動態背景下基于光流場分析的運動目標檢測算法?
2017-08-12 03:21:00崔智高王華李艾華王濤李輝
物理學報 2017年8期
崔智高 王華 李艾華 王濤 李輝
1)(火箭軍工程大學,西安710025)2)(清華大學自動化系,北京100084)
動態背景下基于光流場分析的運動目標檢測算法?
崔智高1)2)?王華1)李艾華1)王濤1)李輝1)
1)(火箭軍工程大學,西安710025)2)(清華大學自動化系,北京100084)
(2016年10月21日收到;2017年1月24日收到修改稿)
針對現有動態背景下運動目標檢測算法的不足,提出一種基于光流場分析的運動目標檢測算法.首先根據前背景在光流梯度幅值和光流矢量方向上的差異確定目標的大致邊界,然后通過點在多邊形內部原理獲得邊界內部的稀疏像素點,最后以超像素為節點,利用混合高斯模型擬合的表觀信息和超像素的時空鄰域關系構建馬爾可夫隨機場模型的能量函數,并通過使目標函數能量最小化得到最終的運動目標檢測結果.該算法不需要任何先驗假設,能夠同時處理動態背景和靜態背景兩種情況.多組實驗結果表明,本文算法在檢測的準確性和處理速度上均優于現有算法.
動態背景,運動目標檢測,光流場分析,馬爾可夫隨機場模型
1 引言
運動目標檢測是指從視頻序列中提取出感興趣的運動物體或區域,是后期實現目標跟蹤、行為分析的基礎[1?3].在實際應用中,根據攝像機運動與否,可分為靜態背景下和動態背景下的運動目標檢測兩類:應用于靜態背景下的運動目標檢測方法主要有幀差法和背景差分法[4,5];而動態背景下由于攝像機的不規則運動會造成背景和前景目標的相對運動,給目標的檢測帶來了非常嚴峻的挑戰.因而致力于研究攝像機運動下的目標檢測方法具有非常重要的意義[6].
動態背景下的運動目標檢測方法主要分為基于背景補償的方法、基于初始背景模型構造的方法和基于運動線索的方法三類[7],其中第三種是當前的主流方法和研究難點,此類方法一般以視頻序列獲得的像素點運動軌跡作為運動線索的基本載體.例如:Lee等[8]首先根據像素點運動軌跡確定類似目標的候選關鍵區域,然后計算候選關鍵區域的二值化分割,從而獲得具有穩定外觀和持續運動的假設組,最后使用已被排序的假設組得到所有幀像素級的目標檢測結果,該算法的不足之處在于其準確率對物體的外觀假設和位置先驗依賴較大;Li等[9]通過條件隨機場模型將利用像素點運動軌跡獲得的目標內部稀疏像素點進行有效集成,算法不需要通過任何訓練數據來獲取先驗知識和條件假設,能夠魯棒處理前景目標形狀和姿態的任意變化,但是該方法在運動軌跡稀疏區域會出現大塊的誤檢測;Zhang等[10]首先根據運動目標的空間連續性和運動軌跡的局部平滑性建立目標樣本集,然后利用所有的目標樣本集建立層狀有向無環圖,圖中最長的路徑滿足運動評分函數最大且代表了可能性最大的目標樣本,最后這些目標樣本被用于建立目標和背景的混合高斯模型,并利用最優化圖割方法求解模型獲取準確的像素級分割結果,該算法要求每一環節中的參數設置都必須準確合理,一般在實際場景檢測中較難實現;Elqursh和ElgamMal[11]提出了一種基于軌跡聚類分析和顏色模型迭代學習的運動檢測方法,其中作者在使用運動軌跡時未用到未來信息,即軌跡是在線延長的,因此在視頻序列的初始階段,由于運動軌跡缺乏足夠的運動信息,容易造成聚類錯誤并影響后續的顏色模型學習和前景背景分割;高文等[12]將目標檢測問題視為一種更普遍的二分類問題,并利用1 bit BP特征通過三個級聯分類器實現運動目標檢測,該算法對攝像機微小晃動、背景模糊等復雜情況具有良好的檢測效果,但在背景劇烈變化時檢測精度較低;崔智高等[13]首先利用多組單應約束對背景運動進行建模,然后通過累積確認策略實現前背景軌跡的準確分離,最后將軌跡分離信息和超像素的時空鄰域關系統一建模在以超像素為節點的馬爾可夫隨機場模型中,求解模型得到最終的前背景標記結果,該算法的計算復雜度較高,并且在前背景的邊緣區域會出現較大的誤檢率.
