基于i-vector和深度學習的說話人識別
2017-06-27 08:14:13林舒都
計算機技術與發展 2017年6期
林舒都,邵 曦
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
基于i-vector和深度學習的說話人識別
林舒都,邵 曦
(南京郵電大學 通信與信息工程學院,江蘇 南京 210003)
為了提高說話人識別系統的性能,在研究基礎上提出了一種將深度神經網絡(Deep Neural Nerwork,DNN)模型成果與i-vector模型相結合的新方案。該方案通過有效的神經網絡構建,準確地提取了說話人語音里的隱藏信息。盡管DNN模型可以幫助挖掘很多信息,但是i-vector特征并沒有完全覆蓋住聲紋特征的所有維度。為此,在i-vector特征的基礎上繼續提取維數更高的i-supervector特征,有效地避免了信息的不必要損失。為證明提出方案的可行性,采用對TIMIT等語音數據庫630個說話人的語音進行了訓練、驗證和測試。驗證實驗結果表明,在提取i-vector特征的基礎上提取i-supervector特征的說話人識別同等錯誤率有30%的降低,是一種有效的識別方法。
說話人識別;深度神經網絡;i-vector;聲紋特征
1 概 述
說話人識別,就是根據采集的聲音信號,來鑒定說話人身份的一種生物識別技術[1]。目前從語音識別的角度來看,說話人識別是一個重要分支,有許多的研究都還在不斷的持續發展中。對于一個文本無關的說話人驗證,其主要的難題在于如何解決訓練集和測試集之間的不一致性。這種不一致性的來源,有很大一部分是由于傳輸信道差異引起的。為了解決這個問題,一般的研究機構從兩方面著手去做語音識別項目:其一,從語音信息獲取的前端去處理,實現更好的語音信息采集(例如語音特征[2]、時-頻特性[3]、相位[4]、噪聲干擾[5]);其二,從針對說話人的后端去處理,設計出一個可以有效建立說話人模型的分類器[1]。事實上,為了研究一個系統的說話人識別課題,提供一個全面可靠的后端系統,顯得尤為重要,因此研究關注點在于后端框架。
近年來,對于說話人識別應用,人們一直將高斯混合模型(GMMs)作為主要方法[6]。通過不斷研究,都使用以GMM為基礎的GMM-UBM框架,努力提高說話人識別系統的性能。GMM-UBM,又叫高斯混合模型-統一背景模型,是由Reynolds提出,并成功應用到說話人驗證系統中的典型模型。Kunny[7-8]提出聯合因子分析(JFA)技術,可以把說話人和信道的差異限制在GMM超矢量高維空間兩個的子空間中。不過,使用聯合因子分析技術,信道空間里面仍然還會包含殘余少量說話人語音信息。
從目前全世界范圍看,基于i-vector的系統是使用得最多的說話人識別系統[9]。它在聯合因子分析技術的基礎上,提出說話人和會話差異可以通過一個單獨的子空間進行表征[10]。利用這個子空間,可以把從一個語音素材上獲得的數字矢量,進一步轉化為低維矢量(就是i-vectors)。使用i-vector有諸多好處,例如i-vector的維數可以定為一個固定值,從而頂替了原來話音信息的變長序列。i-vector極大地方便了說話人識別的建模和測試過程,就可以把線性判別分析(LDA)[11]、干擾屬性映射(NAP)[12]、類內協方差歸一化(WCCN)[13]和概率線性判別分析(PLDA)[14]等技術結合到i-vector系統中。一般情況下,使用PLDA會獲得比較好的性能。
另一方面,隨著儀器設備性能的不斷提升,深度神經網絡(DNN)項目在國際上逐漸受到推動[15]。在語音識別領域,深度神經網絡在成功應用于聲學建模之后,語音識別的性能也有了較大進步[16-17]。使用深度神經網絡獲得的增益,也在不斷地促進語言識別和說話人識別與神經網絡的結合[18]。文獻[19]提出了合理的DNN和i-vector相結合的模型,在提取充分統計量的過程中,把原有的i-vector模型中的UBM替換為基于音素狀態的DNN模型,從而獲得每個幀對應每個類別的后驗概率。
為此,考慮使用i-supervector和DNN相結合的模型,通過DNN強大的學習能力,從聲紋特征中提取出更有利于說話人識別的特征。該i-supervector是基于i-vector產生的聲紋相關矢量,是一個沒有壓縮的聲紋矢量。相關研究表明[20],提取i-supervector作為說話人相關特征比i-vector表現更加良好。
