基于標簽關聯規則的挖掘與研究
2017-09-12 03:48:01劉志剛
科技創新與應用 2017年26期
關鍵詞:服務
劉志剛
摘 要:社會化標簽系統以其巨大的服務商業價值被越來越多的專家學者關注和研究,在社會化標簽系統中,用戶可以按照自己的喜好來對各種網絡資源帖上標簽,能更方便信息的檢索和快速查找。標簽應用技術也逐漸成熟起來,通過傳統的關聯規則挖掘方法,對標簽數據進行標簽預測分析,為用戶推薦有參考價值的標簽,有助于電商提供產品的精準推廣服務,同時促進社會化網絡快速、穩定的發展。將文本挖掘、機器學習技術與標簽數據相結合,利用Apriori算法來進行基于標簽的關聯規則挖掘研究。通過研究結果數據分析可知標簽預測結果,有很好的標簽預測效果,并在各種商業模式的驅動下,作為信息處理的一種抽象形式得到了廣泛關注,各種服務即將快速增長。
關鍵詞:服務;標簽;社會化標簽系統;關聯規則;標簽預測
中圖分類號:TD40 文獻標志碼:A 文章編號:2095-2945(2017)26-0026-02
本文結合目前的研究現狀,利用網絡上的真實數據,結合Apriori算法對標簽數據進行實驗分析,研究一種標簽預測算法,有很好的標簽預測效果。標簽包是標簽預測的一種形式,因此文章在標簽包的基礎上、結合標簽的關聯規則挖掘框架,并進行了實驗分析,給出了實驗結果和后續研究的方向。
1 標簽包
標簽包是一個鏈接資源的總概括,可以稱為標簽頭。另外還有一個更為具體的子標簽集合,可以反映資源的不同方面。利用標簽之間的關系來發現與資源相關的標簽包。標簽不僅能暗示資源的內容,彼此之間含有相似語義關系的一系列標簽能組合起來描述一類具有共同特征的資源。但目前網站中“標簽包”的構建完全依賴用戶手工完成,當用戶已經使用了大量標簽后,無論是采用標簽云還是標簽包的方式,用戶人工選擇標簽都非常復雜。另外,“標簽包”聚合了用戶心中同屬一個類別的網絡資源,用戶瀏覽標注資源時,可以給用戶十分有效的參考。因此,幫助用戶尋找語義相關的標簽,自動完成“標簽包”構建,給用戶進行標簽的實時推薦,是一項非常有意義的工作。
2 基于標簽的關聯規則挖掘框架
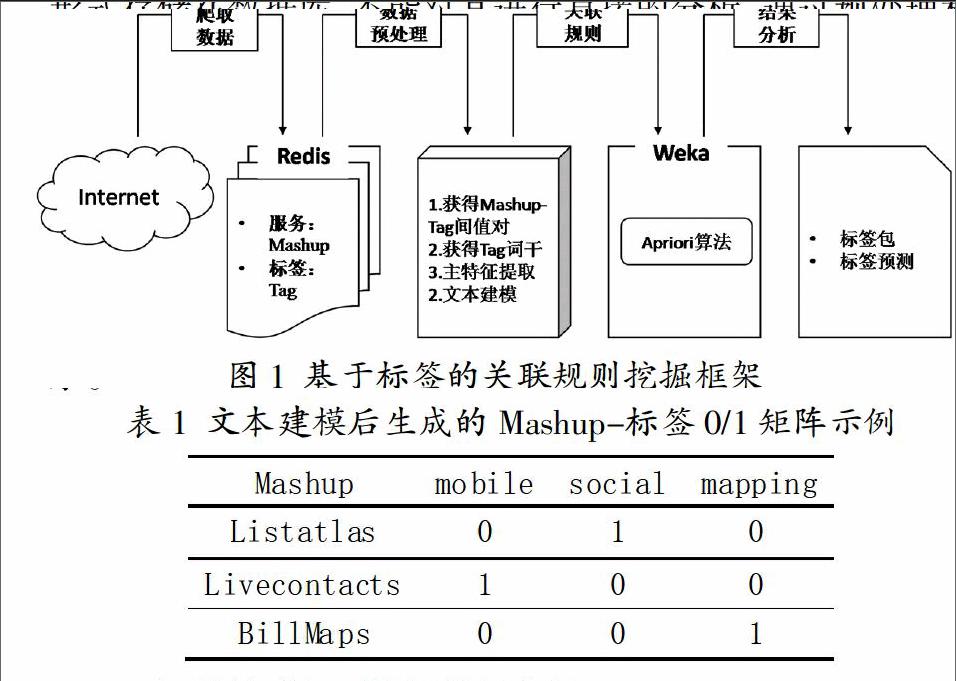
如圖1所示,設計一個關聯規則挖掘框架,包含四個部分:數據獲取;數據預處理;數據利用Apriori算法進行關聯規則挖掘分析建模;結果分析。
研究數據通過網絡爬蟲技術從“http://www.programmableweb.com”網站上爬取得到最新的Mashup、Api和相應的tags數據。在ubuntu12.04系統下,所需配置環境為redis和編ruby爬下來的數據以Key-Value的形式存儲在數據庫redis中。
數據處理先要獲得詞干、接著提取主特征值。獲得詞干:考慮到詞的多態與派生,如mails和mail其在描述服務時是完全相同的,所以需要抽取出基本的詞根。將一些以復數、過去式、現在進行時等形式出現的標簽,通過程序處理生成有相同形式的詞干。主特征提取:通過獲得詞干,生成具有同一形式的標簽集合。剩余的詞項中仍有很多對分析沒有多大貢獻。在標簽集合中含有大量沒有區分度的詞,例如:“result”“information”等,很難解釋所表達的語義信息。同時含有一些沒有代表性的詞,這些稀有詞項獨立表達的信息不強,不足以對關聯規則產生影響。通過利用文檔頻數法(Document Frequency,DF),將在少于50個Mashup服務中出現的關鍵詞去掉,縮減了關鍵詞集合,降低了數據的維度,可以增加關聯規則挖掘的效率,降低時間復雜度,對標簽預測結果帶來比較可觀的提升。
