基于QEMU的動(dòng)態(tài)函數(shù)調(diào)用跟蹤
2017-08-12 15:31:07曹睿東毛英明
計(jì)算機(jī)研究與發(fā)展 2017年7期
向 勇 曹睿東 毛英明
1(清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系 北京 100084)2 (北京理工大學(xué)計(jì)算機(jī)學(xué)院 北京 100081)
?
基于QEMU的動(dòng)態(tài)函數(shù)調(diào)用跟蹤
向 勇1曹睿東1毛英明2
1(清華大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系 北京 100084)2(北京理工大學(xué)計(jì)算機(jī)學(xué)院 北京 100081)
(xyong@csnet4.cs.tsinghua.edu.cn)
函數(shù)調(diào)用一直是Linux內(nèi)核分析研究領(lǐng)域的重點(diǎn).獲得函數(shù)調(diào)用信息主要有2種方法:靜態(tài)分析和動(dòng)態(tài)分析.動(dòng)態(tài)跟蹤方法可實(shí)時(shí)和準(zhǔn)確地獲取函數(shù)調(diào)用關(guān)系信息,在分析和調(diào)試軟件程序時(shí)有極大的幫助作用.針對(duì)現(xiàn)有工具存在跟蹤信息不全面、需要編譯選項(xiàng)支持等不足,基于開源的QEMU模擬器,設(shè)計(jì)并實(shí)現(xiàn)了支持多種CPU平臺(tái)的通用動(dòng)態(tài)函數(shù)調(diào)用跟蹤工具,可在x86_32,x86_64,ARM共3種體系架構(gòu)上動(dòng)態(tài)跟蹤包括Linux內(nèi)核啟動(dòng)過程在內(nèi)的函數(shù)調(diào)用和返回信息.該工具在程序運(yùn)行時(shí)截獲調(diào)用和返回的指令,并記錄相關(guān)信息,利用此種指令只會(huì)在QEMU翻譯塊的最后一條出現(xiàn)的性質(zhì),減少檢查指令的數(shù)量,提高運(yùn)行效率;可不依賴源代碼,只依據(jù)函數(shù)符號(hào)表進(jìn)行函數(shù)調(diào)用關(guān)系分析.實(shí)驗(yàn)結(jié)果表明:跟蹤和分析結(jié)果與源代碼行為一致,相比于S2E提升了分析性能和支持的CPU平臺(tái)種類,且能更好地?cái)U(kuò)展至其他平臺(tái).
函數(shù)調(diào)用;動(dòng)態(tài)跟蹤;模擬器;多平臺(tái);Linux內(nèi)核分析
軟件由眾多函數(shù)組織而成,以Linux內(nèi)核代碼為例,已包含了3萬多個(gè)函數(shù).研究和梳理函數(shù)之間的調(diào)用關(guān)系對(duì)軟件的開發(fā)和測(cè)試有極大的幫助,可以為提高程序執(zhí)行效率提供必要的支持[1],在軟件性能研究等方面也有重大意義.
函數(shù)調(diào)用分析又分為2種方法:
1) 靜態(tài)分析,即利用源代碼,得到函數(shù)的信息以及調(diào)用關(guān)系.但是這樣會(huì)存在一些問題,比如有的函數(shù)是通過指針進(jìn)行調(diào)用的,這在C語言編寫的程序中尤為常見,此時(shí)靜態(tài)分析就有些無能為力了[2].還有的函數(shù)是針對(duì)其他體系結(jié)構(gòu)的,完全不會(huì)調(diào)用,使得結(jié)果中存在冗余.
2) 為了能夠得到較為全面且準(zhǔn)確的信息,還需要另一種方法——?jiǎng)討B(tài)分析,即在程序運(yùn)行的過程中實(shí)時(shí)記錄發(fā)生的函數(shù)調(diào)用.通過動(dòng)態(tài)跟蹤產(chǎn)生的結(jié)果首先可以得知程序的執(zhí)行流程,這對(duì)于分析、了解程序的架構(gòu)有很大幫助,以便于快速厘清程序的運(yùn)行邏輯;其次還能知道哪些函數(shù)執(zhí)行的時(shí)間較長、占用的資源較多,可以對(duì)其進(jìn)行針對(duì)性的優(yōu)化,以提高總體的運(yùn)行速度和程序效率,或是在應(yīng)用程序安全分析中起到識(shí)別的作用[3].
有關(guān)函數(shù)調(diào)用的動(dòng)態(tài)分析是系統(tǒng)研究的傳統(tǒng)方向之一,能夠得到函數(shù)調(diào)用關(guān)系圖的工具有很多,比如GNU binutils系列工具集中的gprof[4],Linux自2.6版本之后已集成在內(nèi)核中的強(qiáng)大的內(nèi)核分析工具Ftrace中的Function Tracer函數(shù)調(diào)用動(dòng)態(tài)跟蹤器,以及診斷Linux系統(tǒng)問題的SystemTap軟件.或者直接利用GCC編譯器的功能在程序中進(jìn)行插樁,在每次進(jìn)入和退出函數(shù)的時(shí)候分別進(jìn)行記錄.
然而這些軟件對(duì)編譯源代碼都有一定的要求,例如gprof只能針對(duì)應(yīng)用程序,無法用于內(nèi)核;Ftrace需要在編譯內(nèi)核時(shí)打開相關(guān)的編譯選項(xiàng);SystemTap無法進(jìn)行系統(tǒng)啟動(dòng)早期階段的跟蹤;直接插樁的方法也要重新編譯內(nèi)核,上面這些方法并不能完全滿足當(dāng)前的實(shí)際需要.
而使用模擬器技術(shù)可以很好地對(duì)函數(shù)調(diào)用關(guān)系進(jìn)行動(dòng)態(tài)跟蹤,而對(duì)模擬器內(nèi)部的系統(tǒng)沒有影響,不需要對(duì)源代碼修改或者插樁,也無需對(duì)程序重新進(jìn)行編譯,同時(shí)可以完整地跟蹤虛擬機(jī)中運(yùn)行的操作系統(tǒng)從啟動(dòng)開始的所有函數(shù)調(diào)用,并獲得機(jī)器中一些必要的實(shí)時(shí)狀態(tài)信息.S2E[5]是基于QEMU[6]模擬器和KLEE開發(fā)的符號(hào)執(zhí)行軟件,提供了插件接口截獲系統(tǒng)運(yùn)行時(shí)的指令,可以通過指令篩選的方法獲得函數(shù)調(diào)用關(guān)系.雖然可以利用它較完善地實(shí)現(xiàn)需求的功能[7],但是S2E軟件本身也存在著一些限制,例如只能運(yùn)行在x86_64的機(jī)器上,同時(shí)也只能跟蹤x86_32平臺(tái),不能在其他平臺(tái)上工作,而且運(yùn)行速度也較慢.
