基于正方形切平面描述符的三維人臉區域標記
2017-07-12 09:45:35陳智董洪偉曹攀
軟件導刊 2017年6期
陳智+董洪偉+曹攀
摘要:針對目前三維人臉模型的語義標記和分割研究較少的問題,提出一種基于正方形切平面描述符的三維人臉模型區域標記算法。這種新的描述符由三維人臉模型頂點的正方形切平面區域內的幾何信息編碼而成。隨后通過隨機森林算法對其進行學習,對模型上的所有頂點進行分類,從而實現對三維人臉模型上眉毛、眼睛、鼻子、嘴巴等區域的識別和標記。在定位仿真實驗中,分類準確率可達94.46%。該描述符具有旋轉、頭部姿勢與三維模型分辨率不變性,對模型噪聲具有魯棒性。實驗結果表明,該方法能有效標記三維人臉模型區域。
關鍵詞:語義標記;三維人臉;網格標記;隨機森林;正方形切平面描述符
DOIDOI:10.11907/rjdk.171139
中圖分類號:TP317.4
文獻標識碼:A 文章編號:1672-7800(2017)006-0189-05
0 引言
在計算機視覺與圖像領域,對于二維圖像人臉的研究(包括人臉識別、人臉檢測、人臉特征點標記等)非常多,并且取得了很大進展。特別是近幾年,隨著深度學習算法的應用,對于二維人臉的研究有了極大突破[1]。然而,相對于二維人臉,人們對三維人臉研究較少。三維人臉的研究是以人臉的三維數據為基礎,結合計算機視覺和計算機圖形學,充分利用三維人臉的深度信息和其它幾何信息,解決和克服現有二維人臉研究中面臨的光照、姿態、表情等問題[3]。三維人臉模型標記與分割是將三維人臉網格模型上的頂點進行分類,將人臉劃分為幾個區域,例如眉毛、眼睛、鼻子、嘴等。對這些區域的標記與分割對三維人臉重建、特征點定位和表情動畫等方面的研究都起著重要作用。三維人臉的研究是模式識別和圖形學領域活躍且極具潛力的研究方向之一,在影視、游戲動畫、人臉識別、虛擬現實、人機交互等方面都有著廣泛應用[2-3]。
目前,許多對三維人臉方面的研究,包括三維人臉重建、識別與跟蹤、姿態估計及特征點標記等,都是基于深度圖的方法[4-7]。Fanelli等[6-8]提出一種方法,將從深度數據估算人臉姿態表達為一個回歸問題(Regression Problem),然后利用隨機森林算法解決該問題,完成一個簡單深度特征映射到三維人臉特征點坐標、人臉旋轉角度等實值參數的學習。通過訓練數據集建立隨機森林,該數據集包括通過渲染隨機生成姿態的三維形變模型得到的5萬張640*480深度圖像。在實驗部分,對Fanelli等提出的從深度圖中提取特征的方法與本文的特征提取方法進行了對比。與文獻[6]中的方法相比,Papazov[9]提出了一個更為復雜的三角形表面patch特征,該特征是從深度圖重建成的三維點云中計算獲得的,主要包括兩部分:線下測試和線上測試。將三角形表面patch(TSP)描述符利用快速最近鄰算法(FLANN)從訓練數據中尋找最相似的表面patches。
