一種加速搜索函數極值的剪枝方法
2017-05-24 14:48:18盧偉榮張磊
現代計算機 2017年11期
關鍵詞:模型
盧偉榮,張磊
(中山大學數學學院,廣州 510275)
一種加速搜索函數極值的剪枝方法
盧偉榮,張磊
(中山大學數學學院,廣州 510275)
函數的極值求解問題是實際應用中有許多優(yōu)化問題的最基本的問題,大多數模型的優(yōu)化問題最終都轉化為目標函數的極值問題,如最大似然估計和最小二乘估計。在極值問題的數值解法中,遍歷搜索可用于函數的高精度極值求解問題,但其時間復雜度非常高;為解決遍歷搜索時間過長的問題,隨機搜索方法被引入,如遺傳算法和模擬褪火算法,而遺傳算法極不穩(wěn)定不適合大數據下智能問題的復雜目標函數的極值搜索。結合遍歷搜索和隨機搜索,設計一種基于二進制編碼的搜索樹,并引入基于模擬退火思想的隨機剪枝算法,在保證模型精度的基礎上對搜索樹進行剪枝。在實驗環(huán)節(jié)使用多種形態(tài)的函數進行效用分析,說明其在精度和穩(wěn)定性及時間效用方面的優(yōu)勢。
極值求解;遍歷搜索;模擬退火;數值解法
0 引言
在科學技術的各個領域,通常會對所處理的實際問題進行抽象、簡化,進而建立數學模型。其中,函數的極值求解對應了一類常見的實際問題,針對處理在一定條件下,如何實現收益最大,或者成本最低等問題。另外,函數的極值求解問題是實際應用中有許多優(yōu)化問題的最基本的問題,大多數模型的優(yōu)化問題最終都轉化為目標函數的極值問題,如最大似然估計和最小二乘估計。
根據求解方法的不同,函數極值求解可分為以下兩類,精確解法和數值解法。極值模型的精確解一般通過基于導數方法得到滿足條件的約束方程,但在實際應用中,往往需要面對目標函數f不可微,或者其基于導數的約束方程難以求解到的問題。相對而言,大部分數值解法,如黃金分割搜索、二次插值法、各種搜索算法及各種迭代法等,僅依賴于目標函數在某些點上的取值,在實際應用中,適用范圍更加廣泛[1-2]。
遍歷搜索,是一種基本且易于理解的數值解法,可用于高精度的函數極值求解。通過對變量區(qū)間進行不斷地迭代細分,遍歷各區(qū)間尋找函數最值的近似。該方法有以下兩個優(yōu)點,適用范圍廣(僅需知道函數值,無可微或連續(xù)要求)和全局性強(不易限于局部最優(yōu)),但運行時間過長的問題限制了該方法在實際中的應用。
針對上述情況,本文設計了一種獨特的搜索流程,即一種基于二進制編碼樹的搜索方法,可設計出深度搜索和廣度搜索流程,還可以靈活地進行剪枝以加速尋優(yōu)進程。本文將基于模擬退火的思想,對搜索樹進行剪枝,在保證模型精度的基礎上,實現算法時間的優(yōu)化。最后,將介紹該模型在多元函數上的推廣。
1 方法設計和相關理論
1.1 數軸的區(qū)間劃分與數的二進制表示
假設已通過變換x=(b-a)*x'+a將函數的定義域從[a,b]映射到[0,1],其中a〈b且a,b∈R,不失一般性將函數記為:

令a0=0,b0=1,對?r∈[0,1],下面將不斷二等分r所在的區(qū)間:二等分區(qū)間[a0,b0],則必有一子區(qū)間包含實數r,記該區(qū)間為[a1,b1];二等分區(qū)間[a1,b1],則必有一子區(qū)間包含實數r,記該區(qū)間為[a1,b1],…,如圖1所示,繼續(xù)下去,可得到一個區(qū)間長度不斷減半的閉區(qū)間序列{[an,bn]}。

圖1 區(qū)間套{[an,bn]}的構建
因為:

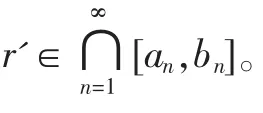
下面追蹤區(qū)間套的構建過程產生一串與實數r相關的二進制數x[1]…x[k]:第i次二等分區(qū)間時,若實數r落入左子區(qū)間,則取x[i]=0;若實數r落入右子區(qū)間,則取x[i]=1,i=1~k。
可見對?x∈[0,1],都可按上述方法產生一串二進制數x[1]…x[k],其中k為細分步數。定義實數x的逼近公式為:

