基于抽樣的不確定圖k最近鄰搜索算法
2017-07-10 10:27:26張偉
計算機應用與軟件 2017年6期
關鍵詞:定義
張 偉
(東北大學計算機科學與工程學院 遼寧 沈陽110819)
基于抽樣的不確定圖k最近鄰搜索算法
張 偉
(東北大學計算機科學與工程學院 遼寧 沈陽110819)
在諸如生物網絡或社交網絡等各種由不確定數據組成的網絡中,不確定圖是一種十分重要和普遍使用的數學模型。由于不確定圖中計算兩點連通概率問題是#P完全問題,其k最近鄰查詢問題要比確定圖復雜得多,并且與“距離”的定義相關。采用“最短距離”作為距離定義,討論了在不確定圖是加權圖的情況下,求解k最近鄰搜索問題(k-NN問題)。為了克服計算兩點連通概率帶來的時間指數爆炸問題,提出了一個基于Dijkstra算法的抽樣k-NN查詢算法,研究了其收斂性和收斂速度,同時通過實驗驗證了所提出的方法效率優于kMinDist方法并且具有很高的查全率。
人工智能 不確定圖 概率圖 生物網絡 k-NN 抽樣技術
0 引 言
隨著云計算和大數據時代的到來,由于數據獲取存在噪聲、網絡傳送存在誤差、數據使用顆粒度差異等各種原因,使得我們面臨大量不確定數據的處理問題。在各種不確定數據組成的網絡(諸如生物網絡、社交網絡)中,不確定圖(或稱概率圖)是一種十分重要和普遍使用的數學模型,對不確定圖的搜索問題,也成為當前大數據研究當中的一個研究熱點[1-3]。
在實際應用中,不確定圖搜索問題十分常見。例如,在社交網絡中,用節點表示用戶,用邊表示好友關系,則好友之間的影響程度就可由邊上的概率來表示,從而構成一個不確定圖;在城市的路網中,用節點表示地點,用邊表示街道,則街道是否擁堵就可由邊上的概率來表示,亦構成不確定圖。不確定圖的搜索問題,通常是“在社交網絡中,與張三關系最密切的三個人是誰?”、“在城市路網中,從地點A到地點B最通暢的三條路徑是哪些路徑?”。這些問題(實質是k-NN問題)在確定圖中是容易解決的,但是對不確定圖而言它們就變得十分復雜[4-5]。
圖1所示的是一個簡單的不確定圖,其中第一條邊線上的括號(1∶0.5)表示節點A到節點B的長度是1,該邊的存在概率是0.5,其他邊也使用類似的表示。在可能世界模型下,圖1的一個可能世界,亦稱可能圖例,如圖1(b)所示,該可能世界的概率是0.5×0.3×0.7×0.8×(1-0.4)×(1-0.6)=0.02。
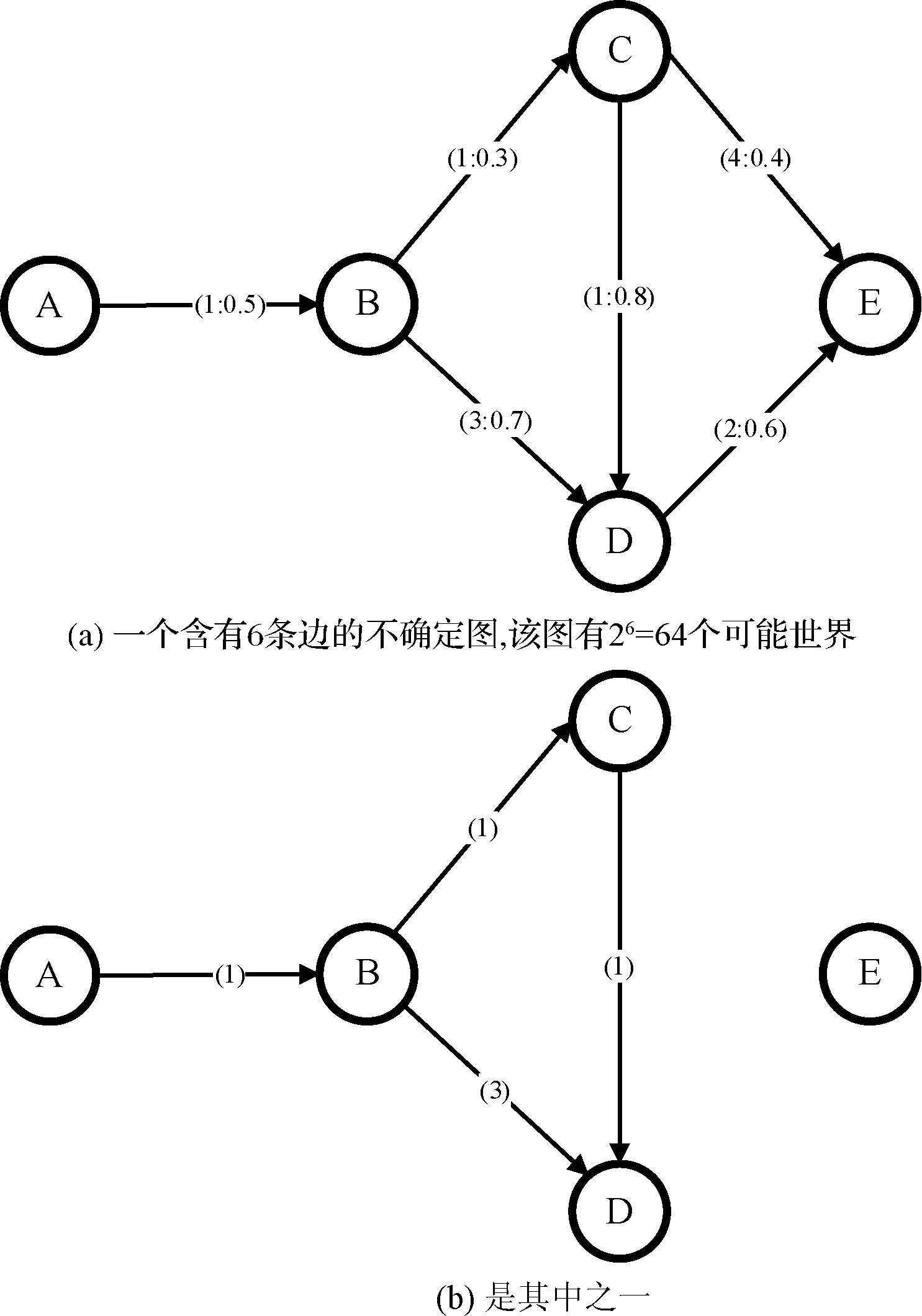
圖1 一個簡單的不確定圖
對于圖1(a),距離A點最近的兩個節點,則有多種可能的答案:(1)按照文獻[1]所定義的以實際距離(路徑權值)占主導考慮因素的距離定義,答案是{B,C},因為B和C距A較近;(2)按照文獻[2]所定義的最大可靠性距離定義(某些文獻稱之為概率可達性),答案是{B,D},其中節點A和B連通的概率是0.5,節點A和D連通的概率是0.5×(0.7+(0.3×0.8)-0.7×(0.3×0.8))=0.386,即A和B連通并且B和D至少有一條路徑連通的概率。而節點A和C連通的概率則是0.5×0.3=0.15,故不選擇C。注意,在最大可靠性距離中沒有考慮路徑的權值(長度)[6-8]。
由此可見,不確定圖的近鄰查詢問題,比確定圖復雜得多,并且與“距離”的定義相關。目前被研究者采納比較多的“距離”定義主要有五種:(1)中位距離,其含義是:對于兩個節點s和t,中位距離是一個最大的數字D,使得s到t的最短距離小于等于D的所有可能圖例的概率之和不超過50%;(2)多數距離,其含義是:對于兩個節點s和t,多數距離是一個數字d,使得s到t的最短距離恰好等于d的所有可能圖例的概率之和最大;(3)期望可信距離,其含義是:兩個節點s和t在所有可能圖例中最短路徑的期望長度;(4)最短距離,其含義是:兩個節點s和t在所有可能圖例中最短路徑(即,在所有可能圖例中的最短路徑當中長度最小者)的長度,注意,該距離定義優先考慮路徑的權值,路徑的概率起輔助作用(詳見下小節k-NN問題);(5)概率可達性距離,其含義是:兩個節點s和t連通的概率[8-9]。
