基于FPGA的DDR3協議解析邏輯設計
2017-07-31 17:47:12譚海清陳正國
計算機應用 2017年5期
關鍵詞:信號
譚海清,陳正國,陳 微,肖 儂
(1.國防科學技術大學 計算機學院, 長沙 410073; 2.高性能計算國家重點實驗室(國防科學技術大學),長沙 410073)
基于FPGA的DDR3協議解析邏輯設計
譚海清1,2*,陳正國1,2,陳 微1,2,肖 儂1,2
(1.國防科學技術大學 計算機學院, 長沙 410073; 2.高性能計算國家重點實驗室(國防科學技術大學),長沙 410073)
(*通信作者電子郵箱tanhaiqing163@163.com)
針對采用DDR3接口來設計的新一代閃存固態盤(SSD)需要完成與內存控制器進行通信與交互的特點,提出了基于現場可編程門陣列(FPGA)的DDR3協議解析邏輯方案。首先,介紹了DDR3內存工作原理,理解內存控制器對存儲設備的控制機制;然后,設計了接口協議解析邏輯的總體架構,采用FPGA實現并對其中的各個關鍵技術點,包括時鐘、寫平衡、延遲控制、接口同步控制等進行詳細闡述;最后,通過modelsim仿真并進行板級驗證,證明了該設計的正確性和可行性。在性能方面,通過單次讀寫、連續讀寫和混合讀寫三種模式下的數據讀寫測試,取得了最高77.81%的DDR3接口帶寬利用率,在實際的SSD開發過程中能夠有效提高系統的訪問性能。
現場可編程門陣列;固態盤;同步時序設計;DDR3接口
0 引言
當前,信息技術高速發展,大數據時代到來,存儲系統規模變得日益龐大,信息的存儲和處理面臨著巨大的挑戰[1]。為滿足數據密集型計算日益增長的性能需求,存儲設備經歷了多次技術革新,基于閃存(Nand Flash)的固態盤(Solid-State Driver, SSD)憑借低延時、低功耗、高帶寬和高并行性等方面的技術優勢,贏得了云計算、高性能計算等領域的青睞[2],并帶動了消費級存儲市場的發展。據國際市場研究者IHS公司預測,到2017年,固態盤將占整個計算機存儲市場的33%以上[3]。
固態盤接口是固態盤與主機系統進行數據交互的通路,決定了二者之間進行數據傳輸的方式,限制了主機與固態盤的峰值傳輸速度。隨著閃存技術的不斷進步、存儲系統性能要求的提高,傳統上基于SATA(Serial ATA)/SAS(Serial Attached SCSI)的固態硬盤已經不能滿足需求,采用PCIE(Peripheral Component Interconnect Express)接口的固態硬盤依然需要經過外設存儲協議層,存在訪存路徑過長的問題,在性能要求苛刻的場合還是無法滿足需求。采用DDR3(Double-Data-Rate Three synchronous dynamic random access memory)接口設計SSD具有訪存路徑短、帶寬大、低延遲等特點[4],可充分發掘固態盤內部的并行性,提高固態盤整體性能。
依據接口性能,可將SSD劃分為3代。第1代SSD采用SATA/SAS接口進行數據傳輸,帶寬有限,其中面向消費級市場采用的SATA Ⅱ、SATA Ⅲ接口帶寬分別為300 MB/s和600 MB/s[5],而面向企業級市場采用的SAS接口帶寬則達到600 MB/s[6]。隨著SSD技術的進步以及市場發展的需求,人們基于PCIE接口設計了第2代SSD,旁路掉傳統SATA/SAS數據通路中的HBA(Host Bus Adapter),訪存延時獲得了一個數量級的提升。雖然PCIE SSD性能具有優勢,然而由于PCIE總線訪存路徑的限制,其讀寫響應時間依然比較長,達到40~70 ms;另一方面,PCIE總線上需要掛載大量的各種設備,導致總線競爭激烈,以至于PCIE SSD的I/O性能無法得到線性的擴展[7]。為減小SSD的存取路徑長度,降低讀寫數據延時,提高I/O可擴展性能,人們提出了采用DDR3接口設計的第3代SSD存儲產品。