本文的目的是不依賴S2E而直接對(duì)QEMU進(jìn)行修改,全面跟蹤包括啟動(dòng)階段在內(nèi)的操作系統(tǒng)執(zhí)行過程中的所有函數(shù)調(diào)用;利用QEMU的跨平臺(tái)特性,在它支持的多種平臺(tái)上實(shí)現(xiàn)這個(gè)功能,包括x86_32,x86_64,ARM,并且能較方便地?cái)U(kuò)展至其他平臺(tái),形成較為通用的方法;支持沒有源代碼的系統(tǒng)軟件跟蹤,提高運(yùn)行的速度和跟蹤性能.基本的思路是監(jiān)控QEMU的行為,當(dāng)遇到函數(shù)調(diào)用或返回的指令時(shí)將相關(guān)信息輸出到日志文件之中,按照標(biāo)準(zhǔn)格式對(duì)數(shù)據(jù)進(jìn)行處理,形成函數(shù)調(diào)用關(guān)系圖.選擇在線處理方式,即在生成數(shù)據(jù)的同時(shí),另一個(gè)工作進(jìn)程讀取日志并解析,將運(yùn)行過程流水化,以提高效率.
1 基于QEMU的動(dòng)態(tài)函數(shù)調(diào)用
1.1 “快速模擬器”QEMU
QEMU是個(gè)應(yīng)用廣泛的開源軟件,可以作為模擬器來使用,它承擔(dān)了模擬各種硬件、外設(shè),翻譯指令、執(zhí)行指令等所有的工作.因此所有在虛擬機(jī)中要執(zhí)行的指令,都會(huì)由QEMU進(jìn)行翻譯成宿主機(jī)可以識(shí)別的指令之后再進(jìn)行.可以通過這個(gè)特性截獲虛擬機(jī)中的函數(shù)調(diào)用和返回指令,從而得到函數(shù)調(diào)用信息.同時(shí)QEMU還具有仿真速度快和跨平臺(tái)的特性,可以模擬包括x86,MIPS,ARM,PowerPC等多種CPU架構(gòu),這樣可以滿足擴(kuò)展至多平臺(tái)的要求[8].
QEMU采用了動(dòng)態(tài)二進(jìn)制翻譯技術(shù),即在運(yùn)行過程中將客戶機(jī)的二進(jìn)制代碼翻譯為宿主機(jī)的二進(jìn)制代碼,從而在宿主機(jī)上執(zhí)行.QEMU的指令翻譯和執(zhí)行都是以“翻譯塊”(translation block, TB)為基本單位進(jìn)行的.所謂的翻譯塊就是數(shù)條連續(xù)執(zhí)行指令的集合,其最后一條指令只能是分支指令如跳轉(zhuǎn)、函數(shù)調(diào)用等可以修改當(dāng)前CPU指令地址的指令[9].為了提高執(zhí)行的速度,QEMU使用了翻譯緩存的機(jī)制,即將翻譯好的宿主機(jī)代碼存入散列表中再執(zhí)行,可供之后的反復(fù)使用而不是再重新翻譯.而考慮到避免在控制代碼和客戶機(jī)代碼之間因?yàn)榻?jīng)常跳轉(zhuǎn)所帶來的開銷,QEMU又使用了塊鏈接的機(jī)制,即翻譯好代碼塊后就嘗試將其與之前的翻譯塊鏈接起來,如果之前的翻譯塊與這個(gè)將要執(zhí)行的翻譯塊的客戶機(jī)代碼不跨內(nèi)存分頁的話,則在它們之間建立直接跳轉(zhuǎn),形成鏈表,這樣大部分的跳轉(zhuǎn)是在翻譯塊之間進(jìn)行的,它們處于同一個(gè)運(yùn)行時(shí)上下文,因此沒有返回QEMU代碼時(shí)所需的切換上下文等復(fù)雜的操作[10],如圖1所示:
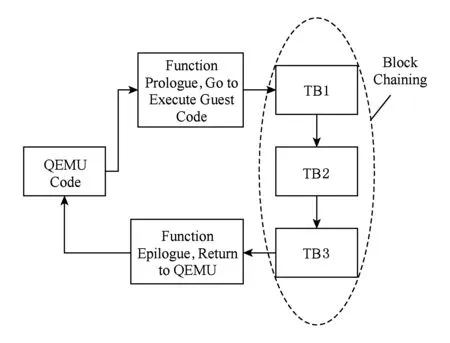
Fig.1 QEMU block chaining圖1 QEMU塊鏈接示意圖
QEMU的運(yùn)行流程是啟動(dòng)后從客戶機(jī)的第1條代碼開始,首先查看客戶機(jī)當(dāng)前的指令指針(program counter, PC)對(duì)應(yīng)的翻譯塊是否在翻譯緩存中,如果沒有的話則進(jìn)行翻譯,并加入翻譯緩存后再執(zhí)行;否則直接執(zhí)行緩存好的代碼,如此循環(huán),如圖2所示:
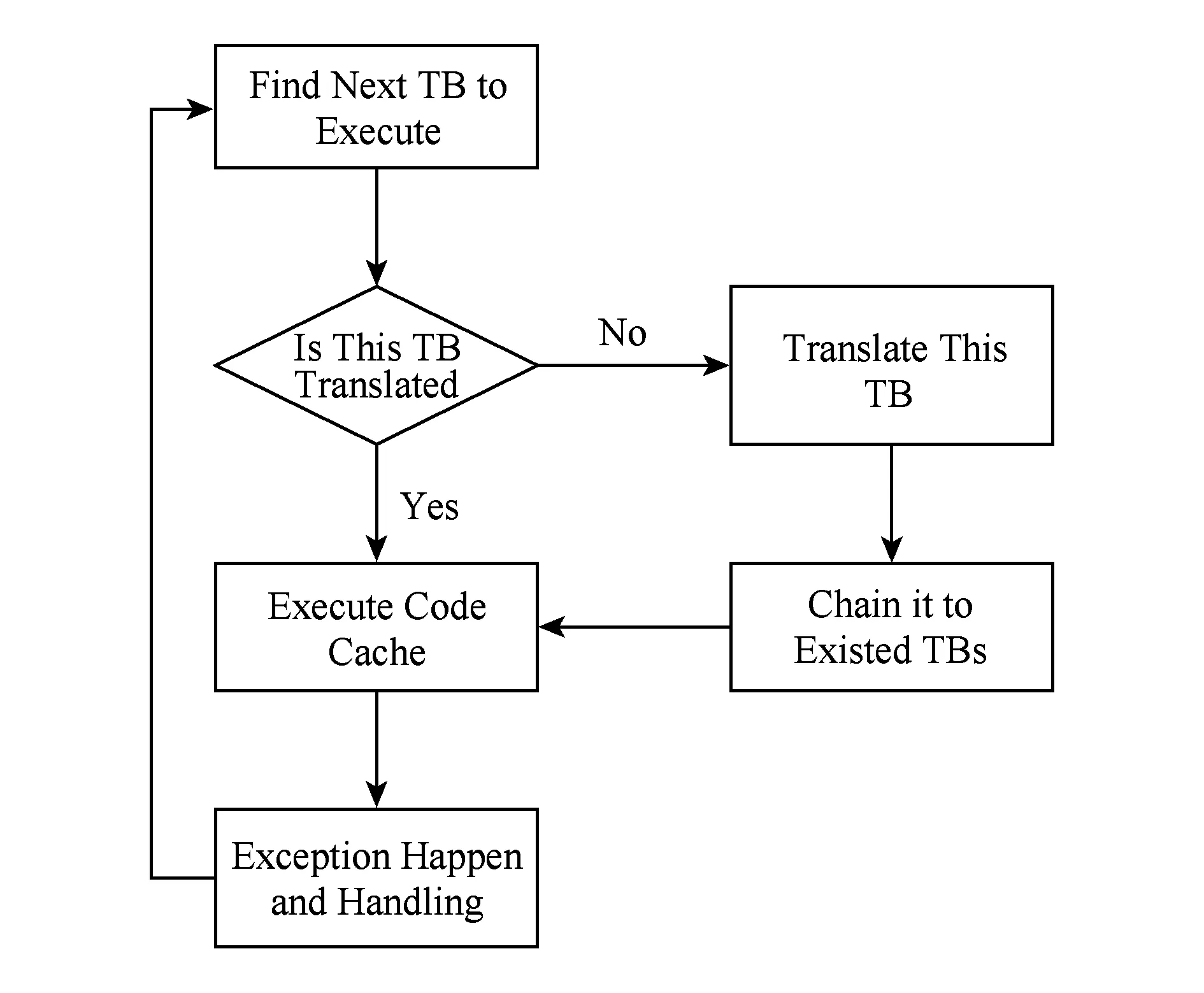
Fig.2 QEMU execution flow chart圖2 QEMU運(yùn)行流程圖
本文要解決的核心問題是:如何在多種平臺(tái)下如x86和ARM中動(dòng)態(tài)地獲取函數(shù)調(diào)用與返回的信息,生成函數(shù)調(diào)用關(guān)系數(shù)據(jù),保證完整和全面;同時(shí)考慮到性能,提高執(zhí)行速度,減少模擬速度慢導(dǎo)致的軟件運(yùn)行異常.
1.2 設(shè)計(jì)思路
如1.1節(jié)所述,QEMU模擬器使用動(dòng)態(tài)二進(jìn)制翻譯技術(shù),所有指令在執(zhí)行前都會(huì)被翻譯,所以可以通過在翻譯時(shí)識(shí)別函數(shù)調(diào)用和返回指令,對(duì)代碼塊進(jìn)行標(biāo)記.在執(zhí)行這些塊之前使用QEMU提供的API獲取如時(shí)間、讀取客戶機(jī)內(nèi)存中的進(jìn)程標(biāo)識(shí)、線程標(biāo)志等信息,利用QEMU已有的輸出日志功能保存到文件中.其中需要額外注意的是信息的完整和全面性問題,QEMU原本的塊鏈接機(jī)制會(huì)造成其中的一些函數(shù)調(diào)用由于沒有返回到主控代碼中而無法輸出到日志中,因此需要禁用塊鏈接,每次執(zhí)行翻譯塊之后都會(huì)返回控制代碼中檢查是否發(fā)生了函數(shù)調(diào)用或返回,保證能夠獲取到所有的函數(shù)調(diào)用關(guān)系.
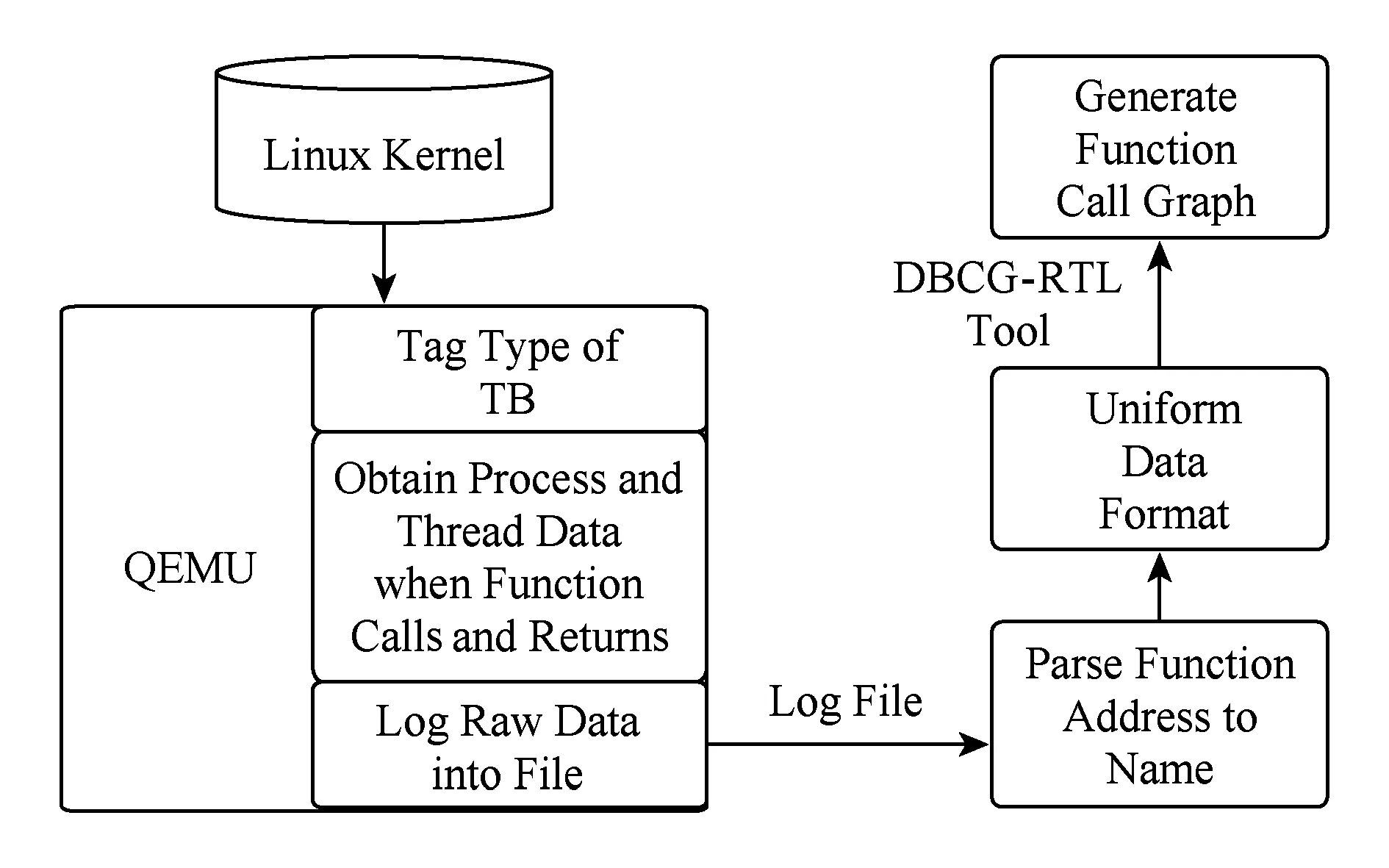
Fig.3 Dynamic function call tracing architecture design圖3 動(dòng)態(tài)函數(shù)調(diào)用跟蹤的結(jié)構(gòu)設(shè)計(jì)圖
本文為了獲取函數(shù)調(diào)用信息,需要進(jìn)行4部分的工作,其中前3部分是對(duì)QEMU進(jìn)行的修改,以支持多個(gè)平臺(tái)上的動(dòng)態(tài)函數(shù)調(diào)用跟蹤.
