基于多特征融合的深度視頻自然語言描述方法
2017-06-27 08:10:42朱清新廖淑嬌牛新征
計算機應用 2017年4期
梁 銳,朱清新,廖淑嬌,牛新征
1.電子科技大學 信息與軟件工程學院, 成都 610054; 2.電子科技大學 計算機科學與工程學院, 成都 610054)(*通信作者電子郵箱qxzhu@uestc.edu.cn)
基于多特征融合的深度視頻自然語言描述方法
梁 銳1,朱清新1*,廖淑嬌1,牛新征2
1.電子科技大學 信息與軟件工程學院, 成都 610054; 2.電子科技大學 計算機科學與工程學院, 成都 610054)(*通信作者電子郵箱qxzhu@uestc.edu.cn)
針對計算機對視頻進行自動標注和描述準確率不高的問題,提出一種基于多特征融合的深度視頻自然語言描述的方法。該方法提取視頻幀序列的空間特征、運動特征、視頻特征,進行特征的融合,使用融合的特征訓練基于長短期記憶(LSTM)的自然語言描述模型。通過不同的特征組合訓練多個自然語言描述模型,在測試時再進行后期融合,即先選擇一個模型獲取當前輸入的多個可能的輸出,再使用其他模型計算當前輸出的概率,對這些輸出的概率進行加權求和,取概率最高的作為輸出。此方法中的特征融合的方法包括前期融合:特征的拼接、不同特征對齊加權求和;后期融合:不同特征模型輸出的概率的加權融合,使用前期融合的特征對已生成的LSTM模型進行微調。在標準測試集MSVD上進行實驗,結果表明:融合不同類型的特征方法能夠獲得更高評測分值的提升;相同類型的特征融合的評測結果不會高于單個特征的分值;使用特征對預訓練好的模型進行微調的方法效果較差。其中使用前期融合與后期融合相結合的方法生成的視頻自然語言描述得到的METEOR評測分值為0.302,比目前查到的最高值高1.34%,表明該方法可以提升視頻自動描述的準確性。
深度學習;特征融合;視頻語義分析;視頻描述;遞歸神經網絡;長短時記憶
0 引言
在移動互聯網、大數據的時代背景下,智能終端的普及與社交網絡的發展,使得互聯網多媒體數據(圖片、視頻)呈現爆發式增長,計算機視覺已成為一個熱點研究領域,以往完全依賴人工對多媒體數據進行標注和描述已成為一項不可能的任務。本文重點關注視頻語義的自然語言自動描述研究,該方向的研究具有較高的應用價值和現實意義,可廣泛應用于智能安防、視頻檢索、人機交互、虛擬現實以及幫助盲人理解電影視頻等。用自然語言對視頻進行描述這一項任務對于正常的人來說非常簡單,但是對于計算機來說卻是一項很難的任務,它要求提出的方法能夠跨越低層的像素特征到高層語義的語義鴻溝,語義鴻溝的存在導致了計算機自動描述視頻準確率低的問題。針對這一現狀問題,在閱讀大量文獻與實驗驗證的基礎下,本文提出一種端到端的、基于長短期記憶(Long-Short Term Memory, LSTM)的自然語言描述的方法。方法首先提取視頻幀序列的各類特征,包括:通過預訓練的深度卷積神經網絡(Convolutional Neural Network, CNN)模型(如:VGG16(Visual Geometry Group)[1]、AlexNet[2]、GoogleNet[3]、ResNet[4]等)提取視頻中幀序列圖片的特征,并提取運動特征如光流(Optical Flow, OP),以及視頻特征如密集跟蹤軌跡(Dense Trajectory, DT)等;采用前期融合的方法融合提取到的多種特征,使用這些特征及融合后的特征的組合與視頻的自然語言描述文本訓練基于LSTM的視頻自然語言描述模型;在生成視頻自然語言描述時使用不同特征訓練的模型進行后期融合,獲得最終的自然語言描述,實現低層特征與自然語言的直接映射。