基于概率統計的水電機組狀態評估數據特性研究
2017-08-16 04:20:18潘羅平曹登峰
水電站機電技術 2017年7期
關鍵詞:特征
周 葉,潘羅平,曹登峰
(中國水利水電科學研究院,北京 100038)
基于概率統計的水電機組狀態評估數據特性研究
周 葉,潘羅平,曹登峰
(中國水利水電科學研究院,北京 100038)
簡要介紹了基于健康樣本的水電機組狀態評估方法,提出完整的健康模型分為特征數據、影響因素和健康樣本3部分,然后針對特征數據的統計特性展開了分析與研究。首先對能反映機組運行狀態的傳感器和信號參數進行分類,再根據參數關系的復雜程度,將其分為基本特征數據和組合特征數據,并分別給出了其計算方法和特征值的選擇。最后,文章通過選取電站長期運行的實際狀態數據,對兩種類型的特征數據進行統計分析,得到其數據特性和影響因素并給出相關結論。
水電機組;健康樣本;特征數據;統計特性;狀態評估
1 前言
與機組發生故障時需要及時判別和處理不同,狀態檢修最終的目標是指導檢修計劃和檢修內容,以發現并消除機組潛在的故障,因此其重點在于收集并積累設備的狀態信息,并對其發展趨勢進行預測和評估。而當前國內外診斷技術的研究大多集中于故障的分析和識別,實際上,由于水電機組故障相對復雜,很難直接檢測到具體的特定故障。因此,要想提高水電機組狀態監測的實用性,切合水電廠的實際需要,需要了解機組長期運行的狀態和發展趨勢,最終指導設備的檢修計劃及內容[1]。
而隨著測試技術和信息技術的不斷發展提高,監測設備越來越成熟,其應用越來越廣泛,各電站通過各種狀態監測系統積累了機組長期海量的運行狀態數據,使得大數據和統計理論在水電機組診斷檢修中的研究和應用成為可能。
基于實用性和狀態檢修的需求,本文從概率統計學的角度研究機組長期運行的狀態數據,建立機組重點或關鍵部位的評估模型,研究其發展趨勢和變化規律,以實現機組的運行狀態評估。作為基于大數據的水電機組狀態評估方法研究成果,文獻[2]中提出了基于健康樣本的水電機組狀態評估方法,按照其結構設計內容,研究思路分為數據特性、模型特性和評估方法研究3個部分,本文的研究內容為第一部分。
文章首先簡單介紹了基于健康樣本的水電機組運行狀態評估方法,并對能反映機組狀態的測量參數進行分類和計算方法分析,然后設計了兩種不同的特征數據模型,最后結合模型結構通過大量的真實數據驗證分析機組運行狀態特征數據的統計特性。
2 基于概率統計的水電機組診斷評估方法
2.1 基于統計學的新異類檢測定義
新異類檢測方法(Novelty Detection Method)是一種檢測隱藏在大量正常數據中的未知或異常現象的技術,它通過對已知狀態觀測樣本的學習,實現對機器學習系統在訓練時未曾遇到的、新的未知的或異常現象的識別,屬于數據挖掘中的無監督學習方法[3]。
依據模型數據的統計特性,獲取模型樣本的分布,并判斷測試樣本是否屬于同一分布,這種檢測方法稱為基于統計學的新異類檢測方法。根據數據和模型的復雜程度不同,可以采用不同的統計學方法。
