針對輿情數據的去重算法①
2017-06-07 08:24:04張慶梅
計算機系統應用 2017年5期
關鍵詞:特征提取
張慶梅
(中國科學技術大學 軟件學院,蘇州 215123)
針對輿情數據的去重算法①
張慶梅
(中國科學技術大學 軟件學院,蘇州 215123)
針對在數據服務中輿情去重不可避免且缺乏理論指導的問題,通過研究SimHash、MinHash、Jaccard、Cosine Similarty經典去重算法,以及常見的分詞和特征選擇算法,以尋求表現優異的算法搭配,并對傳統Jaccard和SimHash進行了改進分別產生新算法:基于短文章的Jaccard和基于Cosine Distance的SimHash.針對比較對象眾多實驗效率低下的問題,提出了先縱向比較篩選出優勢算法,然后橫向比較獲得最佳搭配,最后綜合比較的策略,并結合3000輿情樣本實驗證明:改進的SimHash比傳統的SimHash具有更高的精度和召回率;改進的Jaccard較傳統Jaccard,召回率提高了17%,效率提高了50%;MinHash+結巴全模式分詞和Jaccard+IKAnalyzer智能分詞在保持精度高于96%的條件下,都具有75%以上的高召回率,且穩定性很好.其中MinHash去重效果略低于Jaccard,但特征比較時間較短,綜合表現最好.
輿情數據;去重算法;相似度計算;大數據服務
據中國互聯網絡信息中心統計,截止到2015年12月,我國社交網站、微博等社交應用的網民使用率達77.0%[1],新媒體逐漸成為網民表達意見和看法、行使公民權利的重要渠道和方式[2],是用戶獲取和分享“新聞熱點”、“興趣內容”、“專業知識”、“輿論導向”的重要平臺[3].從社會學角度來看,這些輿情信息反映了民眾的社會政治態度,有著強大的監督力度[4].而輿情信息的價值遠遠不止其傳播性所帶來的社會監督力度,在金融領域也廣泛被使用.由于輿情信息可以準確反映個人和企業的信用狀況,目前已有大數據服務公司采集輿情數據,然后加工分析為金融機構在信用評定、風險評估方面提高參考.然而隨著大數據時代的到來,抓取的輿情數據重復性冗余急劇增大[5],這些重復的數據嚴重影響后期的加工處理和客戶體驗.據調研,目前的去重技術大多針對網頁,專門針對輿情數據的卻很少.因此對于輿情數據服務,迫切需要針對輿情開展去重研究來解決數據重復帶來的一系列問題.本文通過對幾種經典去重算法在輿情數據方面的表現進行研究,并分析不同實現方式的去重算法之間的精度、召回率和效率的差異,尋求在輿情去重上表現優異的算法,為輿情數據服務在機器去重方面提供參考.
1 相關技術和實現方法
本文將整個去重分為三個步驟:首先是分詞,將一篇文章轉化為詞語列表;然后是對文章進行特征選擇,實現文章特征屬性的提取;最后是基于相似度計算的去重算法進行去重.因此關鍵技術包括分詞、特征選擇、相似度計算.每種技術中本文都有多種候選算法,相關技術的研究對象如表1所示.

表1 相關技術的研究對象
1.1 分詞
本文的分詞具體指中文分詞,目的是將漢字序列切分成由詞語組成的序列[6].分詞算法的不同將直接影響去重效果.本文嘗試通過比較不同分詞算法對輿情去重效果的影響,來獲得最適合輿情去重的分詞方法.本文選用中文分詞中比較常用的3種分詞方法:結巴分詞、IKAnalyzer分詞和HanLP分詞,其中結巴分詞包含3種模式:精確模式、全模式和搜索引擎模式.IKAnalyzer包含2種分詞模式:細粒度模式和智能模式.HanLP包含8個分詞器:標準分詞、NLP分詞、索引分詞、N最短路徑分詞、最短路徑分詞、CRF分詞、極速詞典分詞和繁體分詞.由于本文的輿情樣本全部是簡體中文,因此本文只將前7種分詞納入此后的研究中去.
1.2 特征選擇
選用較小維度的特征代表整個文本正文的過程就是特征選擇.在本文中將幾種常見的特征選擇納入研究范圍,分別是:詞頻、TF-IDF和TextRank.這三種特征選擇都是權重特征,適合與Cosine Similarity和SimHash算法結合使用.
1.2.1 詞頻
詞頻是指詞語出現的次數,詞頻統計通常不單獨被使用,一般是結合其他算法一起使用,應用范圍涉及中文分詞、研究熱點分析、文本分析等諸多方面[7-9].常用詞頻的計算方式是獲取某個詞在文章中出現的次數,但這種計算方式忽略了文章有長短之分.當文章篇幅差距很大,將不能準確體現文章內容之間的差異性.因此在本文采用的是相對詞頻,它對的計算公式如式(1)所示.

