基于DAE-RBM-PLDA的說話人確認信道補償技術(shù)*
2017-09-03 09:17:09尹主峰徐志京
網(wǎng)絡安全與數(shù)據(jù)管理 2017年15期
尹主峰,徐志京
(上海海事大學 信息工程學院,上海 201306)
基于DAE-RBM-PLDA的說話人確認信道補償技術(shù)*
尹主峰,徐志京
(上海海事大學 信息工程學院,上海 201306)
在說話人識別系統(tǒng)中,一種結(jié)合深度神經(jīng)網(wǎng)路(DNN)、身份認證矢量(i-vector)和概率線性鑒別分析(PLDA)的模型被證明十分有效。為進一步提升PLDA模型信道補償?shù)男阅埽瑢⒔翟胱詣泳幋a器(DAE)和受限玻爾茲曼機(RBM)以及它們的組合(DAE-RBM)分別應用到信道補償PLDA模型端,降低說話人i-vector空間信道信息的影響。實驗表明相比標準PLDA系統(tǒng),基于DAE-PLDA和RBM-PLDA的識別系統(tǒng)的等錯誤率(EER)和檢測代價函數(shù)(DCF)都顯著降低,結(jié)合兩者優(yōu)勢的DAE-RBM-PLDA使系統(tǒng)識別性能得到了進一步提升。
說話人識別;i-vector;降噪自動編碼器;受限玻爾茲曼機
0 引言
說話人識別屬于生物特征識別技術(shù)的一種,是一項從說話人語音中提取有效特征信息進行說話人識別的技術(shù)。比較流行的說話人識別模型是建立在以混合高斯模型-通用背景模型(GMM-UBM)[1]的基礎上。隨后Patrick等人提出聯(lián)合因子分析(JFA)[2],Najim 等提出全局差異空間因子( i-vector)[3]等建模方法。當前i-vector已成為文本無關的說話人識別最有效的技術(shù),這個框架可以被分為3個步驟:(1)利用GMM-UBM把語音聲學特征序列表示成充分統(tǒng)計量;(2)轉(zhuǎn)換成低維的特征向量i-vector,提取i-vector;(3)使用PLDA模型進行信道補償并通過比較不同語音段的i-vector產(chǎn)生驗證分數(shù)得出判決結(jié)果。
近年來,深度神經(jīng)網(wǎng)路DNN被成功應用于語音識別領域[4]。在說話人識別領域,Lei等[5]利用DNN對語音特征根據(jù)音素分類到不同音素空間中,然后在每個空間中對特征降維提取出不同發(fā)音的聲學特征,提出基于DNN的i-vector。該模型把UBM中計算各類后驗概率的方法利用DNN輸出層Softmax的輸出來表示,為說話人確認帶來顯著的性能提升。
降噪自動編碼器(DAE)可通過訓練從損壞的數(shù)據(jù)重構(gòu)出原始數(shù)據(jù)。把說話人的特征表示i-vector受說話人信道信息的影響看成是受損的數(shù)據(jù)。因此通過DAE重構(gòu)的方法進行信道補償可以獲得更加魯棒的效果,產(chǎn)生抗噪能力,從而降低說話人的信道差異性。在文獻[6]中,基于RBM-PLDA的信道補償技術(shù)被證明性能優(yōu)于傳統(tǒng)PLDA。RBM通過分離出說話人信息和信道信息重構(gòu)i-vector,然后把包含說話人信息的因子應用于PLDA端進行比較。本文結(jié)合DAE和RBM各自的優(yōu)點提出基于DAE-RBM-PLDA的信道補償方法,從而進一步降低說話人信道多樣性的影響。
1 基于i-vector的說話人識別系統(tǒng)
1.1 GMM i-vector技術(shù)
i-vector因子分析模型將說話人差異空間與信道差異空間作為一個整體進行建模。模型建立在GMM-UBM所表示的均值超矢量之上。說話人的一段語音相對應的均值超矢量可以分解為下式:
M=m+Tω
(1)