文獻[10]以生物信息學中的蛋白質交互網和作者合作網絡為背景,提出了適用于中位距離、多數距離和期望可信距離的k-NN查詢算法。該算法使用了抽樣和剪枝技術,實現了較好的搜索效率[10-11]。文獻[10]提出了一個基于隨機抽樣的、可快速估計兩點連通概率的算法,該算法也是面向最大可靠性距離的,如進行一定延展,可以擴展到不確定圖的k-NN查詢問題中。
文獻[12]介紹了在一個有障礙物體的空間內查詢一個特定點可見概率最大的k-NN近鄰的算法。該算法是面向最大可靠性距離的,使用了剪枝技術和近似采樣技術來提高搜索效率[12-13]。
然而,在很多不確定數據組成的網絡應用中,上述的第4種距離定義(即“最短距離”)是最適合的距離定義。例如,在社交網絡中有一類很常用的問題是好友推薦問題:當一個社交網絡用戶A向系統提出好友推薦要求時,怎么給他推薦好友呢?一個經常的做法是,考察A的好友B、C有沒有共同的好友;如果B、C有共同的好友D、E,那么D、E很可能也是A感興趣的人,就可以推薦給A。當D、E距A相等且只能給A推薦一個好友時,優先選擇D、E中與A連通概率大的節點。這里使用的“距離”定義就是以路徑長度為主導以概率為輔助的最短距離定義。文獻[1]根據社交網絡的這種特點,提出了最短距離的定義,并給出了一個k-NN查詢算法。由于該算法是基于可能世界模型的樸素路徑概率計算思想的,故效率受到一定限制。雖然文獻[1]對其算法做了“公用邊”優化,在一定程度上推遲了時間復雜度拐點的出現時間,但不能避免時間復雜度指數爆炸。
因為最短距離在社交網絡中好友推薦類問題及相似的問題中有較好的應用意義,并且可以得到精確的計算結果,本文采用這個距離定義,并討論在不確定圖是加權圖的情況下,求解k最近鄰的查詢問題。提出了一個基于Dijkstra算法的抽樣k-NN算法,同時通過實驗驗證了本文所提出的方法效率優于文獻[1]的kMinDist方法。
1 不確定圖模型
雖然人們根據所探討的具體問題提出過很多與不確定圖相關的問題定義,但是以下概念是核心的、共同的[14-16]。
定義1(不確定圖) 一個不確定圖可由四元組G=(V,E,P,W)表示,其中V和E分別表示G含有的節點集和邊集,變量P表示邊上的概率集合,即P(e)表示邊e∈E的存在概率,變量W表示邊上的權值集合,即W(e)表示邊e∈E的權值,我們約定W的值均為正整數。
定義2(可能世界模型) 對于一個不確定圖G,我們按照概率P對G的邊集合E進行一次采樣得到邊子集E’?E,則稱由E’及V、W構成的確定圖G’=(V,E’,W)為不確定圖G的一個可能世界。
定義3 (最短距離) 對于一個不確定圖G=(V,E,P,W)中的任意兩個節點s和t,我們稱s和t的最短距離是在所有可能圖例中最短路徑(即在所有可能圖例的所有連通s和t的最短路徑當中長度最小者)的長度[1],記為dL(s,t)。本定義采用了文獻[1]的最短距離定義。
對于圖1(a)而言,dL(A,D)=3。
與文獻[1]相同,我們定義k-NN查詢(即kMinDist查詢)為:對一個源點s,找到它的k個最近鄰節點,當其中長度最大的節點多于查詢所需時,用路徑概率PL(s,t)決定取舍(PL(s,t)路徑概率是含有該(最短)路徑的所有圖例的概率之和)。這個k-NN定義意味著k-NN查詢中距離不是最大的節點應直接進入查詢結果集中,其他則須用概率決定取舍。
2 基于Dijkstra算法的k-NN查詢算法
按照上述的距離定義,我們提出了一個基于Dijkstra算法并采用抽樣技術估計連通概率的k-NN查詢算法。首先,給出一個基礎的k-NN算法,它采用兩點連通概率的定義精確計算路徑概率PL(s,t);當然基礎算法存在指數爆炸的缺點。其次,我們給出了一個對基礎算法的改進算法:它采用抽樣技術來估計概率PL(s,t),進而解決k-NN查詢。可以證明,該方法不僅克服了指數爆炸具有高效率,而且也具有很高的k-NN查全率和查準率。