1.2.2 TF-IDF
TF-IDF和詞頻同樣都是常用的加權技術,但相比于詞頻,TF-IDF能夠反映整個詞在一個文本集合或者語料庫中的“重要程度”,詞頻僅僅在一定程度上反映一個詞在一篇文章的重要程度,沒有將整個文本庫的大小考慮進去.TF-IDF廣泛應用于自動關鍵詞提取、文本摘要提取等[10,11].TF-IDF的主要思想是詞語的重要性隨著這個詞在文本出現的次數成正比,同時隨著它在整個文本集合中出現的頻率成反比,某個詞在文章中的重要程度越大,TF-IDF的值就越大.了解TF-IDF首先了解逆文檔頻率,詞頻和逆文檔頻率的乘積就是TF-IDF,逆文檔頻率(IDF)的計算公式如式(2)所示.

1.2.3 TextRank
TextRank是受啟發于PageRank,PageRank最開始是用于網頁相關性和重要性的評估,獲取網頁排序,提高用戶對搜索引擎檢索結果的滿意度,此算法由Google的創始人謝爾蓋?布林和拉里?佩奇在1998年提出[12].PageRank的計算公式如式(3)所示.

S(Vi)表示網頁i的重要性,d是阻尼系數,通常設為0.85.In(Vi)是指向網頁i的鏈接集合,Out(Vi)表示網頁i指向的網頁集合,|Out(Vi)|表示網頁i指向的網頁集合的元素個數.整個計算需要經過多次迭代,初始設置網頁重要性為1.
TextRank計算對象從網頁轉化為文本中的詞語或者句子,每個詞語或句子根據此算法會得到相應的權重.具體計算公式如式(4)所示.

本文利用此特征選擇主要是獲取不同詞語的權重值,即把每個詞語看成一個節點(Vi).當計算對象是詞語時,因為 wjk取值都為 1,TextRank就蛻變成PageRank.不過式4中的變量含義有所變化,S(Vi)表示文本中詞語i的重要性,In(Vi)是文章中指向詞語i的詞語集合,|Out(Vi)|表示文章中詞語i指向的詞語集合的元素個數.詞語之間的相鄰關系,依賴于窗口大小的設置,一個窗口中的任意兩個詞語之間都是相鄰的,并且邊都是無向無權的.由于TextRank需要經過多次迭代,因此特征獲取的時間復雜度很高.
1.3 相似度計算
相似度計算是指是在特征選擇的基礎上通過去重算法來求取文章之間相似度的過程,是自然語言處理和數據挖掘中常用的操作.本文參考網頁去重的經典算法,將 Jaccard、Cosine Similarity、SimHash和MinHash納入研究范圍,對于傳統實現方式, MinHash有兩種:基于單Hash函數的MinHash算法和基于多Hash函數的MinHash算法,其余的各有一種.本文除了實現傳統的算法之外,還對傳統Jaccard和SimHash進行改進分別產生新的算法:基于短文章的Jaccard和基于Cosine Distance的SimHash.
2 基于相似度計算的去重算法
對于不同的應用場景,考慮到數據規模、時間開銷,去重算法的選擇會有所不同.本文在此分析不同算法的去重原理以及時間開銷,從理論上分析不同算法的優缺點,并給出具體的實現步驟.為不同需求的應用場景在去重算法的選擇上提供參考.
2.1 Jaccard算法
Jaccard系數,又稱Jaccard相似度系數,用來評估兩個集合之間的相似度和分散度[13],Jaccard系數越大表明兩篇文章的相似度越大.利用Jaccard去重,首先將文章通過分詞轉化為由詞語構成的特征集合,通過檢查兩個集合的Jaccard系數是否超過指定的閾值來判斷文章是否重復.
1)傳統的Jaccard
傳統的Jaccard,基于Merge算法,通過求取兩個文章的特征集合交集和并集的長度比例來衡量文章之間的距離.計算公式如式(5)所示.

