基于結構與屬性的社區劃分方法
2017-09-01 15:54:43萬新貴李玲娟
計算機技術與發展 2017年8期
萬新貴,李玲娟
(南京郵電大學 計算機學院,江蘇 南京 210003)
基于結構與屬性的社區劃分方法
萬新貴,李玲娟
(南京郵電大學 計算機學院,江蘇 南京 210003)
目前通行的社區劃分方法大多基于結構,但單純基于結構的劃分不能挖掘出社區對象的潛在關系,因而不能發現社區的變化趨勢。為此,提出了基于結構的社區劃分算法(Community Division based on Structure,CDS)。該算法利用度和節點歐氏距離對社會網絡進行結構劃分;同時針對經典K-means算法在社區劃分中所存在的隨機選取初始中心點以及k值選取不合理所導致的聚類結果不佳問題,提出了一種基于社區結構的非人為設定k值的K-means算法—NPCluster(Non Presetting Cluster)算法。該算法基于由CDS算法所提到的社區結構,依次選取度最大的節點作為聚類中心點,以小于平均特征歐氏距離為基準合并簇集,反復迭代直至聚類完成。理論分析和對比實驗結果表明,CDS算法能夠有效劃分出社區結構;相對于K-means算法,NPCluster算法在已劃分的社區結構上具有更高的聚類精度和更好的時效性;結構與屬性相結合的社區劃分方法是有效可行的。
社區劃分;度;K-means;中心點;歐氏距離
0 引 言
在社會網絡研究[1-3]中關心的兩個方面是聯系和結構。目前基于結構角度的社區劃分研究比較充分,但是單純基于結構的劃分(稱為硬劃分)對社區內對象的潛在關系(比如興趣的異同等)表現不夠。而這種潛在關系的發現(稱為軟劃分)對預測社會網絡社區的變化趨勢有著重要的參考價值。
數據挖掘(Data Mining)[4]一般是指從大量的數據中通過算法搜索隱藏于其中信息的過程。聚類挖掘[5]是數據挖掘的算法之一,它將大量的數據劃分為性質相同的子類,以便于了解數據的分布情況,挖掘結果具有簇內高相似性和簇間低相似性,聚類挖掘的性質相當符合社會網絡社區的特點。
聚類挖掘算法[6]主要分為四大類:基于劃分的聚類算法、基于層次的聚類算法、基于密度的聚類算法以及基于網格的聚類算法。不同類別的聚類算法適用于不同的應用場景。K-means算法[7]作為聚類算法中經典的劃分算法,其最大優勢在于簡潔和快速,在實踐中應用廣泛。該算法簡單,易于理解和可擴展,并且很容易修改以便處理不同的數據,例如無監督性學習或流數據。但K-means算法仍有值得改進的地方,隨機選擇中心點以及人為設定k值是K-means算法最大的缺陷,針對這些缺陷,提出了許多改進算法[8-12]。