可證明,通過上述方法可產生逼近函數定義域內的任意實數的二進制表示0.x[1]x[2]x[k]2,其中k為細分步數,且其誤差不大于w[k]=。這里之所以通過追蹤區(qū)間套的構建過程產生一串與實數r相關的二進制數x[1]…x[k],是為了下一節(jié)能夠直觀分析搜索樹的構造。
1.2 搜索樹的設計
搜索算法搜索最優(yōu)解的本質是由初始并非極值點的數產生一個點列,使該點列能夠逼近極值點,如下山法將沿函數的負梯度方向產生點列,順序搜索算法則通過按一定的步長來產生點列,隨機搜索算法則通過隨機方式來產生點列,不同的搜索算法決定了如何由一個初始點產生下一個點。本文的搜索算法的搜索流程將采用基于解空間樹的回溯法,使用回溯法的核心問題是如何將問題的解表示成解空間樹,以及如何通過剪枝來提高效率。
下面給出解空間樹的構造方法:前一節(jié)給出了通過追蹤區(qū)間套的構建過程產生一串與實數r相關的二進制數x[1]…x[k],第i次二等分區(qū)間時,若實數r落入左子區(qū)間,則取x[i]=0;若實數r落入右子區(qū)間,則取x [i]=1;若我們用左子樹追蹤左半區(qū)間的細分過程,用右子樹追蹤右半區(qū)間的細分過程,則追蹤區(qū)間套的構建過程產生一棵二叉樹,每個點唯一落入一個節(jié)點中,而且搜索路徑的分枝值將得到由(2)式確定的一個與結點對應的值值,所有這些值構成了侯選的最值,當K足夠大時這些侯選值可以逼近定義域中的任意點,因此這種二叉樹可以做為解空間樹。
由公式(2)的定義可知,x[i],i=1,2,…,k可能的取值為0或者1,因此解空間樹是圖2所示的滿二叉樹,在特定精度下可以對每個可能的取值進行試探。如圖2所示,對于第i層的結點,x[i]的取值為0時搜索其左子樹,相當于搜索左半區(qū)間;x[i]的取值為1時則搜索其右子樹,相當于搜索左半區(qū)間;可見隨著樹的逐層展開將對定義域進行了更精細的劃分[4]。
圖2給出了解空間的搜索樹結構:其中標注了任何一個節(jié)點所對應區(qū)間的左端點值的二進制表示,當我們用區(qū)間端點值近似表示區(qū)間中的任意值時其誤差為,i=1~k為節(jié)點所在的深度,當我們搜索的深度足夠大時,該誤差可以控制到任意小;因此當我們用這些值做為搜索最值的侯選點時,不失一般性可以保證結果的有效性。由此可得我們可以通過所要求的精度來控制樹的深度:關于k的取值問題,在給定模型截斷誤差ε的基礎上,k通過以下方式定義:


圖2 解空間的搜索樹結構
1.3 引入模擬退火思想的剪枝算法
回溯法在問題的解空間樹中,按深度優(yōu)先策略,從根結點出發(fā)搜索解空間樹。算法搜索至解空間樹的任意一點時,先判斷該結點是否包含問題的解。如果肯定不包含,則跳過對該結點為根的子樹的搜索,逐層向其祖先結點回溯;否則,進入該子樹,繼續(xù)按深度優(yōu)先策略搜索,其用于求最小值遞歸實現的偽代碼如下:

上述代碼中if(constraint(t)&&bound(t))backtrack(t+1)表示在遞歸搜索各棵子樹之前要有解的可行性測試和界限測試,它們構成了剪枝條件,針對不同的應用設計剪枝條件是用好回溯法的極大挑戰(zhàn)。在本文探討的搜索函數極大(小)值的應用中,可行性測試比較容易表達,因為一個特定的值是否被選擇是個簡單測試問題;界限測試則非常核心和難以刻畫,因為界限測試要回答當前子樹是否存在潛在最優(yōu)解的問題,相當于要回答最優(yōu)解是否會落入某個區(qū)間之中,這肯定是沒有一般表達的。本文引入模擬退火算法來設計一種依概率剪枝條件。
模擬退火算法(Simulated Annealing,SA)是一種模擬物理學中固體退火過程的隨機優(yōu)化算法,于1983年由Kirkpatrick S,Jr G C,Vecchi M P等人[5]設計提出并應用于組合優(yōu)化領域。該算法在搜索最優(yōu)解的過程中引入隨機因素,以一定概率接受一個不優(yōu)于當前解的解,通過這種隨時間而變化并且最終趨于零的概率突變性,能一定程度地避免陷入局部最優(yōu),具有漸進收斂性[6]。
在模擬退火算法中,判斷是否接受新解的依據是Metropolis準則。不失一般性,假設我們要求最小值,假定問題的當前解為S0,新解為S1,C(S)為目標函數。若C(S1)〈C(S0),則接受S1作為新的當前解;若C(S1)≥C(S0),則以概率p接受S1作為新的當前解。概率p的定義如下:

其中,T代表當前溫度,每個溫度在進行若干次判斷迭代后會逐漸減少,并最終趨于零。
在本文的函數求解模型中,將基于模擬退火算法的思想,對上小節(jié)的遍歷搜索進行改進。引入模擬退火算法思想的剪枝,是指搜索當前區(qū)間對應的子樹時,新產生的分點作為新解與當前解進行Metropolis準則測試,拒絕了新解則被拒絕的分點所在子區(qū)間對應的子樹不用搜索,即對子樹進行了剪枝,從而節(jié)省了用于搜索一個子區(qū)間的時間,這也是為何剪枝條件設計是提高搜索效率的原因。由于模擬退火算法具有隨機性,為保證模型結果的穩(wěn)定性,我們將從第k0+1層開始,對滿二叉樹進行剪枝,經過大量實驗得到k0=×k可滿足大多數應用。k由公式(3)確定,這樣保證了我們所拒絕搜索的子區(qū)間是可以控制它們的長度的。
關于k0的確定問題的探討:當k0=1時算法退化為模擬退火算法,過于強調隨機機制從而造成求解的不穩(wěn)定性;當k0=k時算法退化為窮舉搜索算法,從而增加了時間復雜度。k0的選取主要考慮以下兩個方面。一方面,為保證模型結果的穩(wěn)定性,k0的取值不宜過小,若選取了一個較小的k0值,則模型則會很快進入剪枝階段,對于高頻震蕩型函數易陷入局部最小值。另一方面,k0的取值不宜過大,若選取了一個較大的k0值,將面臨模型運行時間過長的問題。
可見本文的算法是先進性不剪枝的確定搜索,保證搜索不會遺漏地進入每一個長度為,i=1~k0的區(qū)間,在進入到長度為(i大于等于k0)的區(qū)間進行更精細搜索時才進行隨機剪枝,以一定的概率跳過對更小區(qū)間的搜索,能夠兼顧精度和效率。
2 用本文方法求函數極值的算法實現流程
經過前面的準備工作之后,下面開始介紹函數極值求解模型的構建流程。本小節(jié)將主要介紹一元函數的極值求解,該問題在多元函數上的推廣將在后面介紹。現假定實際問題抽象得到的模型函數記為:

本文算法主要由以下兩個階段構成:定位階段和剪枝階段。
定位階段是指在深度小于k0時所進行的不剪枝的確定性搜索。圖3展示了該算法在定位階段的操作流程,二叉樹的根結點代表全區(qū)間,每次二分一個區(qū)間,左半區(qū)間對應左子樹,右半區(qū)間對應右子樹,其中括號中給出了區(qū)間左端點的值的二進制表示和十進制表示,因此搜尋每個數的過程對應該二叉樹中的一條路徑,而回索法則通過深度優(yōu)先的方式遍歷各路經從而實現解的搜索。
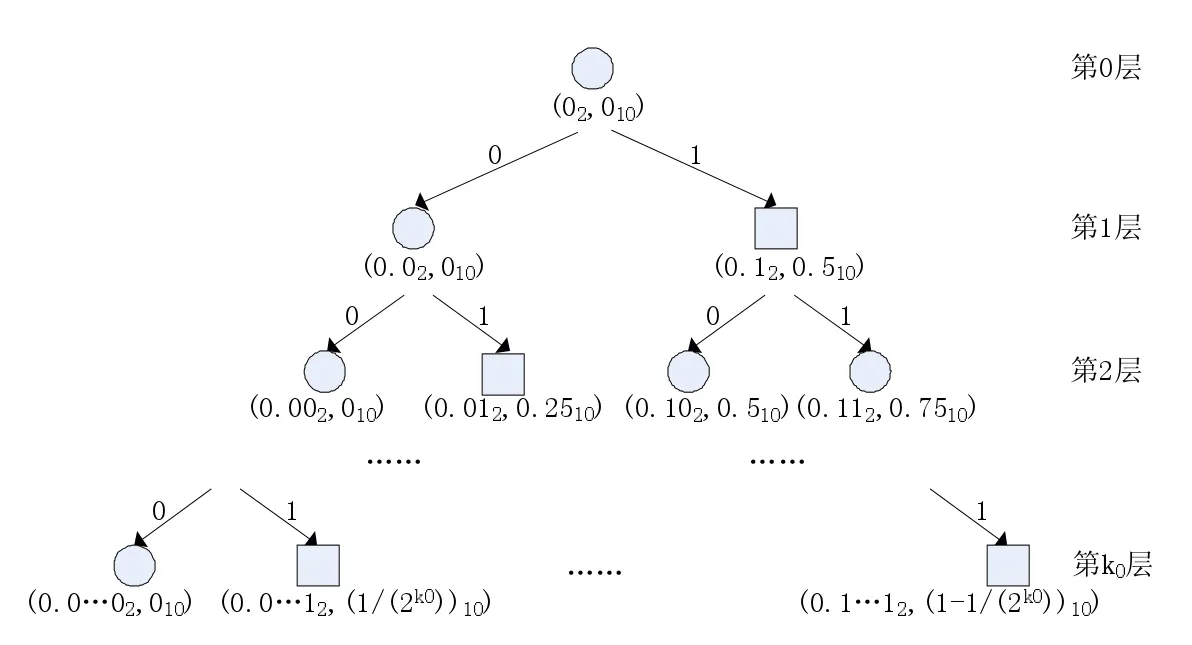
圖3 函數極值求解模型的定位階段
在定位階段進行深度為k0的深度優(yōu)先搜索,為降低時間復雜度僅對各結點的右孩子函數值的更新操作,因為左孩子所產生的區(qū)間端點并非新的值。在圖3中,方型結點將與當前解作函數值大小的比較判斷,圓形結點則不進行該操作。
定位操作發(fā)生在搜索樹的第1至k0層,從第k0+1至k層進行剪枝操作,其中k0=×k,k由公式(3)確定。也就是說在定位階段是對深度為k0的搜索樹進行的深度優(yōu)先搜索,在這個過程中不進行隨機剪枝可有效保證解的精度。但是,如果整棵樹的搜索過程中都不進行剪枝,則算法復雜度太高,因此從第k0+1至k層進行剪枝操作,也就是說在深度大于k0子樹中搜索時則引入1.3節(jié)介紹的剪枝操作,因此下面的過程針對當前要進行剪枝操作的任意一棵深度大于k0子樹。
在剪枝階段,同樣的道理僅對各結點的右孩子進行操作。剪枝規(guī)則定義如下:
(1)若f(x1)〈f(xmin),則接受x1為新的極小值點,不進行剪枝操作,繼續(xù)對子樹的深度優(yōu)先搜索。

①若p>ξ,則不進行剪枝操作;
②若p≤ξ,則進行剪枝操作。
其中,xmin為當前極小值點,x1為待判斷的新點,f為目標函數,i為x1對應結點在滿二叉樹中的層數,用w[i]=作為模擬退火算法的溫度值,這也是本文經大量實驗得出的有效選擇。ξ∈[0,1]為隨機數。圖4展示了該模型在剪枝階段的操作流程。

圖4 函數極值求解模型的剪枝階段
上面的流程是針對一元函數設計的,下面的探討將針對多元函數極值求解進行推廣。為便于理解,以下將以二元函數為例,對于三元或以上的函數,可以通過相似的步驟實現。現假定實際問題抽象得到的模型函數記為