從實現的原理上看,傳統的Jaccard算法,并沒有將兩篇文章的長度差異考慮進去,假設兩篇文章重復的文章長度差異很大,例如一個包含1500個單詞,一個包含500個單詞,兩篇文章的單詞交集長度是500,利用傳統的Jaccard計算兩篇文章距離,結果是:0.25,傳統 Jaccard的閾值一般在0.5以上,在這種情況下,就很容易漏判長度差異大的重復文章.此外Merge算法的時間復雜度是O(m+n)(m和n是兩個集合的長度),不是很高,但當文章篇幅很長,數據規模很大時,這個時間開銷將會非常龐大.因此Jaccard算法不適應文章篇幅普遍較長、數據規模較大的業務場景.
2)基于短文章的Jaccard
針對傳統Jaccard對屬于包含關系重復的文章識別能力低的問題,本文提出一種基于短文章的Jaccard,通過求取兩個特征集合交集占短文章集合長度的比例來衡量兩文章的距離.以下簡稱改進的Jaccard,計算公式如式(6)所示.

在這種改進下,屬于包含關系的重復文章,即使文章長度差異很大,求取的文章Jaccard系數也會隨文章相似程度的增大而增大.對于傳統Jaccard中的例子,使用改進的Jaccard計算,兩篇文章的距離就是1,即完全重復,符合實際情況.改進的Jaccard的時間復雜度和傳統Jaccard相同,但是相比傳統的Jaccard少了求并集的過程,因此時間消耗要少.
2.2 Cosine Similarity算法
Cosine Similarity又稱Cosine Distance,與幾何中的向量余弦夾角很相似.當把一篇文章的特征抽象成一個向量時,可以使用這種方式計算文章之間的相似度,計算公式如式(7)所示.

具體實現步驟如下:

對于Step 3向量坐標的轉化,需要遍歷集合unionS中的元素,并依次判斷每個元素在待轉化向量中的存在情況,因此整個相似度計算的時間復雜度平均為O(n*m)(n為并集的長度,m為待轉化向量的長度),相比于Jaccard,時間開銷更大.
2.3 SimHash算法
SimHash是由Charikar在2002年提出的去重算法,主要用于海量文本的去重工作[14].SimHash對文章進行相似度計算,需要兩步,首先特征提取形成指紋,然后根據指紋進行特征比較,計算相似度.
1)傳統的SimHash
傳統的SimHash首先將一篇文章轉化為由k位0/1構成的指紋(k通常取32或64),然后利用Hamming Distance(海明距離)來對兩篇文章的指紋進行相似計算.海明距離是指兩串二進制編碼對應比特位取值不同的比特數目,海明距離越大則相似度越小.由于SimHash能將一篇文章轉化為k位的字符,相比于Jaccard和Cosine Similarity,能大大降低特征比較的維度.雖然多了特征提取的步驟,但對于大數據服務,一篇文章只需在入庫時進行一次特征提取,然后將形成的指紋保存下來,而特征比較會在每次去重時都要基于指紋進行多次.因此對于大規模的數據去重, SimHash具有絕對優勢的去重效率.傳統的SimHash的具體實現步驟如下:


