基于文獻的知識發現在成礦預測領域的應用研究
2017-09-18 02:44:54呂鵬飛王春寧朱月琴
中國礦業 2017年9期
呂鵬飛,王春寧,周 峰,朱月琴
(1.中國地質圖書館,北京 100083;2.中國科學院大學,北京 100049;3.國土資源部地質信息技術重點實驗室,北京 100037;4.中國地質調查局發展研究中心,北京 100037)
基于文獻的知識發現在成礦預測領域的應用研究
呂鵬飛1,2,3,王春寧1,周 峰1,朱月琴3,4
(1.中國地質圖書館,北京 100083;2.中國科學院大學,北京 100049;3.國土資源部地質信息技術重點實驗室,北京 100037;4.中國地質調查局發展研究中心,北京 100037)
基于文獻的分析挖掘是發現未知新知識的有效途徑,本文提出了基于文獻的知識發現應用于成礦預測領域的研究思路,構建了基于文獻的知識發現模型,主要包括地質實體識別、實體關系識別兩個部分。
文獻的知識發現;成礦預測;中文分詞;關系提取
成礦預測是基于已有的成礦理論、成礦條件、成礦信息以及成礦規律,運用成礦預測方法,對未發現礦體、礦床做出推斷、評價的學科[1]。成礦預測目的是利用現有成礦研究成果的指導,提高找礦的效益和效率。成礦預測的發展大體經歷了三個階段:20世紀70年代以前主要是在確立典型區域成礦條件下,使用經驗類比法在未知區域發現成礦目標;20世紀70年代至80年代初,統計方法和計算機技術開始廣泛應用與成礦預測,其標志是1976年在挪威的洛恩舉行的國際地質對比計劃98項專題提出了區域價值估計、體積估計、豐度估計、德爾菲估計法、礦床模擬法和綜合方法六種資源預測的標準方法[2];進入20世紀80年代后期,GIS開始進入礦產預測領域,產生了一批成功應用的典范。如美國地質調查局實施的國土資源評價計劃(CUSMAP),其對柵格、矢量和表格式數據進行處理并通過定制接口在GIS內建立應用模型及表示評價結果[3];進入新世紀,面對信息大爆炸的時代(即“大數據”時代),成礦預測也應運進入“大數據”時代。如何充分利用地質工作數十年積累的海量數據,將已有數據轉化為新的認識或知識,并運到成礦預測的實踐中,成為地質工作者當下必須面對與思考的問題。趙鵬大院士認為數字找礦是數據科學在礦產勘查中的應用,是用數據分析理論和方法解決礦床勘查中的實際問題[4]。王登紅認為可以從地質大數據中充分挖掘有用信息及其規律,通過成礦理論的系統分析,揭示其內在規律并轉化為新的認識或知識,指導未來的地質礦產工作[5]。地學文獻是地質大數據的重要組成部分,也是地質科學研究成果的重要表現形式,本文旨在通過開展基于地學文獻的知識發現研究,嘗試發現在成礦預測領域從未發現過或驗證過的新知識、新關聯,為地質找礦決策服務提供文獻信息服務。
1 基于文獻的知識發現
