基于中文知識圖譜的電商領域問答系統(tǒng)
2017-06-29 12:00:34杜澤宇
計算機應用與軟件 2017年5期
杜澤宇 楊 燕 賀 樑
(華東師范大學信息科學技術(shù)學院 上海 200062)
基于中文知識圖譜的電商領域問答系統(tǒng)
杜澤宇 楊 燕 賀 樑
(華東師范大學信息科學技術(shù)學院 上海 200062)
隨著知識圖譜的迅速發(fā)展,面向知識圖譜的中文領域問答系統(tǒng)已成為目前最新最熱的研究方向之一,對于提高專業(yè)領域服務智能化程度具有較高的意義和價值。針對中文口語語義表達多樣化、不符合語法規(guī)范以及電商領域特殊性問題,提出一套流式的中文知識圖譜自動問答系統(tǒng)CEQA,能夠較好地完成電商領域商品咨詢以及統(tǒng)計推理等復雜問題,特別是有效地提升了中英文混合商品名稱識別、語義鏈接以及復雜問句的依存分析等方面的性能。實驗結(jié)果表明,該系統(tǒng)在電商領域問答應用中具有較高的準確率和實用價值。
自動問答 知識圖譜 語義網(wǎng) 本體
0 引 言
知識圖譜最早起源于Google的Knowledge Graph,它本質(zhì)上是一種語義網(wǎng)絡,其結(jié)點代表實體或者概念,邊代表實體/概念之間的各種語義關(guān)系。隨著結(jié)構(gòu)化數(shù)據(jù)源的劇增,互聯(lián)網(wǎng)正在從大量互相鏈接的網(wǎng)頁向包含大量描述各種實體和實體之間豐富關(guān)系的語義網(wǎng)演進。如今已經(jīng)有很多著名的知識圖譜知識庫,如DBpedia、Freebase、Yogo、百度知心、知立方等。知識圖譜對搜索引擎提供語義層面上的支持,用戶通過關(guān)鍵詞搜索模式已經(jīng)很難滿足用戶的需求[1]。用戶更希望通過自然語言查詢,直接得到所需的答案,智能問答系統(tǒng)正在成為新一代信息檢索技術(shù)發(fā)展的必然趨勢。
知識圖譜構(gòu)建是自底向上數(shù)據(jù)驅(qū)動型,相對于本體而言,數(shù)據(jù)語義表達靈活,實體覆蓋率更高,語義關(guān)系也更加全面。現(xiàn)有的知識圖譜的標準數(shù)據(jù)通常是由RDF三元組數(shù)據(jù)存儲形式構(gòu)成,即:<主語,謂語,賓語>,還有一些加入本體信息結(jié)構(gòu)的OWL數(shù)據(jù),其中包含本體的基本概念,例如類(Class)、屬性(Property)、實例(Individual)等。龐大知識圖譜不僅包含事實類知識,還有豐富的語義知識為自然語言理解、知識推理和計算等方面提供強有力的支持。
基于知識圖譜的問答系統(tǒng)有兩大核心問題,前端語義理解和后端知識圖譜構(gòu)建。通用的問答流程是將自然語言翻譯成結(jié)構(gòu)化的查詢語言,比如SQL[2]、SPARQL[3-5],以及其他的語言[6-8]查詢知識圖譜中的實體和關(guān)系。基于知識圖譜的自動問答系統(tǒng)能夠支持推理等更多復雜的問題,如包含邏輯判斷的問句,如電商中“與iphone5s相同尺寸的手機有哪些?” 等這類問句。近年來,IBM 的Waston、Google Now和Siri等都應用了知識圖譜相關(guān)技術(shù),目前,我國電商行業(yè)發(fā)展迅速,用戶對于商品的咨詢量較大,自動問答系統(tǒng)可以部分緩解人工客服壓力,做到24×7在線服務,并且容易結(jié)合用戶信息擴展為對用戶提供個性化智能服務,例如京東的JIMI機器人可以提供基本查詢和聊天等服務。
國內(nèi)外在語義網(wǎng)相關(guān)問答系統(tǒng)方面已經(jīng)有了很長時間的研究。AquaLog[9]是較早基于多樣化語義網(wǎng)資源進行自動問答的系統(tǒng),其主要特點在于融合了消岐與排序的技術(shù),可以處理多個語義網(wǎng)資源混合情況下的問答。其瓶頸在于無法處理類似于
目前大部分性能優(yōu)秀的系統(tǒng)和研究都基于英文,因此在中文方面存在很多挑戰(zhàn):① 口語表達多樣化,用戶的表達往往無法在知識庫中進行識別。②不符合語法,對于語法復雜的問句進行依存關(guān)系分析時存在大量語義提取錯誤的問題。③領域特殊性,例如,實體名稱可能包含品牌型號等中英文混雜情況,如果用通用分詞軟件無法做到正確的實體識別。
本文在TBSL算法的基礎上,針對中文特定領域內(nèi)的知識庫進行優(yōu)化,提出了一套流式的中文知識圖譜自動問答系統(tǒng)CEQA,能夠較好地完成商品咨詢以及統(tǒng)計推理等復雜問題。針對商品名稱特征,提出了混合詞典的CRF方法,對該領域特殊實體識別有較好的效果;針對依存分析對于復雜問句三元組提取存在噪聲的問題,本文在哈工大LTP語義依存分析 SDP(Semantic Dependency Parsing)[12]的基礎上,提出了從三元組類別識別,到SDP依賴縮減,語義槽提取等一套算法框架,提高了語義三元組提取的準確率;為了解決自然語言翻譯成SPARQL查詢中自然語言多樣性表達的問題,本文提出利用Word2Vec[13]進行詞與詞直接的語義相似性計算,不需要標注大量數(shù)據(jù),在電商領域的語義鏈接問題上取得了較好的效果。識圖譜的自動問答系統(tǒng)已成為最新最熱的研究范疇。
