一種基于差分隱私保護的協同過濾推薦方法
2017-08-12 15:31:07常盟盟吳小飛
計算機研究與發展 2017年7期
何 明 常盟盟 吳小飛
(北京工業大學計算機學院 北京 100124)
?
一種基于差分隱私保護的協同過濾推薦方法
何 明 常盟盟 吳小飛
(北京工業大學計算機學院 北京 100124)
(heming@bjut.edu.cn)
由于推薦系統需要利用大量用戶數據進行協同過濾,會給用戶的個人隱私帶來相當大的風險,如何保護隱私數據成為推薦系統當前面臨的重大挑戰.差分隱私作為一種新出現的隱私保護框架,能夠防止攻擊者擁有任意背景知識下的攻擊并提供有力的保護.針對推薦系統中的隱私保護問題,提出一種滿足差分隱私保護的協同過濾推薦算法.首先,構建用戶和項目的潛在特征矩陣,有效降低數據稀疏性;然后,采用目標擾動方法對矩陣中添加滿足差分隱私約束的噪聲得到噪矩陣分解模型;通過隨機梯度下降算法最小化相關聯的正則化平方誤差函數來獲取模型中的參數;最后,應用差分隱私矩陣分解模型進行評分預測,并在MovieLens和Netflix數據集上對算法的有效性進行評價.實驗結果證明:所提出方法的有效性能夠在有限的精度損失范圍內進行推薦并保護用戶隱私.
差分隱私;隱私保護;協同過濾;推薦系統;矩陣分解
隨著信息技術特別是互聯網、物聯網和云計算等技術的迅猛發展,網絡空間中所蘊含的信息量呈指數級增長.人們在獲取豐富多彩的信息內容的同時,沉浸于信息海洋而難以及時、準確地獲得滿足其自身需要的信息,“信息過載”現象愈發嚴重,給人們帶來很大的信息負擔.盡管傳統搜索引擎如(Google、百度等)可以在一定程度上解決用戶的信息檢索需求,但仍然不能滿足不同背景、不同目的、不同時期的個性化信息需求,從而不能真正有效地解決“信息過載”問題.推薦系統(recommender systems)[1-2]作為一種有效的信息過濾手段是當前解決信息過載問題及實現個性化信息服務有效方法之一.通過挖掘用戶與項目之間(user-item)的二元關系,幫助用戶從海量數據中便捷發現其可能感興趣的項目(如Web信息、服務、在線商品等),并生成個性化推薦以滿足個性化需求.目前,推薦系統在電子商務(如Amazon、eBay、Netflix、阿里巴巴、豆瓣網、當當網等)、信息檢索(如iGoogle、MyYhoo、GroupLens、百度等)以及移動應用、電子旅游、互聯網廣告等眾多應用領域取得較大進展[3].在眾多的推薦方法中,協同過濾是目前應用最多的算法,其核心思想是利用近似用戶或者用戶喜歡的項目的近似來過濾大量信息,從而為用戶篩選出其可能感興趣的項目.已被廣泛應用于推薦系統中并取得了顯著的效果,同時受到了大量研究者的高度關注.協同過濾推薦算法大致可以分為2類:基于近鄰的協同過濾(neighborhood-based)[4-5]和基于模型的協同過濾(model-based)[6-7].
目前,推薦系統面臨著嚴峻的隱私保護與安全問題.推薦系統需要收集大量的用戶信息、用戶行為等,數據越豐富,推薦精確度可能越高.然而,這些信息可能泄露用戶的個人隱私,用戶出于隱私與信息安全考慮,可能不愿意讓這些數據被推薦系統記錄和存儲.由于推薦系統需要利用大量用戶數據進行協同過濾(collaborative filtering),所以數據的隱私保護已經成為推薦系統研究領域一個迫切需要解決的問題,也越來越受到人們的關注和重視.2010年,Netflix Prize比賽因為用戶要求的隱私問題而不能繼續舉辦.隱私保護推薦系統研究的問題是如何在保證數據集隱私安全的前提下獲取推薦質量最優的模型.其研究通常面向推薦系統領域的具體推薦算法,通過對已有算法的調整和對推薦結果的效用評價來尋求數據安全性和推薦精確度的平衡.
差分隱私(differential privacy,DP)是Dwork[8]在2006年提出的一種新的隱私保護模型,該模型能夠解決傳統隱私保護模型的2個缺陷:1)無需考慮攻擊者所擁有的任何可能的背景知識;2)對隱私保護水平給出了嚴格的定義和量化評估方法.
差分隱私在推薦系統中已得到普遍應用和廣泛關注.McSherry等人[9]將差分隱私保護方法引入到協同過濾推薦系統,在分析項目之間的關系時,他們先建立項目相似度協方差矩陣,并向矩陣中加入噪聲實施干擾,然后再提交給推薦系統實施推薦;Machanavajjhala等人[10]在基于社交網絡數據的推薦系統中使用了差分隱私保護方法;Zhu等人[11]針對K最近鄰算法所面臨的隱私泄露問題提出了一種基于差分隱私保護的鄰居協同過濾算法;另外,針對基于標簽的推薦系統,Zhu等人[12]提出了一種對用戶輪廓(user profile)進行修改并發布的差分隱私保護算法,能夠在一定的精度損失范圍內進行標簽推薦并保護用戶隱私.
雖然人們已經提出了一些差分隱私保護下的推薦算法,但已有的方法并沒有考慮到隱語義模型,存在2方面的局限:1)在面對高維數據稀疏性問題時,導致可擴展性差;2)現有推薦算法隱私保護水平的提高是以犧牲推薦精確度為代價,導致算法推薦質量下降.
針對上述問題,本文將探討隱私保護與協同過濾相結合的推薦方法.使得推薦算法能夠達到推薦精確度與隱私保護的平衡.
本文主要貢獻有3點:
1) 針對高維數據稀疏性問題,采用矩陣分解方法將用戶-項目評分矩陣分解成低維潛在特征矩陣的乘積,有效處理高維稀疏數據以提高推薦精確度.
2) 基于隱語義模型,提出了一種滿足ε-差分隱私的矩陣分解機制,通過隨機擾動目標函數實現差分隱私,并采用隨機梯度下降算進行優化求解.
3) 不僅對模型進行了理論分析和推導,并在MovieLens和Netflix兩種不同規模的數據集上與已有的方法進行實驗比較和分析,展示出該方法在兼顧隱私保護的同時,還具備了較高的推薦精確度.
1 相關工作
差分隱私和數據挖掘研究等領域的結合,使得差分隱私得到了廣泛應用與發展.繼Dwork提出了差分隱私保護模型之后,Friedman等人[13]提出了一種兼顧算法精確性和隱私性的差分隱私保護決策樹建算法DiffP-C4.5;Chaudhuri等人[14]將差分隱私應用到了SVM和Logistic SVM[15]回歸上,實現了經驗風險最小化的差分隱私保護;針對特定數據類型,Cormode等人[16]通過簡化步驟、降低敏感度的方式解決了數據的稀疏性問題,在差分隱私保護過程中,降低了噪聲數據的添加量;Sarathy等人[17]指出將差分隱私保護方法應用于數值類型數據之上,存在一定的局限性;Li等人[18]首次將差分隱私與k-Anonymity算法相結合,解決了在微數據隱私保護下的數據發布問題.