知識發現(Knowledge Discovery in Database,KDD),從字面可以理解為“基于數據的知識發現”,即從原始數據中提煉出有潛在的、有價值的知識。實際上和“數據挖掘”和“數據分析”一脈相承。基于文獻的知識發現就是對目標科學文獻的內容(包括元數據和全文)為對象進行全分析,挖掘、發現文獻關聯獲知新知識的過程,也即對在內容上有關聯的文獻進行比較和分析的基礎上從中識別和抽取有價值的信息的過程[6]。20世紀80年代,芝加哥大學的DR Swanson教授第一次提出了基于文獻的知識發現(Literature-Based Discovery)的概念,引起了學界的關注[7]。歷經數十年的發展,基于文獻的知識發現研究逐漸成熟,研究方法從傳統的計量統計方法發展到人工智能、機器學習,應用領域從最初的醫學、生物學擴展到情報學、工程學。總體來說從知識發現的方式上大致分為兩個方向:傳統的相關文獻知識發現和新進興起的非相關文獻知識發現。
1.1相關文獻知識發現
相關文獻知識發現顧名思義,就是文獻之間存在某種關聯,從文獻的結構上分有文獻元數據(標題、作者、單位、關鍵詞等)相關和文獻內容(全文)相關。基于相關文獻的知識發現研究就是對有直接關聯的文獻進行聚類、比較和分析并從中識別和抽取有價值的信息[8]。主要的分析方法包括共詞分析法和共引分析法等。共詞分析的原理主要是統計同一篇文獻中詞語出現的次數,在此基礎上對這些詞進行分層聚類,揭示出這些詞之間的關系[9]。共引分析是將一組具有同引關系的文獻作為分析對象,綜合利用數學、統計學和邏輯分析方法,通過基于共引關系所形成的文獻共引網絡將學科之間的關聯與親疏直觀的呈現出來[10]。
1.2非相關文獻知識發現
相較于相關文獻,非相關文獻可以理解為文獻之間從外部特征(包括內容和元數據)不存在關聯關系。可是客觀世界是普遍聯系的,在海量的科學文獻之間存在著各式各樣的聯系,這些聯系有相當一部分僅通過常規的查詢與閱讀是不能得到的。非相關文獻知識發現也是由D R Swanson教授首先提出的,他認為兩組看起來沒有任何關聯的文獻(一般理解兩篇文獻不存在關鍵詞同現和共引關系即為非相關文獻)可能存在隱含的關聯,而這種關聯是單獨閱讀任何一組文獻都發現不了的。經過不斷的深入研究,D R Swanson教授提出了“ABC理論”:R(A,B)+R(B,C)->R(A,C),R(A,B)表示實體A與實體B有某種關系R。即,如果A和B有關系,且B和C有關系,則A和C也有關系,當然我們要確定關鍵詞A和關鍵詞C之間是沒有任何關聯關系的。D R Swanson教授依據該理論發現了食用魚油和雷諾氏病、偏頭痛和鎂缺乏之間的關聯關系并在臨床中得到了應用支持[11]。2001年,Weer等在總結和分析前人研究的基礎上提出了“‘兩步法’的基于非相關文獻的發現模式”,認為基于非相關文獻的發現應該包含兩個獨立的過程:構建假設的過程和驗證假設的過程[12]。2012年,Kostoff在提出了關聯文獻知識發現與創新(Literature-Related Discovery and Innovation,LRDI),強調將知識發現和創新結合。此為關于D R Swanson 1986年研究的最新完整表述[13]。國內的非相關知識發現研究起步于2000年以后,由于起步較晚目前研究主要集中于相關理論的研究分析和Swanson算法的實現上。