此過程即輸入視頻,直接生成包含高層語義對象、符合自然語言語義規則的自然語言描述。本文使用深度學習框架Caffe[5]來完成文中描述的所有視頻幀序列的CNN特征提取和LSTM視頻自然語言描述模型的訓練,為了提高特征的提取與模型的訓練速度,采用了圖形處理器(Graphics Processing Unit,GPU)進行并行計算,以提升運算速度。在微軟視頻描述(Microsoft Video Description, MSVD)[6]數據集上的實驗結果表明本文方法在主流自然語言評測標準中取得了較好的評測結果(詳見第3章),表明了本文方法在提升視頻自然語言描述準確性上的有效性。
1 相關研究
近年來,對于圖片和視頻進行自然語言描述受到了廣泛的關注,尤其是2015年ImageNet大規模視覺識別的挑戰(ImageNet Large Scale Visual Recognition Competition, ILSVRC) 和COCO(Common Object in COntext)說明大賽,2015年大規模電影描述挑戰賽(Large Scale Movie Description Challenge, LSMDC),吸引了許多研究人員對該領域的關注,并在圖像和視頻文本描述方面發表了一系列的研究成果。
1.1 圖片文本描述
由圖片直接生成文本描述的方法主要分為兩類。一類為管道方法,首先通過建立模型學習到圖片中視覺對象對應的單詞;再通過基于一個遞歸神經網絡(Recurrent Neural Network, RNN)或LSTM的自然語言模型,將視覺對象對應的單詞組合成一個句子來描述圖片;最后通過相關性模型對句子進行打分排名,這種方法的兩個部分可以單獨進行調試,比較靈活。另一類為端對端的方法,即通過一個模型直接將圖片轉換到文本的描述。Google基于CNN和RNN開發了一個圖像標題生成器[7]。這個工作主要受到了基于RNN機器翻譯[8-9]的啟發。在機器翻譯中,分為編碼階段與解碼階段,編碼階段RNN讀取源語言的句子,將其變換到一個固定長度的向量表示;然后解碼階段RNN將向量表示作為隱層初始值,產生目標語言的句子。Li-Feifei團隊在文獻[10]也提到一種圖片生成文本描述的方法,與Google的做法類似,用圖片的CNN特征作為RNN的輸入,使用這種方法的圖片自然語言描述方法都取得了比較好的結果。
1.2 視頻文本描述
視頻生成自然語言的描述的方法,也大致分為兩類:
一類為包含兩個階段的管道方法[11-12]。第一階段先從視頻中定位出語義內容(如:主語、動詞、對象、場景),第二階段基于固定的模板(如:SVO(Subject、Verb、Object)、SOV(Subject、Object、Verb)、VSO(Verb、Subject、Object)等,不同語言類型,語法結構不同,因此語義內容的順序也不同)生成文本描述,這種基于模板的文本描述生成方法具有一定的局限性,它僅能對視頻進行簡單的陳述,而無法描述視頻中的其他豐富信息。
另一類為端到端的方法[13-16]。該方法將視頻內容與視頻自然語言描述的原始語料結合在一起作為模型的輸入,而不是像第一種方式那樣分開,該方法通過兩個步驟來生成視頻的自然語言描述:第一步以提取的視頻的CNN或視頻特征和人為提供的自然語言描述文本作為模型的輸入數據來訓練模型;第二步該模型用一個固定長度的向量來表示視頻,并將該向量和前一個單詞作為輸入,解碼得到下一個單詞,最終得到視頻向量的一組單詞表示,將這些單詞按序輸出為一個句子即得到視頻的自然語言描述。