1) 利用QEMU已有的日志輸出功能,增加跟蹤選項(xiàng),進(jìn)行信息的輸出;這部分是與平臺(tái)無關(guān)的.
2) 根據(jù)QEMU塊翻譯的特點(diǎn)和目標(biāo)平臺(tái)CPU指令集的特征,在遇到函數(shù)調(diào)用和返回指令時(shí)對(duì)代碼塊進(jìn)行標(biāo)記;這些信息的獲取是與平臺(tái)相關(guān)的,平臺(tái)的指令集不同,需要識(shí)別的函數(shù)調(diào)用和返回指令也不同.
3) 操作系統(tǒng)的進(jìn)程和線程等語義信息的獲取;這也是與平臺(tái)相關(guān)的,并且依賴對(duì)操作系統(tǒng)的了解,QEMU針對(duì)不同的平臺(tái)有不同的模擬代碼,存儲(chǔ)的數(shù)據(jù)結(jié)構(gòu)也有不同.
4) 根據(jù)操作系統(tǒng)內(nèi)核的符號(hào)表,進(jìn)行函數(shù)符號(hào)的解析.
本文使用DBCG-RTL[11]工具作為后端對(duì)數(shù)據(jù)進(jìn)行處理.DBCG-RTL可以對(duì)滿足工具格式要求的函數(shù)調(diào)用關(guān)系數(shù)據(jù)進(jìn)行函數(shù)調(diào)用與返回的匹配,生成函數(shù)調(diào)用關(guān)系圖,比起文字來圖片有更清晰、明了的展示效果,也可以讓人更直觀地觀察函數(shù)之間的聯(lián)系.整體的結(jié)構(gòu)設(shè)計(jì)如圖3所示.
1.3 跟蹤數(shù)據(jù)格式
由于需要跟蹤多個(gè)平臺(tái)的函數(shù)調(diào)用,所以應(yīng)該設(shè)計(jì)統(tǒng)一的數(shù)據(jù)格式,同時(shí)還要滿足DBCG-RTL工具的要求.
首先,最基本的信息包括被調(diào)函數(shù)的地址.為了得到函數(shù)調(diào)用的時(shí)序關(guān)系,還需要當(dāng)前虛擬機(jī)的時(shí)間.為了進(jìn)行函數(shù)調(diào)用和返回的匹配,還需要當(dāng)前的進(jìn)程標(biāo)識(shí)、線程標(biāo)識(shí)和當(dāng)前的棧頂指針.根據(jù)Linux內(nèi)核的設(shè)計(jì),由于分頁機(jī)制,8 KB內(nèi)存為2頁,而線程的內(nèi)核棧應(yīng)該存在于這2頁之中,故可以利用棧頂指針將低13 b屏蔽為0的結(jié)果來標(biāo)識(shí)當(dāng)前線程.可以在解析日志時(shí)進(jìn)行處理,假設(shè)當(dāng)前棧頂指針為esp,則線程標(biāo)識(shí)為esp&0xffffe000的值.而區(qū)分函數(shù)的位置,例如函數(shù)是來自內(nèi)核或者可加載模塊,則需要函數(shù)所在模塊的名稱.根據(jù)以上的分析,需要直接在虛擬機(jī)中獲取的函數(shù)調(diào)用信息格式為“當(dāng)前虛擬機(jī)時(shí)間進(jìn)程標(biāo)識(shí) 當(dāng)前棧頂指針 被調(diào)函數(shù)地址 函數(shù)所在模塊名稱”,函數(shù)返回信息的格式為“當(dāng)前虛擬機(jī)時(shí)間 進(jìn)程標(biāo)識(shí) 當(dāng)前棧頂指針”.
具體的輸出數(shù)據(jù)與平臺(tái)的位數(shù)有關(guān),例如32 b平臺(tái)上,表示“在0xba66171d時(shí)刻,發(fā)生了函數(shù)調(diào)用,此時(shí)的PID為0x1907000,棧頂?shù)刂窞閏1837fb0,函數(shù)的入口地址為c18c696;在0xba66adb5時(shí)刻,發(fā)生了函數(shù)返回,此時(shí)的PID為0x1907000,棧頂?shù)刂窞閏1837fb0”,則對(duì)應(yīng)的輸出數(shù)據(jù)如下:
0xba66171d 0x1907000 c1837fb0 c18c6596 kernel
0xba66adb5 0x1907000 c1837fb0
在64 b的平臺(tái)上,輸出數(shù)據(jù)中的進(jìn)程標(biāo)識(shí)、當(dāng)前棧頂指針和被調(diào)函數(shù)地址的位數(shù)由32 b變?yōu)?4 b.
1.4 標(biāo)記翻譯塊類型
如1.1節(jié)中所說,每個(gè)翻譯塊的最后一條指令只會(huì)是跳轉(zhuǎn)指令,因此可以以翻譯塊為分析的基本單位.在翻譯塊的數(shù)據(jù)結(jié)構(gòu)中增加變量type表示它的類型,并在開始翻譯時(shí)將當(dāng)前的翻譯塊標(biāo)記為一般塊.當(dāng)遇到函數(shù)調(diào)用語句時(shí),將這個(gè)翻譯塊標(biāo)記為發(fā)生了函數(shù)調(diào)用;當(dāng)遇到返回語句時(shí),將這個(gè)翻譯塊標(biāo)記為發(fā)生了函數(shù)返回.
函數(shù)調(diào)用就是在一個(gè)函數(shù)在運(yùn)行中進(jìn)入另一個(gè)函數(shù),執(zhí)行其代碼再返回到主調(diào)函數(shù)的過程.而被調(diào)函數(shù)的入口地址就是它第1條指令的地址,所以只要記錄函數(shù)調(diào)用語句下一條被執(zhí)行指令的地址,也就記錄下了被調(diào)函數(shù)的地址,這個(gè)地址可以進(jìn)一步解析為函數(shù)名稱、所在文件和行號(hào),方便與源代碼進(jìn)行對(duì)照.