1.3基于文獻的知識發現的研究意義
科學文獻被認為是是科學研究成果的重要表現形式,也是開展科研、獲取知識的重要基礎媒介。越來越多的研究人員開始認為基于文獻的知識發現是發現未知的新知識的有效途徑,主要是有幾方面的原因。①科學文獻是專家學者將科研成果或經驗用規范化的科學語言精確表述,并且大多經過實驗驗證,由于其專業性和規范性具有較高的學術價值,為新知識發現提供了可能性。②隨著信息技術的不斷滲透,學科交叉、領域交迭現象日益明顯,在某一領域、專注于一個方向的科學文獻可能隱含著對不同領域、不同研究方向有學術價值的知識點。D R Swanson教授通過對文獻的分析發現了食用魚油和雷諾氏病、偏頭痛和鎂缺乏這兩組概念之間的關聯,而這是之前任何研究從未觸及的。這就為我們發現新的知識點以及現有知識點之間新的關聯佐證了可行性和正確性。③科學文獻是研究人員獲取知識的重要途徑。進入大數據時代,迎來了科學事業蓬勃發展的時期,科學文獻的數量呈幾何量級的增長。面對海量文獻數據,研究人員有了新的需求:一方面不只希望對文獻的研究利用僅僅停留在簡單的信息積累、加工和傳遞的低層次上,而是轉向了高層次的知識開發與利用。人們越來越注重對數據的分析挖掘,對于文獻的需求也從單一文獻信息向多元綜合信息、從簡單文獻資源發現向細粒度知識單元以及知識發現演變[14]。
2 基于地學文獻的知識發現模型
地學文獻知識發現研究的目的是通過開展對地質文獻大數據的特征和組織方式進行研究,構建基于地學文獻的知識發現模型。通過對地質專業文獻數據的挖掘,結合對中文分詞、關系抽取和擴展、知識圖譜構建等關鍵技術的研究,分析專業關鍵詞并建立實體之間的關聯關系,實現新知識發現的目標,面向成礦資源預測這個應用試點專題開展實際應用。模型主要包括地質實體識別、實體關系抽和關系圖譜可視化等,結構如圖1所示。
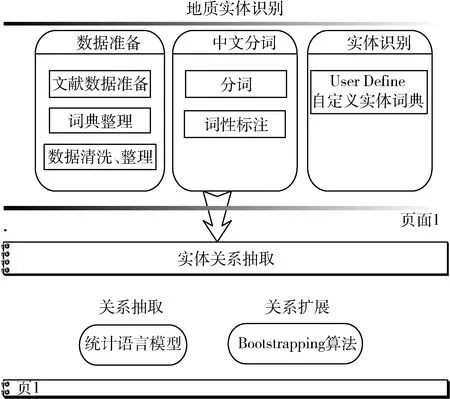
圖1 知識發現模型
2.1地質實體識別
地質實體識別是指采用自然語言處理技術從地學文獻中自動識別出成礦預測領域相關的實體要素,是下一步發現實體間的關聯關系的基礎。主要包括以下工作。
2.1.1 數據準備
1)按照資源儲備和項目需求確定文獻數據的范圍以及文獻全文數據的提取。
2)對已有詞表資源進行梳理。
3)文獻數據的清洗、轉碼。
2.1.2 中文分詞