由于不需要先驗故障知識,且主要診斷依據基于數據的統計特性,更適用于已安裝且長期運行狀態監測系統的水電廠。雖然這種方法在沒有先驗故障知識時,無法得到準確的故障分類和判別,但作為異常狀態識別方法,可以在狀態識別、趨勢預估上起到較好的效果,并為故障診斷提供依據。
2.2 基于健康樣本的水電機組狀態評估方法
文獻[2]中對基于概率統計的水電機組狀態評估診斷方法進行了詳細的描述,這里對該方法進行簡單的闡述和補充。
對水電機組的運行狀態進行評估,需要利用機組的歷史狀態測量數據,對不同測點參數建立數據模型,數據模型包括基準值和限值兩部分,這里將機組在穩定運行狀態下,由測點基準值和限值組成的特征數據模型稱為健康樣本(Health Model)。通過機組當前的實時監測值與健康樣本的比對分析,得到機組的運行健康狀態、劣化度和變化趨勢。
在實際分析過程中,由于水電機組的狀態監測參數大多與其運行條件等有關,如果統計分析時不予以考慮,會導致樣本分散,標準偏差大,不利于健康樣本的確定。因此,在處理樣本數據時,需要將樣本按多維影響因素進行劃分(對機組運行工況而言,典型的如有功、水頭、導葉開度等),對不同分區內的數據分別建立相應的健康樣本,也可大致分為穩定區和非穩定區進行分析,進而評估機組在整個運行條件范圍內的健康狀態。
因此,一個完整的健康樣本模型分為3部分,①該模型的特征數據,即我們選擇的參數物理量以及這些物理量的特征值,它由單個或多個測點參數構成,單個參數的,如某導軸承擺度信號的峰峰值、水輪機頂蓋的水壓脈動主頻值等,多個參數的,如最大最小瓦溫差等;②影響因素,即生成模型時需要考慮的影響參數值變化的因素,二維模型指單個影響因素(如機組工作水頭)與特征數據的組合,三維模型指兩個影響因素(如機組有功和工作水頭)與特征數據的組合;③健康樣本,即該特征數據對應影響因素的運行基準值和限值。本文主要研究健康樣本模型的第一部分即特征數據的結構設計及其統計特性分析。
以機組有功和水頭作為主要工況限定條件為例,將機組有功、水頭和當前健康標準值設定為三維模型,其閾值初始時由當前有功和水頭限定范圍內的監測數據統計值確定,最終建立機組異常狀態評估模型:
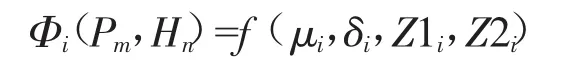
其中Pm為有功區間,Hn為水頭區間,μi為基準值,δi為均方差/標準差,Z1i為健康下限,Z2i為健康上限,對單個特征量的健康樣本而言,i為有功區間劃分數和水頭區間劃分數之積。
3 機組運行狀態特征數據
3.1 狀態參數分類
要開展機組運行狀態評估,首先要確定能反映機組運行特征的參數,這里按照水電機組的結構組成、運行特性和常見故障類別,將機組可能發生故障的部分劃分為水輪機、發電機、軸承系統、主變壓器、GIS開關(含高壓斷路器)、調速器及輔機系統等幾個部分,首先選取每個部分里有代表性的參數構造健康樣本,如部分容易反映出故障特性的特征值,再隨著關注度和數據特征趨勢的發展,逐步擴展到更多的參數,構造更多的狀態模型。這樣既利于提高診斷的效率和準確性,也能夠促使故障診斷研究工作分模塊、分階段開展和實施。
