一種并行化的分類算法研究
2017-07-15 15:05:35李慧彥
智能計算機與應用 2017年3期
李慧彥


摘要:研究并實現TJIT Spark的KNN算法的并行構建。分析了MapReduce模型和Spark在處理迭代計算方面的優劣,結合KNN算法的自身特點設計了對應的Map算子和Reduce算子,實現了KNN算法的spark并行化。實驗結果表明,較傳統的KNN串行算法和MapReduce并行KNN算法,基于Spark的并行KNN分類算法具有較好的效率和較高的可擴展性。
關鍵詞:Spark;KNN:MapReduce
0引言
隨著信息技術的發展,在電子商務、科學研究和互聯網應用等領域積累了海量的數據資源,而且數據量正呈現激增態勢。從海量的數據中尋獲有意義的信息以提供更佳體驗,必須采用有效的數據挖掘技術,其中K-Nearest Neighbor(KNN)算法是時下常用的一種數據挖掘算法,但KNN計算的時間復雜度較高,在大數據處理面前,則難掩效率遜色的不爭事實。目前,許多學者采用MapReduce進行KNN算法的并行化構建,執行效率則得到了顯著提高。MapReduce計算框架對迭代計算缺乏一種特性支持,即在并行計算的各個階段提供重要的數據共享時,Map函數需要將中間結果寫入到磁盤,而Reduce函數在進行讀取時將增加了磁盤IO。基于此,本文即主要結合KNN算法的自身特點展開了Spark技術在KNN算法上的應用研究。
1Spark簡介
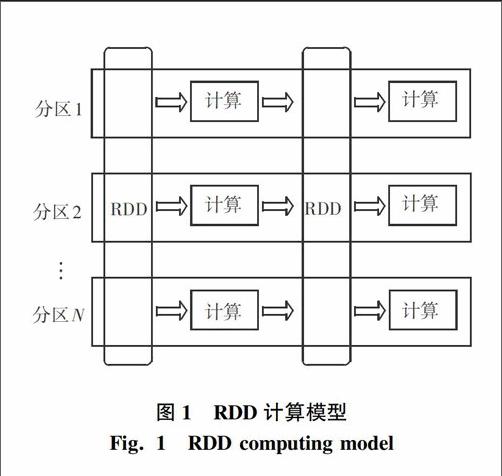
Spark是伯克利大學在2012年提出的一個基于內存的分布式計算框架,其核心是彈性分布式數據集(ResilientDistributed Datasets,RDD),這是對集群上并行處理數據的分布式內存的抽象。spark是一個大數據分布式編程框架,具有Map算子、Reduce算子以及計算框架,能夠實現任務調度、RPC、序列化和壓縮,同時還可為運行在其上的上層組件提供API。由于引進RDD概念,Spark可以在計算中將中間輸出和結果分布式緩存在各個節點內存中,并且允許用戶進行重復使用,省去了磁盤大量的IO操作,從而大幅縮短了訪問時間。
RDD可以看作是對各種數據計算模型的統一抽象,Spark的計算過程主要是RDD的迭代計算過程,具體如圖1所示。spark應用在集群上以獨立的執行器運行在不同的節點上,主程序中以SparkContext對象來設計展開總體調度。目前,YARN、Mesos、Standalone、EC2等都可以作為Spark的集群資源管理器,集群資源管理器的作用可描述為在不同Spark應用間掌控處理資源分配。集群資源管理器主要用于資源的分配與管理,就是將各個節點上的內存、CPU等資源分配給應用程序以盡可能實現數據的本地化計算。運行架構即如圖2所示。
