基于指代消解的漢語句群自動劃分方法
2017-09-01 15:54:43王榮波孫小雪黃孝喜劉和平
計算機技術與發展 2017年8期
關鍵詞:方法
王榮波,孫小雪,黃孝喜,劉和平
(1.杭州電子科技大學 計算機學院,浙江 杭州 310018;2.浙江大學 軟件學院,浙江 杭州 310000)
基于指代消解的漢語句群自動劃分方法
王榮波1,孫小雪1,黃孝喜1,劉和平2
(1.杭州電子科技大學 計算機學院,浙江 杭州 310018;2.浙江大學 軟件學院,浙江 杭州 310000)
漢語句群自動劃分是將篇章劃分成包含不同主題的文本片段,在信息提取、文摘生成、語篇理解及其他多個領域有著極為重要的應用。指代消解是識別篇章中先行詞和照應詞關聯起來的過程,消解不同表達是自然語言理解的基礎之一。針對目前的句群劃分工作的重點在于劃分出主題之間的邊界而較少利用其本身指代關系來進行語言理解,或者因指代模糊而得到錯誤的劃分結果的問題,提出了一種基于指代消解的句群自動劃分方法。該方法從對篇章的指代情況消解出發,利用適合中文的多層過濾指代消解方法得到指代鏈信息,以消除不同名詞代表相同實體、代詞指代不明的問題。結合指代鏈信息,并同時考慮篇章銜接詞因素,設計并進行了基于多元判別分析(Multiple Discriminate Analysis,MDA)的一組評價函數J評價句群劃分驗證實驗。實驗結果表明,所提出的方法能夠有效地進行句群自動劃分,統計正確分割平均Pμ提高了7%左右。
句群劃分;指代消解;多層過濾;多元判別分析
1 概 述
在中文信息處理技術的發展過程中,人們發現傳統的中文語法單位“詞語”、“句子”能夠承載的信息量太小,而“段落”、“篇章”承載的信息量又太大。根據漢語本身的意合特點,語義相關的內容通常會出現在同一片段內,要完全理解一個句子的含義往往需要充分利用其上下文信息[1],因而將篇章段落劃分為不同的句群是篇章理解的重中之重。自然語言中還存在大量的指代現象,篇章理解的另外一個工作就是指代消解,指代消解可以有效避免“一詞多義”和“多詞同義”的問題。指代消解連接了指代詞和先行語,明確了代詞以及有歧義的名詞指向,句群為其內的句子提供了可靠的上下文語境,句群劃分結合指代消解在篇章分析、機器翻譯、自動文摘領域有重要作用[2-3]。
漢語句群自動劃分是將篇章劃分成包含不同主題的文本片段,指代消解是將篇章中的先行詞和照應詞關聯起來的過程,消解不同表達是自然語言理解的基礎之一。目前漢語句群的自動劃分方法研究主要分為兩種:基于規則的漢語句群劃分方法和基于文本信息的句群劃分方法。研究者對句群這一語法單位的相關研究比較少,也不夠深入,相比較而言,他們更加注重句子、段落這種存在天然分割點的語法單位,或者是在研究句群劃分時忽略了語言本身的指代結構、關聯詞等問題,從而得到不夠準確的句群劃分。
張全等[4]根據漢語篇章句群本身的語義關聯性和接應、組合規律制定了句群劃分的相關規則;在概念層次網絡(HNC)語境觀的指導下,通過對領域句類知識的研究,闡述了一種新型的句群處理方法[5]。韋向峰等[6]根據HNC理論,認為句群領域分析是句群分析的關鍵,通過研究自動獲取句群的領域或語境信息得到句群。但是上述基于HNC概念的研究工作會受到相對固定的領域知識或者判定規則的限制。
