融合語義知識的深度表達(dá)學(xué)習(xí)及在視覺理解中的應(yīng)用
2017-06-23 12:47:04張瑞茂彭杰鋒
計算機(jī)研究與發(fā)展 2017年6期
張瑞茂 彭杰鋒 吳 恙 林 倞
(中山大學(xué)數(shù)據(jù)科學(xué)與計算機(jī)學(xué)院 廣州 510006)
融合語義知識的深度表達(dá)學(xué)習(xí)及在視覺理解中的應(yīng)用
張瑞茂 彭杰鋒 吳 恙 林 倞
(中山大學(xué)數(shù)據(jù)科學(xué)與計算機(jī)學(xué)院 廣州 510006)
(linliang@ieee.org)
近幾年來,隨著深度學(xué)習(xí)技術(shù)的日趨完善,傳統(tǒng)的計算機(jī)視覺任務(wù)得到了前所未有的發(fā)展.如何將傳統(tǒng)視覺研究中的領(lǐng)域知識融入到深度模型中提升深度模型的視覺表達(dá)能力,從而應(yīng)對更為復(fù)雜的視覺任務(wù),成為了學(xué)術(shù)界廣泛關(guān)注的問題.鑒于此,以融合了語義知識的深度表達(dá)學(xué)習(xí)為主線展開了一系列研究.取得的主要創(chuàng)新成果包括3個方面:1)研究了將單類型的語義信息(類別相似性)融入到深度特征的學(xué)習(xí)中,提出了嵌入正則化語義關(guān)聯(lián)的深度Hash學(xué)習(xí)方法,并將其應(yīng)用于圖像的相似性比對與檢索問題中,取得了較大的性能提升;2)研究了將多類型信息(多重上下文信息)融入到深度特征的學(xué)習(xí)中,提出了基于長短期記憶神經(jīng)網(wǎng)絡(luò)的場景上下文學(xué)習(xí)方法,并將其應(yīng)用于復(fù)雜場景的幾何屬性分析問題中;3)研究了將視覺數(shù)據(jù)的結(jié)構(gòu)化語義配置融入到深度表達(dá)的學(xué)習(xí)中,提出了融合語法知識的表達(dá)學(xué)習(xí)方法,并將其應(yīng)用到復(fù)雜場景下的通用內(nèi)容解析問題中.相關(guān)的實驗結(jié)果表明:該方法能有效地對場景的結(jié)構(gòu)化配置進(jìn)行預(yù)測.
深度學(xué)習(xí);神經(jīng)網(wǎng)絡(luò);語義嵌入;場景解析;相似性檢索
Fig. 1 Development of computer vision in various fields圖1 計算機(jī)視覺在多個相關(guān)領(lǐng)域的發(fā)展
自1956年達(dá)特茅斯會議開始,有關(guān)人工智能的研究已經(jīng)經(jīng)歷了50年的歷史,而計算機(jī)視覺又是其中最為重要、最具有應(yīng)用價值的研究領(lǐng)域之一.近10年來,伴隨著神經(jīng)網(wǎng)絡(luò)(深度學(xué)習(xí))研究的巨大突破[1-3],以及大型視覺數(shù)據(jù)集的不斷涌現(xiàn)[4-6].基于深度神經(jīng)網(wǎng)絡(luò)的視覺模型對圖像、視頻等數(shù)據(jù)的表達(dá)能力獲得了空前的提升,諸如圖像分類、物體識別等傳統(tǒng)視覺問題得到了有效解決,更加復(fù)雜多樣的視覺任務(wù)也隨之涌現(xiàn).隨著研究的不斷深入,傳統(tǒng)的深度模型(諸如卷積神經(jīng)網(wǎng)絡(luò)、遞歸神經(jīng)網(wǎng)絡(luò)等)已經(jīng)很難滿足日趨豐富的視覺應(yīng)用任務(wù).究其原因,主要集中于2個方面:
1) 深度學(xué)習(xí)植根于人工智能早期的聯(lián)結(jié)主義研究.其核心目的在于構(gòu)建較為通用的網(wǎng)絡(luò)結(jié)構(gòu),進(jìn)而通過組合的方式實現(xiàn)從簡單模式到復(fù)雜模式的抽象.近幾年來,深度學(xué)習(xí)作為機(jī)器學(xué)習(xí)的一個分支再次受到了學(xué)界的廣泛關(guān)注[7].但是在網(wǎng)絡(luò)結(jié)構(gòu)的設(shè)計與改進(jìn)方面,多數(shù)研究工作依舊側(cè)重從學(xué)習(xí)理論入手,如使用Dropout技術(shù)[8]避免過擬合現(xiàn)象,使用ReLU函數(shù)[9]替代Sigmoid函數(shù)避免非線性變化過程中的梯度消失等.該類工作將視覺數(shù)據(jù)作為整體的處理對象,并沒有對數(shù)據(jù)內(nèi)部蘊(yùn)含的信息進(jìn)行深層次地挖掘,因此所能夠處理的視覺任務(wù)也比較單一.而在傳統(tǒng)的計算機(jī)視覺研究中,大量的深層次的視覺信息被用于模型的構(gòu)建,使得模型能夠處理的視覺任務(wù)也較為豐富.
2) 隨著Web2.0技術(shù)及其周邊應(yīng)用的迅猛發(fā)展,互聯(lián)網(wǎng)上的圖片和視頻數(shù)量在近幾年呈極速增長趨勢.例如,截至2014年,雅虎公司旗下的圖片分享網(wǎng)站Flickr所托管的圖片數(shù)量已經(jīng)接近于100億張.除了視覺數(shù)據(jù)本身的增長迅猛,與視覺數(shù)據(jù)相關(guān)的標(biāo)題注釋、文字說明以及標(biāo)簽描述也充斥在互聯(lián)網(wǎng)中.這使得互聯(lián)網(wǎng)中的視覺數(shù)據(jù)普遍包含了豐富的描述性信息以及語義知識.因此,如何利用這些語義信息[10]對視覺數(shù)據(jù)中所呈現(xiàn)的內(nèi)容進(jìn)行深層次的理解,從而更好地實現(xiàn)相關(guān)數(shù)據(jù)的自動標(biāo)注、科學(xué)管理以及高效檢索,成為了互聯(lián)網(wǎng)信息資源高效利用的核心問題之一,受到了學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注.
基于以上討論,如何更為有效地、充分地利用數(shù)據(jù)資源,挖掘數(shù)據(jù)里潛在的語義知識,進(jìn)而提升深度表達(dá)模型的表達(dá)能力,實現(xiàn)更為豐富的視覺理解任務(wù)是當(dāng)下計算機(jī)視覺領(lǐng)域亟待思考與解決的問題.如圖1所示,深度模型表達(dá)能力的提升將進(jìn)一步推動虛擬現(xiàn)實、增強(qiáng)現(xiàn)實、自動駕駛、無人機(jī)、智能媒體等相關(guān)領(lǐng)域的發(fā)展.

Fig. 3 This paper discusses how to combine semantic knowledge with existing deep model from three aspects圖3 本文從3個方面探討了如何將語義知識與現(xiàn)有深度模型相結(jié)合
鑒于此,本課題致力于研究融合語義知識的深度表達(dá)學(xué)習(xí).其特點在于利用多層的非線性模型來對復(fù)雜的視覺內(nèi)容進(jìn)行表達(dá),同時借助豐富的語義知識來指導(dǎo)模型的學(xué)習(xí)和視覺特征的優(yōu)化,從而實現(xiàn)面向特定任務(wù)的視覺理解.如圖2所示,與傳統(tǒng)的深度學(xué)習(xí)研究借助數(shù)據(jù)的體量去提升表達(dá)能力,進(jìn)而填補(bǔ)語義鴻溝不同,本文的研究側(cè)重從人類視覺出發(fā),通過對豐富語義知識的建模來拓展模型的視覺表達(dá)能力,逐步消除語義鴻溝對智能視覺系統(tǒng)發(fā)展的桎梏.

