基于客戶投訴信息的創新預測方法研究
2017-06-10 17:40:49劉世偉呂景楠莫蘭
移動通信 2017年8期
關鍵詞:大數據
劉世偉+呂景楠+莫蘭
【摘 要】為了降低客戶升級投訴數量,通過對客戶投訴現狀進行分析,發現投訴處理環節的短板和不足,并利用大數據工具,使用海量的客戶投訴數據建立預測模型,對有升級傾向的投訴客戶進行預判,在投訴升級之前預先解決客戶的問題,從而提升客戶滿意度。
【關鍵詞】大數據 客戶投訴 決策樹 預測模型
doi:10.3969/j.issn.1006-1010.2017.08.016 中圖分類號:TP181 文獻標志碼:A 文章編號:1006-1010(2017)08-0079-06
引用格式:劉世偉,呂景楠,莫蘭. 基于客戶投訴信息的創新預測方法研究[J]. 移動通信, 2017,41(8): 79-84.
Research on an Novel Prediction Method Based on Customer Complaint Information
LIU Shiwei, LV Jingnan, MO Lan
[Abstract] In order to reduce the number of customers complaints against upgrade, the status of customers complaints was analyzed and shortcomings of complaint link were elaborated. By virtue of mathematical tools, the prediction model based on massive customers complaints was established to determine the potential customers apt to complain. Thus, the appeal of customers could be solved before upgrade to enhance the satisfaction of customers.
[Key words]big data customer complaint decision tree prediction model
1 研究背景
隨著移動業務產品、營銷活動開展的多樣化,客戶建議、投訴越來越多,同時工信部對運營商新增了“用戶申訴率”和“不明扣費申訴率”兩條紅線的考核,這也增加了運營商投訴部門的工作壓力。面對客戶規模化的投訴,應當建立更加科學化的系統管理機制,改善當前傳統管理方式,使兩條紅線指標控制在合理的范圍內,進而避免客戶產生升級投訴,更好地提升客戶忠誠度和滿意率,增加業務產品的良好口碑。
數字化、系統化使得企業擁有大量的客戶投訴數據,但并沒有很好地利用這些數據進行挖掘分析,也未能有效地從這些數據中找到客戶的需求點,無法真正了解客戶的意圖。服務及產品改進和創新需要了解客戶最真實的需求,對客戶投訴信息的挖掘和分析是關鍵。但是,目前還沒有基于客戶投訴信息來獲得改進和創新思路的成功方法,更多是人工根據多年的工作經驗進行淺層次的數據分析,難以形成說服力的建議。