與故障診斷專家系統的知識分類不同,專家系統的故障分類,重點是分析具體的故障內容,并找到對應的參數,而這里的運行狀態參數分類,則是將機組的大量監測參數按照重要程度和關注度的不同進行分類,并通過挑選或組合不同的狀態參數,形成機組健康模型,并不依賴于專家知識庫的推理。
3.2 特征數據設計
要研究水電機組運行狀態的健康指標,首先需要根據特征參數劃分和組合的不同,進行特征數據的統計特性分析,確定其是否體現了機組運行狀態。這里根據選取參數的復雜程度,將特征數據分為基本特征數據和組合特征數據兩類。
(1)基本特征數據
單一信號參數的特征數據稱為基本特征數據,雖然包含是單一參數,但對該參數的特征值計算,依據其測量和存儲方法的不同,仍然有不同的選擇依據。
對于慢變量,通常只需觀察其計量值的變化范圍是否在控制界限以內,就可以基本判定其運行狀態是否正常,如來自機組DCS以模擬量為主的監測量,包括導軸承瓦溫、油泵油壓油位等數據。其他如主變壓器油中氣體含量、發電機氣隙監測值等,根據采樣時間的不同,通常還存有波形趨勢數據,對這種慢變量參數,主要采用幅域統計法選取其特征,即選用一段時間內的最大值、最小值、平均值和方差等。
對穩態工況下機組測點的特征值,概率密度函數是慢變量重要的特征值指標,主要為均值μ和方差δ2。如果數據集服從正態分布N(μ,σ2),可以采用區間(μ-3σ,μ+3σ)作為判斷此次觀測值是否超限的依據[4]。
對于快變量,如振動、壓力脈動等參數的高采樣率波形數據,除了需要觀察其計量值(通常為時域幅值)變化情況外,還需要觀察其頻譜以及無量綱幅域參數的變化,才能比較準確的判斷機組的運行狀態[5]。
因此,快變量還需要采用波形特征數據進行統計分析,包括波形指標、峰值指標、脈沖指標、裕度指標和峰態指標等;對頻譜成分特性,除了基本的轉頻、倍頻諧波的幅值、頻率指標外,還可采用功率譜密度函數、頻率重心、均方頻率、均方根頻率、頻率方差和頻率標準差等作為統計分析對象。
(2)組合特征數據
組合特征數據是建立在基本特征數據基礎上的一種數據類型,由于機組的運行特性常常由多個測點聯合作用共同體現,故單一測點的統計特性往往很難有針對性的反映設備的健康狀態。同時,為了抵消或排除影響因素對數據的干擾,可按實際情況建立相關不同測點的組合特征量,對組合特征量的特征值進行分析和評估。
若X1,X2,…為選取的相關測點參數,可建立如下不同特征量
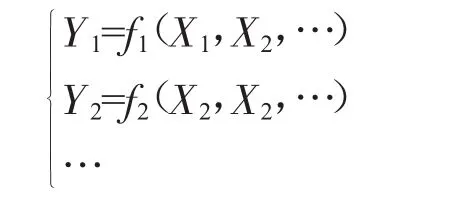
其中,f1,f2,…為預先設定的函數關系,通過對組合特征量Y1,Y2,…的分析來評估設備狀態。
以擺度信號為例,如果監測系統存儲了其主頻幅值和相位,就可以將振幅和相位隨轉速變化的關系比例,作為轉子動平衡模型的特征參數。同樣,對機組的導軸承瓦溫、冷卻水進出口溫度等參數,可以通過比較和數學處理,得到一段時間的最大溫差等特征值,即:△Tmax=tmax-tmin,以抵消環境溫度對其數值的影響。
