探索商業銀行在大數據挖掘技術領域的應用
2017-09-23 03:02:07羅素文孫元浩
計算機應用與軟件 2017年9期
羅素文 韓 路 許 勤 孫元浩
1(中國銀行股份有限公司上海市分行 上海 200233)2(星環信息科技(上海)有限公司 上海 200233)
探索商業銀行在大數據挖掘技術領域的應用
羅素文1韓 路1許 勤1孫元浩2
1(中國銀行股份有限公司上海市分行 上海 200233)2(星環信息科技(上海)有限公司 上海 200233)
由于大數據的快速發展,傳統的以業務經驗模式進行的數據庫營銷面臨極大挑戰。針對這種情況,提出基于大數據的數據挖掘技術方法。首先了解業務需求,根據業務目標設計模型,接著進行數據整合、數據清洗等,最后建立模型、對模型結果進行評估。實驗結果表明,應用大數據挖掘技術能有效提高精準營銷的成功率,進行風險防控以及運營優化管理。
大數據 數據挖掘 精準營銷 風險防控 運營優化
0 引 言
隨著大數據時代的到來,商業銀行數據資產的價值也愈發重要。為此,探索數據的應用場景和商業模式,建立技術平臺,推動商業銀行從傳統數據庫營銷到數據化運營,最終到運營數據的轉變,成為各家商業銀行重點工作。筆者所在的銀行依托分行大數據平臺,致力于大數據+人工智能+數據挖掘的探索與研究。從2014年就啟動了數據挖掘的相關工作,開發了卡分期模型、信用卡疑似套現評分模型、信用卡客戶流失預警模型、信用卡逾期預警模型、網點選址優化模型、大額存單交叉營銷模型、中高端客戶流失預警模型等。下面就精準營銷、風險預警、運營優化三個主要應用場景介紹近三年運用大數據挖掘技術建模實踐的成效。
1 精準營銷
我行基于大數據平臺豐富的數據來源及高效的分布式計算技術,通過邏輯回歸、決策樹、神經網絡、支持向量機等機器學習算法,結合業務目標進行分析挖掘、構建模型、制定精準營銷方案與策略。下面以大額存單交叉銷售模型和信用卡賬單分期模型為例簡要介紹建模方法及收效。
1.1 大額存單交叉銷售模型
個人大額存單產品自推廣以來,維持了較高的存款貢獻與客戶層級上升貢獻,是分行應對同業競爭、拓展存款和客戶的技術手段和措施。為更好地推動大額存單客戶群的維護與拓展,爭攬客戶行外資金,亟需通過該交叉銷售模型找出高響應的客戶進行大額存單精準營銷活動。
1.1.1 建模樣本及目標變量定義
建模樣本定義為資產5萬~100萬的客戶,模型的目標變量定義為首次購買大額存單的客戶。時間窗口定義:觀察期,6個月,表現期,3個月,經統計分析,樣本的目標變量過少。為此,我們將兩個觀察期和表現期的數據分布疊加起來,重新整合樣本后進行建模。
1.1.2 數據預處理
源數據來自客戶基礎屬性、客戶持有產品、客戶交易行為、客戶基礎屬性變化、客戶持有產品變化、貸款信息、代發薪信息、跨行轉賬信息等數據。數據預處理主要包括變量衍生、異常值檢驗及處理、缺失值檢驗及處理三個部分組成。
變量衍生:指根據業務的一些經驗值和數據分析結果,主要針對客戶交易行為衍生了分渠道、分產品每月的交易金額最大值、均值、最小值及每個產品和渠道對應的交易趨勢等變量。
異常值檢驗及處理:異常值是指一個變量的值非常極端或者出現頻率非常低。對于一般的數值型變量根據蓋帽原則,將最大值cap值P99分位數;有業務實際意義的,根據業務邏輯來處理。對應字符型變量通過查看其分布來檢驗,并根據業務邏輯來處理異常值。
缺失值檢驗及處理:對缺失值處理同樣要分數值型和字符型兩部分,對應數值型變量缺失值的填充方法有總體均值填充、類均值填充、回歸預測填充等,本次模型主要采用總體均值填充的方法和業務實際來填充。對字符型變量的缺失值我們用N來填充。
1.1.3 分析建模
變量首次篩選:由于源變量較多,首次篩選去掉那些對目標變量影響不大的變量將會減少后續工作量。結合變量的IV值和單個變量進入邏輯回歸模型的結果,篩選出相對重要的變量。
變量分組:由于LOGISTIC回歸只能對數值型變量進行建模,對字符型變量需要預處理或分組衍生出啞變量,同樣,對數值型變量也做了分組處理。我們在目標變量的監督下,對變量進行分組處理。并將分組結果轉換為變量對應的woe值。