Fig. 2 The semantic gap is eliminated by the integration of deep learning and semantic knowledge modeling圖2 結(jié)合深度學(xué)習(xí)與語義知識建模逐步消除語義鴻溝
如圖3所示,針對視覺理解的實際任務(wù),本文將重點針對3個方面研究融合語義知識的深度表達(dá)學(xué)習(xí):
1) 融合單類型語義知識的深度表達(dá)模型.即僅利用圖像的類別信息來提升特征表達(dá)的判別能力.與傳統(tǒng)的深度學(xué)習(xí)方法利用類別標(biāo)簽對圖像的特征表達(dá)與分類器進(jìn)行聯(lián)合學(xué)習(xí)不同,本文通過圖片之間的相似性關(guān)系來定義模型的損失函數(shù),從而將度量學(xué)習(xí)與卷積神經(jīng)網(wǎng)絡(luò)[11]的訓(xùn)練集成在統(tǒng)一的框架中.在具體的視覺應(yīng)用方面,我們將以基于內(nèi)容的圖像檢索[12-13]問題來驗證所提出模型的有效性.
2) 融合多類型語義知識的深度表達(dá)模型.對于圖片中的不同場景區(qū)域,除了其自身的類別標(biāo)簽之外,區(qū)域之間的上下文信息也能有效地輔助模型的訓(xùn)練.本文利用場景區(qū)域的類別標(biāo)簽以及區(qū)域之間的交互關(guān)系進(jìn)行建模,并通過循環(huán)神經(jīng)網(wǎng)絡(luò)[14]將上述的信息在整個場景中進(jìn)行傳遞,從而更好地實現(xiàn)了場景上下文的表達(dá)學(xué)習(xí).我們將該模型用于場景圖像的幾何屬性分析問題,并在2個數(shù)據(jù)集上驗證了其有效性.
3) 融合結(jié)構(gòu)化語義的深度表達(dá)模型.人類視覺系統(tǒng)對復(fù)雜的場景結(jié)構(gòu)具有較強(qiáng)的感知能力,例如場景中的物體類別、物體的空間位置、物體間的組合關(guān)系等.如何將上述具有明顯結(jié)構(gòu)的語義信息融入到深度模型的設(shè)計中,是視覺研究領(lǐng)域廣泛關(guān)注的問題.本文將把一系列帶有結(jié)構(gòu)的語法知識融入到深度表達(dá)學(xué)習(xí)中,借助遞歸神經(jīng)網(wǎng)絡(luò)[15]的特性對場景中的物體、物體間的關(guān)系等進(jìn)行結(jié)構(gòu)化的組合與表達(dá).最終,我們將利用該模型實現(xiàn)場景圖像的深度層次化解析.
1 融合單類型語義的深度表達(dá)模型
隨著互聯(lián)網(wǎng)分享網(wǎng)站的興起,以及拍攝設(shè)備成本的迅速降低,視覺數(shù)據(jù)呈現(xiàn)出爆炸式的增長,針對視覺數(shù)據(jù)的分類與快速檢索技術(shù)成為了計算機(jī)視覺、多媒體領(lǐng)域重要研究的內(nèi)容.鑒于視覺數(shù)據(jù)的Hash表示占用的存儲空間少,檢索時的效率極高,因此Hash技術(shù)作為一種有效的解決方式,在海量視覺檢索領(lǐng)域[16-20]及其相關(guān)的應(yīng)用領(lǐng)域受到了廣泛的關(guān)注.近幾年來,許多基于學(xué)習(xí)的Hash技術(shù)被提出[21-24],其核心的目標(biāo)是學(xué)習(xí)一個緊致的、能夠有效保持?jǐn)?shù)據(jù)之間語義相似性的視覺表達(dá),即相似的視覺數(shù)據(jù)在轉(zhuǎn)換成為二進(jìn)制編碼之后具有較小的海明距離.
在所有的Hash學(xué)習(xí)方法中,監(jiān)督式的方法[22,25]通過在學(xué)習(xí)的過程中嵌入單一類型的語義知識(通常是視覺數(shù)據(jù)的類別標(biāo)簽)獲得了巨大的成功.監(jiān)督式Hash學(xué)習(xí)方法通常包含2個步驟:1)數(shù)據(jù)庫中存儲的圖像會被表達(dá)成視覺特征向量的形式;2)一系列基于單張圖像或者圖像對的Hash學(xué)習(xí)方法[26-27]被用于學(xué)習(xí)圖像的Hash表達(dá).但是,在先前的研究中,以上2個過程通常是被拆分成2個獨立的過程,這樣的拆分極大地限制了Hash表達(dá)的能力.因為第1個步驟產(chǎn)生的圖像表達(dá)并不一定能夠完美地契合Hash學(xué)習(xí)的目標(biāo).換言之,這里的圖像特征表達(dá)不是面向于Hash學(xué)習(xí)這種特定任務(wù)的.所使用的語義知識也僅僅用于指導(dǎo)分類器或測度空間的學(xué)習(xí).
為了解決以上問題,本文提出一種新的監(jiān)督式位長可變深度Hash學(xué)習(xí)框架,該框架基于卷積神經(jīng)網(wǎng)絡(luò)(convolution neural network, CNN)構(gòu)建了一個端到端的Hash生成網(wǎng)絡(luò),能夠?qū)⑤斎雸D像直接變換成用于快速檢索的二進(jìn)制編碼.同時,網(wǎng)絡(luò)所輸出的編碼的每一位都會對應(yīng)一個確定的權(quán)重.在檢索的過程中,系統(tǒng)可以根據(jù)位的重要性,截取不同長度的Hash編碼.在使用語義知識方面,該框架有別于借助類別標(biāo)簽對分類器和圖像的特征表達(dá)進(jìn)行聯(lián)合學(xué)習(xí)的傳統(tǒng)深度分類框架.本文的方法是基于三元組的相對相似性來構(gòu)建模型的,即通過圖像的類別標(biāo)簽構(gòu)建圖像之間的相對相似關(guān)系,并最終指導(dǎo)圖像的特征以及Hash函數(shù)的聯(lián)合學(xué)習(xí).如前人工作所述[17,26,28],在排序優(yōu)化方法中,基于三元組的方法能夠有效地捕捉類內(nèi)與類間的差距;同時我們也希望具有相似視覺外觀的圖像能夠在海明空間中具有相近的Hash編碼.因此通過引入一個正則項,進(jìn)一步拓展了原有的基于三元組的Hash學(xué)習(xí)方法,引入部分受到了拉普拉斯稀疏編碼(Laplacian sparse coding)[29]工作的啟發(fā).
1.1 基于卷積神經(jīng)網(wǎng)絡(luò)的Hash表達(dá)學(xué)習(xí)
Hash學(xué)習(xí)的主要目標(biāo)是找到映射h(x)將p維的圖像特征表達(dá)x∈p,映射成q維的二進(jìn)制Hash編碼h∈{-1,1}p.本節(jié)我們重點介紹位長可變的深度學(xué)習(xí)框架,如圖4所示,位長可變的深度學(xué)習(xí)框架將原始圖片作為輸入,將圖像的特征表達(dá)學(xué)習(xí)與Hash函數(shù)的學(xué)習(xí)集成為一個非線性變化函數(shù).同時,模型引入一個權(quán)重向量來表示每一個Hash位在相似性檢索的過程中的重要性.
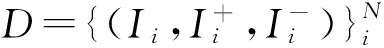
(1)
其中,Φw(·,·,·)是基于一個三元組的最大間隔損失.我們需要帶權(quán)重的海明仿射[30]符合約束:

Fig. 4 The bit-scalable deep Hash learning framework圖4 位長可變的深度Hash學(xué)習(xí)框架
(2)
于是有損失函數(shù):