其中,m為UBM的均值超矢量,T為低秩的全局差異空間矩陣,ω為全局差異空間因子,它的后驗均值即為i-vector矢量。
在i-vector的提取過程中需要使用EM算法估計全局差異空間矩陣T,提取Baum—Welch統(tǒng)計量,說話人s的語音段h在第j個GMM混合成分的零階統(tǒng)計量和一階統(tǒng)計量分別為:
(2)
(3)
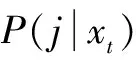
(4)
然后進行如下計算即可得到對應的i-vector:
ωh=E[Wh]=I-1TT∑-1Fh
(5)
1.2 DNN i-vector技術(shù)
GMM具有強大的擬合能力,但它不能有效地對非線性或近似非線性的數(shù)據(jù)進行建模是它的不足之處。因此DNN被應用于聲學建模中,DNN的多層非線性結(jié)構(gòu)使其具有強大的表征能力,它使用無監(jiān)督生成式算法進行預訓練,然后使用反向傳播算法進行參數(shù)微調(diào)。
DNN由輸入層、多隱藏層和Softmax輸出層構(gòu)成。Softmax層給出的是綁定三因素狀態(tài)類在語音幀上的后驗概率P(j|xt) ,它被用作對應高斯上的占有率,代入式(2)和式(3)可以估計出DNN i-vector的零階統(tǒng)計量和一階統(tǒng)計量,然后根據(jù)式(5)提取i-vcetor。基于DNN的i-vector提取過程及判別過程如圖1所示。
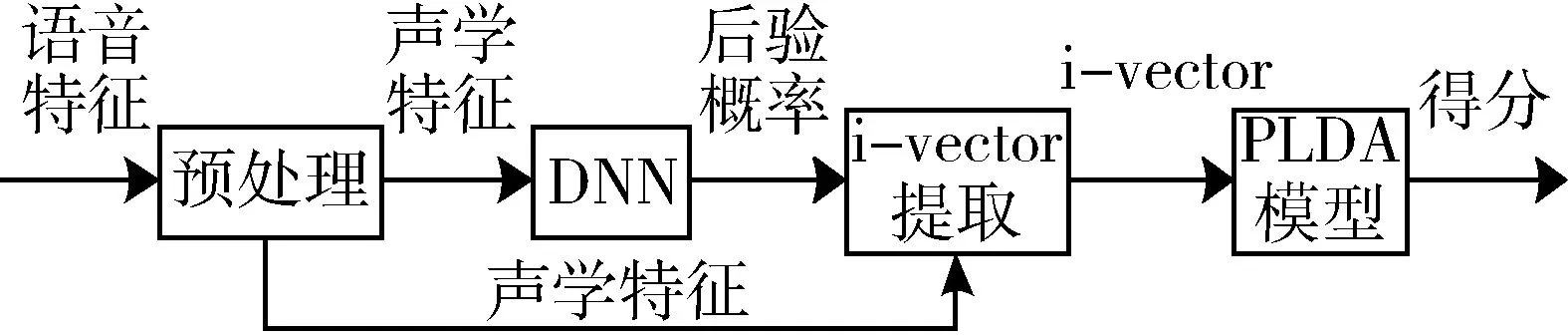
圖1 基于DNN的說話人識別系統(tǒng)流程圖
2 后端PLDA技術(shù)分析
2.1 PLDA模型
PLDA是一種基于i-vector的信道補償算法,i-vector特征包含說話人信息和信道信息。要提取說話人信息,所以需要進行信道補償,去除信道的干擾。經(jīng)過簡化的PLDA被證明是信道補償?shù)挠行Х椒╗7]。簡化的PLDA模型如下式所示:
ωsh=μ+Vys+zsh
(6)
其中,ωsh表示第s個人第h段語音的i-vector,μ為所有訓練數(shù)據(jù)的均值,矩陣V描述說話人的子空間,表征說話人類間差異,ys為隱藏說話人因子,zsh為殘差噪聲。以上參數(shù)滿足如下分布:
ys~N(0,1)
(7)
zsh~N(0,D)
(8)
PLDA訓練階段的目的是根據(jù)一定樣本的說話人語音數(shù)據(jù)集用EM算法估計出模型需要的參數(shù)θ={μ,V,D}。模型訓練好之后進行識別打分,給定相同說話人注冊和測試的i-vector分別為ωe和ωs,采用下式計算似然比分數(shù):
(9)
其中H0表示ωe和ωs來自同一說話人,H1表示來自不同說話人。計算兩個高斯函數(shù)的似然比作為得分進行最終判決。
2.2 基于DAE和RBM的PLDA
降噪自編碼器(DAE)是一種通過特殊訓練得到的自編碼器。在輸入中接受受損數(shù)據(jù)作為輸入,并訓練來預測原始未損壞數(shù)據(jù)作為輸出的自動編碼器,使其產(chǎn)生抗噪能力,從而得到更加魯棒的數(shù)據(jù)重構(gòu)效果。DAE的訓練過程如圖2所示。引入一個損壞過程C(y|x),這個條件代表給定數(shù)據(jù)x產(chǎn)生損壞樣本y的概率。自動編碼器假設x是原始輸入,降噪自動編碼器利用C(y|x)引入損壞樣本y。然后把y當作帶噪聲的損壞輸入,把x當作輸出,對自編碼進行學習訓練。把DAE應用到說話人識別系統(tǒng)后端模型最早在文獻[8]中被提出,本文將在此基礎上繼續(xù)探討進一步提升系統(tǒng)性能。在本系統(tǒng)中把說話人的i-vector受說話人信道信息的影響看成受損的數(shù)據(jù),其訓練可簡化為如下過程。