1 相關(guān)工作
基于知識圖譜問答系統(tǒng)解決核心問題的方法主要有三類:基于模式的問答系統(tǒng)、基于統(tǒng)計學習的語義提取技術(shù)和基于依賴樹的語義提取技術(shù)。基于模式的問答系統(tǒng)根據(jù)模板和規(guī)則最早的系統(tǒng)采用了基于模式匹配的語義提取方法,找到符合規(guī)則的問句,利用制定好的模板進行轉(zhuǎn)換。如:找到一句話中含有(首都,國家)這一對關(guān)鍵詞,則認為該句的問題是詢問國家的首都。TBSL系統(tǒng)第一步根據(jù)依賴關(guān)系、詞性關(guān)系等生成基本的三元組,繼而采用構(gòu)建SPARQL解析器來生成查詢模板。使用更多的信息提取三元組的準確率要高于直接使用依賴關(guān)系來構(gòu)建查詢。基于統(tǒng)計學習的語義提取技術(shù)主要是機器學習的思路,直接針對這種圖結(jié)構(gòu)與關(guān)系數(shù)據(jù)進行學習, 包括ILP歸納邏輯編程和SRL統(tǒng)計關(guān)系學習[14]以及最近的一些研究,如:利用SVM進行語義在線學習[14-16]。推理一直是使用語義網(wǎng)的焦點,基于統(tǒng)計的方法雖然可以一定程度使用語義網(wǎng)的資源進行計算,但也會失去語義網(wǎng)結(jié)構(gòu)中最重要的本體以及支持推理的特性。由于語義網(wǎng)結(jié)構(gòu)數(shù)據(jù)大量涌現(xiàn),在很多情況下基于統(tǒng)計的機器學習技術(shù)非常有效,大量的自動問答系統(tǒng)都應用了基于統(tǒng)計的基本思想。基于依賴樹的語義提取技術(shù), 利用語法樹進行語義提取非常符合語義網(wǎng)本身的鏈接結(jié)構(gòu),很多方法都依賴于一定的語法解析器。
另一些系統(tǒng)如FREyA[17],在QuestID[18]的基礎上加入了用戶模型,利用用戶反饋信息提升領域詞典映射的準確度。而RTV[19]混合了一般基于字典的方法和統(tǒng)計機器學習的方法,將隱馬爾科夫模型加入三元組映射中,相似的系統(tǒng)還有Ngonga[20]。這些系統(tǒng)雖然在模型上有一定的優(yōu)化,但都是針對英語系的知識庫和語法規(guī)律進行。中文領域也有一些基于語義網(wǎng)的研究,最早在文獻[21]的研究中提出了基于本體的自動問答算法,回答了幾種特殊的問題,但模板適用性有一定限制。最新的中文領域的文章[22]對問題進行了分類和細致的處理,但需要大量的問題庫。本文在已有研究成果的基礎上,提出了面向電商領域的中文知識圖譜問答系統(tǒng)(CEQA)。
2 系統(tǒng)架構(gòu)
2.1 系統(tǒng)結(jié)構(gòu)
CE-QA方法是一套針對特定領域的算法框架,重點解決將中文自然語言轉(zhuǎn)換為SPARQL查詢的問題。本文特別針對電商領域進行了實驗,在準確率和算法運行效率方面與其他方法進行了對比,取得了較好的效果。整體算法框架如圖1所示。
(1) 自然語言問題輸入:輸入電商領域與商品查詢相關(guān)的問題,例如,夏普支持翻蓋的手機有哪些?
(2) 問題分類:對于輸入的自然語言,進行問題的分類。本文采用基于SVM算法分類。
(3) 問題分析:主要完成分詞、詞性標注、實體識別和實體消歧工作。本文基于LTP的分詞包之后,如,諾基亞8200 被切分成<諾基亞,8200>, 斯黛爾塑顏腮紅被切分成<斯黛爾,塑顏,腮紅>,另外,蘋果在電商領域中為品牌詞,而不是水果。所以需要針對電商領域的數(shù)據(jù)庫構(gòu)建詞典并訓練其特定的實體識別器。在得到分詞序列和體序列之后,本文依據(jù)SDP的初步依賴結(jié)果進行縮減,提出了SDP-Reduce的方法,縮減了復雜的依賴關(guān)系。
(4) 語義槽提取:語義槽是代表自然語言的三元組集合,是表達問句語義的基本組成,其中的槽代表待鏈接的自然語言描述,由3個部分構(gòu)成:一個變量、一個可能的URL(類別:class,屬性:property,實體:resource)、語義塊(詞或詞組)。本模塊主要完成類型判別,例如夏普=resource,翻蓋=property,手機=class,以及變量提取,,。本文提出了粗分類的方式,先簡單地將依賴縮減后的語義塊分別映射到資源、屬性、和類別上,這里簡化RDF的類別僅分為3類,保證粗分類的準確度。
(5) SPARQL抽取:主要完成構(gòu)造SPARQL模板工作。例如,Select?x WHERE {?x?p?y;?x rdf:type?z}。
(6) 語義鏈接:主要解決語義槽中的待鏈接自然語言表達分別鏈接到 <類別,資源,實體> 對應的知識圖譜中的URL上。例如,
(7) SPARQL查詢生成:查詢生成模塊以及問題類別,以及連接完成的實體,構(gòu)造標準的SPARQL查詢。
PREFIX db:
PREFIX res:
SELECT DISTINCT ?x WHERE ({
?x ?p res:夏普.
