基于代碼模式的軟件問答文檔檢索優化方法*
2017-10-12 03:40:10華晨彥鄒艷珍朱子驍
計算機與生活 2017年10期
關鍵詞:方法
華晨彥,鄒艷珍+,朱子驍,謝 冰
1.北京大學 信息科學技術學院,北京 100871
2.高可信軟件技術教育部重點實驗室,北京 100871
3.北京大學(天津濱海)新一代信息技術研究院,天津 300450
基于代碼模式的軟件問答文檔檢索優化方法*
華晨彥1,2,3,鄒艷珍1,2,3+,朱子驍1,2,3,謝 冰1,2,3
1.北京大學 信息科學技術學院,北京 100871
2.高可信軟件技術教育部重點實驗室,北京 100871
3.北京大學(天津濱海)新一代信息技術研究院,天津 300450
Abstract:Developers often need to search related software Q&A documents in Q&A website.In the search results,the Q&A documents which contain good code snippets(usage examples)are preferred.However,how to metric those code snippets in document is still a big challenge.To address this issue,this paper proposes an approach for refining software Q&A document search results based on code pattern.Firstly,code snippets are extracted from each document in the search results.Then,the common code patterns are mined and used to measure the quality of those code snippets.Finally,the documents with high quality are recommended and ranked at the top of the search results.In the experiments,this paper carries out some evaluations with 10 real problems that software developers meet in practice.Compared to the search results of StackOverflow,the proposed approach has an increment of 40%atNDCG@5.
Key words:code pattern;software Q&Adocument;document search
開發人員通常通過問答網站的搜索引擎進行相關軟件問答文檔的搜索。在檢索結果中,包含優質代碼片段(使用示例)的問答文檔往往更受青睞,但如何度量這些文檔中代碼片段的質量仍是個巨大的挑戰。針對這個問題,提出了一種基于代碼模式的軟件問答文檔檢索優化方法。該方法能夠基于當前檢索結果,抽取文檔中的代碼片段,分析代碼片段中的公共代碼模式,并基于代碼模式度量文檔中代碼片段的質量,從原有檢索結果中向用戶推薦高質量的軟件問答文檔。以軟件開發人員在實踐過程中遇到的真實問題為基礎進行了實驗,對比StackOverflow的搜索結果,所提方法在準確率指標NDCG@5上提升了40%。
代碼模式;軟件問答文檔;文檔檢索
1 引言
近年來,各類技術性問答網站(如StackOverflow等)受到了開發者們的喜愛,這些問答網站上產生了大量的軟件問答文檔。如何檢索和利用這些軟件問答文檔成為軟件復用領域一個非常重要的研究問題。