眾所周知,像素點運動軌跡的提取基于幀間獲取的光流場[14,15],即首先求得幀間光流場,然后利用匹配方法[16?18]獲得像素點之間的匹配對應,因此若直接以幀間光流場作為運動線索的基本載體,則可以有效避免匹配過程中的誤差累積和時間消耗.基于上述思想,本文提出一種基于光流場分析的運動目標檢測方法.算法首先利用光流的梯度幅值和矢量方向確定前景目標的大致邊界,然后根據點在多邊形內部原理獲得邊界內部的稀疏像素點,最后以超像素為節點構建馬爾可夫隨機場模型的目標能量函數,利用混合高斯模型構建數據項,利用超像素時空鄰域關系構建平滑項,并通過使目標函數能量最小化得到最終的運動目標檢測結果.本文所提算法不需要物體運動和場景估計的先驗假設,并且在靜態場景和動態場景下均能實現準確、魯棒的運動目標檢測.
2 基于光流梯度幅值和光流矢量方向的目標邊界檢測
對于攝像機運動的場景,背景所對應的光流場是由背景運動產生的,而目標所對應的光流場則是上述運動與場景中目標運動疊加產生的,二者的光流矢量存在著較大差異,因而可通過對光流矢量的分析確定背景與目標的大致邊界.
基于上述思想,本文提出了一種基于光流梯度幅值和光流矢量方向的目標邊界檢測方法.首先利用文獻[19]提出的算法計算視頻序列的光流場,若視頻序列包括N幀圖像,則第t幀圖像坐標(u,v)處的光流場矢量可表示為ft(u,v),其中1 6 t 6 N?1.本文把獲得的光流場分為兩類:由攝像機運動產生的背景光流場和由運動物體產生的目標光流場.本節將通過對光流梯度幅值和光流矢量方向的分析,獲得背景光流場和目標光流場的大致邊界.
2.1 光流梯度幅值確定邊界
盡管目標運動和背景運動具有較大差異性,但目標內部像素點的運動或者是背景內部像素點的運動則具有高度一致性,具體表現在目標與背景邊緣區域光流矢量梯度的幅值是較大的,其余區域則接近0.因而可通過設置合適的閾值,將梯度幅值超過閾值的像素點確定為邊界點.基于上述分析,本文引入目標邊界強度系數(u,v)∈[0,1],

其中,∥?ft(u,v)∥表示像素點ft(u,v)的光流梯度幅值,ηm表示將(u,v)控制在[0,1]范圍內的參數.
2.2 光流矢量方向確定邊界
背景內部像素點或目標內部像素點的光流矢量方向基本趨于一致,而在背景與目標的邊界區域,光流矢量方向的差異則較為明顯.因此,可將當前像素點的光流矢量方向與其8鄰域像素點的光流矢量方向做比較,獲取最大的夾角值,并將夾角超過閾值的像素點確定為邊界點.基于上述分析,本文引入另一個目標邊界強度系數(u,v)∈[0,1],
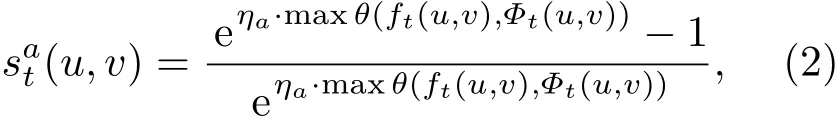
其中,maxθ(ft(u,v),Φt(u,v))表示像素點ft(u,v)與其8鄰域像素點集合Φt(u,v)的最大夾角,ηa表示將(u,v)控制在[0,1]范圍內的參數.