在應用領域,Zhou等人[19]提出了一種應用于超大型數據庫的差分隱私壓縮算法,通過使用高斯隨機變量矩陣以隨機線性或映射變換的方式壓縮數據庫,在實現差分隱私保護的同時保持了原有數據的統計學習應用特性;Vu等人[20]將差分隱私保護與傳統的統計假設檢驗建模相結合,從而獲得統計效率和隱私保護級別之間的平衡;Gehrke等人[21]將改進了的差分隱私保護算法應用于社交網絡的隱私保護建模;Hua等人[22]提出了數據發布在不同交互式環境下的差分隱私保護算法,并對這些方法進行分析和比較.
在基于差分隱私保護的數據挖掘研究中,比較典型的有SuLQ和PINQ接口框架,SuLQ框架將單屬性布爾查詢定義為查詢原語,設計提供了隱私保護的k-means,ID3分類器等復雜算法.PINQ框架基于LINQ實現了敏感數據的差分隱私保護,并提供了一系列便于二次開發的應用接口[23].
此外,Xiao等人[24]將Haar小波變化與差分隱私保護相結合,在添加噪聲前先對數據實施小波變換,提高了區間查詢的準確度;Hay等人[25]將噪聲以分組為單位進行添加,在滿足精度的同時,最大限度地降低了噪聲添加量;Chen等人[26]提出了差分隱私的數據發布機制.
作為一種嚴格的和可證明的隱私定義,差分隱私近年來受到了極大關注并被廣泛研究.當然,差分隱私保護還是一個相對年輕的研究領域,在理論和應用上都還存在一些難點以及新的方向需要進一步深入研究[23].
2 理論基礎
2.1 隱語義分解模型
基于近鄰的協同過濾算法是在預測中直接使用已有數據預測,主要包括基于物品[4]和基于用戶2類[27].基于模型的協同過濾算法主要通過用戶對產品的評分信息訓練出相應的模型,利用此模型預測未知的數據.基于模型的算法其中一大類就是采用矩陣分解方法的隱語義模型構建的,通過降維計算用戶矩陣和項目矩陣的內積來預測評分,相比于近鄰的算法,這種算法的準確性和穩定性都有所提升[28],故本文采用隱語義模型來進行協同過濾.
隱語義模型(latent factor model)[29]就是聯系用戶興趣與物品挖掘之間的隱含關系來構建模型的方法.典型的隱語義模型從奇異值分解(singular value decomposition,SVD)的角度將評分矩陣R分解為用戶U和項目V的2個低維語義矩陣相乘的形式,通過直接最小化訓練集中的均方根誤差(root mean square error,RMSE)來學習矩陣,最終預測得到用戶對項目的評分:
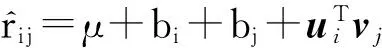
(1)
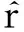
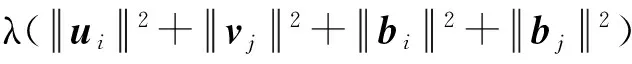
(2)
2.2 差分隱私
差分隱私是基于數據失真的隱私保護技術.通過向查詢或者分析結果中添加噪聲使數據失真,確保在某一數據集中插入或者刪除某一條記錄的操作不會影響任何查詢的輸出結果,從而達到隱私保護的目的.差分隱私的形式化定義如下:
定義1.ε-差分隱私[8].給定2個數據集D和D′,D和D′至多相差1條記錄.給定1個隱私算法A,Range(A)為A的取值范圍,若算法A在數據集D和D′上的任意輸出結果O(O∈Range(A))滿足下列不等式,則A滿足ε-差分隱私:
Pr[K(D)∈S]≤e(ε)×Pr[K(D′)∈S],
(3)
其中,概率Pr[·]由算法A的隨機性所控制,表示隱私被披露的風險;隱私預算參數ε表示隱私保護程度,ε值越小表示隱私保護程度越高,但可用性相對越低.
噪聲機制是實現差分隱私的主要技術.Laplace機制[30](Laplace mechanism)和指數機制[31](exp-onential mechanism)是2種最基礎的差分隱私保護實現機制.其中Laplace機制適用于對數值型結果的保護,指數機制則適用于非數值型結果.基于不同噪聲機制且滿足差分隱私的算法所需噪聲大小均依賴于函數的全局敏感度.
定義2. 全局敏感度[30].對于任意一個函數f:D→d,函數f的全局敏感度定義為
(4)
其中,D和D′之間至多相差1條記錄,d表示函數f的查詢維度,表示所映射的實數空間.
定理1. Laplace機制[30].對于任意一個函數f:D→d,若算法A的輸出結果滿足等式:
A(D)=f(D)+〈lap1(Δfε),
lap2(Δfε),…,lapd(Δfε)〉,
(5)
則A滿足ε-差分隱私,其中lapi(Δfε)(1≤i≤d)是相互獨立的Laplace變量,其對應的概率密度函數為p(x|b)=(12b)e(-|x|b).噪聲大小與Δf成正比,與ε成反比.即全局敏感度越大,所添加噪聲越大.
定理2. 指數機制[31].設隨機算法A輸入為數據集D,輸出為一實體對象r∈Range,q(D,r)為敏感度.若算法A以正比于e(εq(D,r)2Δq)的概率從Range中選擇并輸出r,那么算法A滿足ε-差分隱私保護.
3 差分隱私矩陣分解機制
本文面向集中式推薦場景,如圖1所示,假定推薦系統是可信的,即推薦系統已經收集了用戶的評分且不會泄露用戶的隱私信息.矩陣U是保密的,但攻擊者可以通過學習矩陣V中數據來推測用戶的隱私信息,因此必須對矩陣V的發布進行干擾.為了使矩陣V的發布滿足差分隱私保護的要求,向矩陣V中加入噪聲實施隨機干擾,并以評分預測誤差最小化為目標函數,最終確保矩陣V的發布滿足ε-差分隱私.
