基于云計算平臺Hadoop的線路參數并行辨識算法研究
2017-07-12 18:10:03左劍向萌張可人胡迪軍鄧小亮蔡如昕張瑞國網湖南省電力公司電力科學研究院湖南長沙40007國網湖南省電力公司湖南長沙40004中國科學院深圳先進技術研究院廣東深圳58055
湖南電力 2017年3期
左劍,向萌,張可人,胡迪軍,鄧小亮,蔡如昕,張瑞(.國網湖南省電力公司電力科學研究院,湖南長沙40007;.國網湖南省電力公司,湖南長沙40004;.中國科學院深圳先進技術研究院,廣東深圳58055)
基于云計算平臺Hadoop的線路參數并行辨識算法研究
左劍1,向萌1,張可人1,胡迪軍2,鄧小亮2,蔡如昕3,張瑞3
(1.國網湖南省電力公司電力科學研究院,湖南長沙410007;2.國網湖南省電力公司,湖南長沙410004;3.中國科學院深圳先進技術研究院,廣東深圳518055)
隨著作為電網動態監測技術平臺的廣域量測系統(WAMS)在電網的應用普及,電網運行人員對于電網動態變化有了實時監測與分析的手段,但WAMS所產生的海量數據以及對于分析平臺的高效率要求是WAMS應用的一大挑戰。本文深入研究了基于Hadoop云計算平臺的線路參數并行辨識算法,并提出算法的設計思路以及實現方法,為高效利用WAMS數據辨識線路參數給出了解決方法。對比實驗證明基于云計算平臺Hadoop的線路參數并行辨識算法大大提高線路參數辨識算法的計算效能,適合處理該應用中的WAMS海量數據。
Hadoop平臺;云計算;廣域量測系統;線路參數辨識
隨著電網規模越來越大,結構越來越復雜,電網運行人員對于電網的運行狀態以及特性的把握也越來越依賴于電網的實時監測和分析〔1-2〕。作為電網動態監測技術平臺,廣域測量系統(Wide-Area Measurement System,WAMS)可對全網各個站點主要數據進行實時、同步以及高速率采集,從而實現對電力系統狀態以及參數的實時監測,為電網運行人員掌握電網動態運行狀態變化提供技術手段〔3-5〕。以電力系統線路參數為例,傳統上線路參數以線路投運后實測參數作為運行以及電網仿真參數,而實際運行中隨著運行場景的變化線路參數是會發生動態變化,尤其是在線路發生故障或在惡劣運行環境以及氣候條件下。傳統電網運行所依賴的能量管理系統是無法掌握上述電網參數變化等動態信息的,而通過WAMS中的同步相量測量裝置(Phasor Measurement Unit,PMU)可以同步實時測量線路兩端電流、電壓相量,實現對線路參數的動態辨識〔6〕。
雖然WAMS相對于能量管理系統(Energy Management System,EMS)具有能監測系統動態運行狀態的優點,但是WAMS的應用也存在以下問題〔7〕:
1)數據量大,冗余多。由于WAMS數據采集速率可以達到25幀/s或50幀/s,是EMS數據采集速率的100~200倍,相應的存儲的數據量也是EMS的上百倍,在系統穩態過程中,大量的WAMS數據是冗余數據。數據量大,冗余多給存儲和分析帶來困難。
2)現有WAMS數據處理分析平臺仍然采用常規的數據存儲與管理方法,大量采用價格昂貴的大型服務器以及磁盤陣列,系統擴展性差、成本高。
3)大量基于WAMS的高級應用算法仍然基于常規的數據,依賴于高性能服務器的串行計算能力,計算效率低。
因此,針對WAMS的海量數據,急需引入新的計算技術以解決數據冗余、數據挖掘算法效率低等問題。
1 Hadoop云計算平臺
云計算〔8〕作為一種針對大規模數據處理的新興產物,適合于對電網WAMS海量數據的存儲與應用。其基本原理是將存儲和計算的服務分布在大量分布式計算機上,用大量廉價的分布式計算機代替現有的高性能服務器,用分布式并行算法代替現有的串行算法以提高效率。在現有的云計算平臺中,Hadoop作為一個比較成熟且應用廣泛的系統,具有擴容能力強、成本低、效率高以及可靠性好的優點,其主要由兩部分組成:分布式文件系統(HDFS)〔9〕和MapReduce計算模型〔10〕。
HDFS采用Master/slave架構。一個HDFS集群由一個管理節點(Namesnode)和一定數量的數據節點(Datanode)組成,每個節點均可以是1臺普通PC。管理節點負責文件系統的管理以及客戶端對于文件的訪問,數據節點負責數據塊(block)的管理以及處理。在使用上,HDFS與單機的文件系統非常類似,同樣可以創建目錄,創建、復制、刪除文件,查看文件內容等。但其底層實現上是把文件切割成塊,然后把這些數據塊存儲于不同數據節點上,每個數據塊還可以復制若干份,存儲于不同的數據節點上,以達到容錯的目的。