基于DDR3接口的第3代SSD在位置上更加靠近CPU,并直接與CPU相連,旁路掉所有外設的存儲協議層,因此能夠獲得超低的訪問延時(ultra-low latency)。該SSD存儲設備通過內存總線(memory bus)進行數據傳輸,遵從DDR3總線協議,采用同步數據傳輸方式與CPU進行數據交互,相對于PCIE SSD采用的異步傳輸方式更加高效。在企業級的高性能、大數據處理方面,尤其是對于存儲設備延遲有著苛刻要求的應用場合上,它能夠較好地滿足性能方面的要求,因此可廣泛應用于高頻交易、大數據分析、虛擬桌面基礎架構、內存計算、刀片服務器等領域[8]。
本文的研究工作是針對DDR3接口信號,嚴格按照JEDEC(Joint Electron Device Engineering Council)規定的時序進行協議解析與控制,包括命令解析、地址譯碼、數據格式轉換、接口I/O同步控制等,將DDR3接口信號轉換成SSD后端可識別的信號,并完成接口同步數據傳輸與交互。
本文實驗基于FPGA(Field-Programmable Gate Array)可編程邏輯器件,采用Verilog硬件描述語言設計解析邏輯。實驗中搭建完整的硬件仿真平臺,通過Xilinx ISE軟件生成的MIG(Memory Interface Generator)核作為內存控制器,以產生內存控制信號。解析邏輯按照內存時序規范對接口信號進行解析與控制,完成數據的接收與發送、執行對后端FTL(Flash Translation Layer)發送過來的請求進行處理等工作。實驗最后對解析邏輯進行了完整的測試和驗證,并對實驗結果進行了分析。
1 DDR3工作原理及協議解析設計難點
1.1 DDR3工作原理
DDR SDRAM(Double-Data-Rate SDRAM)即雙倍速率同步動態隨機存儲器,由SDRAM(Synchronous Dynamic Random Access Memory)基礎上發展而來,采用時鐘的上升沿和下降沿均進行數據采樣,從而把數據傳輸速率提高了一倍[9]。DDR內存技術已經歷四代的發展,每一代內存芯片的核心頻率都維持在100~200 MHz,但在I/O性能上都有大幅度提升。這種性能提升一方面得益于半導體晶圓制造工藝的發展,另一方面是因為采用了雙倍數據速率傳輸(Double Data Rate)和預取(prefetch)兩項核心技術[10]。
DDR3是第3代雙倍速率同步動態隨機存儲器。采用 8 b預取技術,管腳時鐘頻率由之前內核頻率的2倍提升到4倍,到達800 MT/s~1 600 MT/s。
DDR3內存主要由內存芯片和基板構成。內存芯片是數據存儲區,內存基板將8顆或16顆內存芯片整合在一塊PCB板上構成一根內存條。內存芯片如圖1所示,左邊是存儲陣列和訪存控制邏輯(Control Logic),右邊是數據緩存區。存儲陣列在邏輯上被劃分為8個Bank,每個Bank都有獨立的行列地址譯碼邏輯。進行數據讀/寫操作時,控制邏輯通過對命令信號的譯碼,識別訪存指令,從而控制地址功能部件定位存儲陣列訪存位置。緩存邏輯部分負責讀寫數據的緩沖,讀操作時,將預取的64 b數據送入讀數據緩沖區(Read FIFO),然后分成8路,通過數據多路復用器(Data MUX)合并成一路數據流輸出到接口。寫緩沖是讀緩沖的逆過程。
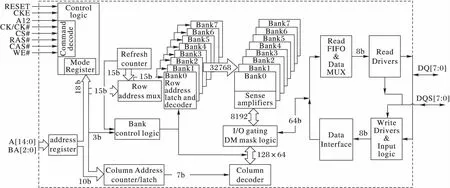
圖1 256 MB ×8的DDR3芯片功能框圖Fig. 1 Functional block diagram of DDR3 chip with 8 banks of 256 MB
DDR3整體上的基本工作流程如圖2所示。上電之后重置,對其每一顆芯片內部的控制邏輯及存儲單元進行初始化,然后設置模式寄存器(Mode Register)MR2、MR3、MR1、MR0,完成一系列的讀寫校準操作,才正式進入工作模式。正常工作模式下的操作包括激活(Bank Active)、讀(Read)、寫(Write)、刷新(Refresh)、預充電(Precharge) 及低功耗模式下的相關操作,所有操作都須嚴格按照JEDEC規范[10]的時序要求進行。
1.2 DDR3內存控制器
DDR3接口的訪存信號由內存控制器向DDR3發出,通過內存總線傳送到DDR3接口。本文依據JEDEC標準對內存總線信號進行解析。本文采用Xilinx公司的ISE軟件生成的MIG核作為DDR3內存控制器,以生成DDR3接口訪存信號源。