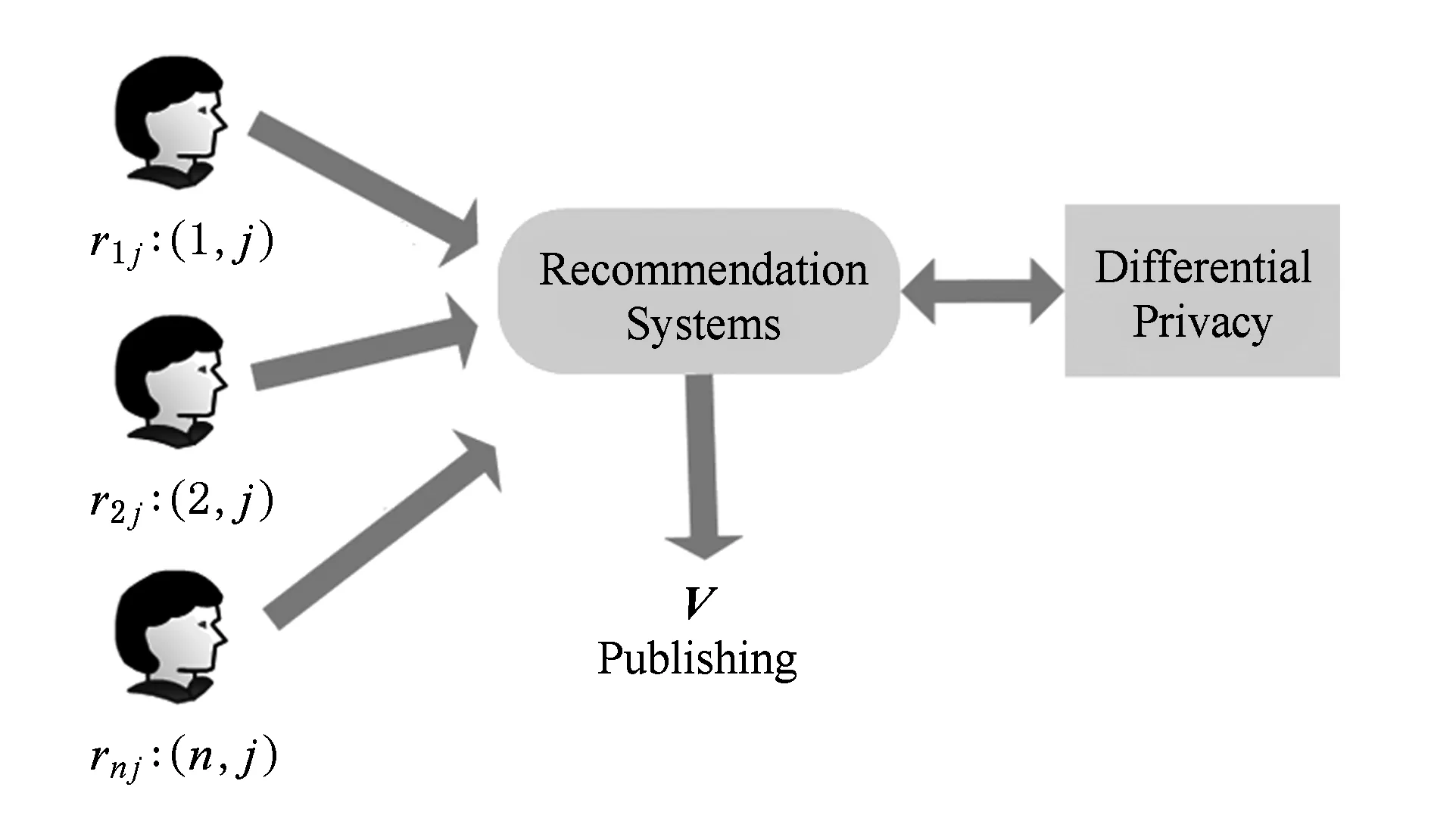
Fig. 1 Centralized recommendation scenario圖1 集中式推薦場景
3.1 差分隱私矩陣分解
值得注意的是,推薦系統中的用戶-項目評分矩陣不僅是高維數據集,而且存在數據的稀疏性問題.在高維情形下出現的數據樣本稀疏導致距離計算困難等維數災難.通常情況下,用戶-項目評分矩陣的稀疏度可能達到99%[32].我們能夠利用的表示用戶興趣的信息實際上是非常稀疏甚至是有限的,這使得很難為較少項目評分的用戶找到興趣相似的用戶.
數據的稀疏性問題導致了推薦系統在相似度計算、評分預測等方面會直接或間接影響推薦精度.甚至對傳統的協同過濾算法起到了很大的負面影響.例如,由于矩陣維度過大,數據稀疏性可能會導致2個用戶之間的相似度為0,甚至由于評分數據太少導致了負相關性.早期的研究依賴于填充的方法,即填充用戶-項目評分矩陣的缺失值使該矩陣變得稠密.例如,利用用戶或項目的平均評分.然而,這種方法存在一定的局限性:由于填充方法極大地增大了數據量,所以代價非常大;除此之外,不準確性的填充也會使得數據變得傾斜.
緩解維數災難的一個重要途徑是降維.在很多情況下,用戶-項目評分數據集中的一部分攜帶了數據集中的大部分信息,其他信息則要么是噪聲,要么就是毫不相關的信息.從數值代數角度來看,矩陣分解可以將規模較大的復雜問題轉化為小規模的簡單子問題來求解;從應用統計學領域來看,通過矩陣分解得到原數據矩陣的低秩逼近,從而可以發現數據的內在結構特征,而其余特征則都是噪聲或冗余特征,這些噪聲數據會直接或間接影響到推薦精度.矩陣的低秩逼近可以有效降低數據的維數和去噪,緩解數據稀疏性問題,節省存儲和計算資源.相對于傳統的直接計算用戶或者物品相似度的方法,在提高推薦準確性的同時,減小了推薦計算量.
矩陣分解(matrix factorization,MF)技術根據觀察到的用戶-項目評分直接建模,通過把用戶-項目評分矩陣分解成2個或者多個低維矩陣的乘積實現維數的規約,將高維稀疏的用戶-項目評分矩陣分解成2個低維的用戶潛在特征矩陣U和項目潛在特征矩陣V,通過重構低維潛在特征矩陣預測用戶對項目的評分.矩陣分解模型提供了一個內存有效的壓縮模型,該模型訓練起來相對容易,加上基于梯度的下降算法的矩陣分解模型實現起來相對容易,使得該模型具有較高的預測準確性和穩定性.
設Rn×m為n個用戶和m個項目的用戶-項目評分矩陣,矩陣分解方法可以把Rn×m分解成2個實數矩陣Un×k和Vn×k,使得:
R≈UVT,
(6)
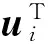
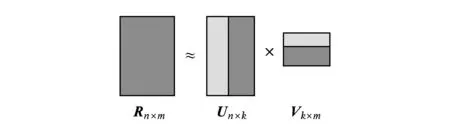
Fig. 2 Matrix factorization basis圖2 矩陣分解基本原理
用戶-項目評分矩陣中的真實評分與用戶矩陣U和項目矩陣V的關系:
(7)
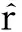
(8)
并且采用隨機梯度下降算法最小化它們之間的誤差dui,即:
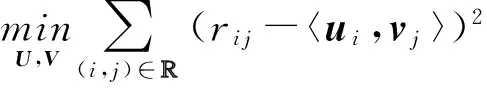
(9)
得到局部最小值.此時,使得R與UV之間的預測誤差極小,數據的預測值與降維前評分矩陣中的實際值基本保持一致,即具有較高的評分預測精度.這樣我們將評分矩陣從一個高維空間壓縮到低維空間,并且空間的壓縮使得數據的可用性損失最小.