當(dāng)QEMU執(zhí)行完一個(gè)翻譯塊時(shí),會(huì)返回到主控循環(huán)中,然后尋找下一個(gè)要執(zhí)行的塊.翻譯塊的數(shù)據(jù)結(jié)構(gòu)中包含第1條指令的地址即PC值的信息.此時(shí)下一個(gè)翻譯塊的PC值就是被調(diào)用函數(shù)的地址.
在1.1節(jié)提到QEMU使用了名為“塊鏈接”的機(jī)制,如果QEMU一直在執(zhí)行翻譯緩存而不返回到主控循環(huán)中,那么中間產(chǎn)生的一些函數(shù)調(diào)用和返回就無法被我們捕獲.因此如果開啟了跟蹤函數(shù)調(diào)用的功能,就要屏蔽塊鏈接機(jī)制,使得每執(zhí)行完一個(gè)翻譯塊,都會(huì)回到主控循環(huán)中.對(duì)每一個(gè)翻譯塊的類型進(jìn)行判斷,如果是函數(shù)調(diào)用或者返回,則輸出相關(guān)信息到日志中,就可以跟蹤虛擬機(jī)中所有的函數(shù)調(diào)用和返回情況了.這樣雖然會(huì)帶來對(duì)性能的影響,但是保證了數(shù)據(jù)的完整性和全面性.我們?cè)u(píng)估了修改前后的執(zhí)行時(shí)間,在相同的硬件環(huán)境中使用QEMU啟動(dòng)Linux3.5.4內(nèi)核,原生即啟用塊鏈接的情況下耗時(shí)3.06 s,禁用塊鏈接則耗時(shí)14.23 s,增加了3.65倍,總體的開銷與原生的在同一數(shù)量級(jí)上.
然而在實(shí)際中,不同CPU平臺(tái)上對(duì)翻譯塊分類的判斷仍不大相同.x86平臺(tái)只依據(jù)指令就能作出判斷,而在ARM平臺(tái)上還需要參考指令的操作數(shù)等具體情況.
因?yàn)閤86_64指令集是x86指令集的擴(kuò)展,實(shí)現(xiàn)了32 b向64 b的過渡,所以x86_64指令集是可以兼容x86指令集的,在指令標(biāo)記上它們可以通用,只是數(shù)據(jù)位數(shù)不同,在輸出日志時(shí)還會(huì)稍有區(qū)別.以x86匯編為例,函數(shù)調(diào)用使用CALL指令,函數(shù)返回使用RET指令.但需要注意的是同一類型的指令可能對(duì)應(yīng)多個(gè)操作碼,QEMU也是根據(jù)操作碼來區(qū)分不同的指令,進(jìn)行相應(yīng)的翻譯操作.
通過查閱Intel指令手冊(cè)可以得知,CALL指令對(duì)應(yīng)多個(gè)不同的操作碼,分別是E8,9A,F(xiàn)F,表示相對(duì)尋址、間接尋址、直接絕對(duì)尋址、立即數(shù)尋址等多種不同的尋址方式.所以需要在每一種情況中都增加標(biāo)記翻譯塊類型的操作.函數(shù)返回使用的RET指令也如此處理,將所有可能出現(xiàn)的情況都覆蓋,保證了信息不會(huì)丟失.
對(duì)于ARM平臺(tái),它與x86有很大不同.因?yàn)樗鼈兏镜捏w系結(jié)構(gòu)差異較大,ARM基于RISC而x86主要基于CISC,所以在ARM上實(shí)現(xiàn)同樣的功能可能會(huì)需要更多的工作.ARM芯片的特點(diǎn)之一是大量使用寄存器,數(shù)量多達(dá)37個(gè),如通用寄存器R0~R15,從名字到功能不一定能和x86上的一一對(duì)應(yīng).另一個(gè)特點(diǎn)是指令歸整、簡(jiǎn)單,基本尋址方式有2~3種.ARM的指令集中沒有類似x86的CALLRET指令來表示函數(shù)調(diào)用和返回,因?yàn)樗鼈兛梢哉J(rèn)為是跳轉(zhuǎn)的特殊情況.根據(jù)ARM程序調(diào)用過程規(guī)范,子程序跳轉(zhuǎn)一般使用BL或BLX指令.同時(shí),ARM指令集的子函數(shù)返回功能是通過BX LR或者出棧語句如POP{R4,PC}來實(shí)現(xiàn)的,因?yàn)楹瘮?shù)返回的效果即是將PC也就是指令指針設(shè)定為函數(shù)調(diào)用的下一條語句.此時(shí)需要判斷pop指令的操作數(shù)中是否包含PC寄存器,如果有則表示起到了函數(shù)返回的功能;否則只是一般的出棧操作.因此ARM指令集不像x86那樣易于識(shí)別和標(biāo)記,需要對(duì)多個(gè)指令進(jìn)行分析,然后根據(jù)操作碼進(jìn)行相應(yīng)的標(biāo)記.
1.5 獲取函數(shù)調(diào)用相關(guān)的CPU狀態(tài)信息
根據(jù)1.3節(jié)的數(shù)據(jù)格式,需要獲取當(dāng)前虛擬機(jī)時(shí)間、進(jìn)程標(biāo)識(shí)、當(dāng)前棧頂指針、函數(shù)所在模塊名稱4項(xiàng)內(nèi)容.
當(dāng)前虛擬機(jī)的時(shí)間可以直接通過QEMU提供的API函數(shù)qemu_clock_get_ns來讀取,比較方便.
進(jìn)程標(biāo)識(shí)和棧頂指針在真實(shí)的物理機(jī)器中一般都保存在寄存器中.在QEMU中維護(hù)著一個(gè)變量env,它模擬了目標(biāo)機(jī)CPU與平臺(tái)相關(guān)的部分,包括了所有寄存器、標(biāo)志位的值,代表目標(biāo)機(jī)的當(dāng)前狀態(tài),可以通過讀取這個(gè)變量來獲得寄存器的值.
不同的體系結(jié)構(gòu)中寄存器的配置也不相同.在x86中,可以使用CR3寄存器來標(biāo)識(shí)進(jìn)程,因?yàn)樗4媪隧撃夸洷淼奈锢韮?nèi)存基地址,每個(gè)進(jìn)程的值都不一樣;棧頂指針則由ESP寄存器保存,可以直接讀取.在ARM中,頁目錄表的物理內(nèi)存基址一般保存在協(xié)處理器CP15中的TTBR0寄存器,QEMU中使用變量ttbr0_el1模擬.棧頂指針則由R13寄存器保存.