變量二次篩選:對轉換為woe值后的變量做共線性診斷,剔除相關性較強的變量。
模型開發:首先將建模樣本分為訓練集和驗證集,采用逐步回歸的方法進行LOGISTIC回歸的開發。基于此模型結果我們可以預測出資產5~100萬的客戶首次購買大額存單的可能性的大小。根據模型的評分結果,給定營銷組A、B和對照組C、D,其中A和C是響應率前10%的客戶,B和D組是響應率后90%的客戶。前10%的客戶提升度為5倍,營銷組A的成功率約為對照組D的9倍。
我行業務部門開展了為期1個月的大額存單交叉營銷活動,最終大額存單銷售量為近500位客戶,購買大額存單近600筆,認購總金額2億多元,人均認購金額超過50萬元。購買客戶中,AUM月均較上月新增的客戶近400位,占比約78%,AUM提升金額近5 000萬元,高于中高端客戶平均增幅,帶動了分行開門紅個人存款及客戶發展工作。
1.2 信用卡賬單分期
1.2.1建模樣本及目標變量定義
針對最近兩年有消費的信用卡客戶,篩選當月賬單余額絕對值>1 111且賬單月內消費金額>1 111的客戶,預測其在未來一個月分期的可能性的大小。
1.2.2 數據預處理
源數據包括每日卡信息表、中銀卡新發卡數據表、中銀卡關系表、中銀卡客戶信息數據、中銀卡賬戶遲繳數據、中銀卡交易數據、賬單客戶信息表。數據預處理主要包括變量衍生、異常值檢驗及處理、缺失值檢驗及處理三個部分組成。
變量衍生:針對客戶的消費行為衍生了客戶近6個月消費金額、最大消費金額、月均消費金額、分期金額、分期次數、利息次數等變量。
異常值檢驗及處理:數值型變量通過查看其分位數來檢驗,根據蓋帽原則將最大值cap值P99分位數,當P99分位數為0,但最大值不為0時,將P99分位數以上的值設為1;字符型變量通過查看其分布來檢驗,并根據業務邏輯來處理異常值。
缺失值檢驗及處理:對缺失值處理同樣要分數值型和字符型兩部分,對應數值型變量缺失值的填充方法有總體均值填充、類均值填充、回歸預測填充等,本次模型主要采用總體均值填充的方法和業務實際來填充。對字符型變量的缺失值用N來填充。
分析建模流程同大額存單交叉銷售模型一致。根據模型結果,可預測出信用卡客戶賬單分期的可能性的大小,業務人員通過模型打分的篩選結果進行精準營銷,取得了良好的業務成效。根據模型結果撥打賬單分期響應率高的前60%的客戶基本可覆蓋98%的分期客戶。通過近10個月電話外呼對每月符合賬單分期的客戶進行卡戶分期營銷,項目期間卡戶分期累計新增交易額近7億元,同比增長20.5%,實現手續費收入近4 000萬元,同比增長24%,手續費貢獻占比37.7%。
2 風險預警
隨著互聯網金融迅速崛起,各家商業銀行紛紛研究大數據風控的應用場景,本文結合大數據、人工智能、銀行風險防控等技術,為銀行加強金融風險管控,保護客戶資金安全提供保障。
2.1 中高端客戶流失預警模型
我行2016年一季度中高端客戶降級流失率為20%左右,中高端客戶的流失導致的損失是比較嚴重的。為預測中高端客戶流失的可能性,需找出潛在的流失客戶,支撐客戶經理的維護工作,定制差異化的產品、服務和營銷策略來挽留客戶,以防客戶流失。
經過對歷史數據的分析驗證,建模樣本及目標變量的定義為:當前6個月資產月日均20萬以上,且相對前6個月資產減少不超過50%的客戶,未來6個月任意月份資產月日均減少90%以上的可能性的大小。
數據預處理及分析建模流程同大額存單交叉銷售模型一致。模型上線后的樣本外數據驗證結果前10%客戶提升度為3倍,同建模結果基本一致。經過模型評分的數據支持,近半年分行客戶降級流失率減少5%,挽回近5 000萬的資產。
此模型的結果同時部署到分行大數據平臺midas工具中,利用大數據平臺的分布式計算能力,能夠實時得到模型打分結果,并將客戶的一些影響流失的重要指標情況實時反饋給客戶經理。下一步,我們將基于此建模方法利用大數據平臺的midas進行機器學習,不斷地對模型結果進行迭代優化,形成客戶流失預警模型的閉環營銷流程。
2.2 信用卡疑似套現評分模型