為了將軟劃分與硬劃分進行有效結合,設計了社區結構建立算法(Community Division based on Structure,CDS)。該算法利用節點度與節點歐氏距離實現了社區中心的選擇,完成了社區結構的建立;并基于CDS算法,提出一種非人為預先設定k值的聚類算法—NPCluster(Non Presetting ClusterK-means)。該算法的原理與CDS算法類似,同樣基于節點度設置聚類中心,避免了k值的不合理設置導致的聚類結果不理想;基于特征歐氏距離進行聚類,實現多維數據集的類別劃分。兩種算法總體實現了社會網絡的硬劃分與軟劃分的結合。
1 相關工作
1.1 基本定義
定義1(特征歐氏距離):數據集中每個數據點可以定義為Xi=(Xi1,Xi2,…,Xid),d為數據點的維度,即特征的個數,則特征歐幾里得距離的計算公式為:
(1)
D值越小,代表兩個數據點的特征相似度越大,從而可以將這兩個數據點劃分到一個簇集中。
定義2(節點歐氏距離):假設有M個節點,可以把節點集定義為X=(X1,X2,…,Xm),Xij表示節點Xi到Xj的最短距離(跳數),則節點歐氏距離定義為:
(2)
D值越小,代表兩個節點的相似度越大,從而可以將這兩個節點劃入同一個社區結構中。
定義3(歐氏距離矩陣及平均歐氏距離):在數據集中,數據點兩兩之間的特征歐氏距離形成特征歐氏距離矩陣;在無向圖中的定義與在數據集中的定義大致相同,以下特征歐氏距離與節點歐氏距離統稱歐氏距離。
平均歐氏距離是由歐氏距離矩陣決定的,將歐氏距離矩陣求和再除以數據點數,得到平均歐氏距離。隨著迭代過程的進行,數據點逐漸減少,歐氏距離矩陣將隨數據點的變動進行更新,平均歐氏距離也會隨之改變。
定義4(度及度的計算):在無向圖中,每個節點連邊的條數就是該節點的度數。
度的計算是根據節點的關系矩陣R來確定的,點Xi與Xj之間有邊,則rij=1,反之rij=0。按行讀取矩陣R,將i行中的值相加,即得到點Xi的度。
1.2 社區劃分
現實世界中,社會網絡[1,13]以各種關系網絡存在于多個領域,社會網絡分析已經成為數據挖掘中的一個研究熱點,而社區劃分則是社會網絡分析中的一項重要內容。社區發現的研究已取得了很多成果,使用聚類算法進行社區劃分的研究比較普遍。
大多數實際網絡都有一個共同的性質,即社區結構。整個網絡就是由若干個“社區”或“組”構成的,而這些社區則具有社區內部高內聚、社區之間低內聚的特性,所以揭示網絡的社區結構對于深入了解網絡結構與分析網絡特性是很重要的。