2 i-vector系統
2.1 i-vector說話人識別原理
數學上,說話人的聲紋矢量建模在一個高斯混合模型的后驗概率密度函數上:
(1)
高斯混合模型的參數表示為:
(2)
統一背景模型(UBM)是一個特殊的高斯混合模型,作為聲紋矢量的通用度量,通過最大后驗概率(MAP)調整成說話人模型[6]:
(3)
同理,UBM模型的參數表示為:
(4)
i-vector曾是很長一段時間里最流行的語音識別和說話人識別系統。和很多說話人建模方法一樣,i-vector也是基于GMM-UBM的模型。在i-vector中[9],分析一個高斯混合模型:
M=μ+Tω
(5)
其中,M表示均值超矢量,它與說話人和信道是相關的;μ表示均值超矢量,它與說話人和信道是無關的;T表示一個變化子空間矩陣;ω表示一個與說話人和信道相關的矢量,ω就是包含了說話人信息的i-vector。
2.2 i-vector特征提取
梅爾頻率倒譜系數(MFCC),是一種在語音自動識別和分類中應用最廣泛的語音參數。在前端處理時經過預處理、分幀、加窗,再通過梅爾濾波器組,得到MFCC特征。給定1條語音片段:
y={Yi|i=1,2,…,I}
(6)
(7)
其中,Yi表示一個F維的特征矢量。
工程上,MFCC一般會選擇F={13,20,39}等維數的特征。提取出MFCC后,先利用期望最大化(EM)算法訓練出一個UBM模型,然后再通過最大后驗概率準則調整得到GMM模型。
從GMM-UBM模型提取i-vector特征的過程中,需要準備好UBM模型超矢量的各階統計量。各階統計量的估計已經有完善的理論[21],對一段語音s的特征表示為xs,t,高斯混合模型分量系數為c。那么,其零階、一階、二階Baum-Welch統計量(也稱充分統計量)為:
Nc,s=∑tγc,s,t
(8)
Fc,s=∑tγc,s,t(xs,t-μc)
(9)
Sc,s=diag{∑tγc,s,t(xs,t-μc)(xs,t-μc)T}
(10)
其中,γc,s,t表示第c個高斯分量的后驗概率;μc表示第c個高斯分量的均值超矢量。
如果語音特征矢量的維數為F,采用一個高斯混合分量總數為C的高斯混合模型,得到的均值超矢量的維數為C·F。
在估計各階統計量后,就可以采用EM算法估計得總體子空間矩陣T。從i-vector的求解過程分析,可以把估計子空間矩陣T的步驟總結[22]為:
(1)初始化。
在T中選擇每個成分的初始值,利用式(8)~(10)求得Baum-Welch統計量。
(2)求E階段。
對每一個語音片段,求期望:
Ls=I+TTΣ-1NsT
(11)
E[ωs]=Ls-1TTΣ-1Fs
(12)
(13)
(3)求M階段。
解方程后更新矩陣T:
(14)
(4)迭代或終止。
如果目標函數收斂,則終止EM步驟;否則,繼續迭代步驟(2)和步驟(3)。
2.3 從i-vector到i-supervector
相比于高斯混合模型的均值超矢量,i-vector可以用一個維數固定的低維空間矢量來表示一個語音片段。對于一個語音觀察序列W,i-vector由其潛在變量ω的期望φ所決定。其中,φ=E{ω|W}。式(5)中,由于T是一個秩較低的矩陣,所以得到i-vector的維數D會遠小于UBM的均值超向量,即D?C·F。
通過把潛在因子空間拓展到均值超向量維數般大小,就是使D=C·F,可以得到:
M=μ+Tω
(15)
與式(5)相比,i-supervector由潛在變量的期望φ=E{z|W}所決定。和i-vector相比,它們的不同之處在于,對角矩陣D是一個C·F×C·F維的對角矩陣。這樣一來,i-supervector就和高斯混合模型的均值超矢量維數相同。對i-supervector的建模可以通過經典的JFA等技術,加上一些改變后就可以方便實現[20]。對每個語音片段,用矩陣D對每個說話人的偏差估計,可獲得說話人和會話之間的差異。文獻[20]指出,使用i-supervector代替i-vector可以獲得更好的性能。
3 深度神經網絡
深度神經網絡是近年來機器學習研究的一個熱門領域,它是前饋型人工神經網絡的一種拓展。Hinton[17]提出,過去幾年間,在機器學習算法和計算機硬件設施不斷提高情況下,使包含有多個非線性隱層和大量輸出層的深度神經網絡,取得許多有效的方法。
3.1 DNN處理識別和分類原理
深度神經網絡,是指有一個以上隱層數目的前饋人工神經網絡。每個隱層單元j使用一個logistic函數,把前一層的xj映射成下一層的yj:
(16)
(17)
其中,bj為第j單元的偏差;ωij為從i單元到j單元的權重。
如果要設計一個分類器,輸出單元j需要把輸入xj映射為某一類的概率。一般通過一個softmax的非線性模塊:
(18)
其中,k表示各個類別的索引。
深度神經網絡用一個損失函數[23]衡量目標輸出和當前輸出之間的差異,其模型可以通過后向傳播算法來訓練得到。使用softmax輸出函數時,其自然損失函數為:
(19)
其中,dj為目標概率;pj為當前概率。
當訓練語音數據集量非常大時,需要把訓練集分割成許多個小片段,而不是把整體的訓練數據都用到神經網絡中。在更新梯度權值比例之前,選取一堆大小隨機的語音片段作為下一批的訓練數據,并計算它們之間的差異。這種隨機梯度下降的方法加一個α系數進行改進,使得對語音片段t梯度計算更加平滑:
(20)
其中,0<α<1。更新單元狀態持續為1的權重。
深度神經網絡有非常多的隱層,使得最優化很難進行[24]。使用隨機初始狀態時,用后向傳播等算法中各層梯度可能會有很大差異。好在深度神經網絡有很多隱層,使得它們足夠應對輸入與輸出之間的復雜、非線性關系。這一點對高質量的聲學建模來說非常有用。除了最優化問題,還要考慮過擬合問題。雖然可以通過大量的訓練數據減少過擬合[25]的影響,與之帶來的是依賴高額的計算處理消耗。因此,需要使用一種更好的方法處理訓練數據,建立一個多層的非線性特征檢測網絡。
3.2 DNN語音識別模型訓練
DNN分類器可以作為自動語音識別(ASR)的聲紋模型,用來計算聲紋觀察序列的子音素單元(稱為“senone”)的后驗概率。觀察序列在固定采樣頻率時采用頻譜技術,如濾波分析、MFCC、感知器線性預測(PLP)系數等。
(1)預訓練。
在預訓練階段,嘗試尋找合適初始化對權值調優更有利,同時也對減少過擬合有意義。定義v是可見層變量,h是不可見層變量,那么它們之間的聯合概率為:
(21)
(22)
其中,Z表示partition函數;W表示可見變量和不可見變量之間的權值關系矩陣。
(2)構造RBMs。
受限的玻爾茲曼機(RBMs)是一種兩層結構模型。RBM可見單元和隱藏單元聯合的能量為:
(23)
其中,i表示可見狀態單元;j表示不可見狀態單元;vi表示i單元的狀態;hj表示j單元的狀態;ai,bj分別表示它們的偏置;ωij表示單元間的權重。
RBM模型的優化目標是讓邊緣概率最大化:
(24)
其求解過程可以通過最大似然準則得到:
(25)
Δωij=ε(
(26)
其中,N表示訓練數據大小;ε表示學習率。
直接求解比較困難,大家一般采用由Hinton[26]提出的對比散度(Contrastive Divergence-CD)快速算法。
(3)數據建模并將RBMs堆疊為深度置信網絡。
語音特征數據(如MFCC)通常通過含高斯噪聲的線性變量建模:

(27)
其中,σi表示高斯噪聲的標準差。
自動學習標準差比較困難,所以一般需要在預訓練時把數據調整為標準正態分布,避免了分析噪聲級別的問題。
當訓練完一層數據為RBM后,可以用隱層的輸出生成下一層RBM。采用這種逐層的訓練方式,可以得到一個DBN網絡。DBN網絡一個非常大的好處就是可以推測隱層單元的狀態,這是多層感知器及其他非線性模型沒有的。最后,可以在頂層加一個softmax層做分類任務。
(4)利用DNN與HMM的對接。
在預訓練和調優過后,DNN會輸出隱馬爾可夫模型(HMM)的后驗概率。輸出的標注需要依賴強對齊技術,與另一個聲紋建模程序進行對齊。
4 實 驗
4.1 實驗設置
實驗采用了美國國家標準技術局上的TIMIT語音數據庫(National Institute of Standards and Technology TIMIT Speech Corpus,NIST TIMIT)和實驗室自建的語音數據庫。
在TIMIT中包含了美國8個地區方言的說話人測試集,在630人中挑出430人構成訓練集,剩下200人構成驗證集和測試集。其中,訓練集每人10句話,一共4 300個語音素材進行訓練。驗證集和測試集中,每個人拿8句話來做驗證集的訓練,剩下2句話用來測試說話人。實驗室自建的語音素材使用方式類似。對測試集的200人進行交叉驗證,并求出對應的det曲線。
