分布式深度學習研究
2017-10-16 00:22:19辜陽楊大為
科技創新與應用 2017年29期
關鍵詞:深度學習
辜陽++楊大為
摘 要:傳統單機深度學習模型的訓練耗時,動輒花費一周甚至數月的時間,讓研究者望而卻步,因此深度學習并行訓練的方法被提出,用來加速深度學習算法的學習過程。文章首先分析了為什么要實現分布式訓練,然后分別介紹了基于模型并行和數據并行兩種主要的分布式深度學習框架,最后對兩種不同的分布式深度學習框架的優缺點進行比較,得出結論。
關鍵詞:深度學習;分布式訓練;模型并行;數據并行
中圖分類號:TP181 文獻標志碼:A 文章編號:2095-2945(2017)29-0007-02
1 概述
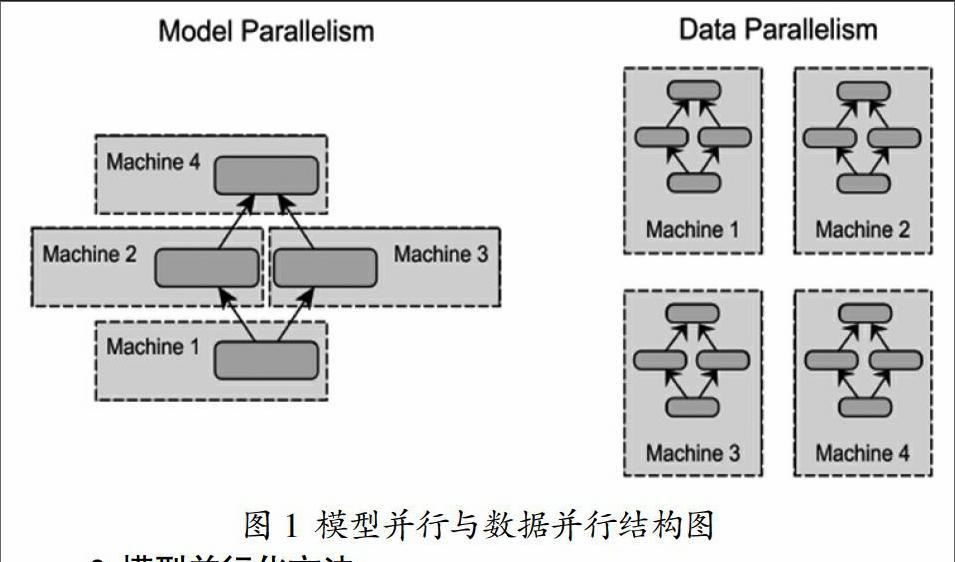
深度學習已經在計算機視覺,文本處理,自然語言識別等領域取得了卓越成就,受到學術界和工業界的廣泛關注。隨著對深度學習領域研究的深入,有證據表明增大模型參數規模和訓練數據集,能有效的提高模型精度。但精度提升同時也帶來了巨大的訓練時間成本。簡單的采用單機加GPU計算的方式,受限于目前GPU的顯存限制和單機擴展能力,已經不能滿足大型深層網絡結構和超TB大小的訓練集所要求的計算能力和存儲空間。針對上述問題,研究者投入了大量的工作,研究分布式深度學習訓練框架,來提升訓練效率。當前的分布式深度學習框架主要包含模型并行(model parallelism),數據并行(data parallelism)兩種方法,兩者的結構如圖1所示,左邊為模型并行結構,右邊為數據并行結構。
2 模型并行化方法
在模型并行化方法里,分布式系統中的不同機器節點負責單個網絡模型的不同部分計算。例如,卷積神經網絡模型中的不同網絡層被分配到不同的機器。每個機器只計算網絡結構的一部分,能夠起到加速訓練的效果。模型并行化適合單機內存容納不下的超大規模的深度學習模型,其具有良好的擴展能力,盡管在實際應用中的效果還不錯,但是在模型能夠在單機加載的情況下,數據并行化卻是多數分布式深度學習系統的首選,因為數據并行化在實現難度、容錯率和集群利用率方面都優于模型并行化,數據并行化方法適用于采用大量訓練數據的中小模型,具體介紹見第3小節。
3 數據并行化方法
在數據并行化方法里,分布式框架中的每個節點上都存儲一份網絡模型的副本,各臺機器只處理自己所分配到的一部分訓練數據集,然后在各節點之間同步模型參數,模型參數同步算法分為同步式和異步式兩種。
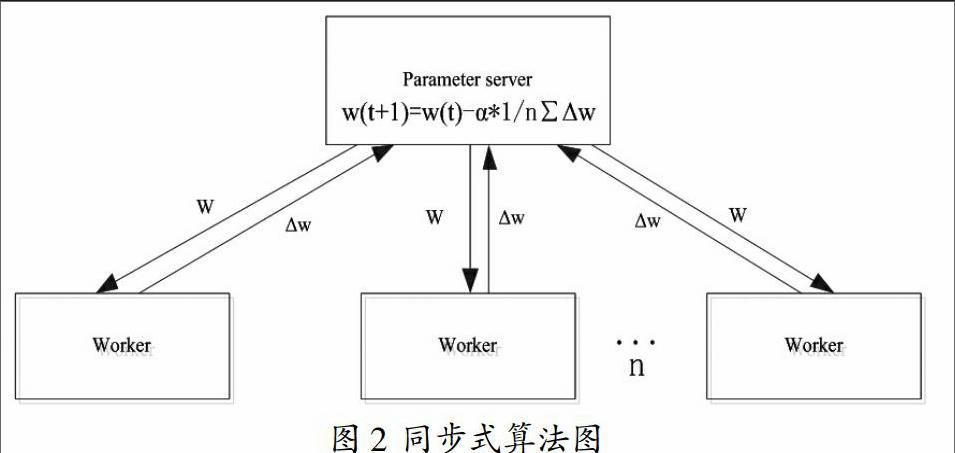
3.1 同步式算法
標準的同步式算法,每次迭代都分為三個步驟,首先,從參數服務器(Parameter Server,PS)中把模型參數w拉取(pull)到本地,接著用新的模型參數w計算本地mini-batch的梯度Δw,最后將計算出的梯度Δw推送(push)到PS。PS需要收集所有節點的梯度,再按照公式(1)進行平均處理更新模型參數,其中?琢為學習率。
雅虎開源的基于Spark平臺的深度學習包CaffeOnSpark就是采用的同步式算法,同步式算法如圖2所示。
這種強同步式算法,會由于系統中各個機器之間的性能差異,導致所有的節點都要等待計算最慢的一個節點執行完,產生木桶效應問題。而且大量的同步操作,造成的通訊時間開銷會限制同步式擴展能力,導致性能瓶頸。
3.2 異步式算法