(3)

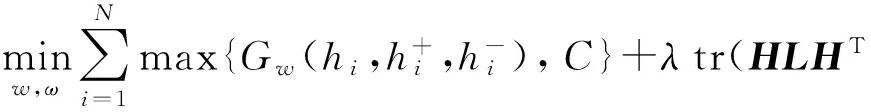
(4)
由于Hash編碼是一種二值化的表示,因此式(4)是不連續(xù)且非可導(dǎo)的,無法直接使用梯度下降法來進(jìn)行優(yōu)化.為了解決此問題,本節(jié)提出使用類雙曲正切函數(shù)o(·)來替代符號函數(shù).而在測試階段,我們將直接使用符號函數(shù)作為激活函數(shù)來獲得離散的Hash編碼.本文我們將Hash編碼hi近似地表示為ri∈[-1,1]q:
r=o(φ(I)).
(5)
(6)

Hash編碼在檢索任務(wù)中的優(yōu)勢在于能夠?qū)ξ皇褂卯惢虿僮鳎蛘呤褂貌楸淼男问窖杆俣攘縃ash編碼之間的距離.我們提出一種基于查表法(lookup table, LUT)的相似性計算方式來迅速地返回2個Hash編碼之間帶權(quán)的仿射值.令l表示Hash編碼的長度,于是可以構(gòu)建一個長度為2l的查詢表,其長度等于2個Hash編碼所有可能的異或操作結(jié)果.至此,在確定查詢圖片的情況下,查詢結(jié)果的序列可以通過查表法迅速地返回.然而查詢表的大小會隨著Hash位的增長呈指數(shù)級增長.一種解決方式是將Hash編碼分成等長的若干段(本節(jié)中該長度設(shè)置為8),每一段與一個子表相對應(yīng),則每一個子表所輸出的帶權(quán)相似性就與對定的Hash段相關(guān)聯(lián).最終,整個Hash編碼的帶權(quán)相似性可以通過累加每一段Hash編碼的帶權(quán)相似性獲得,最后的排序結(jié)果也基于這一總的帶權(quán)相似性.
1.2 視覺相似性檢索中的應(yīng)用
本節(jié)將在圖像檢索的標(biāo)準(zhǔn)數(shù)據(jù)集CIFAR-10上對本節(jié)所提出的位長可變的深度Hash學(xué)習(xí)框架的有效性進(jìn)行驗證.其中,將使用DRSCH來表示最完整的帶有正則項的方法,同時使用DSCH來表述該方法的簡化版本,即移除拉普拉斯正則項的版本.這里需要注意,DRSCH和DSCH均是使用了不帶權(quán)重的訓(xùn)練方法,因此訓(xùn)練的過程需要預(yù)先確定Hash位的長度.而位長可變的Hash學(xué)習(xí)方法將分別使用BS-DRSCH和BS-DSCH表示.
本節(jié)使用了近期提出的4種有監(jiān)督的Hash學(xué)習(xí)方法作為對比方法,它們分別是最小損失Hash(MLH)[31]、二值重建嵌入(BRE)[32]、基于核方法的有監(jiān)督Hash(KSH)[22]和深度語義排序Hash(DSRH)[33].為了公平比較,前3種方法我們還使用了深度特征,后文中用-CNN進(jìn)行表示.提取CNN特征使用了AlexNet[34]網(wǎng)絡(luò),整個網(wǎng)絡(luò)在ImageNet數(shù)據(jù)集上進(jìn)行了分類任務(wù)的預(yù)訓(xùn)練.在這種情境下,CNN網(wǎng)絡(luò)可以看作是一個通用的特征提取器[35].本節(jié)中所有關(guān)于DSRH的實驗結(jié)果均是基于作者在Caffe框架上的自行實現(xiàn)結(jié)果.表1報告了具體的檢索精度.圖5報告了位長可變方法與直接訓(xùn)練方法前500張的準(zhǔn)確率.

Table 1 Image Retrieval Results (Mean Average Precision, MAP) with Various Number of Hash Bit on the CIFAR-10 Dataset
Note: The bold indicates the best results.

Fig. 5 Precision on CIFAR-10 dataset圖5 CIFAR-10數(shù)據(jù)集上的檢索準(zhǔn)確率
2 融合多類型語義的深度表達(dá)模型
從單張圖片中感知場景的幾何結(jié)構(gòu)是人類視覺系統(tǒng)的一項基本能力,但是對于現(xiàn)有的多數(shù)智能系統(tǒng),例如機(jī)器人、自動巡航儀,這仍舊是一項十分具有挑戰(zhàn)性的任務(wù).本節(jié)重點研究場景幾何屬性分析問題,即給定輸入的場景圖像,輸出像素級別的場景幾何面標(biāo)注,同時對不同幾何面之間的交互關(guān)系進(jìn)行預(yù)測.與傳統(tǒng)場景分析方法[36-40]僅僅用于分割出場景中的視覺元素(如“建筑物”、“車輛”、“樹木”等)不同,場景的幾何屬性分析需要更深層次地理解場景中的內(nèi)容.其主要包含2個難點:1)在確定的場景內(nèi)容中,同一個幾何區(qū)域常常包含不同的語義區(qū)域和空間配置.例如,樹木和建筑物雖然屬于不同語義區(qū)域,但是它們卻同屬于“垂直面”這一幾何區(qū)域.2)除了對幾何區(qū)域進(jìn)行識別之外,對幾何區(qū)域之間的關(guān)系預(yù)測也至關(guān)重要.一方面,幾何關(guān)系的預(yù)測能夠反過來約束幾何面的預(yù)測;另一方面,關(guān)系的有效挖掘?qū)τ诨謴?fù)場景的幾何結(jié)構(gòu)有著巨大的幫助.