很多研究者針對軟件問答文檔檢索問題進行了研究[1-2],主要關注點是對檢索結果進行優化和重排序[3]。例如,Atwood[4]使用StackOverflow的基于軟件問答文檔元數據的檢索結果排序方法。該方法通過軟件問答文檔的閱讀量、回答數量、贊同數量等指標綜合計算每篇文檔的得分,按得分的高低對檢索結果進行排序。Ponzanelli等人[5]設計并實現了一個Eclipse插件PROMPTER。PROMPTER以代碼片段作為查詢的輸入,考慮了文本相似度(使用tf-idf)、代碼相似度(代碼克隆)、API(application programming interface)類型相似度、API方法相似度等參數,加權平均決定軟件問答文檔的最終得分。Williams等人[6]提出了基于遞歸偽相關反饋策略的相似文檔檢索方法。對于給定查詢的結果列表R,對R的前k篇文檔遞歸進行檢索,通過遞歸檢索的結果反饋評價原始結果,從而優化檢索結果。Cha等人[7]提出了基于主題模型的文檔檢索優化方法,使用LDA(latent Dirichlet allocation)主題模型給每篇文檔計算一個主題分布,根據查詢與每個主題的相關程度確定文檔在檢索結果中的排名位置。Zou等人[8]提出的面向軟件的文本檢索方法將問題分為6種類別,依據檢索問題與檢索結果是否屬于同一類別對檢索結果進行重排序。
從這些工作可以看出,如何挑選或推薦高質量的檢索結果是當前軟件問答文檔檢索優化的主要目標。本文在調研中發現,軟件問答文檔中包含大量的代碼示例片段,包含代碼片段的問答文檔質量較高,可以更好地幫助開發者了解或解決遇到的問題。但是由于不同文檔討論不同的問題,其針對的開發任務不同,并且問答文檔由不同的人編寫,其編碼的語言、風格也大不相同,如何度量檢索結果文檔中代碼片段的質量以及如何進行檢索結果重排序仍是個巨大的挑戰。
為此,本文提出了一種基于代碼模式的軟件問答文檔檢索優化方法。該方法從解決相同/相似開發任務的軟件問答文檔的代碼片段中,抽取公共的代碼模式,通過代碼模式度量代碼片段和軟件問答文檔的質量,由此通過檢索結果重排序向用戶推薦高質量的軟件問答文檔。
與現有工作相比,本文的主要貢獻包括:
(1)定義了一種面向開發任務的軟件代碼使用模式,并提出了基于數據流圖的代碼模式挖掘方法。
(2)提出了一種基于代碼模式的軟件問答文檔檢索優化方法。通過代碼模式度量代碼片段和軟件問答文檔的質量,給每篇問答文檔一個評分,并結合該文檔在原有檢索結果中的排序進行檢索優化。
(3)實現并開源了一個基于代碼模式的軟件問答文檔推薦工具。以10個軟件開發人員在實踐過程中遇到的真實問題為基礎進行了實驗,對比了Stack-Overflow的搜索結果,本文工作在準確率指標NDCG@5上提升了約40%。
本文組織結構如下:第2章介紹了代碼模式的定義和作用;第3章詳細討論了基于代碼模式的軟件問答文檔檢索優化方法;第4章通過實驗驗證了方法的有效性;第5章對本文工作進行了總結。
2 代碼模式
一般來說,軟件問答文檔的來源可分為兩類:軟件項目官網與技術性問答網站。軟件項目官網的軟件問答文檔由軟件項目的開發人員撰寫,準確度高,結構簡單,通常采用一問一答的形式,但數量少,覆蓋面狹窄;技術性問答網站的軟件問答文檔數量巨大,且為大量開發人員在實踐過程中總結出的經驗教訓,覆蓋面廣,實用性高。在這兩類問答文檔中,為了更好地幫助提問者理解回答或解決問題,回答者一般都會在答案中附上相應的代碼片段。研究表明,在StackOverflow上的軟件問答文檔中,包含代碼片段的文檔數量約占總文檔數量的50%!這些代碼片段可能是回答者針對這一問題給出的,或是其曾經開發過的項目中與該問題相關的代碼片段。
