基于DPDK的流量動態負載均衡方法
2017-09-18 07:52:54李凱葉麟余翔湛胡陽
智能計算機與應用 2017年4期
李凱 葉麟 余翔湛 胡陽

摘要: 隨著互聯網技術的不斷發展,數據中心網絡以及國家骨干網絡的流量規模也在不斷增長,大規模的流量以及無用的惡意流量對多核處理器的負載均衡有著很大的影響,所以對于多核處理器來說,負載均衡是一個亟待解決的問題。本文提出了一種基于DPDK平臺的動態多重Hash的技術來更好地解決在多核處理器中流量分配不均衡的問題。文章中對現有的RSS等相關技術進行分析,通過采用對稱RSS技術與動態負載相關技術相結合的方法,將捕獲的數據包發配到不同的收包隊列,實現處理器多核間的負載均衡。
關鍵詞: DPDK; 負載均衡; 多核處理
中圖分類號:TP393
文獻標志碼:A
文章編號:2095-2163(2017)04-0085-06
0引言
隨著互聯網技術的不斷發展,網絡中的流量規模日益增大,傳輸速度也在不斷提高,流量的負載均衡問題成為了限制諸多網絡服務的瓶頸,為了應對網絡中數據包的高速傳輸,Intel針對X86架構設計了高性能的數據包處理框架DPDK,DPDK通過對大頁技術、零拷貝技術、 網卡隊列技術以及CPU的親和性等成熟技術的開發運用,以及對數據包處理的過程引入了效能優化,相比Linux系統的數據包處理性能提高了數倍。DPDK框架主要應用在多核處理器系統對數據包的處理流程中,在多核處理器的負載均衡方面,傳統的負載均衡算法主要有輪詢、哈希散列、響應速度等,DPDK框架在負載均衡上采用了RSS技術,但是單純地采用RSS技術對于高性能會話連接的處理以及特殊情況出現Hash碰撞這些問題在技術探討中卻仍然呈現出一定的缺陷與不足。基于此,本文即研究提出了一種基于DPDK平臺的動態多重Hash的技術,通過對原有的RSS進行修改以及結合動態調整的方法來更好地解決在多核處理器中流量分配不均衡的問題。
1相關工作
1.1RSS技術
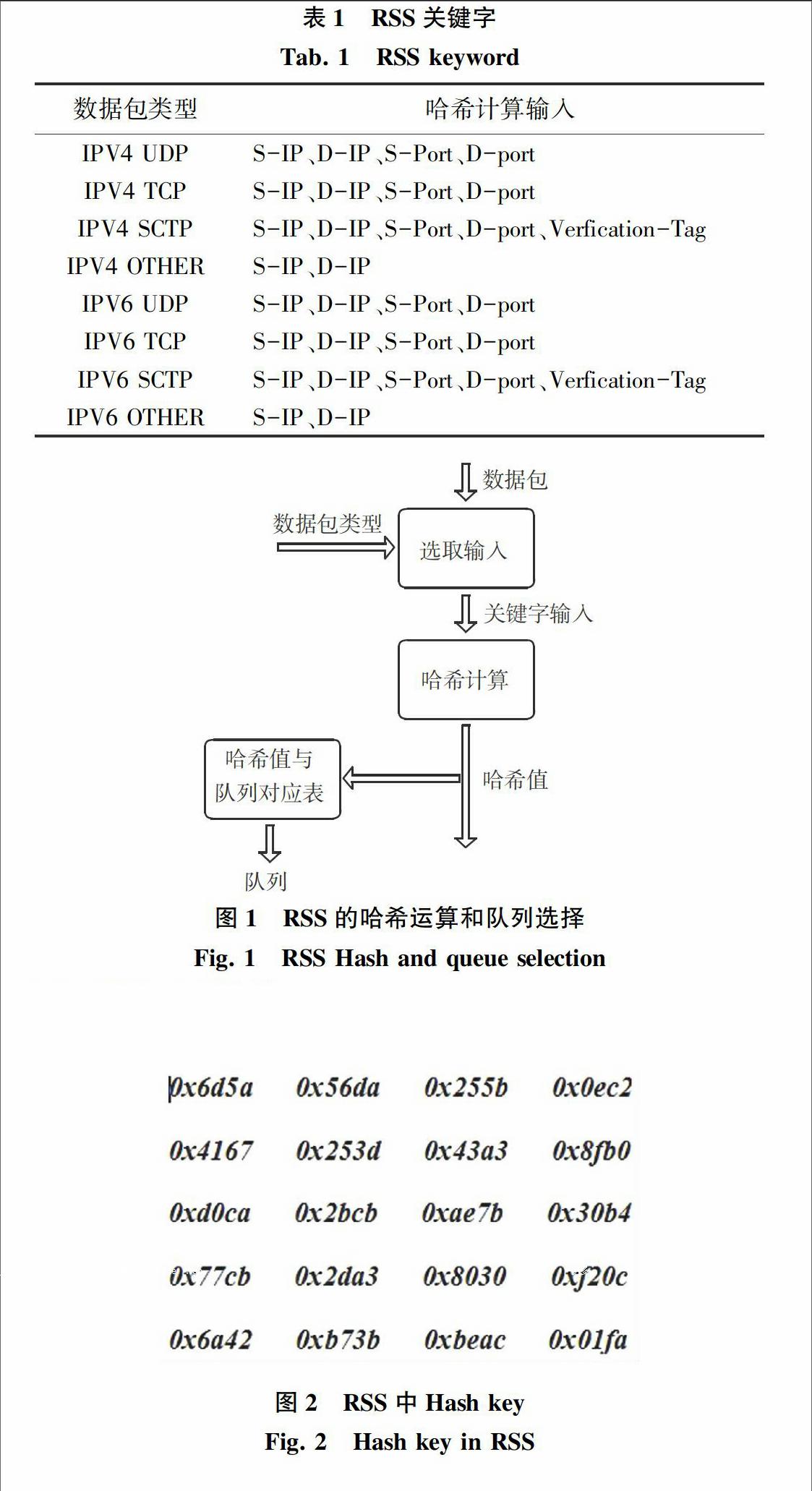
RSS(Receive Side Scaling)是與底層硬件相關聯,在多核處理器收到數據報文后能夠在多核之間進行高速轉發的網卡驅動技術。該技術需要通過相關的硬件網卡支持展開哈希值的計算,根據哈希值的不同將收到的數據報文發送到不同的收發隊列當中,由于CPU的親核性,Linux內核將不同隊列的報文映射到不同的處理器核中。同時,考慮到DPDK支持網卡的多隊列功能,因而可以比較容易地給特定應用指定接收(RX)或發送(TX)隊列。
[JP2]通俗地講,RSS是利用特定的報文字段值進行哈希計算得出哈希值,再通過得出的哈希值將數據報文送往不同的隊列,網卡會根據數據包的不同類型確定其特定的字段信息,如表1所示。例如IPV4 TCP的特定字段是由(S-IP、D-IP、S-Port、D-port)四元組構成,此外,DPDK還可以根據需要采用數據包中的其他特定字段滿足不同的需求。并且圖1還進一步闡釋了通過Hash計算得到的哈希值與隊列索引之間的關系。
1.2對稱RSS技術