Fig. 6 An illustration of our geometric scene parsing圖6 場景幾何屬性分析示意圖
圖6給出了場景的幾何屬性分析的示意圖,其中第1列是輸入圖片以及算法預(yù)測出的幾何標(biāo)注,第2列是算法預(yù)測出的幾何面之間的交互關(guān)系.針對這一問題,我們需要在模型的訓(xùn)練過程中引入類型豐富的語義信息.例如,場景區(qū)域的幾何類別信息(天空、水平面、垂直面等),以及幾何面之間的交互關(guān)系(同類關(guān)系、支撐關(guān)系、層次關(guān)系等).2種類型的語義知識可以相互作用,從3個方面共同促進(jìn)幾何屬性分析的效果:1)相鄰區(qū)塊在局部的語義一致性.例如圖6中,雖然“建筑物”和“樹木”具有較大的外觀差異,但是它們同屬于“垂直面”的范疇.因此在建模的過程中,需要通過像素/超像素級的類別標(biāo)簽去促進(jìn)較大幾何區(qū)域的識別能力.2)局部區(qū)域上區(qū)塊之間關(guān)系的一致性.例如,“建筑物”和“地面”之間應(yīng)該存在“支撐關(guān)系”,“樹木”和“地面”之間也存在“支撐關(guān)系”,則在局部關(guān)系一致性的前提下,“建筑物”和“樹木”應(yīng)該存在“類同關(guān)系”.3)幾何面類別屬性和關(guān)系屬性之間的一致性,也就是說特定的幾何面之間應(yīng)該呈現(xiàn)特定的幾何關(guān)系.
基于以上討論,本文提出一種基于高階圖模型的長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(high-order graph LSTM network, HG-LSTM),并將其用于場景的上下文表達(dá)建模中,從而使得幾何面的標(biāo)注和幾何面間交互關(guān)系的預(yù)測能夠從局部到全局地保持一致性.該模型包括2個相互耦合的子網(wǎng)絡(luò)結(jié)構(gòu):1)面向超像素本身構(gòu)建的基于圖模型的長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò),用于對幾何面進(jìn)行像素級別的標(biāo)注.由于幾何面的分割是幾何面關(guān)系預(yù)測基礎(chǔ),因此該子網(wǎng)絡(luò)在本節(jié)中表述為First-order LSTM,簡稱F-LSTM.2)面向超像素之間關(guān)系構(gòu)建的基于圖模型的長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò),用于對幾何面之間的交互關(guān)系進(jìn)行預(yù)測.這里圖模型的節(jié)點用于表示任意相鄰超像素之間的交互關(guān)系,因此該子網(wǎng)絡(luò)在本節(jié)中稱為Second-order LSTM,簡稱S-LSTM.與F-LSTM相類似,S-LSTM中的節(jié)點之間也能夠相互傳遞信息,從而在局部上保持近鄰超像素對之間語義關(guān)系的一致性.本節(jié)提出的2個子網(wǎng)絡(luò)能夠相互之間傳遞信息,從而使得整個網(wǎng)絡(luò)更為全面地挖掘場景的上下文信息,聯(lián)合的優(yōu)化過程也有助于2個子任務(wù)的相互促進(jìn).
2.1 基于長短期記憶神經(jīng)網(wǎng)絡(luò)的上下文學(xué)習(xí)
本節(jié)提出一種新的基于高階圖模型的長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(HG-LSTM)模型用于對場景的上下文進(jìn)行學(xué)習(xí).借助多種類型的語義信息,實現(xiàn)場景幾何屬性的分析任務(wù).如圖7所示,輸入圖像首先經(jīng)過卷積神經(jīng)網(wǎng)絡(luò)(CNN)生成圖像的卷積特征表達(dá).之后模型將借助第三方算法從圖片中提取一系列的超像素,并將這些超像素的分割結(jié)果作用在卷積特征表達(dá)上,傳入到F-LSTM網(wǎng)絡(luò)中用于對幾何面進(jìn)行標(biāo)注/分割.同時,任意2個相鄰的超像素將產(chǎn)生一個關(guān)系表達(dá),將所有的超像素對生成的關(guān)系集合構(gòu)建起圖模型并傳入到S-LSTM中,從而進(jìn)行幾何面之間的關(guān)系預(yù)測.這里需要說明的是,在本模型中底層的超像素構(gòu)成了一階的圖模型,圖模型的邊表示了2個超像素之間的關(guān)系.此關(guān)系將被抽象成二階圖模型中的節(jié)點.

Fig. 7 The proposed LSTM recurrent framework for geometric scene parsing圖7 提出的基于高階圖模型的長短期記憶循環(huán)神經(jīng)網(wǎng)絡(luò)

(7)

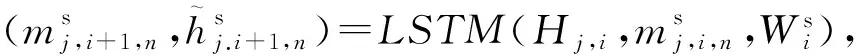
(8)
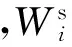
(9)


Fig. 8 The structure of F-LSTM[41]圖8 F-LSTM的結(jié)構(gòu)示例[41]
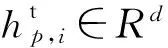
(10)

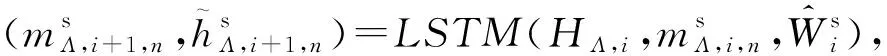

(11)
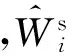
(12)

2.2 場景幾何屬性分析中的應(yīng)用
我們使用了2個數(shù)據(jù)集分別是LM+SUN數(shù)據(jù)集[42]和Cityscapes數(shù)據(jù)集[6].其中,LM+SUN數(shù)據(jù)集包含45 676張圖片(21 182張室內(nèi)圖片、24 494張室外圖片);Cityscapes數(shù)據(jù)集是一個用于對城市街道場景進(jìn)行語義分割的數(shù)據(jù)集.本節(jié)使用了該數(shù)據(jù)集中的2 975張精細(xì)標(biāo)注的圖片作為訓(xùn)練圖片,500張圖片作為測試圖片.本文使用了像素準(zhǔn)確率、平均類別準(zhǔn)確率和平均交并比(IoU)作為幾何面標(biāo)注評測指標(biāo),使用了平均準(zhǔn)確率作為幾何關(guān)系預(yù)測的評測指標(biāo).
1) 幾何面標(biāo)注任務(wù).表2列舉了提出的方法與當(dāng)前3種方法的平均IoU以及平均準(zhǔn)確率.在2個數(shù)據(jù)集上實驗結(jié)果說明了2個問題:①將F-LSTM網(wǎng)絡(luò)和S-LSTM網(wǎng)絡(luò)相結(jié)合能夠有效捕捉復(fù)雜的上下文信息,進(jìn)而對外觀差異巨大的幾何面進(jìn)行有效地標(biāo)注;②在較大的數(shù)據(jù)集LM+SUN上,效果更為明顯.說明本文的方法在處理海量數(shù)據(jù)的問題時,將具有更為突顯的效果.
2) 交互關(guān)系預(yù)測.S-LSTM子網(wǎng)絡(luò)可以對2個相鄰超像素之間的幾何關(guān)系進(jìn)行預(yù)測.在所有實驗中,我們將每張圖片分割成1 024個超像素.任意2個相鄰的超像素之間定義了其幾何關(guān)系,表3展示了2個數(shù)據(jù)集上不同S-LSTM層輸出的關(guān)系預(yù)測的平均準(zhǔn)確率.通過實驗可以看到,在大多數(shù)情況下,隨著HG-LSTM層數(shù)的加深,預(yù)測的準(zhǔn)確率也將進(jìn)一步提升.這說明學(xué)習(xí)到的關(guān)系特征表達(dá)將隨著層數(shù)的加深更加具有判別性.
3) 基于單張圖片的三維重建.我們將利用文獻(xiàn)[43]中的提出的pop-up模型,基于場景幾何解析的結(jié)果實現(xiàn)單張圖片的三維場景重建.該模型利用預(yù)測的幾何面及其之間的關(guān)系對圖片進(jìn)行“切割和折疊”操作.這個過程可以分為2個步驟:①通過近鄰超像素之間的幾何關(guān)系恢復(fù)出三維的空間結(jié)構(gòu);②通過將圖片匯總對應(yīng)幾何區(qū)域的外觀、紋理信息賦值給三維空間中的不同平面,輸出最終的重建結(jié)果.圖9展示了部分場景圖片以及在本文幾何屬性預(yù)測的結(jié)果之上,通過第三方軟件重建出來的不同視角下的三維效果圖,其中,圖9(a)是輸入的原始圖像,圖9(b)是重建后在不同視角下的結(jié)果.

Table 2 Performance of Geometric Surface Labeling Over LM+SUN and Cityscapes

Table 3 Geometric Relation Prediction with Different Number of S-LSTM Layers

Fig. 9 Some results of single-view 3D reconstruction圖9 利用本節(jié)場景幾何屬性的分析結(jié)果實現(xiàn)的單張圖片的三維重建結(jié)果
3 融合結(jié)構(gòu)化語義的深度表達(dá)模型
場景解析任務(wù)的核心目的是通過構(gòu)建模型,從圖像中推斷出符合人類認(rèn)知的場景配置信息,例如物體的部件、物體本身以及它們之間的交互關(guān)系等.現(xiàn)有的場景理解工作多集中于場景的標(biāo)注或分割問題[44,47-48],即為場景圖像中的每一個像素賦予類別標(biāo)簽.但是卻很少有工作針對輸入的場景圖片,生成有意義的結(jié)構(gòu)化配置.其原因在于,該類工作通常包含兩大困難:1)傳統(tǒng)的融入語法知識的視覺模型[49]中,場景的結(jié)構(gòu)化信息通常存在著多義性.相同的場景可能存在多個合理的結(jié)構(gòu)化配置,因此,如何使得得到的場景結(jié)構(gòu)化配置更加符合人類的認(rèn)知規(guī)律,是解決該類問題的第1個挑戰(zhàn).2)模型訓(xùn)練數(shù)據(jù)的獲取成本高昂.在使用傳統(tǒng)的有監(jiān)督學(xué)習(xí)方法對場景結(jié)構(gòu)化解析模型進(jìn)行訓(xùn)練時,需要包括像素級標(biāo)簽、物體之間關(guān)系、場景結(jié)構(gòu)在內(nèi)的多種語義信息.每種信息都具有較高的復(fù)雜性,且成體呈現(xiàn)較為明顯的結(jié)構(gòu)化.如果通過手工進(jìn)行標(biāo)注,標(biāo)注的成本將極其昂貴.這也極大地限制了包括深度神經(jīng)網(wǎng)絡(luò)在內(nèi)的數(shù)據(jù)驅(qū)動型模型在相關(guān)問題上的發(fā)展.