?x rdf:type db:手機.
?x db:翻蓋 ?z
}
2.2 問題分類器
將知識圖譜中的實體概念和屬性等詞加入領域詞庫,同時初始化分詞器,完成領域分詞器的構(gòu)建。針對百度知道抓取獲得的用戶問題分詞后的結(jié)果,根據(jù)抓取的集進行抽取標注,共定義8類問題類別,見表1所示。

表1 問題類別
對于輸入的自然語言,首先進行問題的分類,根據(jù)問題類別的關(guān)鍵詞(“能”、“嗎”、“有”、“可以”、“哪些”、“多大”等詞)構(gòu)造出問句類別向量,問題分類大多是從統(tǒng)計學的角度進行分類。由于本文初步問題分類類別少,特征突出,所以本文基于LibSVM[23]進行多分類器的訓練。
2.3 實體識別與消歧
傳統(tǒng)的實體識別包括人名、機構(gòu)名等命名實體識別,主流的算法是基于條件隨機場(CRF)的命名實體識別算法。而電商領域的實體不同于傳統(tǒng)的命名實體,其主要包括品牌名(BrandName)、型號名(SerialName),單品名(TrunkName),并且電商領域內(nèi)的實體往往由中英文混搭、長實體等多種不同的形式構(gòu)成。例如,商品標題為:<嬌韻詩(clarins)花樣年華纖柔美腹霜200 ml> ,其中單品名為(花樣年華纖柔美腹霜);或者 <三星 Galaxy Note4 > 型號名為(Note4)。由于CRF沒有HMM那樣嚴格的獨立性假設條件,因而可以容納任意的上下文信息,特征設計靈活。針對電商領域特點,本系統(tǒng)在CRF++[24]的基礎上混合n-gram特征模板混合詞型和單品特征在商品標題數(shù)據(jù)訓練領域內(nèi)的實體識別模型。線性CRF主要目標函數(shù)如式(1)所示,其中tk和sl是特征函數(shù),而λlμl分別是它們對應的參數(shù)。這里特征函數(shù)tk和sl取0或1,當滿足條件時為0,不滿足時為1,對于上述特征模板實際上會轉(zhuǎn)化為0或1的特征向量。部分特征模板如表2所示。

(1)
2.4 序列詞性依賴標注
本文基于哈工大LTP工具進行詞性標注,獲得標注好的詞序列。中文領域不同于英文的語法結(jié)構(gòu),傳統(tǒng)的依存句法分析關(guān)注實詞和實詞之間的介詞關(guān)系,而針對問答,則更關(guān)心有語義關(guān)系的詞。這里我們結(jié)合LTP的語義依存分析SDP(Semantic Dependency Parsing),替代了傳統(tǒng)的依存語法DP(Dependency Parsing)。雖然SDP能夠部分有效地提取語義相關(guān)的詞匯關(guān)系,但用于特定領域的問句時存在兩個問題,一是SDP的訓練和效果依賴于語料,并不能廣泛適用于特定領域;二是SDP的依賴過于復雜,同時針對一些較短的語句不能很好提取。本文在SDP的語義依存序列和領域內(nèi)實體序列的基礎上提出了依賴縮減算法。