對稱RSS是指在網卡驅動開啟RSS功能后相同連接的雙向數據報文能夠分配到多核處理器的同一個核中,因為在不同核中共享連接信息會產生死鎖的現象,即使得對稱RSS對于保存連接信息的網絡應用在減少性能開銷上獲得了大幅提升。
[JP2]RSS采用的是Toeplitz Hash算法,此算法需要2個輸入變量:數據報文中的五元組信息以及默認的Hash key。DPDK網卡驅動層采用的Hash key是Microsoft推薦的,對于相同連接的雙向數據報文經過哈希后得到的Hash值是不同的,Hash值的不同會出現2個方向的數據報文分配到不同的接收隊列,通過不同的處理器核心進行處理。對于如何生成對稱的RSS,文獻[1]對RSS原有的Hash key融入了一定的修改,并證明這組Hash key可以用來實現對稱RSS。原有的Hash key以及論文中提到的Hash key值分別如圖2和圖3所示。
1.3技術分析
研究分析可得,RSS技術的缺點是一些網絡應用處理的設備中,僅僅使用RSS技術會影響處理性能,例如電信轉發設備,對一個網絡連接的雙向流處理的方式是相近的,所以希望在多核處理器的同一個核上對存在對稱信息的數據報文進行處理,比較有代表性的應用有網絡防火墻、服務質量保證。若在不同的核上處理同一個流上的雙向信息,就會出現不同核研發設定數據同步的問題,這就會產生處理器的多余開銷,降低處理器的性能。
相對DPDK平臺的RSS技術改進的對稱RSS技術雖然解決了同一個流的對向數據報文在不同核上有效處理的問題,但是對于出現Hash碰撞的情況以及大規模相同連接的流量時,還是會出現多核處理器某一個核上的負載過重,甚或負載不均衡的情況。
[JP2]綜上可得,當網絡流量出現比較單一極端的情況下,僅僅利用靜態的哈希技術是無法滿足對數據報文處理的需求的,也就是將出現單核負載過重的情形,從而降低CPU的處理效率。[JP]
2框架設計及實驗分析
2.1負載均衡框架
DPDK 對于數據包的處理主要設計推出了2種框架,分別是: run-to-completion(運行至終結,簡稱RTC)模型和Pipeline(流水線)模型。在此,將給出各自研究闡釋如下。
[JP2]首先,Pipeline模型能夠將處理器密集的操作集中在一個核上執行,將I/O密集的操作配置在另一個核上執行,將不同的操作利用過濾器分配到不同的線程中。具體來說,Pipeline 模型把整個框架分為3部分:輸入端口、輸出端口和工作核(worker Lcore), ring 隊列將端口與工作核相連。[JP3]通過這種方式,從一個端口收到的數據報文能夠依據應用需求而分配至任一指定的工作核上處理,處理后工作核將數據包發送到輸出端口。[JP]endprint
其次,run-to-completion模型主要是DPDK平臺對于一般程序的運行方法, run-to-completion通過網卡的多隊列的功能,將接收的數據報文分配給多個CPU核上處理,對于CPU的每個核,都是獨立處理到達該隊列的數據報文,硬件資源分配也比較固定,降低了數據報文在核間的傳遞的開銷,能夠隨著核的數目較為靈活地擴展處理能力。
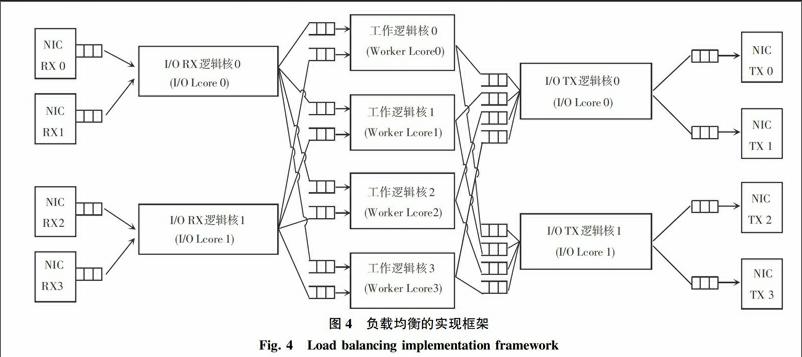
