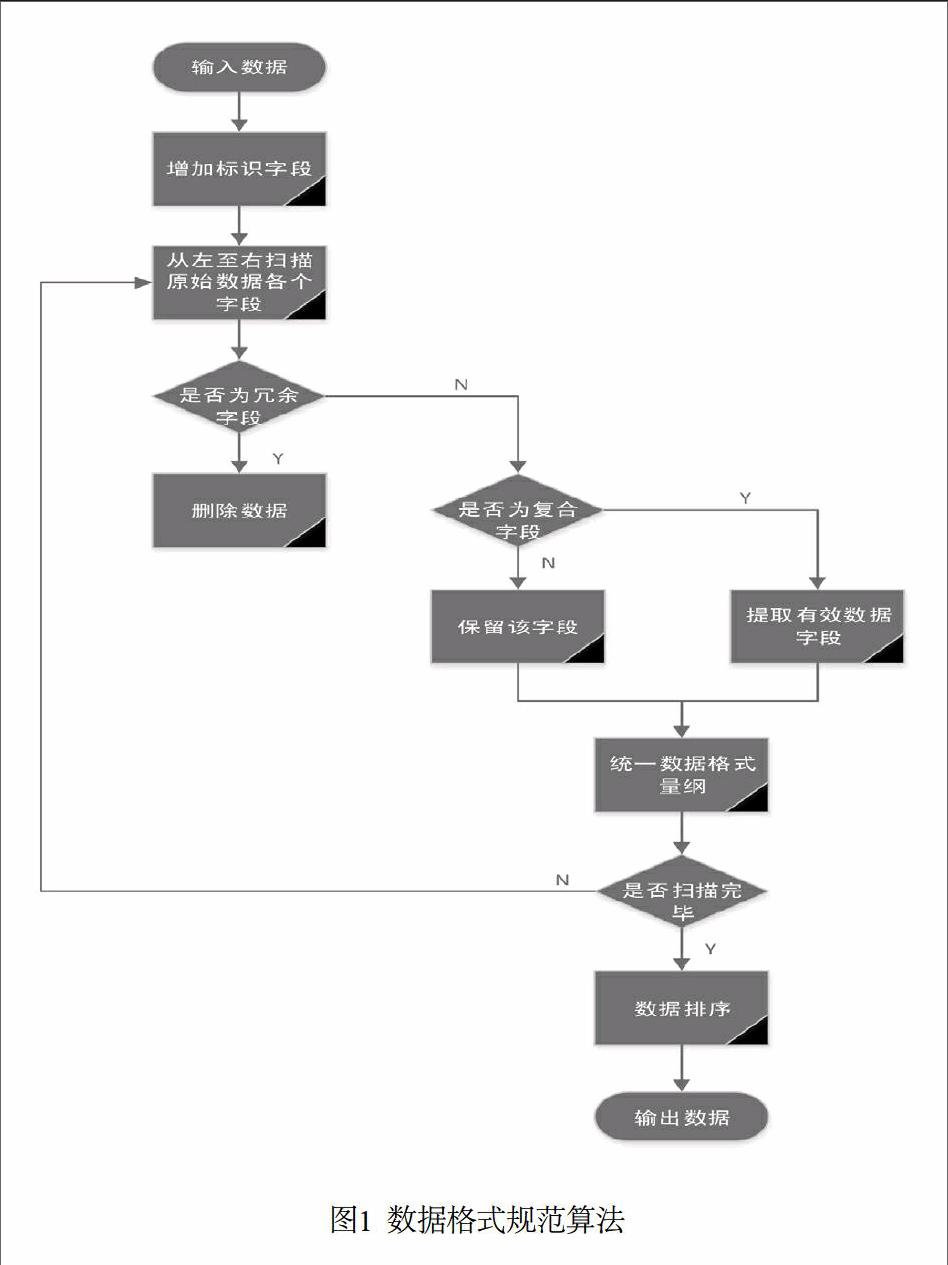
將來自多平臺的多類數據按表1的格式要求進行規范化處理,刪除冗余字段、拆分復合字段、統一格式與量綱,同時為了辨識來自不同試驗、不同裝備的多類數據,需要適當增加數據標識字段,以實現數據的分門別類存儲,便于后續的數據處理和查詢。通過將算法代碼化,實現對海量的海空目標航跡數據的自動、快速規范化處理。本文提出的數據格式規范化方法如圖1所示。
第一步:輸入原始的海空目標航跡數據。
第二步:添加標識字段。增加多源多類數據標識、試驗標識、裝備標識等字段,如“數據類型編號”、“所屬試驗號”等字段,實現數據的分門別類存儲。
第三步:刪除冗余字段,拆分復合字段。按照數據格式規范,從左至右掃描數據字段,判斷該數據字段是否在數據格式規范中,如果是,則保留,如果不是,則刪除。如果是復合字段,如“情報源站號+批號”,則提取當中的有效字段予以保留存儲。
第四步:統一數據格式、量綱。將所有的字段轉換成統一的格式和量綱,如將長度的單位統一為“米”,經度、緯度、方位等的單位統一為“度”等。
第五步:數據字段排序。按照規范的格式要求,將數據字段排序。
第六步:輸出數據。
4 數據清洗
在多系統的數據進行規范化之后,數據清洗過程是對數據中存在的錯誤數據行、空數據行等進行進一步的細化處理。
4.1 數據篩選
海空目標航跡數據規模龐大,在進行裝備效能評估時,通常不需要全部時段的所有數據,如演習過程是10:00至12:00,那么我們就可以重點提取10:00至12:00的數據進行綜合分析,而不需要考慮全天的數據。當前,常用的數據提取方法有三種:一是按照時間軸提取,提取固定時間段或者時間節點的數據;二是根據經緯度進行提取,提取重點海域內的海空目標航跡數據;三是根據演習關注的重點,提取重點目標航跡數據。
4.2 檢測并剔除離群點
在海空目標航跡數據中,存在部分離群點,即相應的目標位置偏離目標原有航跡不合理的距離,視其為探測錯誤點,這樣的航跡點,在數據監測中,要將其記錄下來并刪除相應的數據行,作為問題進行分析,但不參與后續裝備效能評估運算。