1) 生成基于SDP初始化的依賴圖。如圖2所示:每個節(jié)點表示一個詞,每條邊表示它們的依賴關(guān)系。在下圖的例子中,Agt表示施事關(guān)系(如我送她一束花 (我 <--送)),F(xiàn)eat表示描寫關(guān)系,Cont表示客事關(guān)系,在這個句子中相應詢問的實體是<中興C580>,而其屬性是<網(wǎng)絡類型>,三句話表述相同的含義,由于缺少領域?qū)嶓w的支持,在SDP的描述下形成復雜的依賴結(jié)構(gòu)。
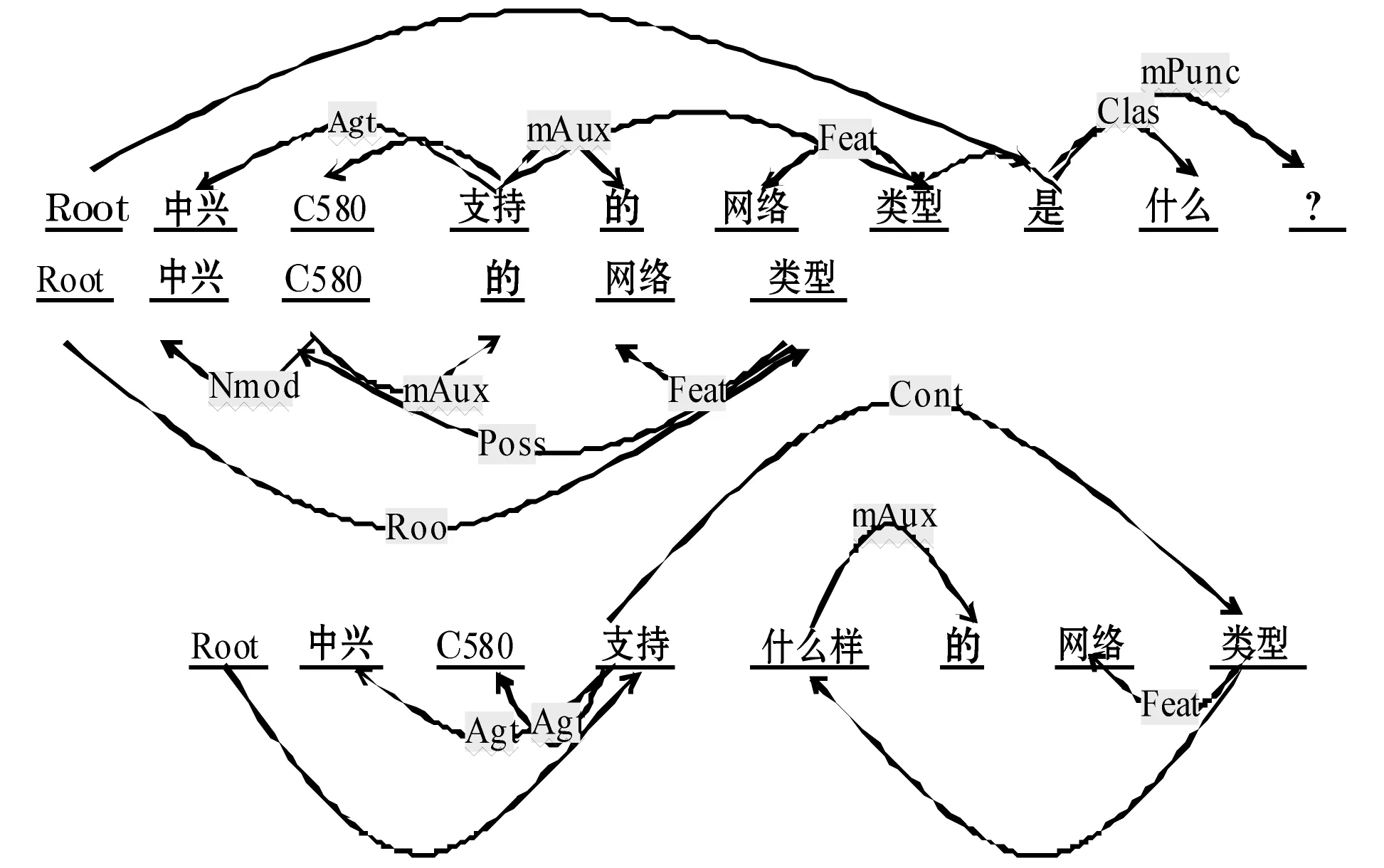
圖2 SDP依賴初始化
2) 利用CRF識別出的實體進行初步合并,如圖3所示,合并品牌名和型號名為同一個產(chǎn)品詞,并利用約簡規(guī)則減少標簽,我們對于每種依賴關(guān)系定義了四種基本操作:刪除(OMT)、合并(MRG),反轉(zhuǎn)(REV)和保持(REM)。OMT:表示刪除該條關(guān)系,并分別刪除兩端節(jié)點詞之間的鏈接。MRG:表示A詞和B詞之間的關(guān)系需要合并,合并后詞保留在源節(jié)點中,并使用源節(jié)點的指向關(guān)系,如圖3所示,要合并(類型->feat->網(wǎng)絡)則保留類型的指向關(guān)系(網(wǎng)絡類型->Feat-什么樣)。REV:表示反轉(zhuǎn)關(guān)系。REM:表示關(guān)系保持,及保留這一條邊。
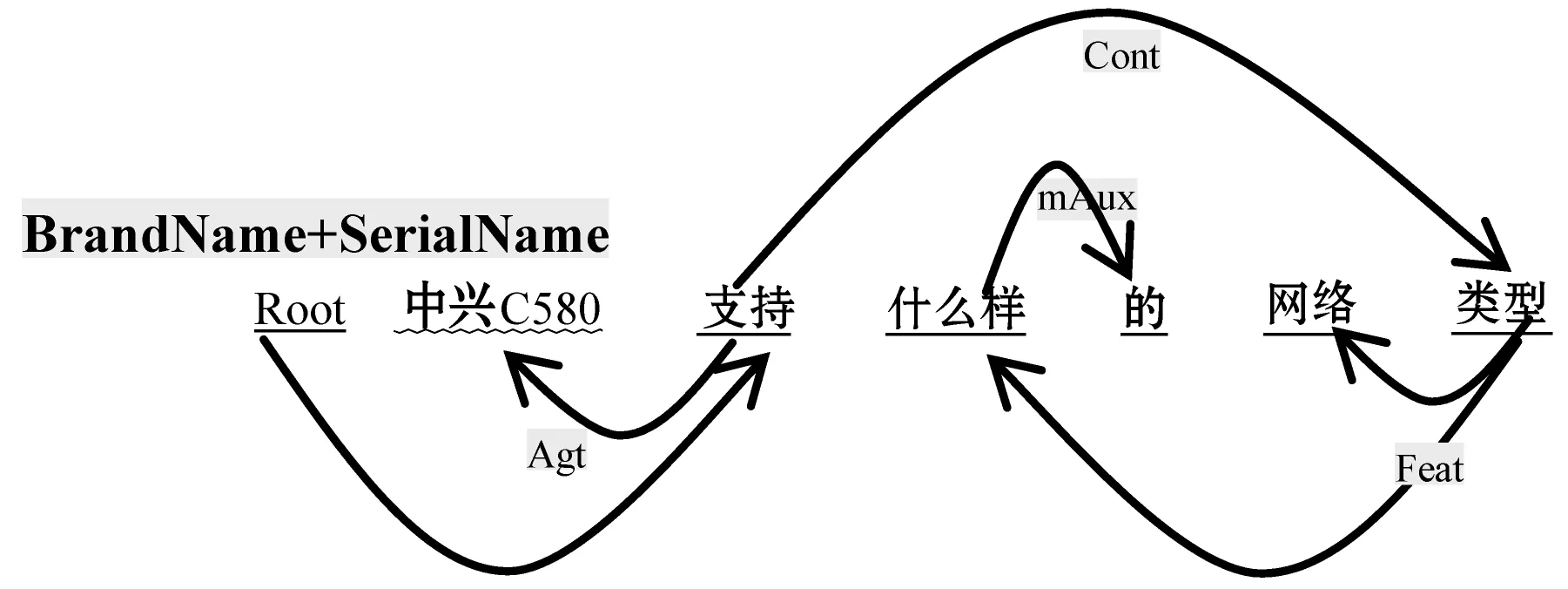
圖3 SDP實體初步合并
我們得到帶依賴序列的詞序列,并定義依賴縮減規(guī)則。定義縮減操作為F,對于任意語義依賴關(guān)系s,一定能找到一種操作(OMT、MRG、REV、REM中的一種)對該依賴進行操作。
F(Agt , 中興 C580[brandName+serialName],支持[v]) = REM
F(mAux , 的[u],什么樣[r]) = OMT
如圖4 所示,最后獲得的實體序列為:<中興c580>、<支持>、<網(wǎng)絡類型>。基于依賴縮減的簡化規(guī)則簡化了復雜依賴關(guān)系,保留保護語義的實體塊之間的依賴關(guān)系。
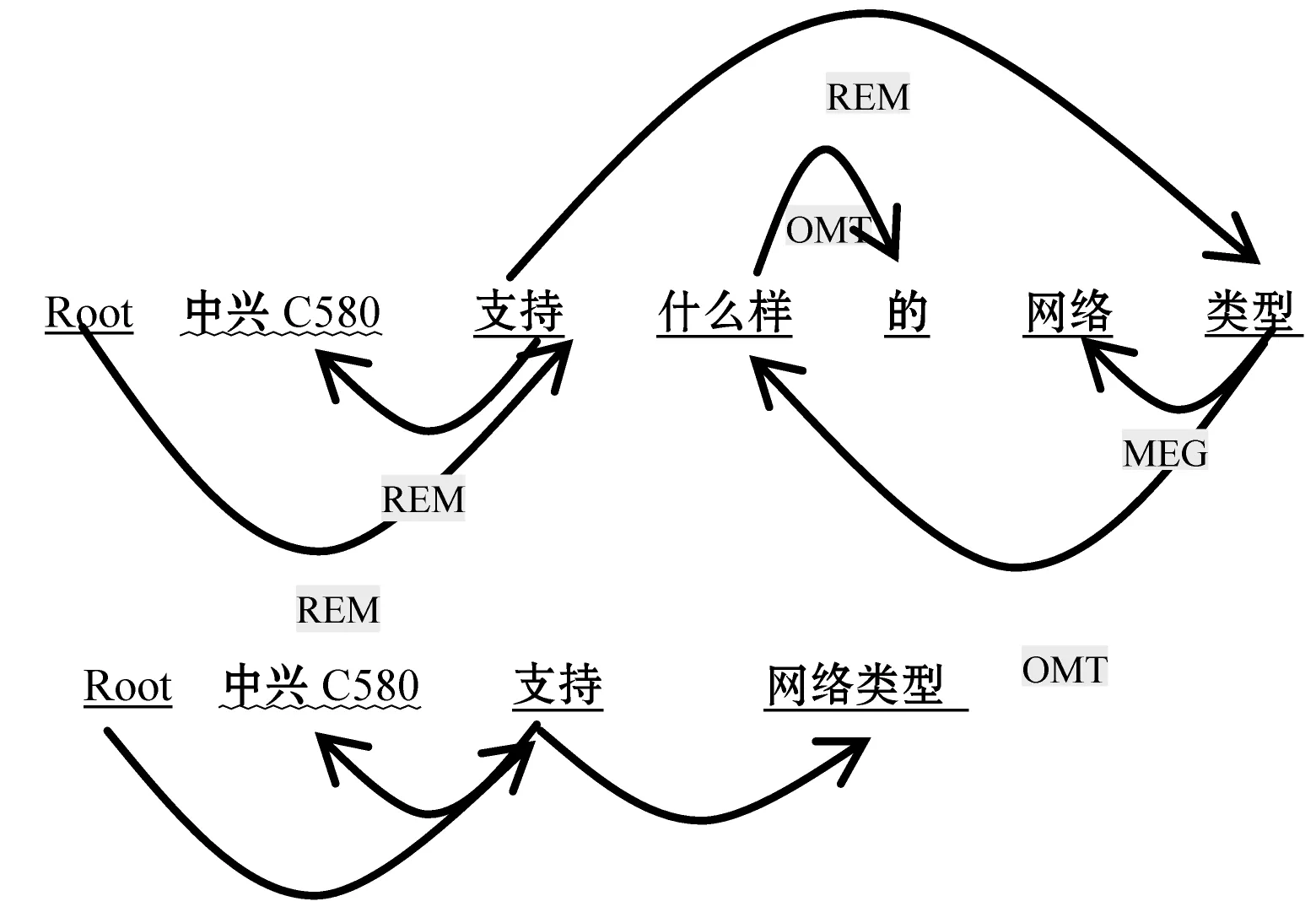
圖4 SDP依賴縮減
2.5 SPARQL提取
SPARQL模板是在上述的標注序列中生成的,針對不同的問題類別采用不同的策略。
事實類問題:定義了基本的查詢模板。對于類是完全正確的,使用?c替換對應的類。使用的詞匯信息(連詞如“和”,關(guān)系代詞如“什么”)和依存句法分析進行三元組的提取。