句子完整含義的理解需要有較為全面的上下文。陳怡疆等[1]認為,如果上下文信息量太少,那么很多有用的信息就會丟失,將得不到句子全部的含義,但是如果信息量太大,又會造成搜索空間過大和數據稀疏問題,因而表示這個合適的大小不是句子或者段落,而是句群,是包含一個意義完整的主題的一組句子。他們提出了一種利用局部重現度較高的詞作為特征的層次聚類算法,將篇章表示成一棵句群樹,葉子節點為單個句子,內部節點就是一個多重句群,但是并未考慮篇章指代詞的作用。李杰等[7]提出一種基于多元判別分析的漢語句群自動劃分方法,是一種明確可計算的模型。算法通過Skip-Gram Model獲取句子的特征向量,與傳統VSM相比,減少了數據稀疏,再考慮句群內部距離、句群間距離、切分片段長度和篇章銜接詞等因素,設計基于MDA方法的評價函數J,通過比較J的值獲得句群劃分結果,但僅僅考慮了句首指代詞。
針對現有的句群劃分缺少指代消解的情況,在已有基于多元判別分析(MDA)的句群劃分方法的基礎上,通過引入指代消解來優化漢語句群的自動劃分。基本步驟為:利用適合中文的多層過濾指代消解模型獲取中文語料指代消解的結果[8];通過Skip-Gram Model獲取句子的特征向量;設計明確可計算的基于MDA的評價函數J,加入指代因素、考慮關聯詞的作用,實現對段落的切分并對所有的劃分結果進行評價;評價值最高的句群劃分序列為該段落的最佳句群劃分結果。實驗結果表明,加入指代消解后指代鏈信息提高了句群劃分的效果,與傳統MDA方法的結果對比,Pu提升約9%,WindowDiff降低約1%;與未加入指代消解的相同方法相比Pu提升約7%。
2 基于指代消解的漢語句群自動劃分方法
2.1 指代消解的處理
中文指代消解的研究發展較為緩慢,主流方法主要有三類:基于無監督的方法、基于有監督的方法和基于規則的層次過濾的方法。因為基于無監督的指代消解方法不依賴標注好的語料庫,所以一度盛行。隨著中文語料庫的發展,基于有監督的指代消解方法以其較高的消解準確率取得一席之地。然而,基于有監督的指代消解方法在提取的特征向量中存在一些消解正確率較低的特征,該類特征會覆蓋消解正確率較高的特征,從而影響模型的消解正確率。基于規則的層次過濾模型不需要標注好的語料庫,而且模型的各個層次按照消解精度從高到低排列,不會出現消解正確率低的特征覆蓋消解正確率高的特征的現象,因此該方法會獲得更好的消解效果,也比較適合中文的指代消解[9]。
按照基于規則的層次過濾指代消解的思想,該模塊的系統框架分為三部分:預處理、待消解項識別、指代消解處理[10-11]。
(1)預處理:對語料進行分詞,詞性標注,命名實體識別和句法分析,句法分析結果由Stanford Parser處理得到。根據相應的語言學規則從句法分析結果抽取出候選待消解項,包括名詞、名詞短語和代詞。
(2)待消解項識別:待消解項識別的精度對整個指代消解模型的精度產生了極大影響,并且丟失待消解項比錯分指代鏈更影響消解模型的精度。待消解項識別分為兩部分:擴充階段,提取所有的名詞和名詞短語,盡量保證不會丟失待消解項;過濾階段,去除一些無需消解的停用詞,沒有意義的時間,數詞,金錢等詞匯,過濾重復詞,在保證一定召回率的同時,提高待消解項識別的正確率[12]。
(3)指代消解處理:字符串完全匹配,別名匹配和同位語對名詞短語的指代消解貢獻達到了97%[13],而代詞指代消解是篇章指代消解的一個關鍵。因此,設置四個層次,將各個過濾層次按照消解正確率從高到低排列,名詞短語和代詞通過層次過濾尋找其先行語。各個層次過濾模塊如表1所示。
●完全字符串匹配。
若兩個字符串完全相同,則認為這兩個名詞短語指向同一個實體。該層的準確率最高。

表1 指代消解各層過濾模塊
●別名匹配。
若一個字符串是另外一個的子串或抽取子串,則說明它們之間有別名關系,是指向的同一個實體。例如:“普京”是“弗拉基米爾·弗拉基米羅維奇·普京”的子串,“中國”是“中華人民共和國”的抽取子串。
●同位語。
若兩個短語之間有同位語關系,則說明他們指向相同。同位語的定義是一個名詞(或其他形式)對另一個名詞或代詞進行解釋或補充說明,這個名詞(或其他形式)就是同位語。
