節點進行處理,比較節點中的中文字符數量。該方法雖利用了中文網頁的特性,實現簡單,健壯性強,但未考慮英文網頁,且對短正文網頁效果不理想。(4)基于視覺分塊的方法。
通常在瀏覽網頁時,人們往往將不同的功能區域看成不同的語義塊。較早的分塊方式是按照HTML的樹形結構進行[13],但隨著HTML的發展,僅僅依賴樹形結構,不足以滿足通用性。2003年,微軟亞洲研究院提出基于頁面視覺分塊的算法(VIsion-based Page Segmentation,VIPS),利用頁面的可視化信息在樹形結構的基礎上進行網頁分塊。然而它僅僅是一種分塊算法,利用已有的視覺信息,并未對頁面進行凈化操作,可以在算法的基礎上加入規則進行頁面凈化操作。文獻[14]通過修改VIPS算法迭代過程,在塊劃分后進行一系列的分隔條提取和語義塊重構,采用制定規則對頁面進行去噪操作。VIPS算法充分考慮了用戶的視覺習慣,但由于分隔條提取和語義塊重構需要過多的人工參與,復雜度較高,且缺乏對網頁中和信息的利用。
文中在VIPS算法分塊的基礎上,提出樣式樹,再根據鏈接比及樹路徑距離生成相應的權重樹,自動調整權重,根據權重進行剪枝操作,生成去噪頁面。
2 樣式樹定義
樣式樹由DOM樹演化而來[15],主要包含兩類虛擬節點:樣式節點(Style nodes)和元素節點(Element nodes)。樣式節點描述了節點布局或者展現風格,樣式節點A的表現樣式SA是一個序列。其中li是一個二元組(Tag,Styles)元素,通常Styles表示為{width:300,height:200,bg-Color:red},n表示樣式長度。節點E描述節點的屬性信息,表示為E(Tag,Attrs,Content),其中Tag表示節點標識,Attrs表示屬性信息,Content表示節點的文本信息。基本樣式樹如圖1所示。
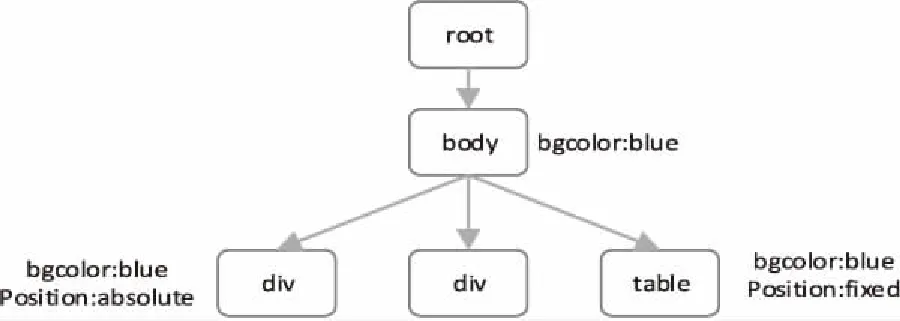
圖1 基本樣式樹
3 基于節點權重的網頁去噪算法
3.1算法基本思想
基于節點權重的去噪算法在VIPS基礎上,將VIPS生成的基本視覺塊樹進行樣式樹的轉化,利用樣式樹節點中的樣式特性,將葉子節點劃分成細粒度的樣式樹,再對樣式樹進行權重標注,根據權重標注進行剪枝,生成去噪頁面。基本流程如圖2所示。
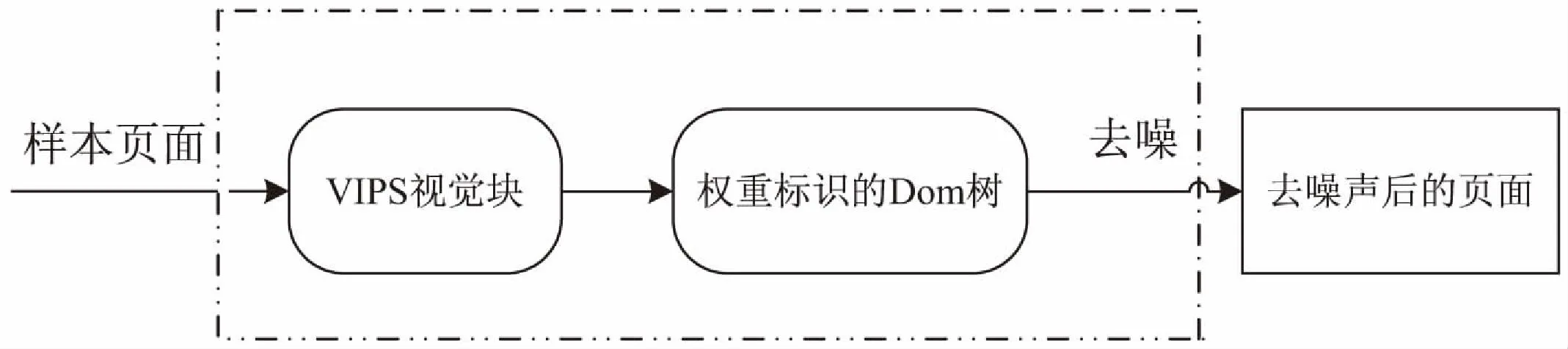
圖2 從樣本頁面到凈化頁面的總體流程
通常生成的樣式樹,無權重表示,在屬性節點的基礎上,引入權重節點的概念。權重節點T表示為QT,記為Q(k,d,t,m)。其中,k表示鏈接比,即當前節點中鏈接數占總鏈接數的比值;d表示樹路徑距離,即當前節點與容器節點在樹形結構上的距離;t表示文本比,即當前節點文本占總文本的比例;m表示節點私有屬性的權重系數。為了使H(Qi)的值落在[0,1]之間,使用節點的標簽個數n將H(Qi)歸一化。