基于前文研究可知,run-to-completion 模型確實能夠減少CPU核心間通信的開銷,但對于負載均衡是不合適的,對于同屬于一個鏈接的不同數據包會出現被分配到CPU的不同核上進行處理,這樣保持會話連接就比較困難,而Pipeline能夠通過自定義規則選出特定的核心來處理數據報文,為此在負載均衡框架的設計上采用了Pipeline模型。負載均衡的實現框架則如圖4所示。
在該負載框架中用于處理來自不同網卡端口報文的邏輯核稱I/O邏輯核(I/O Lcore),其余被指定執行應用處理的邏輯核稱為工作邏輯核(Worker Lcore)。圖4即建立展示了2個特定的RX I/O邏輯核和2個特定TX I/O邏輯核用于處理來自網卡端口的報文收發的過程。下面則針對各關鍵核的工作內容研究得到如下設計表述。[FL)]
1)I/O 接收邏輯核(I/O RX Lcore)。每個I/O接收邏輯核從指定的網卡環形隊列接收報文,然后分發到工作線程(Worker Thread)。該框架允許每個I/O接收邏輯核與任何一個工作線程進行通信,因此每個(I/O RX Lcore,Worker Lcore)對之間就可以通過專用的“生產者—消費者”Ring環形隊列而展開連接。
2)I/O 發送邏輯核(I/O TX Lcore)。針對多個已預先定義的網卡端口,每個I/O邏輯核擁有報文發送能力。為啟動每個工作線程發送報文到任何TX端口,框架為每個(Worker Lcore ,NIC_TX_Port)創建了一個Ring環形隊列,而每個I/O發送邏輯核就可以處理這些網卡端口上的環形隊列。
3)工作邏輯核(Worker Lcore)。每個工作邏輯核從一系列的Ring環形隊列讀取報文,通過將這些報文拆分到輸出軟件環,報文被轉發到網卡口。轉發邏輯是基于DPDK提供的LPM查表轉發的,所有的工作線程共享同樣的LPM規則。
2.2多重Hash算法
主要思想是采用2種哈希的方法解決負載不均衡的問題。首先建立2張Hash表,用來存儲一個連接與CPU不同核之間的映射關系,在網卡接收到報文后,對包頭的四元組設定2次不同的Hash計算,為了保證相同連接需要送到同一個核而統一處理的大原則,即使在CPU過載情況也要遵循這一原則,根據計算來研究轉入哈希表查詢:若查到映射關系說明收到的數據包是已有連接中的數據包,將數據包送到相應CPU核心進行處理;若在查表過程中沒有查詢到映射關系,說明收到的數據包屬于新連接,在負載正常的情況下,收到的新連接數據包進行對稱RSS處理,將映射關系存在哈希表1中并將數據包送到相應CPU實現后續處理,若系統出現負載不均導致某些CPU核心過載的情況下則剔除負載過重的核,收到的新連接數據包即加載第2套哈希算法,將映射關系存在哈希表2中并將數據包送到相應CPU實現定制處理,通過這種方式能夠將收到的新連接中的數據包分散到負載較輕的CPU核心中去,從而能夠達到將負載均勻分配的目的。
采用多重Hash方法的好處是進一步分離不同流的數據包,因為單次Hash可能會出現Hash碰撞的可能。相對多核匹配,優點在于能有更多的核參與到均衡流量。圖5即例示說明了在硬件層面對算法的支持。