計數(shù)最值類問題:包含一個聚合函數(shù)問題的模板,使用了“聚合”屬性,說明是否需要添加聚合語句。定義的“聚合”函數(shù)有“計數(shù)”、“過濾器”和“比較器”這三種,并定義了目標作為聚合函數(shù)的目標。例如,使用了兩種類型的函數(shù),分別用于回答計數(shù)類和比較類的問題:
1) COUNT: SELECT COUNT (DISTINCT?x) WHERE {?x?p?y.}
2) ORDER: SELECT DISTINCT?x WHERE {?x?p?y.} ORDER BY DESC(?x)OFFSET 0 LIMIT n
另外,對于一些詞有特殊的功能類型。我們將這些話定義為“聚合指標”。例如,如果一個句子包含“多少”,則提取計數(shù)模板和提取技術(shù)指標。如果問題中包含一個“高級的”,我們認為這個問題需要過濾器。如果問題包含比較,推斷這個問題需要一個比較器操作。我們使用“聚合指標”來檢測這些類型的操作的目標和常數(shù)(如價格多于2 000的手機,會直接使用2 000和手機的依賴關(guān)系,Quan (手機,2 000 )。針對不同問題類別,制定相應的語義模板,再結(jié)合之前獲得實體序列獲得初步的SPARQL表達式。
2.6 語義鏈接
生成可以執(zhí)行的SPARQL后,還有復雜的鏈接問題需要處理。由于上文得到的函數(shù)式還包括自然語言,語義網(wǎng)中的表達則是以URL為單位的,本文提出先粗分類再利用Word2Vec混合詞典鏈接的模型。
主要流程如圖5所示:
1) 構(gòu)建字典,直接從RDF中建立到名詞短語識別資源/類URI的鏈接關(guān)系詞典,并基于Redis(一個開源的Key-Value存儲系統(tǒng))進行數(shù)據(jù)緩存。
2) 自然語言表達首先根據(jù)如下公式進行粗分類。
ScoreclassW(i)=WSDP(W(i))+Wdepm(W(i))+Whdpt(W(i))
(2)
其中Wi表示原問句中的一個詞,WSDP(W(i))表示當這個詞的詞性得分,Wdepm(W(i))表示這個詞的依賴得分,Whdpt(W(i))代表這個詞是否在RDF詞典中存在這個類別(存在為1,不存在為0)。利用SDP的依賴結(jié)果標注一部分數(shù)據(jù)進行訓練,最終獲得WSDP、Wdepm兩個參數(shù)。
3) 利用粗分類的結(jié)果,分別對每個自然語言的表達構(gòu)建候選項集合。