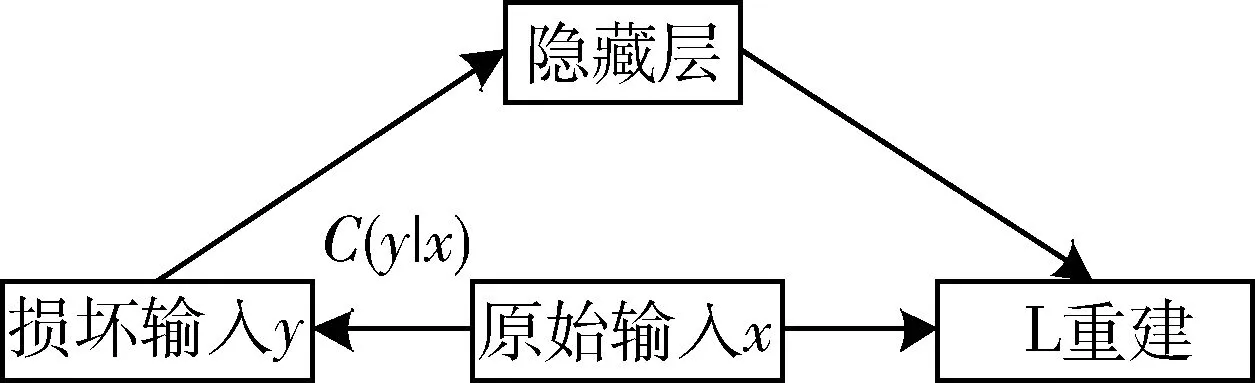
圖2 DAE結(jié)構(gòu)原理圖
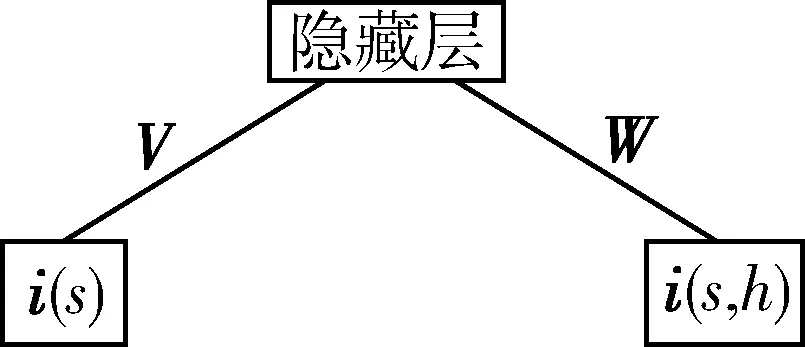
圖3 RBM預訓練
實驗中DAE的訓練過程是先按圖3進行RBM預訓練。隱含層神經(jīng)元取二進制值并服從伯努利分布,可見層神經(jīng)元連接兩個服從高斯分布的實數(shù)值向量i(s)和i(s,h)作為輸入。其中向量i(s)表示說話人s的所有語音段的平均i-vector,向量i(s,h)表示從說話人s的第h段語音提取的i-vector。RBM的訓練用CD算法[9],權(quán)重矩陣參數(shù)V、W用來初始化DAE模型。
預訓練之后把模型展開成如圖4所示,此模型可以看作標準DAE模型來重建i-vector。輸出端采用說話人平均i-vector降低說話人信道信息的差異性。之后采用反向傳播算法對網(wǎng)絡參數(shù)進行調(diào)優(yōu)。DAE的輸出經(jīng)白化和長度規(guī)整處理后可直接作為標準PLDA模型的輸入(DAE-PLDA)進行得分驗證并根據(jù)事先設定的閾值進行判決。
RBM是一種由隨機性的一層可見層神經(jīng)元和一層隱藏神經(jīng)元所構(gòu)成的無向圖模型。它可以作用于PLDA信道補償端,隱藏層被分解為說話人信息因子和信道信息因子,如圖5所示。采用文獻[6]類似的算法進行訓練,不同之處是為保持與前文DAE預訓練時隱藏層數(shù)值類型一致,這里隱藏層采用二進制數(shù)值并服從高斯伯努利分布。進入識別階段,可見層輸入說話人的i-vector,輸出端包含說話人信息的說話人因子作為PLDA模型(RBM-PLDA)的輸入來進行得分比較。
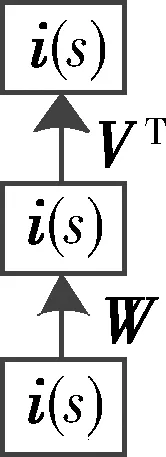
圖4 DAE

圖5 RBM-PLDA
由以上分析可知,基于DAE是無損轉(zhuǎn)換和RBM的有效特征提取原理。考慮使用DAE和RBM混合的方法,第一層為DAE,經(jīng)白化和長度規(guī)整技術(shù)處理后輸出作為RBM的輸入,RBM與標準PLDA結(jié)合后組成判別模型,記為DAE-RBM-PLDA。系統(tǒng)框圖如圖6所示。
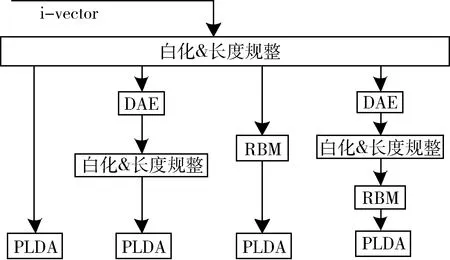
圖6 PLDA、DAE-PLDA、RBM-PLDA、DAE-RBM-PLDA流程
3 實驗與結(jié)果
本文采用TIMIT語料庫作為實驗語音數(shù)據(jù)庫,采用等錯誤率(EER)和檢測代價函數(shù)(DCF)作為性能評價指標。
在UBM i-vector系統(tǒng)中使用MFCC加一維能量及其一、二階差分共39維MFCC特征。語音幀長25 ms,幀移10 ms。DNN i-vector系統(tǒng)中DNN說話人特征為40維Filter Bank特征以及一、二階差分共120維。DNN共5個隱藏層,每層2 048個結(jié)點。首先比較了標準PLDA模型在UBM i-vector和DNN i-vector系統(tǒng)下的性能,實驗證明DNN系統(tǒng)的識別性能比GMM-UBM系統(tǒng)顯著提高。之后以DNN i-vector的PLDA為基線系統(tǒng),性能對比如圖7和表1所示。
由表1實驗結(jié)果可以看到,相對于標準PLDA模型系統(tǒng),應用深度學習模型的DAE-PLDA和RBM-PLDA后端信道補償模型等錯誤率和檢測代價函數(shù)都顯著降低。將兩者結(jié)合后的DAE-RBM-PLDA模型,性能提升更加明顯,相對于基線系統(tǒng)性能提升了14.5%,體現(xiàn)了該信道補償方法的有效性。