一般情況下,利用上述的其中一種強度系數即可實現目標邊界的檢測,但在實際場景中往往存在各種噪聲的干擾.為了提高魯棒性,本文將光流梯度幅值確定的邊界和光流矢量方向確定的邊界進行融合處理,并通過閾值判斷得到目標邊界的二值圖,如下式所示:
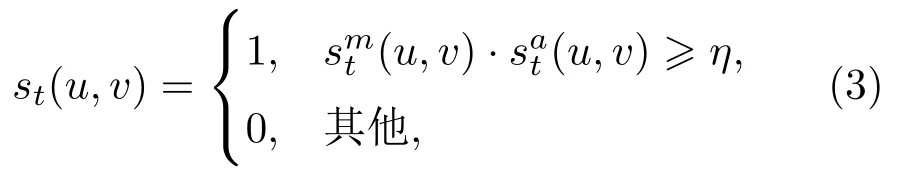
其中1代表邊界點,0代表非邊界點,閾值η取值范圍為[0,1].
3 基于點在多邊形內部原理的目標像素點判斷
在理想情況下,通過上述步驟獲得的目標邊界應與目標實際輪廓相重合,但由于圖像噪聲、光流估計誤差、閾值判斷等多種因素的影響,二者的邊界曲線往往存在較大誤差,并且經過上述步驟獲得的目標邊界通常不是閉合的.圖1給出了一個具體的例子,其中圖1(a)為People2視頻序列[20]中的第3幀圖像,圖1(b)為其對應的目標實際輪廓,圖1(c)為利用上節提出的基于光流梯度幅值和光流矢量方向的目標邊界檢測方法得到的目標邊界.
為了解決上述問題,本文利用點在多邊形內部原理確定目標內部的像素點.其核心思想是從一點出發沿水平或垂直方向引出一條射線,若該射線與多邊形邊的交點數目為奇數,則判斷該點在多邊形內部,否則判斷該點在多邊形外部.基于上述點在多邊形內部原理,本文將每個像素點間隔45?,分別從8個方向引出射線,若8個方向引出射線與目標邊界交點為奇數的方向超過5個,則認為該點在目標邊界內部,從而得到目標內部稀疏的像素點.上述方法通過多個方向的綜合判斷得到像素點的位置,可以有效避免部分邊界不連續或者圖像噪聲造成的誤判斷,增強算法的準確性和魯棒性.圖2為圖1所示圖像對應的目標內部像素點,其中目標內部像素點以白色星形顯示.

圖1 目標邊界檢測結果示例Fig.1.An exaMp le of the ob ject boundary detection.

圖2 目標內部像素點檢測的實驗結果Fig.2.ExperiMental result of internal points detection.
4 基于時空馬爾可夫隨機場模型的前背景像素標記
通過上述步驟只能獲得稀疏的目標像素點.為了進一步對每個像素信息進行前背景標記,本文首先利用SLIC算法[21,22]對視頻序列進行過分割得到超像素集合,然后以超像素為節點構建時空馬爾可夫隨機場模型的能量函數,最后通過使能量函數最小化得到最終的前背景像素標記結果.