4) 計算相似度,本文并沒有采用WordNet或者同義詞網(wǎng)絡,而是采用Word2Vec尋找相似詞(找到 花花公子=Playboy simi=0.89)。Word2vec 是 Google的詞向量化工具,使用深度學習的思想,可以計算詞與詞之間的相似性,其主要假設是相似的單詞擁有相似的語境。主要目標函數(shù)如下所示:單詞w用長度為d的列向量表示,條件概率p(c|w)表示當w出現(xiàn)時,某一語境c出現(xiàn)的概率,θ表示模型參數(shù),D表示所有單詞w和它的語境C(w)構(gòu)成的組合的集合。
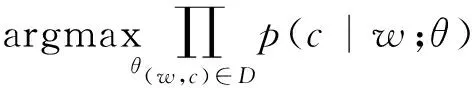
(3)
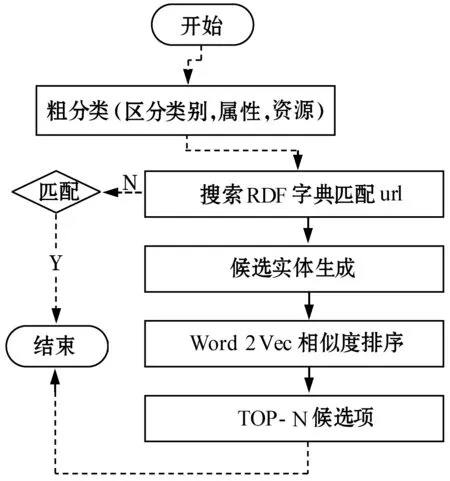
圖5 語義鏈接
5) 對于直接命中的進行構(gòu)建查詢,對于未命中的自然語言表達,取滿足閾值T的TopN的相似詞進行查詢,直到有查詢結(jié)果為止。
3 實驗與結(jié)論
3.1 數(shù)據(jù)準備
實驗主要對比該系統(tǒng)在實際電商領域問答數(shù)據(jù)中的問答準確度,我們參考國際標準比賽QALD的評測方法,利用準確率,召回率,和F值三個指標綜合衡量系統(tǒng)的準確程度,計算方法見式(4)。P表示準確率,R表示召回率,Pnum是準確答案的數(shù)目,ResNum是對所有問題系統(tǒng)給出的答案數(shù)據(jù),AucNum是實際的答案數(shù)目。
(4)
實驗抓取了京東、蘇寧等電商手機和電腦類的SPU數(shù)據(jù)整理成RDF資源,共有手機類(103 137個三元組),電腦類(508 123個三元組)。并利用百度知道和新浪愛問的相關(guān)問題100個和手工整理不同類別問題共200個作為訓練數(shù)據(jù)。
3.2 實驗分析
實驗主要比較了3種方法,最基礎的是TBSL(一個開源的問答系統(tǒng),由DBpedia團隊設計)算法的基礎上加入了實體識別,CEQA-N-W2V是CEQA框架下加入Word2Vec的實體鏈接的方法,后者取得了比以前更高的F值。此外,我們對后者是否添加依賴縮減算法進行對比,縮減圖的方法取得了最高的F值。如表3所示。
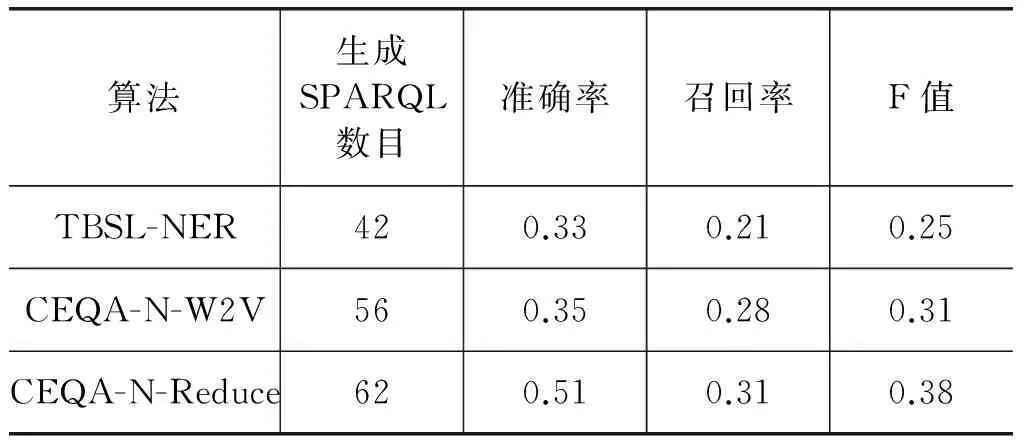
表3 實驗結(jié)果
在電商領域內(nèi),由于用戶關(guān)注的實體詞具有特殊性,構(gòu)建友好的問答系統(tǒng)需要解決領域內(nèi)的實體詞識別,以及行業(yè)內(nèi)的自然語言鏈接。從TBSL-NER實驗中可以發(fā)現(xiàn),在加入品牌名、型號名、單品名識別的基礎上F值可以達到0.25,而不使用實體識別的情況下無法正常解析用戶問句,由此說明的CEQA中加入領域特征的實體識別已經(jīng)初步具備回答問題的能力。進一步,我們對比了先粗分類,再利用Word2Vec做鏈接的CEQA-N-W2V方法,將類別、屬性、資源分別進行鏈接,并在Word2Vec的基礎上解決語義槽到圖譜數(shù)據(jù)鏈接的問題。