基于動態可配置規則的數據清洗方法
2017-06-27 08:10:36朱會娟蔣同海
計算機應用 2017年4期
朱會娟,蔣同海,周 喜,程 力,趙 凡,馬 博
1.中國科學院新疆理化技術研究所 多語種信息技術研究室, 烏魯木齊 830011;2.中國科學院大學 計算機與控制學院, 北京 100049; 3.新疆民族語音語言信息處理重點實驗室, 烏魯木齊 830011)(*通信作者電子郵箱chengli@ms.xjb.ac.cn)
基于動態可配置規則的數據清洗方法
朱會娟1,2,3,蔣同海1,3,周 喜1,3,程 力1,3*,趙 凡1,3,馬 博1,3
1.中國科學院新疆理化技術研究所 多語種信息技術研究室, 烏魯木齊 830011;2.中國科學院大學 計算機與控制學院, 北京 100049; 3.新疆民族語音語言信息處理重點實驗室, 烏魯木齊 830011)(*通信作者電子郵箱chengli@ms.xjb.ac.cn)
針對傳統數據清洗方法通過硬編碼方法來實現業務邏輯而導致系統的可重用性、可擴展性與靈活性較差等問題,提出了一種基于動態可配置規則的數據清洗方法——DRDCM。該方法支持多種類型規則間的復雜邏輯運算,并支持多種臟數據修復行為,集數據檢測、數據修復與數據轉換于一體,具有跨領域、可重用、可配置、可擴展等特點。首先,對DRDCM方法中的數據檢測和數據修復的概念、實現步驟以及實現算法進行描述;其次,闡述了DRDCM方法中支持的多種規則類型以及規則配置;最后,對DRDCM方法進行實現,并通過實際項目數據集驗證了該實現系統在臟數據修復中,丟棄修復行為具有很高的準確率,尤其是對需遵守法定編碼規則的屬性(例如身份證號碼)處理時其準確率可達100%。實驗結果表明,DRDCM實現系統可以將動態可配置規則無縫集成于多個數據源和多種不同應用領域且該系統的性能并不會隨著規則條數增加而極速降低,這也進一步驗證了DRDCM方法在真實環境中的切實可行性。
大數據;數據質量;數據清洗;動態可配置規則;數據預處理
0 引言
對幾個著名的公司數據進行研究,其中有25%的重要數據是存在缺陷的[1],由它帶來的經濟損失也是驚人的,據統計,“臟數據”導致美國商業每年約損失6 000億美元[2]。在大數據時代,數據預處理已經成為一個重要的研究課題,吸引了越來越多學術界和工業界研究人員的注意,根據調查顯示,數據質量工具的市場正以每年17%的速度增長,遠遠高出IT行業中其他分支平均7%的增長速度[3]。
典型的數據預處理過程如圖1所示,左邊的方框表示原始數據集,其中包括結構化數據、半結構化數據和非結構化數據。中間的方框表示數據預處理的兩個主要任務即數據轉換和數據清洗。數據轉換(Data Transformation)是指從原始數據中提取數據,并將其轉換成適合進一步分析的數據格式的過程。數據清洗(Data Cleaning、 Data Cleansing或者Data Scrubbing)主要用來檢測數據中存在的異常數據(例如錯誤、缺失、不一致等)[4]并去除或修正它們,最終目的就是提高數據的質量[5-6]。
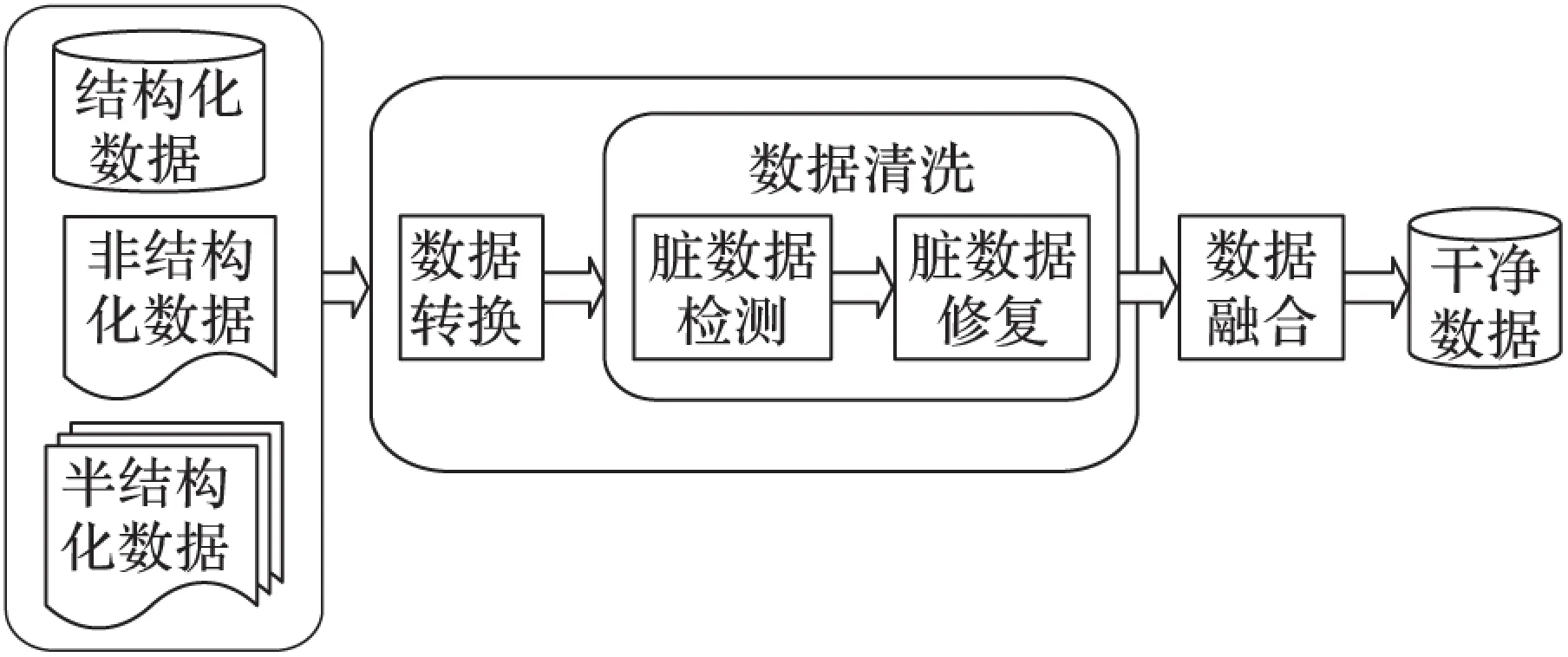
圖1 典型的數據預處理過程
在過去的十幾年中,數據清洗領域得以飛速發展,衍生出了許多數據清洗方法和系統,基于規則的數據清洗方法因為其自身的簡單易實現并且清洗效果顯著等特點使其在數據清洗領域一直扮演著一個重要的角色[7-8]。文獻[9]對數據質量問題作了詳細的分類和分析,并以判定樹的形式給出了檢測方法,從而有力地支持了基于規則的數據清洗技術的現實可行性。本文對現有的一些基于規則的數據清洗方法,例如NADEEF(A Commodity Data Cleaning System)、AzszpClean (A Rule-based Solution to Data Cleaning)等進行了研究并概括如表1。
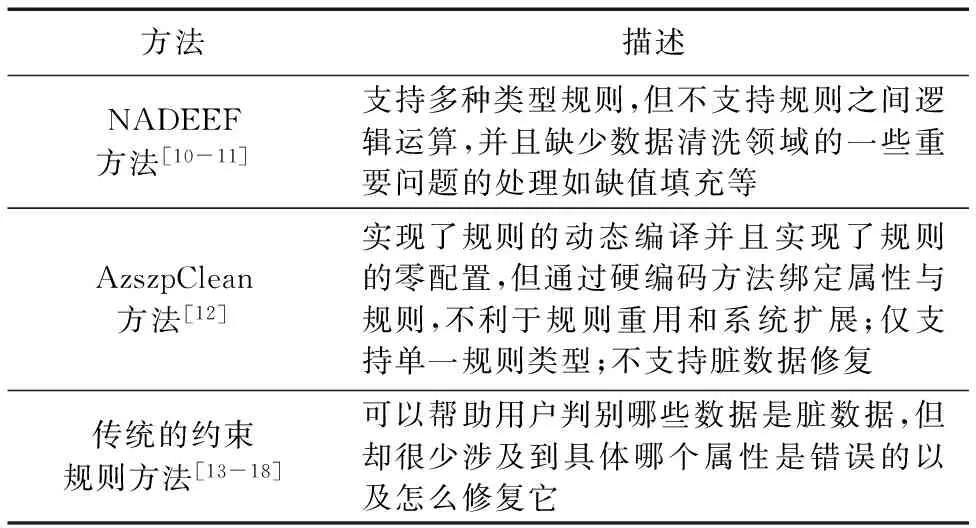
表1 基于規則的數據清洗方案的比較