采用基于鄰近性的離群點檢測方法[3],基于距離監測離群點,對一個目標航跡定義距離閾值r,如果一個航跡點與相鄰若干個航跡點的距離在r之內,則將其視為有效點,如果一個航跡點與其臨近的若干個航跡點距離超出r,則將其認為是離群點,記錄并剔除。
4.3 航跡插值
采集的原始數據中,部分航跡點存在航跡過于稀疏的情況,這樣在后續計算中,會存在樣本量少的問題,對這種情況要將其航跡稀疏現象記錄下來,并進行插值處理,增加航跡點數量。
采用拉格朗日三點插值法[4],對稀疏的航跡點進行插值處理。當沒有和真值航跡時標一致的目標航跡時,對與真值航跡時標一致的目標航跡點數據進行插值計算。確保在兩小時的目標航跡上有至少5個航跡點,且相鄰兩個航跡點間隔不大于20分鐘。
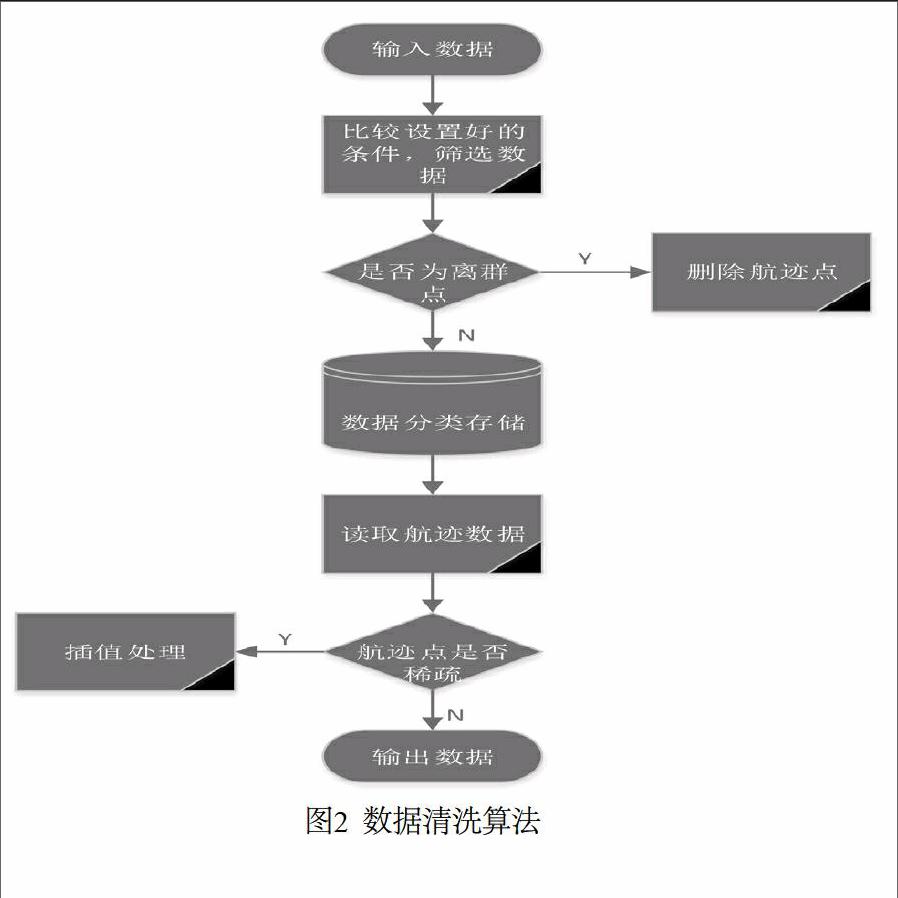
本文提出的數據清洗算法[5]如圖2所示。
第一步:輸入格式規范后的數據。
第二步:數據篩選。根據裝備評估需求,對重點時段、重點目標、重點海域的目標航跡數據進行篩選,提取出重點時間段重點海域的所有航跡數據,并提取其中的重點目標航跡數據。
第三步:剔除離群點。針對重點目標航跡數據,按照時間軸從前到后掃描每一行數據的經緯度和探測時間信息,采用基于鄰近性的方法判斷航跡點是否為錯誤的離群點,若是則記錄該離群點出現的時間、經緯度、目標屬性、探測源、目標批號等信息,并刪除該數據行。
第四步:重點時段、重點目標、重點海域數據的分類存儲。
第五步:針對重點目標航跡數據,綜合比對分析該時段內的目標真值數據,分析目標航跡數據的稀疏程度,分析目標航跡數據與真值航跡數據中時間戳相同的數據行的數量(因為后續在定位誤差等指標的計算中,要比對同一時刻的目標探測位置和目標真值位置,因此要保證時間戳相同的數據行達到一定數量,以確保參與計算的樣本量),設置閾值R,如果時間戳重合數據行數量少于R,則需要對目標航跡進行插值處理,如果時間戳數據行數量大于R,則無需作任何處理。
第六步:輸出數據。
5 試驗驗證