MapReduce是一種高效分布式并行編程模型〔10〕。其主要的工作流程:
1)輸入(Input):對輸入數據集分塊,返回若干個數據塊。提供數據集讀取接口(RecordReader),規定如何處理每一個數據塊的每一行數據,經過上述處理獲得輸入鍵值對<key,value>。
2)映射(Map):調用用戶定義的Map函數,對輸入的每一組鍵值對<key,value>進行處理,同時生成并輸出一批新的中間鍵值對<key′,value′>,輸入輸出鍵值對的類型可能不同。
3)數據整理(Shuffle):Map和Reduce操作可在不同的數據節點上,在將Map輸出的鍵值對傳輸給Reduce操作中需要消耗一定的網絡以及磁盤資源,是影響效率的關鍵。因此,為了減少不必要的網絡傳輸以及磁盤輸入輸出操作,需要對Map輸出的鍵值對在內存中進行數據整理,包括根據key的排序(Sort)與合并(Combine)等,上述數據整理操作稱之為shuffle。
4)歸約(Reduce):遍歷經過shuffle整理后的中間數據,對每一個唯一的key,執行用戶自定義的Reduce函數。輸入參數是<key,{list of values}>,輸出的是新的<key,value>鍵值對。
5)輸出(Output):將Reduce輸出的結果輸出到制定位置。上述就是一個典型的MapReduce計算過程。
2 基于Hadoop的并行線路參數識別算法
輸電線路模型有分布式參數模型和集中參數π形等效模型,以最常用的集中參數π形等效電路為例,圖1為輸電線路拓撲結構。
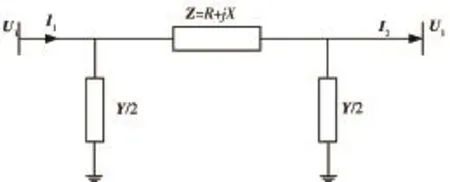
圖1 輸電線路結構等效模型
如圖1所示,PMU安裝在線路的兩端,可以直接同步測量線路兩端的電壓和電流相量,分別為U1,U2,I1,I2,待求的參數為線路阻抗Z=R+j X以及線路對地導納Y。建立線路兩端電流電壓關系:
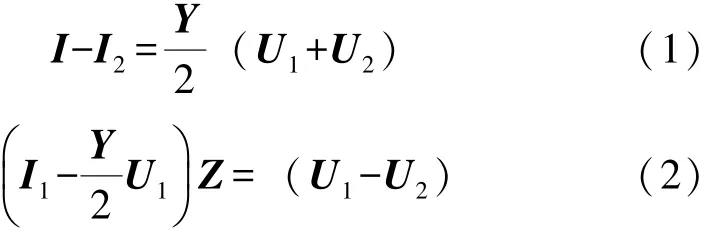
因此,
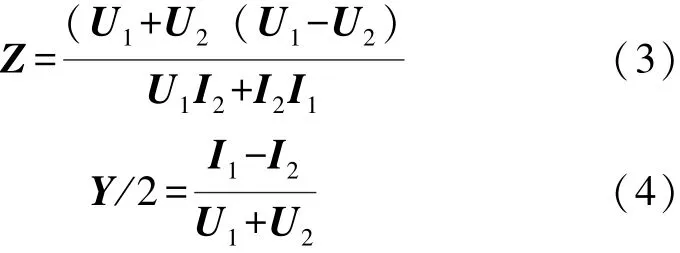
通過(3)和(4)可由線路兩端的PMU測量的電流電壓相量直接求得線路各相的阻抗和對地導納。分析上述計算線路參數串行算法,可以將計算阻抗和對地導納的運算步驟進行分解,分成(U1+U2),(U1-U2),(I1-I2)等“原子”運算,并將上述“原子”運算通過MapReduce進行并行化處理。下面分別描述對應的Map,Combine以及Reduce函數設計。
2.1 M ap函數設計
Map函數輸入為默認的<key,Value>鍵值對格式,其中key包括以下子鍵:Timestamp(時間戳)、LineName(線路名稱)、Phase(A,B,C中某一相序)。而Value包括以下子項:OptType(運算類型)、Operand1(運算數一)、Operand2(運算數二)。

所對應的Map函數的偽代碼為:
Map(<key,value>,<key′,value′>
{
從value中解析出運算的類型以及運算數,分別記為optType、operand1以及operand2;
Case optType
{
Opt1:attr=A1,res=operand1+operand2;
//(U1+U2)運算
Opt2:attr=A2,res=operand1-operand2;
//(U1-U2)運算
Opt3:attr=B1,res=operand1?operand2;
//(U1?I2)運算
Opt4:attr=B2,res=operand1?operand2;
//(U2?I2)運算
Opt5:attr=C1,res=operand1+operand2;
//(I1+I2)運算
}
key′=key;
value′={attr,res};
輸出<key′,value′>;
}
為減少數據傳輸量和通訊代價,在Map操作后,對輸出的鍵值對進行合并操作,首先通過key中的Timestamp排序并將具有相同鍵(key)的輸出項映射到同一個合并操作中。在Combine函數中對具有相同鍵的輸出項進行合并。
2.2 Combine函數設計