我們首先討論第一種方法,即基礎的k-NN查詢算法(亦稱樸素k-NN算法)。
2.1 樸素的k-NN查詢算法
查詢一個不確定圖的給定源點s的k個最近鄰節點,可采用以下簡捷的方法:
將不確定圖G看成確定圖,采用Dijkstra算法從源點s出發,找到距離s節點最短距離(≤d)的所有節點集T(這里d為記錄當前離開s的距離閾值變量,初始時d=0),當|T|
上述求解k-NN方法可用算法語言形式描述如下:
算法1 Minimum Distance k-NN(G,s,k)
/* G是一個不確定圖,s是源點,k是需要查詢的節點個數 */
begin
置T :=?;
令G’ = (V,E,W),其中V,E,W 與不確定圖G=(V,E,P,W)中的相同;/* 此操作將不確定圖G當作確定圖G’來處理 */
d := 0; /* d為以源點s為中心的搜索范圍半徑,初始時為0 */
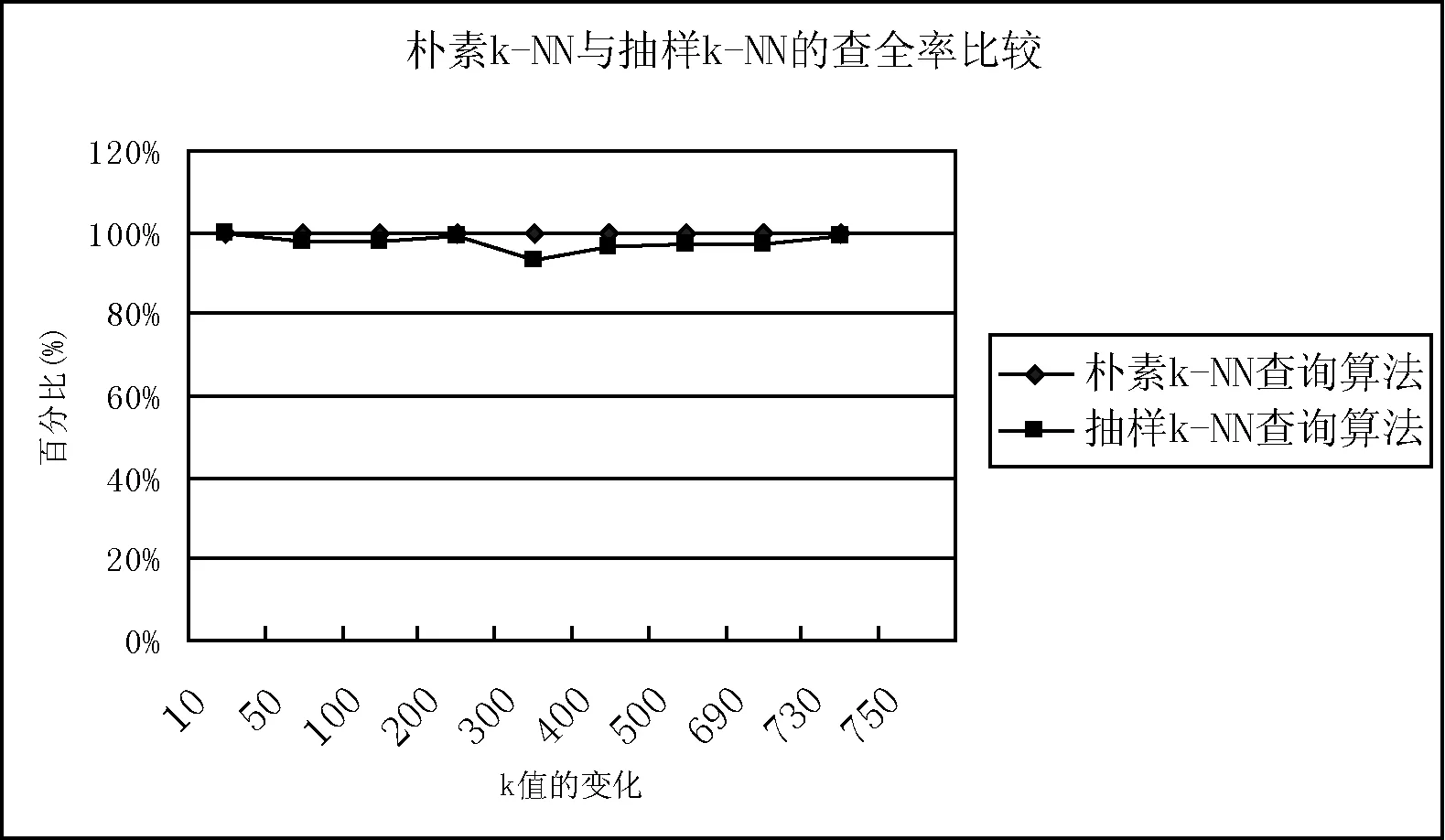
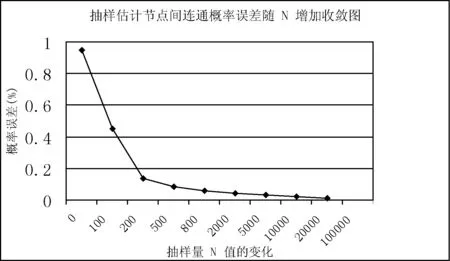
While (|T| begin Dijkstra (G’, s, d, T); /* 調用Dijkstra求取G’中離開源點s最短距離小于等于d的所有節點,放入T */ d := d+1; /* 遞增d */ end; /* while */ If |T|=k then return(T); else /* |T|>k */ { for (tn1,…,tnj∈T with the largest dL(s,tni)) do { /* tn1,…,tnj是T中具有相等的最大dL(s,tni)的節點,要選取概率最大的幾個留在T中*/ shortest-path-length = dL; ComputPL(G,s, tni, shortest-path-length); 按照PL(s, tni)(1≤i≤j)的從大到小順序排列{ tn1,…,tnj},取前m個留在T中使|T|=k; Return (T); } /* for */ } /* else*/ end /* of the algorithm */ 這里Dijkstra算法是稍做修改的Dijkstra*算法,當同一個節點t離開源點s有多條最短路徑時,Dijkstra*算法要記錄所有這些最短路徑。子算法ComputPL(s, t)計算源點s到節點t的最短路徑概率,其算法描述如下: 子算法1 ComputPL(G,s,t,shortest-path-length) /* 這里G是不確定圖,s是源點,t是當前節點,shortest-path-length是s到t的最短路徑長度 */ begin PL(s, t) :=0; /* 初始化 */ 計算G中所有連通(s,t)的最短路徑長度為shortest path-length的路徑集合,記之為shortest-paths; 依shortest-paths刪節G得到g,使g是G的子圖且僅含shortest-paths中的邊和節點,則g由源點s到節點t的長度為dL(s,t) 的所有最短路徑組成; 生成g的所有可能圖例集Pg; for Pg中的每個圖例g’ do { If g’包含shortest-paths中的任一最短路徑, then { 計算g’的概率Pr(g’): 累加Pr(g’)到PL(s, t)中: PL(s, t) := PL(s, t) + Pr(g’); } /* end of if */ } /end of for */ return(PL(s, t)); end /* Sub-Algorithm */ 該算法根據定義3的距離定義,求取k-NN查詢時找到距離源節點s最近的k個節點集T,并在解決最后競爭時(離開s具有相同距離的多個節點全加入T使|T|多于k)將最短路徑概率大者保留在T中。由于需精確計算最短路徑概率,故其不能避免可能世界圖例的指數爆炸。為了解決這個問題,我們提出了一個基于抽樣技術的k-NN算法。 