信用卡套現行為給銀行帶來了呆壞賬的風險,需要通過系統智能化的識別,根據持卡人及商戶的交易行為特征,建立疑似套現模型,提高疑似套現卡片的甄別率及工作效率的同時,降低銀行風險敞口。
通過分析客戶最近6個月的消費情況,對客戶是否存在套現給定一個評分,該模型是一個經驗模型。
為此引入兩個概念,客戶在某商戶的大額交易:客戶在商戶交易單筆金額大于3 000元;客戶在某商戶的可疑金額:最近6個月,客戶在某商戶大額交易筆數至少3筆,且累計交易金額大于等于50 000元。
信用卡套現主要從客戶角度和商戶角度入手,如果商戶涉嫌套現,那么商戶消費金額中有很大比重來自套現,再引入商戶可疑度指標,設為ε,商戶可疑度=所有客戶在該商戶的可疑消費金額/該商戶的所有消費金額。涉嫌套現的商戶一般不正規、不知名、手續費較低。
對商戶信息進行清洗和分類,引入白名單,在知名商戶的消費不計入套現。不可疑商戶標準:普通商戶可疑度<0.25;房車商戶可疑度<0.3;第三方支付商戶可疑度<0.1;批發類商戶可疑度<0.15。
如果客戶涉嫌套現,其在可疑商戶消費金額的比重就較大,引入指標α、β、γ,定義M為客戶的總消費金額,Mi為客戶在某商戶的可疑金額,Mj為客戶在某商戶的可疑金額2,即最近6個月內,客戶在某商戶至少5個月有大額交易,且累計交易金額≥5萬元。Mx為客戶的可疑金額,定義為客戶在所有商戶的可疑金額之和。
(1)
(2)
(3)
這樣,我們初步得到評分公式:
0.2(log10Mx-5)
(4)
同時經過分析我們發現,取現越多和在知名商戶的消費越多,客戶套現的概率越低,最后我們得到優化的評分公式:

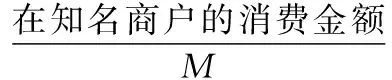
(5)
n1:最近6個月內,客戶在可疑商戶每筆消費3 000元以上的次數。
n2:最近6個月內,客戶在可疑商戶每筆消費9 900元以上的次數。
模型應用于信用卡高額度客戶排查、套現排查、套取積分等排查工作中,按模型提供數據,已開展對套現評分最高的500張卡片進行排查,共處置近90張卡片,成功率為業務經驗排查的6倍,為分行優化信用卡資產結構及客戶質量、有效遏制不良資產的新增提供有效的決策支持。
3 運營優化
在構建了網點選址優化模型后,對其中四家支行的選址進行了對比分析。該模型主要基于客戶位置、屬性及商圈經濟等數據的人流分析、潛在客戶分析、位置畫像分析、人群畫像分析和應用偏好分析,提供金融網點評估建議,作為網點選址優化的依據。
3.1 人流分析
分析人流密度及分布,主要評估人口類型是居住人口、工作人口還是流動人口。
3.2 潛在客戶分析
分析客戶的活動區域分布、客戶的基本屬性信息、消費信息等數據。通過look-alike相似人群擴展機器學習算法,將高PA客戶群作為種子用戶,作為機器學習的正樣本,剩下的客戶則為負樣本,從而將上述問題轉化為一個二分類的模型,正負樣本組成學習的樣本。經過對模型的訓練,利用模型結構對客戶進行打分,最終得到我們想要的潛在高PA客戶群,即根據相似人群的擴大,尋找出符合業務的潛在客群。
3.3 位置畫像分析
通過對周邊資源的分析,以及金融同業的分析,評估周邊交通便利層度。
3.4 人群畫像分析
主要分析客戶的年齡、性別、學歷、職業、婚育狀況、車輛情況、應用使用偏好、消費品位、消費品類等多維度。
3.5 應用偏好分析
本文著重分析客戶對金融類APP的偏好,主要包括金融同業、互聯網金融機構等消費傾向的分析。
四家支行從上述五個方面對比分析發現:四家支行的定位差別很大,支行1處于核心區域,位置環境優越,人群質量和業務都占優,潛在客戶群大,各方面都具有明顯的優勢;支行2和支行3處于人口密集區,中國銀行手機銀行APP安裝率較高,說明老客群體相對較多,50歲以上人群在四個支行中人群占比最高;支行4相對于其他三個支行劣勢較多。
4 結 語