在社區劃分的研究中,社區劃分的算法所要劃分的網絡大致分為兩類:比較常見的網絡(僅包含正聯系的網絡)和符號社會網絡(網絡中既包含正向聯系的邊,也包含負向聯系的邊)。
社區劃分算法有很多種,比較經典的三種是[14]:Kernighan-Lin算法、基于Laplace圖特征值的譜二分法和GN算法。
1.3K-means算法
K-means算法是一種基于樣本間相似性度量的間接聚類方法,屬于非監督學習方法。此算法以k為參數,將n個對象分為k個簇,以使簇內相似度較高,而簇間相似度較低。
K-means算法描述如下:
算法1:K-means算法。
輸入:數據集,k值;
輸出:簇集。
(1)適當選擇k個類的初始中心;
(2)在第m次迭代中,對任意一個樣本,求其到k的歐氏距離,將該樣本歸到距離最短的中心所在的類;
(3)利用均值更新該類的中心值;
(4)對于所有的k個聚類中心,如果利用步驟2和步驟3迭代更新后,值保持不變,則迭代結束,否則繼續迭代。
K-means算法需要人為確定k值的大小,并且算法隨機選取初始簇心,對初始簇心非常敏感,因此針對K-means算法的改進主要從這兩方面入手。
2 CDS算法
2.1 算法基本思想
基于硬劃分方法產生的社區結構是進行軟劃分的基礎。因此,首先設計一種建立社區結構的算法-CDS算法。該算法的基本思想是:首先計算各節點的度值,選取度值最大的節點作為中心節點;然后計算所有節點之間的歐氏距離,形成節點歐氏距離矩陣,計算得出平均節點歐氏距離;將除中心節點以外的節點與中心節點的節點歐氏距離進行比對,當節點歐氏距離小于平均節點歐氏距離時,將此節點納入該中心節點所在的社區,算法迭代至所有節點都被納入社區。
以節點度的大小作為中心點的選擇依據,符合社會網絡中度越大凝聚力越強的物理意義;以平均節點歐氏距離作為聚類的標準符合社會網絡中,距離同一節點的跳數越接近,節點之間越接近的物理意義。
2.2 算法流程與描述
CDS算法的主體流程如圖1所示。
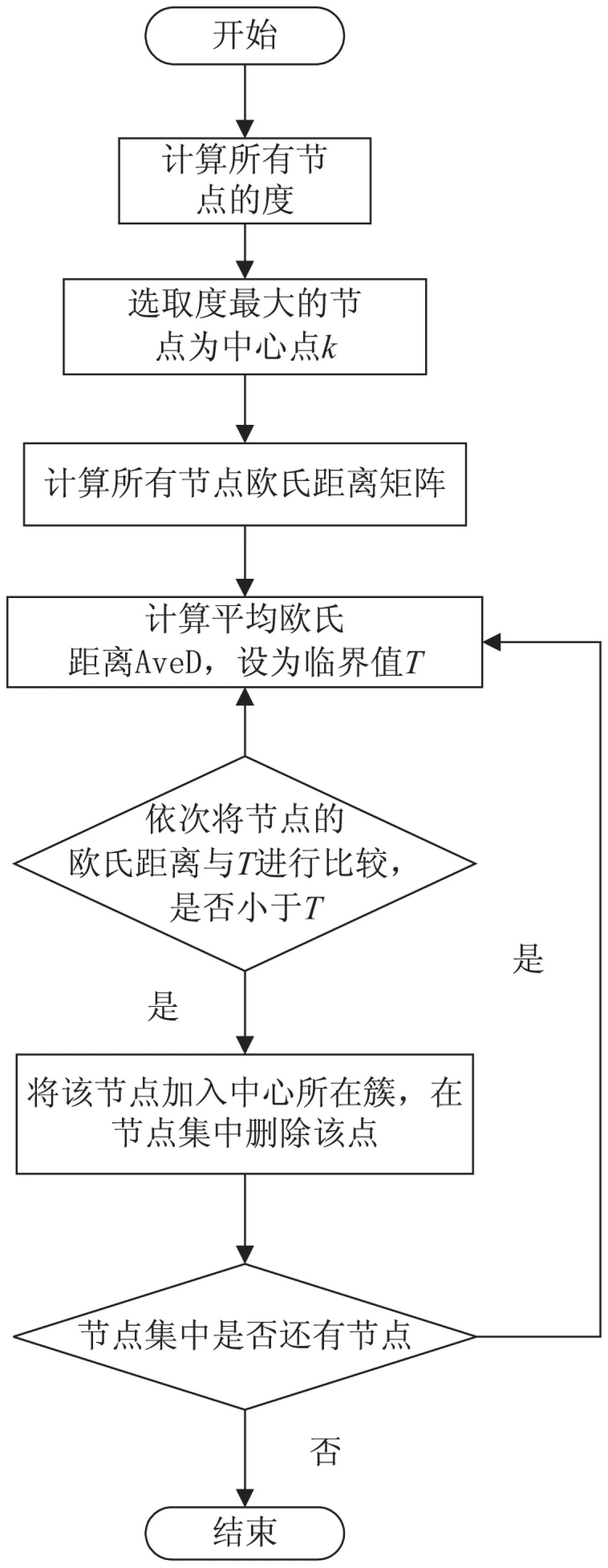
圖1 CDS算法流程圖
CDS算法具體描述如下:
算法2:社區結構建立算法。
輸入:一個無向無權網絡G=
輸出:網絡的社區結構。
(1)計算所有節點的度degree;
(2)找出現有節點中degree最大的節點,設置為中心節點k;
(3)計算所有節點的節點歐氏距離矩陣;