在計算機圖形學領域,網格理解在建立和處理三維模型中起著重要作用。為了有效地理解一個網格,網格標記是關鍵步驟,它用于鑒定網格上的每個三角形屬于哪個部分,這在網格編輯、建模和變形方面都有著重要應用。Shapira等[10]利用形狀直徑函數作為分割三維模型的一個信號,通過對該信號的計算,定義一個上下文感知的距離測量,并且發現眾多目標之間的部分相似性;隨后,Sidi等[11]提出一個半監督的聯合分割方法,利用一個預定義的特征集實現對目標的預先分割,然后將預先做好的分割嵌入到一個普通空間,通過使用擴散映射獲得最終的對網格集的聯合分割。網格標記的一個關鍵問題是建立強大的特征,從而提高各類網格模型標記結果的準確性,增加泛化能力。為了解決該問題,Kalogerakis等[12]提出采用一種基于條件隨機場算法的方法來標記網格。通過對已標記的網格進行訓練,成功地學習了不同類型的分割任務;Xie等[13]提出一種三維圖形快速分割與標記的方法,用一系列特征描述法和極端學習器來訓練一個網格標記分類的神經網絡;Guo等[14]提出用深度卷積神經網絡(CNNs)從一個大的聯合幾何特征中學習網格表示方式。這個大的聯合幾何特征首先被提取出來表示每個網格三角形,利用卷積神經網絡的卷積特征,將這些特征描述符重新組織成二維特征矩陣,作為卷積神經網絡的輸入進行訓練與學習。
本文提出一種新的幾何特征描述符(正方形切平面描述符)來表示人臉模型上的頂點特征,利用隨機森林算法對三維人臉模型頂點進行訓練,實現對人臉模型上頂點的分類(屬于鼻子或是眼睛區域等),從而實現三維人臉模型的區域標記。這種新描述符并非從深度圖提取的簡單矩形區域特征,而是直接從三維人臉模型計算獲得,在人臉的姿勢、尺寸、分辨率的改變上具有一定魯棒性。因此,訓練過程是在三維人臉模型上執行的,這種數據相對于真實的深度圖數據更容易獲取(例如在文獻[6]中使用的訓練數據)。
1 特征描述符與三維人臉區域分割
1.1 正方形切平面描述符
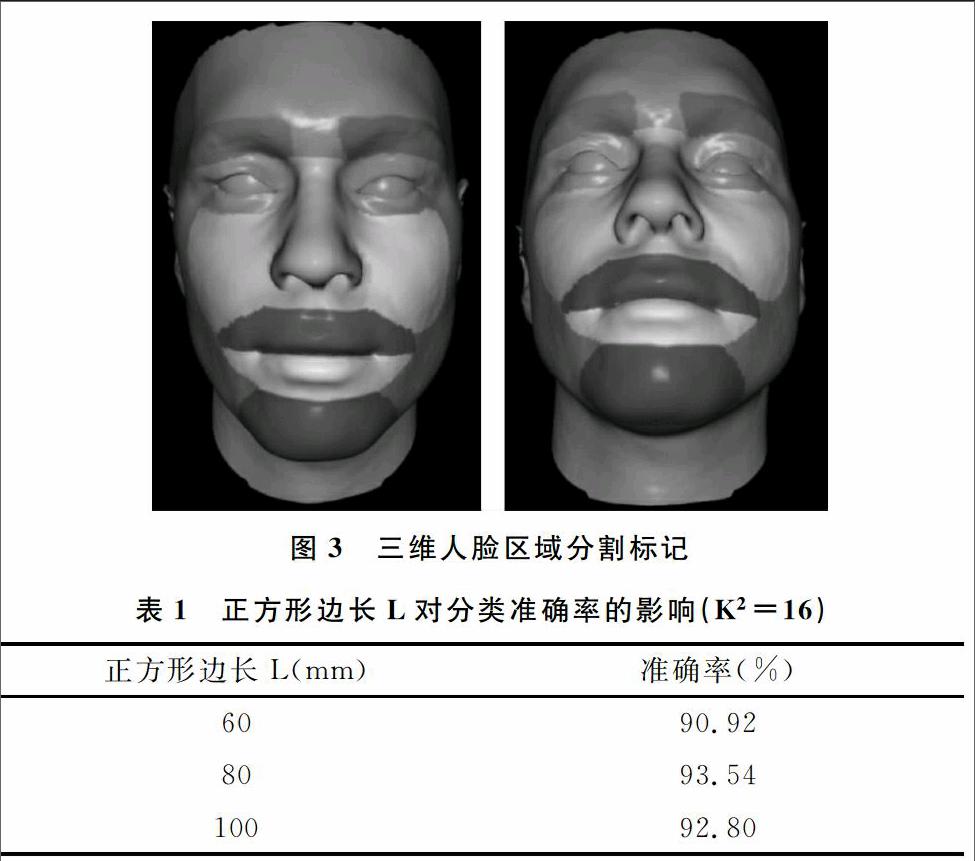
從一個三維人臉模型M的所有頂點上隨機選取一個種子點P,根據三維人臉模型的幾何結構,計算該種子點的法向量,此時根據一點和法向量即可確定一個切平面。確定正方形的邊長L和正方形的方向。正方形的方向(正方形局部坐標系)是根據全局坐標系下建立的正方形,通過法向量轉換而成。建立正方形局部坐標系,以便于計算三維人臉上的點到正方形的投影距離,減少程序運行時間,從而可以確定一個正方形切平面塊S。在這種情況下,根據正方形切平面塊S,可以計算出一個簡單且具有魯棒性的幾何描述符V。將正方形邊長分成K等份,正方形則細分為K2個小正方形,如圖1(a)所示。