本文提出一種基于多特征融合的深度視頻自然語言描述方法,基于主流的前期融合與后期融合方法,進行多種特征的融合方法研究,提取訓練視頻數據集的各類特征,進行前期特征融合得到融合特征向量,并將訓練樣本的自然語言描述轉為向量方式與融合的特征作為模型的輸入,基于不同的特征訓練多個視頻自然語言描述模型,在進行自然語言描述時再通過權值向量對不同特征訓練的模型進行后期融合,以獲取最好的結果。最后通過實驗評價本文方法的效果,并分析特征融合對于視頻的自然語言描述結果評價的影響。
2 研究思路
本文研究的技術路線如圖1所示,主要分為四個研究階段:基礎理論、實證研究、數據分析、結論。各個階段的研究內容根據箭頭的方向先后進行,各階段具體研究內容與技術途徑詳見圖1中各步驟詳解。
2.1 視頻描述模型
本文提出的生成自然語言描述的模型結構如圖2,輸入視頻幀序列(x1,x2,…,xn),最終得到的輸出自然語言的單詞序列(y1,y2,…,ym),正常情況下輸入幀的數量與輸出的單詞序列的單詞數都是可變的。在本文的模型中,給出一個輸入(x1,x2,…,xn),估計自然語言輸出序列(y1,y2,…,ym)的條件概率,可用式(1)表示:
p(y1,y2,…,ym|x1,x2,…,xn)
(1)
本文方法首先通過輸入的視頻幀序列提取視頻的3類特征,包括空間特征(基于VGG16、AlexNet的fc7層特征)、運動特征(提取視頻的光流并生成可視化光流圖并提取光流圖CNN特征)、視頻特征(DT特征);然后對于可進行融合的特征進行前期融合;再通過一個特征選擇器,該特征選擇器的作用為選擇提取到的及前期融合后得到的特征的組合作為LSTM描述模型的輸入;訓練一個基于LSTM的視頻自然語言描述模型;使用訓練得到的LSTM描述模型進行生成視頻自然語言描述實驗;最后如果實驗需要進行后期融合,在得到最終的視頻自然語言描述前,先使用2.3節中描述的方法確定后期融合時使用的各模型的權值,再依據權值得到概率最大的輸出結果。

圖1 本文研究技術路線
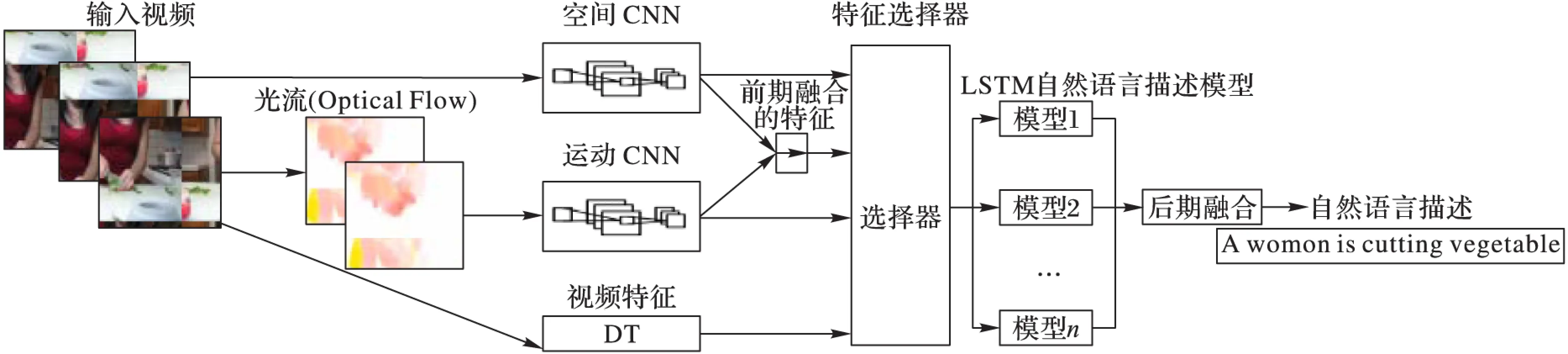
圖2 LSTM自然語言描述模型結構示意圖
2.2 特征提取
本文使用的特征均通過預訓練的模型或公開的方法的實現來提取。使用預訓練好的被公認比較優秀的模型提取的特征可以很好地表達視頻或者視頻幀。本文主要提取了如下幾類特征:
空間特征:本文使用預訓練的模型提取視頻幀序列圖像的空間特征,因為近年來CNN在圖像分類、目標檢測、圖像語義分割等領域取得了一系列突破性的研究成果[17],通過CNN提取的特征能夠很好地表達圖像。因此本文選擇在ImageNet分類任務數據集中取得很好數據的CNN模型VGG16[1]和AlexNet[2],提取預處理好的視頻幀序列中所有圖片的fc7層的特征,并計算幀序列特征的均值,最終得到一個4 096維特征向量來表示整個視頻。
運動特征:視頻的一個特點是其由許多連續的視頻幀組成,幀與幀之間存在運動的變化,因此在進行視頻分析時極有必要分析視頻的運動特征。本文使用文獻[18]中描述的方法提取相鄰幀的光流,并將提取到的光流數據歸一化到0~255,存儲為圖片文件,視頻幀數量為N時,光流圖像的數量為N-1。使用預訓練的模型[19]提取光流圖像的fc7層特征作為運動特征,并計算光流序列特征的均值,最終得到一個4 096維特征向量表示整個視頻的運動特征。
視頻特征:與單獨的圖片描述問題不同的是,視頻幀之間具有時間上的關聯性,因此在對視頻進行分析和研究時很有必要進行視頻的時間上的特征提取。本文使用文獻[20]方法提取DT特征,在提取DT特征時采用不重疊的長方形塊覆蓋圖像上的區域,最后拼接獲取到的各區域的DT特征作為整個視頻的特征。
