融合用戶(hù)相似度與信任度的協(xié)同過(guò)濾推薦算法
2017-07-12 02:49:32蔣宗禮李慧
軟件導(dǎo)刊 2017年6期
蔣宗禮+李慧

摘要:傳統(tǒng)的協(xié)同過(guò)濾算法難以解決“稀疏性”和“冷啟動(dòng)”等問(wèn)題。鑒于此,提出一種融合用戶(hù)相似度和信任度的方法。首先根據(jù)用戶(hù)對(duì)共同項(xiàng)目的評(píng)分創(chuàng)建初始信任度,通過(guò)信任關(guān)系的傳遞規(guī)則,建立沒(méi)有直接信任關(guān)系的用戶(hù)之間的信任關(guān)系,然后融合用戶(hù)相似度與信任度,用于傳統(tǒng)的協(xié)同過(guò)濾推薦系統(tǒng),找出用戶(hù)的最近鄰居集,進(jìn)行項(xiàng)目的評(píng)分預(yù)測(cè),從而產(chǎn)生推薦列表。實(shí)驗(yàn)表明,改進(jìn)后的算法能有效提高系統(tǒng)推薦的準(zhǔn)確性。
關(guān)鍵詞:協(xié)同過(guò)濾;推薦系統(tǒng);信任度;用戶(hù)相似度
DOIDOI:10.11907/rjdk.162798
中圖分類(lèi)號(hào):TP312
文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1672-7800(2017)006-0028-04
0 引言
隨著互聯(lián)網(wǎng)的迅猛發(fā)展,信息過(guò)載問(wèn)題越發(fā)嚴(yán)重。為了緩解該問(wèn)題,在海量信息中找到真正所需的信息,Goldberg等[1]在1992年首次提出了協(xié)同過(guò)濾推薦算法。該算法利用用戶(hù)對(duì)項(xiàng)目的評(píng)分記錄,計(jì)算與目標(biāo)用戶(hù)有著相似興趣愛(ài)好的最近鄰居用戶(hù)集,并根據(jù)該鄰居集對(duì)目標(biāo)項(xiàng)目的評(píng)分情況,計(jì)算目標(biāo)用戶(hù)對(duì)目標(biāo)項(xiàng)目的預(yù)測(cè)評(píng)分值,最終把N個(gè)最高預(yù)測(cè)評(píng)分值的項(xiàng)目推薦給目標(biāo)用戶(hù)。協(xié)同過(guò)濾推薦算法簡(jiǎn)單高效,已經(jīng)成為目前最流行的個(gè)性化推薦算法之一。然而,隨著系統(tǒng)規(guī)模的擴(kuò)大,協(xié)同過(guò)濾算法會(huì)出現(xiàn)數(shù)據(jù)稀疏性(Data Sparsity)、冷啟動(dòng)(Cold Start)、可擴(kuò)展性等問(wèn)題,使得協(xié)同過(guò)濾算法容易受到這些問(wèn)題的困擾[2]。
針對(duì)稀疏性問(wèn)題,Sarwar等[3]提出使用矩陣奇異值分解的方法對(duì)評(píng)分矩陣進(jìn)行降維以減少稀疏性。鄧愛(ài)林等[4]提出首先根據(jù)基于項(xiàng)目的協(xié)同過(guò)濾算法預(yù)測(cè)部分項(xiàng)目評(píng)分,減少評(píng)分稀疏性,再根據(jù)基于用戶(hù)的協(xié)同過(guò)濾算法為用戶(hù)推薦。Herlocker等[5]將信任引入商品推薦系統(tǒng)中,該系統(tǒng)通過(guò)維護(hù)用戶(hù)對(duì)其他用戶(hù)的信任或不信任列表來(lái)建立用戶(hù)間的信任關(guān)系,基于信任的推薦系統(tǒng)認(rèn)為用戶(hù)會(huì)傾向于采取受信任的身邊用戶(hù)的建議,目前,基于信任的推薦系統(tǒng)已經(jīng)得到了廣泛研究與應(yīng)用。經(jīng)過(guò)驗(yàn)證,融合信任的推薦算法可以取得比傳統(tǒng)協(xié)同過(guò)濾算法更好的效果,尤其是在緩解用戶(hù)“冷啟動(dòng)”和數(shù)據(jù)“稀疏性”等方面[6-7]。