一般的矩陣分解方法采用2個向量U和V內積的形式來表示用戶對該物品的評分,存在一定的局限性,評分矩陣的稀疏度太大或者迭代次數過多,擬合噪聲數據,分解很容易產生過度擬合.本文采用帶偏置的矩陣分解方法,將獨立于用戶或產品的因素作為偏置部分.偏置部分有助于提高評分預測準確度.本文通過將偏置部分與數據噪聲相結合來實現差分隱私保護.結合偏置部分,則第i個用戶對第j個物品的評分預測可表示為
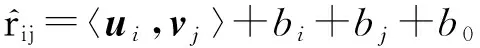
(10)
其中,〈ui,vj〉表示用戶i和項目j的潛在特征向量的內積,b0表示所有項目評分的全局平均數,用戶偏置bi表示該用戶的打分習慣,物品偏置bj表示物品得到的打分情況.為了得到更加準確的預測值,需要對預測值和實際值之間的損失度進行優化評估,并通過正則化學習參數來避免過擬合現象,本文建立的目標優化函數:
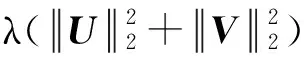
(11)
其中,常量λ控制了正則化程度,以預防過擬合觀測數據.
對目標函數進行極小化的優化求解通常有2種方法:交替最小二乘法(alternative least square,ALS)和隨機梯度下降法(stochastic gradient descent,SGD).交替最小二乘法是通過平方損失函數建立模型優化目標函數的一種思路,此時求解最優模型過程便具體化為最優化目標函數的過程;隨機梯度下降法作為最優化目標函數的一種優化算法,求解的是使得目標函數能達到最優或者近似最優的參數集.本文采用隨機梯度下降算法來進行優化,基本思想是使得變量沿著目標函數負梯度的方向移動,直至移動到極小值點.矩陣分解的目標函數是凸函數,因此,通過梯度下降算法我們能夠得到目標函數的極小值.在梯度下降算法的隱含矩陣更新公式中,通過不斷迭代來更新矩陣U和V中的元素:
ui←ui+α(eui·vj-λui),
(12)
(vj←vj+α(eui·ui-λvj),
(13)
bu←bu+α(eui-λbu),
(14)
bi←bi+α(eui-λbi),
(15)
其中,eui為預測評分與實際評分之間的誤差值;ui為矩陣U中的向量;vj為矩陣V中的向量;λ為正則化參數;α表示學習速率,它是一個超參數,表示訓練樣本誤差的學習程度,需要調參確定.迭代終止主要包括3個條件:
1) 設定閾值,當目標函數值小于閾值停止迭代.
2) 當前后2次函數值變化絕對值小于某一閾值時,停止迭代.
3) 固定迭代次數.
本文采用條件2作為迭代終止條件.
3.2 差分隱私預算的選取
差分隱私預算參數ε衡量了DPMF算法的隱私保護水平,參數ε越小提供的隱私保護能力越大,這是因為ε與噪聲的添加幅度成反比.噪聲矩陣和差分隱私預算參數ε的關系:
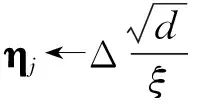
(16)
因此,當ε的取值較小時,DPMF算法輸出的發布矩陣Vp中添加的噪聲越大,相反,當ε的取值較大時,矩陣V和發布矩陣Vp相差越小,隱私保護力度越差.為了選取合適的參數ε,Lee和Clifton[33]提出了一種攻擊模型,給出選取參數ε上界的計算為
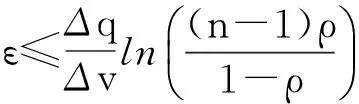
(17)
可以看出,參數ε的選取依賴于4個參數:ρ,Δq,Δv,n.其中ρ為攻擊者成功概率,Δq為查詢函數的敏感度,Δv為潛在輸入集的函數敏感度[33],n是潛在特征向量的維度.在一般實驗中,對于ε的取值主要通過列舉不同的預算值,然后對比這些不同取值算法的查詢平均差錯率來評估ε的最佳取值.文獻[34]提出了ε的取值與攻擊者成功的概率二者之間的關系.當攻擊者的成功概率ρ滿足:
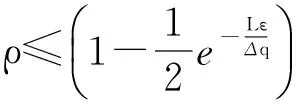
(18)
可以得到參數ε的取值滿足:

(19)
其中,Δq為查詢函數的敏感度,L為查詢的容錯區間長度,ρ攻擊者成功的概率.可見參數ε的上界與數據集大小無關,僅僅與查詢函數(Δq,L)和攻擊者的成功概率有關[34].
3.3 隱私性分析


?j∈{1,2,…,m},迭代地進行目標函數的極小化,直到收斂.由于負梯度方向是使目標函數下降最快的方向,在迭代的每一步對vj求偏導數并令其為0,可得:
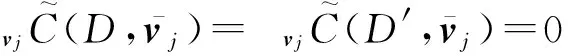
(20)
因此:
(21)
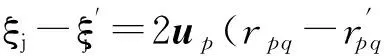

證畢.
3.4 差分隱私保護
添加噪聲是實現差分隱私保護的主要技術,常用的噪聲機制包括拉普拉斯機制[30]和指數機制[31].本文采用目標函數擾動方法實現差分隱私保護,其基本思想是將噪聲加在目標函數中,通過隨機擾動目標函數而不是學習算法的輸出來滿足差分隱私,在降低噪聲量的同時,有助于提高推薦精確度.本文采用目標優化函數:
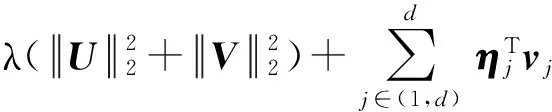
(22)
其中,ηj是干擾目標函數的噪聲矩陣.
算法1.RatingMatrixProcessing(R,b0,λ,α).
輸入:原始用戶-項目評分矩陣R、所有項目評分的全局平均數b0、正則化參數λ、學習速率α、潛在特征向量維度d;
輸出:用戶潛在特征矩陣U.
Step1. 計算目標函數誤差
① foriin rangeU:
② forjin rangeV:
③ if 用戶參與了評分
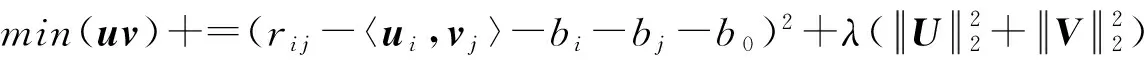
end if
⑤ end for
⑥ end for
Step2. 訓練得到最優化U
① while(abs(連續2次目標值之差)>epsilon)
② foriin rangeU:
③ forjin rangeV:
④ 計算預測用戶評分;
⑤eui=rij-〈ui,vj〉-bi-bj-b0;*計算預測評分與實際評分誤差eui*
⑥ forkin ranged:
⑦ui←ui+α(eui·vj-λui);
⑧vj←vj+α(eui·ui-λvj);
⑨ end for
⑩bu←bu+α(eui-λbu);


算法2.GenerateNoiseMatrix(ε).