分詞是將句子由連續的字序列按照一定的規范切分重新組合成詞序列的過程[15]。中文表達不像英文那樣有明顯的詞語分隔符,只有句子之間有明顯的符號劃分,可是詞是最基本的語義表達符,所以分詞是中文自然語言處理的基礎。目前分詞工具方法較為成熟,主要有以下幾種:基于詞典的字符匹配法、基于統計語言模型以及以上二者的結合。分詞工具方法各有優缺點,分詞工具方法的選擇需要統籌考慮語料基礎以及項目對分詞效果、效率的要求。由于分詞的結果對后續關系抽取效果有巨大影響,我們對應用范圍較廣的主流分詞工具進行了進行選型評估。結合本項目實際,綜合考慮詞典基礎、分詞結果需求(準確性、效率、詞性標注等)選擇了最大逆向匹配分詞算法的中科院分詞器的作為本項目的分詞工具。
2.1.3 實體識別
在分詞的基礎上,采用自定義字典user Define進行標注進行實體識別。即基于已有詞典資源構建地質類實體詞典,作為關系抽取中的實體。
2.2實體關系抽取模型
實體關系抽取也屬于自然語言處理的一項基礎工作,是在實體識別的基礎上結合語義環境提取出實體之間的關系[16]。通過自然語言處理我們得到了一個個獨立的實體知識點,可有價值的信息往往是通過實體間的關系來體現的,比如在基于文獻的成礦預測研究中,研究的目的是發現礦種和土壤、巖石、生物等實體間的關聯關系,從而為成礦預測決策提供科學數據支持。關系抽取技術路線經歷了從模式、詞典等簡單方法到機器學習等復雜方法的演變[17],目前基于統計語言模型的機器學習關系抽取方法憑借其入手易、效率高成為研究人員的主要選擇。本項目選擇了基于機器學習的關系抽取方法:采用統計語言模型的關系抽取方法和Bootstrapping的關系擴展方法。
2.2.1 基于統計語言模型的關系抽取模型
2.2.1.1 統計語言模型研究
統計語言模型可以形式化統一表示為式(1)。
p(S)=p(w1,w2,…,wn)=
(1)
p(S)就是語言模型,即用來計算一個句子S概率的模型。那么如何計算p(wi|w1,w2,…,wi-1),最簡單的辦法就是采用極大似然估計(Maximum Likelihood Estimate,MLE),見式(2)。
p(wi|w1,w2,…,wi-1)=fraccount(w1,w2,…,
wi-1,wi)count(w1,w2,…,wi-1)
(2)
式中,count(w1,w2,…wi)表示詞序(w1,w2,…,wi)在語料庫中出現的頻率。但由于數據稀疏和參數空間過大,導致實際中無法得到應用。
所以,實際中通常采用N元語法模型(N-Gram),它采用馬爾科夫假設:語言中每個單詞只與其前面N-1的上下文有關。
假設下一個詞的出現只依賴它前面的一個詞,即二元語法模型(BiGram),則有式(3)。
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)
…p(wn|w1,w2,…,wn-1)
=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
(3)
對于N的選擇:理論上,越大越好;經驗上,TriGram用的最多。原則上,能有BiGram解決的,就不用TriGram。