因此,可以通過對客戶投訴數據進行深度的大數據分析和挖掘,提煉出各維度的權重,從投訴信息中挖掘隱含的客戶需求和商機,進而獲得服務及產品改進和創新思路的方法。有效地利用客戶投訴數據建立模型,對有升級傾向的投訴客戶進行預判,在投訴升級之前預先解決客戶的問題,以提高客戶滿意度。通過建模構建了中國移動投訴信息挖掘平臺,使得信息處理系統化、有序化和智能化,工作價值得到進一步提升,從而形成長效工作機制,為中國移動轉型和可持續發展提供強有力支撐和幫助,加強投訴信息利用和創新,提高企業核心競爭力。
2 客戶投訴分析
2.1 客戶投訴的現狀
投訴是客戶不滿意的表達,更能貼切反映客戶對產品業務的滿意度。客戶投訴數據主要通過文本和語音格式保留、投訴系統記錄保留這兩種方式存儲。當前客戶投訴信息主要用于解決客戶投訴的具體問題,對投訴背后的隱性問題分析很少,也沒有有效地通過投訴信息挖掘獲得服務和產品改進、創新思路。另外,當前客戶投訴處理環節比較傳統化,未有較好的創新點。
2.2 客戶投訴面臨的問題
(1)投訴預警不及時
投訴預防不到位,缺乏事前分析的信息、工具,對客戶投訴的熱點問題、風險問題缺乏有效的監控手段。同時投訴處理環節效率較低,處理效果欠佳,相對應的投訴處理手段有限,未能做到精準的客戶投訴信息定向挖掘。另外,應對客群關系欠缺有效的策略,導致投訴頑疾長期存在,投訴處理沒有形成較好的閉環。
(2)投訴數據不準確
客戶投訴信息中記錄字段多,并且字段信息記錄出現缺失、錯誤。另外,前臺的手工填寫文本字段太多,沒有統一的分類選擇標準,文本信息太過繁雜。而客戶投訴信息的缺失、異常和噪聲數據太多會直接影響數據挖掘結果。
(3)衍生的問題
由此衍生出升級投訴量波動大、升級投訴無法預測、投訴缺少過程管控、重點投訴無法規避以及關鍵環節無法回歸、重點問題重復發生等問題,因此需進一步借助模型數據分析來優化并解決當前問題,以提升客戶滿意度。
3 決策樹模型助力客戶投訴
3.1 預測模型的處理方法
中國移動擁有海量的客戶投訴數據并不斷更新,要獲得服務、產品改進及創新思路,必須借助數據分析和挖掘。利用數據挖掘技術提取可能升級投訴的客戶,以達到事前預警升級的目的,可采用國際通用CRISP-DM(Cross-Industry Standard Process for Data Mining,跨行業數據挖掘標準流程)數據挖掘建模有效地解決這個問題。
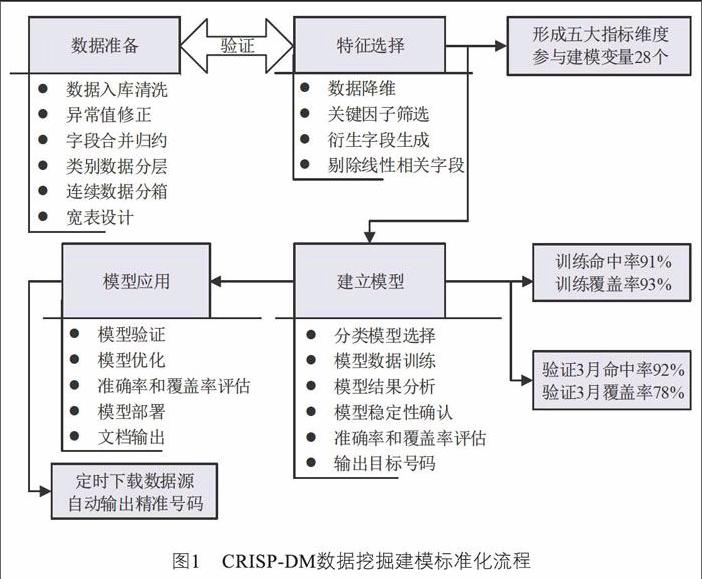
CRISP-DM將模型分為6個階段:商業理解→數據理解→數據準備→建模→評估→部署。CRISP-DM數據挖掘建模標準化流程如圖1所示。
3.2 升級投訴預警模型數據挖掘實踐
(1)數據準備
1)數據清洗體系建設
將升級投訴數據來源進行梳理整合,主要包括如下:
數據來源確認:確認升級工單的7個數據來源,對數據大小和數據質量進行初步驗證。
數據質量管理:將缺失數據、異常數據、噪聲數據進行數據清洗,保證數據符合建模的要求。
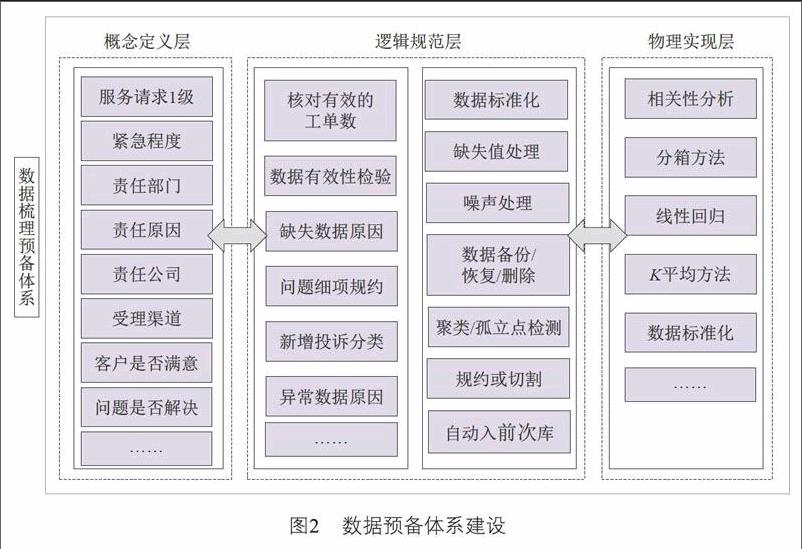