(4)計算節點集中節點的平均歐氏距離AveD,將之設定為臨界值T;
(5)將各個非中心節點與中心節點的歐氏距離與T進行比較,若小于T,則將該點加入社區結構,在節點集中刪除該點;
(6)重復步驟4和5,當節點集中沒有節點時,社區劃分完成。
3 NPCluster算法
3.1 NPCluster算法思想
K-means算法的k值需事先確定,自主設定k值并不能保證合理性。假設被聚類的數據集中的數據點之間已經非常靠近,不需要進一步分類,但是由于人為設定的k值,數據集被聚集為k類。顯然上述算法得到的結果是不合理的。針對這種情況,提出一種基于已建立的社區結構的非人為預先設定k值的聚類算法-NPCluster算法。
在一個數據集(社區)中,某個數據點(節點)的度直接反映了這個點在該社區中的結構地位,即度越大,這個點越靠近所在社區的中心。若根據度來選擇聚類中心,即可避免人為確定k值和隨機選擇聚類中心點。兩個數據點之間的距離一般用特征歐氏距離表示,特征歐氏距離越小,表示這兩個點越靠近。如果用數據點的多維特征作為數據點歐氏距離計算的基礎,那么有理由相信,特征歐氏距離越小,兩者的整體特征越接近。所以,以度作為中心點的選擇,以特征歐氏距離作為聚類閾值的算法思想是可行的,并且同時兼顧了社會網絡的結構和內在關系兩個方面。
NPCluster算法的基本思想是:首先計算數據點的特征歐氏距離矩陣,求得平均特征歐氏距離;然后選取度最大的數據點作為聚類中心點,將剩余數據點與中心點的特征歐氏距離與平均特征歐氏距離進行比對,若小于平均特征歐氏距離,則將該點劃入中心點所在簇;迭代直至所有數據點都被劃分,最后一個簇內的數據點在特定情況下可以視為孤立點。
該算法結合了數據點的結構關系和特征關系,基于這種聚類的社區劃分是一種軟硬劃分的結合,聚類結果更符合社區的物理意義,也有其特殊的應用價值。由于NPCluster算法必須基于已建立的社區結構,所以算法的聚類結果會受到社區結構的影響,并且該算法不適用于一般無結構的數據集,僅適用于社會網絡。
3.2 NPCluster算法流程與描述
NPCluster算法的主體流程如圖2所示。
NPCluster算法的具體描述如下:
算法3:NPCluster算法。
輸入:數據集;
輸出:簇集。
(1)計算所有數據點的度degree;
(2)選取現有數據點中度值最大的數據點,設置為簇心k;
(3)計算所有數據點的特征歐氏距離矩陣;
(4)求出數據集中所有數據點的平均特征歐氏距離AveD,將之設定為臨界值T;