輸入:隱私預算參數ε、潛在特征向量維度d;
輸出:添加噪聲后的矩陣η.
① foriin ranged:

③ end for
④ returnη.
其中,Hj是一個隨機向量,滿足指數分布Hj~Exponential(1).將Hj加入每一個用戶向量Ui中.Ci是一個獨立隨機向量,并且滿足Ci~N(0,1k).生成噪聲矩陣η后,采用vj添加到目標函數中,在每次迭代過程中實現擾動操作.其中,η滿足定理1,噪聲矩陣任意向量ξi∈N之間相互獨立,且其概率密度函數為,因此矩陣η滿足ε-差分隱私.
算法3.ItemProfileMatrix(R,b0,U,λ,α,η).
輸入:原始評分矩陣R、評分記錄的全局平均數b0、用戶特征矩陣U、正則化參數λ、學習速率α、噪聲矩陣η、潛在特征向量維度d;
輸出:物品特征矩陣V、用戶偏置bu、物品偏置bi.
Step1. 目標函數加擾
① foriin rangeU:
② forjin rangeV:
③ if 用戶參與了評分
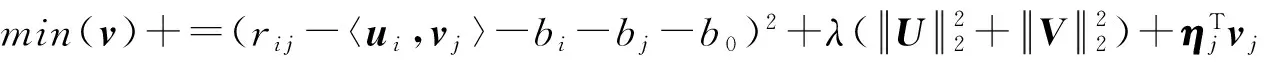
⑤ end if
⑥ end for
⑦ end for
Step2. 訓練優化
① while(abs(連續2次目標值之差)>epsilon)
② foriin rangeU:
③ forjin rangeV:
④ 計算預測用戶評分;
⑤eui=rij-〈ui,vj〉-bi-bj-b0;*計算誤差eui*
⑥ forkin ranged:
⑦vj←vj+α(eui·ui-λvj);
⑧ end for
⑨bu←bu+α(eui-λbu);
⑩bi←bi+α(eui-λbi);


4 實驗結果與分析
在本節中,將通過具體的實驗來對本文提出的方法進行分析、驗證和說明.實驗環境為Intel Core 2 Duo CPU 2.94 GHz,4 GB內存、Windows7 64 b操作系統,實驗使用Python實現相關推薦算法.
4.1 評價指標
評價推薦系統推薦質量的度量標準主要有統計精度度量方法(prediction error)、決策支持精度度量方法(IR metrics)和排名度量方法(ranking metrics).本文實驗采用統計精度度量方法中均方根誤差RMSE作為評價指標來衡量評分預測推薦精確度:
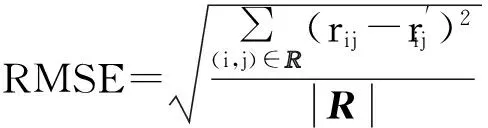
(23)
4.2 數據集
為了評價算法的性能,本文實驗采用2個不同規模的數據集:
1) 本文采用GroupLens研究組提供的MovieLens(www.grouplens.org)數據集ML-100k對算法進行評估,該數據集包含了943個用戶對1 682部電影的100 000個評分記錄,每個用戶至少對20部電影評過分,評分范圍為1~5之間的整數,代表喜好程度從低到高.該數據集的評分稀疏度為93.7%.實驗中,我們將數據集平均分成5組,采用交叉驗證的方法進行實驗,訓練集與測試的大小比例為4∶1.
2) Netflix數據集是一個評分比較稀疏的數據集(評分稀疏度為98.8%),該數據集包括480 189個用戶對17 770部電影的103 297 638條評分數據,評分為1~5之間的整數.實驗中,我們隨機選取2 000個用戶對4 000部電影的214 690條評分數據作為本文的實驗基礎數據集,評分稀疏度為97.3%.數據集的具體描述如表1所示:
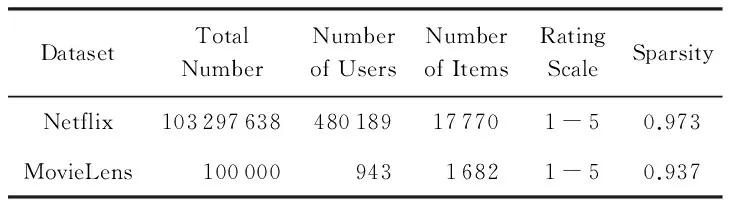
Table 1 Experimental Dataset Characteristics表1 實驗數據集特征描述
4.3 對比算法
根據推薦應用場景的特點,我們將本文提出的基于差分隱私保護的矩陣分解方法(differentially private matrix factorization, DPMF)與4種推薦算法進行實驗對比來驗證其有效性:
1) 基于用戶的推薦方法(user-basedKNN);
2) 基于項目的推薦方法(item-basedKNN);
3) SVD++;
4) 交替最小二乘法ALS.
推薦算法1,2是基于近鄰的協同過濾推薦算法,該算法簡單有效且能夠提供準確及個性化的推薦.基于近鄰的方法可以分為基于用戶的和基于項目的推薦.基于用戶的推薦方法是依賴于和自己興趣相同的用戶來預測一個評分,而基于項目的推薦方法是通過評分相近的項目來預測.SVD是一種常用的矩陣分解算法,能夠有效獲取低維特征空間上的語義概念.SVD++是基于SVD的一種改進算法,該方法在SVD的基礎上整合了一種隱式反饋,能夠提供比SVD方法更好的精確度.ALS算法的核心思想與本文采用的SGD方法類似,通過分別交替固定用戶和項目特征向量來計算其中另一個.當其中的一個特征向量是常量時,最優化問題變成二次的,就可以進行優化求解.
4.4 實驗比較與分析
我們在MovieLens數據集和Netflix數據集上進行了不同條件組的實驗分析,將潛在特征維度的范圍設置為20~100,差分隱私預算ε分別取0.05,0.1,0.15,0.2.實驗的基本參數配置如表2所示.
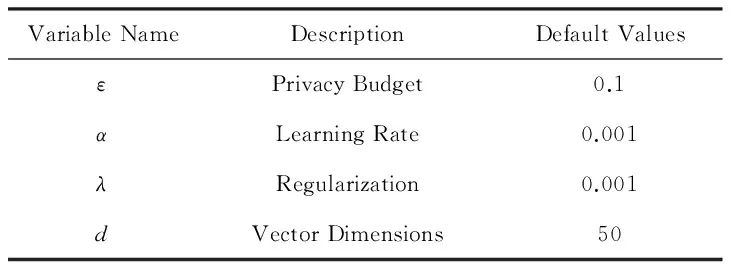
Table 2 Experimental Parameters表2 實驗參數列表
實驗1. 數據稀疏性條件下推薦算法預測準確度
本組實驗的目的是考察不同推薦算法在數據稀疏時的推薦結果精度.為了比較本文提出的DPMF對推薦系統性能的影響,該實驗通過將DPMF與4.3節中提到的4種算法在MovieLens數據集上進行了實驗結果的對比,證明DPMF推薦算法的有效性.如圖3所示,在數據稀疏的情況下,基于用戶user-basedKNN和基于物品item-basedKNN推薦算法的RMSE值分別為1.048和1.008.而基于矩陣分解的SGD,ALS,SVD++方法RMSE值分別為0.955,0.955,0.950,這3種方法的RMSE值較user-basedKNN和item-basedKNN推薦算法平均下降7.29%.