數據預備體系建設:將數據來源、數據清理、數據整合/規約、數據驗證、入庫等各階段任務進行統一系統管理,實現整個前端數據處理流圖的自動化和智能化管理。具體如圖2所示。
2)數據梳理成果
在數據梳理成果中,主要是數據梳理的建模維度和字段,具體包括如下:
寬表設計:很多常用模型在集團規范中都有明確的業務描述和寬表設計,可以直接參考使用。業務人員結合經驗定義寬表結構,并對寬表字段進行適當添加、刪減、調整。技術人員在業務人員指導下對某些重要字段進行衍生,如通話次數衍生出占比、趨勢、波動。
通過預先設定數據處理的可視化功能節點,以達到可視化進行數據清洗和數據轉換的目的。針對縮減并集成后的數據,通過組合預處理子系統提供各種數據處理功能節點,能夠以可視化的方式快速有效地完成數據清洗和數據轉換過程。
數據清洗:對缺失數據進行填充,如終端信息不全由業務部門提供后補充。有些缺失數據也可以通過技術手段(如均值、中位數、眾數等)填充。對業務意義相同的數據進行合并加工,如“NOTE3”與“note3”。諸如流量等指標會出現異常大/小的數值,可采取“封頂保底”或者分層的策略,視情況使用。
數據抽取:從不同的數據來源中,通過ETL(Extract Transform Load,數據倉庫技術)工具或者編程技術生成寬表數據,供后期做數據挖掘。
3)數據梳理總結
在數據梳理過程中,針對遇到的各項問題采取了相應的解決方案,具體如下:
字段分類過多:分類字段的類別維度太小,漸趨于明細數據,如問題細項有940多個分類。字段分類過多容易造成模型過度擬合及泛化性能較差,可以在系統設定時采用選項的方式而不是手工輸入方式。
數值型數據過多:基于特征選擇的結果梳理字段后,參與建模字段中分類型字段有17個,數值型(連續型)數據字段有11個。對數值型數據的建模容易產生過度擬合或無屬性可分的情況,可以采取分箱或手工生成衍生字段來解決此問題。
缺失值數據嚴重:部分重要建模字段的缺失值嚴重,主要是投訴反饋維度的相關字段,數據缺失值會導致模型的結果擬合效果差。基于數據狀況,可以采用忽略該條記錄、手工填補遺漏值、利用缺省值填補遺漏值等處理方法。
噪聲數據:異常值(噪聲數據)會嚴重影響后期的建模效果。對于異常點的數據,可以采用直接刪除異常數據的方法,也可以基于異常點檢驗的方法再刪除。
(2)數據探索
1)整體投訴數據統計分析
數據探索主要是整理歷史客戶的整體投訴數據,然后根據相關整理的字段、因子進行科學統計分析,探索數據特征。對客戶整體和一次升級客戶進行分析,從投訴問題分類、投訴業務、投訴問題的緊急程度等方面進行深入分析。
2)數據探索結果
根據數據探索發現,數據業務影響客戶的升級投訴占比很大,同時費用投訴也是主要因素,總體概況如下:
涉及數據業務和國際/港澳臺業務的投訴升級比率較高,并且這兩部分客戶的價值遠高于普通客戶,因此應重點關注這兩部分業務的投訴客戶,防止因投訴而流失重點客戶。
客戶在一次投訴沒有徹底解決或沒有相應答復時會第一時間進行升級投訴,這需要在發現客戶投訴時第一時間安撫客戶,防止因其情急而升級投訴。
費用和業務退訂涉及到公司內部系統數據對質量管控的支持,后續可以建立與數據支持部門的溝通合作,對費用和業務查詢快速響應,及時解決客戶咨詢的問題。