Combine函數對輸入的鍵值對<key,value>根據鍵進行合并。函數偽代碼為:
Combine(<key,value>,<key′,value′>)
{
初始化一個數組s,用于已經合并后的鍵值對
pos=-1;//數組中最后一個鍵值對所存儲的位置
For i=0 to k-1 do{
if<key,value>[i].key存于在數組s中{
s[j].value={s[j].value,<key,value>[i].value};
//將<key,value>[i].value與s中key相同的鍵值對進行合并
}
else{
pos=pos+1;//在數組中存入一個新的鍵值對
s[pos]=<key,value>[i];
}
}//For
輸出數組s作為<key′,value′>;
}
2.3 Reduce函數設計
Reduce函數輸入的<key,value>是Combine函數輸出的中間結果,對同一個鍵(key)的數值(value)進行歸約,并輸出鍵值對<key′,value′>作為結果。函數偽代碼:
Reduce<key,value>,<key′,value′>)
{
初始化一個數組s,用于已經合并后的鍵值對
For i=0 to k-1 do{
將<key,value>[i].value根據attr解析為A1,A2,B1,B2以及C1;
z=(A1?A2)/(B1+B2);
y_half=C1/A1;
s[i].key=<key,value>[i];
s[i].value={z,y_half};
}
輸出數組s作為<key′,value′>;
}
根據Reduce的輸出結果,得到線路不同時間點A,B以及C相的阻抗以及對地導納值。
3 實驗以及結果分析
3.1 實驗平臺以及數據
本文中對在單臺計算機上線路參數辨識串行算法與多臺計算組成Hadoop平臺上并行算法進行計算效率比較。上述計算機均為四核2.33 GHz的CPU,內存均為2 GB。Hadoop平臺由4臺計算機組成,其中1臺為管理節點,其余3臺為計算節點,Hadoop版本為2.6.4。
實驗數據采用15條線路兩端PMU數據,每條線路PMU數據時間長度均為0.5 h,速率為25幀/s。分別在上述單臺計算機以及Hadoop并行計算平臺上對比計算線路三相動態阻抗以及對地導納參數。
3.2 實驗結果
單臺計算機上計算用時184 s,Hadoop平臺上用時約59 s。在4臺計算機組成的Hadoop平臺上采用并行算法的計算效率約為單臺計算機上串行算法的3倍,并且兩者計算結果一致。實驗結果表明采用云計算平臺Hadoop的線路參數并行辨識算法大大提高對WAMS海量數據的分析效能,增加Hadoop計算平臺規模將進一步提升算法計算效率。
3.3 應用展示
圖2為通過上述線路參數辨識并行算法計算得到某條220 kV輸電線路不同時間段對地電納參數動態辨識值,對比可以看到圖2(a)中線路三相對地電納參數有明顯的“尖刺”。由于輸電線路對地電納參數值對于線路電暈放電十分敏感,雨、霧或大濕度條件下易于在導線表明形成水滴,引起導線表面電場畸變,降低導線起暈電壓從而發生電暈放電,而晴好天氣下輸電線路一般不會發生電暈放電〔12〕。因此,懷疑圖2(a)中數據對應于線路處于雷雨等惡劣天氣下。能量管理系統中線路雷擊跳閘記錄證實上述猜測,線路參數動態變化記錄了線路在雷擊跳閘前的電暈放電。因此,上述例子證明通過實時辨識并監測線路參數,可以準確的反映當前線路的運行狀態,在線路遭遇雷雨、山火等惡劣運行條件時可以作為提供給運行人員的早期預警參考。

圖2 某條220 kV線路三相對地電納參數辨識值
4 總結
本文對基于云計算平臺Hadoop的線路參數并行辨識算法進行了深入研究。首先簡要介紹了WAMS應用中存在的問題以及采用云計算平臺的必要性,并介紹了Hadoop平臺的基本組成,包括HDFS構成以及MapReduce的主要功能模塊,然后給出了基于Hadoop云計算平臺線路參數辨識并行算法的主要設計思路以及各主要模塊的構成與實現。最后,通過對比實驗證實了基于Hadoop云計算平臺的線路參數并行算法在計算效能上大大優于單機上線路辨識串行算法,并結合實際的應用實例展示了在成熟的云計算平臺上WAMS應用的前景。
〔1〕湯涌.基于響應的電力系統廣域安全穩定控制〔J〕.中國電機工程學報,2014,34(29):5041-5050.