Fig. 11 The structured prediction of a scene image using our proposed CNN-RNN model圖11 利用本節(jié)提出的CNN-RNN模型對場景圖片進(jìn)行結(jié)構(gòu)化預(yù)測
圖10給出了視覺場景解析的示意圖,其中輸入圖片被自動地解析成包含分層的語義物體(黑色標(biāo)簽標(biāo)注)以及物體之間的交互關(guān)系(紅色標(biāo)簽標(biāo)注)在內(nèi)的結(jié)構(gòu)化配置.當(dāng)輸入一副場景圖片時,模型將會自動輸出一個包含有物體之間交互關(guān)系的場景結(jié)構(gòu)化配置.針對這一問題,我們需要在對深度模型訓(xùn)練過程中引入結(jié)構(gòu)化的語義知識.例如,場景中像素/超像素級別的類別信息(人、馬、草地等),物體之間的交互信息(人騎馬、人牽馬等),以及整個場景的組合配置結(jié)構(gòu),同時要盡可能降低上述語義知識獲取的成本.一個直觀的方法就是借助自然語言的標(biāo)準(zhǔn)解析模型[50]、WordNet詞語知識庫[51]以及相應(yīng)的后處理操作,將圖像的語句標(biāo)注解析成一棵包含了名詞和動詞的語義樹,從而廉價高效地獲得場景結(jié)構(gòu)化所需要的全部監(jiān)督信息.

Fig. 10 An illustration of our structured scene parsing圖10 視覺場景解析的示意圖
為了更好地利用上述結(jié)構(gòu)化語義知識,本節(jié)提出一種新的混合神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),用于深度結(jié)構(gòu)化場景解析任務(wù).該網(wǎng)絡(luò)包含了2個相互連接的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),底層是深度卷積神經(jīng)網(wǎng)絡(luò)(CNN)[1,44],上層是遞歸神經(jīng)網(wǎng)絡(luò)(RNN)[15].前者能夠生成具有判別能力的圖像特征表達(dá),因此被廣泛地應(yīng)用于圖像分類與物體識別任務(wù)中;后者則被一系列工作[48,52-53]證明能夠?qū)D像或者自然語言[15]中的結(jié)構(gòu)化組合關(guān)系進(jìn)行預(yù)測,其原因在于該類網(wǎng)絡(luò)能夠同時對語義和結(jié)構(gòu)化表達(dá)進(jìn)行遞歸地學(xué)習(xí).對于本節(jié)所提出的CNN-RNN模型、CNN模型和RNN模型將協(xié)同工作.其中,CNN模型將被用作物體類別的表達(dá)學(xué)習(xí);RNN模型將把CNN模型產(chǎn)生的特征表達(dá)作為輸入,用于進(jìn)一步生成場景的結(jié)構(gòu)化配置.受圖片描述生成模型[54-55]的啟發(fā),本節(jié)還提出了一種弱監(jiān)督訓(xùn)練方法對CNN-RNN模型進(jìn)行訓(xùn)練.
3.1 基于CNN-RNN混合神經(jīng)網(wǎng)絡(luò)的場景語義表達(dá)
本節(jié)所提出的場景內(nèi)容解析模型主要完成以下3個方面工作:語義實體的標(biāo)注、分層結(jié)構(gòu)的生成以及物體之間交互關(guān)系的預(yù)測.圖11舉例說明了場景結(jié)構(gòu)化解析的過程.
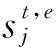
(13)

(14)
為了生成每一個實體類別的特征表達(dá),算法將具有相同類別標(biāo)簽的像素聚合到一起獲得具體的語義實體.我們將使用Log-Sum-Exp(LSE)[57]方法來融合不同像素的特征表達(dá),最終獲得物體區(qū)域的特征表達(dá).
在本節(jié)的模型中,RNN模型將利用CNN模型所輸出的每個語義類別的特征表達(dá)來生成圖像的解析樹,從而對圖像進(jìn)行內(nèi)容上的分層表達(dá),同時預(yù)測語義實體之間的交互關(guān)系.這里的RNN模型包含5個子網(wǎng)絡(luò),分別是中間轉(zhuǎn)換網(wǎng)絡(luò)(用transitionmapper表示)、節(jié)點合并網(wǎng)絡(luò)(用combiner表示)、語義解釋網(wǎng)絡(luò)(用interpreter表示)、關(guān)系分類網(wǎng)絡(luò)(用categorizer表示)和合并分?jǐn)?shù)網(wǎng)絡(luò)(用scorer表示),則RNN網(wǎng)絡(luò)的參數(shù)集合可以表述為WR={Wtran,Wcom,Wcat,Wscore}.

Fig. 12 An illustrate of recursive neural network圖12 遞歸結(jié)構(gòu)示意圖
如圖12所示,實體的特征vk首先將被輸入到中間轉(zhuǎn)換網(wǎng)絡(luò)中進(jìn)行特征空間的變化,該層在神經(jīng)網(wǎng)絡(luò)中用一個全連接的神經(jīng)網(wǎng)絡(luò)表示,其中,xk表示映射的特征.而后,被變化的2個實體的特征(xk和xl)將被作為遞歸樹種的2個子節(jié)點輸入到節(jié)點合并網(wǎng)絡(luò)Fcom,并輸出父節(jié)點的特征表達(dá)xk l來表達(dá)2個子節(jié)點的語義信息及合并的結(jié)構(gòu)信息.進(jìn)一步,關(guān)系分類網(wǎng)絡(luò)Fcat通過xk l預(yù)測2個節(jié)點之間的語義關(guān)系yk l.同時,合并分?jǐn)?shù)網(wǎng)絡(luò)Fscore度量出2個子節(jié)點能夠合并的置信度hk l.
3.2 融入語法知識的弱監(jiān)督學(xué)習(xí)方法
1) 語句預(yù)處理.為了能夠利用圖片的語句標(biāo)注有效地進(jìn)行場景的標(biāo)注和結(jié)構(gòu)化配置,本節(jié)將利用一些自然語言處理的基本技術(shù)將語句轉(zhuǎn)換成為語義樹.如圖13所示.在圖例的頂端,語言解析工具將根據(jù)輸入的語句生成一個構(gòu)造語法樹.圖例的中間展示了對構(gòu)造語法樹中的詞語進(jìn)行過濾的過程.圖例的最低端展示了轉(zhuǎn)換之后的語義樹.
2) 損失函數(shù). 對于輸入圖像Ii,假設(shè)全標(biāo)記的語義圖Ci和真實的語義樹Ti已知.則損失函數(shù)可以定義為3個部分的累加,分別是:語義標(biāo)記的損失JC,場景結(jié)構(gòu)的損失JR,和模型參數(shù)的正則化約束R(W).對于一個包含Z張圖片{(I1,C1,T1),(I2,C2,T2),…,(IZ,CZ,TZ)}的數(shù)據(jù)集,損失函數(shù)可以定義為
(15)
其中,W={WC,WR}表示模型所有的參數(shù);WC,WR分別表示CNN模型和RNN模型的參數(shù).