大數據挖掘可讓金融機構更加了解客戶,在一段時間內,大數據在金融應用中還將以營銷、風控和運營為主要場景。未來,金融機構在合規的前提下,將引入更多維度的外部數據。在大數據分析挖掘取得成效的基礎上,一方面豐富數據指標體系,進行模型的優化工作,全口徑掌握客戶使用銀行產品和服務的狀態,以及與其他客戶的關系,對客戶進行全視角的風險評估;另一方面,充分利用大數據平臺計算架構的優勢,基于大數據平臺的分布式計算能力進行機器學習,為業務發展提供實時的決策與支持。
[1] 霍魁.大數據時代下數據挖掘技術在銀行中的應用[J].商,2015(26):191-192.
[2] 彭爽.商業銀行轉型升級的大數據戰略分析[J].中國商論,2016(1):71-73.
[3] 宋志德.論我國商業銀行業務創新[J].商業文化,2015(6):96-97.
[4] 王雅軒,頊聰.數據挖掘技術的綜述[J].電子技術與軟件工程,2015(8):204-205.
[5] 崔冬梅.大數據時代之統計數據挖掘實證[J].統計與決策,2016(4):180-182.
[6] 劉鳳艷.基于聚類分析的證券業客戶分層實證研究[J].赤峰學院學報(自然科學版),2016(8):99-101.
[7] 曹凌雁,曹慧,劉向榮.基于數據挖掘技術的信用卡透支影響因素研究[J].知識經濟,2015(2):87-88.
[8] 張覺文,張心蓓.我國電子銀行業務現狀及發展趨勢[J].統計與管理,2015(7):60-61.
[9] 許佳馨,劉曉星,崇章.大數據對商業銀行的影響分析[J].農業發展與金融,2016(5):51-52.
[10] 南楠.基于關聯規則的銀行潛在客戶挖掘研究[J].電子商務,2016(8):48-50.
EXPLORETHEAPPLICATIONOFBIGDATAMININGINCOMMERCIALBANKS
Luo Suwen1Han Lu1Xu Qin1Sun Yuanhao21
(BankofChinaShanghaiBranch,Shanghai200233,China)2(TranswarpTechnology(Shanghai)Co.,Ltd,Shanghai200233,China)
Due to the rapid development of big data, the traditional database management with business experience model is facing great challenge. In view of this, we propose a data mining technology based on big data. We first understand the business requirements, design the model according to the business goal, then carry on the data integration and the data cleaning, finally establish the model and evaluate the model results. The experimental results show that the application of big data mining can effectively improve the success rate of precision marketing, risk prevention and control and operational optimization management.
Big data Data mining Precision marketing Risk prevention and control Operation optimization
TP311
A
10.3969/j.issn.1000-386x.2017.09.009
2017-06-02。羅素文,碩士,主研領域:數據挖掘,機器學習。韓路,碩士。許勤,高工。孫元浩,碩士。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