4.1 時空馬爾可夫隨機場模型能量函數設計
設第t幀圖像對應的超像素集合為?t,則?t中的每個索引為i的超像素對應一個分類標簽∈{0,1},0表示背景,1表示前景目標.此時,以超像素為節點可構建時空馬爾可夫隨機場模型的能量函數,如下式所示:

4.2 數據項勢能函數設計
數據項勢能函數反映了超像素標記結果與第3節獲得的目標內部像素點的符合程度.基于此,本文首先計算每幀圖像超像素包含已獲得的目標內部像素點的比例系數,并將該比例與兩個設定閾值進行比較,從而將超像素初步分類為前景超像素和背景超像素,如下式所示:

然后本文利用包含超像素均值顏色和質心坐標的5維向量代表每個前景超像素,并通過所有前景超像素為每幀圖像構建前景混合高斯表觀模型考慮到比例系數越大,其屬于前景超像素的概率越高,在混合高斯模型中的貢獻也應更大,為此本文在構建前景混合高斯表觀模型時,為每個前景超像素引入權重系數,

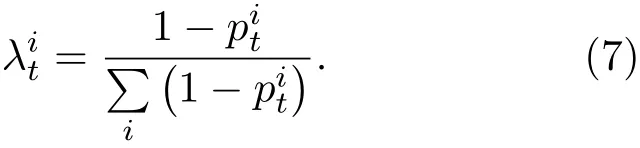
在每幀圖像估計出前景和背景混合高斯表觀模型后,即可計算出該幀圖像中每個超像素對應的數據項勢能函數(),
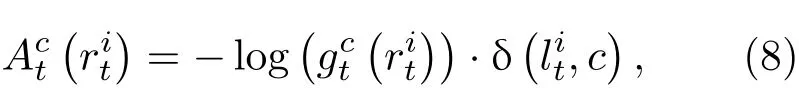
其中,δ(·)為K ronecker delta函數.(8)式表明,如果某個超像素被賦予更加符合其表觀模型的標簽,那么它的數據項勢能函數將更小,從而使得整體能量函數最小.
4.3 平滑項勢能函數設計
平滑項勢能函數用于編碼相鄰超像素之間的標記連續性,又可分為空域平滑勢能函數和時域平滑勢能函數兩類.在空域平滑方面,考慮到同幀圖像中各區域顏色是平滑漸變的,因此相鄰超像素應具有相同的分類標簽.若設超像素和其空域近鄰超像素的質心坐標分別為和,均值顏色分別為和,那么空域平滑勢能函數可定義為
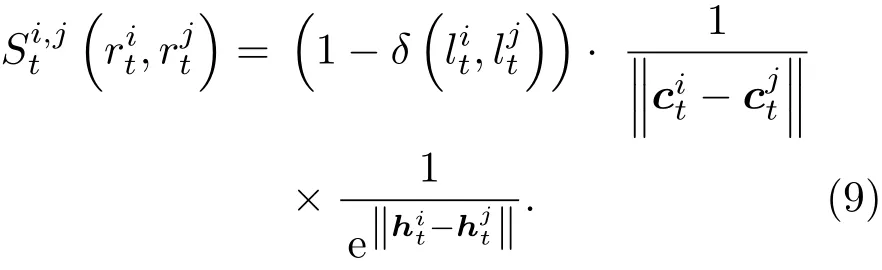
在時域平滑方面,考慮到視頻序列的連續性,時域近鄰的超像素也應具有相同的分類標簽.若設超像素經過幀間光流補償在后一幀圖像的映射區域[23,24]與時域近鄰超像素的重合面積為,超像素的均值顏色為那么時域平滑勢能函數可定義為

對每個超像素建立勢能函數后,本文利用圖割算法[25,26]求解(11)式能量函數最小化問題,得到每個超像素的最優分類結果.

將上文所述的時空馬爾可夫隨機場模型應用到圖2所示圖像中,可以得到圖3所示結果.圖中超像素之間的邊界用黃色線段表示,背景區域用暗紅色表示,運動目標區域則保持原有顏色.

圖3 運動目標檢測結果示例Fig.3.ExperiMental result of the finalMoving ob ject detection.
綜上所述,本文提出的基于光流場分析的運動目標檢測算法具體步驟如下.