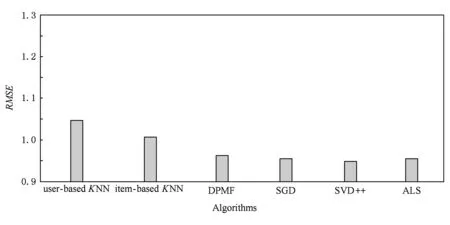
Fig. 3 Comparison of different recommendation algorithms圖3 不同推薦算法的比較
由此可見,在數據稀疏的情況下,基于矩陣分解方法的預測準確度要優于基于用戶和項目的協同過濾算法.這主要是因為矩陣分解方法提供了一個有效的壓縮模型,保留了原始數據的潛在特征,而傳統的協同過濾算法雖然維持了原始數據的完整性,但推薦算法受到數據稀疏性、噪聲數據和無代表性的特征數據等負面影響,導致了推薦精度低于矩陣分解方法.同時,我們注意到DPMF的RMSE值在0.963左右,這與其他4種沒有采用隱私保護機制的推薦算法的評分預測準確度相比僅損失了約0.027.由此可見,加入適量干擾噪聲后,DPMF能夠在一定的預測準確度損失范圍內進行有效推薦并保護用戶隱私.
實驗2. 隱私保護對推薦結果的影響
本組實驗的目的是考察本文提出的DPMF在對推薦數據進行差分隱私保護的同時對推薦效果的影響.因此,這里我們重點考察了在不同差分預算下的DPMF對推薦結果的影響.
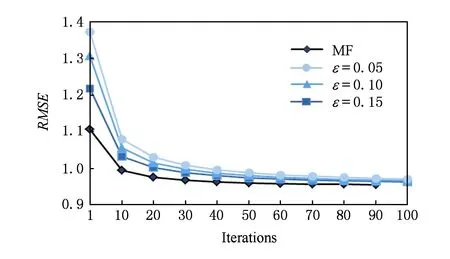
Fig. 4 RMSE comparison of MF and DPMF圖4 MF與DPMF的RMSE比較
我們在MovieLens數據集上進行了100次迭代實驗,分別設置ε=0.05,0.1,0.15.由圖4可以看出,預測準確度隨著迭代次數的增加而逐漸提高.經過40次迭代之后RMSE值變化趨于平緩,隨機擾動后的預測準確度也有所提高,但下降速率和趨勢與MF預測結果趨于一致.
本組實驗結果表明:DPMF對預測準確度的影響范圍是有限的,一方面既能對推薦數據進行隱私保護;另一方面對最終預測準確度的影響不是很明顯.
實驗3. 不同的差分隱私保護方法對推薦精度的影響
本組實驗的目的是考察在滿足差分隱私保護的前提下,本文提出的DPMF和文獻[9]提出的差分隱私保護算法對推薦精度的影響.文獻[9]提出了首先將評分矩陣進行差分隱私預處理,然后將處理后的數據作為推薦系統的輸入數據,在本文中稱之為PreDP方法.在MovieLens數據集上進行了2種隱私保護方法實驗結果的對比,其中采用相同的差分隱私預算值ε=0.05.在PreDP方法中,我們選擇基于項目的item-basedKNN推薦算法.

Fig. 5 RMSE comparison of PreDP and DPMF圖5 PreDP與DPMF的RMSE比較
PreDP方法的推薦精確度依賴于k值的選擇,由圖5可以看出,推薦精度隨著最近鄰個數的增加而增加.在最近鄰個數超過40之后,RMSE趨于穩定值1.092.這是由于評分矩陣稀疏性的原因,影響了推薦算法的推薦精度,PreDP方法沒有采用隱語義模型來解決稀疏性問題.在DPMF方法實驗中,經過100次迭代之后,RMSE值達到了0.963.
本組實驗結果表明:DPMF和PreDP方法在同樣滿足差分隱私保護的前提下,本文提出的DPMF方法的具有較高的推薦精度.
實驗4. 基于矩陣分解的不同差分隱私保護方法對推薦精度的影響
在實驗3中,由于PreDP方法并未考慮矩陣分解的模型,因此本組實驗的目的是考察在滿足差分隱私保護的前提下,本文提出的DPMF和文獻[9]提出預處理基礎上進行矩陣分解方法,對推薦結果精度的影響.首先,我們采用了文獻[9]提出了的差分隱私預處理方法;然后在加擾后的評分矩陣上采用隨機梯度下降算法進行矩陣分解,在本文中稱之為PreSGD方法.在MovieLens數據集上進行了實驗對比,其中差分隱私預算值ε=0.05.
由圖6可以看出,DPMF和PreSGD方法的精確度隨著迭代次數的增加而逐漸提高,在100次迭代之后,DPMF的RMSE值低于PreSGD方法.預處理PreSGD方法在初始評分矩陣中加入噪聲實現差分隱私保護,而本文提出的DPMF將噪聲的引入參與到矩陣分解的訓練過程中,減少了噪聲的整體添加量,在隱私保護的基礎上進一步提高了推薦算法的準確性.
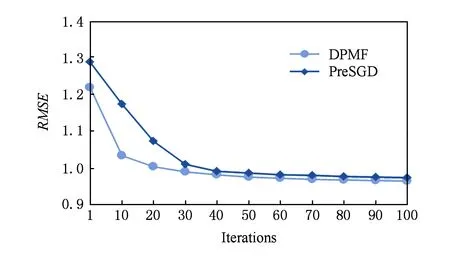
Fig. 6 RMSE Comparison of PreSGD and DPMF圖6 PreSGD與DPMF的RMSE比較
本組實驗結果表明:同樣具備差分隱私保護的隱語義模型推薦方法中,DPMF具有較高的推薦精度.
實驗5. 潛在特征向量維度對DPMF推薦結果的影響
本組實驗的目的是考察本文提出的DPMF在不同潛在特征向量維度下的推薦效果.設定ε=0.1,通過將參數d分別取20,50,100來觀察預測誤差累計分布函數(cumulative distribution function,CDF)的變化.
由圖7可知,預測準確度隨著迭代次數的增加而提高.經過40次迭代之后,我們注意到DPMF預測準確度與MF非常接近.因此,DPMF算法對預測準確度影響不大.此外,可以看出隨著d的增加,上升速率相對略有減小,這說明隨著d值的增加也會對DPMF預測精度產生一定的影響.但隨著迭代次數的增加,誤差值也逐步減少.在Netflix數據集中,我們觀察到當d=50和d=100時的預測精度優于MF,這主要是稀疏性數據對推薦結果產生了影響.