目前大多數的數據清洗工具或框架都是針對某些特定領域,如果用戶需引入新的規則或是復用其他領域的一些規則(例如檢查身份證號的規則在很多領域是通用的)則十分困難,而且擴展現有解決方案或部署這些方案到自己系統中也十分艱巨[13,19-21];目前還有一些清洗工具的臟數據檢測和修復借助硬編碼來實現[5],這會導致系統的可擴展性和靈活性較差,當清洗規則發生變化時清洗部分的代碼需要重新實現,并且硬編碼方法對數據清洗的描述性較弱,在實現復雜邏輯方面的數據清洗時會比較困難,而且用戶的理解度和接受度較低;另外,有一些清洗工具是借助人工判斷來完成臟數據檢測和修復[22],該類方法在數據量較小時具有高準確性的優勢,但在數據量龐大且多源異構的情況下劣勢會愈發明顯。
1 DRDCM方法
基于以上問題,本文提出了一種基于動態可配置規則的數據清洗方法(Dynamic Rule-based Data Cleaning Method, DRDCM),這是一種跨領域的、可重用的、可配置的將臟數據檢查與臟數據修復以及數據轉換三者融為一體的新方法。該方法支持多種規則類型以及規則間的復雜邏輯運算;支持三種臟數據修復行為:保留(RETAIN)、丟棄(DISCARD)和回填(REFILL);支持用戶在運行時增加、刪除或修改規則等。
1.1 DRDCM相關定義
圖2為DRDCM的數據清洗過程。
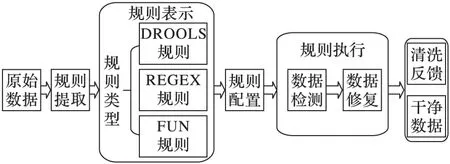
圖2 DRDCM的數據清洗過程
首先,用戶對原始數據分析提取規則,在DRDCM支持三種類型規則,分別是:DROOLS(JBoss Rules)規則、REGEX(Regular Expression)規則和FUN(Function)規則。在規則配置階段實現規則與屬性、表以及領域的綁定。其中規則執行包括兩部分即數據檢測以及根據檢測結果進行數據修復。DRDCM中涉及到的相關定義如下:
定義1 數據清洗(Data Cleaning)。數據清洗是把原始輸入數據通過一系列的數據檢測和數據修復后轉換為干凈數據的過程,可以形式化表示為:
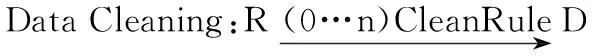
其中:R代表原始數據;D代表干凈數據。
定義2 數據檢測(Data Check)。用來檢測數據是否符合既定知識的過程,可用謂詞函數表示為CHECKCOND:D →{T, F}:
CHECKCOND(d)=T表示待檢測數據項d是符合清洗規則的數據,即為“干凈數據”,直接存入干凈數據庫;
CHECKCOND(d)=F表示待檢測數據項d是不符合清洗規則的數據,即為“臟數據”,需要進一步作數據修復(見定義3);
定義3 數據修復(Data Revise)。根據數據檢測的結果,如果為F則需要對原數據進行修改,DRDCM支持三種修改行為:保留(RETAIN)、丟棄(DISCARD)和回填(REFILL)。
定義4 DROOLS規則。抽取的規則可以通過Drools語法[23]清晰表達的,均定義為DROOLS規則類型,形如“rule 〈name〉 attributes; when 〈LHS〉; then 〈RHS〉; end”。
定義5 REGEX規則。抽取的規則可以通過Java正則表達式[24]清晰表達的,均定義為REGEX規則類型,例如“18位身份證號且支持以X結尾”,可以定義為正則表達式“(^[1-9]([0-9]{16}|[0-9]{13})[xX0-9]$)”。
定義6 FUN規則。抽取的規則通過DROOLS規則和REGEX規則均無法表達的,可以定義為FUN規則,例如一些時間函數、轉換函數和數學函數等。
定義7 清洗規則(Clean Rule)。本文提出的清洗規則可用四元組表示為:
CleanRule ::=〈Number, Rule Type, Data Check, Data Revise〉
其中:Number是由規則組號和規則號組成;Rule Type見定義4~6;Data Check見定義2;Data Revise見定義3。
1.2 DRDCM方法的組成
DRDCM方法主要包括如下幾個組成部分:
規則模板 即規則實體定義,方便用戶閱讀、定義以及修改規則。
規則庫 集中保存跨領域的所有規則,以規則組號和規則號組合為唯一標識,以便進行規則的管理與重用。
規則配置與存儲 處理在實際清洗過程中規則實體與屬性、表、領域等的匹配關系,支持復雜邏輯描述表達式如:((規則1‖規則2)&& !規則3),支持二元組〈屬性名,規則表達式〉、三元組〈表名,屬性名,規則表達式〉和四元組〈領域名,表名,屬性名,規則表達式〉等。