周林軻[8]提出無(wú)需用戶(hù)主動(dòng)地給出對(duì)其他用戶(hù)的信任評(píng)分,而是通過(guò)挖掘用戶(hù)間的社交信息從而預(yù)測(cè)出用戶(hù)的信任度。Victor P等[9]則利用信任網(wǎng)絡(luò)特征計(jì)算信任度,并構(gòu)建基于信任的推薦系統(tǒng)。林韶娟等[10]提出使用GenTrust算法,利用二值的信任網(wǎng)絡(luò)來(lái)預(yù)測(cè)擴(kuò)展信任網(wǎng)絡(luò), 提高了算法準(zhǔn)確率。
還有一些學(xué)者利用信任傳播的方法計(jì)算信任度,也起到了改善數(shù)據(jù)稀疏性的作用。文獻(xiàn)[11]提出了一種基于信任傳播的加權(quán)平均方法計(jì)算信任度。文獻(xiàn)[12]則是利用信任傳播過(guò)程中信任值的衰減,設(shè)計(jì)了3種信任度計(jì)算方法。
本文提出信任度的構(gòu)建方法是基于用戶(hù)共同評(píng)論的項(xiàng)目,而不依賴(lài)用戶(hù)主動(dòng)給出對(duì)其他用戶(hù)的信任評(píng)分。有共同評(píng)論項(xiàng)目的用戶(hù)之間可以直接計(jì)算出信任值,沒(méi)有共同評(píng)論項(xiàng)目的用戶(hù)之間雖然不存在直接信任關(guān)系,但是可以通過(guò)信任的傳遞,間接地建立信任關(guān)系,而間接信任關(guān)系的建立在一定程度上解決了數(shù)據(jù)稀疏問(wèn)題。最后將用戶(hù)信任度與相似度結(jié)合起來(lái),引入到傳統(tǒng)的協(xié)同過(guò)濾推薦系統(tǒng)中,找出用戶(hù)的最近鄰居集,進(jìn)行項(xiàng)目的評(píng)分預(yù)測(cè),從而產(chǎn)生推薦列表。實(shí)驗(yàn)表明,本文提出的相似度與信任度相融合的方式能有效地提高系統(tǒng)推薦的準(zhǔn)確性。
1 相似度計(jì)算
1.1 用戶(hù)模型建立
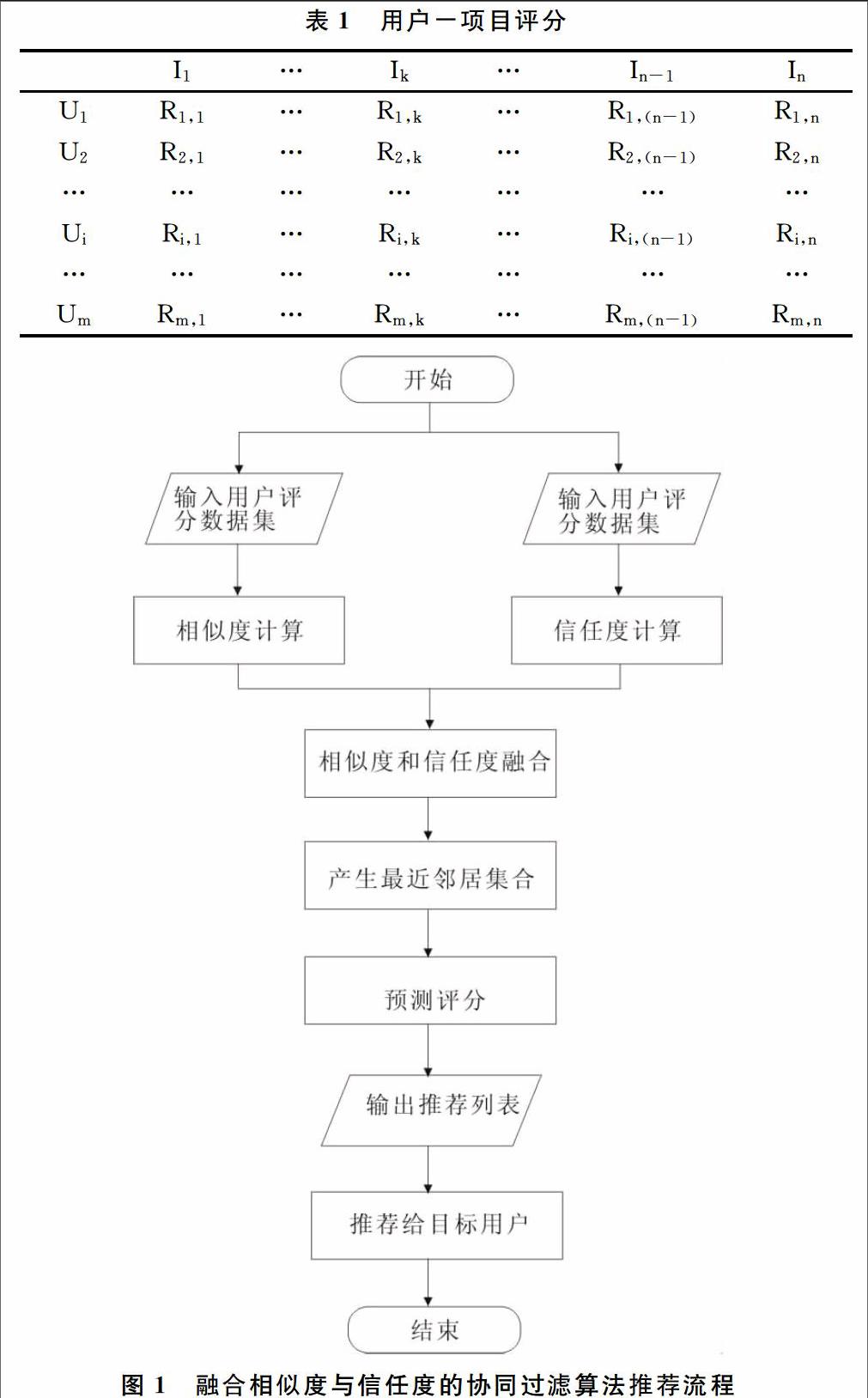
協(xié)同過(guò)濾推薦算法的根本出發(fā)點(diǎn)是任意用戶(hù)的興趣不是孤立存在的,也即假如兩個(gè)用戶(hù)對(duì)一些項(xiàng)目的評(píng)價(jià)比較相似,那么他們對(duì)其它項(xiàng)目的評(píng)價(jià)也會(huì)比較相似。因此,協(xié)同過(guò)濾推薦算法的核心是計(jì)算用戶(hù)之間的相似度,根據(jù)相似度找出最近鄰居集,通過(guò)他們對(duì)項(xiàng)目的評(píng)分,預(yù)測(cè)評(píng)分較高的項(xiàng)目并推薦給用戶(hù)。可以用一個(gè)m*n的用戶(hù)-項(xiàng)目評(píng)分矩陣A來(lái)對(duì)用戶(hù)相似度進(jìn)行建模。如表1所示,矩陣A中的m行代表m個(gè)用戶(hù),n列代表n個(gè)項(xiàng)目,第i行第j列元素Ri,j表示第i個(gè)用戶(hù)對(duì)第j個(gè)項(xiàng)目的評(píng)分(如果用戶(hù)對(duì)項(xiàng)目沒(méi)有進(jìn)行評(píng)分,則Ri,j=0)。