模型M上的所有點向正方形切平面塊上投影,如果投影點在正方形內,此點則肯定在K2個小正方形中的某一個正方形內,稱該點屬于該小正方形或者稱小正方形包含該點。每個小正方形的描述符是其包含所有點投影距離的平均值。考慮到人臉模型的幾何特征,有些人臉部分存在于正方形上面,有些部分則存在于正方形下面,因此每個點的投影距離有正負之分。整個正方形切平面塊的描述符V是所有小正方形描述符的簡單串聯。在實驗部分,本文將對邊長L和劃分的小正方形個數K2對分類的準確率進行對比研究。
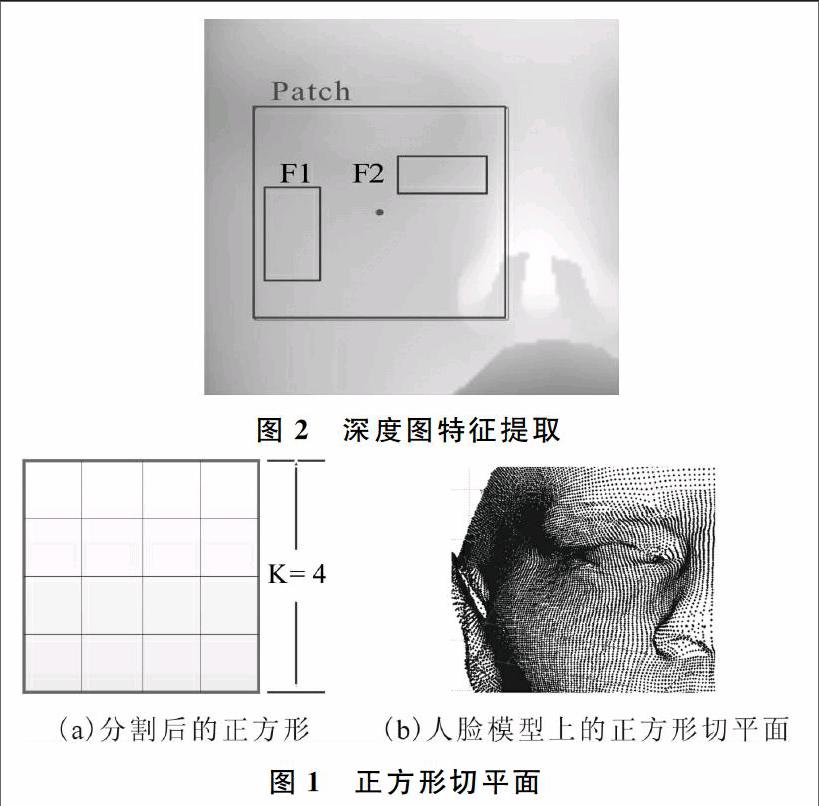
使用每個小正方形包含所有點的平均投影距離作為描述符,使得該描述符對噪聲、數據分解和分辨率上的變化具有魯棒性,這在實驗部分有所體現。許多三維幾何特征已經在一些文章中被提出,包括Spin Images(SI)[15]、3D shape context (SC)[16]、 SHOT[17]和MeshHOG[18-19]。這些描述法都根據局部坐標系定義并且依賴于大量的平面法向量,使噪聲數據對結果產生一定影響。和以上描述法相比,本文描述符取平均投影距離,并且正方形取的足夠大,使描述法更加簡單、有效且具有魯棒性。除三維幾何特征外,許多文章也對三維模型投影生成的深度圖進行了特征選取和處理。例如,Fanelli等[6-8]在深度圖中選取patch,然后在patch中隨機選取兩個矩形框F1、F2,如圖2所示。以像素點的深度值和幾何法向量的X、Y、Z值作為隨機森林的4個特征通道,F1和F2中所有像素點某個特征通道平均值的差值作為隨機森林每棵樹節點的二元測試。二元測試定義為:
本文在實驗部分對上述特征選取方式與本文提出的正方形描述符在三維人臉區域標記上的結果進行了比較。
1.2 數據庫與人臉區域分割
訓練階段的正方形切平面描述符均取自于高分辨率的人臉網格模型,這些訓練模型由Basel Face Model (BFM)[20]生成。BFM是一個公開、可獲得的基于PCA的三維形變模型,由200個人臉對象的高分辨率三維掃描創建而成。通過從一個正態分布取樣的PCA系數,BFM能被用來生成任意數量的隨機網格人臉。此外,在所有生成的人臉網格模型上,對應頂點的索引都是一樣的。例如,在所有訓練模型上,在鼻尖的頂點有相同的索引數字,這將帶來諸多便利。對于訓練模型,只需在任意一個BFM人臉模型上進行一次人臉區域的手動標記,即可知道每個訓練模型要分割的區域上各點的索引,如每個模型鼻子區域的所有頂點索引都是一樣的。
對訓練模型進行手動分割標記(只需分割標記一次),將一個三維人臉模型分割為10個區域:左眉毛、右眉毛、左眼睛、右眼睛、左臉頰、右臉頰、鼻子、上嘴唇、下嘴唇、下巴,剩下部分屬于其它區域。如圖3所示,對三維人臉模型進行區域分割,不同的分割區域用不同顏色進行標記,每個區域包含很多三維人臉模型頂點。由于很多三維人臉模型額頭部分包含的頂點相對較少,特征信息也相對較少,所以將額頭區域劃分至其它區域。人臉模型的每個區域包含的所有頂點屬于同一類,根據上述BFM數據庫特點可知,數據庫中任何一個人臉模型每個區域包含的所有頂點索引都是一致的。