●代詞匹配層。
代詞指代是指代的重點和難點。這層是解決代詞和名詞或名詞短語之間是否具有指代關系,主要通過判斷單復數匹配關系、性別是否一致、有無生命,還有根據命名實體結果分為組織、地點、人名、雜項等的匹配。
基于指代消解的漢語句群劃分方法整體框架如圖1所示。

圖1 基于指代消解的漢語句群劃分方法整體框架圖
2.2 句群劃分模型
句群,顧名思義就是若干句子的組合,它們描述同一個中心,意義完整,句子的組合有一定的邏輯順序[14]。句群劃分主要依據語言本身的特點和組合規律。句群劃分實例如圖2所示。句群1中的“它”是一個指代詞,指代白楊樹,通過指代關系的確認可以很好地消解詞語的二義性,對以后衡量類內距離有重要作用;句群2揭示了其組合規律,用“難道”開頭的四個反問句表達了對北方軍民的贊頌,是一種遞進關系,第④句中存在銜接詞“但是”,代表轉折關系,如果切分出來必然不合理,需要對這種切分結果進行懲罰。

圖2 句群劃分實例
根據漢語表達習慣,一個句子可以獨立地表達一個完整的意思,相似的內容一般出現在同一片段內,段落是一個意義完整性的天然分割點。但一個段落中可能包含不同的主題,所以句群的劃分以句子為基本單位進行,在一個段落中劃分出不同主題的句子群。
MDA是一種獨立于具體領域的文本線性分割統計模型方法,可以通過定義評價函數實現對句群劃分的全局評價[15]。具體是對句子向量構成的數據空間進行劃分,考慮句群內部距離、句群之間距離、切分片段長度、指代因素以及篇章銜接詞因素,設計基于MDA的評價函數J,使函數J值取得最大的劃分即為最優劃分結果。
設最優劃分結果為D,則:
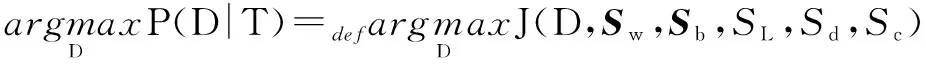
(1)
其中,Sw為類內離散矩陣;Sb為類間離散矩陣;SL為切分片段長度懲罰因子;Sc為指代因子;Sd為篇章銜接詞懲罰因子。
(1)句群內部距離與句群間距離。
句群內部的緊湊性和句群間的離散性是重要特點。類內離散矩陣可用于衡量句群內部的內聚程度。
(2)切分片段長度因素。
當劃分模式切分出連續的單句時,需要對結果進行懲罰。
(3)指代因素。
消除代詞的指代不明和實體的不同名詞短語表達問題是計算機理解自然語言的基礎。這里將指代消解后的指代鏈信息加入評價函數J。
(4)篇章銜接詞因素。
句子之間在表達形式上也會顯示出其連貫性。建立篇章銜接詞表Dict,包含“而”、“并且”等詞。
3 實驗測試
3.1 實驗語料與測評
(1)語料設置。
目前還沒有一個公開、通用的中文句群劃分評測語料,為了驗證指代消解對句群劃分的影響,取與文獻[7]相同的實驗語料—《讀書》雜志(1979-1983),共50期,人工標注了其劃分結果,分割片段的平均句子數為3,段落的平均句子數為9,文獻作者通過計算Kappa值說明了語料的相對一致可靠性。
首先對原語料進行指代消解處理,得到指代鏈信息,對位于同一指代鏈上的名詞、名詞短語或者代詞進行一定規則的替換。之后進行句群自動劃分的處理,分詞后使用詞向量訓練工具word2vec獲取詞語在低維空間中的向量表示,再對形成的數據空間進行劃分,通過評價函數J得到最優劃分結果。
(2)測評指標。
傳統的評價方式(準確率和召回率)主要是考慮絕對匹配的情況,而在句群劃分中,這一評價方式不再適合。為此,采用文本分割中常用的Pu[16]和WindowDiff[17]評價方法。
Pu通過計算任意兩個句子是否被算法正確劃分為同一片段的概率,分割點距離正確的分割點越近,Pu評價值越高。計算公式如下:
(2)
WindowDiff對不正確的分割點做出懲罰,即“正錯誤”和“負錯誤”。“正錯誤”是指在實驗中多做了分割,“負錯誤”是指在實驗中遺漏了分割。WindowDiff值越小,說明分割結果越好。計算公式如下:
b(hypi,hypi+k)|>0)
(3)
其中,b(i,j)為相應劃分模式下位置i和位置j直接的切分點的數量;k為平均切分片段句子數的1/2。
3.2 實驗結果及分析
(1)實驗結果。
指代消解性能見表2。其中,P(正確率)=正確識別的個體數/識別出的個體總數;R(召回率)=正確識別的個體總數/測試集中存在的個體總數;F=準確率*召回率*2/(準確率+召回率)。

表2 基于層次過濾的指代消解性能
表3展示了對文本進行指代消解后的句群劃分在不同維度下評價函數J的實驗結果,統計正確分割的平均Pu值為91.26%,統計錯誤分割的平均WindowDiff值為27.26%,從100~300維,Pu值略有提升、WindowDiff值下降,而在400維,Pu下降、WindowDiff上升。

表3 不同維度下評價函數J的實驗結果 %
表4展示了加入指代消解和未加入指代消解的基于MDA的漢語句群自動劃分方法的比較結果,Pu提升約7%,WindowDiff提升約2%。

表4 加入和未加入指代消解的基于MDA的漢語句群自動劃分方法對比 %
表5展示了文中方法與傳統MDA方法的結果對比,Pu提升9%,WindowDiff降低1%。其中傳統MDA方法的評價函數J'通過衡量類內離散矩陣、類間離散矩陣和切分片段長度得到。實驗結果表明,指代因素Sc和篇章銜接詞因素Sd起到了一定的作用。

表5 文中方法與傳統MDA方法的比較 %
(2)實驗分析。
加入指代消解后,顯著提高了句群劃分的效果,統計平均正確分割Pu有一定程度的提升,統計錯誤的平均分割WindowDiff有所下降。對句群劃分加入指代消解的處理消除了代詞指代不明、不同名字實則相同實體的情況,是篇章理解的重要因素,在后續衡量句群內部的緊湊性和句群之間的離散性中發揮了重要作用。漢語篇章表述中,代詞指代是文本中數量較多的指代形式,而另外三種指代形式則出現較少,所以代詞指代對句群劃分的貢獻度最大,而因為完全字符串匹配、別名匹配、同位語匹配這三層準確率達到97%左右,因此也很好地涵蓋了其他形式的指代情況。
通過Skip-Gram Model訓練大規模語料獲取詞語在低維實數空間向量表示,通過挖掘深層語義信息獲取文本表面的聯系,通過表3說明并不是維度越高越好,Pu值與維度并不是線性關系。
由表4知,加入指代消解較未加入指代消解的Pu值提升明顯,說明加入指代消解后劃分句群的算法得到的切割點較接近實際的切割點,而WindowDiff值也較未加入指代消解的大,WindowDiff是對“正錯誤”和“負錯誤”的衡量,說明分割算法在這方面是有缺陷的。
4 結束語
為了在篇章理解的基礎上優化漢語句群自動劃分,提出一種基于指代消解的句群自動劃分方法。該方法在MDA句群劃分法的基礎上,從語料名詞、名詞短語、代詞的指代消解出發,進而實現漢語句群的自動劃分。基于該方法構建了自動劃分系統,并實現了基于指代消解的句群劃分。實驗結果表明,與傳統MDA方法對比,Pu提升約9%,WindowDiff降低約1%;與未加入指代消解進行對比,Pu提升約7%。表明該方法有效可行。
[1] 陳怡疆,史曉東,周昌樂.Automatic partition of Chinese sentence group[J].Journal of Donghua University:English Edition,2010,27(2):177-180.
[2] 劉福君.基于指代消解的自動文摘研究[D].合肥:安徽大學,2012.
[3] 石 晶.文本分割綜述[J].計算機工程與應用,2006,42(35):155-159.