〔2〕金基圣,牛夏牧.電網動態穩定實時監測系統〔J〕.電力系統自動化,1999,23(10):17-19.
〔3〕宋方方,畢天姝,楊奇遜.基于WAMS的電力系統受擾軌跡預測〔J〕.電力系統自動化,2006,30(23):27-32.
〔4〕肖永,金小明,付超,等.基于廣域量測系統的暫態失穩判別方法適應性研究〔J〕.南方電網技術,2015,9(3)81-86.
〔5〕劉兆燕,江全元,曹一家.基于廣域測量系統的快速暫態穩定預測方法〔J〕.電力系統自動化,2007,31(21):1-4.
〔6〕趙菲,焦彥軍,王鐵強.基于WAMS的輸電線路參數在線辨識的研究〔J〕.電力科學與工程,2011,27(8):15-19.
〔7〕曲朝陽,朱莉,張士林.基于Hadoop的廣域測量系統數據處理〔J〕.電力系統自動化,2013,37(4):92-97.
〔8〕陳康,鄭緯.云計算:系統實例與研究現狀〔J〕.軟件學報,2009,20(5):1337-1348.
〔9〕Ghemawat S,Gobioff H,Leung S.The google file system〔J〕. SACM SIGOPSOperating System Review,2003,37(5):29-43.
〔10〕Dean J,Ghemawat S.Mapreduce:simplified data processing on large clusters〔C〕.Proceedings of Operation System Design and Implementation.San Francisco,CA,2004:137-150.
〔11〕李剛,焦譜,文福拴,等.基于偏序約簡的智能電網大數據預處理方法〔J〕.電力系統自動化,2016,40(7):98-106.
〔12〕黃宏新,劉士源.交流電暈放電特性的影響因素研究〔J〕.河北電力技術,2010,29(3):42-45.
Study of Parallel Line Parameter Identification Algorithm Based on Hadoop Platform
ZUO Jian1,XIANGMeng1,ZHANG Keren1,HU Dijun2,DENG Xiaoliang2,CAIRuxin3,ZHANG Rui3
(1.State Grid Hunan Electric Power Corporation Research Institute,Changsha 410007,China;2.State Grid Hunan Electric Power Corporation,Changsha 410004,China;3.Shenzhen Institute of Advanced Technology,Chinese Academy of Sciences,Shenzhen 518055,China)
As the power grid dynamic monitoring platform,the widely use ofWide-area Measurement System(WAMS)will help the grid operatormonitor and analyze the dynamic changes in power grid operation.However,the huge dataset generated by WAMS and requirement of high efficient analysis platform are the challenges of WAMS applications.This paper has conducted thorough study of the parallel line parameter identification algorithm based on Hadoop platform,and provided the parallel algorithm design and implementation methods.It provides a efficient solution for line parameter identification using WAMS data.The comparison test demonstrates that the Hadoop platform based parallel line parameter identification algorithm will boost the efficiency greatly,and it is suitable for processing huge datasets.
Hadoop platform;cloud computing;WAMS;line parameter identification
TM715
B
1008-0198(2017)03-0007-04
左劍(1980),男,博士,高級工程師,主要從事電力系統分析以及廣域測量應用研究。
向萌(1988),女,碩士,工程師,主要從事電力系統仿真分析工作。
張可人(1982),男,本科,工程師,主要從事電力系統分析和規劃研究。
胡迪軍(1976),男,碩士,高級工程師,主要從事電力系統自動化研究。
鄧小亮(1983),男,碩士,工程師,主要從事電網調度運行以及新能源并網研究。
10.3969/j.issn.1008-0198.2017.03.002
2016-11-14 改回日期:2016-12-08