2.2.1.2 構建基于統計語言模型的關系抽取模型
關系抽取中采用二元語法模型,及每個詞只和它前一個詞有關,滿足一元馬爾科夫假設。操作步驟如下。
1)分詞。對每個句子進行分詞,過濾出名詞、動詞和介詞。
2)關系詞過濾。對關系詞進行過濾,過濾出不及物動詞(例如奔跑)以及以人為主語的詞(例如,看見)。
3)獲得關系三元組集合。找出句子中所有n-v/p-n結構的三元組(不考慮相鄰關系)。并計算獲得的所有三元組的聯合概率作為該三元組的得分(用二元語法模型);找出得分最高的三元組作為候選的關系三元組。
4)確定關系三元組。通過規則,對關系三元組的候選集合進行過濾,得到關系三元組,目前主要通過兩條規則進行過濾:對于抽取出來的n1-(v/p)-n2結構,如果n1和n2之間距離超過5,我們認為這個關系較弱而舍棄;對于抽取出來的n1-(v/p)-n2結果,如果n2后面是一個動詞,我們認為這個關系抽取的不完整故舍棄。
5)關系三元組置信度計算。加入評分函數計算抽取的關系三元組的置信度。評分函數為關系三元組在語料中出現的頻率。
2.2.2 構建基于Bootstrapping算法的關系擴展模型2.2.2.1 Bootstrapping算法研究
統計語言模型解決的是關系抽取的問題,而Bootstrapping解決的是關系擴展的問題。Bootstrapping的方法主要的思路是通過人工指定幾個初始種子,隨后系統會尋找滿足人工提供種子的句式模板,利用得到的模板找到新的種子不斷的迭代下去,最終達到舉一反三的目的。該方法的缺點是對初始關系種子的質量要求較高。比如我們現在知道“中國-北京”,“美國-華盛頓”兩個國家-首都的關系,但是還想知道所有其他的國家-首都關系,那么就可以用Bootstrapping方法,以“中國-北京”,“美國-華盛頓”為基礎,可以找到語料中幾乎所有的國家-首都關系。
Bootstrapping算法基本思想是:構建初始種子集;依據上下文語義環境,構建候選模式集;采用種子集訓練初始分類器,并對未標注數據集進分類;把分類結果中具有高置信度的樣本加入種子集中,重新訓練分類器,直到沒有新數據加入種子集為止;最后用訓練好的分類模型對測試集進行評估,輸出識別的最終結果。
2.2.2.2 基于Bootstrapping算法的關系擴展模型
依據Bootstrapping算法的基本思想,設計算法流程共分為以下幾個步驟:上下文構建階段、模板抽取階段、候選種子抽取階段和候選種子評分階段。
1)上下文構建階段。上下文構建階段主要是利用一種前綴字典樹的數據結構來存儲種子的前后的文字,在抽取上下文的時候只選擇在同一個分句當中的內容即任何標點符號都作為邊界處理。前綴字典樹是一種壓縮存儲的數據結構,他的特征在于父節點是子節點的前綴。
2)模板抽取階段。模板抽取階段主要是利用上下文構建得到的兩個字典樹,找到滿足所有種子的最長的句式模板。