Fig. 7 Prediction error CDF圖7 預測誤差CDF趨勢圖
本組實驗結果表明:潛在特征向量維度對DPMF預測精度沒有非常明顯的影響.
實驗6. 不同差分預算對推薦精確度的影響
本組實驗的目的是考察本文提出的DPMF方法中隱私預算參數對矩陣的保護程度.因此,這里我們重點考察差分隱私預算ε在一定取值范圍內的DPMF對推薦結果的影響.
我們設置d=50,ε分別取0.05,0.1,0.15來對比實驗.經過40次迭代之后,MF與差分隱私曲線相融合,這表明無論ε的取值大小,只要滿足差分隱私保護,迭代結果不會明顯影響最終的預測準確度.另外,根據不同的ε值曲線對比,可以得出隨著ε的取值越小,DPMF隱私保護水平越高,但可用性相對越低.相反,ε的取值越大DPMF隱私保護水平越低.在圖8(a)中,我們可以看到當差分預算值為ε=0.15時,與無差分隱私保護的MF的曲線基本一致;在圖8(b)中,預測曲線與圖8(a)中走勢一致,隨著迭代次數的增加,預測準確度接近一致.
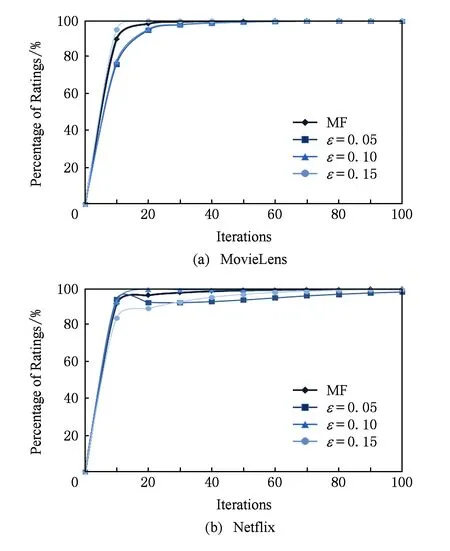
Fig. 8 Different privacy budgets CDF圖8 不同差分預算CDF趨勢圖
本組實驗結果表明:差分隱私預算ε與DPMF隱私保護水平成反比,與預測準確度成正比.
實驗7. 不同差分隱私預算下的平均誤差
本組實驗的目的是考察本文提出的DPMF方法中隱私預算參數ε對推薦結果的誤差率.因此,這里我們重點考察了在不同隱私預算下的DPMF的平均誤差下降速率.
在100次迭代過程中,預測誤差下降平均速率與差分隱私預算關系如圖9所示.預測誤差表示在每次迭代過程中,預測精度的下降平均速率.我們分別得出基于差分隱私預算ε取不同值時對應的平均下降速率.比較明顯的是:在MovieLens數據集中,當ε=0.15時,預測錯誤率達到0.74;而當ε=0.2時,預測誤差有所回升.因此,我們可以判斷在ε=0.15附近,預測錯誤率達到了某一極小值(極小值≤0.74).如果我們減小差分隱私保護,即將ε從0.1提升到0.15,經過100次迭代,結果顯示推薦精度變得非常接近實際評分.
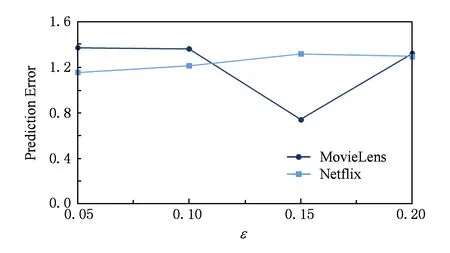
Fig. 9 The prediction error by average speed圖9 預測誤差下降平均速率
本組實驗結果表明:差分預算ε在DPMF隱私保護中存在一個最優ε值,使得隱私保護程度和推薦的可用性相對平衡.
5 結束語
本文將差分隱私保護方法應用于解決推薦問題的矩陣分解方法之中.面向集中式推薦場景,建立基于矩陣分解的協同過濾推薦模型,提出了一種滿足ε-差分隱私的矩陣分解機制,采用目標擾動技術對目標函數進行隨機干擾,并通過對引入差分隱私保護后的推薦質量進行分析,得到了若干有指導意義的結論.與現有典型推薦方法相比,本文提出新的帶隱私保護的矩陣分解方法既能夠在一定推薦精確度損失范圍內進行推薦并保護用戶隱私信息,它為推薦系統中隱私保護問題的研究提供了新的思路.如何在隱私保護和推薦質量之間尋找一個平衡是一個值得深入研究的課題.下一步的工作是研究如何在不可信推薦系統中實現滿足差分隱私保護的推薦方法.
[1]Resnick P, Iakovou N, Sushak M, et al. GroupLens: An open architecture for collaborative filtering of netnews[C]Proc of ACM Conf on Computer Supported Cooperative Work. New York: ACM, 1994: 175-186
[2]Hill W, Stead L, Rosenstein M, et al. Recommending and evaluating choices in a virtual community of use[C]Proc of SIGCHI Conf on Human Factors in Computing Systems. New York: ACM, 1995: 194-201
[3]Wang Licai, Meng Xiangwu, Zhang Yujie. Context-aware recommender systems[J]. Journal of Software, 2012, 23(1): 1-20 (in Chinese)(王立才, 孟祥武, 張玉潔. 上下文感知推薦系統[J]. 軟件學報, 2012, 23(1): 1-20)
[4]Sawar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 285-295
[5]Shi Yue, Larson M, Hanjalic A. Exploiting user similarity based on rated-item pools for improved user-based collaborative filtering[C]Proc of the 3rd ACM Conf on Recommender Systems. New York: ACM, 2009: 125-132
[6]Kamishima T, Akaho S. Nantonac collaborative filtering: A model-based approach[C]Proc of the 4th ACM Conf on Recommender Systems. New York: ACM, 2010: 273-276
[7]Zhou Ke, Yang Shuanghong, Zha Hongyuan. Functional matrix factorizations for cold-start recommendation[C]Proc of the 34th ACM Conf on Research and Development in Information Retrieval. New York: ACM, 2011: 315-324
[8]Dwork C. Differential privacy[C]Proc of the 33rd Int Colloquium on Automata, Languages and Programming. Berlin: Springer, 2006: 1-12
[9]McSherry F, Mironov I. Differentially private recommender systems: Build privacy into the net[C]Proc of the 15th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2009: 627-636
[10]Machanavajjhala A, Korolova A, Sarma A D. Personalized social recommendations: Accurate or private[J]. Proceedings of the VLDB Endowment, 2011, 4(7): 440-450
[11]Zhu Tianqing, Li Gang, Ren Yongli, et al. Differential privacy for neighborhood-based collaborative filtering[C]Proc of ACM Int Conf on Advances in Social Networks Analysis and Mining. New York: ACM, 2013: 752-759
[12]Zhu Tianqing, Li Gang, Ren Yongli, et al. Privacy preserving for tagging recommender systems[C]Proc of ACM Int Conf on Web Intelligence. New York: ACM, 2013: 81-88
[13]Friedman A, Schuster A. Data minning with differential privacy[C]Proc of the 16th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2010: 493-502
[14]Chaudhuri K, Monteleoni C, Sarwate A D. Differentially private empirical risk minimization[J]. The Journal of Machine learning Research, 2011, 12(2): 1069-1109
[15]Chaudhuri K, Monteleoni C. Pricacy-preserving logistic regression[C]Proc of Annual Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2008: 289-296
[16]Cormode G, Procopiuc M, Srivastava D, et al. Differentally private publication of sparse data[OL]. [2011-03-04]. http:arxiv.orgabs1103.0825
[17]Sarathy R, Muralidhar K. Some additional insights on applying differential privacy for numeric data[C]Proc of Int Conf on Privacy in Statistical Databases. Berlin: Springer, 2010: 210-219
[18]Li Ninghui, Qardaji W, Su Dong. Procably private data anonymization: Or,k-anonymity meets differential privacy, CERIAS TR2010-24[R]. West Lafayette, Indiana: Center for Education and Research Information Assurance and Security, Purdue University,2010
[19]Zhou Shuheng, Ligett K, Wasserman L. Differential privacy with compression [C]Proc of IEEE Int Symp on Information Theory. Los Alamitos, CA: IEEE Computer Society, 2009: 2718-2722
[20]Vu D, Slavkovic A. Differential privacy for clinical trial data: Preliminary evaluations[C]Proc of the 9th IEEE Int Conf on Data Mining. Los Alamitos, CA: IEEE Computer Society, 2009: 138-143
[21]Gehrke J, Lui E, Pass R. Towards privacy for social networks: A zero-knowledge based definition of privacy[C]Proc of the 8th Conf on Theony of Cryptography. Berlin: Springer, 2011: 432-499