2.2 采用抽樣技術的k-NN查詢算法 理論和實驗都表明,當k變大時,計算圖中兩點的最短路徑概率是影響算法kMinDist[1]和本文的樸素k-NN查詢算法(Minimum Distance k-NN算法)效率的關鍵因素。為了徹底避開可能圖例的指數爆炸問題,我們對樸素Minimum Distance k-NN算法做以下改進,主要想法是放棄樸素k-NN查詢算法查詢最優k-NN的目標,轉而求取近似最優k-NN來保持k-NN算法的高效率。 注意到本文的樸素算法Minimum Distance k-NN算法僅在計算(s,t)以最短路徑連通的概率PL(s,t)時,才引發可能圖例數量的指數爆炸。在下面的對該樸素算法的改進算法Approximate Minimum Distance k-NN中,對T中距離s最遠的若干節點tn1,tn2,…,tnj(它們與s的距離相等)中,在計算PL(s,tni) (1≤i≤j)時,不再按照子算法ComputPL(s,tni)去逐一枚舉連通(s,tni)的所有可能圖例來計算源點s到節點tni的精確最短路徑概率,而是抽取所有可能圖例的一部分樣本來估計PL(s,tni)的近似值。抽取可能圖例的方法是:按照連通(s,tni)的子圖中每個邊的存在概率來決定該邊出現與否,并組成圖例。根據Chernoff引理,只要圖例抽樣個數N達到足夠大,就可以保證估計的精確度,而N不是k-NN查詢之k的一個指數函數,從而避免了指數爆炸。 改進算法按照上述最遠點最短路徑概率(估計值)較大原則,選取若干最短路徑概率較大的節點保留在T中使|T|=k,而從T中刪除其他最遠節點。我們實現了這個算法Approximate Minimum Distance k-NN,并分析和驗證了其不僅效率大大高于文獻[1]的kMinDist算法,而且其給出的k-NN的查詢結果具有令人滿意的查全率(平均≥97%)。 算法Approximate Minimum Distance k-NN的偽代碼形式描述與上節的算法Minimum Distance k-NN只有一條語句不同:即使用計算最短路徑概率近似值的Approx-ComputPL′(G,s,tni,shortest-path-length)語句替代了前算法的計算最短路徑概率之精確值的ComputPL(G,s,tni,shortest-path-length)語句。對應的子程序也相應改變: 子算法Approx-ComputPL′(s,t)采用抽樣法計算源點s到節點t的最短路徑概率的近似值,其算法描述如下: 子算法2 Approx-Comput PL′(G, s, t, shortest-path-length) /* 這里G是不確定圖,s是源點,t是當前節點,shortest-path-length是s到t的最短路徑長度 */ begin (1) N=0,M = 0; /* N表示需要抽取圖例總數,其計算法見Chernoff定理;M為循環記數器*/ (2) number-of-I = 0; /*N個圖例中使(s,t)以最短路徑連通的圖例個數*/ (3) 計算s到t的所有的最短路徑集shortest-paths,根據該最短路徑集組成一個子圖g,使g是G的子圖且僅含shortest-paths中的邊和節點; (4) 子圖g =(V,E)的所有的邊組成一個向量(e1,e2…em); (5) while (M≤N) { /*循環N次*/ 對每邊ei依該條邊上的概率P(ei)選取“1”作為Xi的值(未能取1則取0),得到由{0,1}構成的 隨機向量X = (X1,X2,…,Xm);隨機向量X有2m種取值,代表所有可能圖例;若X的當前取值代表的圖例使(s,t)以最短路徑連通,我們記I(X) =1,否則記I(X) =0; (6) if (I(X)==1) number-of-I = number-of-I + 1; (7) M=M+1; /* 遞增循環計數變量M*/ (8) } /* end of while */ (9) return (number-of-I/N); /* number-of-I/N =PL′(s, t)就是節點s與節點t抽樣算法得到的概率近似值*/ end /* Sub-Algorithm */ 該算法按照最遠節點概率較大原則選取若干最短路徑概率較大的最外層節點保留在T中仍可保證給出的k-NN的查詢結果是最優k-NN查詢的很好近似的原因有兩個:(1)根據我們采用的文獻[1]的最短距離dL(s,t)定義,所有非最外層節點應落入最優k-NN查詢結果T中,該近似算法首先將所有非最外層節點選入k-NN查詢結果T中;(2)對于最外層節點(它們與源點s的距離相等)tn1,tn2,…,tnj,要選取近似概率PL′(s,tni)最大的幾個tni留在T中,使得|T|=k。我們通過大量的實驗,證明了這種近似算法的有效性,它不僅效率大大高于樸素k-NN查詢算法,而且其給出的k-NN的查詢結果具有令人滿意的查全率。 關于子算法Approx-ComputPL′(s,t)采用抽樣法計算連通概率近似值PL′(s,t)時的取樣容量N,我們有以下Chernoff定理[2]給出的取樣容量N與估計概率值(與精確概率值)的誤差關系作理論保障。 定理1 (Chernoff定理) 令X1,X2,…,XN是獨立同分布的隨機變量且它們有相同的期望值μ=E(Xi)。當N滿足 那么有: 我們稱N個樣本(的平均值)給出了μ的一個(ε,δ)精度的近似,其中0≤ε≤1、0≤δ≤1分別是誤差精度和置信度。 上述Chernoff定理在概率圖k-NN查詢問題中的一個直接應用[2]就是以下定理2。 定理2 令g是s到t的所有的最短路徑組成一個子圖、向量Xi=(e1,e2,…,em)是對g中所有邊ek按照其存在概率抽樣得到的一個圖例,當Xi使(s,t)以最短距離連通時令I(Xi)=1,否則I(Xi)=0。顯然I(X1),I(X2),…,I(XN)是獨立同分布的隨機變量且它們有相同的期望值E(Ii)=PL(s,t)。當N滿足: 那么有: 在定理2的實際應用中,為了計算N,我們引進一個連通概率閾值ρ(通常為某個很小的常數,如ρ=0.001),當節點對(s,t)的(最短路徑)連通概率PL(s,t)小于ρ時,認為k-NN查詢可以忽略t,也即這樣的t是我們不感興趣的節點。于是定理2變為:當N滿足: 有: 其中0≤ε≤1、0≤δ≤1分別是誤差精度和置信度,ρ是預先給定的一個很小的常數。 定理2的最后形式既給出了抽樣容量N與近似連通概率誤差的關系,也為我們計算N提供了理論公式。下一節的實驗驗證了該公式的準確性。 為了驗證上述算法的有效性,我們在美國Enron公司的郵件網絡數據[1,10]上進行了k-NN查詢實驗。該郵件網絡把每個郵件帳戶看作一個網絡節點,如果帳戶i曾經向帳戶j發送過一個郵件,就認為節點i與節點j之間存在一條無向邊。這個網絡有36 692個節點、183 818條邊。我們對數據進行了預處理:為每條邊附加了一個隨機產生的概率值,使之成為不確定圖,每條邊的權值為1。于是,每條邊附加的信息為:(1:p),其中1為權值、p∈[0,1]為概率值[10,17-19]。 3.1 實驗環境 我們實驗的硬件為主頻率為2.6 GHz的雙核CPU、4 GB內存、硬盤500 GB的PC臺式計算機,操作系統為Windows XP,編程環境為VS2010集成開發平臺,編程語言為C++語言。 3.2 實驗1 本實驗主要顯示本文的樸素k-NN查詢算法(Minimum Distance k-NN)的效率。我們對美國Enron公司的郵件網絡數據進行了抽取以減小其圖數據的分枝系數(即,出邊數),使每個節點連接的邊不超過7條,抽取到的不確定圖數據Data1的節點個數N=200,邊數為665條;Data2的節點個數為663節點,邊的條數為1 785;Data3的節點個數為3 480節點,邊的條數為6 815。本實驗中我們采用數據集Data3 ,觀察k-NN查詢的k由50至730不斷增長時,算法為了得到查詢結果所需要的時間(時間單位為毫秒ms)。 