過程中,需要在何種情況下對處理器的負載配置優化調整,算法即在本節內容中研究提出了采用負載均衡度[2]對多核的負載進行評估,負載均衡度表示了接收的數據包在CPU多核處理器之間的分配比例與多核之間的處理能力比例的差異程度。負載均衡度的值越小,表明各處理節點的負載程度就越均勻。而考慮到對于多核處理器各核的處理性能均相同,為此這里的負載均衡度就是CPU多核之間負載量的差異程度 。具體的公式表述如下:
RLBM(t)=1-〖SX(〗〖JB((〗∑〖DD(〗n〖〗i=1〖DD)〗Ri(t)〖JB))〗2〖〗n∑〖DD(〗n〖〗i=1〖DD)〗R2i(t)〖SX)〗[JY](1)
其中,R(t)表示在時刻 t 多核處理器的第i個核的利用率,n 為多核處理器核的數量。通過反復實驗,可以得出在負載均衡度的值高于0.2時,就會對處理器的流量負載進行動態的多重Hash調整。在確定了動態調整的評估方法后,整體算法的基本流程則如圖6所示。算法流程步驟詳述如下:
1)收到數據包后,分別通過Hash1()以及Hash2()計算得到哈希結果,并利用哈希表1以及哈希表2進行查找,如果存在映射關系就將數據包分配到對應的處理核心中。
2)在第1)步中如果沒有在2張哈希表中查到對應關系,說明數據包屬于一條新連接,而后將通過對當前CPU的整體負載均衡度的統籌判斷操作來決定數據包的下步操作。
3)負載均衡度沒有超過系統設定的閾值,說明目前系統負載均衡情況較好,數據包根據Hash1()的結果在哈希表1中建立映射關系,并將數據包分配到對應的處理核心中。
4)負載均衡超過設定閾值時,說明目前出現了負載均衡不良,某些處理核心存在過載嚴重的情況,需在下一步中剔除過載嚴重的處理核心,并動態更新Hash2()的所有計算結果與處理核心id的映射關系,采用Hash2()進行計算,數據包根據Hash1()的結果在哈希表2中建立映射關系,并將數據包分配到對應的處理核心中。
2.3實驗分析
實驗選擇Pktgen對單位時間內關于處理接收數據報文的CPU核心的使用率進行統計,并對一個時間段的核心使用率計算平均值,通過比較多核處理器各個處理節點的使用率來對負載均衡度而展開有效的衡定與測量。研究中選定的實驗平臺的配置信息則如表2所示。endprint
2)使用多重Hash方法,各核的負載情況。也可由研究得到對應運行效果即如圖8所示。
在此基礎上,又引入了柱狀圖的模式來展開研究,研究可得結果如圖9所示。通過柱狀圖的遞進趨勢來看,相比在DPDK平臺單純使用RSS技術而言,使用多重Hash方法將負載過重的處理節點的后續接收的數據報文分配到其他負載較輕的負載節點上,從而能夠使得各個處理節點的使用率相對平均,充分利用了多核處理器的性能,處理器也隨即將更好地發揮可調用設計潛能,一定程度上提高了多核處理器的處理效率。
3結束語
本文圍繞高速網絡壞境中多核處理器關于捕獲數據包負載均衡的問題,首先對DPDK平臺提供的RSS以及對稱RSS靜態哈希的技術探討引入了可行有效分析,并進一步論述了目前呈現的問題;其次是針對這些不足致力于研究改進,由此則開發提出了靜態與動態相結合的多重Hash負載均衡的算法;最后,基于DPDK平臺設計得出一個負載均衡的框架,并通過實驗分析算法性能,從而全面對照比較了在DPDK平臺單純地采用RSS算法和多重Hash算法之間的差異程度。