基于Virtex-6 FPGA的內存控制器邏輯如圖3所示。中間部分是內存控制器,兩邊的是用戶接口(User Interface, UI)信號和DDR3內存訪問信號。用戶邏輯模擬CPU的訪存行為,向內存控制器發出讀/寫訪存命令,并通過用戶接口送達內存控制器。DDR3內存訪問信號則具體用于對DDR3存儲器進行訪存。

圖2 DDR3 SDRAM操作流程Fig. 2 DDR3 SDRAM operation state diagram
本文設計DDR3協議解析邏輯通過圖3右邊的DDR3接口信號完成與內存控制器之間的交互。實驗最終在左端User Design部分設計讀寫測試激勵,驗證解析邏輯的正確性并測試讀寫性能。
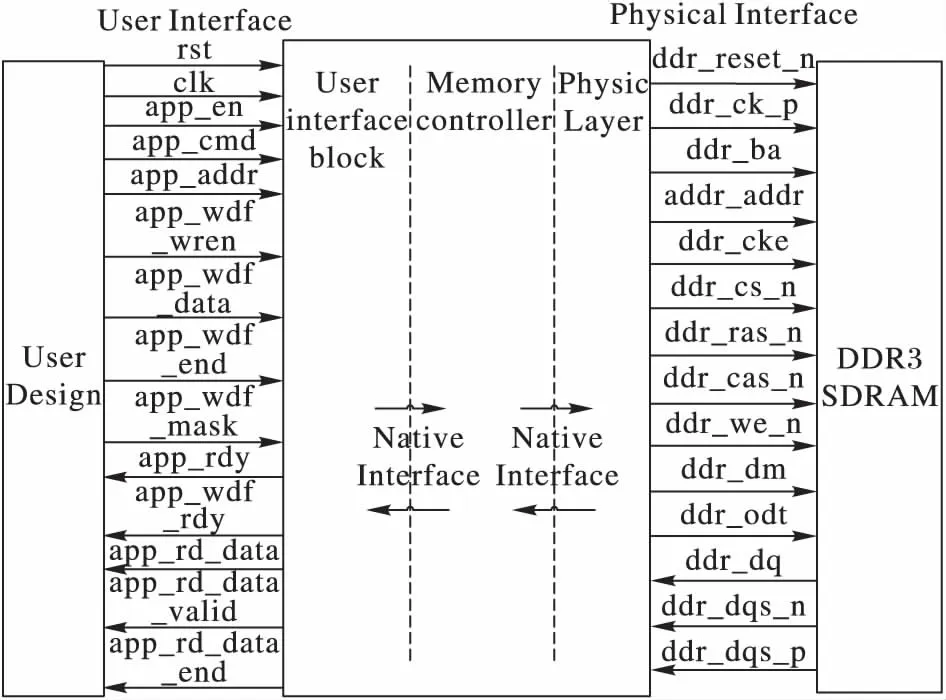
圖3 Virtex-6 FPGA 存儲器接口邏輯框圖Fig. 3 Logical diagram of Virtex-6 FPGA memory interface
1.3 DDR3協議解析設計難點
根據JEDEC標準(JESD79-3)[11]規定的DDR3內存總線時序規范,對協議進行研究與分析,本文設計DDR3協議解析邏輯有以下難點:
1)DDR3 SDRAM在進行正式的讀寫操作之前需要完成漫長的初始化、校準操作,直至控制器置信號phy_init_done有效,用戶邏輯才能通過控制器進行讀寫操作。因此,在初始化及校準操作完成之前,解析邏輯只能被動地配合控制器進行數據交互。只有完成初始化及校準流程才能驗證前期工作的正確性,而無法一步一步迭代前進,這為解析邏輯的設計帶來了不小的挑戰。
2)DDR3總線協議采用同步時序控制方式,在進行讀寫訪問時,從Bank激活到讀/寫命令發出,再到數據送達總線,每一步都有固定的延時限制,延時長度由相關參數設定。在與激活操作相對固定的時間點上必須完成相關數據操作,否則會造成讀寫數據出錯。延時精確控制是解析邏輯設計中有待重點解決的問題。
3)DDR3接口信號采用雙邊沿觸發數據采樣機制,采樣時鐘為數據的源同步信號DQS,頻率與時鐘相同。基于FPGA設計解析邏輯,在400 MHz的工作時鐘下,如何完成雙邊沿觸發數據采樣,并且保證采樣的準確性,是研究中的難點。
2 解析邏輯設計方案
2.1 基于DDR3接口的固態盤架構
基于DDR3接口的SSD原型系統是課題組正在研發的一款大容量、高性能的固態存儲系統,主要針對企業級高性能計算、大數據處理等對訪存延時要求苛刻的領域。原型系統采用較為成熟的系統架構方案,由主控制器、DRAM緩存和Flash存儲空間三部分構成。主控制器采用FPGA可編程邏輯+ARM核實現,用于對存儲系統的讀寫控制和訪存調度,是原型系統的核心;DRAM緩存采用大容量的DDR3芯片,集成在固態盤內部,用于緩沖Flash中的熱點數據,以提高固態盤的讀寫性能;Flash存儲空間由多顆NAND Flash構成,形成大容量的數據存儲區。基于DDR3接口的固態盤原型系統總體架構如圖4所示。
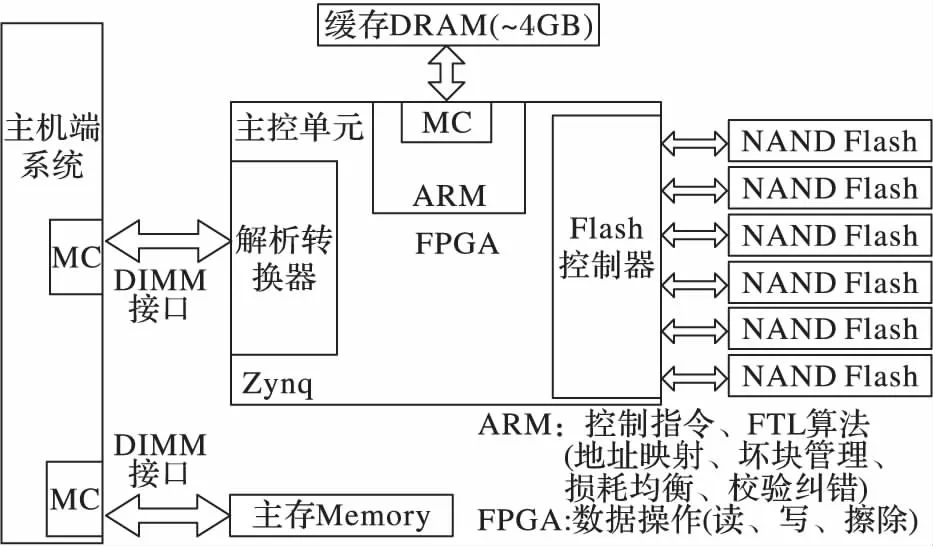
圖4 基于DDR3接口的固態盤原型系統架構Fig. 4 Architecture of SSD prototype based on DDR3 interface
固態盤主控制器是實現高性能數據讀寫的關鍵。本課題研制的基于DDR3接口的固態盤原型系統采用帶有ARM核的Zynq芯片作為主控單元。Zynq中集成了ARM核和FPGA可編程邏輯,主控制器使用ARM核作為指令控制單元,以實現FTL算法;使用FPGA,利用硬件的并行處理特性實現高效數據傳輸與控制等。
原型系統通過DIMM(Dual-Inline-Memory-Modules)插槽直接與主機相連,主機CPU通過內存控制器(Memory Control, MC)像訪問內存一樣訪問該固態存儲設備。圖4中解析轉換器即為本文所要實現的協議解析邏輯模塊,涉及與兩端的通信,一端是對DIMM接口信號進行解析,另一端是與主控制器后端控制邏輯進行交互。本文主要完成針對與DIMM接口信號進行交互的設計工作。
2.2 DDR3協議解析邏輯設計