(5)將各非中心點與中心點的特征歐氏距離逐一與T進行比較,若小于T,則將該點加入該簇,并將該點從數據集中刪除;
(6)重復步驟3~5,當數據集中沒有數據點時,聚類結束。
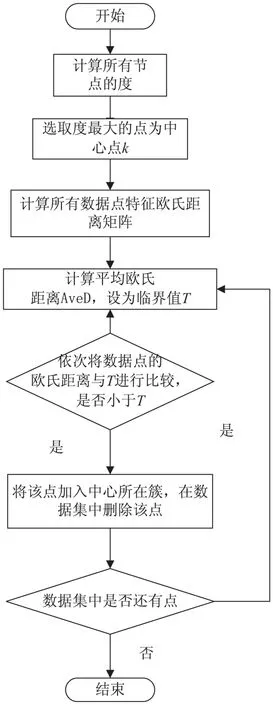
圖2 NPCluster算法流程圖
實現該算法的程序中涉及到的方法主要有:
(1)caldistance(String file)方法:根據多維特征計算所有數據點之間的特征歐氏距離,形成特征歐氏距離矩陣;
(2)avgdistance(double[][] a)方法:根據已得出的歐氏距離矩陣與數據點的數量,計算所有數據點的平均特征歐氏距離;
(3)Caldegree(String file)方法:根據度矩陣計算所有數據點的度;
(4)findmaxdegree(Map
通過這些方法,更易于理解NPCluster算法的核心思想。
4 實驗結果及分析
4.1 CDS算法驗證
考慮到NPCluster算法基于已建立的社區結構,所以在NPCluster算法與K-means算法的對比實驗前,需先驗證CDS算法的正確性,以確保整體算法在無結構數據集上仍然具備有效性。
CDS算法驗證數據采用來自空手道俱樂部中的一個社區進行實驗,社區結構圖如圖3所示,具體社區結構如表1所示。
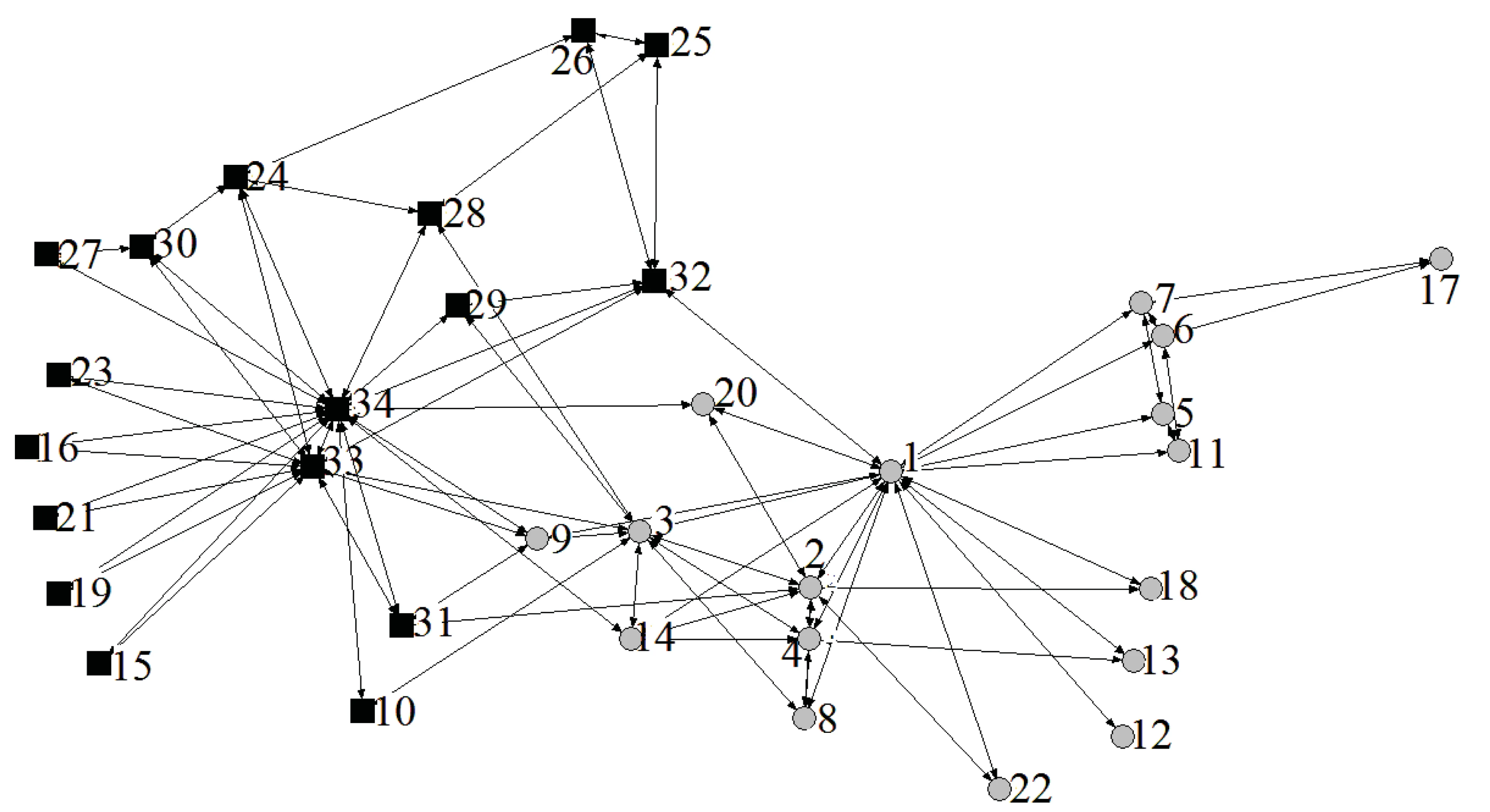
圖3 空手道社區結構圖

社區數字社區110,15,16,19,21,23,24,25,26,27,28,29,30,31,32,33,34社區21,2,3,4,5,6,7,8,9,11,12,13,14,17,18,20,22
由圖3可以看出,實驗數據基于結構共分為兩個社區,圖中數字代表社區中的各節點。
CDS算法社區結構劃分結果如圖4所示。
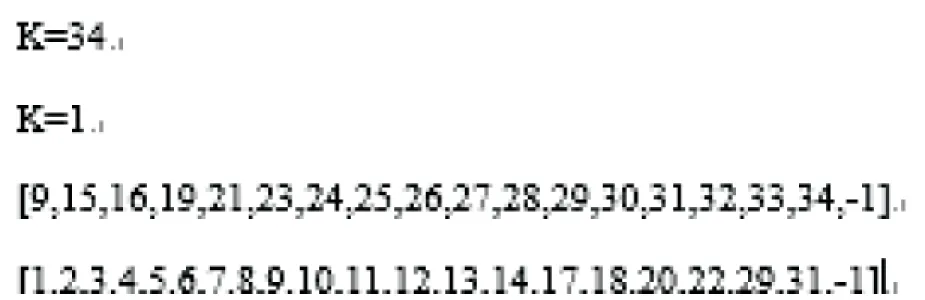
圖4 空手道社區結構劃分圖
由圖4與表1的對比可以看出,節點10被劃分錯誤,節點29和31被同時劃分到兩個社區中,經過計算得到CDS算法社區結構劃分的正確率達到97.06%,實驗結果表明CDS算法是有效的。
4.2 NPCluster算法性能驗證
NPCluster算法與K-means算法的對比實驗采用校內網離散型數據集,該數據集共7 000條6維數據。使用CDS算法進行社區結構劃分得到3個社區,選取人數最多的社區2作為對比數據集。社區2共4 500條數據,按興趣團體共分為3大類。
4.2.1 精確度測試及分析