在討論相同/相似問題的軟件問答文檔中,代碼片段(使用示例)往往調用相同的API方法,或包含一些共同的語句、方法調用、控制結構,本文將這些共性稱為開發任務的代碼模式(code pattern)。對于簡單的開發任務,這些API可能為單個對象的若干方法順序執行,然而對于復雜的任務,便會涉及多個對象互相交互,還可能包含復雜的控制結構。圖1展示了兩個StackOverflow文檔體現的代碼模式(加粗高亮表示的部分)。該模式是使用JDK的Scanner讀取文件的常用模式。
在問答文檔檢索過程中,這些面向開發任務的代碼模式將帶來如下益處:(1)可以度量文檔中代碼片段的質量,過濾不完整或不準確的示例代碼;(2)可以解決文檔檢索中的模糊性問題,如提問者對問題的理解存在偏差,提問者的問題過于特化等情況。在圖1包含代碼模式的兩篇文檔中,其中文檔1[9]的開發任務是輸出給定文件中所有符合特定條件的行,文檔2[10]的開發任務是讀取csv格式的文件。通過代碼模式的抽取,用戶在檢索“Scanner read file”時也可以定位到它們。

Fig.1 Code pattern of reading file using“Scanner”圖1 使用Scanner讀取文件的代碼模式
3 基于代碼模式的軟件問答文檔檢索優化方法
本文提出了一種基于代碼模式的軟件問答文檔檢索優化方法。如圖2所示,該方法主要分為三部分:
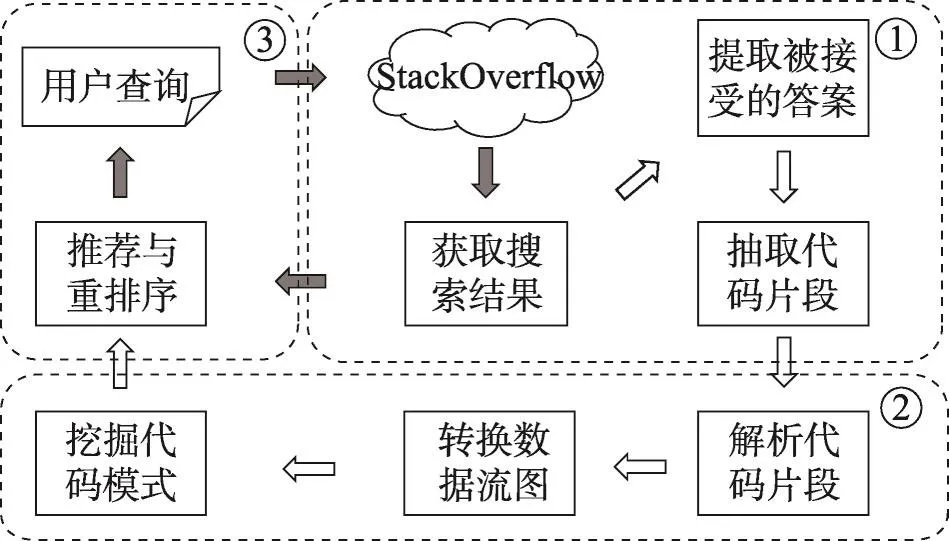
Fig.2 Framework of refining software Q&Adocument search results based on code pattern圖2 基于代碼模式的軟件問答文檔檢索優化方法框架
(1)檢索結果的獲取與解析。根據用戶的查詢獲取與查詢相關的軟件問答文檔,并解析出其中的代碼片段。
(2)代碼模式的抽取。將代碼片段轉換為數據流圖,通過頻繁子圖挖掘算法,在這些數據流圖中挖掘出代碼模式。
(3)檢索結果的優化。通過代碼模式給每一篇軟件問答文檔一個評分,將所有的軟件問答文檔按評分高低重排序,推薦給用戶。
3.1 檢索結果的獲取與解析
本文的軟件問答文檔數據來源于StackOverflow,根據用戶的查詢,使用StackOverflow的搜索API進行在線搜索,并將結果下載至本地,便于后續的解析與處理。StackOverflow的軟件問答文檔為HTML格式。HTML使用標簽表明文檔的內容,依據嵌套關系表明文檔的層次結構,通過特定的標簽即可解析出文檔中的代碼片段。
3.2 代碼模式的抽取
本文使用數據流圖(data flow graph)表示代碼模式。使用數據流圖存在以下兩個優點:一是在面向對象語言開發過程中,開發者常常遇到多個對象需要互相協作的場景[11],使用數據流圖可以有效地梳理這種交織關系;二是開發者對代碼元素的命名有著各自的喜好,而代碼元素的命名不會影響代碼實現的功能。數據流圖只關心每條語句的輸入來源與輸出去向,可以有效地過濾代碼元素命名帶來的干擾。
建立數據流圖需要變量的定值-使用關系,該信息可以通過靜態單賦值形式的控制流圖獲得。然而Java語法復雜,抽象語法樹的結點類型較多,難以直接轉換為控制流圖,并且不同開發人員實現相同功能的代碼可能使用了不同的語法,存在偏好差異,導致生成了不同的數據流圖,最終無法抽取出代碼模式。為此,需要先將Java語言的代碼片段通過中間代碼表示,再進行后續操作。
(1)解析代碼片段。在前文中提到不同開發人員在代碼編寫過程中存在偏好差異,本文通過解析代碼片段,并使用中間代碼表示(intermediate representation,IR)的方式消除這些差異。