3)候選種子抽取階段。候選種子抽取階段主要是利用找到的句式模板,在整個語料中找到滿足句式句子并利用句式抽出去對應位置的種子,作為候選種子。
4)候選種子評分階段。候選種子評分階段主要是利用隨機游走的方法從圖中進行迭代直到到達圖中的任何一點的概率收斂。
3 文獻知識發現實驗
結合項目開展實際,經過前期充分的咨詢調研,確定探索挖掘“金礦”領域知識關聯圖譜為試點,在目標文獻中自動發現構建“金礦”的關聯關系網絡,實現為“金礦”成礦預測提供有價值的新知識、新關聯的目標。
3.1數據準備
3.1.1 數據源確定
在文獻數據準備階段我們提取了CNKI2016年以前“金礦”相關文獻的全文數據,提取標準為:在基礎科學大類中選擇地質,這些文獻的元數據(題目、關鍵詞、內容提要)中必須包含有“金礦”一詞;在工程科技大類中選擇礦業工程學文獻,其文獻的元數據(題目、關鍵詞、內容提要)中也必須包含有“金礦”一詞。
最終共提取金礦會議文獻約1 647篇,大小約457 M;金礦期刊文獻約28 740篇,大小約9.54 G。其中,元數據為XML格式,文獻全文為TXT格式。
3.1.2 詞表收集整理
收集整理用于自然語言處理的中文詞表和其他相關規范、標準等文件。經收集整理可利用的詞表及其文件格式如下:1)地質分類法(xls,doc);2)敘詞表(pdf);3)2003~2014年度地質文摘庫自由詞(xls);4)地球科學百科全書(pdf);5)地球科學大辭典(xls);6)地球物質科學術語匯編(pdf);7)地質大辭典(pdf);8)地質圖書分類法(pdf)。
3.1.3 專業詞匯提取
在已有的文獻數據中提取了“金礦”相關專業詞匯,包括:從金礦會議文獻中提取關鍵詞2 668個,從金礦期刊文獻中提取關鍵詞26 794個、常用字典詞匯677 844個,最終收錄詞典詞目數717 819個。
3.2利用統計語言模型構建金礦領域知識圖譜
3.2.1 第一輪實驗
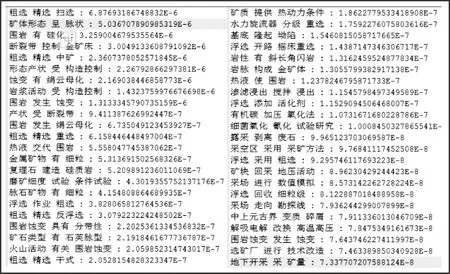
圖2 統計語言模型構建知識圖譜第一輪實驗結果
3.2.2 第二輪實驗
根據第一輪實驗結果,進行了關系詞(關系三元組中間的詞)去除,關系詞的問題有如下三類:第一類:關系詞包含意義模糊,表意不清。例如“有”、“受”、“使”、“添加”、“進行”、“采”等;第二類:關系詞是不及物動詞,沒法接賓語。例如“作業”、“發生”、“精選”、“進行”、“加壓”等;第三類:關系詞的主語為人,而項目抽取關系的主語為物。例如“建造”、“實驗”等。
針對這三類關系詞,分別做出如下處理。第一類關系詞包含意義模糊,采用停用詞表的方式在關系抽取的時候將這類詞過濾出去。實驗中發先這類詞比較少(由于文獻的格式用語比較規范統一),所以只構建了擁有三百多個詞的停用詞表就達到了很好的過濾效果,人工干預工作量并不大,且為一次性工作。第二類關系詞是不及物動詞,在詞性標注的時候將不及物動詞單獨標注出來,在關系抽取過程中可以直接過濾掉,過程完全自動化。第三類關系詞的主語為人,這類詞語和第二類不及物動詞有很大的重合,所以在過濾第二類詞的時候已經過濾了大量的第三類詞,剩下少量的詞通過停用詞表來過濾,人工干預工作量小,且為一次性干預,而效果極其顯著(圖3)。