圖2所示的是本文給出的樸素k-NN查詢算法(Minimum Distance k-NN)所耗費時間隨k變化的情況。我們知道,求取最短路徑的概率要枚舉含有最短路徑的子圖上的可能世界模型的所有圖例,是最耗費時間的計算步驟,也是決定k-NN算法效率的關鍵因素。上述實驗表明,樸素k-NN算法的時間復雜度會發生急速上升(指數爆炸),拐點是在k=690處。這個實驗表明,在k較大時,即使求取一次兩節點連通概率都可能引發指數爆炸。 圖2 樸素k-NN查詢算法的時間復雜度隨k值變化的過程 3.3 實驗2 實驗2主要比較本文提出的樸素k-NN查詢算法(Minimum Distance k-NN)與抽樣k-NN查詢算法(Approximate Minimum Distance k-NN)的效率及查全率(recall ratio)。我們采用的不確定圖數據Data3是從Enron郵件數據中抽取的:節點個數為3 480節點,邊的條數為6 815時,觀察k-NN查詢的k由10至750不斷增長時,樸素k-NN查詢算法、抽樣k-NN查詢算法為了得到查詢結果所需要的時間(時間單位為毫秒ms),同時考察兩算法的查全率變化情況。抽樣算法的參數為ε=0.1,δ=0.1,ρ=0.01。 從圖3中我們可以看到,抽樣k-NN查詢算法效率比樸素k-NN查詢算法高得多,因為它只對實際可能世界中的N個圖例(N是常數)計算路徑的概率,減少了一個指數級復雜度的計算。樸素k-NN查詢算法在k大于690后時間復雜度開始急劇上升,而抽樣k-NN查詢算法則一直沒有驟然上升的情況。同時,從查全率和查準率來看(這里查全率指:抽樣k-NN查詢所得的k個節點與標準定義的k-NN查詢所得的k個節點的交集的勢除以k所得的比例[20]。顯然針對本文的k-NN定義,查準率等于查全率),樸素k-NN查詢算法的查全率和查準率(當然)是100%;而抽樣k-NN算法也保持了很高的查全率和查準率(平均≥97%),在實際應用中表現很好(如圖4所示)。 圖3 樸素k-NN查詢算法與抽樣k-NN查詢算法的時間比較 圖4 樸素k-NN查詢算法與抽樣k-NN查詢算法的查全率比較 我們也將本文的抽樣k-NN查詢算法與文獻[1]提出的“共用邊”優化kMinDist算法的效率進行了比較。實驗表明(見圖3所示),該優化算法較之樸素k-NN只是推遲了指數爆炸而不能避免它,而抽樣k-NN算法則避免了指數爆炸。 3.4 實驗3 我們對抽樣法近似計算連通概率近似值PL(s,t)的收斂速度(相對于抽樣容量N)進行了研究。針對不確定圖數據Data1、 Data2和Data3,我們以樸素k-NN查詢算法(可以)計算出的節點間連通概率為基礎真實概率數據,考察抽樣算法計算的相應節點間近似連通概率的誤差的絕對值隨著抽樣量N的變化趨勢。我們做了k取不同值時的k-NN實驗,并記錄了在對應的k個節點上的近似連通概率與真實連通概率誤差的平均值(這里‘對應的k個節點’是指用抽樣算法近似計算出的k-NN節點集與真實k-NN節點集交集節點上的概率誤差)。在圖5中,以抽樣算法計算近似概率的抽樣容量N為橫軸,以近似概率誤差為縱軸,畫出了絕對概率誤差的平均值隨著抽樣量N的變化曲線。 可以看出,概率誤差隨著N的增加而迅速收斂。通常可在N≥2 000的范圍內收斂到誤差不超過10%。這是相當好的結果,它為抽樣算法既保持較高的查詢搜索速度又保證高查全率提供了抽樣容量N的經驗數據。 圖5 抽樣估計節點間連通概率之誤差隨抽樣量N的增加而變小 在各種不確定數據組成的網絡(諸如生物網絡、社交網絡)中,不確定圖(或稱概率圖)是一種十分重要和普遍使用的數學模型,對不確定圖的搜索問題,也成為當前大數據研究當中的一個研究熱點。依據參考文獻[1],本文采用最短距離作為不確定圖的節點間距離定義,并討論在不確定圖是加權圖的情況下,求解最近k近鄰的查詢問題(k-NN問題)。本文提出了一個基于Dijkstra算法的抽樣k-NN算法,同時通過實驗驗證了本文所提出的方法效率優于以前的方法。 [1] 張旭,何向南,金澈請,等. 