Fig. 13 An illustration of the tree conversion process圖13 圖片的描述語句變換成解析樹的具體過程
① 語義表述的損失.令Cf表示最終預(yù)測的語義圖,Ce表示第e個尺度下預(yù)測的語義圖.則圖像I在語義標(biāo)注任務(wù)上的最終的損失函數(shù)可以定義為
(16)
其中,i={1,2,…,Z}.Lf表示最終預(yù)測語義圖Cf以及全標(biāo)記的語義圖Ci之間的損失.為了考慮多尺度下的預(yù)測,我們同時定義了每一個尺度下的損失Le,{e=1,2,…,E}.
② 場景結(jié)構(gòu)的損失.場景結(jié)構(gòu)的損失可以進(jìn)一步表示為2個部分.第1部分用于定義場景結(jié)構(gòu)化的構(gòu)建中的損失,第2部分用于定義物體之間關(guān)系的損失,
JR(W;I,T)=Jstruc(W;I,TS)+Jrel(W;I,TR),
(17)

Jstruc(W;I,TS)=
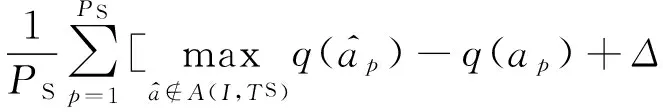
(18)


3.3 場景結(jié)構(gòu)化解析中的應(yīng)用
本節(jié)首先使用了PASCAL VOC 2012[58]的語義分割數(shù)據(jù)集作為測試本節(jié)提出方法的標(biāo)準(zhǔn)數(shù)據(jù)集.該數(shù)據(jù)集包括20個前景語義類和一個背景類,共計有1 464張標(biāo)注圖片用于訓(xùn)練,有1 456張圖片用于測試.同時,我們還自行構(gòu)建了一個新的用于場景語義解析的數(shù)據(jù)集SYSU-Scenes.該數(shù)據(jù)集包括5 046張圖片,涉及到33個語義類別.對于每張圖片,我們提供了物體的語義標(biāo)注圖、場景的分層結(jié)構(gòu)標(biāo)注和語義物體之間的交互關(guān)系在內(nèi)的3種標(biāo)注信息.在所有的圖片中,將有3 793張圖片用于訓(xùn)練、1 253張圖片用于測試.在上述2個數(shù)據(jù)集中,我們分別定義了9種和13種常見的物體之間的交互關(guān)系.

Fig. 14 Visualized scene parsing result of weakly supervised method on PASCAL VOC 2012圖14 PASCAL VOC 2012數(shù)據(jù)集上弱監(jiān)督條件下的場景解析可視化結(jié)果
1) 語義標(biāo)注任務(wù).為了評測本節(jié)提出方法在場景的語義標(biāo)注任務(wù)上的效果,我們將像素級別的標(biāo)簽預(yù)測圖上采樣到與原始的真實標(biāo)注同樣的大小.分別使用像素準(zhǔn)確率、平均類別準(zhǔn)確率和平均IoU[44]作為評測指標(biāo)對本節(jié)提出的方法進(jìn)行評估.對于語義標(biāo)注任務(wù),表4和表5分別列舉了在3種評測指標(biāo)下相關(guān)方法在PASCAL VOC 2012數(shù)據(jù)集和SYSU-Scene數(shù)據(jù)集上的結(jié)果.
2) 場景結(jié)構(gòu)生成任務(wù).本節(jié)首先引入2個用于場景結(jié)構(gòu)生成的評測指標(biāo):結(jié)構(gòu)準(zhǔn)確率和平均關(guān)系準(zhǔn)確率.令T是由CNN-RNN模型生成的圖像的解析樹,P={T,T_1,T_2,…,T_m}表示解析樹所有子樹的集合.對于葉節(jié)點,算法認(rèn)為其正確當(dāng)且僅當(dāng)其對應(yīng)的語義類別同語義樹(由描述語句生成)中對應(yīng)位置的名詞相一致.對于非葉子節(jié)點T_i(存在2個子樹T_l和T_r),我們說T_1是正確的,當(dāng)且僅當(dāng)左右子樹都是正確的,且2棵子樹之間的關(guān)系也是正確的.則關(guān)系的準(zhǔn)確率可以定義為(#ofcorrectsubtrees)(m+1),該準(zhǔn)確率可以通過遞歸遍歷整個樹結(jié)構(gòu)而獲得.而平均的關(guān)系準(zhǔn)確率只是每個類別關(guān)系準(zhǔn)確率的平均值.表6報告了PASCAL VOC 2012數(shù)據(jù)集和SYSU-Scene數(shù)據(jù)集上的測試結(jié)果.圖14展示了場景結(jié)構(gòu)化解析的可視化結(jié)果,圖14(a)是解析正確的示例,圖14(b)是失敗的示例.在每個示例中,左邊的樹結(jié)構(gòu)是基于圖像的描述語句生成的,右邊的樹結(jié)構(gòu)是通過本文的CNN-RNN模型預(yù)測得到的.
Table 4 PASCAL VOC 2012 Result of Weakly Supervised Methods
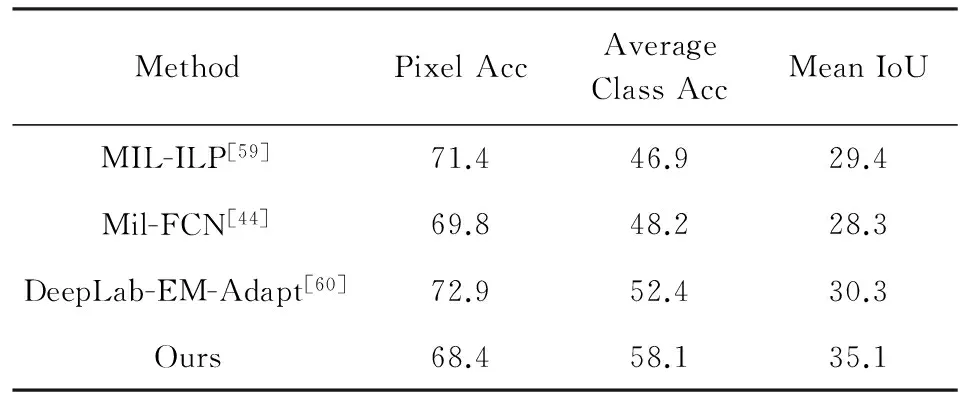
表4 弱監(jiān)督學(xué)習(xí)方法在PASCAL VOC 2012 數(shù)據(jù)集上的結(jié)果 %