NPCluster算法與K-means算法的精確度測試結果如圖5所示。其中為確保實驗不受人為因素影響,將K-means算法的k值設置為3,與已知類別數目相同。
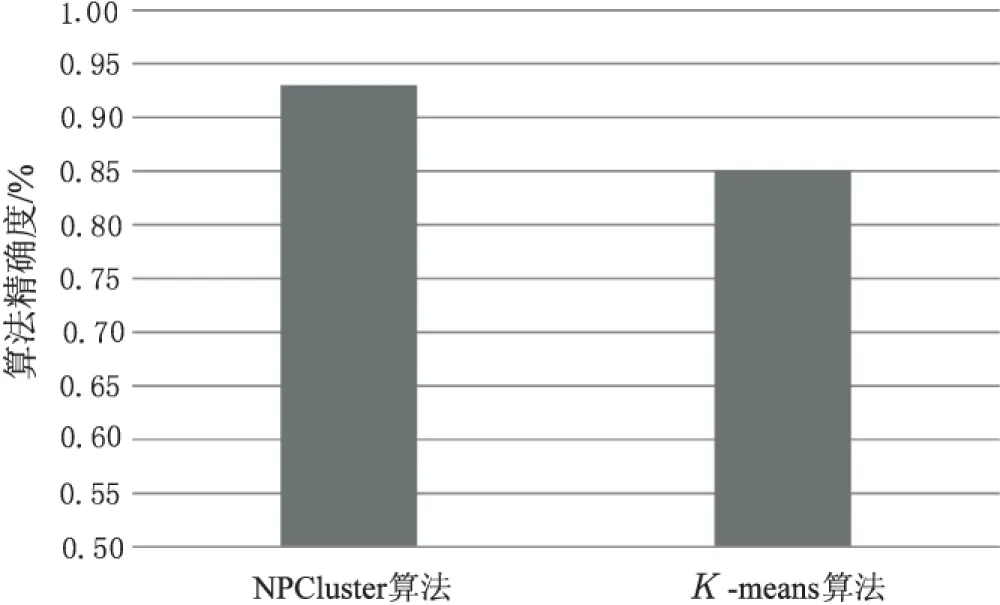
圖5 算法精確度測試結果
從圖5可以看出,NPCluster算法聚類的正確率明顯高于K-means算法,并且NPCluster算法聚類得出的最后一個簇的成員可以看作一個孤立點。
由此可以得出,NPCluster算法相對于基本K-means算法而言有著明顯優勢,既不用人為給定k值,又能找出數據集中的孤立點,且算法精確度更高。
4.2.2 效率測試及分析
NPCluster算法效率測試結果如圖6所示。
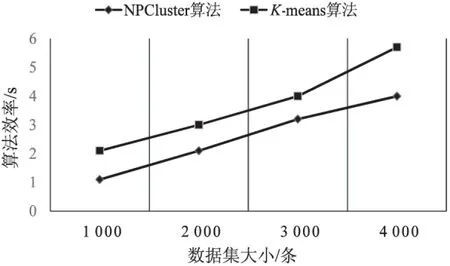
圖6 算法效率測試結果
由圖6可以得出,NPCluster算法效率要高于K-means算法。這是因為K-means算法在迭代選取中心點時消耗的時間較多,而NPCluster算法只需要比較特征歐氏距離即可。考慮到NPCluster算法是基于社區結構的,社區結構的建立過程也有時間消耗,由于算法原理相似,CDS算法的時間消耗與NPCluster算法相當。因此,最終對比結果表明,基于社區結構的NPCluster算法的效率與K-means算法基本持平。
5 結束語
為了研究社會網絡中的社區劃分,并進一步挖掘社區對象的潛在關系,重點研究了基于結構與屬性的社區劃分方法。提出了基于結構的社區劃分算法—CDS,以節點度和節點歐氏距離為社區結構劃分準則,對社會網絡進行結構劃分,形成社區結構。基于上述社區結構,提出了一種非人為設定k值的聚類算法—NPCluster。該算法以節點度作為聚類中心選取依據,以多維特征的平均歐氏距離作為聚類閾值,聚類成功的點在數據集中被刪除,經過多次迭代,直至數據集中不存在點,聚類結束,所產生的簇即對應于社區興趣團體。由于NPCluster算法是基于社區結構來劃分興趣團體的,所以數據點之間基于特征的緊密性呈現會受到社區結構的影響。實驗結果表明,CDS算法能夠以較高的準確度劃分社區結構;NPCluster算法在聚類效果上優于基本K-means算法,總體算法執行效率與K-means算法相當。
NPCluster算法具備無需人為干擾的特性,在社會網絡數據集上具備較好的適應性,能夠發現結構社區下的興趣團體劃分,以及社會網絡軟硬結合的社區劃分。
[1] 宗乾進,袁勤儉,沈洪洲.國外社交網絡研究熱點與前沿[J].圖書情報知識,2012(6):68-75.