異步隨機梯度下降算法(Asynchronous Stochastic Gradient Descent,ASGD)是對同步式算法的改進。參數服務器只要接收到一個節點的梯度值就進行更新,而不是等待所有節點發送完梯度值,再進行平均操作,消除了木桶效應問題,并且利用梯度的延遲更新,如迭代m次再進行同步,減少網絡通信量,降低網絡通訊造成的時間開銷,獲得明顯加速。文獻[1]證明算法是收斂的。
異步式算法比同步式訓練加速效果明顯,但帶來了一個新的問題,即梯度值過時問題。當某個節點算完了梯度值并且將其與參數服務器的全局參數合并時,全局參數可能已經被其他節點更新了多次,而此時傳遞過來的是一個已經過時的梯度值,會降低算法的收斂速率,達不到異步算法原本應有的加速效果,同時導致模型準確率下降。
異步隨機梯度下降方法有多種形式的變種,都采取了各種策略來減弱梯度過時所造成的影響,同時保持分布式深度學習訓練的高效率。解決梯度值過時的方法主要包括以下兩種:
(1)對每次更新的梯度Δw,引入縮放因子?姿,控制梯度過時對全局的影響。參數的更新形式為:
(2)
(2)采用弱同步(soft synchronization)策略[2],相對于立即更新全局參數向量,參數服務器等待收集n(1≤j≤n)個節點產生的s(1≤s≤m)次更新后,參數隨之按照公式(3)進行更新。若s=1,n=1;(3)式即為普通的異步隨機梯度下降算法。若s=m;即為異步隨機梯度下降法延遲更新。若s=1,n為所有的節點數,(3)式即為同步式算法。
這些改進方法相比簡單的異步算法都能有效降低梯度值過時的影響,提升算法的收斂性能。正是由于異步式明顯的加速優勢,當前熱門的分布式深度學習框架,如MXNet、TensorFlow、CNTK等大多采用異步隨機梯度下降算法及其變種。
4 結束語
同步式方法就每一輪epoch的準確率,以及全局的準確率來說更勝一籌,然而,額外的同步開銷也意味著這個方法的速度更慢。最大問題在于所謂的木桶效應問題:即同步系統需要等待最慢的處理節點結束之后才能進行下一次迭代。結果將會導致隨著工作節點的增加,同步系統變得越來越慢,越來越不靈活。
異步式算法是當前加速訓練模型的有效方法,在實際使用中也得到廣泛應用,只需要控制好梯度值過時的問題。但是帶有中心參數服務器的異步式算法仍然可能存在通訊瓶頸,還需要進一步研究解決存在的問題,充分發揮異步式的優勢。未來兩者的混合模型將是重點研究方向,使得分布式深度學習可以在大模型大訓練集上快速訓練,得到更加精準的模型。
參考文獻:
[1]Zinkevich M,Langford J,Smola A. Slow learners are fast[C]. Advances in Neural Information Processing Systems 22(NIPS 2009),2009:2331-2339.
[2]Wei Zhang,Suyog Gupta,Xiangru Lian,and Ji Liu. Staleness-aware async-sgd for distributed deep learning. IJCAI, 2016.
[3]張行健,賈振堂,李祥.深度學習及其在動作行為識別中的進展[J].科技創新與應用,2016(06):66.endprint
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