其中,D={(x1,x2)∈R2|0≤x1≤1,0≤x2≤1}。
為達到模型精度要求,由公式(3)求得k值后,將構建一棵層數為2k的滿二叉樹。模型同樣由兩個階段構成:定位階段和剪枝階段。
在定位階段,先對定義域各端點作比較,取其最小者作為初始極小值點,在二元函數中,有以下四個端點(0,0)、(0,1)、(1,0)和(1,1)。然后,在對滿二叉樹搜索的過程中,以兩層為單位,在奇數層對x1的取值進行試探,在偶數層對x2的取值進行試探,如圖5所示,結點下括號內左數值代表變量x1的取值(二進制表示);右數值代表變量x2的取值(二進制表示)。同樣的,僅各層結點的右孩子進行比較判斷。
定位操作發(fā)生在搜索樹的第1至k0層,從第k0+1至k層進行剪枝操作,其中k0=×2×k。在剪枝階段,剪枝規(guī)則與一元函數相似,這里不再贅述。
3 實證分析
3.1 實驗所選函數簡介
在該小節(jié),主要介紹用于測試本文算法效果的各個實驗函數。為確保算法的泛化能力,實驗函數將盡可能地涵蓋不同的類型。如表1所示,在一元函數極值求解模型中,有六個函數用于測試,函數類型與函數特點不盡相同,圖6為各函數對應圖像。
對于多元函數的實驗測試,這里選用了一個二元函數,其定義如下:
統(tǒng)計并記錄兩組患者的血糖水平,包括空腹血糖、餐后2 h血糖水平、不良妊娠結果。其中不良妊娠結果包括早產、死產、感染、剖宮產。

其對于函數圖像如下:

圖5 二元函數極值求解模型的定位階段
3.2 算法效用分析
在一元函數極值求解的實驗中,取精度ε1= 0.0000001,根據公式(3)計算可知,k1=24。在二元函數的實驗中,ε2=0.0001,k2=14。
(1)穩(wěn)定性分析
前面分析中提到隨機搜索是一種不穩(wěn)定的算法,因此下面的實驗對比本文方法和模擬退火算法的穩(wěn)定性在實驗環(huán)節(jié),各算法將在不同函數上各運行10次,觀測各次求解得到的極小值是否一致,以本文算法在y=sinx+cos函數上的運行結果為例,通過表2可知,10次運行求得的極小值點相同,具有較強的穩(wěn)定性。在其余5個一元函數上,該算法均表現十分穩(wěn)定。
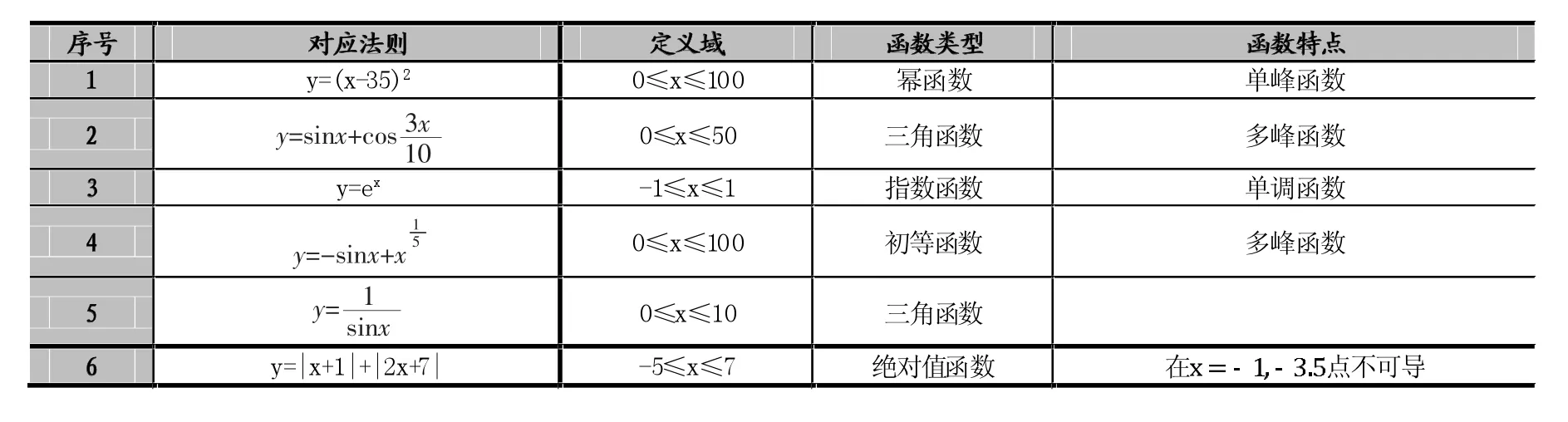
表1 實驗所選一元函數的簡要介紹