對每一段語音片段,實驗用采樣速率16 kHz提取語音中的基本聲紋特征MFCC。MFCC在幀長度25 ms、幀移10 ms,并通過23維漢明窗梅爾濾波器的前端處理得到一組20維(包括第0級系數)的特征矢量。提取的特征還需要經過語音活動檢測(VAD)。之后,使用經特征提取和VAD模塊處理后的聲紋特征分別訓練兩個(背景和說話人)高斯混合模型和一個深度神經網絡模型。
實驗訓練了一個包含6個隱層的神經網絡模型。網絡模型隱層p-norm的輸入/輸出維數為3 500/350,使用3 000個語音素材迭代訓練,在經過13次循環后達到穩定。
4.2 DNN/i-vector說話人識別系統
傳統的i-vector系統是依靠GMM-UBM框架,再使用與聲紋矢量對齊獲得的充分統計量。在GMM-UBM中,一個高斯混合模型混合分量即代表一個類別。而在DNN語音識別中,DNN替代了GMM-HMM聲學模型中的高斯混合模型。HMM中不同狀態的發射概率可以用DNN的輸出來標注。當DNN的輸入為拼接多幀的聲學矢量,輸出為三因素狀態,由貝葉斯公式,HMM的狀態概率為:
(28)
其中,O表示升學特征;S表示三因素狀態。
這樣,DNN就提供了充分統計量計算所需要的標注信息。
圖1展示GMM和DNN在語音識別處理上差異。
傳統的基于GMM方法使用相同的聲紋特征標注后驗概率,而基于DNN的方法使用自動語音識別特征獲得計算統計信息。但是使用GMM的混合分量是由無監督聚類取得的,所以混合分量表示的類別也沒有明確含義。但是使用DNN是由有監督聚類得到的信息(受綁定的三因素狀態),與發聲語音有比較明確的對應關系。所以,DNN在處理語音識別上可以使用DNN模型替代GMM-UBM模型中的GMM進行每個類的后驗概率計算。
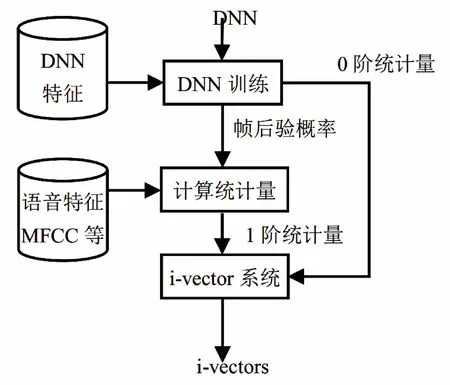
圖1 與i-vector技術的結合:基于DNN的說話人識別
4.3 實驗結果及分析
實驗采用同等錯誤率(Equal Error Rate,EER)——錯誤接收率和錯誤拒絕率的同等準確值指標對實驗結果進行度量。在det曲線畫出后,計算最小代價函數(minimum Detection Cost Function,minDCF)作為系統性能評價指標。
(1)i-vector/DNN基線系統。
所有系統都使用了語音活動檢測,語音訓練后生成了高斯混合模型。其中,i-vector系統使用MAP等技術進行了T矩陣估計。測試打分階段使用PLDA方法。除了輸入的聲紋特征和各階統計量之外,i-vector系統自動提取了一個67維高斯分量的GMM-UBM模型和一個400維的i-vector子空間。
(2)i-supervector/DNN系統。
使用i-supervector/DNN系統和i-vector/DNN系統的最明顯差別在于使用的i-vector維數和子空間矩陣T的維數。在求i-supervector特征時,估計子空間矩陣T的高斯分量也需要調整到合適狀態。假如高斯混合模型有67維的高斯分量,i-supervector需要使用67*20(特征維數)=1 340維的高斯分量估計T。
由于i-vector系統是使用的EM算法進行迭代,以相同迭代次數為例進行分析。如表1所示,在迭代次數相同的情況下,測試每組模型的EER。
從表1可以看出,i-vector傳統方法的準確度較差,i-vector/DNN在i-vector的基礎上有了些許提升,使用i-supervector/DNN的搭配獲得了進一步提升。

表1 同等迭代次數下的EER %
為了進一步觀察使用i-supervector/DNN的說話人識別性能,分別對不同的實驗設置展開測試,在迭代次數為10時查看識別模型的準確率。表2展示了考慮所有說話人的識別方案,表3和表4展示了只考慮男/女性說話人的識別方案。

表2 不同系統不考慮區分性別的差異

表3 不同系統識別男聲的差異

表4 不同系統識別女聲的差異
i-supervector說話人識別的det曲線見圖2。
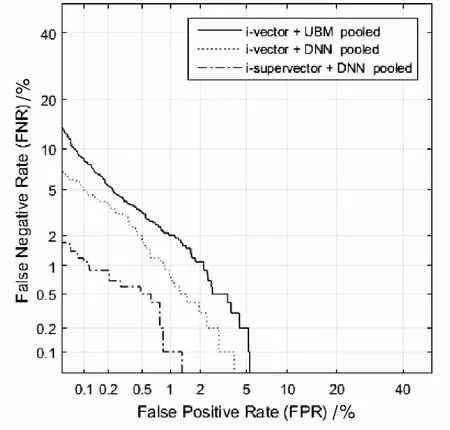
圖2 i-supervector說話人識別的det曲線
通過實驗對比可以看出,在進行訓練時,使用經過i-supervecor特征提取的神經網絡進行聲學建模,可以更好地處理說話人識別。
綜上所述,使用深度神經網絡處理語音識別,利用了深度網絡一個逐層抽象的特點,把說話人標簽作為網絡輸出。在神經網絡中結合傳統的語音識別方法,可以使聲學模型更好地表達說話人的聲紋特征,進一步提升語音識別的準確率。