面向不確定圖的k最近鄰查詢 [J]. 計算機研究與發展, 2011,48(10):1871-1878. [2] Potamias M,Bonchi F, Gionis A, et al. K-nearest neighbors in uncertain graphs[J].The VLDB Journal, 2010,3(1):997-1008. [3] 華斌,楊超.主成分分析在復雜網絡社區發現的應用[J].計算機應用與軟件,2015,32(9):261-263. [4] 張碩,高宏,李建中,等.不確定圖數據庫中高效查詢處理[J].計算機學報, 2009,32(10):2066-2079. [5] Beskales G, Soliman M A, Ilyas I F. Efficient search for the top-k probable nearest neighbors in uncertain databases[J]. Proceedings of the Vldb Endowment Vldb Endowment Hompage, 2008, 1(1):326-339. [6] 張偉,俞瑞釗,何志均. 可采納搜索算法最壞復雜度的下確界[J].計算機學報,1990,13(6):449-455. [7] 梁聰,唐振華.一種基于DCT域局部能量的多聚焦圖像融合算法[J].計算機應用與軟件,2016,33(5):235-238. [8] 信俊昌,王國仁,公丕臻,等. 不確定數據庫中的閾值輪廓查詢處理[J]. 計算機研究與發展,2009, 46(5):126-132. [9] 黃冬梅,鄧斌,趙丹楓.帶權不確定圖的K最近鄰查詢算法[J].計算機應用與軟件,2016,33(2):212-216. [10] 袁野,王國仁. 面向不確定圖的概率可達查詢[J].計算機學報, 2010,33(8):1378-1386. [11] Aggarwal C C. Managing and mining uncertain data: advances in database systems[M].New York: Springer,2009:77-107. [12] 李傳文,谷峪,李芳芳,等.一種障礙空間中不確定對象的連續最近鄰查詢方法[J].計算機學報,2010,33(8):1359-1368. [13] 王艷秋, 徐傳飛, 于戈,等. 一種面向不確定對象的可見k近鄰查詢算法[J]. 計算機學報, 2010, 33(10):1943-1952. [14] 梁美麗,牛之賢.改進的綜合顏色紋理特征圖像檢索[J].計算機應用與軟件,2014,31(6):228-231. [15] 于戈,谷峪,鮑玉斌,等.云計算環境下的大規模圖數據處理技術:挑戰與進展 [J]. 計算機學報,2011,34(10):1753-1767. [16] 張偉,洪聲貴. 基于GAG的Horn邏輯分布式推導模型[J]. 遼寧大學學報,2012,39(4):1-6. [17] 周林,晏立,沈項軍.基于邊密度的復雜網絡社區結構劃分方法[J].計算機應用與軟件,2013,30(12):8-11. [18] 唐德權,吳紹兵,凌志剛.一種新的圖聚類算法研究[J].計算機應用與軟件,2014,31(6):18-20. [19] 亞森·艾則孜,李衛平,郭文強.復雜網絡中基于WCC的并行可擴展社團挖掘算法[J].