現有Java語言的中間代碼生成工具只能應用于完整的Java項目,無法處理代碼片段。因此,本文設計與實現了一個Java語言的中間代碼生成工具。IR的設計主要有兩點:一是能與原語法相對應;二是便于進一步處理。在本文的IR設計中,產生式主要分為塊級與語句級兩個層次。塊級產生式對應于控制流圖中的基本塊,便于轉換為控制流圖;語句級產生式對應于一條語句,也是數據流圖的結點。語句級產生式均為變量賦值的形式,便于定值-使用分析。
(2)轉換數據流圖。本文使用靜態單賦值形式(static single form,SSA)的控制流圖來獲取與建立數據流圖所需要的變量定值-使用關系。
從中間代碼表示轉換至流圖只需要針對控制流語句在相應結點之間添加邊即可。
將控制流圖轉換為SSA形式的關鍵就是對每個變量的定值添加版本號,在其支配邊界處添加φ函數,并相應地更新所有使用的版本號。計算支配邊界先使用Lengauer-Tarjan算法[12]計算出直接支配結點,再通過直接支配結點計算支配邊界[13]。
將靜態單賦值形式的流圖轉換成數據流圖只需要對應每一個變量的定值結點、連邊至其所有的使用即可。
(3)挖掘代碼模式。本文將代碼模式表示為數據流圖后,該問題便可轉換為頻繁子圖挖掘問題。
頻繁子圖挖掘(frequent subgraph mining)[14]是數據挖掘領域的熱門問題之一,基于頻繁子圖挖掘可以發現大量圖數據中的公共模式。簡單地說,給定一個圖,頻繁子圖挖掘的目的就是找出其中出現最頻繁的子圖。頻繁子圖挖掘的常見應用場景包括化合物結構、社交網絡等。給定圖的集合S={G1=(V1,E1),G2=(V2,E2),…,Gn=(Vn,En)},頻繁子圖挖掘的完整定義如下。
定義1(圖的大小)任意給定一個圖G=(V,E),稱G的大小為|V|,記為size(G)。
定義2(子圖)如果?Gi=(Vi,Ei),Gj=(Vj,Ej),Vi?Vj,Ei?Ej,則稱Gi包含于Gj,或Gi是Gj的子圖,記為Gi?Gj。
定義3(支持度)任意給定一個圖G,稱G的支持度為|{g|g∈S且G是g的子圖}|,記為support(G)。
定義4(頻繁子圖)圖的集合S的所有頻繁子圖為{g|size(g)≥fsize且support(g)≥fsupport},其中fsize和fsupport是事先給定的閾值。
gSpan算法[15]是一種基于模式增長的頻繁子圖挖掘算法。其核心思想是對圖進行dfs編碼和最右擴展,通過最小dfs編碼判斷同構。由頻繁子圖的定義可知,若圖G1是頻繁子圖,G2?G1,那么G2也是頻繁子圖。然而對于代碼模式而言,G2的代表性嚴格劣于G1,因此本文刪除了這些冗余的結果。
3.3 檢索結果的優化
軟件問答文檔中代碼片段包含的代碼模式數量越多,該文檔越具有代表性。然而代碼片段的長度會影響其包含的代碼模式數量。因此本文提出了兩個評價軟件問答文檔質量的方法。
(1)依據每篇軟件問答文檔被接受的答案中的代碼片段包含的代碼模式數量作為評分依據。使用公式表述為:

(2)依據每篇軟件問答文檔被接受的答案中代碼片段數據流圖中屬于代碼模式的結點數量與總結點數量的比值作為評分依據。使用公式表述為:
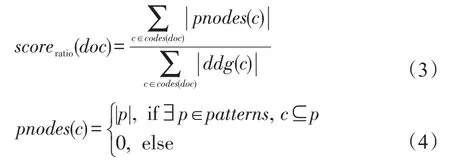
其中,codes(doc)表示文檔doc中的代碼片段集合;ddg(c)表示代碼片段c的控制流圖;patterns為挖掘出的代碼模式集合。
最終的推薦結果依據文檔的評分,評分越高的文檔,排序越靠前。
4 實驗與案例研究
基于上述工作,本文設計并實現了一個軟件問答文檔推薦工具。該工具目前已經在github上進行開源(https://github.com/woooking/qa_sorting)。下面將以軟件開發人員遇到的實際問題為例,說明推薦方法的實現過程和效果。
4.1 實驗數據