函數(shù)所在模塊的名稱可以表示函數(shù)的來源.如果是內(nèi)核中的函數(shù),則規(guī)定所在模塊的名稱為kernel.如果函數(shù)來自內(nèi)核可加載模塊,則需要讀取虛擬機(jī)的內(nèi)存獲得模塊的名字.這需要依賴操作系統(tǒng)源碼進(jìn)行的分析.Linux在內(nèi)存中維護(hù)著一個(gè)存儲(chǔ)可加載模塊信息的環(huán)形鏈表,每加載一個(gè)模塊,就會(huì)向鏈表中插入一個(gè)新的節(jié)點(diǎn).第1個(gè)模塊的加載地址是固定的,即內(nèi)核符號(hào)表中變量modules的值.模塊的數(shù)據(jù)結(jié)構(gòu)中含有名字以及加載地址、模塊大小等信息.可以通過它們相對(duì)于結(jié)構(gòu)體的偏移量來計(jì)算變量在內(nèi)存中的實(shí)際地址,然后可以利用QEMU提供的訪問客戶機(jī)內(nèi)存的API函數(shù)cpu_memory_rw_debug()來讀取相應(yīng)地址的內(nèi)容.這一部分主要與平臺(tái)的位數(shù)有關(guān),它決定了偏移量的大小,也與內(nèi)核版本有關(guān),不同的版本可能導(dǎo)致數(shù)據(jù)結(jié)構(gòu)有所變化.
我們可以根據(jù)這一特點(diǎn)遍歷整個(gè)鏈表,查找每個(gè)模塊的起始地址和大小,當(dāng)被調(diào)函數(shù)的地址在某一模塊的起始地址和結(jié)束地址即起始地址+模塊大小之間時(shí),認(rèn)為函數(shù)屬于此模塊,讀取并記錄模塊的名字和函數(shù)相對(duì)于模塊的偏移量即函數(shù)實(shí)際地址-模塊加載地址.這樣在解析的時(shí)候就能夠直接利用相應(yīng)模塊的符號(hào)表信息了.
1.6 日志解析
使用DBCG-RTL工具可以畫出函數(shù)調(diào)用關(guān)系圖.需要將日志文件處理成DBCG-RTL規(guī)定的標(biāo)準(zhǔn)格式,即“PID:pidTID:tidCALL_TIME:time1 RETURN_TIME:time2 FROM:function1:file1:line1 TO:function2:file2:line2 TIME:deltatime”.
主要是將函數(shù)地址解析成函數(shù)名稱和將棧頂指針處理為線程標(biāo)識(shí)符即可.僅需要執(zhí)行程序的符號(hào)表信息,而不需要整體的源代碼.DBCG-RTL的數(shù)據(jù)庫表中存儲(chǔ)有函數(shù)的地址、名稱、所在文件、起始行號(hào)等信息,因此可以利用數(shù)據(jù)庫來進(jìn)行解析工作.
以自己編寫的可加載模塊的函數(shù)調(diào)用為例,驗(yàn)證數(shù)據(jù)的正確性.內(nèi)核的可加載模塊有著一系列的編寫格式和規(guī)范,比如必須包括初始化模塊的函數(shù)init_module和卸載模塊的函數(shù)cleanup_module,這里不作贅述.按照標(biāo)準(zhǔn)編寫一個(gè)非常簡(jiǎn)單的可加載模塊,它的功能是遞歸地計(jì)算5的階乘并輸出,源代碼如下:
intfactorial(intnum) {
if (num==1‖num==0)
return 1;
else
returnnum*factorial(num-1);
}
intinit_module(void){
printk(KERN_INFO “5!=%d ”,factorial(5));
return 0;
}
voidcleanup_module(void){
printk(KERN_INFO “Goodbye! ”);
}
編譯后生成內(nèi)核模塊文件,然后加載這個(gè)模塊,會(huì)自動(dòng)執(zhí)行其中的函數(shù)init_moudle.跟蹤出的原始數(shù)據(jù)如圖4所示:

Fig.4 Loadable kernel module tracing data圖4 可加載模塊跟蹤結(jié)果
factorial.ko文件的符號(hào)表如表1 所示:
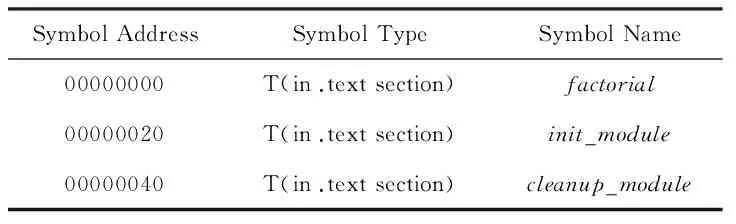
Table 1 Symbol Table of File factorial.ko表1 factorial.ko文件的符號(hào)表
可以看到,第2條記錄表明首先調(diào)用了函數(shù)init_module進(jìn)行初始化,然后調(diào)用了4次函數(shù)factorial,因?yàn)閒actorial(2)在計(jì)算factorial(1)時(shí)后者的結(jié)果已被編譯器直接優(yōu)化為1了,不再發(fā)生函數(shù)調(diào)用了,然后是4次逐級(jí)的函數(shù)返回.接下來的一條函數(shù)調(diào)用地址c1620fdc正是內(nèi)核函數(shù)printk的地址.經(jīng)過對(duì)比可以發(fā)現(xiàn)跟蹤出的數(shù)據(jù)與源代碼的行為相同,即發(fā)生了init_module到factorial,factorial到自身的遞歸調(diào)用和init_module到printk的函數(shù)調(diào)用.而且運(yùn)行時(shí)讀取的進(jìn)程號(hào)和棧頂指針的值可以對(duì)應(yīng)起來,函數(shù)調(diào)用與返回信息能夠互相匹配,說明了數(shù)據(jù)的正確性.
從這個(gè)例子也可以看出,我們的工具對(duì)于嵌套的函數(shù)調(diào)用如遞歸和普通的函數(shù)調(diào)用的處理是一致的.遞歸函數(shù)的進(jìn)程標(biāo)識(shí)都是071c5000,線程標(biāo)識(shí)經(jīng)過計(jì)算都是c71a6000,被調(diào)用的地址也都一樣,唯一不同的是棧頂指針依次遞減,通過棧幀的結(jié)構(gòu)可以看出發(fā)生了3次函數(shù)factorial到自身的遞歸調(diào)用.
當(dāng)然有的特殊情況可能只有函數(shù)調(diào)用或返回,而沒有配對(duì)的信息,比如一些明確聲明為noreturn的函數(shù),主要為一些可能出現(xiàn)錯(cuò)誤的函數(shù),而經(jīng)過fork之后父子進(jìn)程會(huì)分別返回,但是只有一次調(diào)用.