Table 5 SYSU-Scenes Result of Weakly Supervised Methods

Table 6 Comparison of Different Learning Strategies on Two Datasets
4 結(jié)束語
隨著機(jī)器視覺技術(shù)、智能硬件、多媒體技術(shù)的快速發(fā)展,針對大規(guī)模視覺數(shù)據(jù)的高層次理解任務(wù)成為了當(dāng)前最熱門的研究方向.而如何借助豐富的語義知識提升深度模型的表達(dá)學(xué)習(xí)能力,又是處理上述任務(wù)的重要技術(shù)手段.本文主要研究了融合語義知識的深度表達(dá)學(xué)習(xí).基于視覺數(shù)據(jù)的相似性比對,場景數(shù)據(jù)的內(nèi)容解析等應(yīng)用場景對該問題進(jìn)行了深度探討和研究.主要研究內(nèi)容可以概括為3個方面:
1) 研究了將單類型語義知識融入到深度表達(dá)模型中,提出了嵌入正則化語義關(guān)聯(lián)的深度Hash學(xué)習(xí)方法,并將其應(yīng)用于圖像的相似性比對與檢索問題中;
2) 研究了將多類型語義知識與深度模型的學(xué)習(xí)相結(jié)合,提出了基于長短期記憶神經(jīng)網(wǎng)絡(luò)的場景上下文學(xué)習(xí)方法,并將其應(yīng)用于復(fù)雜場景的幾何屬性分析問題中;
3) 研究了將視覺數(shù)據(jù)的結(jié)構(gòu)化語義配置融入到深度表達(dá)的學(xué)習(xí)中,提出了融合語法知識的表達(dá)學(xué)習(xí)方法,并將其應(yīng)用到復(fù)雜場景下的通用內(nèi)容解析問題中.
本文針對融合語義知識的深度表達(dá)學(xué)習(xí)及其在視覺理解中的應(yīng)用進(jìn)行了相關(guān)的研究和討論.但是針對實際的應(yīng)用場景,完全解決計算視覺中各種面向高層理解的任務(wù)仍然需要長期不懈的探索.類似的任務(wù)包括如何利用更為豐富的語法知識實現(xiàn)深入和精確的解析算法、如何利用海量的視覺數(shù)據(jù)自動地強(qiáng)化模型的表達(dá)能力、如何處理高層視覺理解中的多義性和不確定性、如何針對視覺信息進(jìn)行行為估計和預(yù)判、如何更為自然流暢地進(jìn)行視覺問答等.上述問題的解決將對未來人工智能的發(fā)展起到積極的推動作用.從學(xué)術(shù)研究角度來說,設(shè)計和發(fā)展更為輕量化、高效化的表達(dá)模型來解決上述問題,使用無標(biāo)注數(shù)據(jù)來進(jìn)行模型的訓(xùn)練,自動地挖掘視覺數(shù)據(jù)中的語義知識都是亟待解決的學(xué)術(shù)問題.
[1]Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2012: 1097-1105
[2]Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231
[3]Wang X, Zhang L, Lin L, et al. Deep joint task learning for generic object extraction[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 523-531
[4]Russakovsky O, Deng J, Su H, et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211-252
[5]Xiao J, Ehinger K A, Hays J, et al. Sun database: Exploring a large collection of scene categories[J]. International Journal of Computer Vision, 2016, 119(1): 3-22
[6]Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C] //Proc of the 2016 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2016: 3213-3223
[7]LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444[8]Srivastava N, Hinton G E, Krizhevsky A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958
[9]Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C] //Proc of Aistats. Brookline, MA: Microtome Publishing, 2011, 15(106): 275
[10]Zhu Rong. Research on key problems of image understanding based on semantic information[J]. Application Research of Computers, 2009, 26(4): 1234-1240 (in Chinese)
(朱蓉. 基于語義信息的圖像理解關(guān)鍵問題研究[J]. 計算機(jī)應(yīng)用研究, 2009, 26(4): 1234-1240)
[11]LeCun Y, Boser B, Denker J S, et al. Backpropagation applied to handwritten zip code recognition[J]. Neural Computation, 1989, 1(4): 541-551
[12]Zhang Lei, Lin Fuzong, Zhang Ba. A forward neural network based relevance feedback algorithm design in image retrieval[J]. Chinese Journal of Computers, 2002, 25(7): 673-680 (in Chinese)
(張磊, 林福宗, 張鈸. 基于前向神經(jīng)網(wǎng)絡(luò)的圖像檢索相關(guān)反饋算法設(shè)計[J]. 計算機(jī)學(xué)報, 2002, 25(7): 673-680)
[13]Li Qingyong, Hu Hong, Shi Zhiping, et al. Research on texture-based semantic image retrieval[J]. Chinese Journal of Computers, 2006, 29(1): 116-123 (in Chinese)
(李清勇, 胡宏, 施智平, 等. 基于紋理語義特征的圖像檢索研究[J]. 計算機(jī)學(xué)報, 2006, 29(1): 116-123)
[14]Elman J L. Distributed representations, simple recurrent networks, and grammatical structure[J]. Machine Learning, 1991, 7(2/3): 195-225
[15]Socher R, Manning C D, Ng A Y. Learning continuous phrase representations and syntactic parsing with recursive neural networks[C] //Proc of the NIPS-2010 Deep Learning and Unsupervised Feature Learning Workshop. Cambridge, MA: MIT Press, 2010: 1-9
[16]Jegou H, Douze M, Schmid C. Hamming embedding and weak geometric consistency for large scale image search[C] //Proc of the 10th European Conf on Computer Vision. Berlin: Springer, 2008: 304-317
[17]Wang J, Song Y, Leung T, et al. Learning fine-grained image similarity with deep ranking[C] //Proc of the 2014 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2014: 1386-1393
[18]Liu Z, Li H, Zhou W, et al. Contextual hashing for large-scale image search[J]. IEEE Trans on Image Processing, 2014, 23(4): 1606-1614
[19]Cao L, Li Z, Mu Y, et al. Submodular video hashing: A unified framework towards video pooling and indexing[C] //Proc of the 20th ACM Int Conf on Multimedia. New York: ACM, 2012: 299-308
[20]Peng Tianqiang, Li Fang. Image retrieval based on deep convolutional neural networks and binary hashing learning[J]. Journal of Electronics & Information Technology, 2016, 38(8): 2068-2075 (in Chinese)
(彭天強(qiáng), 栗芳. 基于深度卷積神經(jīng)網(wǎng)絡(luò)和二進(jìn)制哈希學(xué)習(xí)的圖像檢索方法[J]. 電子與信息學(xué)報, 2016, 38(8): 2068-2075)
[21]Li X, Lin G, Shen C, et al. Learning Hash functions using column generation[C] //Proc of ICML. Brookline, MA: Microtome Publishing, 2013: 142-150
[22]Liu W, Wang J, Ji R, et al. Supervised hashing with kernels[C] //Proc of 2012 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2012: 2074-2081
[23]Kong W, Li W J. Isotropic hashing[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2012: 1646-1654
[24]Zhu X, Zhang L, Huang Z. A sparse embedding and least variance encoding approach to hashing[J]. IEEE Trans on Image Processing, 2014, 23(9): 3737-3750
[25]Cheng J, Leng C, Li P, et al. Semi-supervised multi-graph hashing for scalable similarity search[J]. Computer Vision and Image Understanding, 2014, 124: 12-21
[26]Chechik G, Sharma V, Shalit U, et al. Large scale online learning of image similarity through ranking[J]. Journal of Machine Learning Research, 2010, 11(3): 1109-1135
[27]Frome A, Singer Y, Malik J. Image retrieval and classification using local distance functions[C] //Proc of the 19th Int Conf on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2006: 417-424
[28]Ding S, Lin L, Wang G, et al. Deep feature learning with relative distance comparison for person re-identification[J]. Pattern Recognition, 2015, 48(10): 2993-3003
[29]Gao S, Tsang I W H, Chia L T. Laplacian sparse coding, hypergraph laplacian sparse coding, and applications[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(1): 92-104
[30]Weiss Y, Fergus R, Torralba A. Multidimensional spectral hashing[C] //Proc of the 12th European Conf on Computer Vision. Berlin: Springer, 2012: 340-353
[31]Norouzi M, Blei D M. Minimal loss hashing for compact binary codes[C] //Proc of the 28th Int Conf on Machine Learning (ICML-11). Brookline, MA: Microtome Publishing, 2011: 353-360
[32]Kulis B, Darrell T. Learning to Hash with binary reconstructive embeddings[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2009: 1042-1050
[33]Zhao F, Huang Y, Wang L, et al. Deep semantic ranking based hashing for multi-label image retrieval[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1556-1564
[34]Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2012: 1097-1105
[35]Babenko A, Slesarev A, Chigorin A, et al. Neural codes for image retrieval[C] //Proc of European Conf on Computer Vision. Berlin: Springer, 2014: 584-599
[36]Luo Xiping, Tian Jie. Overview of image segmentation methods[J]. Pattern Recognition & Artificial Intelligence, 1999, 12(3): 300-312 (in Chinese)
(羅希平, 田捷. 圖像分割方法綜述[J]. 模式識別與人工智能, 1999, 12(3): 300-312)
[37]Wang Xili, Liu Fang, Jiao Licheng. Multiscale Bayesian image segmentation fusin context information[J]. Chinese Journal of Computers, 2005, 28(3): 386-391 (in Chinese)
(汪西莉, 劉芳, 焦李成. 融合上下文信息的多尺度貝葉斯圖像分割[J]. 計算機(jī)學(xué)報, 2005, 28(3): 386-391)
[38] He Ning, Zhang Peng. Varitional level set image segmentation method based on boundary and region information[J]. Acta Electronica Sinica, 2009, 37(10): 2215-2219 (in Chinese)
(何寧, 張朋. 基于邊緣和區(qū)域信息相結(jié)合的變分水平集圖像分割方法[J]. 電子學(xué)報, 2009, 37(10): 2215-2219)
[39]Guo Lei, Hou Yimin, Lun Xiangmin. An unsupervised color image segmentation algorithm based on context information[J]. Pattern Recognition & Artificial Intelligence, 2008, 21(1): 82-87 (in Chinese)
(郭雷, 侯一民, 倫向敏. 一種基于圖像上下文信息的無監(jiān)督彩色圖像分割算法[J]. 模式識別與人工智能, 2008, 21(1): 82-87)
[40]Qiu Zeyu, Fang Quan, Sang Jitao, et al. Regional context-aware image annotation[J]. Chinese Journal of Computers, 2014, 37(6): 1390-1397 (in Chinese)
(邱澤宇, 方全, 桑基韜, 等. 基于區(qū)域上下文感知的圖像標(biāo)注[J]. 計算機(jī)學(xué)報, 2014, 37(6): 1390-1397)
[41]Liang X, Shen X, Feng J, et al. Semantic object parsing with graph LSTM[C] //Proc of European Conf on Computer Vision. Berlin: Springer, 2016: 125-143
[42]Tighe J, Lazebnik S. Superparsing: Scalable nonparametric image parsing with superpixels[C] //Proc of European Conf on Computer Vision. Berlin: Springer, 2010: 352-365
[43]Hoiem D, Efros A A, Hebert M. Automatic photo pop-up[J]. ACM Trans on Graphics, 2005, 24(3): 577-584
[44]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2015: 3431-3440
[45]Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFS[J]. arXiv preprint arXiv: 1412.7062, 2014
[46]Peng Z, Zhang R, Liang X, et al. Geometric scene parsing with hierarchical LSTM[C] //Proc of IJCAI-16. Palo Alto, CA: AAAI Press, 2016: 3439-3445
[47]Lempitsky V, Vedaldi A, Zisserman A. Pylon model for semantic segmentation[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2011: 1485-1493
[48]Sharma A, Tuzel O, Liu M Y. Recursive context propagation network for semantic scene labeling[C] //Proc of Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2447-2455
[49]Zhu S C, Mumford D. A stochastic grammar of images[J]. Foundations and Trends?in Computer Graphics and Vision, 2007, 2(4): 259-362
[50]Socher R, Bauer J, Manning C D, et al. Parsing with compositional vector grammars[C] //Proc of ACL (1). Stroudsburg, PA: ACL: 2013: 455-465
[51]Miller G A, Beckwith R, Fellbaum C, et al. Introduction to WordNet: An on-line lexical database[J]. International Journal of Lexicography, 1990, 3(4): 235-244
[52]Socher R, Lin C C, Manning C, et al. Parsing natural scenes and natural language with recursive neural networks[C] //Proc of the 28th Int Conf on Machine Learning (ICML-11). Brookline, MA: Microtome Publishing, 2011: 129-136
[53]Sharma A, Tuzel O, Jacobs D W. Deep hierarchical parsing for semantic segmentation[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2015: 530-538
[54]Karpathy A, Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2015: 3128-3137
[55]Xu J, Schwing A G, Urtasun R. Tell me what you see and I will show you where it is[C] //Proc of the 2014 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2014: 3190-3197
[56]Xie S, Tu Z. Holistically-nested edge detection[C] //Proc of the IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2015: 1395-1403
[57]Boyd S, Vandenberghe L. Convex Optimization[M]. Cambridge, UK: Cambridge University Press, 2004
[58]Everingham M, Eslami S M A, Van Gool L, et al. The pascal visual object classes challenge: A retrospective[J]. International Journal of Computer Vision, 2015, 111(1): 98-136
[59]Pinheiro P O, Collobert R. From image-level to pixel-level labeling with convolutional networks[C] //Proc of the 2015 IEEE Conf on Computer Vision and Pattern Recognition (CVPR). Piscataway, NJ: IEEE, 2015: 1713-1721
[60]Papandreou G, Chen L C, Murphy K P, et al. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation[C] //Proc of the IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2015: 1742-1750