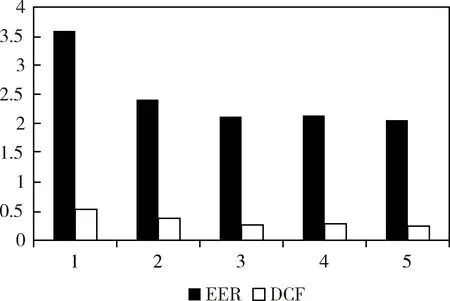
圖7 模型性能柱狀圖
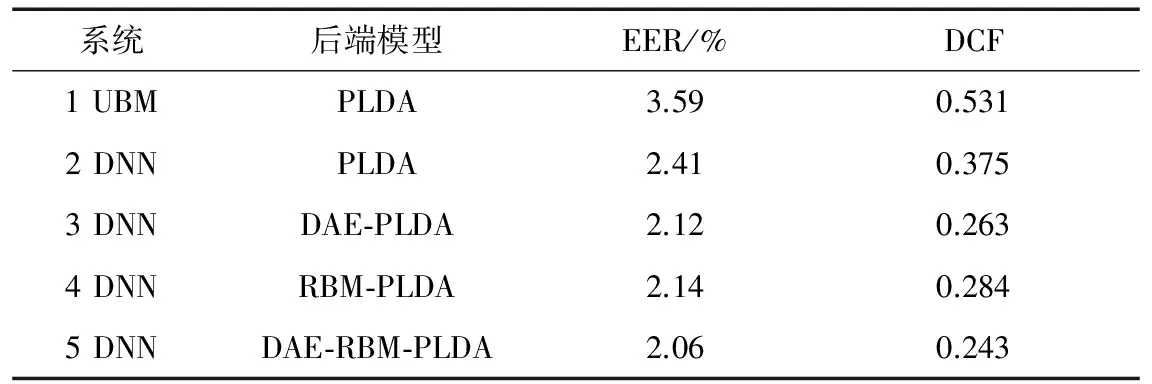
表1 PLDA、DAE-PLDA、RBM-PLDA、DAE-RBM-PLDA性能比較
4 結(jié)論
本文結(jié)合DAE和RBM的優(yōu)點提出了基于DAE-RBM-PLDA的說話人確認信道補償方法。該方法先把經(jīng)過白化和長度規(guī)整技術(shù)處理的i-vector進行RBM預訓練并初始化DAE模型,DAE的輸出為說話人所有語音段的平均i-vector,從而降低了說話人信道信息的影響。然后與RBM相結(jié)合,把DAE的輸出i-vector作為RBM的輸入,隱含層重構(gòu)分離出說話人信息和說話人信道信息,選擇實驗需要的說話人信息進行后端PLDA最終的似然比分數(shù),進一步降低了說話人的信道差異性。在TIMIT數(shù)據(jù)集上的說話人確認實驗表明結(jié)合了DAE和RBM兩者優(yōu)勢的DAE-RBM-PLDA模型,可有效提高識別率。
[1] REYNOLDS D A, QUATIERI T F, DUNN R B. Speaker verification using adapted Gaussian mixture models[J]. Digital Signal Processing, 2000, 10(1-3): 19-41.
[2] KENNY P,OUELLET P,DEHAK N,et al. A study of interspeakervariability in speaker verification[J]. IEEE Transaction on Audio,Speech, and Language Processing, 2008,16(5): 980-988.
[3] DEHAK N,KENNY P,DEHAK R,et al. Front-end factor analysis for speaker verification[J]. IEEE Transactions on Audio,Speech,and Language Processing,2011,19(4): 788-798.
[4] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[5] VARIANI E, LEI X, MCDERMOTT E, et al. Deep neural networks for small footprint text-dependent speaker verification[C]. 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014: 4052-4056.
[6] STAFYLAKIS T, KENNY P, SENOUSSAOUI M, et al. PLDA using gaussian restricted boltzmann machines with application to speaker verification[C].Interspeech, 2012: 1692-1695.
[7] GARCIA-ROMERO D, ESPY-WILSON C Y. Analysis of i-vector length normalization in speaker recognition systems[C].Interspeech, 2011: 249-252.