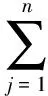
(1)
其中,ki表示第i個標簽的鏈接比;ti表示第i個標簽的文本系數;di表示第i個標簽的樹路徑距離;D表示權重樹中的節點路徑和。
3.2視覺塊樹細粒度化
通常,VIPS生成的視覺樹,只是初步提取了頁面的基本布局信息,粗粒度的視覺塊樹將噪聲和正文融合到了相同的塊中,必須進行細粒度化。此時對生成的樣式樹進行樣式節點和屬性節點的標注。對已經標注完的塊節點,進行子元素的相似度分析。子元素的樣式節點用二元組表示,屬性節點標識為E(Tag,Attrs,Content),由于li的Styles是以鍵值對的形式存在,在此將鍵值對轉化為樣式系數Ci,將塊標簽Tag表示為HTML中對應的NODE值,此時li表示為(Ti,Ci)。節點相似度判斷如下:
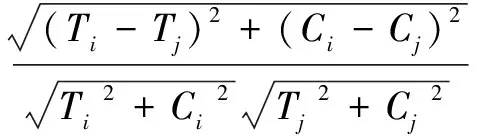
(2)
當相關系數較小時,將子節點進行分裂。采用自頂向下的層次遍歷方式,完成對視覺樹的初步分裂。
3.3細節樹剪枝
此時得到的是一棵基于樣式的視覺樹,在樣式和基本屬性上已經不可細分,在此基礎上進行噪聲的判斷。根據大量線上頁面的統計,噪聲區域往往有比正文區域更多的鏈接比,更少的文本比,以及更淺的樹距離。故此處引入權重節點的概念,對細粒度化的視覺塊樹進行自頂向下的標注,對權重低的節點進行剪枝操作。在初次遍歷的過程中,可進行一次簡單的預處理,對含有樣式樹節點中含有鍵值對display:none和position:fixed的節點進行刪除操作,前者是網頁中不做顯示的元素,后者是懸浮窗,據大量網頁的觀察,兩者都是判斷噪聲節點的重要依據。
剪枝算法描述如下:
(1)獲取樣式樹,設樣式樹為Ti;
(2)For(樣式樹的每個節點Qi)
(3)if(該節點的css屬性中含有position:fixed,display:none等鍵值對時) then
(4)刪除該節點;
(5)Else if
(6)計算出文本比,節點的距離深度,計算權重值H(Qi);
(7)For(樣式樹的每個節點QT);
(8)刪除平級節點中權重小的節點。
4 實 驗
4.1數據集
為了驗證文中算法的去噪效果,使用該算法對含有噪音的網頁進行處理。考慮到頁面抽取時信息獲取的客觀性,選取網易、新浪等頁面各200個,考研論壇等論壇型網頁200個,從網頁處理的整體效果出發,進行網頁去噪的實驗。
4.2評價指標