5 結束語
針對說話人聲紋特征,提出了一種基于i-supervector特征和深度神經網絡模型的說話人識別方法。該方法以深度神經網絡機器學習的特征提取器為基礎,從中提取出更有利于說話人區分性的i-supervertor特征。在相同的參數下,語音數據使用i-supervector特征和DNN的同等錯誤率更優于傳統的兩種方案,說明了該方案識別準確率的優勢。實驗結果表明,利用補足i-vector特征不能完全表征聲紋矢量所有維度的缺點,是在深度學習中一條提高說話人識別準確率的有益途徑。
[1] Kinnunen T,Li H.An overview of text-independent speaker recognition:from features to supervectors[J].Speech Communication,2010,52(1):12-40.
[2] Espy-Wilson C Y,Manocha S,Vishnubhotla S.A new set of features for text-independent speaker identification[C]//International conference on interspeech.[s.l.]:[s.n.],2006:1475-1478.
[3] Kinnunen T,Lee K A,Li H.Dimension reduction of the modulation spectrogram for speaker verification[C]//Proceedings of the speaker and language recognition workshop.Odyssey:[s.n.],2008.
[4] Nakagawa S,Wang L,Ohtsuka S.Speaker identification and verification by combining MFCC and phase information[J].IEEE Transactions on Audio Speech and Language Processing,2012,20(4):1085-1095.
[5] Wang L,Minami K,Yamamoto K,et al.Speaker identification by combining MFCC and phase information in noisy environments[C]//Proceeding of international conference on acoustics,speech and signal processing.Dallas,TX,USA:[s.n.],2010:4502-4505.
[6] Reynolds D A,Quatieri T F,Dunn R B.Speaker verification using adapted Gaussian mixture models[J].Digital Signal Processing,2010,10(1-3):19-41.
[7] Kenny P,Ouellet P,Dehak N,et al.A study of interspeaker variability in speaker verification[J].IEEE Transactions on Audio Speech and Language Processing,2008,16(5):980-988.
[8] Kenny P,Boulianne G,Ouellet P,et al.Speaker and session variability in GMM-based speaker verification[J].IEEE Transactions on Audio Speech and Language Processing,2007,15(4):1448-1460.
[9] Dehak N,Kenny P J,Dehak R,et al.Front-end factor analysis for speaker verification[J].IEEE Transactions on Audio Speech and Language Processing,2011,19(4):788-798.