為了檢驗本文工作,收集了10個軟件人員在開發過程中遇到的問題。表1描述了這10個問題對應的開發任務及其在StackOverflow檢索時輸入的查詢條件。譬如,第一行描述了某軟件開發人員現有一個開發任務是完成某個網絡游戲的后臺。經過團隊協商決定使用TCP協議進行網絡傳輸,但是他并不知道如何創建一個TCP服務器。因此,使用“create tcp server”作為查詢條件在StackOverflow上進行檢索,希望得到與創建TCP服務器相關的問答文檔。

Table 1 Queries used in experiment表1 實驗所用查詢
對于每個查詢,本文從StackOverflow上獲取文本相關性排名前10的軟件問答文檔。將這些文檔打亂順序交由提出查詢的軟件開發人員為這些文檔打分,分數范圍是1~5分,評分依據為該文檔是否可以解決軟件開發人員的問題。
4.2 案例研究
任務1在StackOverflow上的檢索結果如表2(左側)所示。可以看到,檢索結果中排名第一位的文檔評分只有1分;前3個檢索結果中只有一個文檔的評分為5分;而前5個檢索結果中也只有一個文檔的評分為5分。這樣的檢索結果將耗費用戶大量的時間用于文檔瀏覽,降低用戶的檢索體驗。
基于上述檢索結果,本文從排名前10的包含被接受答案與代碼片段的文檔中總共提取出20段代碼片段。解析這20段代碼片段,并將其轉換為數據流圖。在這20個數據流圖中進行頻繁子圖挖掘,挖掘算法中的閾值fsize和fsupport均設為3,總共挖掘出3個代碼模式。圖3展示了其中的一個代碼模式。
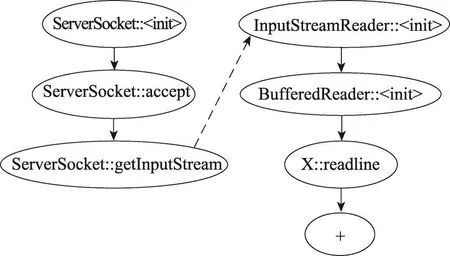
Fig.3 Acode pattern example of“create tcp server”圖3 create tcp server的代碼模式
依據代碼模式,本文對每一篇問答文檔中的代碼片段進行評分,評分依據為文檔中代碼片段包含的代碼模式的數量。由此對檢索結果進行重排序,推薦結果如表2(右側)所示。可以看到,檢索結果中排名前4的文檔都為5分,排名第5的文檔也有4分。這樣的檢索結果可以幫助用戶準確快速地定位至高質量的軟件問答文檔。通過對比可以發現,本文推薦方法可以有效地幫助軟件開發人員解決問題。
4.3 對比實驗
為了更好地驗證本文工作,對上述10組檢驗結果分別進行了分析。為了評價推薦結果的好壞,本文選取了信息檢索中常用的指標之一NDCG@k[16]。該指標的計算公式如下:
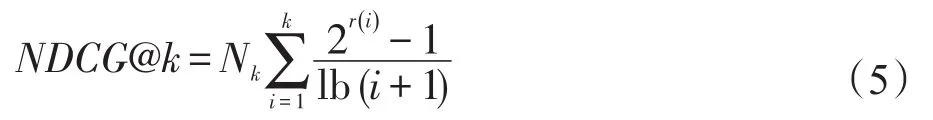
其中,r(i)表示排在結果第i位的項與查詢的相關程度,r(i)越高,相關程度越大。在本文中相關程度共分為5級,最高為4,最低為0;Nk是歸一化參數,它使得在最佳排序(即r(i)為降序)時,NDCG@k的值為1。
本文選取NDCG@k作為評價指標的理由為:
(1)軟件開發人員只有閱讀高質量的文檔才能解決開發問題,因此在評價指標中需要體現出高質量的文檔比低質量的文檔對結果的影響性更大。在NDCG@k的公式中,指數位的r(i)體現了這一點。
(2)高質量文檔在推薦結果中的位置十分重要。在NDCG@k的公式中,體現了這一點,結果越靠后的文檔被開發者閱讀的幾率越低,對排序結果的影響也就越低。
在實驗過程中,本文對比了4種問答文檔檢索/推薦方法。
(1)StackOverflow:該站點的原始搜索結果。
(2)pattern_ratio:依據代碼模式結點數與代碼片段結點數的比例評價文檔質量。
(3)pattern_count:依據代碼片段包含的代碼模式數量評價文檔質量的評分。
(4)replace:僅對包含被接受答案與代碼片段的文檔使用pattern_count方式評分,其余文檔的位置保持不變。