DDR3協議解析邏輯作為固態盤與主機CPU進行交互的橋梁和紐帶,是整個固態盤系統中非常重要的一環,其設計方案如圖5所示。其中包括三部分:用戶訪存邏輯、MIG核實現的內存控制器以及DDR3協議解析邏輯,整個解析邏輯架構都在FPGA上實現和驗證。
待解析的DDR3接口信號主要有三類:地址、命令和數據信號,根據這些信號狀態,解析邏輯完成相應的數據收發功能。圖5右側是協議解析邏輯,主要包括接收模塊、發送模塊和數據存儲區三個部分。接收模塊用于接收MC發送的指令和數據,并進行重構與緩存;發送模塊則將讀出的數據緩存,并以數據流的方式發送出去;存儲數據區用來保存數據。由于解析轉換器沒有與主控單元后端相銜接,因此這里將后端部分用一個數據存儲區表示,以完成對DDR3接口信號的解析功能,并保證讀寫時序的正確性。
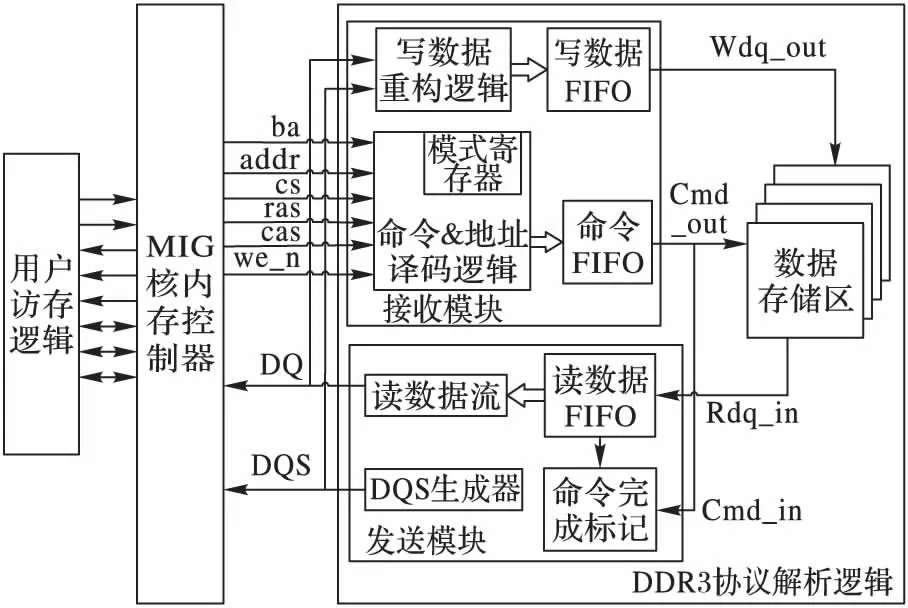
圖5 固態盤解析邏輯的整體結構Fig. 5 Overall structure of SSD parsing logic
解析邏輯中接收模塊包含寫數據重構邏輯和命令&地址譯碼邏輯及兩個FIFO(First Input First Output)緩沖區。寫數據重構邏輯在特定的時刻對有效數據進行采樣并緩沖到寫數據FIFO中。命令&地址譯碼邏輯則根據命令信號cs_n、ras_n、cas_n、we_n的高低電平組合譯碼成DDR3操作指令,如表1所示(H表示高電平,L表示低電平);根據地址信號ba、addr及命令信號進行行列地址識別;在初始化階段,模式寄存器會根據地址和命令信號進行相應的參數設置。
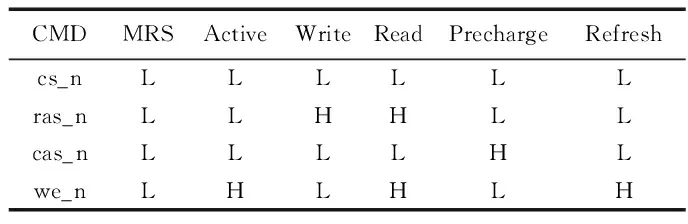
表1 DDR3命令真值表Tab. 1 DDR3 command truth value table
協議解析邏輯中的發送模塊將從數據存儲區中讀回的數據緩存入讀數據FIFO中并在特定的時刻以數據流的形式連續發送到DDR3接口,輸出數據; 同時,雙向數據選通 (Data Strobe Signal,DQS)生成器會產生數據選通信號DQS,與有效數據信號同步輸出。本文設計的DDR3協議解析邏輯采用可綜合的Verilog硬件描述語言實現,綜合出的比特流文件打入FPGA中驗證,完成設計與實現工作。
3 DDR3協議解析邏輯實現
3.1 時鐘網絡
在基于FPGA的數字電路設計中,時鐘是設計中非常關鍵的環節,合理地利用各種時鐘資源設計時鐘網絡,可有效改善所設計的FPGA數字邏輯電路的綜合和實現效果。本文設計的協議解析邏輯時鐘資源主要分為兩種:系統工作時鐘和源同步時鐘。其中,系統工作時鐘由MC通過接口時鐘管腳CK/CK#輸入,驅動解析邏輯大部分工作,包括譯碼、控制、數據存儲和DQS信號生成等;源同步時鐘即數據選通信號DQS,在讀寫操作時與數據信號DQ(Data Strobe)同步傳輸,并使用它對DQ信號進行精確采樣和提取,獲取有效數據。
文中內存控制器采用DDR3-800的內存條參數,因此解析邏輯的系統工作時鐘為400 MHz,符合Xilinx FPGA所限制的時鐘頻率范圍,而源同步時鐘DQS只有在接口進行數據傳輸時才有效,頻率上與系統工作時鐘CK相同。
本文針對時鐘資源的管理如圖6所示,采用三種不同的FPGA時鐘資源分別驅動內部控制邏輯、數據采樣邏輯和跨時鐘域同步邏輯。其中,工作時鐘CK/CK#走FPGA全局時鐘網絡,通過Xilinx時鐘原語IBUGDS+BUFG具體實現, 驅動解析控制邏輯,以使解析邏輯可以在任意位置布局布線;而源同步時鐘DQS使用FPGA的區域時鐘資源,一方面通過I/O邏輯時鐘緩沖BUFIO驅動數據采樣邏輯,在接口位置完成采樣功能,另一方面通過BUFR驅動數據的跨時鐘域同步邏輯,完成寫數據FIFO的跨時鐘域同步,保證通過DQS采樣到的數據能夠在時鐘CK下進行操作。
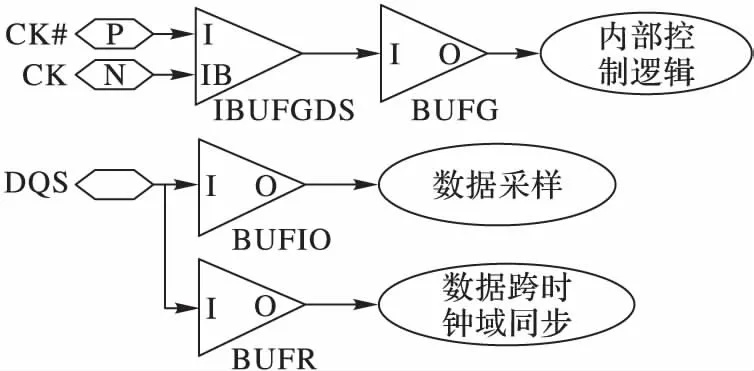
圖6 時鐘資源管理Fig. 6 Clock resource management
3.2 寫平衡