2 隨機森林算法分類標記人臉區域
2.1 隨機森林算法
分類回歸樹[21]是一個強大的工具,能夠映射復雜的輸入空間到離散或者分段連續的輸出空間。一棵樹通過分裂原始問題到更簡單、可解決的預測以實現高度非線性映射。樹上的每一個節點包含一個測試,測試的結果指導數據樣本將分到左子樹或是右子樹。在訓練期間,這些測試被選擇用來將訓練數據分組,這些分組對應著實現很好預測的簡單模型。這些模型是由訓練時到達葉子節點的被標記的數據計算而來,并且存儲于葉子節點。Breiman[22]指出雖然標準的決策樹單獨使用會產生過擬合,但許多隨機被訓練的樹有很強的泛化能力。隨機被訓練樹的隨機性包括兩方面,一是用來訓練每棵樹的訓練樣本是隨機選取的,二是每棵樹上的二元測試是從使每個節點最優的測試集中隨機選取的。這些樹的總和稱為隨機森林。本文將三維人臉模型區域的標記與分割描述為一個分類問題,并利用隨機森林算法來有效地解決它。
2.2 訓練
訓練數據集是由BFM生成的50個三維人臉模型。從每個模型上隨機取n=10 000個頂點樣本,每個頂點對應一個正方形切平面塊。本文實驗中森林由100棵樹建立而成,森林里每個樹由隨機選取的一系列塊(patch){Pi=Vfi,θi}構建而成。Vfi是從每個樣本提取的特征,即正方形切平面描述符,f是特征通道的個數,正方形劃分為K2個小正方形,f=K2。實值θi是這個樣本所屬的類別,例如鼻子區域類別設為數字1,那么鼻子區域內的頂點樣本所對應的θ=1。建立決策樹時,在每個非葉子節點上隨機生成一系列可能的二元測試,該二元測試定義為:
這里的Pi∈{L,R}是到達左子樹或右子樹節點上的樣本集合,wi是到左子樹或右子樹節點的樣本數目和到父節點樣本數目的比例,例如:wi=|Pi||P|。
2.3 測試
通過BFM生成55個三維人臉模型,其中50個人臉模型作為訓練數據,剩下5個人臉模型作為測試數據。測試數據依然取10 000個樣本點,并且知道每個樣本點屬于哪一個區域,通過測試數據計算三維人臉模型網格點分類的準確率。為了測試提出方法的有效性,研究過程中從網上下載獲取了其它三維人臉模型,對人臉模型上的所有網格點通過之前訓練好的隨機森林模型進行分類。因為其它人臉模型與BFM生成人臉模型的尺寸、坐標單位等不一致,所以本研究對這些測試模型進行了后期處理,對正方形的邊長按照模型尺寸的比例進行選取。
3 實驗
3.1 數據集與實驗環境