2.3 特征融合
前期融合:需要在進行模型訓練前融合特征,以融合后的特征作為模型的輸入。本文驗證了兩種前期融合方式:
1)特征拼接。在特征提取階段,為了拼接多種模型提取的特征,各個模型均使用一個向量Fi表達整個視頻,其中i表示第i種特征。選取這些特征的組合直接拼接得Ffusion,自然語言描述模型的視頻特征輸入,可用式(2)表示:
Ffusion=(F1,F2,…,Fm)
(2)
其中:m表示融合的特征數量。
2)加權求和。將不同模型提取到的特征進行長度對齊,設置權值向量W=(w1,w2,…,wm),對特征進行加權求和,融合后的特征作為視頻自然語言描述生成模型的視頻特征輸入,可用式(3)表示:
Ffusion=WFT=(w1F1+w2F2+…+wmFm)
(3)
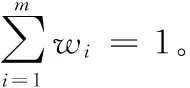
后期融合:在自然語言描述模型生成后進行融合,本文驗證了兩種后期融合的方式。
1)微調模式。用一種特征作為輸入訓練視頻自然語言描述模型M1,完成訓練后再使用另外一種特征作為輸入,以先前訓練的模型作為權重初始值,使用相同的視頻文本生成模型網絡進行微調,最后得到可用于生成視頻自然語言描述模型M2。
2)加權求和。在估計輸出時,使用一種模型M1與前一個詞作為輸入,估計下一個詞的可能輸出,獲得當前輸入條件下概率最高的10個備選詞,這些詞的概率分別為p1=p1k(y′) (k=1,2,…,10),使用其他模型Mi,分別計算這些備選詞的概率,通過權值向量重新計算輸出的概率,如式(4)所示:
p(y′)=WPT=(w1p1+w2p2+…+wnpn)
(4)
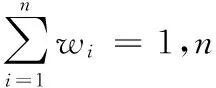
2.4 視頻自然語言描述模型
本文的自然語言描述模型受文獻[7]的啟發,采用兩層LSTM網絡模型:一層用于編碼,將輸入的視頻特征轉為向量表示;一層用于解碼,將視頻特征向量轉為單詞序列。選擇LSTM模型的原因在于其滿足本研究內容的三個基本條件:模型需要能夠處理不同長度的視頻,并能夠生成不同長度的自然語言描述;同時模型要能夠學習到視頻前后幀在時間上的依賴關系;在訓練過程中使用梯度下降法,誤差信號和梯度需要能夠長時間范圍內向底層回傳。
1)在訓練階段,此網絡底層輸入數據包含直接提取的特征F或融合后的視頻特征向量Ffusion,以及自然語言描述視頻的句子轉為與特征向量相同長度并通過嵌入層轉化為向量。將視頻特征向量與視頻自然語言描述的向量進行鏈接,形成視頻特征與自然語言描述的嵌入特征。
2)在1)中的視頻特征與自然語言描述的嵌入特征通過兩層LSTM網絡訓練整個網絡。
3)在驗證階段,第一層將視頻進行編碼得到特征向量Ffusion,第二層用于解碼,接收隱含層表示(ht),并將其解碼為單詞序列,在解碼階段,模型采用最大化對數似然函數來估計ht及前一個單詞能夠預測的下一個單詞。設θ為參數,輸出單詞序列為Y=(y1,y2,…,ym),模型可由式(5)表示:
(5)
圖3描述的是本文LSTM模型中的一個LSTM單元,一個LSTM單元包含一個記憶細胞m,該記憶細胞的輸出值受當前時間t、輸入x、前一個輸出y和前一個記憶細胞mt-1的影響。一個LSTM單元有4個門:輸入門(i)、輸入調制門(g)和忘記門(f)控制m更新,輸出門(o)控制輸出。忘記門允許LSTM單元忘掉前一個記憶細胞mt-1,輸出門決定多少記憶傳入隱含層(mt),這一過程的公式如式(6)~(11)所示:
it=σ(Wxixt+Whiht-1)
(6)
ft=σ(Wxfxt+Whfht-1)
(7)