最后文本關聯規則挖掘分析建模:由于標簽是字符串的形式存儲在數據庫,不能對其進行直接的分析。通過預處理和特征選擇,最終得到表示該Mashup服務的關鍵詞集合:Addressdoctor=[validation shipping address mail] 在Mashup服務關鍵詞集合的基礎上,所有的Mashup集合可以表示為一個 M×N的Mashup-Tag矩陣 R,這里每個不同的Mashup對應矩陣 R 的一行;而每一個不同的標簽對應于矩陣 R 中的一列。R表示為:R=[rij],其中rij為0或1,表示第 j個標簽在第i個Mashup服務中是否出現。建模處理后結果數據如表1所示。
3 標簽關聯規則挖掘數據分析
通常基于某種意圖來創建Mashup服務,例如一個與旅游相關的Mashup服務可能是包含了旅游景點的選擇、機票的預定、天氣預報的查看等等一系列功能的服務組合起來構成的。對于這種含有特定功能的Mashup服務,需要為它添加一些類似于“旅游、天氣、酒店、機票”等標簽,當這些標簽同時出現的時候,對一個未知的Mashup就可以預測到這個Mashup服務的主要功能的內容。所以在進行搜索查詢時,可以通過標簽之間的一些關聯規則來快速的定位想要獲取的內容。網站標簽推薦系統可以根據整個網站現有的大量信息,通過挖掘出標簽的頻繁項集,以及標簽與資源之間的關聯,研究標簽經常同時出現的頻率,進行標簽預測,將規范的標簽內容推薦至用戶,使用戶有更好的體驗。
根據所描述研究對象,通過機器學習來挖掘出Mashup的標簽之間的一些關聯規則,對挖掘出來的頻繁項集合關聯規則作出恰當分析。
數據中包含4000個Mashup和相應的1528個標簽(tags)。由于有些標簽的使用量太少(只被幾個Mashup使用過),因此生成的0/1矩陣維度很大,并且數據很稀疏。經過數據預處理后,留下64個使用頻度比較大的標簽作為最終的關聯規則分析的實驗數據。數據中Mashup作為行屬性,tags作為列屬性,Mashup服務Mi如果包含標簽Tj那么陣Mij=1,反之Mij=0。用weka的Aprior算法對輸入的實驗數據M4000x64的0/1矩陣進行試驗,測試數據表明標簽之間的支持度和置信度比較高。因此對于上面提到的標簽預測功能,當用戶輸入像“lyrics”的標簽,可以預測出另外一個標簽“music”很有可能是用戶有意圖使用的標簽,同樣的如果用戶輸入像“mapping”的標簽時,可以給他推薦另外的“travel,hotels”的標簽,挖掘出標簽mapping的標簽包,如下圖2所示。
4 結束語
通過解決社會標簽預測問題有兩個優點:(1)能掌握標簽最基本的“信息內容”;(2)可以使用一個標簽的預測來改善社會標簽網站。后續研究可以通過以下2種方法進行改進:
增加單標簽查詢的召回率。在標簽系統中,大部分的查詢對象都有被一個特定的標簽標記過。同樣,許多標簽系統允許用戶監控標有特定標簽的資源。例如,一個社會書簽網站的用戶可能會成立一個與“攝影”標簽相關的網頁導航。標簽的預測可以作為一種查詢和導航的召回率提高策略。
用戶間的協同。許多用戶具有相似的興趣,但可能使用不同的詞匯。標簽的預測將實現對象的輕松共享,盡管詞匯之間存在一定的差異。
參考文獻:
[1]魏建良,朱慶華,基于社會化標注的個性化推薦研究進展[J].情報學報,2010,29(4):625-633.endprint
猜你喜歡
杭州金融研修學院學報(2022年5期)2022-06-15 11:41:48
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年11期)2019-08-13 00:49:08
今日農業(2019年13期)2019-08-12 07:59:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
銅仁學院學報(2018年4期)2018-06-13 03:21:34
商周刊(2017年9期)2017-08-22 02:57:56