(2)基于Cosine Distance的SimHash
在對Cosine Distance和傳統SimHash研究的基礎上,本文提出基于Cosine Distance的SimHash,以下簡稱SimHashCosine.該SimHash特征提取只保留傳統SimHash實現步驟的Step1.1-1.4,然后利用Cosine Distance來計算指紋之間的相似度,最后通過判斷是否超過給定的閾值來判定是否重復.兩種SimHash的時間開銷差異主要體現在是特征比較上,若n為指紋碼的長度,m為閾值(n>m),傳統的SimHash相似度計算利用Hamming Distance,時間復雜度最壞情況是O(n),最小只有O(m),而SimHashCosine,相似度計算利用Cosine Distance,時間復雜度至少O(n),且時間頻度至少是傳統SimHash的3倍,因此在特征比較效率上傳統的SimHash更高一點.
2.4 MinHash算法
MinHash和SimHash一樣,能對文章進行很好的降維,適用于大規模的網頁去重工作[15].MinHash經過特征提取,將一篇文章最終轉化為n個最小Hash函數值構成的特征集合,然后基于Hash函數值集合獲取Jaccard距離來衡量相似度.
1)基于單Hash函數的MinHash
基于單 Hash函數的 MinHash,以下簡稱MinOneHash,在進行特征提取僅使用了一個Hash函數,然后使用傳統的基于Merge算法的Jaccard計算相似度,具體的實現步驟如下:

2)基于多Hash函數的MinHash
基于多 Hash函數的 MinHash,以下簡稱MinMutilHash,使用n個Hash函數進行特征提取(n>1),特征提取的步驟:對于事先確定的n個Hash函數,對于每個Hash函數,按照約定的順序都對文章的詞語集合s中的所有詞語進行Hash操作,形成各自的Hash函數值集合,然后各自從各自的Hash函數值集合中篩選出最小Hash值,n個Hash函數最終獲得n個最小值.由于特征提取計算維度的擴大,相對于MinOneHash,時間復雜度較高.但MinMutilHash相似度計算法是根據Broder提出的最小獨立置換概念,通過求得兩個Hash函數值集合中對應位置Hash值相同的元素數目來評估相似度,特征比較的時間復雜度是 O(n),相比于MinMutilHash的O(m+n),特征比較效率要高.
3 實驗測試及分析
3.1 測試方案設計
由于涉及算法眾多,以排列組合的形式進行組合測試需要耗費大量時間.因此本文針對表1所列算法,先縱向比較剔除明顯劣勢的算法,然后橫向比較獲得各個去重算法最適宜的分詞算法和特征選擇,最后對去重表現良好的候選算法,進行進一步優化后再綜合測試比較的策略.
本文以精度、召回率、計算時間來衡量算法的去重效果.精度是衡量算法準確性的指標,公式如式(8)所示.召回率是衡量算法查全程度的指標.公式如式(9)所示

考慮到大數據服務對數據準確性的要求,去重效果的衡量標準以精度優先,精度越高表示去重效果越好;其次是召回率,召回率越高去重效果越好;在精度相差不大時,優先選擇召回率高的算法,相差不大的標準是正負差值不超過1%;計算時間最后考慮.計算時間中包括兩部分:特征提取時間,特征比較時間.在大數據服務的輿情去重中,對一篇文章特征提取只需要進行一次,特征比較則會進行很多次,因此對于不同的去重算法,算法特征比較時間要優于特征提取時間考慮.測試樣本統一使用包含3000真實輿情文章的數據集.
3.2 縱向比較
3.2.1 分詞算法的比較
為了保證實驗結果不受特征選擇的影響,在本實驗中對詞語都不進行特征選擇,為了保證實驗結果不受去重算法的影響,在本實驗中去重算法統一使用傳統的SimHash.測試結果如表2所示.

表2 基于結巴分詞不同模式的去重測試結果
由表2可得,精度:IKAnalyzer智能>HanLP CRF>結巴全模式分詞>90.5%,召回率:IKAnalyzer智能>HanLP CRF>結巴全模式分詞>55.5%,因此保留IKAnalyzer智能、HanLP CRF和結巴全模式.
3.2.2 特征選擇算法的比較
本文繼續使用SimHash算法,分詞算法選用IKAnalyzer智能分詞,以無加權為參照,觀察不同特征選擇下去重效果的差.實驗結果如表3所示.
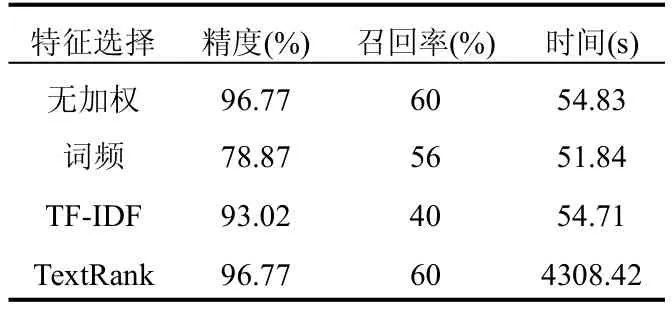
表3 基于不同特征選擇的去重測試結果
由表3可得,無加權和TextRank去重表現最好,但是根據實驗發現TextRank特征提取時間很長導致總計算時間太長,且更換其他分詞算法時,結合TextRank的去重效果都有所降低,因此輿情去重在此只保留無加權.
3.2.3 去重算法比較
去重算法的比較研究部分主要任務是從Jaccard、SimHash、MinHash中各篩選出一種,然后和Cosine Similarity進行比較.測試結果如表4所示.