在實驗中,常見的評測指標有準確率和召回率。由于準確率和召回率介于[0,1]之間,而且不相互獨立。所以文中引入同時兼顧準確率和召回率的F1,即F-measure,作為綜合評價指標。
準確率為:
P=t0/t1
(3)
召回率為:
R=t0/t2
(4)
其中,t0表示當前頁面被抽取出的正文塊;t1表示當前頁面中全部的正文塊;t2表示被當做正文中抽取出來的信息塊。
由于在F-measure公式中β通常用來調節準確率和召回率的權重,而此處重點考慮的是網頁抽取的準確率和召回率,所以取β為1,最終用來判斷實驗效果的公式如下:
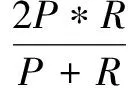
(5)
4.3實驗結果與分析
為了驗證文中算法,分別進行了兩組實驗,結果如表1和表2所示[16]。
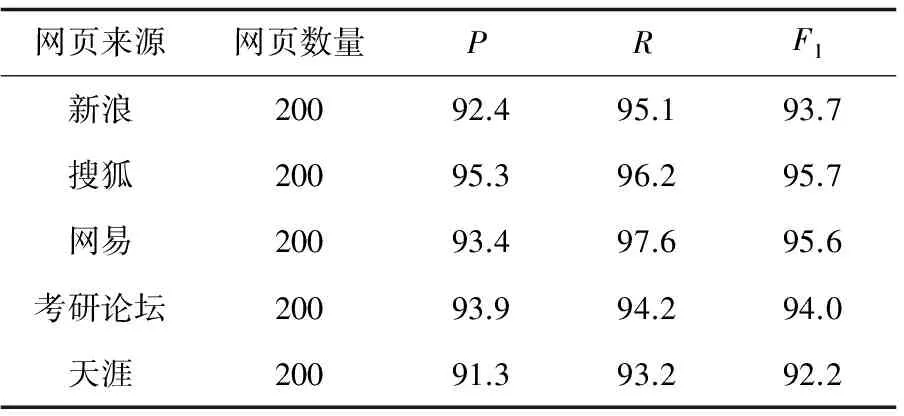
表1 文中算法
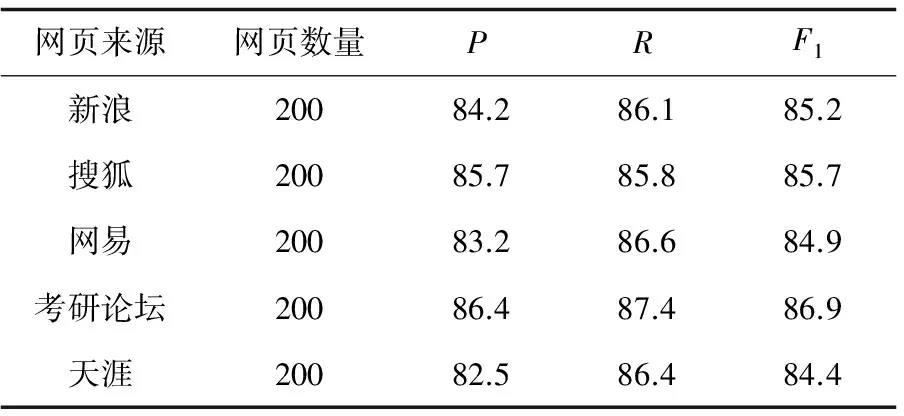
表2 基于行塊分布函數算法
從上述實驗可以看出,文中算法在準確率和召回率方面要優于基于行塊分布函數算法的頁面處理效果。基于行塊分布函數的方法雖然實現簡單,但是對去除標簽后的文本分塊的數量選取將直接影響網頁正文提取的準確率,而且去除標簽同時也去除了頁面中大量可用的視覺信息,當噪音文本與正文文本混雜時,將會被提取。文中充分考慮了頁面的視覺特征,在當前視覺元素豐富的網頁中,從網頁制作者的方向出發,利用大量的視覺特性,提取視覺系數,再利用正文內容特征,合理去除頁面中的噪音塊,使正文塊更易被識別。
5 結束語
文中在VIPS分塊的基礎上,引入了樣式樹的概念,取消了原有的基于視覺繁雜的啟發式的規則,只使用了VIPS粗粒度的視覺分塊,對粗粒度的視覺塊樹進行細粒度的劃分,進一步考慮了視覺塊之間的相關性,再對標注完權重的樣式樹進行去噪操作。實驗結果表明,該算法可以更好地去除頁面中導航欄等局部噪聲以及隱藏中正文塊的全局噪聲。該算法主要針對主題型頁面、論壇型頁面,但當正文內容和噪音內容相似度較高時,去噪效果不夠理想,這是該算法的局限性。在以后的研究中,將進一步分析這些網頁的特征,尋求改進方法,增強算法的健壯性。
[1] 歐石燕,唐振貴,蘇翡斐.面向信息檢索的術語服務構建與應用研究[J].中國圖書館學報,2016,42(2):32-51.
[2] Witten I H,Frank E.Data mining:practical machine learning tools and techniques[M].[s.l.]:Morgan Kaufmann Publishers Inc.,2011:206-207.