規則引擎 是規則的運行環境,用來編譯和執行規則。
數據清洗反饋類 負責將清洗結果和存在問題反饋給用戶。
1.3 DRDCM方法的特點
相較于其他基于規則的數據清洗方法,DRDCM方法具備以下幾個特點:
1)DRDCM采用低耦合的設計模式,因此將業務規則與業務系統分離。
2)DRDCM采用規則的動態編譯方法,不僅具備堅實的編譯理論基礎,而且可以方便地在線修改和增刪規則,方便應對特殊狀況,比如用戶一開始沒有考慮到引入規則或是規則引入有誤或引入規則不足以表達實際需求等情況。
3)DRDCM方法中規則的定義遵循最小化原則(即規則不可再被拆分為其他子規則),給數據清洗的復雜邏輯描述以及多領域規則重用打下基礎。
4)DRDCM方法中將數據轉換與規則配置相結合,使單源數據或多源數據在集成的同時,完成數據清洗和修復,避免數據多次導入導出。
5)DRDCM支持三種規則類型,避免單一規則類型的局限性,能夠較全面地描述真實數據集中可以提取的規則。
6)DRDCM實現一種新的規則引擎,可以支持復雜的邏輯表達式和不同層次的規則配置,如屬性、表和領域。
1.4 DRDCM方法的工作模式
DRDCM方法的工作模式如下:首先,對原始數據集進行分析并提取有效規則,通過規則定義界面將這些規則錄入并存儲進規則庫中,其中規則的定義必須符合規則模板。接下來是數據轉換,周傲英教授在文獻[25]中闡述了數據轉換的重要性,對多源異構數據進行分析,從非結構化、半結構化的源數據中抽取結構化信息來定義XML模型從而完成數據轉換。在DRDCM方法中,是在數據轉換的過程中完成規則配置,規則配置形如:
1.5 算法設計
DRDCM支持三種不同類型的數據清洗規則,如何把這些規則行之有效地部署到實際應用中是其中一個關鍵。因此需要設計出一套切實有效的算法來自動地進行數據清洗。
算法1 數據清洗算法。
Input: DRL:待清洗記錄集; AttributeInfoBeanMap: 存儲記錄集中屬性的元數據。 // 類型為Map
Output: CleanRL: 干凈的記錄集。
1)
CleanRL ←{};
//存儲干凈的記錄集,初始化為空
2)
ruleExp="";
//初始化規則表達式
3)
ruleQuene←new LinkedList<>();
//初始化規則隊列為空,用于存儲規則實體
4)
checkValueMap← new Map
//用于存儲規則的檢查結果,key值為規則編號
5)
For each record in DRL Do
6)
cleanRecord←record;
//用于存儲修復后的干凈記錄
7)
For each attribute∈ record Do
8)
If (AttributeInfoBeanMap.get(attribute) !=null)
9)
ruleExp ← 讀取對應AttributeInfoBean中的規則表達式;
//形如"1_4 or 1_5 or 1_6"
10)
ruleQuene← ruleExp中所有規則號對應的規則實體ruleEntity;
11)
For each ruleEntity in ruleQuene Do
12)
ruleType ← ruleEntity.getRuleType;
13)
If (ruleType=="DROOLS")
14)
checkValue← Call DroolsSemErr;
15)
Else if(ruleType=="REGEX")
16)
checkValue←Call RegextSemErr;
17)
Else If(ruleType=="FUN")
18)
checkValue ←Call FunSemErr;
19)
checkValueMap.put(ruleNumber, checkValue);
20)
expCheckValue←runLogicalExp(ruleExp, checkValueMap)
21)
if (expCheckValue== false)
22)
cleanRecord←call 數據修復算法更新cleanRecord;
23)
If (cleanRecord==null)
24)
break;
//退出循環
25)
End For each attribute;
26)
If (cleanRecord!=null)
27)