DDR3 SDRAM在時鐘、地址、命令及控制信號上采用Fly-by拓撲結構[13],這些信號以菊花鏈的方式連接,串行地發送到各個內存芯片,以提高信號的完整性。由于數據信號DQ和選通信號DQS是以并行的方式發送到各個內存芯片顆粒的,因此造成了DQS信號與時鐘信號CK之間的歪斜。在CPU正式進入讀寫訪存狀態之前,MC會自動對DDR3進行寫平衡校準操作,調整相位使DQS和CK之間的偏斜變得最小。因此,本文設計的解析邏輯必須配合MC完成寫平衡校準。
寫平衡校準在時序上是一個反復而漫長的操作過程,其校準過程如圖7所示。DQS信號反復地采樣時鐘信號CK,并通過數據信號DQ將采樣結果回送到內存控制器,內存控制器會根據采樣結果對DQS信號作延時調整,以盡量使DQS與CK邊沿對齊。
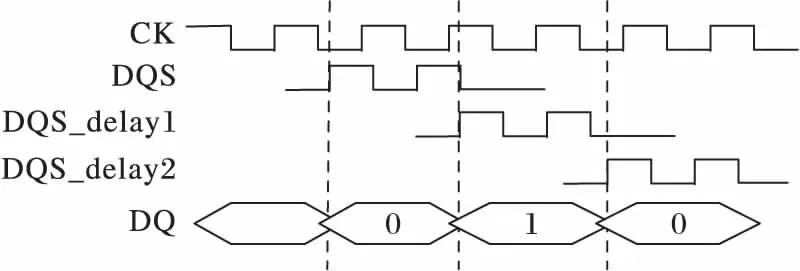
圖7 寫平衡時鐘信號采樣Fig. 7 Write leveling clock signal sampling
當解析邏輯檢測到MC發出模式寄存器設置命令,將MR1的A7地址位設置為1時,指示寫平衡開始。解析邏輯不斷采樣CK、MC,不斷調整DQS延時,反復調整直到MC確定DQS與CK之間的偏斜滿足JEDEC規范的要求,才重新設置 MR1,完成寫平衡。本文通過仿真測試,統計出MC反復采樣142次,DQS延時調整32次,最終完成時鐘CK與DQS之間的偏斜調整,達到最小。
3.3 延遲槽
為實現對延時的精確控制,在DDR3協議解析邏輯中加入延遲槽,即多組延遲計數邏輯。通常,DDR3存儲器的性能可通過一系列的時序參數體現:tCL-tRCD-tRP-t RAS[14],例如DDR3-800的一組參數是6-6-6-15。這是一系列的時鐘周期數,表示一個操作到另一個操作之間的延遲周期。比如從讀命令發出,到數據讀出送達接口之間延時為tCL,提早或稍晚讀數據都會造成出錯。
為保證滿足DDR3接口的同步數據傳輸要求,本文中解析邏輯通過設置延遲槽來實現對操作時序上的精確控制。解析邏輯中共設置5個延遲槽:write_delayslot、read_delayslot、bank_delayslot、row_delayslot、col_delayslot,其中將write_delayslot和read_delayslot設置為15 b的一維向量,以記錄讀寫命令發出后的延遲時間,將bank_delayslot、row_delayslot、col_delayslot設置成深度為15、寬度為相應地址寬度的二維向量,以保存讀寫命令發出時的地址信息Bank、Row、Col。
延遲槽中的向量數據在每個時鐘沿右移一次,當零號向量位有效時表示對應命令進入數據操作階段,開始采樣數據或發送數據。延遲槽從偵測到讀寫命令時開始延時計數,對于讀命令,命令發出后延時CL(CAS Latency)個周期,將從存儲器中取得的數據送達DDR3接口,開始將其拆分以數據流的形式輸出;對于寫命令,延時CWL(CAS Write Latency)個周期數據到達內存總線,開始從接口提取有效數據并寫入存儲區。
如圖8所示為讀延時控制,當read_delayslot[0]=1有效時,指示數據輸出開始(中間豎線位置),因此下一拍解析邏輯必須開始向DDR3接口發送數據。圖中進行了8次數據觸發,完成了一次BL=8的突發傳輸操作。與此同時,使能各種控制信號并生成源同步信號,包括數據輸出使能dq_out_en、突發傳輸位置burst_position、DQS輸出使能dqs_out_en和DQS輸出信號dqs_out等,精確控制其在時序上的有效時間。
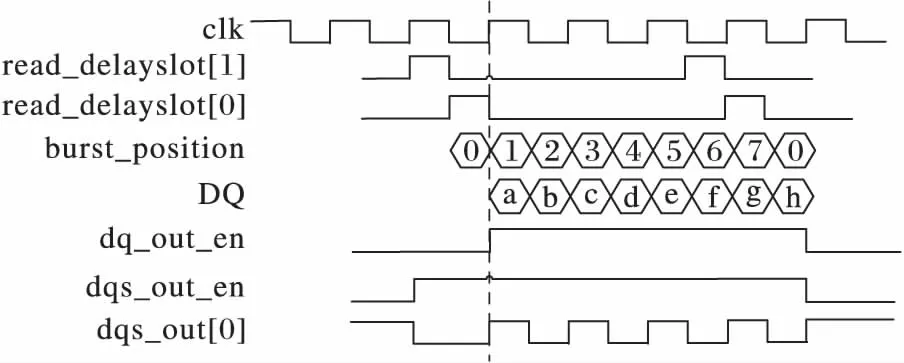
圖8 延遲槽時序控制Fig. 8 Timing control by delayslot
3.4 接口源同步信號I/O控制
數據采樣需要有精確的采樣時鐘。傳統的共同時鐘系統在頻率提升到一定程度時,數據采樣時序裕量不足,無法滿足采樣時序的要求,進而采用更加穩定有效的源同步時鐘系統。在源同步時鐘系統中,發送端將選通信號與數據信號同步發出,在接收端通過選通信號控制數據讀取,選通信號即為源同步時鐘信號。由于兩個信號從發送端到接收端的飛行時間完全一致,從而保證了數據采樣的準確性。