在實驗中我們發(fā)現(xiàn),如這樣的句子“ThinkPad R4007445A46的硬盤容量有多大?”,Thinkpad本身并不在知識庫中,而“聯(lián)想”在知識庫中,利用word2vec訓練商品標題可以增加自然語言表達的豐富性。從實驗中也可以看出其增加了6%的F值,并且準確率沒有下降。雖然word2vec并不會比人工構(gòu)建同義詞庫準確度高,但是人工構(gòu)建的代價太大,在存儲電商標題數(shù)據(jù)的時候,直接使用標題無監(jiān)督訓練出詞向量更有優(yōu)勢。最后,加入了依賴縮減規(guī)則的CEQA-N-Reduce可以將一部分語義過于復雜的語句進行縮減,效果最好。在實驗中我們發(fā)現(xiàn),如“中興C580支持什么樣的網(wǎng)絡類型?”,“中興C580的網(wǎng)絡類型”均可以進行有效解析答案,實驗結(jié)果符合預期縮減SDP提取三元組的設想,其最終增加了7%的F值。并由于依賴縮減,使得準確率有了17%的提升,說明在SDP基礎上的依賴縮減對于電商領域的問答不僅可以回答更多的問題,而且更加準確。
現(xiàn)有實驗說明CEQA的整套框架可以有效地在電商領域的知識圖譜數(shù)據(jù)上提供問答服務,整套框架中各個模塊都可以持續(xù)優(yōu)化,而實際上鏈接算法、分類算法針對其他領域的問題方便設計特征進行替換,算法的可移植性也很好。
4 結(jié) 語
本文研發(fā)了基于中文知識圖譜的電商領域自動問答系統(tǒng),利用語義依存分析等自然語言處理技術(shù),提出縮減依賴算法提高問題的識別率,提取相應的語義槽,構(gòu)建SPARQL查詢。先進行粗分類,再結(jié)合Word2Vec完成了自然語言的鏈接,提高了URL的匹配的覆蓋率。另外,我們結(jié)合特定領域的特征在實體識別部分加入了特定的實體識別,使得進一步使用LTP變?yōu)榭赡堋H欢疚奶岢龅南到y(tǒng)仍然有局限性,制定規(guī)則來確定標簽是一項艱巨的任務,比如對于這樣的問題:“給我所有的手機與手機的顏色。”這樣的句子規(guī)則難以提取,同時LTP的精確度也有很大的影響。在未來的工作中,我們將重點放在LTP縮減的問題上,目前的縮減規(guī)則準確但是覆蓋率不夠,下一步將使用更多的機器學習算法提取。此外,我們還將研究在答案存在多個或沒有答案時的推薦式展現(xiàn)策略。
[1] Lopez V, Unger C, Cimiano P, et al. Evaluating question answering over linked data[J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2013, 21: 3-13.