[4] 吳 晨,張 全.自然語言處理中句群劃分及其判定規則研究[J].計算機工程,2007,33(4):157-159.
[5] 韋向峰,繆建明,張 全,等.基于概念基元的句群情景框架抽取研究[J].微計算機應用,2010,31(4):21-24.
[6] 韋向峰,繆建明,張 全.漢語句群領域的自動抽取研究[J].計算機工程與應用,2009,45(4):11-15.
[7] 王榮波,李 杰,黃孝喜,等.基于多元判別分析的漢語句群自動劃分方法[J].計算機應用,2015,35(5):1314-1319.
[8] 周炫余,劉 娟,盧 笑.篇章中指代消解研究綜述[J].武漢大學學報:理學版,2014,60(1):24-36.
[9] 周炫余,劉 娟,羅 飛,等.中文指代消解模型的對比研究[J].計算機科學,2016,43(2):31-34.
[10] Raghunathan K,Lee H,Rangarajan S,et al.A multi-pass sieve for coreference resolution[C]//Conference on empirical methods in natural language processing.Mit Stata Center,Massachusetts,USA:A Meeting of Sigdat,A Special Interest Group of the ACL,2010:492-501.
[11] Lee H,Peirsman Y,Chang A,et al.Stanford's multi-pass sieve coreference resolution system at the CoNLL-2011 shared task[C]//Proceedings of the fifteenth conference on computational natural language learning:shared task.[s.l.]:Association for Computational Linguistics,2011:28-34.
[12] 孔 芳,朱巧明,周國棟.中英文指代消解中待消解項識別的研究[J].計算機研究與發展,2012,49(5):1072-1085.
[13] 高俊偉,孔 芳,朱巧明,等.基于SVM的中文名詞短語指代消解研究[J].計算機科學,2012,39(10):231-234.
[14] 梅漢成.現代漢語句群研究概述[J].鹽城師范學院學報:人文社會科學版,1996(3):35-37.
[15] 朱靖波,葉 娜,羅海濤.基于多元判別分析的文本分割模型[J].軟件學報,2007,18(3):555-564.
[16] Beeferman D,Berger A,Lafferty J.Statistical models for text segmentation[J].Machine Learning,1999,34(1-3):177-210.
[17] Pevzner L,Hearst M A.A critique and improvement of an evaluation metric for text segmentation[J].Computational Linguistics,2002,28(1):19-36.
An Automatic Partition Method for Chinese Sentences Group with Coreference Resolution
WANG Rong-bo1,SUN Xiao-xue1,HUANG Xiao-xi1,LIU He-ping2
(1.School of Computer,Hangzhou Dianzi University,Hangzhou 310018,China;2.School of Software,Zhejiang University,Hangzhou 310000,China)
Automatic Chinese sentence grouping is to divide the text into texts fragments with different theme and plays an important role in information extraction,summary generation,sentence comprehension and other fields.Coreference resolution is a procedure of recognizing antecedent and anaphora and associating them in the chapter.Resolution of the different expression is one of the basis of natural language understanding.Currently,focus of automatic Chinese sentences grouping is recognizing boundaries of different topics.Instead,the coreference relations of passage are rarely used for language comprehension,and inaccurate results are usually existed due to vagueness resolution.So an automatic Chinese sentences grouping method based on coreference resolution is proposed,which starts with resolution of the passages and get link of resolution with multi-layer filter resolution method to eliminate different terms referred to the same entity or to unknown.Besides,the cohesive markers of passages are taken into account.A group of evaluation functions are designed to evaluate sentences grouping and the experimental results show that it has improved the Chinese sentences grouping work,by which Pμ has increased about 7%.
sentences grouping;coreference resolution;multi-pass sieve;MDA
2016-09-14
2016-12-15 網絡出版時間:2017-07-05
國家自然科學基金資助項目(61202281,61103101);教育部人文社會科學研究項目青年基金(10YJCZH052,12YJCZH201)
王榮波(1978-),男,副教授,CCF會員(E200017318M),研究方向為自然語言處理、篇章分析。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170705.1651.062.html
TP391
A
1673-629X(2017)08-0061-05
10.3969/j.issn.1673-629X.2017.08.013
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