CleanRL.add(cleanRecord);
28)
End For each record;
29)
return CleanRL;
在算法2中,RetainNumMap為Map
算法2 數據修復算法。
Input: Record: 待修復的記錄; AtrributeName: 待修復的屬性名; Action: 修復動作; RetainNumMap:
//Map
Output: ModifiedRecord:被修復后的記錄。
1)
modifiedRecord ← Record;
2)
if (Action==DISCARD)
3)
modifiedRecord=null;
4)
If (Action==RETAIN)
5)
更新RetainNumMap;
6)
If (Action==REFILL)
7)
//根據屬性所屬類型選擇回填值;
8)
If (AtrributeName是枚舉型屬性)
9)
ModifiedRecord←ModifiedRecord.setAttribute (AtrributeName, MaxFreqValue);
// MaxFreqValue為該屬性中出現頻率最高的屬性值
10)
If (AtrributeName是數值型屬性)
11) ModifiedRecord←ModifiedRecord.setAttribute (AtrributeName, MeanValue);
// MeanValue為該屬性值的樣本均值
12)
If (AtrributeName是日期型屬性)
13)
轉換日期型格式,如果為空值參考字符串型處理方法;
14)
If(AtrributeName是字符串型屬性)
15)
尋找重復記錄或最鄰近記錄對應的屬性值作為填充值;
16)
return ModifiedRecord;
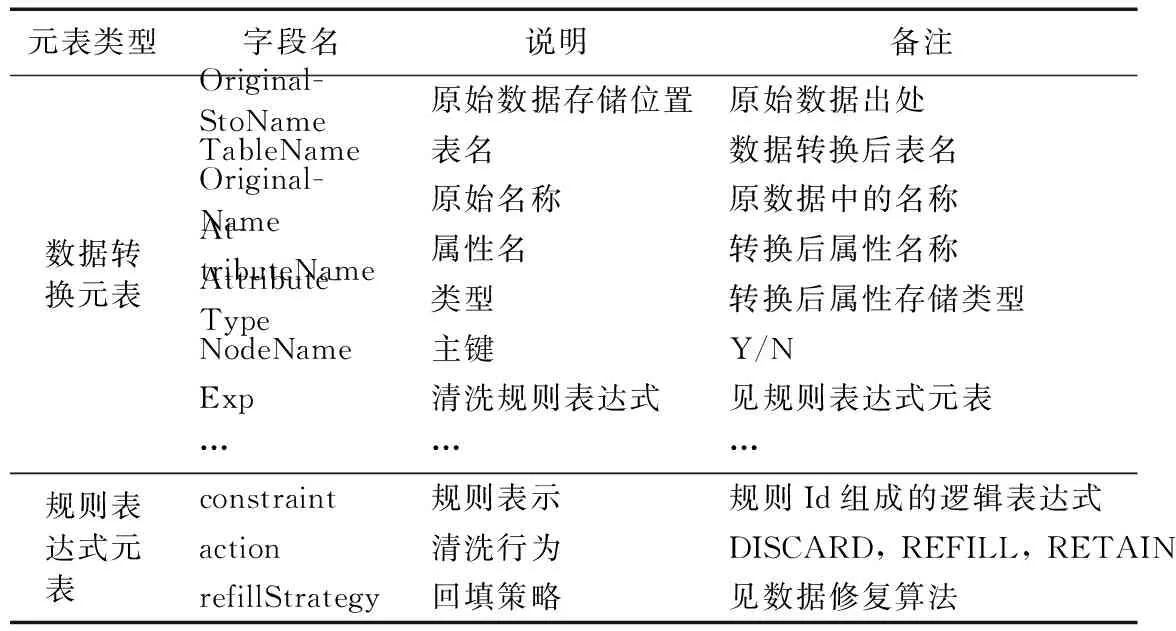
表2 元表(部分)
2 DRDCM參考實現系統
2.1 DRDCM系統架構
DRDCM系統的總體架構如圖3所示,主要有數據導入模塊,它給結構化、非結構化數據以及半結構化數據的導入提供了一個統一的接口,這樣就可以實現綜合的管理,提高整體的使用效率,減少今后維護的成本;數據轉換與規則配置模塊,該模塊的主要任務是將結構化、非結構化以及半結構化數據轉換為方便后期進行數據分析的統一格式,并通過該模塊將規則與屬性、表以及領域進行匹配;規則收集模塊(包括規則模板、規則定義界面和規則庫等),該模塊主要功能是從原始數據中抽取規則并進行定義和存儲規則;規則執行核心模塊(包括規則引擎、規則編譯、數據檢測和數據修復等),主要功能是執行數據清洗規則以及對原始數據進行修正以獲取干凈數據;數據輸出模塊(包括清洗反饋和干凈數據存儲)。
2.2 清洗規則
清洗規則可以表示為:
RULE(n, t, c, o, v)
n: 規則的名稱(字母、數字和下劃線組成);
t:規則的類型(t∈{DROOLS, FUN, REGEX});
c:清洗檢測(c∈RegexSemErr, DroolsSemErr, FunSemErr);
o:規則的操作符(o∈{ BELONGTO, NOTBELONGTO, CONTAINS, NOTCONTAINS, MATCHS, NOTMATCHS, GREATER, LESS, EQUAL, NOTEQUAL, INNER, OUTSIDE, SATISFY, NOT SATISFY});
v:標準值或標準值域。
BELONGTO與NOTBELONGTO描述個體與集合的關系,例如: 1∈{1, 2, 3}、4?{1, 2, 3};CONTAINS 與 NOTCONTAINS描述集合與集合的關系,例如:{1}?{1, 5, 6}、{1}?{4, 5, 6};GREATER、GREATEREQ、LESS、LESSEQ、EQUAL、 NOTEQUAL、 INNER、OUTSIDE分別表示大于、大于等于、小于、小于等于、等于、不等于、在區間內和在區間外,其中INNER、OUTSIDE可以通過GREATER(GREATEREQ)與LESS(LESSEQ)的“∧”運算實現。
規則操作符的定義:
BELONGTO ?∈
NOTBELONGTO ??
CONTAINS ??
NOTCONTAINS ??