3.2.3 第三輪實驗
在這一輪實驗中主要對評分函數進行了完善:在實驗中,發現評分函數存在缺陷:評分函數使用兩個二元組的聯合概率之和,這樣的評分函數放大了關系詞在抽取的關系三元組中的比重關系詞對關系三元組影響占比為50%(關系詞計算了兩次),然而關系詞的抽取在關系抽取中又是最不穩定的,所以導致抽取結果準確度較低。據此,對評分函數進行了改進:將原始計算兩個二元組聯合概率之和改成直接計算三元組的聯合概率,使得兩個實體詞和關系詞對關系三元組的占比都是1/3,達到平衡(圖4)。
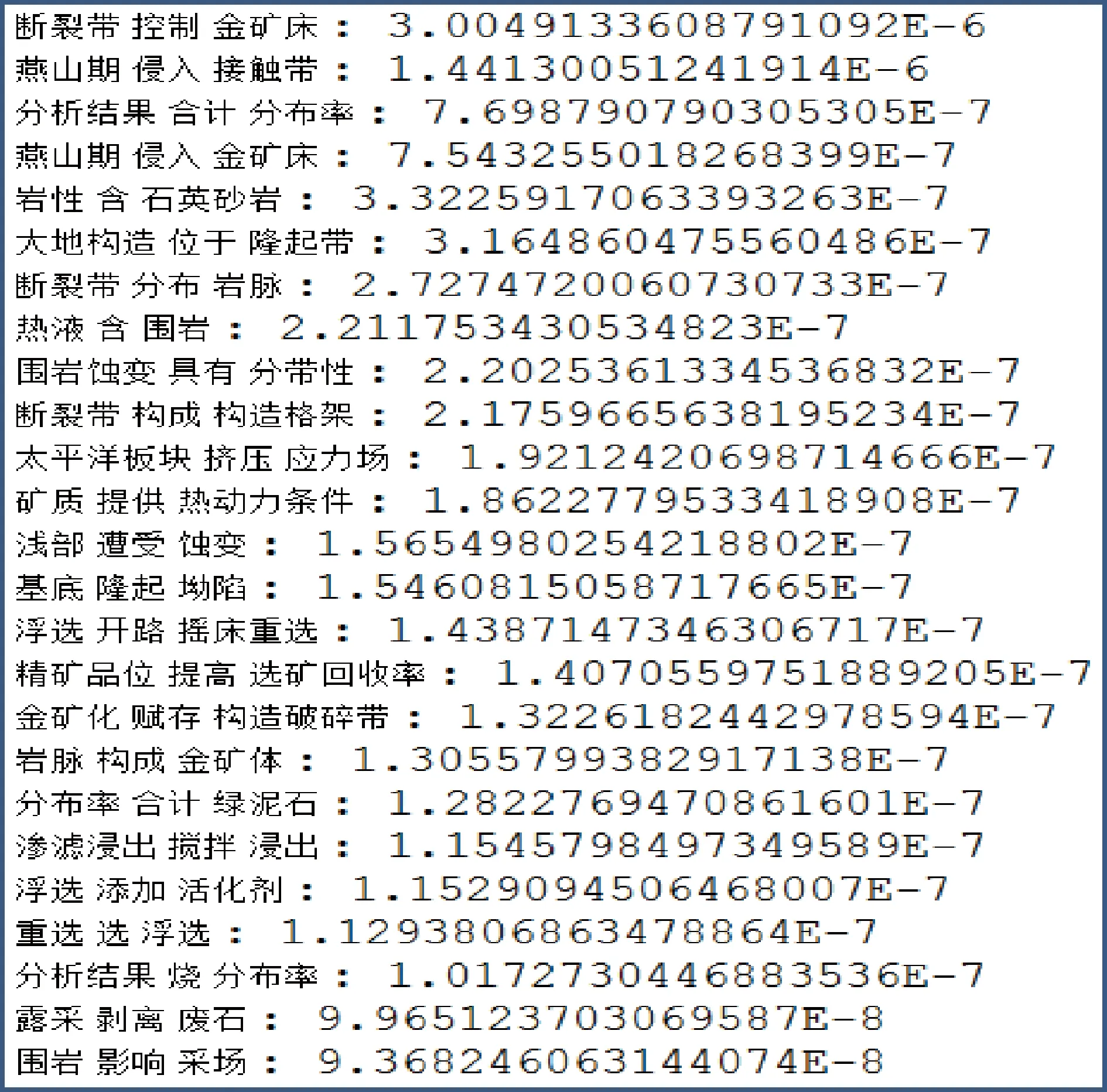
圖3 統計語言模型構建知識圖譜第二輪實驗結果

圖4 統計語言模型構建知識圖譜第三輪實驗結果
3.3利用Bootstrapping構建金礦領域知識圖譜
3.3.1 第一輪實驗
1)實驗種子設置:金礦-黃金。
2)關系抽取模板,如圖5所示。
3)實驗結果,如圖6所示。
4)結果分析。僅發現一個有效種子,經分析主要原因如下:文獻數量不夠、文獻種子分布不均衡、漢語表達的多樣性、模板太過具體、臟數據過多等。
3.3.2 第二輪實驗
依據第一輪實驗發現的問題進行改進,效果比較明顯。
1)種子設置:礦石-磁鐵礦、礦石-黃鐵礦。
2)關系抽取模板,如圖7所示。
3)實驗結果,如圖8所標。
3.4領域圖譜可視化
在關系抽取實驗基礎上,將抽取關系對采用可視化技術,獲得關金礦領域關系圖譜如圖9所示。

圖5 Bootstrapping第一輪二元關系抽取模板

圖6 Bootstrapping第一輪二元關系實驗結果

圖7 Bootstrapping第二輪關系抽取模板

圖8 Bootstrapping第二輪二元關系實驗結果
4 結 論
科學文獻是記錄、傳播知識的重要的載體,在學科領域交叉日益深入的今天,越來越多的科研工作者認識到科學文獻的挖掘分析是發現新知識的一個有效方式。本文通過對地質專業文獻數據的挖掘,結合自然語言處理、機器學習等方法,驗證了一套基于文獻數據的知識發現解決方案,包括數據處理、分詞/詞性標注、關系抽取算法與模型研發(關系發現、關系擴展)等環節。下一步研究將在不斷完善關系抽取模型的基礎上構建可視化圖譜,并進一步深入擴展圖譜的應用,實現例如基于知識圖譜的熱點、趨勢發現等功能,從而使地質文獻資源內容展示的程度進一步加深、資源之間的內部聯系更加一目了然,為成礦預測決策和科研提供快捷的知識獲取服務。

圖9 金礦領域知識圖譜
[1] 劉石年.成礦預測學[M].長沙:中南工業大學出版社,1993.