ot=σ(Wxoxt+Whoht-1)
(8)
gt=φ(Wxmxt+Whmht-1)
(9)
mt=ft⊙mt-1+it⊙gt
(10)
ht=ot⊙φ(mt)
(11)
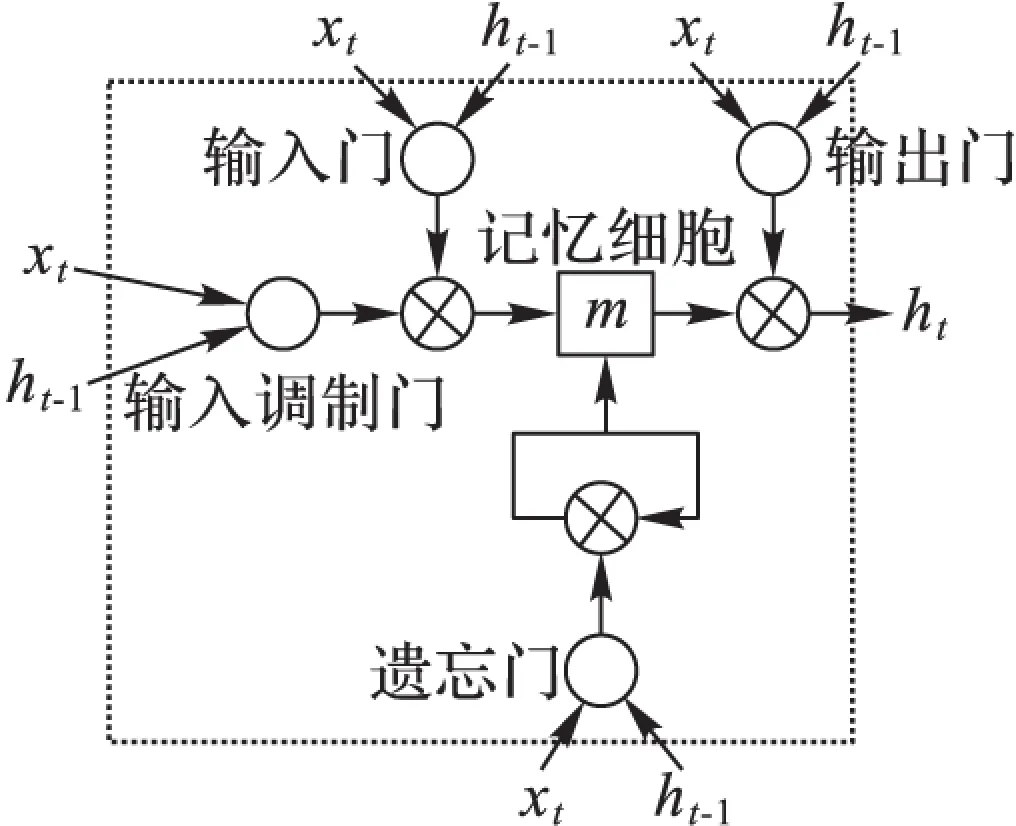
圖3 LSTM細胞單元
4)測試階段,使用訓練好的模型進行預測時,采用后期融合中的加權求和方法時,需要確定權值向量W的具體值,本文通過在驗證子集上進行微調得到。微調的過程為依次固定一個權值wi,然后將1-wi分配到n-1個權值,權值的最小值設定為0.01,每次變化的幅度為0.01,滿足式(12)所示的條件下依次計算每一組權值下,驗證子集生成的自然語言描述的評估分數,并選擇取得最大值時的W。
(12)
其中:n為模型數量,當n取1時即測試一個單獨的模型。
3 實驗與分析
3.1 數據集
MSVD[6]數據集是一個專門用于視頻描述實驗的標準數據集,該數據集總共包含2 089個視頻,但由于部分鏈接失效,最終保存下來的可用視頻共有1 970個,通過土耳其機器人獲取多種語言的描述,本文使用其英文描述,該數據集總共包含80 827條可用英文描述,總共包含567 874個字符,不相同的單詞和符號數量12 594個,每個視頻平均長度10.2s,且每個視頻平均擁有41條英文文本描述。按照文獻[13]方案進行數據集劃分,將數據集中劃分為3個子集,其中訓練集包含1 200個視頻,驗證集包含100個視頻,測試集包含670個視頻。
3.2 評價指標
本文采用LSMDC指定的四種標準評價指標CIDEr(Consensus-basedImageDescriptionEvaluation)[21]、BLEU(BiLingualEvaluationUnderstudy)[22]、ROUGE_L(Recall-OrientedUnderstudyforGistingEvaluation,Longestcommonsubsequence)[23]和METEOR[24]。這四種指標計算出的值為百分比,值越高表示描述越接近給定的原始描述。在本文中用來衡量使用特征融合方法生成的自然語言描述與人工描述的相似程度,以此來評價本文提出的視頻自然語言描述方法的優劣。
3.3 實驗步驟
本文方法的實驗基本流程如下:
1)視頻預處理:通過ffmpeg提取視頻中每一幀的圖片,并將提取到的視頻幀圖片尺寸縮放為固定大小256×256,按先后順序將視頻幀從1開始編號命名。
2)特征提取:基于視頻和幀序列提取包含2.2節描述的空間特征、運動特征、視頻特征。
3)前期特征融合:通過2.3節描述的特征融合方法,選擇不同的空間特征、運動特征、視頻特征進行融合。
4)選擇第3)步描述的前期特征融合后得到新特征,并結合訓練數據集的自然語言描述作為模型的輸入數據,訓練多個基于LSTM的自然語言描述模型。該過程基于深度學習框架Caffe實現,其中訓練此自然語言模型的部分參數如表1所示。
5)在生成視頻的自然語言描述時,選擇多個已訓練的模型進行后期融合,按照2.3節特征融合中所描述的后期融合方法中的加權法得到權值向量W。
6)使用選擇的已訓練的模型及上一步得到的權值向量W,生成測試集的自然語言描述。
7)使用CocoCaption[25]工具,結合本文方法生成的自然語言描述與測試集中給出的人工對視頻的描述,評估相似度分值。
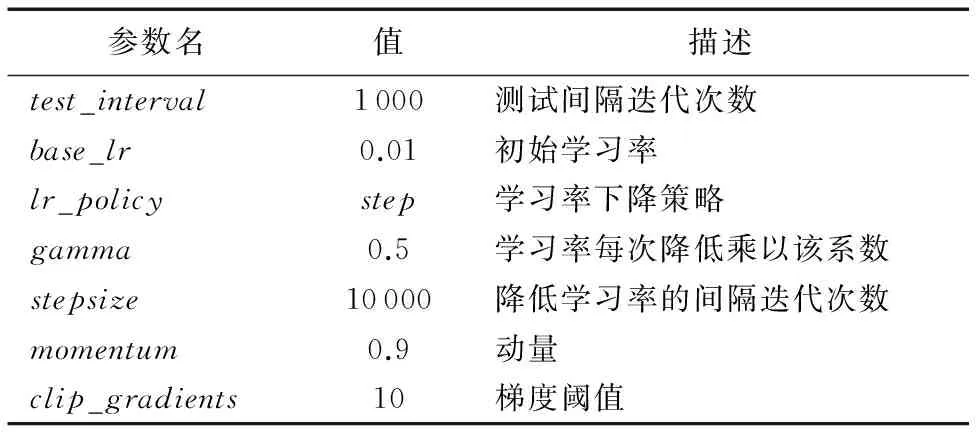
表1 LSTM自然語言描述模型部分參數
3.4 實驗結果與分析
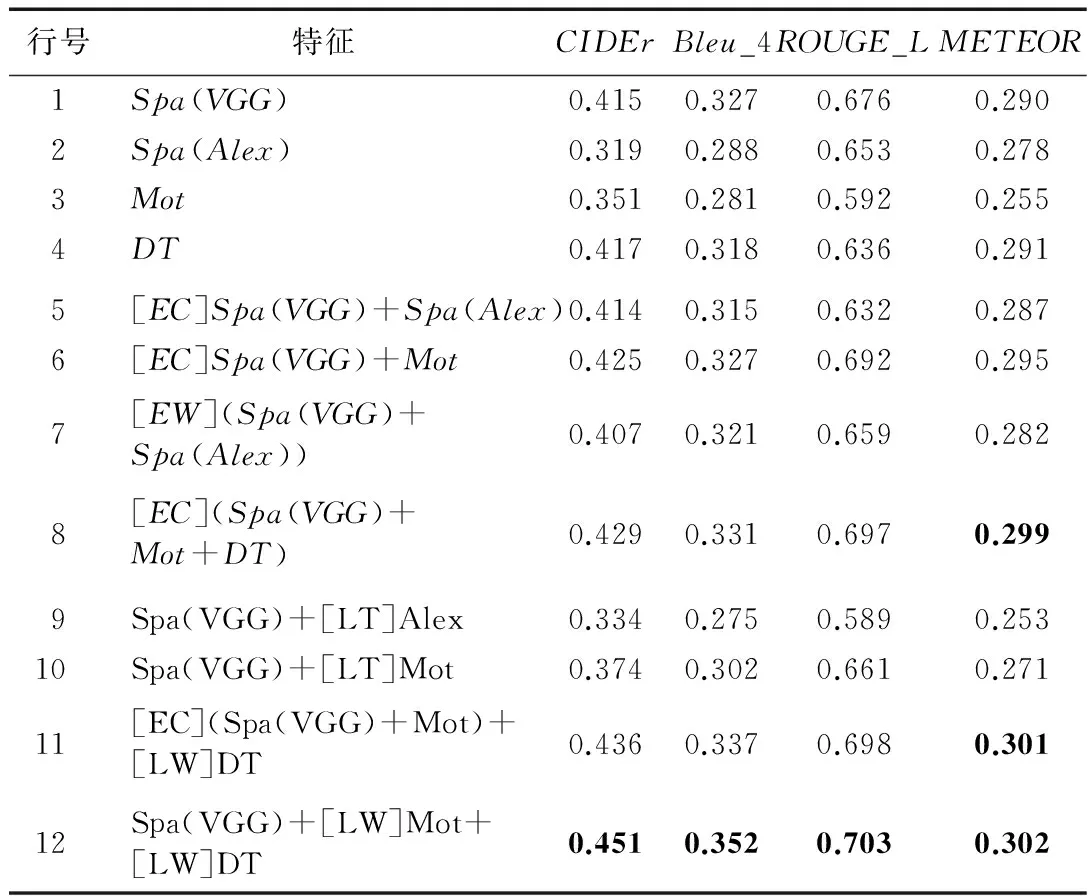
表2 自然語言描述方法評估結果