本文三維人臉標記與分割所用的訓練和測試三維人臉模型由BFM生成,50個模型作為訓練數據,5個模型作為測試數據。每個模型包含53 490個頂點和106 466個三角形網格,每個訓練模型選取10 000個頂點樣本。用C++和OpenGL、OpenCV等庫對三維人臉模型數據進行采樣,得到每個樣本的正方形切平面描述符。在Matlab平臺下用隨機森林算法對數據集進行訓練和測試,并對實驗結果進行可視化。
3.2 實驗結果
利用已訓練好的模型對測試數據集上三維人臉模型的所有頂點進行分類,計算頂點分類的準確率。準確率(Accuracy Rate)計算公式為:
準確率=預測正確的頂點個數(m)人臉模型上所有頂點個數(N)
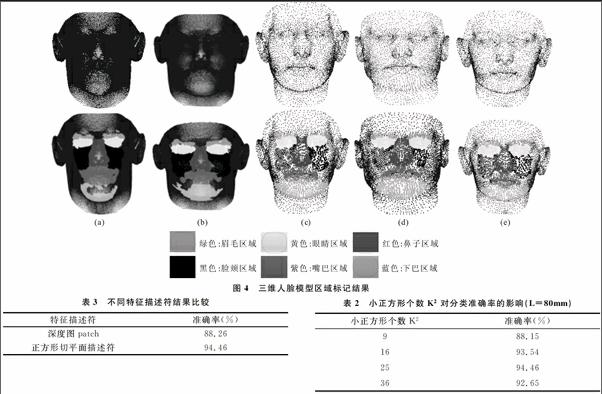
根據文獻[10]提出的類似描述符參數選取以及參數優化策略,經過多次實驗,研究發現正方形邊長L和正方形劃分的小正方形數目K2兩個參數的選取對頂點分類準確率有著一定影響。實驗中選取參數L∈{60,80,100}、參數K2∈{9,16,25,36}進行對比,具體對比結果如表1、表2所示(其中表1中K2為16,表2中L為80mm)。
根據上面兩個表格,可以明顯得出,L=80mm,K2=25時頂點分類準確率最高。接下來對L=80mm,K2=25情況下的三維人臉模型區域進行標記,可視化結果如圖4所示,上邊是原始三維模型數據,下邊是標記后的結果。(a)、(b)模型標記圖是由BFM生成的三維人臉模型區域標記的結果,模型有53 490個頂點。為了驗證本文方法的一般性和對分辨率具有不變性,(c)~(e)模型標記圖是非BFM生成的其它三維人臉模型的標記結果,模型約有5 000個頂點。以上所有圖都是對三維人臉模型所有頂點進行標記的結果。
文獻[6]~[8]中提到的基于深度圖的特征提取方法(見圖1),同樣利用隨機森林算法進行了實驗,并與本文的正方形特征描述符的實驗結果進行了比較,如表3所示。將深度圖投影到96*96大小,深度圖patch所取邊長與深度圖大小的比例和正方形所取邊長與模型大小的比例相等。
由表3可得,對三維人臉模型頂點級分類和區域標記問題,本文提出的特征描述符的標記結果優于深度圖patch特征選取方法。此外,由于深度圖的一些局限性,直接對三維模型處理要比對深度圖處理更有優勢。
3.3 結果討論與分析
圖4中5個模型頂點數目、三角形面數目和頭部姿勢都不一樣,驗證了本文所提方法對于姿勢、模型尺寸和模型分辨率具有較好的魯棒性。并且其對不同的眉毛、眼睛、臉頰區域也能進行很好的區分,將左右眉毛、左右眼睛和左右臉頰用同一顏色、不同符號進行顯示。本文提出的描述符和直接對三維模型處理的方法,與在深度圖上選取特征方法相比具有一定優勢。由于手動分割人臉區域時,很難避免分割粗糙,區域交界處有的部分頂點沒有包含進去,因此在區域交界處頂點的分類誤差會相對略大,特別是嘴唇之間的部分。另外,三維人臉模型中額頭和下巴的頂點和特征相對較少,所以相較于其它區域,這兩個區域的頂點分類誤差也會略大。