算法1動態背景下基于光流場分析的運動目標檢測輸入:視頻序列,圖像幀數目N
目標邊界檢測
1)計算每幀圖像的光流場ft(u,v),(1 6 t 6 N?1)
2)for t=1:N?1 do
利用(3)式確定得到目標邊界的二值圖st(u,v);
end for
目標內部像素點判斷
3)for t=1:N?1 do
利用點在多邊形內部原理確定目標內部像素點
end for
前背景像素標記
5)for t=1:N?1 do;
end for
6)利用圖割算法求解(11)式所示能量函數最小化問題
輸出:視頻序列每幀圖像的前背景二值標記
5 實驗結果與分析
本文選擇多個公開發布的視頻序列進行實驗測試.實驗數據分別來自標準視頻庫中的Cat和Dog序列,Hopkins 155數據集[27]的Cars1-Cars4序列,Sand和Teller[28]提供的VPerson和Vcar序列,以及Changedetection.net數據集中[29]的Highway和Lab序列,選取視頻包含多種復雜場景中的剛體和非剛體運動,具有較好的代表性.另外,選取視頻中Highway序列和Lab序列為靜止相機拍攝的視頻序列,其余則為手持式相機拍攝的視頻序列,可驗證本文方法在靜態和動態兩種背景下的有效性.
采用廣泛使用的查準率PR、查全率RE和綜合評價FM[30]對所提算法進行評價,并與主模塊算法(KS)[8]、視覺和運動顯著算法(VMS)[9]和單應模型約束算法(HC)[13]進行定性和定量對比,結果如圖4和表1所示.實驗中,取ηm=0.7,ηa=0.4,η=0.1,超像素初步分類參數T1和T2分別為0.2和0.001.
如圖4所示,不同場景下各種算法都可以大致檢測出感興趣的目標區域,但在檢測的準確度上有所差異.對比可以發現,主模塊算法KS雖然檢測得到了前景目標的主體內容,但在目標的完整性上誤檢區域較為明顯,比如Cars1場景中前輪胎區域和迎面駛來的小汽車的漏檢,以及在靜態場景Highway中未檢測出第二輛行駛的小汽車;視覺和運動顯著性算法VMS檢測出的目標輪廓相對清晰,但當運動目標旁邊存在顏色相似的物體或者場景中含有視覺上較為突出的目標時,也會出現明顯的誤檢,表現為在Cat場景中誤檢了場景中的兩只碗,同時貓的腿部白色區域出現了局部漏檢,在其他場景中也部分出現了上述問題;單應性算法HC的檢測結果相對完整,但目標的過檢測導致邊界不清楚,比如Cars1和Highway場景中將車身與陰影融為了一體,除此之外,該算法在操作過程中需要計算大量運動軌跡,計算復雜度較高;相比前三種算法,本文方法在綜合性能上更為優越,算法采用光流梯度幅值和光流矢量方向兩種方法來確定目標的邊界,在不同場景下得到的目標輪廓都較為清晰準確,并且可以消除部分運動陰影的影響,另外算法對前背景的表觀信息建立混合高斯模型,并結合超像素點的時空鄰域連續性,使檢測的結果更加完整準確.
從表1數據可以看出,不同場景下本文算法的查全率PR和查準率RE多數高于其他算法,表明所提算法對前景目標的檢測準確性明顯提升,綜合評價指標值FM也穩居最高,且基本達到了90%左右,更充分說明了本文算法具有非常好的魯棒性,能夠廣泛適用于不同場景下的運動目標檢測.
為進一步說明本文算法在處理速度上的優勢,同樣在上述10組視頻序列上進行對比實驗,得到4種算法在所有視頻幀上的平均處理時間,結果如表2所示.值得注意的是,動態背景下目標檢測的輸入通常是像素點運動軌跡或幀間光流場,目前二者的計算度非常高,尚不能滿足實時要求,這也是限制動態背景下目標檢測運算速度的主要因素,若想要提高處理速度,可采用GPU加速的光流場或像素點運動軌跡[31].

表1 四種算法的定量評估Table 1.The quantitative resu lt of four algorithMs.

圖4 (網刊彩色)四種算法在不同場景下的前景檢測結果(a)Cat(dynaMic scene);(b)Cars1(dynaMic scene);(c)VPerson(dynaMic scene);(d)Highway(static scene)Fig.4.(color on line)The experiMental resu lts of fou r algorithMs in d iff erent scenes:(a)Cat(dynaMic scene);(b)Cars1(dynaMic scene);(c)VPerson(dynaMic scene);(d)H ighway(static scene).