本文中選通信號DQS是數據信號DQ的源同步時鐘信號,解析邏輯針對DQS和DQ的處理如圖9所示。在讀寫操作過程中,二者同步輸入輸出,確保數據采樣的準確性:1)圖9上方信號時序所示,在進行寫操作時,選通信號DQS和數據信號DQ由內存控制器發送到解析邏輯,其中DQS與時鐘CK中心對齊(center-aligned),二者相位偏差90°,而數據信號DQ則直接與時鐘CK邊沿對齊(eged-aligned)。解析邏輯使用DQS信號對DQ信號采樣,采樣位置在DQ有效周期的中心處,以此獲得最大的采樣時間裕度;2)圖9下方所示,在進行讀操作時,DQS和DQ由解析邏輯發送到內存控制器,并且二者均與時鐘CK邊沿對齊,在時鐘CK的邊沿觸發下同時向DDR3接口發送,以保證在MC端數據采樣的準確性。
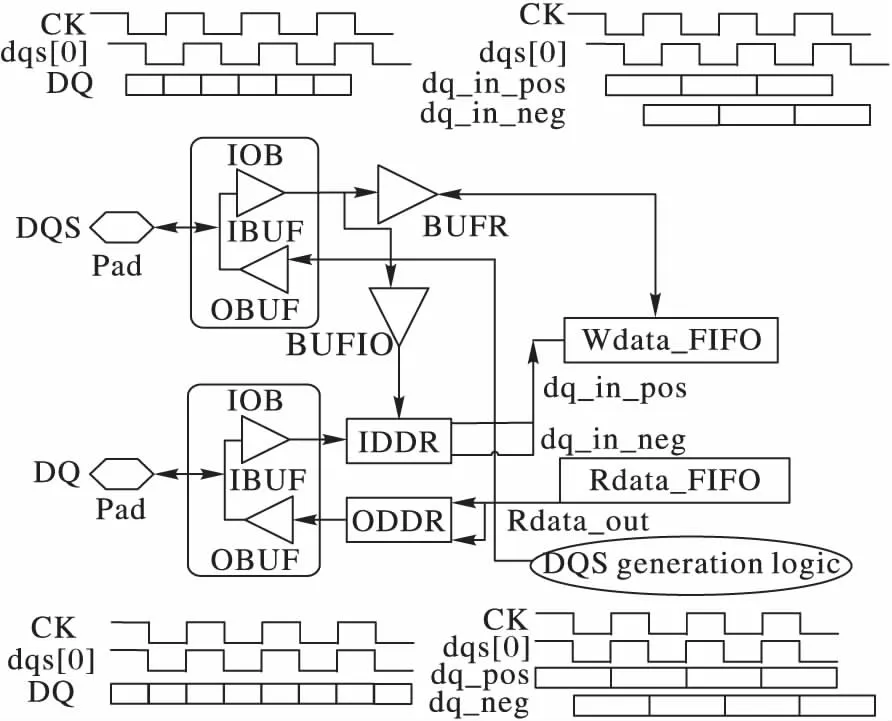
圖9 DQS與DQ的I/O處理Fig. 9 I/O processing of DQS and DQ
本文實驗中對于輸入數據信號使用IDDR原語,將它轉換成兩路單邊沿觸發的信號,在采樣時鐘DQS的上升沿處,一次性采樣取得周期內的兩撥數據(如圖9右上角所示)。單邊沿觸發采樣時間更長,以保證在FPGA內部數據采樣的穩定性,提高設計的綜合和實現效果。在讀操作過程中,對于輸出數據信號,數據在時鐘上升沿一次性從FIFO中取得144 b 數據,分成兩路72 b數據(如圖9右下角所示),用ODDR聚合成數據流輸出,同時DQS生成邏輯會產生同步DQS信號數據往接口輸出。
4 實驗結果與分析
實驗采用Xilinx ISE軟件生成的MIG核作為DDR3控制器,向DIMM口發送訪存信號,并通過MIG核的用戶接口,在用戶邏輯中設計測試激勵,模擬CPU向內存控制器發送訪存命令。采用的DDR3類型為DDR3-800,理論峰值帶寬為6.4 GB/s,采用的DDR3接口類型為適用于服務器內存插槽RDIMM口,接口數據位寬為72 b(64 b有效數據+8 b ECC校驗)。DDR3協議解析邏輯采用Micron的 MT18JSF51272PZ-1G4內存芯片的參數,工作頻率為 400 MHz,采用BL8突發方式進行數據傳輸。
實驗分為正確性驗證和讀寫性能測試兩個部分:正確性驗證檢測協議解析邏輯在時序上的正確性;讀寫性能測試分為單次讀寫數據測試、連續讀寫數據測試和混合讀寫數據測試,分別驗證解析邏輯的正確性和測試解析邏輯的有效性能。
4.1 正確性驗證
協議解析邏輯配合內存控制器完成初始化和校準過程,然后進入讀寫數據狀態,并保證初始化和校準的正確性和讀寫數據的正確性,只有完成整個流程才能確認解析邏輯工作正常。
實驗嚴格按照JEDEC標準的時序要求進行設計,完成了解析邏輯與控制器之間進行初始化及數據校準的交互過程,并在MIG核的用戶接口(UI)端生成的讀寫激勵,通過仿真顯示,解析邏輯能夠正確地配合內存控制器完成數據的寫入和讀出,如圖10所示。
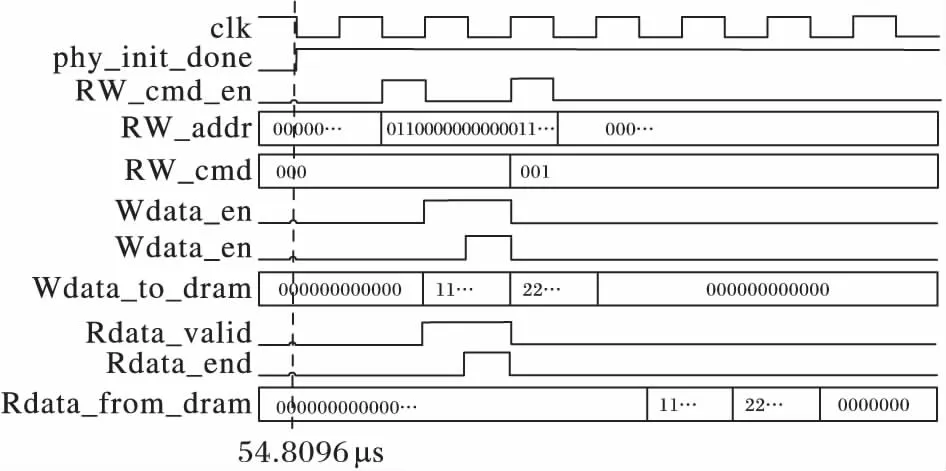
圖10 寫后讀正確性驗證Fig. 10 Correctness verification of reading after writing
UI端的phy_init_done電平信號拉高表示初始化及校準操作成功,從圖10中可以看出,在仿真的54.8 μs處(虛線指示),初始化及校準工作完成。之后,驗證寫、讀數據的正確性,在UI端將數據 256′h11111111111111AA11111111111111BB1111111111111CC11111111111111DD和256′h22222222222222AA22222222222222BB22222222222222CC22222222222222DD共512 b數據通過Wdata_to_dram信號寫入解析邏輯,寫入地址為30′b011000000000001110111100000000。寫完成后發送讀命令,從同一地址將數據讀出,通過Rdata_from_dram將數據讀回,圖中仿真波形顯示,讀回的數據與寫入的數據完全一致,從而驗證了解析邏輯在配合內存控制器完成初始化及校準工作的正確性。
4.2 數據讀寫性能測試
1)單次讀寫性能測試。