計(jì)算得到用戶(hù)對(duì)項(xiàng)目的預(yù)測(cè)評(píng)分值后,將預(yù)測(cè)的評(píng)分值從大到小排序,將評(píng)分值大于指定閾值或前N個(gè)評(píng)分最高的項(xiàng)目推薦給目標(biāo)用戶(hù)。
融合相似度與信任度的協(xié)同過(guò)濾推薦算法的推薦過(guò)程如圖1所示。
4 實(shí)驗(yàn)
本文提出了融合相似度與信任度的協(xié)同過(guò)濾算法,為了證明本方法的有效性,做了一系列實(shí)驗(yàn),其中也包括對(duì)傳統(tǒng)基于相似度的協(xié)同過(guò)濾算法相關(guān)實(shí)驗(yàn)。
4.1 數(shù)據(jù)集選取
本文所有實(shí)驗(yàn)均在公開(kāi)的MovieLens數(shù)據(jù)集上進(jìn)行,該數(shù)據(jù)集包含了943位用戶(hù)對(duì)1 682部電影的100 000條評(píng)分記錄,每個(gè)用戶(hù)至少有20條評(píng)分記錄。評(píng)分有5個(gè)等級(jí),用1~5的整數(shù)表示,數(shù)值越大表示用戶(hù)對(duì)該電影的喜愛(ài)程度越高。
將整個(gè)MovieLens數(shù)據(jù)集進(jìn)一步劃分為訓(xùn)練集和測(cè)試集。為此,引入變量x作為測(cè)試集占整個(gè)數(shù)據(jù)集的百分比。本文選用x=0.2,即在整個(gè)數(shù)據(jù)集中,訓(xùn)練集占80%,測(cè)試集占20%,即訓(xùn)練集為100 000*80%=80 000條數(shù)據(jù),測(cè)試集為100 000*20%=20 000條數(shù)據(jù)。
4.2 評(píng)價(jià)標(biāo)準(zhǔn)
本文采用度量標(biāo)準(zhǔn)平均絕對(duì)誤差( MAE) 作為評(píng)價(jià)標(biāo)準(zhǔn)來(lái)評(píng)價(jià)推薦系統(tǒng)的推薦效果。在推薦算法研究中,MAE是最常用也是應(yīng)用最廣泛的評(píng)價(jià)指標(biāo)。MAE的基本思想是計(jì)算系統(tǒng)對(duì)項(xiàng)目的預(yù)測(cè)評(píng)分與用戶(hù)對(duì)項(xiàng)目的實(shí)際評(píng)分之間的平均絕對(duì)偏差,MAE值越小表示推薦系統(tǒng)的推薦精度越高。MAE的計(jì)算公式如下所示:
4.3 結(jié)果分析
在計(jì)算信任度矩陣時(shí),λ值的選取以及信任傳遞的深度MPD會(huì)影響整個(gè)信任矩陣的計(jì)算,因此針對(duì)這兩個(gè)重要參數(shù)進(jìn)行了實(shí)驗(yàn),找出最佳的參數(shù)組合,利用參數(shù)組合對(duì)各種不同的推薦方案進(jìn)行實(shí)驗(yàn)比較。
首先,對(duì)λ的取值進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖2所示。