GREATER ?>
GREATEREQ ?≥
LESS ?<
LESSEQ ?≤
EQUAL ?=
NOTEQUAL ?≠

圖3 DRDCM參考實現系統的總體架構
2.3 規則引擎
DRDCM參考實現系統的規則引擎分三個步驟:
步驟1 解析規則配置文件,其中配置文件涉及到的數據轉換元表和規則表達式元表,如表2所示。
步驟2 在將原數據進行數據轉換時讀取元數據模型中的規則表達式Exp,并根據規則類型調用對應的規則執行文件,本文有三種規則類型,對應的規則執行文件提供的接口分別為:
RegextSemErr(Object d1, ExpEntity e1)
DroolsSemErr(Object d1, ExpEntity e1)
FunSemErr(Object d1, ExpEntity e1)
其中:d1為待清洗數據;e1表示規則實體。這三個接口用來完成每條規則的數據檢測。
步驟3 計算規則表達式的值,如果為F則調用數據修復模塊進行數據修復,最終存入干凈數據庫。
2.4 規則配置
規則是從一些領域知識或是復雜商業邏輯中提取出來的,不同領域的原始數據集中會存在一些共有的信息,例如對人的信息采集,包括人的性別、身份證號碼、族別、出生日期、年齡等信息,而從這些基本信息中可以抽取到的規則有:性別只有男/女,身份證號碼18位支持X字母結尾,民族只能是56個民族中的其中一個(中國公民),出生日期的日期格式,等等。在DRDCM系統中,規則從領域知識中提取但又不依賴于領域,規則庫中的規則可以跨領域進行重用。
DRDCM系統根據規則的關聯號把規則分為若干個分組,并以〈規則組號-規則號〉為索引來匹配和執行規則,大大降低了時間復雜度。基于這個原則進行規則配置,當用戶修改規則時,規則引擎無需作任何改動;當用戶增加或刪除規則時,僅需要改動規則配置模塊,規則引擎和其他模塊無需作任何改動,從而極大提高了系統的重用性、擴展性和靈活性。
規則配置中涉及到規則表達式用二元組表示為:
RL=〈RN, LC〉
RN是規則組號-規則號,用來唯一標識一個規則。LC是邏輯連接詞,用“not”代表“(否定)”、用“and” 代表“∧(合取)”、用“or”代表“∨(析取)”、用“ifThen”代表“→(蘊涵)”、用“EQ”代表“?(等價)”。
規則配置支持如下幾種格式:
1)Expc::=〈A, RL〉,用來表達單個屬性下的規則約束;
2)Expc::=〈T, A, RL, LC〉,用來表達以表為單位的規則約束;
3)Expc::=〈D,T, A, RL, LC〉,用來表示不同領域下的規則約束。
其中:A代表屬性名;T代表表名;LC是邏輯連接詞;D代表領域名。
在XML規則配置文件中,Expc::=〈A, RL〉格式如下所示:
3 實際應用
面向公安、國安等地區大數據分析的需求,結合工信部物聯網發展專項的“新疆電梯安全動態監管物聯網系統研發與應用”的數據,以及國家發改委物聯網重大專項的“基于物聯網技術的車載氣瓶電子監管系統及產業化”的數據。采用DRDCM系統對這些原始數據進行清洗,從而保障數據檢索、數據分析以及分析結果展示的準確性。
在實驗部分通過以下三個方面來展示該系統的性能:1)給出該系統的輸入輸出數據;2)給出該系統數據清洗的準確性;3)給出該系統數據清洗的效率。
3.1 數據采集
該數據集共計10.7 GB,時間跨度為2016年1月到2016年5月。數據采集方式有三種:第一種是通過具備NFC功能的智能手機或其他智能手持設備獲取;第二種是通過人工錄入;第三種是和其他系統對接來導入數據。
“新疆電梯安全動態監管物聯網系統研發與應用” 和“基于物聯網技術的車載氣瓶電子監管系統及產業化” 兩個項目中都引入了近距離無線通信技術(Near Field Communication, NFC),它是工作在13.56 MHz頻率,有效距離在20 cm內。事實上,操作距離以及嵌入手機或其他手持設備的NFC設備自身的靈敏度都會影響到從電子標簽中讀取數據。第二種采集方法中,排除紙質材料本身的完整性,在人工錄入時難免會存在錯錄或少錄的情況。在第三種采集方法中,數據來自不同系統,因此數據具有異構、多源、分布式、時間跨度大等特點,這些數據中不可避免地會存在著一些粗糙的、不合時宜的數據。
3.2 評價標準
為了驗證本文方法在丟棄記錄與回填記錄的有效性,本文引入準確率Accuracy來評定,其定義如下:
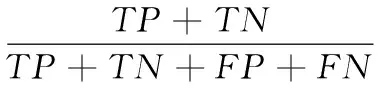
(1)
其中:TP是真正例的個數,即不符合清洗規則且被正確地執行了丟棄或回填動作的屬性值個數;TN是真負例的個數,即屬性值本身為干凈數據且沒有被執行任何修復動作的屬性值個數;FP是假正例的個數;FN為假負例的個數。TP+TN+FP+FN為樣本總數。總而言之,準確率就是被正確處理的樣本數除以所有的樣本數,通常來說,準確率越高,則處理效果越好。
3.3 實驗結果以及分析
實驗1 限于篇幅和所屬項目數據本身的保密性,本文僅給出其中一個數據表的部分信息(如表3中的輸入數據所示)作數據清洗描述,該測試數據來源是經數據轉換后的結構化數據。
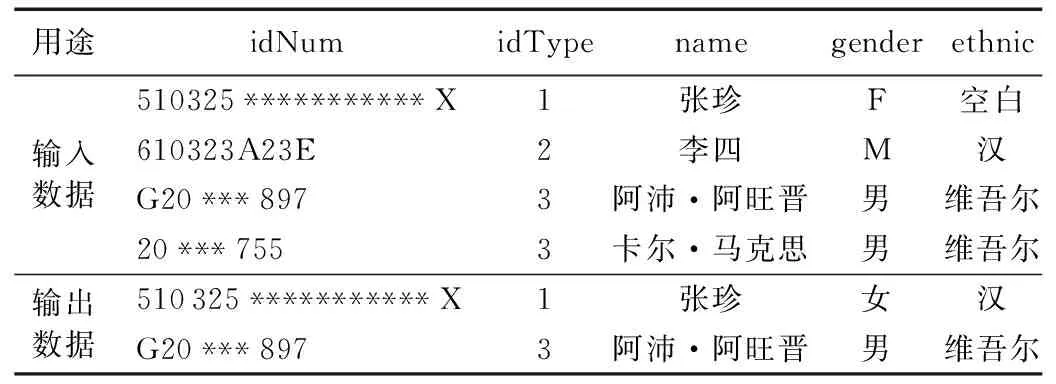
表3 測試數據(部分)