表2中列舉了本文描述的自然語言描述方法在測試集上生成自然語言描述的評估分數。其中:Spa表示空間特征,Mot表示運動特征,DT代表視頻特征,[EC]表示前期融合的特征拼接,[EW]表示前期融合的特征加權和,[LT]表示后期融合微調方式,[LW]表示后期融合加權方式。第1~4行的數據為不進行特征融合使用單一特征進行實驗的評估分數;第5~8行的數據為僅進行前期特征融合得到的評估分數;第9~12行的數據為前期融合與后期融合相結合得到的評估分數。通過表2中的測評結果可看出:在METEOR評測指標方面,本文提出的3種特征融合組合的結果評分超過了文獻[12]的最佳值0.298;但是CIDEr和BLEU指標方面,本文的特征融合組合的結果評分均低于文獻[16]中的最佳值0.516 7和0.419 2。通過數據的對比分析可以得出如下的結論:1)融合不同類型的特征方法能夠獲得評測分值的提升,如表2中的第6、8、11、12行都比融合前的單特征模型獲得了更高的評測分值。2)相同類型的特征融合的結果不會高于單特征的分值,如表2中第5和7行結果比其中某一個單獨的特征生成的模型評測分值都低。3)使用不同特征對現有模型進行微調的方法效果較差,如表2中的第9、10行,分值比融合前單特征模型的評測分值都要低很多。
圖4中的三個子圖為視頻1中的部分幀,數據集中給出的該視頻的部分參考文本描述為:1)apersonisridingamotorcycleonthebeach; 2)amanridesamotorcyclethroughtheocean。本文方法生成的描述為Apersonisridingamotorcycleonthesnow。圖5中的三個子圖為視頻2中的部分幀,數據集中給出的該視頻的部分參考文本描述為:1)amanisplayingaguitar; 2)amanisplayingtheguitarwhilesittingonaparkbench。本文方法生成的描述為Amanisplayingaguitar。圖6中三個子圖為視頻3中的部分幀,數據集中給出的該視頻的部分參考文本描述為:1)apersoniscuttingafishwithknife; 2)amanisslicingopenafishandcutsoffitshead。本文方法生成的描述為Awomaniscuttingacookedfishonacuttingboard。通過這些示例可以看出本文方法能夠比較準確地生成部分視頻的自然語言描述。

圖4 視頻1中部分幀

圖5 視頻2中部分幀

圖6 視頻3中部分幀
4 結語
本文提出一種多特征的視頻自然語言描述的框架方法,此方法在兩個階段進行特征的融合,以提升生成自然語言描述的準確性。本文使用的特征包括空間特征(如VGG16、AlexNet提取的視頻幀序列特征)、運動特征(光流圖像的CNN特征)、視頻特征(DT特征)等。在MSVD數據集上進行了多種特征的融合組合實驗,通過實驗驗證了本文方法的可行性與有效性,并得出結論:使用多特征融合能夠提升視頻自然語言描述的準確性,相同類型的特征融合無法提升準確率,不同類型的特征之間的融合對于準確性的提升幅度更大。基于本文提出的特征融合方法框架,選擇適當的不同類型特征,還可以進一步提升視頻自然語言描述的準確性。
)
[1]SIMONYANK,ZISSERMANA.Verydeepconvolutionalnetworksforlarge-scaleimagerecognition[EB/OL]. [2016- 09- 14].https://arxiv.org/pdf/1409.1556v6.pdf.