為測試解析邏輯所能實現的性能,本文首先進行了單次讀寫數據測試。通過在MIG核的用戶端采用Non-back-to-back模式(非連續地址操作模式),產生多次獨立的寫數據和讀數據激勵,測試DDR3接口帶寬的利用率。
實驗中共進行200次獨立的數據讀寫測試,其中100次寫數據測試和100次讀數據測試,分別測試在同Bank同行、同Bank不同行、不同Bank地址上的讀寫性能。其中在同Bank同行地址上讀寫性能最好,分別達到4.31 GB/s和3.2 GB/s,DDR3-800接口帶寬利用率達到67.3%和50.0%。同Bank不同行地址上的讀寫性能最差,僅有1.2 GB/s和1.31 GB/s。這種差別主要源于內存控制器的訪存機制。對于同一Bank 行上數據的連續操作,內存控制器不進行行切換,即不需要對前一訪問行進行預充電,從而大幅減少了兩次讀/寫操作的時間間隙,提高了帶寬的利用率。對于不同Bank地址上的讀/寫測試,由于兩次操作的Bank位置不同,因此對前一個Bank預充電的同時可激活另一個Bank,從而平滑地過渡到對兩個Bank的訪存,因此讀寫性能比同Bank同行模式稍差,但比不同Bank不同行模式要好一倍左右,讀/寫性能分別達到3.69 GB/s和2.75 GB/s,DDR3-800接口帶寬利用率為57.65%和42.96%。在同Bank不同行上進行數據訪問,每次從一行中完成讀/寫后,需要對該Bank行進行預充電,此時這個Bank都不能做其他的操作,因此,同Bank內不同行之間切換時間開銷比較大,讀/寫性能也最差。
2)連續讀寫性能測試。
內存控制器的訪存位置連續,讀寫性能會獲得較大的提升。本文實驗中進行了連續地址讀寫測試,在MIG核的用戶接口端使用Back-to-back模式,向同Bank同行的連續列地址上發送訪存命令,測試讀寫數據的性能。
在同Bank同行連續列地址上寫數據速率達到4.41 GB/s,帶寬利用率為68.90%,而讀數據速率達到4.98 GB/s,接口帶寬利用率為77.81%。兩種連續讀寫模式都比單次讀寫模式中的同Bank同行模式下的性能高出15%~30%。連續地址訪存過程中,由于地址連續,只需在第一個數據讀/寫時進行地址訪問,后續地址在原有地址上加上固定偏移即可,因此減少了列地址尋址時間,提高了訪存性能。
3)混合讀寫性能測試。
現實情形中,CPU向內存控制器發出的讀寫命令很可能是混合在一起的,既有可能讀后寫,也有可能寫后讀,讀寫數據之間可能還存在相關。本文實驗模擬CPU產生混合讀寫激勵,在激勵中讀寫操作不斷切換,測試隨機數據讀寫性能。實驗結果如表2所示。

表2 混合讀寫性能Tab. 2 Mixed read and write performance
實驗中,連續的兩個讀寫命令地址不相同,即連續操作的數據不存在相關性,由此觀察時間開銷。實驗數據顯示,混合讀寫的帶寬利用率普遍較低,為DDR3接口峰值帶寬的20%~45%,其中連續讀寫操作地址在同Bank同行時,讀寫性能相對較高,數據傳輸速率到達2.76 GB/s,而連續讀寫操作地址在同Bank不同行時性能最低,僅為1.47 GB/s。這是由于在進行讀寫操作切換時,同Bank 不同行地址上的讀寫只能串行地操作,由此引入的時間開銷比較大。
5 結語
基于DDR3接口設計SSD在位置上更加靠近CPU,具有較短的訪存路徑,因此在性能上具有巨大的優勢。本文在總結和分析了DDR3存儲器工作原理的基礎上,根據JEDEC規范的時序,設計了DDR3接口信號解析邏輯,完成了協議解析功能,保證了SSD與內存控制器交互的正確性。實驗結果表明,解析邏輯能夠正確地完成與內存控制器的交互,并取得較為理想的I/O性能,為后續實現DDR3接口的SSD原型系統奠定了良好的基礎。本文MIG配置命令順序執行,在一定程度上限制了數據訪問性能,在本文基礎上,可對MIG配置成命令亂序執行,以優化設計;并且在本文基礎上,后續可采用DDR3-1600或者DDR4接口,充分發揮內存接口性能的優勢,提升SSD的I/O訪問帶寬。
References)
[1] MICHAEL K, MILLER K W. Big data: new opportunities and new challenges[J].Computer, 2013,46(6):22-24.