計算機應用與軟件,2016,33(6):37-39. [20] Jiang L, Cai Z, Wang D. Bayesian citation-knn with distance weighting[J].International Journal of Machine Learning and Cybernetics,2014,5(2):193-199. K-NEAREST NEIGHBOR SEARCH ALGORITHM FOR UNCERTAIN GRAPHS BASED ON SAMPLING Zhang Wei (CollegeofComputerScienceandEngineering,NortheasternUniversity,Shenyang110819,Liaoning,China) Uncertain graphs are a very important and widely used mathematical model in networks composed of uncertain data such as biological networks or social networks. Since the two-point connectivity probability problem in the graph is a complete problem, the k nearest-neighbor query problem is much more complex than the normal graph and is related to the definition of "distance". Using the shortest distance as the definition of distance, we discuss the k-nearest neighbor search problem (k-NN) under the condition that the uncertain graph is a weighted graph. In order to overcome the problem of time exponential explosion caused by computing two-point connectivity probability, a sampling k-NN query algorithm based on Dijkstra algorithm is proposed. The convergence rate and convergence rate are studied. The proposed method is proved to be more efficient than kMinDist method and has high recall rate. Artificial intelligence Uncertain graphs Probability graph Biological network k-NN Sampling technique 2016-07-07。國家科技支撐計劃項目(2014BAI17B01);軟件開發環境國家重點實驗室開放課題(SKLSDE-2012KF-02)。張偉,教授,主研領域:人工智能,機器學習。 TP311.13 TP392 A 10.3969/j.issn.1000-386x.2017.06.033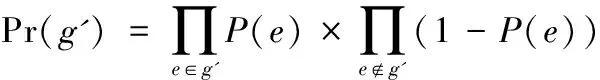
3 實驗結果與性能比較
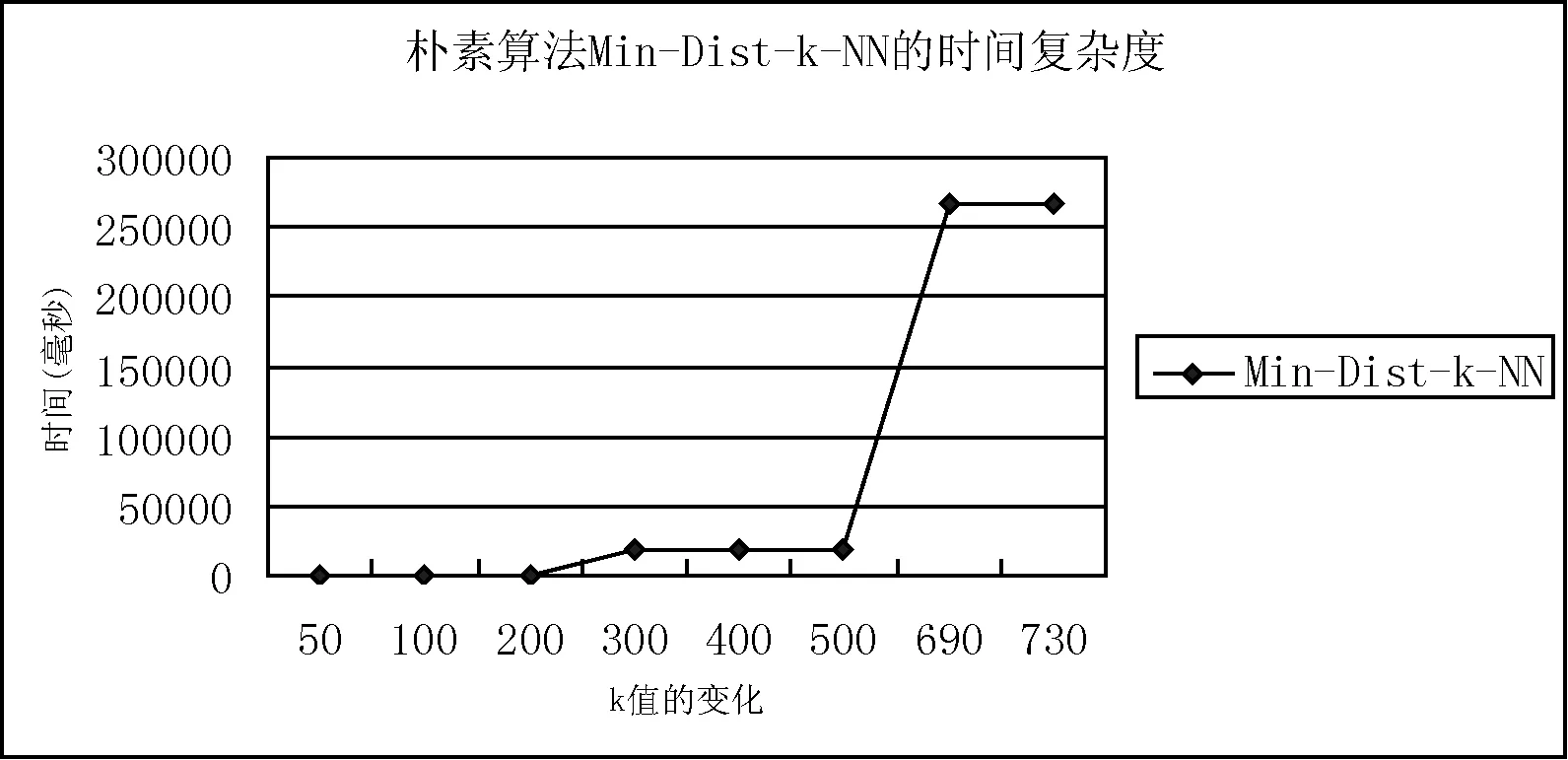
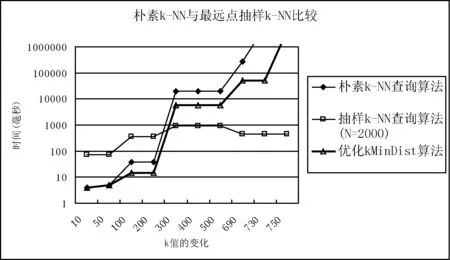
4 結 語
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學生數理化(高中版.高考數學)(2021年3期)2021-06-09 06:09:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:38
中學生數理化(高中版.高二數學)(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護與修理(2015年6期)2015-02-28 12:16:55
當代修辭學(2014年3期)2014-01-21 02:30:44