[2]KRIZHEVSKYA,SUTSKEVERI,HINTONGE.ImageNetclassificationwithdeepconvolutionalneuralnetworks[EB/OL]. [2016- 09- 14].https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
[3]SZEGEDYC,LIUW,JIAY,etal.Goingdeeperwithconvolutions[C]//Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2015:1-9.
[4]HEK,ZHANGX,RENS,etal.Deepresiduallearningforimagerecognition[EB/OL]. [2016- 09- 14].https://www.researchgate.net/publication/286512696_Deep_Residual_Learning_for_Image_Recognition.
[5]JIAY,SHELHAMERE,DONAHUEJ,etal.Caffe:convolutionalarchitectureforfastfeatureembedding[EB/OL]. [2016- 03- 10].https://arxiv.org/pdf/1408.5093v1.pdf.
[6]CHENDL,DOLANWB.Collectinghighlyparalleldataforparaphraseevaluation[C]//HLT2011:Proceedingsofthe49thAnnualMeetingoftheAssociationforComputationalLinguistics:HumanLanguageTechnologies.Stroudsburg,PA,USA:AssociationforComputationalLinguistics, 2011, 1:190-200.
[7]VINYALSO,TOSHEVA,BENGIOS,etal.Showandtell:aneuralimagecaptiongenerator[C]//Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2015:3156-3164.
[8]SUTSKEVERI,VINYALSO,LEQV.Sequencetosequencelearningwithneuralnetworks[C]//NIPS2014:Proceedingsofthe27thInternationalConferenceonNeuralInformationProcessingSystems.Cambridge,MA:MITPress, 2014.
[9]CHOK,MERRIENBOERBV,GULCEHREC,etal.LearningphraserepresentationsusingRNNencoder-decoderforstatisticalmachinetranslation[EB/OL]. [2016- 09- 10].https://arxiv.org/pdf/1406.1078v3.pdf.
[10]KARPATHYA,LIFF.Deepvisual-semanticalignmentsforgeneratingimagedescriptions[C]//Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2015:3128-3137.
[11]KRISHNAMOORTHYN,MALKARNENKARG,MOONEYRJ,etal.Generatingnatural-languagevideodescriptionsusingtext-minedknowledge[C]//AAAI2013:ProceedingsoftheTwenty-SeventhAAAIConferenceonArtificialIntelligence.MenloPark,CA:AAAIPress, 2013:541-547.
[12]THOMASONJ,VENUGOPALANS,GUADARRAMAS,etal.Integratinglanguageandvisiontogeneratenaturallanguagedescriptionsofvideosinthewild[EB/OL]. [2016- 03- 10].http://www.cs.utexas.edu/users/ml/papers/thomason.coling14.pdf.
[13]VENUGOPALANS,ROHRBACHM,DONAHUEJ,etal.Sequencetosequence—videototext[EB/OL]. [2016- 03- 10].https://arxiv.org/pdf/1505.00487v3.pdf.
[14]VENUGOPALANS,XUH,DONAHUEJ,etal.Translatingvideostonaturallanguageusingdeeprecurrentneuralnetworks[EB/OL]. [2016- 03- 10].https://arxiv.org/pdf/1412.4729v3.pdf.
[15]SHETTYR,LAAKSONENJ.Videocaptioningwithrecurrentnetworksbasedonframe-andvideo-levelfeaturesandvisualcontentclassification[EB/OL]. [2016- 03- 10].https://arxiv.org/pdf/1512.02949v1.pdf.
[16]YAOL,TORABIA,CHOK,etal.Describingvideosbyexploitingtemporalstructure[C]//Proceedingsofthe2015IEEEInternationalConferenceonComputerVision.Piscataway,NJ:IEEE, 2015: 4507-4515.
[17] 李彥冬, 郝宗波, 雷航. 卷積神經網絡研究綜述[J]. 計算機應用, 2016, 36(9): 2508-2515.(LIYD,HAOZB,LEIH.Surveyofconvolutionalneuralnetwork[J].JournalofComputerApplications, 2016, 36(9): 2508-2515.)