圖6 本實驗涉及的一元函數圖像

圖7 本實驗涉及的二元函數圖像
需要注意的是,穩(wěn)定性與k0的選取有關,若k0的值過小,則有可能出現極小值點不同的情況,影響模型精度。
表2 本文模型在y=sinx+cos函數上的運行結果

表2 本文模型在y=sinx+cos函數上的運行結果
(2)精度分析與運行時間分析
搜索算法的時間復雜度取決于其侯選搜索空間的設定,為了能對比不同搜索算法的時間復雜度,我們約定用各算法完成對相同搜索空間的搜索時間,本實驗中對一元函數取精度ε1=0.0000001,根據公式(3)計算可知,樹的深度k1=24。在二元函數的實驗中,取ε1= 0.0001,樹的深度k1=14。
在該環(huán)節(jié),將取10次實驗的眾數用于精度的考察,實驗時間均數用于運行時間的考察。對于一元函數,在減低實驗耗時上,本文算法優(yōu)于遍歷搜索算法,僅需其約10%的運行時間,六個函數中,最短為后者的7.87%,最長為13.14%,與模擬退火算法相比則兩者相近,本文算法依然有一定優(yōu)勢。在精度上,本文算法均有很好的表現。表3給出了對比結果。
可見本文算法能用更短的時間找到搜索空間中的最小值,本文設計的剪枝策略能夠在不影響精度的情行下降低時間復雜度,是一種能兼顧精度穩(wěn)定性和效率的有效方法。
4 結語
本文在遍歷搜索算法的基礎上,基于模擬退火的思想,通過對搜索樹進行剪枝,在保證模型精度的同時,解決其運行時間過長的問題。本文結合遍歷搜索和隨機搜索,設計了一種基于二進制編碼的搜索樹,并引入了基于模擬退火思想的隨機剪枝算法,在保證精度的基礎上對搜索樹進行剪枝,從而可以兼顧精度和效率。該算法適用范圍廣,全局性強,能有效處理高精度函數極值求解問題,能有效推廣至多元函數。算法的改進方向為如何使得該模型能更好地處理高頻震蕩函數,進一步地,考慮實現模型的并行化,更大程度地優(yōu)化運行時間。

表3 三種方法在精度與耗時上的比較
[1]Brent,Richard.P.,Algorithms for Minimization Without Derivatives,Prentice-Hall,Englewood Cliffs,New Jersey,1973.
[2]Forsythe,G.E.,M.A.Malcolm,C.B.Moler.Computer Methods for Mathematical Computations,Prentice-Hall,1976.
[3]鄧東皋,尹小玲.數學分析簡明教程.上冊[M].高等教育出版社,1999.
[4]王曉東.計算機算法設計與分析[M].電子工業(yè)出版社,2012.
[5]Kirkpatrick S,Jr G C,Vecchi M P.Optimization by Simulated Annealing[J].Science,1983,220(4598):671-80.
[6]Van Laarhoven P J M,Aarts E H L.Simulated Annealing:Theory and Applications[J],1987,37(1):108-111.
A Pruning Method for Accelerating to Search Function Extremum
LU Wei-rong,ZHANG Lei
(School of Mathematics,Sun Yat-sen University,Guangzhou 510275)
There are many optimization problems in practical applications that can be abstracted and simplified to search the function extremum. However,the problem that the function is not differentiable or its derivative is difficult to compute limits the use of exact methods.The traversal search,one of the numerical methods,can be used to search the high-precision extremum.To solve its problem of running too long,the search tree will be pruned based on the idea of simulated annealing in the case of ensuring the model accuracy.The model can be extended to multivariate function,which has the advantages of wide applicability and strong global character.To ensure the practical significance of the model,various types of functions will be used to test in the experimental part.
Function Extremum Search;Traversal Search;Simulated Annealing;Numerical Methods
1007-1423(2017)11-0003-07
10.3969/j.issn.1007-1423.2017.11.001
盧偉榮(1993-),男,廣東東莞人,碩士生,研究方向為人工智能
2017-01-10
2017-03-10
張磊(1964-),女,湖北羅田人,副教授,研究方向為數據分析
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