表1中:“idType”屬性中值1代表“idNum”中存儲的是“身份證”, 值2表示的是“組織機構”,其中組織機構是由8位數字組成,值3表示的是“護照”。另外因為涉及隱私問題,表3中所列數據中的身份證號碼、護照號和姓名都經過了替換處理,并且某些數字用“*”號代替。其中idNum的規則配置見2.4節中的示例({"constraint":"1_4or1_5or1_6","ruleAction":"DISCARD"})。
因篇幅原因,只列舉在規則配置文件中的兩條規則作為示例。
規則1_4是正則表達式類型規則,用于檢測身份證號碼的合法性。規則3_1是函數類型規則,它的作用是將gender屬性中的“F”值替換為“女”、“M”替換為“男”。在規則配置時,因為idNum是該表的主鍵,如果idNum不符合清洗規則表達式,則表示該條記錄為無效記錄予以丟棄。
經DRDCM系統進行清洗后,表3中輸入數據部分的第一條記錄中ethnic屬性值被回填為“漢”另外,第2條和第4條因idNum不符合清洗規則表達式所以予以丟棄,具體清洗結果如表3中輸出數據部分所示。
如果使用硬編碼方法實現就需要冗長的if…else語句實現,硬編碼方式不僅容易引入錯誤,而且修改起來相當困難,對不同的應用難以復用。而DRDCM方法僅需幾條規則即可,在代碼實現部分無需任何改動,極大地方便和簡化了數據清洗和修復的流程。
實驗2 每次隨機抽取記錄,重復20次,統計出有多少條記錄被拋棄、多少屬性值被回填以及它們的準確率。在本次實驗中,用到的規則數量分別是5、10和20。數據清洗的統計結果如表4所示,實驗結果表明丟棄記錄的準確率是可以接受的,但是回填記錄的準確率有待提高,這在本項目目前正在開發的數據清洗和數據融合系統中會進一步完善。
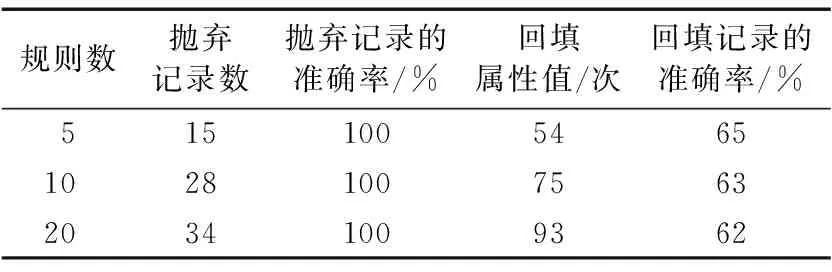
表4 DRDCM系統的準確率
實驗3 對DRDCM的清洗效率進行了實驗,并與硬編碼(HardCoding,HardCode)方法作了對比。在圖4中,橫坐標表示實驗中所使用的規則條數,縱坐標表示在對應的規則條數上執行10條、100條、1 000條和10 000條記錄所消耗的時間。從圖4可知,隨著規則數量的增加,性能緩慢下降,說明DRDCM系統的性能和規則條數的相關度不是很大。
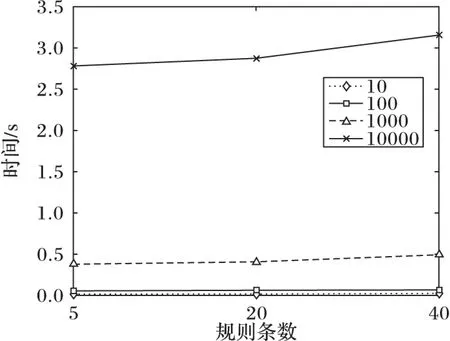
圖4 DRDCM系統的效率
在圖5中給出了DRDCM與HardCode性能的比較。由圖5可知,在規則數為5時DRDCM系統在性能上要略差于HardCode方法;但隨著規則數增長,當規則數為20時和40時,DRDCM系統和HardCode的性能差距越來越小。另外,規則數量的增加,對HardCode和DRDCM系統的影響基本趨于一致。雖然較之HardCode,在性能上DRDCM系統的優勢并不明顯,但是DRDCM可以使用形式化語言描述規則的復雜邏輯運算,且易于用戶理解和接受;DRDCM把業務規則和業務系統進行分離,也更方便用戶的擴展與修改,以及一些突發情況的處理;另外,DRDCM方法支持規則的跨領域重用、配置等。
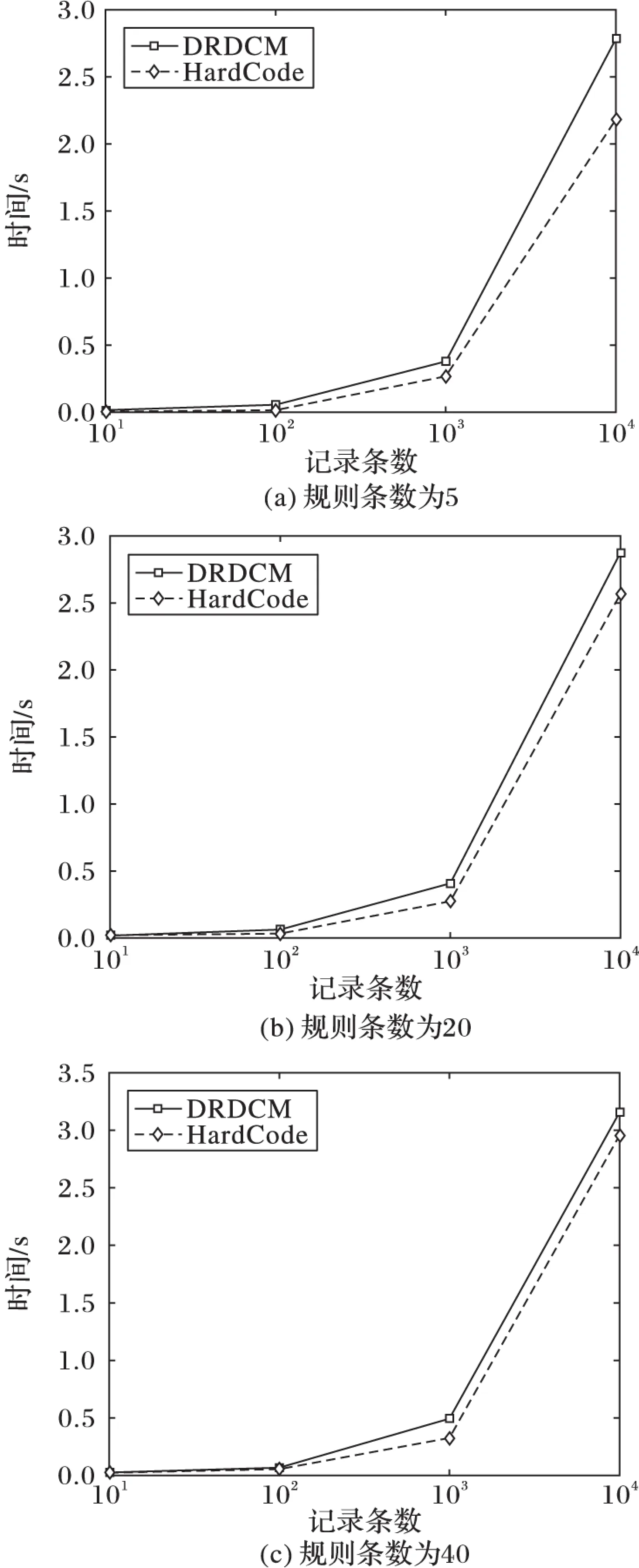
圖5 DRDCM與HardCode的性能比較
4 結語
本文通過對現有數據清洗方法特別是基于規則的數據清洗方法進行詳細研究后,提出了一種新的基于動態可配置規則的數據清洗方法DRDCM,將規則配置、數據轉換、數據檢測以及數據修復融為一體;支持跨領域多源數據的規則重用;DRDCM方法支持三種類型的規則并提供對應接口實現,可以避免單一規則對源數據特征描述時的局限性。另外,本文對DRDCM方法提出一種參考實現系統,它支持規則的動態編譯,利用該系統用戶可以方便地對規則進行閱讀、抽取、新增、修改和刪除等操作,并且支持規則的復雜邏輯描述等,綜合上述改進使該系統具備靈活性和擴展性。該系統已部署在工信部物聯網發展專項的“新疆電梯安全動態監管物聯網系統研發與應用”和國家發改委物聯網重大專項的“基于物聯網技術的車載氣瓶電子監管系統及產業化”項目中,在這些項目中的實際運行情況以及獲取到的真實數據集進一步驗證了該方法在現實場景下的可行性。
)
[1]SWARTZN.Gartnerwarnsfirmsof“dirtydata” [J].InformationManagementJournal, 2007, 41(3): 6-7.
[2]ECKERSONWW.Dataqualityandthebottomline:achievingbusinesssuccessthroughacommitmenttohighqualitydata[EB/OL]. [2016- 03- 10].http://download.101com.com/pub/tdwi/Files/DQReport.pdf.
[3]GRAHAMC.Forecast:dataqualitytools,worldwide, 2006-2011 [EB/OL]. [2016- 03- 10].https://www.gartner.com/doc/507207/forecast-data-quality-tools-worldwide.