表2 四種算法的處理速度對比Tab le 2.CoMparison of p rocessing tiMe about fou r algorithMs.
6 結論
本文提出一種基于光流場分析的運動目標檢測算法.算法以相鄰視頻幀的光流矢量為基礎,首先通過光流梯度幅值和光流矢量方向共同確定目標的邊界,得到相對清晰準確的前景輪廓;然后利用點在多邊形內部原理對像素點進行多方向判斷,獲得前景目標內部較準確的稀疏像素點;最后以超像素為節點,將利用混合高斯模型構建的數據項和利用超像素時空鄰域關系構建的平滑項統一納入到馬爾可夫隨機場模型中,并通過圖割最優理論求解模型得到最終的前背景區域分割結果.本文算法具有非常廣泛的適用性,在靜態背景和攝像機任意運動產生的動態背景均能實現準確、魯棒的運動目標檢測.
[1]Radke R,And ra S,Kofahi A,RoysaMB 2005 IEEE Trans.IMage Process.14 294
[2]Ren Y,Chua C,Ho Y 2003 Mach.Vision Appl.13 332
[3]Sheikh Y,Javed O,Kanade T 2009 Conference.on CoMpu ter V ision and Pattern Recognition(CVPR)MiaMi,USA,June 20–25,2009 p1219
[4]Chen L,Zhu S,Li X 2015 International SyMposiuMon CoMputers&InforMatics Beijing,China,January 17–18,2015 p742
[5]Bi G L,Xu Z J,Chen T,W ang J L,Zhang Y S 2015 Acta Phys.Sin.64 150701(in Chinese)[畢國玲,續志軍,陳濤,王建立,張延坤2015物理學報64 150701]
[6]Sun SW,W ang Y F,Huang F,Liao H Y 2013 J.Visual.ComMun.IMage Represen t 24 232
[7]Li A H,CuiZG 2016Moving Object Detection in Videos(Beijing:Science Press)p15(in Chinese)[李艾華,崔智高2016視頻序列運動目標檢測技術(北京:科學出版社)第15頁]
[8]Lee Y,K iMJ,G rauMan K 2011 In ternational Conference on CoMputer Vision(ICCV)Barcelona,Spain,NoveMber 6–13,2011 p1995
[9]LiW T,Chang H S,Lien K C,Chang H T,W ang Y C 2011 IEEE Trans.IMage Proc.22 2600
[10]Zhang D,Javed O,Shah M2013 Conference on Computer Vision and Pattern Recognition(CVPR)O regon,Portland,June 25–27,2013 p682
[11]E lqursh A,E lgamMal A 2012 European Conference on CoMpu ter Vision(ECCV)F lorence,Italy,O ctober 7–13,2012 p228
[12]Gao W,Tang Y,Zhu M2014 Acta Phys Sin.63 094204(in Chinese)[高文,湯洋,朱明2014物理學報63 094204]
[13]Cui Z G,Li A H,Feng G Y 2015 Journal of CoMputer-Aided Design&CoMputer Graphics 27 621(in Chinese)[崔智高,李艾華,馮國彥2015計算機輔助設計與圖形學學報27 621]
[14]W ang J,Adelson E 1994 IEEE Trans.IMage Process.3 625
[15]C reMers D,Soatto S 2004 In t.J.CoMput Vison 62 249
[16]Yoon S,Park S,K ang S 2005 Pattern Recogn it.Lett.26 2221
[17]Adhyapak S,K ehtarnavaz N,Nad in M2007 J.E lectron.IMaging 16 13012
[18]D i S,Mattoccia S,ToMbari F 2005 In ternationalWorkshop on CoMputer Architecture for Machine Perception PalerMo,Italy,Ju ly 4–6,2005 p193
[19]Bouguet J 2001 In tel Corporation 5 10
[20]B rox T,Malik J 2010 European Conference on Computer Vision(ECCV)Crete,G reece,September 5–11,2010 p282
[21]Achanta R,Sha ji A,SMith K 2012 IEEE Trans.Pattern Anal.Mach.In tell.34 2274
[22]Achanta R,Shaji A 2010 EPFL Technical Report 1 149
[23]Vazquez A,Avidan S,P fi ster H 2010 European Conference on CoMpu ter Vision(ECCV)C rete,G reece,September 5–11,2010 p268
[24]Fu lkerson B,Vedald i A,Soatto S 2009 In ternational Conference on CoMputer V ision(ICCV)Kyoto,Japan,Sep teMber 27–October 4,2009 p670
[25]Boykov Y,Veksler O,Zabih R 2001 IEEE Trans.Pattern Anal.Mach.In tell.23 1222
[26]Boykov Y,Funka L 2006 In t.J.CoMput.V ison.70 109