4 結語
本文提出一種基于正方形切平面描述符的三維人臉區域標記方法。將這種幾何特征描述符作為選取樣本的特征,通過隨機森林算法,對三維人臉模型進行區域分類和標記。該方法可有效識別出三維人臉模型的眉毛、眼睛、鼻子、嘴巴和臉頰等區域,這對三維人臉特征點的定位及其它三維人臉方面的研究都具有重要意義。本文提出的方法對三維人臉模型頭部姿態、模型尺寸、模型分辨率具有較好的魯棒性。和基于深度圖的方法相比,本文提出的方法具有更好的泛化能力,是一種行之有效的特征提取方法。
然而,手動分割人臉區域的做法在一定程度上略顯粗糙,特征選取速度亦仍需優化。同時,本文僅對三維模型上所有頂點所屬區域進行標記,沒有將標記后的結果結合三維分割算法進行區域分割優化。如何對相關算法加以改進,將是下一步需要解決的問題。
參考文獻:
[1]SUN Y, WANG X, TANG X. Deep convolutional network cascade for facial point detection[J]. Computer Vision & Pattern Recognition,2013,9(4):3476-3483.
[2]CAO C, WENG Y, LIN S, et al. 3D shape regression for real-time facial animation[J]. Acm Transactions on Graphics, 2013, 32(4):96-96.
[3]CAO C, HOU Q, ZHOU K. Displaced dynamic expression regression for real-time facial tracking and animation[J]. Acm Transactions on Graphics, 2014, 33(4):1-10.
[4]SEEMAN E, NICKEL K, STIEFELHAGEN R. Head pose estimation using stereo vision for human-robot interaction[C].ICAFGR, 2004 Sixth IEEE International Conference on Automatic Face and Gesture Recognition. IEEE, 2004: 626-631.
[5]BREITENSTEIN M D, KUETTEL D, WEISE T, et al. Real-time face pose estimation from single range images[C]. Proc.IEEE Conf.Comput.Vis.Pattern Recognit, 2008:1-8.