[22]Hua Jingyu, Xia Chang, Zhong Sheng. Differentially private matrix factorization[C]Proc of the 24th Int Joint Conf on Artificial Intelligence. New York: ACM, 2015: 1763-1770
[23]Xiong Ping, Zhu Tianqing, Wang Xiaofeng. Differential privacy protection and application[J]. Chinese Journal of Computers, 2014, 37(1): 113-114 (in Chinese)(熊平, 朱天清, 王曉峰. 差分隱私保護及其應用[J]. 計算機學報, 2014, 37(1): 113-114)
[24]Xiao Xiaokui, Wang Guozhang, Gehrke J. Differential privacy via wavelet transforms[C]Proc of the 26th IEEE Int Conf on Data Engineering. Piscataway. NJ: IEEE, 2010: 225-236
[25]Hay M, Rastogi V, Miklau G, et al. Boosting the accuracy of differentially private histograms through consistency[J]. Proceedings of the VLDB Endowment, 2010, 3(1): 66-69
[26]Chen R, Mohammed N, Fung Bcm, et al. Publishing setvalued data via differential privacy[J]. Proceedings of the VLDB Endowment, 2011, 4(11): 1087-1098
[27]Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE Trans on Knowledge and Data Engineering, 2005, 17(6): 734-749
[28]Koren Y. Factorization meets the neighborhood: A multi-faceted collaborative filtering model[C]Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2008: 426-434
[29]Koren Y, Robert B, Chris V. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37
[30]Dwork C, Mcsherry F, Smith A. Calibrating noise to sensitivity in private data analysis[C]Proc of the 3rd Theory of Cryptography Conf. Berlin: Springer, 2006: 265-284
[31]Mcsherry F. Mechanism design via differential privacy[C]Proc of the 48th Annual IEEE Symp on Foundations of Computer Science. Piscataway, NJ: IEEE, 2007: 94-103
[32]Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]Proc of the 10th Int Conf on World Wide Web. New York: ACM, 2001: 285-295
[33]Lee J, Clifton C. How much is enough? Choosingεfor differential privacy[C]Proc of the 14th Int Conf on Information Security. Berlin: Springer, 2011. 325-340
[34]He Xianmang, Wang Xiaoyang, Chen Huahui, et al. Research on the selection of differential privacy protection parameterε[J]. Journal on Communications, 2015, 36(12): 125-129 (in Chinese)(何賢芒, 王曉陽, 陳華輝, 等. 差分隱私保護參數ε的選取研究[J]. 通信學報, 2015, 36(12): 125-129)

He Ming, born in 1975. Associate professor at Beijing University of Technology. His main research interests include recommendation systems, data mining and machine learning.

Chang Mengmeng, born in 1987. Master candidate at Beijing University of Technology. His main research interests include differential privacy and machine learning.

Wu Xiaofei, born in 1991. Master candidate at Beijing University of Technology. His main research interests include personalized recommendation and information retrieval.
A Collaborative Filtering Recommendation Method Based on Differential Privacy
He Ming, Chang Mengmeng, and Wu Xiaofei
(CollegeofComputerScience,BeijingUniversityofTechnology,Beijing100124)
Collaborative filtering with large amount of user data will raise serious risk privacy of individuals. How to protect private data information from disclosure has become one of the greatest challenges to recommender systems. Differential privacy has emerged as a new paradigm for privacy protection with strong privacy guarantees against adversaries with arbitrary background knowledge. Although several studies explored privacy-enhanced neighborhood-based recommendations, little attention has been paid to privacy preserving latent factor models. To address the problem of privacy preserving in recommendation systems, a new collaborative filtering recommendation algorithm based on differential privacy is proposed in this paper, which achieves trade-off between recommendation accuracy and privacy by matrix factorization technique. Firstly, user and item latent feature matrices are constructed for decreasing sparsity. After that, matrix factorization model with noise is generated by adding the differential noisy using objective perturbation method, and then stochastic gradient descent is utilized to minimize regularized squared error function and learn the parameters of model. Finally, we apply a differentially private matrix factorization model to predict the ratings and conduct experiments on the MovieLens and Netflix datasets to evaluate its effectiveness. The experimental results demonstrate that our proposal is efficient and has limited side effects on the precision of recommendation.
differential privacy; privacy protection; collaborative filtering; recommender systems; matrix factorization
2016-03-20;
2016-09-06
國家自然科學基金項目(91646201,91546111,60803086);國家科技支撐計劃項目(2013BAH21B02);北京市自然科學基金項目(4153058,4113076);北京市教育委員會科技計劃重點項目(KZ20160005009);北京市教育委員會科技計劃一般項目(KM201710005023) This work was supported by the National Natural Science Foundation of China (91646201, 91546111, 60803086), the National Key Technology Research and Development Program of China (2013BAH21B02),the Beijing Natural Science Foundation (4153058,4113076), the Key Project of Beijing Municipal Education Commission (KZ20160005009), and the General Project of Beijing Municipal Education Commission (KM201710005023).
TP391; TP18
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