[10] 栗志意,張衛強,何 亮,等.基于總體變化子空間自適應的i-vector說話人識別系統研究[J].自動化學報,2014,40(8):1836-1840.
[11] Kanagasundaram A,Dean D,Vogt R,et al.Weighted LDA techniques for i-vector based speaker verification[C]//Proceedings of IEEE international conference on acoustics,speech,and signal processing.Kyoto,Japan:IEEE,2012:4781-4794.
[12] Campbell W M,Sturim D E,Reynolds D A,et al.SVM based speaker verification using a GMM supervector kernel and NAP variability compensation[C]//Proceedings of international conference on acoustics,speech,and signal processing.Philadelphia,USA:IEEE,2005:97-100.
[13] Hatch A O,Kajarekar S,Stolcke A.Within-class covariance normalization for SVM-based speaker recognition[C]//International conference on interspeech.[s.l.]:[s.n.],2006:1471-1474.
[14] Machlica L,Zajic Z.An efficient implementation of probabilistic linear discriminant analysis[C]//Proceedings of IEEE international conference on acoustics,speech,and signal processing.Vancouver,Canada:IEEE,2013:7678-7682.
[15] 戴禮榮,張仕良.深度語音信號與信息處理:研究進展與展望[J].數據采集與處理,2014,29(2):171-179.
[16] Hinton G,Deng L,Dong Y,et al.Deep neural networks for acoustic modeling in speech recognition:the shared views of four research groups[J].IEEE Signal Processing Magazine,2012,29(6):82-97.
[17] Dahl G E,Yu D,Deng L,et al.Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J].IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):30-42.
[18] 王山海,景新幸,楊海燕.基于深度學習神經網絡的孤立詞語音識別的研究[J].計算機應用研究,2015,32(8):2289-2291.
[19] Richardson F,Reynolds D,Dehak N.Deep neural network approaches to speaker and language recognition[J].IEEE Signal Processing Letters,2015,22(10):1671-1675.
[20] Jiang Y,Lee K A,Wang L.PLDA in the i-supervector space for text-independent speaker verification[J].EURASIP Journal on Audio,Speech,and Music Processing,2014(1):1-13.
[21] Glembek O,Burget L,Matějka P,et al.Simplification and optimization of i-vector extraction[C]//Proceedings of IEEE international conference on acoustics,speech and signal processing.Prague:IEEE,2011:4516-4519.
[22] Li Zhiyi,He Liang,Zhang Weiqiang,et al.Speaker recognition based on discriminant i-vector local distance preserving projection[J].Journal of Tsinghua University (Science and Technology),2012,52(5):598-601.
[23] Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[J].Nature,1986,323(6088):533-536.
[24] Glorot X,Bengio Y.Understanding the difficulty of training deep feedforward neural networks[C]//Proceedings of AISTATS.[s.l.]:[s.n.],2010:249-256.
[25] Ciresan D C,Meier U,Gambardella L M,et al.Deep,big,simple neural nets for handwritten digit recognition[J].Neural Computation,2010,22(12):3207-3220.
[26] Hinton G,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
Speaker Recognition with i-vector and Deep Learning
LIN Shu-du,SHAO Xi
(College of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
To improve the performance of speaker recognition systems,a novel scheme combined DNN (Deep Neural Network) model with the i-vector model has been proposed.Via construction of network,the hidden information in the voice of speakers has been extracted accurately.Although DNN model can help dig a lot of information,the i-vector features have not completely cover all dimensions of voiceprint.Thus i-supervector characteristics of higher dimension have been drawn with the i-vector features,which have effectively avoided the unnecessary loss of information.Experiments on TIMIT and other speech databases which contain 630 the speaker’s voices for training,validation and testing have been conducted to verify the proposed scheme.The results illustrate that the i-supervector features with i-vector features for speaker recognition have achieved 30% reduction of equal error rate that implies effectiveness of the identification method proposed.
speaker recognition;DNN;i-vector;voiceprint
2016-07-30
2016-11-04 網絡出版時間:2017-04-28
國家自然科學青年基金項目(61401227);江蘇省高校自然科學研究面上項目(16KJB520013)。
林舒都(1991-),男,碩士研究生,研究方向為多媒體音樂信息處理和檢索;邵 曦,博士,副教授,研究生導師,研究方向為多媒體信息處理系統、基于內容的音樂信息檢索等。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170428.1704.086.html
TP301
A
1673-629X(2017)06-0066-06
10.3969/j.issn.1673-629X.2017.06.014
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