圖3中的Sim&Trust表示將相似度與信任度相結(jié)合的推薦方案,Trust表示只利用信任度的推薦方案。實(shí)驗(yàn)結(jié)果是在MPD=2,最近鄰居數(shù)量為20的前提下所得出。從實(shí)驗(yàn)結(jié)果中可以看到,當(dāng)λ值在0~0.1時(shí),推薦方案的MAE值比較穩(wěn)定,在0.05時(shí),Sim&Trust推薦方案取得最小值,大于0.1后MAE有上升趨勢(shì)。因此,可以認(rèn)為0.05對(duì)于系統(tǒng)而言是一個(gè)比較好的參數(shù),在后面的推薦系統(tǒng)對(duì)比實(shí)驗(yàn)中,也是將λ值設(shè)置為0.05。
確定λ的取值之后,對(duì)信任傳遞深度進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如圖3所示。
實(shí)驗(yàn)中一共設(shè)置了5組對(duì)比實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果是在λ=0,最近鄰居數(shù)量為20的前提下所得出。
當(dāng)信任傳遞的深度小于3時(shí),隨著MPD的增加,MAE的值逐漸減小,當(dāng)超過(guò)3之后趨于平穩(wěn),考慮到算法的復(fù)雜度和運(yùn)行時(shí)間,認(rèn)為MPD取值為3比較合適。
當(dāng)決定信任度矩陣的λ和信任度最大傳播深度MPD的值確定后,對(duì)傳統(tǒng)協(xié)同過(guò)濾算法的3種計(jì)算相似度的方法以及基于信任度的協(xié)同過(guò)濾算法中只有信任度和信任度與相似度相結(jié)合的方法進(jìn)行實(shí)驗(yàn)比較。實(shí)驗(yàn)結(jié)果如圖4所示。
從圖4可以看出,本文提出的相似度與信任度相融合的方法在MAE表現(xiàn)來(lái)看,其效果優(yōu)于傳統(tǒng)推薦方案。從鄰居數(shù)量的選取對(duì)MAE的影響來(lái)看,隨著鄰居數(shù)量的增加,除Pearson外,所有推薦系統(tǒng)都會(huì)有性能上的提升。從現(xiàn)實(shí)意義上講,給你提建議的人越多,你值得信任的人就可能越多,綜合給出的推薦效果就會(huì)越好。但并不是鄰居越多越好,到達(dá)一定程度,對(duì)實(shí)驗(yàn)結(jié)果的影響就會(huì)越來(lái)越不明顯。如圖4所示,當(dāng)最近鄰居的數(shù)量超過(guò)100之后,MAE的值趨于穩(wěn)定,那是因?yàn)猷従拥竭_(dá)一定程度后,新擴(kuò)展的鄰居與目標(biāo)用戶(hù)相關(guān)性太低,以至于無(wú)法產(chǎn)生影響。
5 結(jié)語(yǔ)
融合用戶(hù)相似度和信任度的方法選擇余弦相似度和Jaccard相似度相結(jié)合的方式計(jì)算用戶(hù)間的相似度,在計(jì)算用戶(hù)信任度時(shí)分為直接信任度和間接信任度。之后將信任度和相似度融合,通過(guò)融合后的用戶(hù)相關(guān)度找出與某用戶(hù)相關(guān)性最強(qiáng)的用戶(hù)群作為該用戶(hù)的鄰居集,用于傳統(tǒng)的協(xié)同過(guò)濾推薦系統(tǒng)中,找出用戶(hù)的最近鄰居集,進(jìn)行項(xiàng)目的評(píng)分預(yù)測(cè)。實(shí)驗(yàn)表明,改進(jìn)后的算法能有效提高系統(tǒng)推薦的準(zhǔn)確性。鑒于相同地區(qū)相似年齡的同性人群對(duì)事物的觀(guān)點(diǎn)可能類(lèi)似的假設(shè),下一步的工作是,將用戶(hù)的個(gè)人信息加入到相似度的構(gòu)建之中,希望可以進(jìn)一步提高推薦系統(tǒng)的準(zhǔn)確性。
參考文獻(xiàn):