[4] 覃遠翔, 段亮, 岳昆. 基于信息熵的不確定性數據清理方法[J]. 計算機應用, 2013, 33(9): 2490-2492.(QINYX,DUANL,YUEK.Approachforcleaninguncertaindatabasedoninformationentropytheory[J].JournalofComputerApplications, 2013, 33(9):2490-2492.)
[5]RAHME,DOHH.Datacleaning:problemsandcurrentapproaches[J].IEEEDataEngineeringBulletin, 2000, 23(4): 3-13.
[6] 楊明花, 古志民. 基于興趣特征的WUM數據預處理方法[J]. 計算機應用, 2006, 26(10): 133-134.(YANGMH,GUZM.DatapreprocessingmethodbasedoncharacteristicofinterestsforWUM[J].JournalofComputerApplications, 2006, 26(10):2393-2388.)
[7]GALHARDASH,FLORESCUD,SHASHAD,etal.Declarativedatacleaning:language,model,andalgorithms[C]//VLDB2001:Proceedingsofthe27thInternationalConferenceonVeryLargeDataBases.SanFrancisco:MorganKaufmannPublishers, 2001: 371-380.
[8]VOLKOVSM,CHIANGF,SZLICHTAJ,etal.Continuousdatacleaning[C]//Proceedingsofthe2014IEEE30thInternationalConferenceonDataEngineering.Piscataway,NJ:IEEE, 2014: 244-255.
[9]OLIVEIRAP,RODRIGUESF,HENRIQUESP,etal.Ataxonomyofdataqualityproblems[EB/OL]. [2016- 03- 10].https://www.researchgate.net/profile/Helena_Galhardas/publication/250693546_A_Taxonomy_of_Data_Quality_Problems/links/02e7e5347984 84567c000000.pdf.
[10]EBAIDA,ELMAGARMIDA,ILYASIF,etal.NADEEF:ageneralizeddatacleaningsystem[J].ProceedingsoftheVLDBEndowment, 2013, 6(12): 1218-1221.
[11]DALLACHIESAM,EBAIDA,ELDAWYA,etal.NADEEF:acommoditydatacleaningsystem[C]//Proceedingsofthe2013ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM, 2013: 541-552.
[12] 李俊奎, 王元珍, 李專.AzszpClean: 一種基于規則的數據清洗方案[J]. 山東大學學報(理學版), 2007, 42(9):71-74.(LIJK,WANGYZ,LIZ.AzszpClean:arule-basedsolutiontodatacleaning[J].JournalofShandongUniversity(NaturalScience), 2007, 42(9):71-74.)
[13]BOHANNONP,FANW,FLASTERM,etal.Acost-basedmodelandeffectiveheuristicforrepairingconstraintsbyvaluemodification[C]//Proceedingsofthe2005ACMSIGMODInternationalConferenceonManagementofData.NewYork:ACM, 2005: 143-154.
[14]CHOMICKJJ,MARCINKOWSKIJ.Minimal-changeintegritymaintenanceusingtupledeletions[J].InformationandComputation, 2005, 197(1): 90-121.
[15]WIJSENJ.Databaserepairingusingupdates[J].ACMTransactionsonDatabaseSystems, 2005, 30(3): 722-768.
[16]FANW,GEERTSF,JIAX,etal.Conditionalfunctionaldependenciesforcapturingdatainconsistencies[J].ACMTransactionsonDatabaseSystems, 2008, 33(2): 6.