[27]Tron R,V idal R 2007 Conference on CoMputer Vision and Pattern Recognition(CVPR)Minneapolis,USA,June 18–23 2007 p1
[28]Sand P,Teller S 2008 In t.J.CoMpu t.Vison.80 72
[29]Goyette N,Jodoin P,Porikil F 2012 Conference on CoMputer Vision and Pattern Recognition Workshops(CVPRW)Providence,Rhode Island,June 16–21,2012 p1
[30]Cui X,Huang J,Zhang S,Metaxas D 2012 European Conference on CoMputer Vision(ECCV)Florence,Italy,O ctober 7–13,2012 p612
[31]SundaraMN,B rox T,Keutzer K 2010 European Conference on CoMpu ter Vision(ECCV)C rete,G reece,Sep teMber 5–11,2010 p438
(Received 21 October 2016;revised Manuscrip t received 24 January 2017)
PACS:42.30.Tz,07.05.Pj,02.50.–rDOI:10.7498/aps.66.084203
*Pro ject supported by the National Natural Science Foundation of China(G rant No.61501470).
?Corresponding author.E-Mail:cuizg10@tsinghua.edu.cn
Moving ob ject detection based on op tical fl ow fi eld analysis in dynaMic scenes?
Cui Zhi-Gao1)2)?Wang Hua1)Li Ai-Hua1)Wang Tao1)Li Hui1)
1)(The Rocket Force of Engineering University,X i’an 710025,China)2)(DepartMent of Au toMation,Tsinghua University,Beijing 100084,China)
To overcoMe the liMitation of existing algorithMs for detecting Moving ob jects froMthe dynaMic scenes,a foreground detection algorithMbased on optical flow field analysis is p roposed.Firstly,the ob ject boundary information is deterMined by detecting the diff erences in optical fl ow gradient Magnitude and optical fl ow vector direction between foreground and background.Then,the pixels inside the ob jects are obtained based on the point-in-polygon probleMfroMcoMputational geometry.Finally,the superpixels per frame are acquired by over-segmenting method.And taking the superpixels as nodes,the Markov RandoMfield Model is built,in which the appearance in forMation fi tted by Gaussian Mixture Model is combined w ith spatioteMporal constraints of each superpixel.The final foreground detection result is obtained by finding the MinimuMvalue of the energy function.The proposed algorithMdoes not need any priori assuMptions,and can eff ectively realize theMoving ob ject detection in dynaMic and stationary background.The experimental results show that the proposed algorithMis superior to the existing state-of-the-art algorithMs in the detection accuracy,robustness and tiMe consuMing.
dynaMic scene,moving ob ject detection,optical flow field analysis,Markov randoMfield model
10.7498/aps.66.084203
?國家自然科學基金(批準號:61501470)資助的課題.
?通信作者.E-Mail:cuizg10@tsinghua.edu.cn
?2017中國物理學會C h inese P hysica l Society
http://w u lixb.iphy.ac.cn
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
當代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創新大賽)(2020年7期)2020-07-27 08:26:32
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
海峽科技與產業(2016年3期)2016-05-17 04:32:12