實驗結果如圖4所示。對比上述4種方法的結果可以發現:整體而言,pattern_count方法的效果最佳。相比于StackOverflow的原始結果,pattern_count方法在NDCG@1(只看第一名)上從60.8%提升至83.3%,在NDCG@5(第一名到第五名)上從52.8%提升至75.1%,提升幅度為40%左右。pattern_ratio的效果略遜色于pattern_count。經過分析發現,回答者在回答問題時給出的代碼片段往往來源于其曾經寫過的某個項目,因此會包含一些冗余代碼,這些代碼無法構成代碼模式,但也不會影響文檔的質量。而pattern_ratio依據代碼模式結點數與代碼片段結點數的比例評價文檔質量,因此會降低此類文檔的評分。
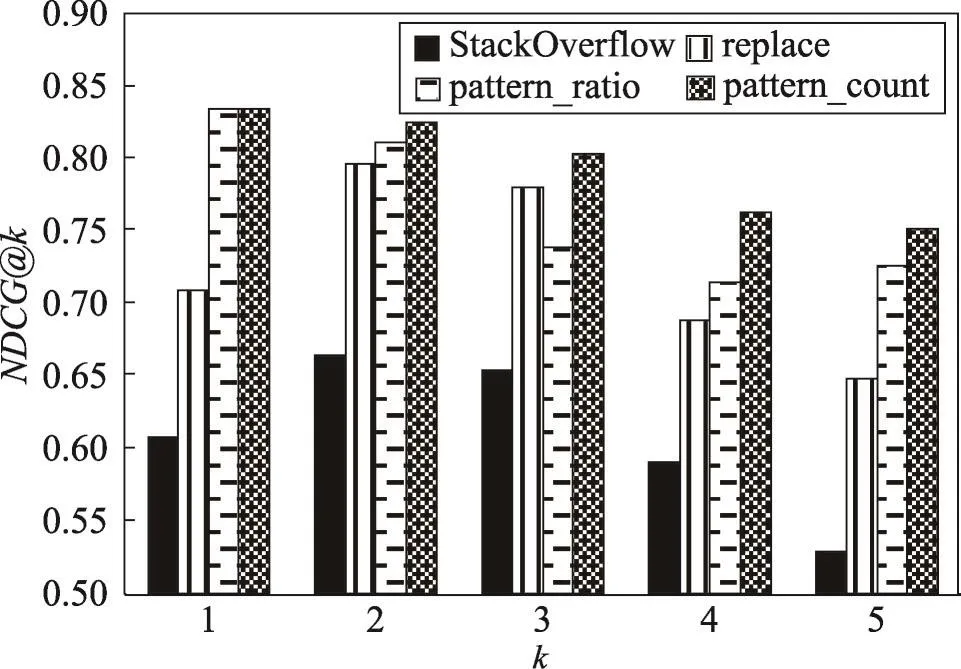
Fig.4 Result of experiment圖4 實驗結果
因為本文提出的軟件問答文檔檢索優化方法基于軟件問答文檔中的代碼片段,所以最終的推薦結果只包含代碼片段。為了驗證本文方法獲得的效果提升不僅僅是因為推薦了包含代碼片段的文檔,可以對比replace和StackOverflow兩種方法。replace與StackOverflow的文檔排序區別僅在于包含代碼片段的文檔,在結果中,replace比StackOverflow在k=1至5時均有提升,因此可以證明本文方法獲得的效果提升不僅僅是因為推薦了包含代碼片段的文檔,而是基于代碼模式的軟件問答文檔度量方法的確有效。
5 總結
為了在檢索過程中幫助用戶更快地找到包含優質示例代碼的相關文檔,本文提出了一種基于代碼模式的軟件問答文檔推薦方法,并以10個開發人員實際遇到的問題為基礎進行了實驗,驗證了本文方法的有效性。在未來工作中,將考慮加入更多來源、類型的軟件文檔數據,以提升本文方法的適用性;進一步改進代碼模式挖掘方法,使得檢索系統能更快、更準確地理解軟件問答文檔中的代碼片段。
[1]Wang Xiaoling,Wen Jirong,Luan Jinfeng,et al.A method to query document database by content and structure[J].Journal of Software,2003,14(5):976-983.
[2]Ye Ting,Xie Bing,Zou Yanzhen,et al.Interrogative-guided re-ranking for question-oriented software text retrieval[C]//Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering,Vasteras,Sweden,Sep 15-19,2014.New York:ACM,2014:215-220.
[3]Huang Zhenhua,Zhang Jiawen,Tian Chunqi,et al.Survey on learning-to-rank based recommendation algorithms[J].Journal of Software,2016,27(3):691-713.
[4]Atwood J.What formula should be used to determine“hot”questions?[EB/OL].(2008)[2016-07-18].http://meta.stackexchange.com/questions/11602/what-formula-should-beused-to-determine-hot-questions.
[5]Ponzanelli L,Bavota G,Di Penta M,et al.Mining Stack-Overflow to turn the IDE into a self-confident programming prompter[C]//Proceedings of the 11th Working Conference on Mining Software Repositories,Hyderabad,India,May 31-Jun 1,2014.New York:ACM,2014:102-111.