[2] 薛順榮,胡光道,丁俊.成礦預測研究現狀及發展趨[J].云南地質,2001,20(4):411-416.
[3] 劉林,芮會超.成礦預測的發展現狀及趨勢[J].地質力學學報,2016,22(2):223-231.
[4] 趙鵬大.找礦理念:從定性到定量[J].地質通報,2011,30(5):625-629.
[5] 王登紅,劉新星,劉麗君.地質大數據的特點及其在成礦規律、成礦系列研究中的應用[J].礦床地質,34(6):1143-1154.
[6] 張樹良,冷伏海.基于文獻的知識發現的應用進展研究[J].情報學報,2006(6):700-712.
[7] Swanson D R.Online Search for Logically Related Non—interactive Medical Literatures:a Systematic Trial and Error Strategy[J].Journal of American Society for Information Science,1989,40(5):356-358.
[8] 黃水清.非相關知識發現方法及在農業經濟學中的應用[D].南京:南京農業大學,2010.
[9] 馮璐,冷伏海.共詞分析方法理論進展[J].中國圖書館學報,2006,32(2):88-92.
[10] 王建芳,冷伏海.共引分析理論與實踐進展[J].中國圖書館學報,2006,32(1):85-88.
[11] Swanson D R,Smalheiser N R.Aninteractivesystemforfinding complementary literatures:a Stimulus to scientific discovery[J].Artificial Intelligence,1997,91:183-203.
[12] Weeber M,Klein H,Lolkjc T W,et a1.Using Concepts in Literature-Based Discovery:Simulating Swanson’S Baynaud-Fish Oil and Migraine-Magnesium Discoveries[J].Journal of the American Society for Information Science and Technology,2001,52(7):548-557.
[13] 田瑞強,姚長青,潘云濤.關聯文獻的知識發現與創新研究進展[J].情報理論與實踐,2013(8):117-123.
[14] 趙瑞雪,鮮國建,寇遠濤,等.大數據環境下的農業知識發現服務探索[J].數字圖書館論壇,2016(9):28-33.
[15] 劉遷,賈惠波.中文信息處理中自動分詞技術的研究與展望.計算機工程與應用[J],2006(3):175-182.
[16] 馮志偉.當前自然語言處理發展的幾個特點[J].暨南大學華文學院學報,2006(1):34-40.
[17] 徐健,張智雄.典型關系抽取系統的技術方法解析[J].數字圖書館論壇,2008(9):13-18.
Theapplicationstudyonmetallogenicprognosisofliterature-basedknowledgediscovery
LYU Pengfei1,2,3,WANG Chunning1,ZHOU Feng1,ZHU Yueqin3,4
(1.National Geological Library of China,Beijing100083,China;2.University of Chinese Academy of Sciences,Beijing100049,China;3.Key Laboratory of Geological Information Technology of Ministry of Land and Resources,Beijing100037,China;4.Development and Research Center,China Geological Survey,Beijing100037,China)
The analysis and data mining of literature is an effective way to find unknown knowledge.This essay put forward research ideas of literature-based knowledge discovery applied in metallogenic prognosis,and building model of Literature-based Knowledge Discovery consisted of geological entity recognition,entity relation recognition and extraction.
literature-based knowledge discovery;metallogenic prognosis;Chinese segmentation;entity relation recognition and extraction
2017-06-27責任編輯:趙奎濤
國土資源部公益性行業科研專項項目資助(編號:201511079)
呂鵬飛(1978-),男,碩士研究生,高級工程師,主要從事地質文獻數據分析與挖掘方面的研究工作,E-mail:23690271@qq.com。
朱月琴(1975-),女,博士,高級工程師,主要從事地質大數據、地圖綜合與可視化研究工作,E-mail:yueqinzhu@163.com。
P208
:A
:1004-4051(2017)09-0085-07