[18]FARNEBACKG.Two-framemotionestimationbasedonpolynomialexpansion[C]//SCIA2003:Proceedingsofthe13thScandinavianConferenceonImageAnalysis,LNCS2749.Berlin:Springer, 2003:363-370.
[19]GKIOXARIG,MALIKJ.Findingactiontubes[C]//Proceedingsofthe2015IEEEConferenceonComputerVisionandPatternRecognition.Piscataway,NJ:IEEE, 2015:759-768.
[20]WANGH,KLASERA,SCHMIDC,etal.Actionrecognitionbydensetrajectories[C]//CVPR2011:Proceedingsofthe2011IEEEConferenceonComputerVisionandPatternRecognition.Washington,DC:IEEEComputerSociety, 2011:3169-3176.
[21]VEDANTAMR,ZITNICKCL,PARIKHD.CIDEr:consensus-basedimagedescriptionevaluation[EB/OL]. [2016- 03- 10].https://arxiv.org/pdf/1411.5726v2.pdf.
[22]PAPINENIK.BLEU:amethodforautomaticevaluationofmachinetranslation[J].WirelessNetworks, 2015, 4(4):307-318.
[23]FLICKC.ROUGE:apackageforautomaticevaluationofsummaries[EB/OL]. [2016- 03- 10].http://anthology.aclweb.org/W/W04/W04-1013.pdf.
[24]DENKOWSKIM,LAVIEA.Meteoruniversal:languagespecifictranslationevaluationforanytargetlanguage[EB/OL]. [2016- 03- 10].https://www.cs.cmu.edu/~alavie/METEOR/pdf/meteor-1.5.pdf.
[25]CHENX,FANGH,LINT,etal.MicrosoftCOCOcaptions:datacollectionandevaluationserver[EB/OL]. [2016- 09- 14].https://arxiv.org/pdf/1504.00325v2.pdf.
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61300192),theFundamentalResearchFundsfortheCentralUniversities(ZYGX2014J052).
LIANG Rui, born in 1985, Ph. D. candidate. His research interests include computer vision, video semantic analysis.
ZHU Qingxin, born in 1954, Ph. D., professor. His research interests include software engineering, graphics and vision, computational operations research, bioinformatics.
LIAO Shujiao, born in 1981, Ph. D. candidate. Her research interests include machine learning, granular computing.
NIU Xinzheng, born in 1978, Ph. D., associate professor. His research interests include machine learning, big data, mobile computing.
Deep natural language description method for video based on multi-feature fusion
LIANG Rui1, ZHU Qingxin1*, LIAO Shujiao1, NIU Xinzheng2
(1. School of Information and Software Engineering,University of Electronic Science and Technology of China, Chengdu Sichuan 610054, China;2. School of Computer Science and Engineering,University of Electronic Science and Technology of China, Chengdu Sichuan 610054, China)
Concerning the low accuracy of automatically labelling or describing videos by computers, a deep natural language description method for video based on multi-feature fusion was proposed. The spatial features, motion features and video features of video frame sequence were extracted and fused to train a Long-Short Term Memory (LSTM) based natural language description model. Several natural language description models were trained through the combination of different features from early fusion, then did a late fusion when testing. One of the models was selected to predict possible outputs under current inputs, and the probabilities of these outputs were recomputed with other models, then a weighted sum of these outputs was computed and the output with the highest probability was used as the next output. The feature fusion methods of the proposed method include early fusion such as feature concatenating, weighted summing of different features after alignment, and late fusion such as weighted fusion of outputs’ probabilities of different models based on different features, finetuning generated LSTM model by early fused features. Comparison experimental results on Microsoft Video Description (MSVD) dataset indicate that the fusion of different kinds of features can promote the evaluation score, while the fusion of the same kind of features cannot get higher evaluation score than that of the best feature; however, finetuning pre-trained model with other features has poor effect. Among different combination of different features tested, the description generated by the method of combining early fusion and later fusion gets 0.302 of METEOR, which is 1.34% higher than the highest score that can be found, it means that the method is able to improve the accuracy of video automatic description.
deep learning; feature fusion; video semantic analysis; video description; recurrent neural network; Long-Short Term Memory (LSTM)
2016- 09- 14;
2016- 12- 25。
國家自然科學基金資助項目(61300192);中央高校基本科研業務費專項資金資助項目(ZYGX2014J052)。
梁銳(1985—),男,四川遂寧人,博士研究生,CCF會員,主要研究方向:計算機視覺、視頻語義分析; 朱清新(1954—),男,四川成都人,教授,博士,CCF會員,主要研究方向:軟件工程、圖形與視覺、計算運籌學、生物信息學; 廖淑嬌(1981—),女,福建漳州人,博士研究生,CCF會員,主要研究方向:機器學習、粒計算; 牛新征(1978—),男,四川成都人,副教授,博士,主要研究方向:機器學習、大數據、移動計算。
1001- 9081(2017)04- 1179- 06
10.11772/j.issn.1001- 9081.2017.04.1179
TP37;TP181
A
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