參考文獻:
[1] WOO S, PARK K S. Scalable TCP session monitoring with symmetric receive-side scaling[R]. Daejeon, South Korea:KAIST, 2012.
[2] 陳一驕, 盧錫城, 時向泉,等. 一種面向會話的自適應負載均衡算法[J]. 軟件學報, 2008, 19(7):1828-1836.
[3] 趙寧, 謝淑翠. 基于dpdk的高效數據包捕獲技術分析與應用[J]. 計算機工程與科學, 2016, 38(11):2209-2215.
[4] 何佳偉, 江舟. 基于Intel DPDK的高性能網絡安全審計方案設計[J]. 電子測試, 2016(Z1):87-91.
[5] 張瑩, 吳和生. 面向多進程負載均衡的Hash算法比較與分析[J]. 計算機工程, 2014, 40(9):71-76.
[6] 于洪偉. 基于多核處理器高效入侵檢測技術研究與實現[D]. 成都:電子科技大學, 2009.
[7] 莊卓俊. 基于多核平臺的入侵檢測系統的設計與實現[D]. 上海:上海交通大學, 2009.
[8] Shemesh O. System and method for symmetric receiveside scaling (RSS):US,8635352[P]. 2014-01-22.
[9] BOKHARI M U, ALAM M, HASAN F. Performance analysis of dynamic load balancing algorithm for multiprocessor interconnection network[J]. Perspectives in Science, 2016, 8(C):564-566.
[10] ZAJDA K. Evaluation of possible applications of dynamic routing protocols for load balancing in computer networks[J]. Theoretical & Applied Informatics, 2010, 22(2):141-151.
[11]李敬喆. 多核環境下的負載均衡方法研究與設計[D]. 北京:北方工業大學, 2011.
[12]劉熙. 若干負載均衡技術的研究[D]. 南京:南京大學, 2011.
[13]李彥君, 鐘求喜, 陳誠,等. 多核平臺入侵檢測系統負載均衡算法設計與實現[J]. 計算機應用研究, 2012, 29(4):1413-1416.
[14][JP4]HOU E S H, ANSARI N, REN H. Genetic algorithm for multiprocessor[JP] scheduling[J]. IEEE Transactions on Parallel & Distributed Systems, 1994, 5(2):113-120.endprint