[2] OUYANG J, LIN S, JIANG S, et al. SDF: Software-defined flash for Web-scale internet storage systems[J]. ACM SIGPLAN Notices, 2014, 49(4): 471-484.
[3] IHS homepage[EB/OL].[2016-05-20]. https://www.ihs.com/index.html.
[4] BAEK S H, PARK K W. A fully persistent and consistent read/write cache using flash-based general SSDs for desktop workloads[J]. Information Systems, 2016, 58: 24-42.
[5] LUO J, FAN L, CHEN Z, et al. A solid state drive architecture with memory card modules[J]. IEEE Transactions on Consumer Electronics, 2016, 62(1): 17-22.
[6] GALBRAITH R E, CLEVELAND L D, YU J, et al. Highly automated hardware and firmware RAID SoC design optimized for memory class storage devices[C]// Proceedings of the 2013 International SoC Design Conference. Piscataway, NJ: IEEE, 2013: 282-285.
[7] StorageAcceleration[EB/OL].[2016-05-20]. http://www.storageacceleration.com.
[8] OIKAWA S. Performance Impact of New Interface for Non-volatile Memory Storage[M]// Software Engineering Research, Management and Applications. Berlin: Springer, 2015: 1-13.
[9] 黃萬偉. Xilinx FPGA應用進階[M]. 北京:電子工業出版社, 2014: 21-29.(HUANG W W. Advanced Xilinx FPGA Applications[M]. Beijing: Publishing House of Electronics Industry, 2014: 21-29.)
[10] BALAJI T, PALANISAMY Z V. Memory design considerations for DDR-3 SDRAM[J]. Asian Journal of Information Technology, 2007, 6(6): 720-725.
[11] SPECIFICATION D D R S. Revision of JESD79-3[S/OL].[2016-10-20].http://www.jedec.org/.
[12] LEE T, KIM D, PARK H, et al. FPGA-based prototyping systems for emerging memory technologies[C]// Proceedings of the 2014 25nd IEEE International Symposium on Rapid System Prototyping. Piscataway, NJ: IEEE, 2014: 115-120.
[13] CHEN C K, GUO W D, YU C H, et al. Signal integrity analysis of DDR3 high-speed memory module[C]// Proceedings of the 2008 Electrical Design of Advanced Packaging and Systems Symposium. Piscataway, NJ: IEEE, 2008: 101-104.
[14] LIN C S, TSAI Y C. System and method for processing booting failure of system: U.S. Patent 8296556[P]. 2012-10-23.
This work is partially supported by the National Natural Science Foundation of China (NSFC61433019, NSFC61432472).
TAN Haiqing, born in 1991, M.S. candidate. His research interests include memory controller, solid-state storage.
CHEN Zhengguo, born in 1991, Ph. D. candidate. His research interests include high performance storage, deduplication technology.
CHEN Wei, born in 1982, Ph. D., associate professor. Her research interests include high performance microprocessor, computer architecture.
XIAO Nong, born in 1969, Ph. D., professor. His research interests include high performance computing, large-scale network storage.
Design of DDR3 protocol parsing logic based on FPGA
TAN Haiqing1,2*, CHEN Zhengguo1,2, CHEN Wei1,2, XIAO Nong1,2
(1.CollegeofComputer,NationalUniversityofDefenseTechnology,ChangshaHunan410073,China;2.StateKeyLaboratoryofHighPerformanceComputing(NationalUniversityofDefenseTechnology),ChangshaHunan410073,China)
Since the new generation of flash-based SSD (Solid-State Drivers) use the DDR3 interface as its interface, SSD must communicate with memory controller correctly. FPGA (Field-Programmable Gate Array) was used to design the DDR3 protocol parsing logic. Firstly, the working principle of DDR3 was introduced to understand the controlling mechanism of memory controller. Next, the architecture of this interface parsing logic was designed, and the key technical points, including clock, writing leveling, delay controlling, interface synchronous controlling were designed by FPGA. Last, the validity and feasibility of the proposed design were proved by the modelsim simulation result and board level validation. In terms of performance, through the test of single data, continuous data and mixed read and write data, the bandwidth utilization of DDR3 interface is up to 77.81%. As the test result shows, the design of DDR3 parsing logic can improve the access performance of storage system.
Field-Programmable Gate Array (FPGA);Solid-State Driver (SSD);synchronous timing design; DDR3 interface
2016-07-15;
2016-11-30。 基金項目:國家自然科學基金資助項目(NSFC61433019, NSFC61472432)。
譚海清(1991—),男,湖南衡陽人,碩士研究生,主要研究方向:內存控制、固態存儲; 陳正國(1991—),男,浙江溫州人,博士研究生,主要研究方向:高性能存儲、數據重刪; 陳微(1982—),女,江蘇蘇州人,副教授,博士,主要研究方向:高性能微處理器、計算機系統結構;肖儂(1969—),男,江西南昌人,教授,博士,CCF會員,主要研究方向:高性能計算、大規模網絡存儲。
1001-9081(2017)05-1223-06
10.11772/j.issn.1001-9081.2017.05.1223
TP391
A
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