[6]Williams K,Giles C L.Improving similar document retrieval using a recursive pseudo relevance feedback strategy[C]//Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries,Newark,USA,Jun 19-23,2016.New York:ACM,2016:275-276.
[7]Cha M S,Kim S Y,Ha J H,et al.Topic model based approach for improved indexing in content based document retrieval[J].International Journal of Networked and Distributed Computing,2016,4(1):55-64.
[8]Zou Yanzhen,Ye Ting,Lu Yangyang,et al.Learning to rank for question oriented software text retrieval(T)[C]//Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering,Lincoln,USA,Nov 9-13,2015.Washington:IEEE Computer Society,2015:1-11.
[9]Java scanner class help[EB/OL].(2011)[2016-07-18].http://stackoverflow.com/questions/3947761/java-scanner-class-help.
[10]Why does scanner read every other line of CSV file?Java[EB/OL].[2016-07-18].http://stackoverflow.com/questions/36564422/why-does-scanner-read-every-other-line-of-csvfile-java.
[11]Nguyen T T,Nguyen H A,Pham N H,et al.Graph-based mining of multiple object usage patterns[C]//Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering,Amsterdam,Aug 24-28,2009.New York:ACM,2009:383-392.
[12]Lengauer T,Tarjan R E.A fast algorithm for finding dominators in a flowgraph[J].ACM Transactions on Programming Languages and Systems,1979,1(1):121-141.
[13]Cytron R,Ferrante J,Rosen B K,et al.Efficiently computing static single assignment form and the control dependence graph[J].ACM Transactions on Programming Languages and Systems,1991,13(4):451-490.