對(duì)于將函數(shù)地址解析成函數(shù)名稱和位置,以及調(diào)用與返回匹配的工作,可以選擇在運(yùn)行時(shí)進(jìn)行,也可以在整個(gè)系統(tǒng)運(yùn)行結(jié)束后進(jìn)行.日志的數(shù)量很大,邊運(yùn)行邊處理會(huì)較快地得到結(jié)果,選擇這種在線的處理方式效果更好.
1.7 擴(kuò)展支持其他CPU平臺(tái)
為了將函數(shù)調(diào)用跟蹤分析功能在其他CPU平臺(tái)上實(shí)現(xiàn),本文已對(duì)實(shí)現(xiàn)方法中與平臺(tái)相關(guān)的部分進(jìn)行了特別說明,只需了解目標(biāo)平臺(tái)的一些架構(gòu)信息和指令集信息;其他部分如輸出日志的功能都是通用的,不需要重新編寫.
以在MIPS上實(shí)現(xiàn)基于QEMU的動(dòng)態(tài)函數(shù)調(diào)用跟蹤為例.首先應(yīng)根據(jù)MIPS32或者M(jìn)IPS64數(shù)據(jù)位數(shù)的不同來修正一些成員變量在結(jié)構(gòu)體中偏移量的值和輸出的格式;其次,應(yīng)了解一些架構(gòu)信息,如對(duì)應(yīng)x86中CR3寄存器存儲(chǔ)頁目錄基地址的是MIPS中的哪個(gè)寄存器,堆棧指針又是由哪個(gè)寄存器來存儲(chǔ)的,在QEMU中由哪些變量來表示,輸出日志時(shí)需要獲取這些變量的值;最后是查閱MIPS的指令集,如果有專門的函數(shù)調(diào)用和返回語句,像x86那樣,那么只要找到這些指令對(duì)應(yīng)的所有操作碼并作標(biāo)記操作即可.否則,可能需要將所有可能的跳轉(zhuǎn)語句都記錄下來,利用一些其他條件如操作數(shù)進(jìn)行篩選和過濾,處理之后形成最終的調(diào)用和返回語句.
2 與S2E的比較
2.1 功能特性
S2E本身對(duì)QEMU進(jìn)行了大量的修改,最大的功能是符號(hào)執(zhí)行,其中最主要的是基于虛擬機(jī)當(dāng)前狀態(tài)的事件處理機(jī)制和插件編寫模式.S2E有完整的模塊化插件架構(gòu),插件之間通過發(fā)布、訂閱的事件處理機(jī)制交互.事件可以由S2E軟件本身或者其他自己編寫的插件產(chǎn)生.如果插件需要訂閱某種事件,比如函數(shù)調(diào)用,需要注冊(cè)這個(gè)事件,并聲明回調(diào)函數(shù).那么當(dāng)這個(gè)事件觸發(fā)之后,會(huì)自動(dòng)調(diào)用插件中設(shè)定的對(duì)應(yīng)的回調(diào)函數(shù),執(zhí)行規(guī)定的動(dòng)作.
然而S2E不能夠很好地跨平臺(tái),目前僅支持在x86_64系統(tǒng)中模擬x86_32客戶機(jī),對(duì)ARM的支持還處在實(shí)驗(yàn)狀態(tài).同時(shí)開發(fā)者的發(fā)布速度較慢[12],相比于原始的QEMU缺失了很多新功能.
我們直接對(duì)QEMU進(jìn)行修改,只實(shí)現(xiàn)了跟蹤函數(shù)調(diào)用與返回這一個(gè)常用功能.這樣的優(yōu)點(diǎn)是修改的內(nèi)容較少,也不會(huì)對(duì)原有的其他功能產(chǎn)生影響,便于開發(fā)和調(diào)試.同時(shí)也能很快地在其他的平臺(tái)上實(shí)現(xiàn),而不需要重新實(shí)現(xiàn)S2E這樣復(fù)雜的功能平臺(tái).修改分為2部分:1)平臺(tái)無關(guān)的,如整體的執(zhí)行流程框架:翻譯—執(zhí)行—輸出日志,這部分各個(gè)平臺(tái)是統(tǒng)一的,不需要重復(fù)實(shí)現(xiàn);2)與平臺(tái)相關(guān),我們提供了設(shè)置翻譯塊類型等幫助函數(shù),在不同平臺(tái)的翻譯過程中的適當(dāng)位置插入即可,同時(shí)將獲取寄存器值等跟CPU架構(gòu)相關(guān)的函數(shù)抽象成接口,只要實(shí)現(xiàn)了特定平臺(tái)上的這些函數(shù),執(zhí)行時(shí)就會(huì)根據(jù)平臺(tái)調(diào)用不同的函數(shù),比起S2E更加容易擴(kuò)展.
2.2 性能比較
本文工具的另一個(gè)優(yōu)點(diǎn)是直接操縱QEMU原生的一些數(shù)據(jù)結(jié)構(gòu),而不通過S2E,同時(shí)將解析的工作交給另一個(gè)進(jìn)程,處理的速度也會(huì)大大地提高.針對(duì)動(dòng)態(tài)函數(shù)調(diào)用跟蹤這個(gè)功能而言,在相同的實(shí)驗(yàn)環(huán)境中,跟蹤內(nèi)核為Linux3.5.4和根文件系統(tǒng)為busybox的鏡像從開機(jī)到內(nèi)核啟動(dòng)完畢出現(xiàn)shell的所有函數(shù)調(diào)用關(guān)系,S2E消耗的時(shí)間為3 520.13 s,大約1 h,而使用本文的工具運(yùn)行和解析總共的時(shí)間為1 810.69 s.整體效率比S2E提升了94.4%.通過以上實(shí)驗(yàn)可以看出本文工具的性能要強(qiáng)于S2E.
3 結(jié)論與展望
本文基于QEMU實(shí)現(xiàn)了針對(duì)Linux操作系統(tǒng)的動(dòng)態(tài)函數(shù)調(diào)用分析,利用模擬器的特性,可跟蹤自系統(tǒng)啟動(dòng)開始后的所有函數(shù)調(diào)用和返回信息.此功能可以方便地支持多種平臺(tái),分別在x86_32,x86_64,ARM平臺(tái)進(jìn)行了實(shí)現(xiàn).同時(shí)將數(shù)據(jù)的獲取和解析2個(gè)步驟并行進(jìn)行,提高了處理效率.在對(duì)跟蹤得出的原始數(shù)據(jù)經(jīng)過初步處理后,可以為分析軟件的執(zhí)行邏輯、瓶頸或逆向工程提供一定的支持.