[6]FANELLI G, GALL J, GOOL L V. Real time head pose estimation with random regression forests[C]. IEEE Conference on Computer Vision & Pattern Recognition, 2011:617-624.
[7]FANELLI G, WEISE T, GALL J, et al. Real time head pose estimation from consumer depth cameras[C].Pattern Recognition Dagm Symposium, Frankfurt/main, Germany, 2011:101-110.
[8]FANELLI G, DANTONE M, GALL J, et al. Random forests for real time 3D face analysis[J]. International Journal of Computer Vision, 2013, 101(3):437-458.
[9]PAPAZOV C, MARKS T K, JONES M. Real-time 3D head pose and facial landmark estimation from depth images using triangular surface patch features[C].IEEE Conference on Computer Vision and Pattern Recognition. 2015:4722-4730.
[10]SHAPIRA L, SHALOM S, SHAMIR A, et al. Contextual part analogies in 3D objects[J]. International Journal of Computer Vision, 2010, 89(2):309-326.
[11]SIDI O, KAICK O V, KLEIMAN Y, et al. Unsupervised co-segmentation of a set of shapes via descriptor-space spectral clustering[C].SIGGRAPH Asia Conference. 2011.
[12]KALOGERAKIS E, HERTZMANN A, SINGH K. Learning 3D mesh segmentation and labeling[J]. Acm Transactions on Graphics, 2010, 29(4):157-166.
[13]XIE Z, XU K, LIU L, et al. 3D shape segmentation and labeling via extreme learning machine[J]. Computer Graphics Forum, 2014, 33(5):85-95.
[14]GUO K, ZOU D, CHEN X. 3D mesh labeling via deep convolutional neural networks[J]. Acm Transactions on Graphics, 2015, 35(1):1-12.
[15]JOHNSON A E, HEBERT M. Using spin images for efficient object recognition in cluttered 3d scenes[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1999, 21(5):433-449.
[16]FROME A, HUBER D, KOLLURI R, et al. Recognizing objects in range data using regional point descriptors[J]. Lecture Notes in Computer Science, 2004.
[17]TOMBARI F, SALTI S, STEFANO L D. Unique signatures of histograms for local surface description[C].European Conference on Computer Vision Conference on Computer Vision. Springer-Verlag, 2010:356-369.
[18]ZAHARESCU A, BOYER E, VARANASI K, et al. Surface feature detection and description with applications to mesh matching[C]. IEEE Conference on Computer Vision & Pattern Recognition, 2009:373-380.
[19]ZAHARESCU A, BOYER E, HORAUD R. Keypoints and local descriptors of scalar functions on 2D manifolds[J]. International Journal of Computer Vision, 2012, 100(1):78-98.
[20]PAYSAN P, KNOTHE R, AMBERG B, et al. A 3D face model for pose and illumination invariant face recognition[C].IEEE International Conference on Advanced Video & Signal Based Surveillance. IEEE Computer Society, 2009:296-301.
[21]BREIMAN, LEO. Classification and regression trees[M].Classification and regression trees /. Chapman & Hall/CRC, 1984:17-23.
[22]MITCHELL. Machine learning[M]. McGraw-Hill, 2003.
(責任編輯:黃 健)
英文摘要Abstract:Aiming at the shortcomings of current research on semantic marking and segmentation of 3D face models, a 3D region labeling algorithm based on square tangent plane descriptors was proposed. This new descriptor was obtained by encoding the geometric information in the square area on the surface of 3D face mesh model. Then it was learnt by the random forest algorithm to realize the classification of the vertex on 3D face model, so as to identify and mark the eyebrows, eyes, nose, mouth and other regions. Simulation result can achieve a classification accuracy of 94.46%. The proposed descriptor has rotation, head pose, 3D model resolution invariance and is robust to noise. Experimental results show that the proposed method can effectively mark the 3D face model region.
英文關鍵詞Key Words: Semantic Marking; 3D Face; Random Forest; Square Tangent Plane Descriptor; Mesh Labeling