Peng Jiefeng, born in 1993. Received his BEn degree from the School of Mathematics, Sun Yat-sen University, Guangzhou, China, in 2016. Master candidate in computer science at the School of Data and Computer Science. His main research interests include deep learning, computer vision, and related applications.

Wu Yang, born in 1993. Received her bachelor degree from the School of Mathematics, South China University of Technology, Guangzhou, China, in 2016. Master candidate in computer science in the School of Data and Computer Science. Her main research interests include computer vision, data mining, machine learning and other relevant areas.

Lin Liang, born in 1981. Received his BSc and PhD degrees from the Beijing Institute of Technology, Beijing, China, in 1999 and 2008, respectively. Professor with the School of Data and Computer Science, Sun Yat-sen University, China. Associate Editor of Neurocomputing and the Visual Computer. His main research interests include new models, algorithms, and systems for intelligent processing and understanding of visual data, such as images and videos.
The Semantic Knowledge Embedded Deep Representation Learning and Its Applications on Visual Understanding
Zhang Ruimao, Peng Jiefeng, Wu Yang, and Lin Liang
(SchoolofDataandComputerScience,SunYat-senUniversity,Guangzhou510006)
With the rapid development of deep learning technique and large scale visual datasets, the traditional computer vision tasks have achieved unprecedented improvement. In order to handle more and more complex vision tasks, how to integrate the domain knowledge into the deep neural network and enhance the ability of deep model to represent the visual pattern, has become a widely discussed topic in both academia and industry. This thesis engages in exploring effective deep models to combine the semantic knowledge and feature learning. The main contributions can be summarized as follows: 1)We integrate the semantic similarity of visual data into the deep feature learning process, and propose a deep similarity comparison model named bit-scalable deep hashing to address the issue of visual similarity comparison. The model in this thesis has achieved great performance on image searching and people’s identification. 2)We also propose a high-order graph LSTM (HG-LSTM) networks to solve the problem of geometric attribute analysis, which realizes the process of integrating the multi semantic context into the feature learning process. Our extensive experiments show that our model is capable of predicting rich scene geometric attributes and outperforming several state-of-the-art methods by large margins. 3)We integrate the structured semantic information of visual data into the feature learning process, and propose a novel deep architecture to investigate a fundamental problem of scene understanding: how to parse a scene image into a structured configuration. Extensive experiments show that our model is capable of producing meaningful and structured scene configurations, and achieving more favorable scene labeling result on two challenging datasets compared with other state-of-the-art weakly-supervised deep learning methods.
deep learning; neural networks; semantic embedding; scene parsing; similarity search
mao, born in 1989.
his PhD degree from the School of Data and Computer Science, Sun Yat-sen University, Guangzhou, China, in 2016. His main research interests include computer vision, pattern recognition, machine learning, and related applications.
2017-01-03;
2017-03-30
國家自然科學(xué)基金優(yōu)秀青年科學(xué)基金項目(6162200366) This work was supported by the National Natural Science Foundation of China for Excellent Young Scientists (NSFC) (6162200366).
TP391.41
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