[3] 高 琪,張永平.超鏈接導向搜索算法中主題漂移的研究[J].計算機應用,2009,29(11):3100-3102.
[4] 劉華星,楊 庚.HTML5-下一代Web開發標準研究[J].計算機技術與發展,2011,21(8):54-58.
[5] 李效東,顧毓清.基于DOM的Web信息提取[J].計算機學報,2002,25(5):526-533.
[6] 胡金棟.網頁正文提取及去重技術研究[D].杭州:浙江大學,2011.
[7] 汪建偉,楊冬青,高 軍,等.一種基于分類算法的網頁信息提取方法[J].計算機科學,2008,35(3):91-93.
[8] 王 琦,唐世渭,楊冬青,等.基于DOM的網頁主題信息自動提取[J].計算機研究與發展,2004,41(10):1786-1792.
[9] 李文立,王樂超,宋春雷.基于HTML樹和模板的文獻信息提取方法研究[J].計算機應用研究,2010,27(12):4615-4617.
[10] Fu Y,Yang D,Tang S,et al.Using XPath to discover informative content blocks of web pages[C]//Proceedings of third international conference on semantics,knowledge and grid.[s.l.]:[s.n.],2007.
[11] 趙 文,唐建雄,高慶鋒.基于統計的中文網頁正文抽取的研究[J].電腦知識與技術,2008(1):120-123.
[12] 孫承杰,關 毅.基于統計的網頁正文信息抽取方法的研究[J].中文信息學報,2004,18(5):17-22.
[13] 劉晨曦,吳揚揚.一種基于塊分析的網頁去噪音方法[J].廣西師范大學:自然科學版,2007,25(2):149-152.
[14] 穆 瓊.基于視覺特征的網頁清洗研究與實現[D].北京:北京郵電大學,2013.
[15] Yi L,Liu B,Li X.Eliminating noisy information in Webpages for data mining[C]//Proceedings of the 9th ACMSIGKDD international conference on knowledge discovery and data mining.New York:ACM,2003:296-305.
[16] 高慶寧,吳 鵬,張晶晶.基于文檔對象模型與行塊分布算法的網頁信息抽取[J].情報理論與實踐,2016,39(4):133-137.