[2] Popescu A M, Etzioni O, Kautz H. Towards a theory of natural language interfaces to databases[C]//Proceedings of the 8th International Conference on Intelligent User Interfaces. ACM, 2003: 149-157.
[3] Unger C, Bühmann L, Lehmann J, et al. Template-based question answering over RDF data[C]//Proceedings of the 21stInternational Conference on World Wide Web. Lyon, France: ACM, 2012: 639-648.
[4] Yahya M, Berberich K, Elbassuoni S, et al. Natural language questions for the web of data[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2012: 379-390.
[5] 郭磊. 基于領域本體中文自動問答系統(tǒng)相關(guān)技術(shù)的研究與實現(xiàn)[D]. 上海:華東理工大學, 2013.
[6] Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of EMNLP, 2013: 1533-1544.
[7] Berners-Lee T, Hendler J, Lassila O. The Semantic Web[J]. Scientific American, 2001, 284(5): 35-43.
[8] Fazzinga B, Lukasiewicz T. Semantic Search on the Web[J]. Semantic Web, 2010, 1(1-2): 89-96.
[9] Lopez V, Pasin M, Motta E. AquaLog: An ontology-portable question answering system for the semantic web[C]//Second European Semantic Web Conference, 2005: 546-562.
[10] Cimiano P, Haase P, Heizmann J. Porting natural language interfaces between domains: an experimental user study with the ORAKEL system[C]//Proceedings of the 12th International Conference on Intelligent User Interfaces. ACM, 2007: 180-189.
[11] Unger C, Cimiano P. Pythia: Compositional meaning construction for ontology-based question answering on the semantic web[C]//16thInternational Conference on Applications of Natural Language to Information Systems, 2011: 153-160.
[12] Che W, Li Z, Liu T. LTP: A Chinese Language Technology Platform[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Demonstrations. ACM, 2010: 13-16.
[13] Goldberg Y, Levy O. word2vec Explained: deriving Mikolov et al.’s negative-sampling word-embedding method[DB]. arXiv preprint arXiv: 1402.3722.
[14] Muggleton S, Raedt L D. Inductive Logic Programming: Theory and Methods[J]. The Journal of Logic Programming,1994, 19-20(S1): 629-679.
[15] Bordes A, Glorot X, Weston J, et al. A semantic matching energy function for learning with multi-relational data[J]. Machine Learning, 2014, 94(2): 233-259.
[16] Fanizzi N, d’Amato C, Esposito F. Learning with kernels in description logics[C]//18thInternational Conference on Inductive Logic Programming, 2008: 210-225.
[17] Damljanovic D, Agatonovic M, Cunningham H. FREyA: an interactive way of querying linked data using natural language[C]//Proceedings of the 1stWorkshop on Question Answering over Linked Data lab (QALD-1), 2011: 125-138.
[18] Damljanovic D, Tablan V, Bontcheva K. A text-based query interface to OWL ontologies[C]//Proceedings of the 6th Language Resources and Evaluation Conference(LREC), 2008: 205-212.
[19] Giannone C, Bellomaria V, Basili R. A HMM-based approach to question answering against linked data[C]//Proceedings of the 3rdWorkshop on Question Answering over Linked Data lab (QALD-3) at CLEF, 2013: 1-13.
[20] Shekarpour S, Ngomo A C N, Auer S. Question answering on interlinked data[C]//Proceedings of the 22nd International Conference on World Wide Web (WWW). ACM, 2013: 1145-1156.
[21] 何海蕓, 袁春風. 基于Ontology 的領域知識構(gòu)建技術(shù)綜述[J]. 計算機應用研究, 2005, 22(3): 14-18.
[22] 洪韻佳, 許鑫. 聯(lián)合虛擬參考咨詢系統(tǒng)知識庫的發(fā)展現(xiàn)狀與趨勢[J]. 現(xiàn)代圖書情報技術(shù), 2012(9): 2-9.
[23] 張巍, 陳俊杰. 信息熵方法及在中文問題分類中的應用[J]. 計算機工程與應用, 2013, 49(10): 129-131,179.
[24] 唐旭日, 陳小荷, 張雪英. 中文文本的地名解析方法研究[J]. 武漢大學學報信息科學版, 2010, 35(8): 930-935,982.
QUESTION ANSWERING SYSTEM OF ELECTRIC BUSINESS FIELD BASED ON CHINESE KNOWLEDGE MAP
Du Zeyu Yang Yan He Liang
(SchoolofInformationScienceTechnology,EastChinaNormalUniversity,Shanghai200062,China)
With the rapid development of knowledge map, the Chinese domain question answering system for knowledge map has become one of the newest and hotest research directions at present, and it is of great significance and value to improve the intelligence level of professional field. In this paper, a set of streaming Chinese knowledge map automatic question answering system (CEQA) is proposed for the diversification of Chinese spoken language semantic expression, grammatical specification and the particularity of electricity business domain. It can accomplish the complex problem of commodity consultation and statistical reasoning in the field of electric business, especially the improvement of the interdependence between Chinese and English mixed commodity name recognition, semantic link and complex question. The experimental results show that the system has high accuracy and practical value in the application of question and answer.
Question answering Knowledge map Semantic Web Ontolog
2016-02-21。國家高技術(shù)研究發(fā)展計劃項目(2015BAH12F01-04);上海市科委重點項目(14511107000)。杜澤宇,碩士生,主研領域:自然語言處理。楊燕,博士生。賀樑,教授。
TP3
A
10.3969/j.issn.1000-386x.2017.05.027
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
開放教育研究(2020年2期)2020-03-31 01:54:14
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