有過歷史投訴的客戶更容易升級,他們熟悉投訴流程,這需要建立重復投訴客戶名單,防止客戶多次升級投訴,并且當投訴和抱怨積累一定次數時,都會轉化為升級。
針對一次升級客戶,事件的緊急程度和處理結果的滿意度與是否升級投訴沒有直接關聯。
(3)模型算法的選擇
根據前期梳理的數據源,分析數據源中各字段屬性,然后依據分類算法的對比分析,篩選出基于現有數據源最優的模型。
目前基于預測目標分類用戶的算法模型有很多,比較常用的是邏輯回歸、支持向量機、神經網絡和決策樹。具體如下:
1)邏輯回歸是對訓練數據的擬合,得到一個回歸模型,對數據進行預測。
2)支持向量機是二類分類模型,為特征空間上的間隔最大的線性分類。
3)神經網絡是模仿人體神經系統的感知機模型,算法較為復雜。
4)決策樹是一種基本的分類與回歸方法,它可以被認為是一種if-then規則的集合。決策樹是數據挖掘技術中的一種重要的分類方法,它是一種以樹結構(包括二叉樹或多叉樹)形式來表達的預測分析模型。
通過對邏輯回歸模型、支持向量機模型、神經網絡模型、決策樹模型的詳細介紹及模型應用場景的分析,基于現有數據源質量和模型的適用條件,最終選擇決策樹作為實施模型。
(4)建立模型
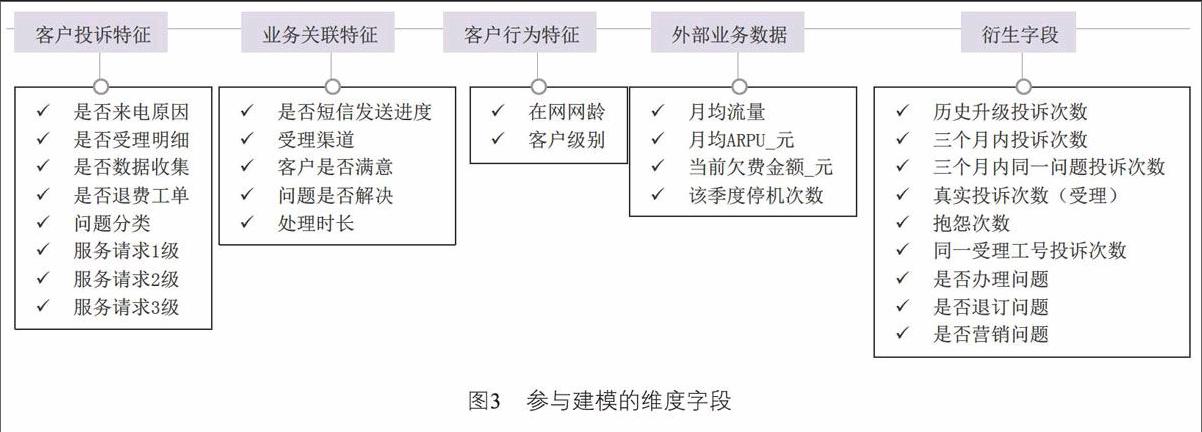
1)確定維度字段
對字段的重要程度進行初步預判,主要通過業務判斷、特征選擇、相關性分析選擇影響模型的字段,將選出的字段參與特征選擇過程,剔除對建模結果影響不顯著的字段,同時將與結果相關性強的字段為母本衍生出新的字段,并直接剔除母字段即利用新生成字段進行建模分析。
基于7個數據來源,形成客戶投訴屬性、投訴反饋、客戶消費行為、客戶屬性四大維度60個模型字段。經特征選擇(主成份分析/降維)后,新增衍生字段維度,調整為五大維度28個字段參與建模。參與建模的維度字段如圖3所示:
2)建模流程
通過決策樹分類算法運算,得出評估模式的值或者預測值,最終將原始數據集進行分類,輸出預測結果。建模流程如圖4所示。
3)模型參數設置
決策樹模型設計的重要參數有Boosting次數、N折交叉驗證、決策樹葉子修剪程度和誤分類的成本,具體如下:
Boosting實驗次數:Boosting采用投票方式判別,不會出現過度擬合問題,當實驗次數設置越大時,花費時間越久。
交叉驗證:設置折疊次數K次,則將數據分為K份,每次運行選擇其中一份作檢驗集,其余的全作為訓練集,該過程重復K次,使得每份數據都用于檢驗一次。
修剪嚴重性:表示決策樹的修剪程度,為防止決策樹過度擬合,需修剪決策樹的枝葉,根據決策樹節點的深度,一般設置為75~80。
誤分類的成本:基于模型效果的評估,當設置矩陣中某一類成本高時,則模型會自動向成本低的方向移動,可以根據模型的目標追求準確率或覆蓋率進行設置。
4)模型優化過程
初期模型中將7個來源表中的投訴數據進行合并,整合各個數據表中的因子、字段,根據整理出的原始數據,采用決策樹模型中的C5.0算法建立模型,通過模型算法的運算得出模型樣本的命中率為22%,能夠有效地達到初期設想。為了提高模型預測的準確性,分別采用衍生字段、參數調優、分箱處理等方法對模型進行優化,具體如下:
衍生字段:針對原數據,區分7個來源表的投訴數據,衍生投訴來源字段,如是否來電原因。衍生服務請求級別字段,對其細化分類。
參數調優:根據字段細分結果,進一步優化衍生投訴類行為數據,如計算當前受理號碼歷史升級投訴次數等,對模型剪枝(75~80),增加模型預測錯誤成本。
分箱處理:對數值型變量進行分箱處理。
最后通過增加客戶消費行為數據,對數值型數據分箱處理,采用C5.0算法建立模型,模型命中率提高為78%。
5)模型效果評估
判斷一個模型是否可接受,需要考察該模型對數據集的分類效果,其中重要的檢測指標是準確率、命中率和覆蓋率。C5.0模型的結果可以通過分析節點,以輸出矩陣的方式展現,模型結果還可以輸出字段重要性的排名。根據模型訓練結果,總體上能夠有效地預測產生升級投訴的客戶及原因,強有力地控制兩條紅線處于合理的區間。
6)模型部署
將構建好的模型導出為SQL(Structured Query Language,結構化查詢語言)或PMML(Predictive Model Markup Language,預言模型標記語言);將SQL或PMML嵌入腳本,定時執行腳本生成名單后派送。
4 結束語
本文基于大數據工具,利用客戶投訴數據建立模型,構建了智能化的投訴信息挖掘平臺。通過模型可以加強升級投訴預防工作,在降低客戶投訴升級的同時提高客戶滿意度,并控制了兩條紅線,使得兩條紅線指標呈現良性化趨勢。系統智能化集成簡化了成熟的投訴處理流程,使得客戶投訴問題的解決更加快捷和準確,節約了大量的人力資源,從而有效地降低了投訴處理成本。并且通過建模可以從投訴信息中挖掘隱含的客戶需求和商機,進而獲得服務及產品改進和創新思路的方法。
參考文獻
[1] 薛薇,陳歡歌. 基于Clementine的數據挖掘[M]. 北京: 中國人民大學出版社, 2012.
[2] 周志華. 機器學習[M]. 北京: 清華大學出版社, 2016.
[3] 陸富琪. 電信增值業務及其發展模式分析[J]. 信息網絡, 2004(3): 21-24.
[4] 盛朕業,才鳳艷. 顧客忠誠的內涵及價值衡量[J]. 商業時代, 2006(25): 35-36.
[5] 郭麗麗,丁世飛. 深度學習研究進展[J]. 計算機科學, 2015(5): 28-33.
[6] 左超,耿慶鵬,劉旭峰. 基于大數據的電信業務發展策略研究[J]. 郵電設計技術, 2013(10): 1-4.
[7] 羅芳,李志亮. 基于分類的機器學習方法中的決策樹算法[J]. 寧德師專學報: 自然科學版, 2009(1): 40-42.
[8] 季桂樹,陳沛玲,宋航. 決策樹分類算法研究綜述[J]. 科技廣場, 2007(1): 9-12.
[9] 丁俊民,廖振松. 基于大數據建模的投訴預測與應用[J]. 信息通信, 2015(9): 291-292.
[10] 董智純,楊林,詹念武,等. 一種基于大數據技術的投訴分析與預測系統[J]. 信息通信, 2015(9): 285-286.
[11] 周文杰,楊璐,嚴建峰. 大數據驅動的投訴預測模型[J]. 計算機科學, 2016(7): 217-223.
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