ResearchonWebPageDenoisingMethodBasedonNodeWeight
WANG Jian,ZHANG Jin
(College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
As the network information is increasing continuously,website information is not only an important information resource of users,but also important data source for data mining,information retrieval and other studies.To provide the text information with high quality,website denoising has become a nonnegligible step for webpage processing.With the continuous improvement of webpage making technology,visual elements in webpage are raised increasingly,and the information of webpage node becomes richer and richer.Visual information has been a nonnegligible and important part in webpage denoising.From a user’s point of view,the visual information can immediately reflect the importance of module in the page when browsing the web page.Traditional webpage denoising technology is neglected in the visual characteristics of webpage too much.Facing to the current complex webpage,the denoising effects are decreased greatly.Based on the comprehensive visual information and node information,a noise weight-based denoising method is proposed which fully considers the visual and content characteristics of nodes.The experimental results indicate that its accuracy rate and recall rate is improved to certain content.
vision characteristics;node weight;accuracy rate;recall rate
TP301
A
1673-629X(2017)10-0083-04
2016-11-15
2017-03-07 < class="emphasis_bold">網絡出版時間
時間:2017-07-19
教育部專項研究項目(2013116)
王 健(1991-),男,碩士,研究方向為大數據。
http://kns.cnki.net/kcms/detail/61.1450.tp.20170719.1110.056.html
10.3969/j.issn.1673-629X.2017.10.018
主站蜘蛛池模板:
偷拍久久网|
中文字幕在线视频免费|
91无码人妻精品一区|
午夜福利无码一区二区|
怡红院美国分院一区二区|
亚洲一区二区三区香蕉|
国产精品所毛片视频|
亚洲精品人成网线在线
|
99精品一区二区免费视频|
中文字幕在线观看日本|
日本道中文字幕久久一区|
欧美综合区自拍亚洲综合天堂|
亚洲免费毛片|
五月丁香在线视频|
美美女高清毛片视频免费观看|
老司机精品一区在线视频|
在线播放真实国产乱子伦|
久久夜色撩人精品国产|
免费看美女毛片|
免费99精品国产自在现线|
亚洲日韩AV无码一区二区三区人|
丁香五月婷婷激情基地|
日韩欧美国产综合|
亚洲一区二区三区国产精华液|
欧美一级夜夜爽|
亚洲成人免费在线|
久久特级毛片|
日韩午夜福利在线观看|
精品国产99久久|
综合网久久|
日本道综合一本久久久88|
美女一级毛片无遮挡内谢|
日本福利视频网站|
亚洲男女天堂|
国产特级毛片aaaaaaa高清|
欧亚日韩Av|
国产视频a|
国产真实二区一区在线亚洲|
欧美精品成人一区二区在线观看|
免费国产在线精品一区|
爆乳熟妇一区二区三区|
福利视频久久|
国产人妖视频一区在线观看|
亚洲熟女偷拍|
国产精品天干天干在线观看|
色欲不卡无码一区二区|
免费国产高清精品一区在线|
九九热视频在线免费观看|
青青青国产视频手机|
国产网站一区二区三区|
99re在线观看视频|
www.精品视频|
91精品国产麻豆国产自产在线|
欧美高清三区|
国产一区二区丝袜高跟鞋|
亚洲精品免费网站|
久久无码免费束人妻|
国产成人精彩在线视频50|
日本91在线|
国产在线一区二区视频|
日韩美女福利视频|
久久精品中文字幕少妇|
国产成在线观看免费视频|
无码日韩人妻精品久久蜜桃|
色有码无码视频|
真实国产乱子伦高清|
精品国产免费观看一区|
国产欧美自拍视频|
久久天天躁狠狠躁夜夜躁|
黄色一级视频欧美|
中文字幕日韩欧美|
中文字幕亚洲综久久2021|
久热re国产手机在线观看|
伊人无码视屏|
日本妇乱子伦视频|
国产91小视频在线观看|
精品色综合|
久久国产精品嫖妓|
欧美亚洲中文精品三区|
全午夜免费一级毛片|
国产一级毛片高清完整视频版|
成人91在线|