[2] 王 亮.基于局部聚類的復雜網絡社區發現算法研究[D].大連:大連理工大學,2011.
[3] 張 鑫,劉秉權,王曉龍.復雜網絡中社區發現方法的研究[J].計算機工程與應用,2015,51(24):1-7.
[4] Wu X,Zhu X,Wu G Q,et al.Data mining with big data[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(1):97-107.
[5] 周 濤,陸惠玲.數據挖掘中聚類算法研究進展[J].計算機工程與應用,2012,48(12):100-111.
[6] Verma M,Srivastava M,Chack N,et al.A comparative study of various clustering algorithms in data mining[J].International Journal of Engineering Research and Applications,2012,2(3):1379-1384.
[7] Krishna K,Murty M N.Genetic K-means algorithm[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics),1999,29(3):433-439.
[8] Celebi M E,Kingravi H A,Vela P A.A comparative study of efficient initialization methods for the k-means clustering algorithm[J].Expert Systems with Applications,2013,40(1):200-210.
[9] 王玉雷,李玲娟.一種密度和劃分結合的聚類算法[J].計算機技術與發展,2015,25(9):53-56.
[10] 尹成祥,張宏軍,張 睿,等.一種改進的K-Means算法[J].計算機技術與發展,2014,24(10):30-33.
[11] 劉莉莉,曹寶香.基于差分進化算法的K-Means算法改進[J].計算機技術與發展,2015,25(10):88-92.
[12] 趙京勝,孫夢丹,張 麗.一種有效的K-means初始中心優化算法[J].信息技術與信息化,2016(5):77-79.
[13] 朱 琪,于濟坤,王明德,等.社會網絡數據的可視化[J].吉林大學學報:信息科學版,2015,33(5):584-587.
[14] 時京晶.三種經典復雜網絡社區結構劃分算法研究[J].電腦與信息技術,2011,19(4):42-43.
Community Division Method with Structure and Attribute
WAN Xin-gui,LI Ling-juan
(School of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Most of the current methods of community division are based on structure,but the structure-based division cannot excavate the potential relationship of community objects,which is not to find the tendencies of community variations.Therefore a community-based partitioning algorithm (Community Division based on Structure,CDS) has been designed which applies degree and node-Euclidean distance to divide social network.Simultaneously,an algorithm by nonhuman (artificial) settingk-value—NPCluster algorithm (Non Presetting Cluster)—based on the community structure has been proposed,which is based on the community structures divided by CDS algorithm and has improved the unsatisfactory clustering outcomes caused by the inappropriateness of random selection of initial centers and that ofKvalue.Thus the maximum degree nodes are chosen as a cluster center in turn and the data are merged and clustered until the average feature-Euclidean distance is less than a given threshold.Theoretical analyses and experimental results show that the proposed CDS algorithm can effectively divide the community structures;compared withK-means algorithm,NPCluster algorithm has higher clustering quality and better clustering timeliness on the divided community;the community division method based on structure and attribute is practical and effective.
community division;degree;K-means;center;Euclidean distance
2016-08-04
2016-11-10 網絡出版時間:2017-06-05
國家自然科學基金資助項目(61302158,61571238)
萬新貴(1991-),女,碩士研究生,CCF會員(E200041361G),研究方向為流數據挖掘;李玲娟,教授,CCF會員(E200015276M),研究方向為數據挖掘、信息安全、分布式計算。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170605.1508.050.html
TP301
A
1673-629X(2017)08-0097-05
10.3969/j.issn.1673-629X.2017.08.020
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
哲學評論(2021年2期)2021-08-22 01:53:34
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