4 機組運行狀態數據統計特性
4.1 基本特征數據的統計特性分析
(1)長期基本特征數據的分布特性
為研究長期監測數據的統計特性與分布規律,這里選取某電站15F機組2011年8月18日~2014年8月18日期間的監測數據,包括機組有功、上導Y向擺度峰峰值、上機架Y向水平振動峰峰值3個測點信號。按每2 min取特征值的均值,得到3年時間區間內的樣本數據。
考慮到運行工況的影響,選取各測點在機組穩態運行時的歷史數據做頻率分布統計,在95%置信水平下,用Matlab的Jbtest函數進行正態分布檢驗,得到檢驗結果見表1。
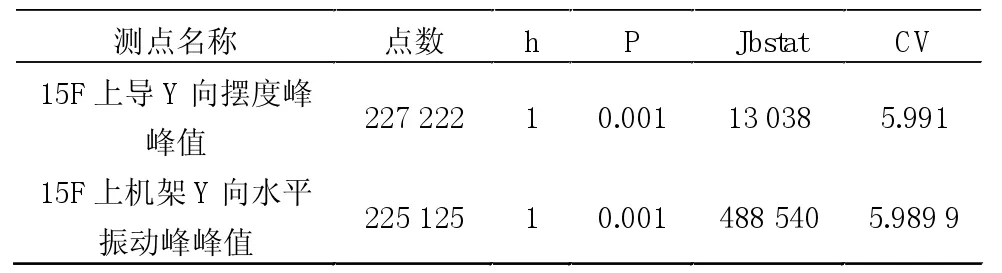
表1 正態分布檢驗結果(2011.8.18~2014.8.18)
其數據分布直方圖見圖1。
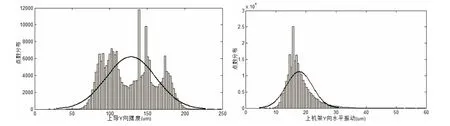
圖1 上導擺度和上機架振動的數據分布直方圖
通過JBTest函數計算結果和數據分布直方圖可以看出,兩個測點數據均無法通過正態分布檢驗,其檢驗量Jbstat遠遠超過臨界值CV。究其原因,由于選取了3年時長的機組運行數據,期間機組檢修的影響和機組狀態的變化較大,因此很難把3年時間的機組運行數據統一為一個標準的穩態數據模型。
(2)不同時間長度對統計特性的影響
分別以半年、3個月、1個月、1周為時間段,選取4個時間區間內的上機架Y向水平振動峰峰值數據進行正態分布檢驗,其概率值檢驗圖如圖2、圖3所示。
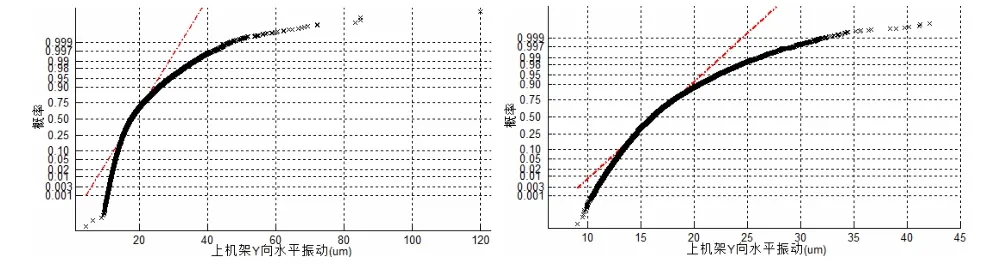
圖2 15F機組上機架Y向水平振動概率值檢驗圖(左圖:半年;右圖:3個月)
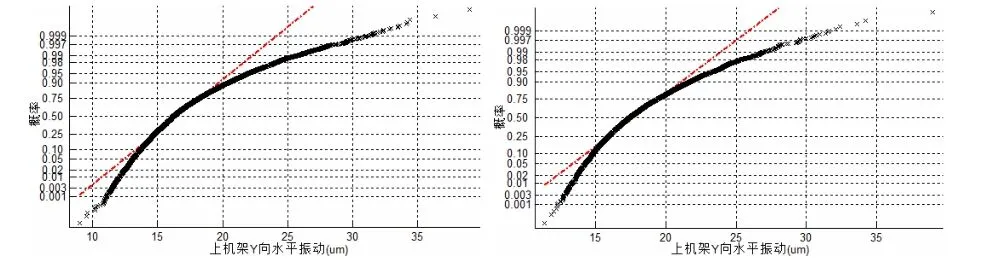
圖3 15F機組上機架Y向水平振動概率值檢驗圖(左圖:1個月;右圖:1周)
從圖2、圖3可以看出,隨著數據時長的改變,上機架Y向水平振動峰峰值的分布特性雖然無法通過正態分布檢驗,但已經在逐步趨向標準正態分布。
4.2 組合特征的統計特性分析
為了消除基本特征數據受到工況和壞境因素的影響,采用組合特征的方式來進行統計分析,這里選取某電廠18F機組2014年8月31日12:00~2014年09月14日00:00:00期間的水導瓦溫監測數據,期間機組滿負荷運行,包括3號、4號兩塊水導軸瓦的瓦溫數據。計算其平均值和最大瓦溫差的統計特性,即在95%置信水平下,用Matlab的Jbtest函數進行正態分布檢驗。檢驗結果見表2。
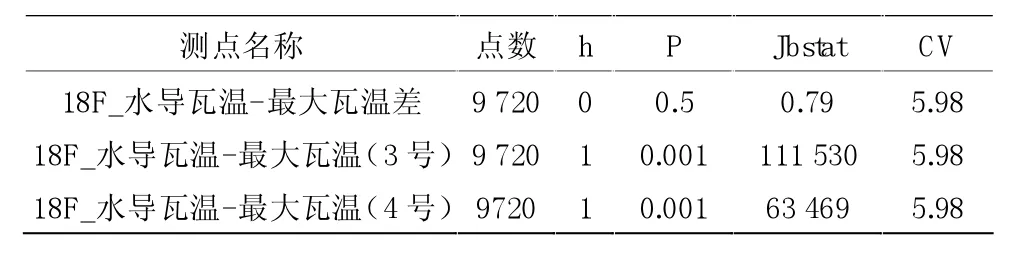
表2 水導瓦溫組合特征量正態分布檢驗結果
檢驗結果表明,3號水導瓦和4號水導瓦該段數據均無法通過正態分布檢驗,但組合測點最大瓦溫差該段數據可以通過正態分布檢驗,認為其服從正態分布。