[1]D GOLDBERG,D NICHOLS,D TERRY.Using collaborative filtering to weave an information tapestry[C].Communications of the ACM,1992.
[2]范永全,杜亞軍.一種融合用戶(hù)偏好與信任度的增強(qiáng)協(xié)同過(guò)濾推薦方法[J].西華大學(xué)學(xué)報(bào),2015,34(4):8-12.
[3]B SARWAR,G KARYPIS,J KONSTAN.Item-based collaborative filtering recommendation algorithms[C].In Proceedings of the 10th International Conference on World Wide Web,New York,USA,2001:285-295.
[4]鄧愛(ài)林,朱揚(yáng)勇,施伯樂(lè).基于項(xiàng)目評(píng)分預(yù)測(cè)的協(xié)同過(guò)濾推薦算法[C].軟件學(xué)報(bào),2003,14(9):1621-1628.
[5]MASSA P,AVESANI P.Trust metrics in recommender systems[M].Computing with Social Trust.London:Springer,2009:259-285.
[6]U SHARDANAND,P MAES.Social information filtering: algorithms for auto mating "word of mouth"[C].in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems,Denver,Colorado,USA,1995:210-217.
[7]D GOLDBERG,D NICHOLS,D TERRY.Using collaborative filtering to weave an information tapestry[C].Communications of the ACM,1992.
[8] 周林軻.電子商務(wù)中基于信任的推薦算法研究[D].長(zhǎng)沙:湖南大學(xué),2011.
[9]VICTOR P,CORNELIS C,TEREDESAI A M,et al.Whom should I trust? the impact of key figures on cold start recommendations[C].Proceedings of the 2008 ACM Symposium on Applied Computing,2008:2014-2018.
[10]林韶娟,陶曉鵬.基于二值信任網(wǎng)絡(luò)的推薦算法改進(jìn)[J].計(jì)算機(jī)應(yīng)用與軟件,2012,29(12):157-160.
[11]CHAKRABORTY P S,KARFORM S.Designing trust propagation algorithms based on simple multiplicative strategy for social networks[J].Procedia Technology,2012:534-539.
[12]SCHAFER J B,KONSTAN J A,RIED J.E-commerce recommendation applications[J].DataMining and Konwledge Discovery,2001,5(1-2):115-153.
(責(zé)任編輯:孫 娟)