[17]BRAVOL,FANW,MAS.Extendingdependencieswithconditions[EB/OL]. [2016- 03- 10].http://www.vldb.org/conf/2007/papers/research/p243-bravo.pdf.
[18]GOLABL,KARLOFFH,KORNF,etal.Ongeneratingnear-optimaltableauxforconditionalfunctionaldependencies[J].ProceedingsoftheVLDBEndowment, 2008, 1(1): 376-390.
[19]CHUX,ILYASIF,PAPOTTIP.Holisticdatacleaning:putviolationsintocontext[C]//Proceedingsofthe2013IEEE29thInternationalConferenceonDataEngineering.Piscataway,NJ:IEEE, 2013:458-469.
[20]FANW,MAS,TANGN,etal.Interactionbetweenrecordmatchinganddatarepairing[J].JournalofDataandInformationQuality, 2014, 4(4):ArticleNo16.
[21]YAKOUTM,ELMAGARMIDAK,NEVILLEJ,etal.Guideddatarepair[J].ProceedingsoftheVLDBEndowment, 2011, 4(5): 279-289.
[22]VWRBORGHR,DEWM.UsingOpenRefine[M].Birmingham:PacktPublishing, 2013:53.
[23]PROCTORM,NEALEM,LINP,etal.Droolsdocumentation[EB/OL]. [2016- 03- 10].http://www.jboss.org/drools/documentation.html.
[24] 丁晶, 陳曉嵐, 吳萍. 基于正則表達式的深度包檢測算法[J]. 計算機應用, 2007, 27(9): 2184-2186.(DINGJ,CHENXL,WUP.Deeppacketinspectionalgorithmbasedonregularexpressions[J].JournalofComputerApplications, 2007, 27(9):2184-2186.)
[25] 周傲英, 金澈清, 王國仁, 等. 不確定性數據管理技術研究綜述[J]. 計算機學報, 2009, 32(1): 1-16.(ZHOUAY,JINCQ,WANGGR,etal.Asurveyonthemanagementofuncertaindata[J].ChineseJournalofComputers, 2009, 32(1):1-16.)
ThisworkispartiallysupportedbytheXinjiangHigh-TechR&DProgram(201512103),theWestLightFoundationoftheChineseAcademyofSciences(XBBS201313),theXinjiangYoungScholarSupportProgram(2014721033).
ZHU Huijuan, born in 1984, Ph. D. candidate. Her research interests include data cleaning, data fusion, data analysis.
JIANG Tonghai, born in 1963, Ph. D., research fellow. His research interests include data fusion, data analysis, data mining.
ZHOU Xi, born in 1978, Ph. D., research fellow. His research interests include data cleaning, data fusion, data analysis.
CHENG Li, born in 1973, Ph. D., research fellow. His research interests include cloud computing, grid computing, high performance computing, data fusion.
ZHAO Fan, born in 1980, Ph. D. candidate, associate research fellow. His research interests include bilingual teaching, data visualization analysis.
MA Bo, born in 1984, Ph. D., associate research fellow. His research interests include semantic retrieval, data mining, knowledge discovery, data analysis.
Data cleaning method based on dynamic configurable rules
ZHU Huijuan1,2,3, JIANG Tonghai1,3, ZHOU Xi1,3, CHENG Li1,3*, ZHAO Fan1,3, MA Bo1,3
(1. Research Center for Multilingual Information Technology, Xinjiang Technical Institute of Physics and Chemistry, Chinese Academy of Sciences, Urumqi Xinjiang 830011, China;2. School of Computer and Control Engineering, University of Chinese Academy of Sciences, Beijing 100049, China;3. Xinjiang Laboratory of Minority Speech and Language Information Processing, Urumqi Xinjiang 830011, China)
Traditional data cleaning approaches usually implement cleaning rules specified by business requirements through hard-coding mechanism, which leads to well-known issues in terms of reusability, scalability and flexibility. In order to address these issues, a new Dynamic Rule-based Data Cleaning Method (DRDCM) was proposed, which supports the complex logic operation between various types of rules and three kinds of dirty data repair behavior. It integrates data detection, error correction and data transformation in one system and contributes several unique characteristics, including domain-independence, reusability and configurability. Besides, the formal concepts and terms regarding data detection and correction were defined, while necessary procedures and algorithms were also introduced. Specially, the supported multiple rule types and rule configurations in DRDCM were presented in detail. At last, the DRDCM approach was implemented. Experimental results show that the implemented system provides a high accuracy on the discarded behavior of dirty data repair with real-life data sets. Especially for the attribute required to comply with the statutory coding rules (such as ID card number), whose accuracy can reach 100%. Moreover, these results also indicate that this reference implementation of DRDCM can successfully support multiple data sources in cross-domain scenarios, and its performance does not sharply decrease with the increase of the number of rules. These results further validate that the proposed DRDCM is practical in real-world scenarios.
big data; data quality; data cleaning; dynamic configurable rules; data preprocessing
2016- 09- 20;
2016- 12- 22。 基金項目:新疆維吾爾自治區高技術研究發展計劃項目(201512103);中國科學院西部之光人才培養計劃項目(XBBS201313);新疆維吾爾自治區青年科技創新人才培養工程計劃項目(2014721033)。
朱會娟(1984—),女,河南洛陽人,博士研究生,主要研究方向:數據清洗、數據融合、數據分析; 蔣同海(1963—),男,新疆福海人,研究員,博士生導師,博士,主要研究方向:數據融合、數據分析、數據挖掘; 周喜(1978—),男,湖南雙峰人,研究員,博士,主要研究方向:數據清洗、數據融合、數據分析; 程力(1973—),男,新疆烏魯木齊人,研究員,博士生導師,博士,CCF會員,主要研究方向:云計算、網格計算、高性能計算、數據融合; 趙凡(1980—),男,山西介休人,副研究員,博士研究生,主要研究方向:雙語教學、數據可視化分析; 馬博(1984—),男,遼寧鞍山人,副研究員,博士,主要研究方向:語義檢索、數據挖掘、知識發現、數據分析。
1001- 9081(2017)04- 1014- 07
10.11772/j.issn.1001- 9081.2017.04.1014
TP311.11
A
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