本文的工作還有一些不足,例如輸出信息的性能有很大的提升空間,可以使用一些壓縮算法;由于使用模擬器,QEMU的時(shí)鐘與真實(shí)系統(tǒng)有所差距,可能導(dǎo)致操作系統(tǒng)的行為異常[13].可以擴(kuò)展的地方也有很多,如增加對(duì)函數(shù)參數(shù)和返回值的獲取,進(jìn)一步提高函數(shù)調(diào)用分析的能力;目前模擬跟蹤的是單核CPU,以后會(huì)擴(kuò)展到多核CPU上,有很多文獻(xiàn)利用了多核加速Q(mào)EMU的CPU模擬[14-16],主要的變化是需在輸出中增加CPU的標(biāo)識(shí)符,并在解析時(shí)對(duì)不同CPU上的函數(shù)調(diào)用和返回信息使用不同的棧來匹配,可以顯著地提高程序的運(yùn)行速度.
[1]Zheng Yuhui, Mu Yongmin, Zhang Zhihua. Research on the static function call path generating automatically[C]Proc of the 2nd IEEE Int Conf on Information Management and Engineering. Piscataway, NJ: IEEE, 2010: 405-409
[2]Terashima Y, Gondow K. Static call graph generator for C++ using debugging information[C]Proc of the 14th Asia-Pacific Software Engineering Conf (APSEC’07). Piscataway, NJ: IEEE, 2007: 127-134
[3]Hall M W, Kennedy K. Efficient call graph analysis[J]. ACM Letters on Programming Languages & Systems, 1997, 1(3): 227-242
[4]Graham S L, Kessler P B, McKusick M K. Gprof: A call graph execution profiler[J]. ACM SIGPLAN Notices, 2004, 39(4): 49-57
[5]Chipounov V, Kuznetsov V, Candea G. S2E: A platform for in-vivo multi-path analysis of software systems[J]. Computer Architecture News, 2012, 39(1): 265-278
[6]Bellard F. QEMU, a fast and portable dynamic translator[C]Proc of USENIX ATC’05. Berkeley, CA: USENIX Association, 2005: 41-46
[7]Singh P, Batra S. A novel technique for call graph reduction for bug localization[J]. International Journal of Computer Applications, 2012, 47(15): 1-5
[8]Bartholomew D. Qemu: A multihost multitarget emulator[J]. Linux Journal, 2006(145): 68-71
[9]Liu Yuchen, Wang Jia, Chen Yunji, et al. Survey on computer system simulator[J]. Journal of Computer Research and Development, 2015, 52(1): 3-15 (in Chinese)(劉雨辰, 王佳, 陳云霽, 等. 計(jì)算機(jī)系統(tǒng)模擬器研究綜述[J]. 計(jì)算機(jī)研究與發(fā)展, 2015, 52(1): 3-15)
[10]Chylek S. Collecting program execution statistics with Qemu processor emulator[C]Proc of 2009 Int Multi Conf on Computer Science and Information Technology. Piscataway, NJ: IEEE, 2009: 555-558
[11]Jia Di, Xiang Yong, Sun Weizhen, et al. Database-based online call graph tool applications[J]. Journal of Chinese Computer Systems, 2016, 37(3): 422-427 (in Chinese)(賈荻, 向勇, 孫衛(wèi)真, 等. 基于數(shù)據(jù)庫的在線函數(shù)調(diào)用圖工具[J]. 小型微型計(jì)算機(jī)系統(tǒng), 2016, 37(3): 422-427)
[12]Chipounov V, Kuznetsov V, Candea G. The S2E platform: Design, implementation, and applications[J]. ACM Trans on Computer Systems, 2012, 30(1): 1-49
[13]Dovgalyuk P. Deterministic replay of system’s execution with multi-target QEMU simulator for dynamic analysis and reverse debugging[C]Proc of the 16th European Conf on Software Maintenance and Reengineering. Piscataway, NJ: IEEE, 2012: 553-556
[14]Ding J H, Chang P C, Hsu W C, et al. PQEMU: A parallel system emulator based on QEMU[C]Proc of the 17th IEEE Int Conf on Parallel & Distributed Systems. Piscataway, NJ: IEEE, 2011: 276-283
[15]Hong D Y, Hsu C C, Yew P C, et al. HQEMU: A multi-threaded and retargetable dynamic binary translator on multicores[C]Proc of the 10th Int Symp on Code Generation and Optimization. New York: ACM, 2012: 104-113
[16]Wang Zhaoguo, Liu Ran, Chen Yufei, et al. COREMU: A scalable and portable parallel full-system emulator[J]. ACM SIGPLAN Notices, 2011, 46(8): 213-222

Xiang Yong, born in 1967. PhD and associate professor. Senior member of CCF. His main research interests include operating system and computer networks.

Cao Ruidong, born in 1992. Master candidate. His main research interests include operating system and computer networks (crdong@csnet4.cs.tsinghua.edu.cn).

Mao Yingming, born in 1988. PhD candidate. His main research interests include operating systems and computer networks (myming@csnet4.cs.tsinghua.edu.cn).
QEMU-Based Dynamic Function Call Tracing
Xiang Yong1, Cao Ruidong1, and Mao Yingming2
1(DepartmentofComputerScienceandTechnology,TsinghuaUniversity,Beijing100084)2(SchoolofComputerScience,BeijingInstituteofTechnology,Beijing100081)
Function call has always been an important research topic in Linux kernel analysis. There are two main approaches to obtain function calls, static analysis and dynamic analysis. Using dynamic tracing approach can provide accurate and real-time function calls. It is great help to analyze and debug software programs. Considering that existing tools need some particular compile options or their tracing data is not very comprehensive, a new dynamic function call tracing tool that supports multiple CPU architectures based on an open source emulator QEMU is designed and implemented. It can provide function call and function return information including those in the Linux kernel booting phase on three architectures, x86_32, x86_64 and ARM. When the system is running, this tool intercepts procedure call and return assembly instructions. Then it logs necessary state information to file. Based on the property that these kinds of instructions must be the last one of a QEMU translation block, the amount of checked instructions is lowered and the efficiency is promoted. Only the symbol table of the program not the source code is needed to parse function call data. Test result shows that the behavior indicated by tracing data concurs with the corresponding source code. This tool has higher performance and supports more CPU architectures than S2E. It is easier to extend to other architectures.
function call; dynamic tracing; emulator; multiple platform; Linux kernel analysis
2016-02-26;
2016-08-29
“核高基”國家科技重大專項(xiàng)基金項(xiàng)目(2012ZX01039-004-41,2012ZX01039-003) This work was supported by the National Science and Technology Major Projects of Hegaoji (2012ZX01039-004-41,2012ZX01039-003).
TP391
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測(cè)控技術(shù)(2018年5期)2018-12-09 09:04:26
電子測(cè)試(2018年18期)2018-11-14 02:30:34
中華手工(2017年2期)2017-06-06 23:00:31
電信科學(xué)(2016年10期)2016-11-23 05:11:56
中外會(huì)展(2014年4期)2014-11-27 07:46:46
西安航空學(xué)院學(xué)報(bào)(2014年5期)2014-07-13 01:27:52
機(jī)電信息(2014年27期)2014-02-27 15:53:56
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