[14]Inokuchi A,Washio T,Motoda H.An Apriori-based algorithm for mining frequent substructures from graph data[C]//LNCS 1910:Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery,Lyon,France,Sep 13-16,2000.Berlin,Heidelberg:Springer,2000:13-23.
[15]Yan Xifeng,Han Jiawei.gSpan:graph-based substructure pattern mining[C]//Proceedings of the 2002 IEEE International Conference on Data Mining,Maebashi City,Japan,Dec 9-12,2002.Washington:IEEE Computer Society,2002:721-724.
[16]J?rvelin K,Kek?l?inen J.Cumulated gain-based evaluation of IR techniques[J].ACM Transactions on Information Systems,2002,20(4):422-446.
附中文參考文獻:
[1]王曉玲,文繼榮,欒金鋒,等.一種通過內容和結構查詢文檔數據庫的方法[J].軟件學報,2003,14(5):976-983.
[3]黃震華,張佳雯,田春岐,等.基于排序學習的推薦算法研究綜述[J].軟件學報,2016,27(3):691-713.
Refine Software Q&ADocument Search Results Based on Code Pattern*
HUAChenyan1,2,3,ZOU Yanzhen1,2,3+,ZHU Zixiao1,2,3,XIE Bing1,2,3
1.School of Electronics Engineering and Computer Science,Peking University,Beijing 100871,China
2.Key Laboratory of High Confidence Software Technologies,Ministry of Education,Beijing 100871,China
3.Peking University Information Technology Institute(Tianjin Binhai),Tianjin 300450,China




A
TP301
+Corresponding author:E-mail:zouyz@pku.edu.cn
HUA Chenyan,ZOU Yanzhen,ZHU Zixiao,et al.Refine software Q&A document search results based on code pattern.Journal of Frontiers of Computer Science and Technology,2017,11(10):1591-1598.
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2017/11(10)-1591-08
10.3778/j.issn.1673-9418.1609028
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
*The National Key Research and Development Program of China under Grant No.2016YFB1000804(國家重點研發計劃);the National Science Fund for Distinguished Young Scholars of China under Grant No.61525201(國家杰出青年科學基金).
Received 2016-08,Accepted 2016-10.
CNKI網絡優先出版:2016-10-31,http://www.cnki.net/kcms/detail/11.5602.TP.20161031.1652.024.html
HUA Chenyan was born in 1994.He is an M.S.candidate at Peking University.His research interest is software engineering.
華晨彥(1994—),男,上海人,北京大學碩士研究生,主要研究領域為軟件工程。
ZOU Yanzhen was born in 1976.She received the Ph.D.degree in software and software theory from Peking University in 2010.Now she is an associate professor at Peking University,and the member of CCF.Her research interests include software engineering,software reuse and information retrieval,etc.
鄒艷珍(1976—),女,遼寧蓋州人,2010年于北京大學軟件與理論專業獲得博士學位,現為北京大學信息科學技術學院副教授,CCF會員,主要研究領域為軟件工程,軟件復用,信息檢索等。
ZHU Zixiao was born in 1990.He is a Ph.D.candidate at Peking University.His research interests include software engineering,software comprehension and reuse,etc.
朱子驍(1990—),男,湖南郴州人,北京大學博士研究生,主要研究領域為軟件工程,軟件資源理解與復用等。
XIE Bing was born in 1970.He received the Ph.D.degree from School of Computer,National University of Defense Technology in 1998.Now he is a professor and Ph.D.supervisor at Peking University,and the senior member of CCF.His research interests include software engineering and formal methods,etc.
謝冰(1970—),男,湖南湘潭人,1998年于國防科技大學計算機學院獲得博士學位,現為北京大學信息科學技術學院軟件所教授、博士生導師,CCF高級會員,主要研究領域為軟件工程,形式化方法等。發表學術論文40余篇,主持國家863重點項目多項,獲國家科技進步二等獎。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