表4 不同去重算法的測試結果
由表4可知:
① 在精度和召回率上,SimHashCosine同時高于SimHashHamming,保留SimHashCosine.
②MinMultiHash精度略低于MinOneHash,但兩者相差不大,且在召回率和特征比較時間上, MinMultiHash相比于MinOneHash具有絕對優勢,因此保留MinMultiHash.
③Cosine Similarity時間花費太大,確定舍去.
④ 傳統的Jaccard精度明顯高于改進的Jaccard,但改進的Jaccard召回率和特征效率明顯高于傳統的Jaccard,各具明顯優勢,實際使用時可以根據場景需求進行選擇,在面向金融行業的大數據服務中,以精度優先保留傳統的Jaccard.
3.3 橫向比較
在算法橫向比較部分,分詞算法保留IKAnalyzer智能、HanLP CRF和結巴全模式,排除使用特征選擇,因此在橫向比較部分主要研究保留的分詞算法對去重算法的影響.便于表示在此將IKAnalyzer智能、HanLP CRF、結巴全模式分詞分別簡稱為智能、CRF、全模式.橫向比較結果如表5所示.

表5 橫向比較結果
由表5可知:
① 精度優先原則,SimHashCosine與IKAnalyzer智能結合效果最高.
②MinMultiHash與三種分詞方法結合時,全模式和CRF精度最高且相差很小,考慮全模式的召回率明顯高于CRF,確定MinMultiHash和全模式結合.
③Jaccard與三種分詞方法結合時,召回率和精度都相差不大,但特征比較時間,全模式:1018.42s,智能:638.54s,CRF:861.57s,其中IKAnalyzer智能模式最短,因此選擇智能模式和Jaccard結合.
3.3 綜合比較
算法橫向比較后篩選出這3種算法: MinMultiHash+結巴全模式、Jaccard+IKAnalyzer智能、SimHashCosine+IKAnalyzer智能.閾值的不同,會導致去重結果有很大差異,此處研究這3種算法去重效果隨著閾值的變化情況.此外本文認為一個好的去重算法,應當在保持較高精度時召回率也很高,算法的特征比較時間短,算法的穩定性較好.這個穩定性主要體現在在整個閾值取值范圍內,精度和召回率隨閾值的整體變化是否比較平穩.本文以折線圖的形式展示每種算法隨著閾值的改變,精度和召回率的變化趨勢.精度隨閾值的變化折線圖如圖1所示,召回率隨閾值變化折線圖如圖2所示.如果一個算法的某個閾值精度少于80%或召回率低于40%,相應閾值下的精度和召回率都不再被顯示.