[8] NOVOSELOV S, PEKHOVSKY T, KUDASHEV O, et al. Non-linear PLDA for i-vector speaker verification[C].Interspeech, 2015: 214-218.
[9] HINTON G E. A practical guide to training restricted boltzmann machines[M].Neural Networks: Tricks of the Trade. Springer Berlin Heidelberg, 2012: 599-619.
Technology of speaker verification channel compensation based on DAE-RBM-PLDA
Yin Zhufeng, Xu Zhijing
(College of Information Engineering, Shanghai Maritime University, Shanghai 201306, China)
A hybrid model combining the deep neural network (DNN), i-vector and probabilistic linear discriminant analysis (PLDA) has been shown effective in the system of speaker recognition. In order to improve the performance of PLDA recognition model, the denoising autoencoder (DAE) and restricted boltzmann machine(RBM) and the combination of them(DAE-RBM) are used to channel compensation on PLDA model to minimize the effect of the speaker i-vector space channel information. The experiment showed that the recognition system based on DAE-PLDA and RBM-PLDA is significantly decreased than the standard PLDA for the equal error rate(EER) and detection function(DCF). The DAE-RBM-PLDA which combined with the advantages of them makes the performance of the recognition system has been further improved.
speaker recognition; i-vector; denoising autoencoders; restricted boltzmann machine
國家自然科學基金項目(61404083)
TP391
A
10.19358/j.issn.1674- 7720.2017.15.018
尹主峰,徐志京.基于DAE-RBM-PLDA的說話人確認信道補償技術(shù)[J].微型機與應用,2017,36(15):62-64,72.
2017-03-02)
尹主峰(1986-),男,碩士研究生,主要研究方向:智能信息處理。
徐志京(1972-),男,工學博士,副教授,主要研究方向:無線通信和導航技術(shù)、人工智能、深度學習。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