頻率分布直方圖與概率值檢驗圖如圖4所示。
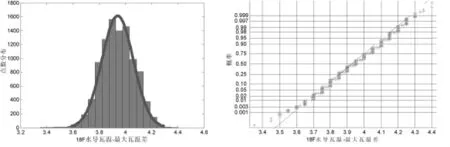
圖4 18F機組水導瓦溫-最大瓦溫差頻率分布直方圖和概率密度檢驗圖
5 結論
通過對實際數據的分析和檢驗,可以得出如下結論:
(1)數據長度不宜選擇過長。雖然概率統計方法希望取得的數據樣本數越大越好,但實際驗證分析證明,影響機組運行狀態變化的因素很多,想要確定機組的健康樣本,需要機組運行狀態相對穩定,因此建議在采用率盡可能高的情況下,選取適當時長的數據進行統計分析。
(2)組合特征量相比單個特征量更容易反映機組運行特性。本文僅給出了簡單的瓦溫差作為示例,其他如機組發電機能量損耗、動不平衡時機架振動主頻分量與轉速平方比值等其他與機組運行特性緊密相關的組合特征,都可以用來進行統計分析,也容易起到較好的評估效果。
(3)通過概率統計分析可以得到機組的穩定運行狀態和樣本,能夠作為后期機組異常狀態評估和趨勢預估的標準。當然,可以根據參數值的數學特性,選用其他的分布函數進行驗證和分析。要想得到理想的機組健康樣本,還需要考慮其基本的影響因素即工況參數的影響,可以通過網格劃分得到多維特征數據,以更好的獲取其統計特性。
[1]陳國慶,程 建,李友平,等.水電機組狀態檢修技術的幾點認識[J].水電自動化與大壩監測,2012,36(4):31-33.
[2]周 葉,潘羅平,曹登峰.基于新異類檢測的水電機組診斷評估方法研究 [C]//水電設備的研究與實踐—第20次中國水電設備學術討論會論文集.北京:中國水利水電出版社,2015:344-351.
[3]Markou M,Singh S,Novelty Detection:A Review–Part 1: Statistical Approaches[J].Signd Processing,2003(12).
[4]Manson G,Pierce G,Worden K,et al.Long-term Stability of Normal Condition Data for Novelty Detection[C]//Proceedingsofthe 7th International Symposium on Smart Structures and Materials,California,USA,2000.
[5]梁武科,張彥寧,羅 興.水電機組故障診斷系統信號特征的提取[J].大電機技術,2003,35(4):53-56.
TV738
A
1672-5387(2017)07-0022-04
10.13599/j.cnki.11-5130.2017.07.006
2017-04-27
周 葉(1980-),男,高級工程師,從事水電機組狀態監測與故障診斷研究工作。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