圖1 精度隨閾值的變化折線圖

圖2 召回率隨閾值的變化折線圖
由圖1和2很明顯可以看出:
①Jaccard和MinMultiHash在很大的閾值變化范圍內,都能同時保證較高的精度和較高的召回率.
②Jaccard始終以微弱的優勢,在精度和召回率上高于MinMultiHash.
③ 算法的穩定性排序:Jaccard>MinMultiHash> SimHashCosine.
④ 結合表4觀察,MinMultiHash特征比較時間遠小于Jaccard.
因此在輿情去重場景中,對算法精度和召回率非常高,推薦Jaccard;追求較高的精度和召回率,同時對時間的要求也很高的情況,推薦MinMultiHash.
4 結語
輿情是大數據服務中一種重要的數據產品,但隨著大數據時代的來臨,輿情服務必須解決重復嚴重的問題才能提供更高質量的數據.本文通過對分詞算法、特征選擇和去重算法進行實驗研究,并對傳統的Jaccard和SimHash進行了改進.提出了先縱向比較,后橫向比較,最后綜合比較的實驗策略,通過此實驗策略篩選出了輿情去重表現突出的算法搭配.隨著輿情研究的深入,在今后可將Hadoop算法納入研究范圍,以提高算法的去重效率.
1中國互聯網信息中心.2016年第37次中國互聯網絡發展狀況 統 計 報 告 .http://www.cnnic.net.cn/gywm/xwzx/rdxw/ 2016/201601/t20160122_53293.htm.[2016].
2魏超.新媒體技術發展對網絡輿情信息工作的影響研究.圖書情報工作,2014,58(1):30–34.
3胡洋,劉秀榮,魏娜,張么九,劉婉行,鈕文異.北京健康教育微博體系初建參與者網絡及微博使用習慣的現狀分析.中國健康教育,2014,30(8):706–708.
4吳紹忠,李淑華.互聯網絡輿情預警機制研究.中國人民公安大學學報,2008,14(3):38–42.
5賀知義.基于關鍵詞的搜索引擎網頁去重算法研究[碩士學位論文].武漢:華中師范大學,2015.
6龍樹全,趙正文,唐華.中文分詞算法概述.電腦知識與技術, 2009,5(10):2605–2607.
7劉洪波.詞頻統計的發展.情報科學,1991,12(6):69–73.
8朱小娟,陳特放.基于SVM的詞頻統計中文分詞研究.微計算機信息,2007,23(30):205–207.
9華秀麗,朱巧明,李培峰.語義分析與詞頻統計相結合的中文文本相似度量方法研究.計算機應用研究,2012,29(3):833–836.
10王景中,邱銅相.改進的TF-IDF關鍵詞提取方法.計算機科學與應用,2013,35(10):2901–2904.
11 Cho J,Shivakumar N,Garcia-Molina H.Finding Replicated WebCollections.AcmSigmodRecord,2000,29(2):355–366.
12黃德才,戚華春.PageRank算法研究.計算工程,2003,32(4): 145–146.
13 Real R,Vargas JM.The Probabilistic Basis of Jaccard's Index of Similarity.Systematic Biology,1996,45(3):380–385.
14 Sood S,Loguinov D.Probabilistic Near-Duplicate Detection Using SimHash.Acm Conference on Information,New York,2011:1117–1126.
15 Rao BC,Zhu E.Searching Web Data using MinHash LSH. International Conference on Management of Data,New York,2016:2257–2258.
Duplicate RemovalAlgorithm for Public Opinion
ZHANG Qing-Mei
(School of Software Engineering,University of Science and Technology of China,Suzhou 215123,China)
In big data services,duplicate removal of public opinion information is inevitable,and it lacks theoretical guidance.There is a research on the classical duplicate removal algorithm such as SimHash,MinHash,Jaccard,Cosine Similarty,as well as common segmentation algorithm and feature selection algorithm in order to seek excellent performance of the algorithm.The Jaccard based on short article and the SimHash algorithm based on Cosine Distance are proposed to improve the traditional algorithms.Aiming at the problem of the low efficiency of experiment on many research subjects,the strategy is adopted that filters out algorithm of obvious advantages by vertical comparison firstly, and gets the most appropriate algorithm collocation by horizontal comparison secondly,at last,makes a comprehensive comparison.The experiment of 3000 public opinion samples shows that improved SimHash has better effect than traditional SimHash;improved Jaccard increases the recall rate by 17%and improves the efficiency by 50%compared with traditional Jaccard.Under the condition that the accuracy is higher than 96%,MinHash+Jieba full pattern word segmentation and Jaccard+IKAnalyzer intelligent word segmentation has more than 75%recall rate and good stability. MinHash is a bit weak than Jaccard in the aspect of removal effect,yet has the best comprehensive performance and shorter feature comparison time.
public opinion data;duplicate removal algorithm;similarity computation;big data service
2016-08-28;收到修改稿時間:2016-09-27
10.15888/j.cnki.csa.005745
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