為驗證本文所提出算法的有效性,選取部分樣本數據,進行數據規范化和數據清洗。如圖3所示為選取樣本數據。樣本數據包括原始報文時間、站號、批號、經度、緯度、高度、航速、航向、入庫時間、目標種類、目標屬性、情報源等信息。
首先進行數據規范化處理,增加標識字段、刪除冗余字段、拆分復合字段,其次進行數據篩選,設置篩選條件為入庫時間從16:31:00至16:41:00,最后進行離群點剔除,得到如圖4所示的清洗結果數據。
原始數據中“原始報文時間”與“入庫時間”兩個字段分別被拆分為 “原始報文時間-時”、“原始報文時間-分”、“原始報文時間-秒”與“入庫時間-時”、“入庫時間-分”、“入庫時間-秒”字段。增加了“數據類型編號”、“數據所屬試驗號”等標識字段。篩選了重點時段數據,同時原來的第6條報文,因其經緯度位置嚴重偏離正常航跡,被檢測為離群點,記錄離群點信息并刪除該行數據。
試驗證明,本文提出的算法能夠實現對海空目標原始數據的規范和清洗,實現對數據的有效存儲。
6 結束語
為得到高質量的數據以備后續指標計算與效能評估,必須進行切實有效的清洗工作,消除數據中的冗余、缺失、離群點、不一致等問題。
隨著海軍海空目標探測體系內多型裝備的不斷發展,獲取的海空目標航跡數據在內容上將更加精細、規模上更加龐大,當前提出的數據清洗方法是為了解決當前多系統數據記錄不統一、不規范、不完整等問題,在后續工作中,應在裝備規劃之初,就充分考慮后續開展裝備效能評估的需要,規范各裝備數據記錄的內容、格式、量綱和導出環節等,以確保整個海空目標探測體系內數據記錄的整齊、統一。
參考文獻
[1] 郭逸重.Hadoop分布式數據清洗方案[D].廣州:華南理工大學,2012.
[2] 朱前磊.電子政務系統中海量數據清洗[D].上海:東華大學,2010.
[3] 范明,孟曉峰.數據挖掘概念與技術[M].北京:機械工業出版社,2010.
[4] 同濟大學數學系.高等數學[M].北京:高等教育出版社,2014.
[5] 王紅梅,胡明.算法設計與分析[M].北京:清華大學出版社,2013.endprint
