基于Hadoop的分布式并行算法在最佳路徑中的研究
2017-05-18 09:22:02河南許繼智能科技股份有限公司藺俊強張長煒
電子世界 2017年9期
河南許繼智能科技股份有限公司 藺俊強 張長煒
西南交通大學信息科學與技術學院 孫希鵬
基于Hadoop的分布式并行算法在最佳路徑中的研究
河南許繼智能科技股份有限公司 藺俊強 張長煒
西南交通大學信息科學與技術學院 孫希鵬
隨著人們生活水平的不斷提高,對于城市中最佳路徑的選擇有了更進一步的要求,比如,選擇兩座城市的最佳旅游路徑,不僅可以節約時間和金錢,同時也方便了人們的出行。文章主要對Hadoop分布式并行算法進行了研究,分別在Hadoop分布式環境與單機環境下,使用att48數據集,對NP問題求解的時間與空間復雜度進行了對比研究,并最終計算出城市中的最佳路徑。
分布式并行算法;Hadoop;NP問題
0 引言
云計算是近年來流行的一種新興計算模型,而Hadoop[1]作為一個便捷開發和并行處理巨大數據的云計算平臺,以其低成本、高效率、可靠性而備受人們關注。 T White發表的《Hadoop: The Def i nitive Guide》[3]是非常著名的Hadoop權威指南,對Hadoop的底層原來進行了深入的剖析與講解,D Borthakur在《The hadoop distributed fi le system: Architecture and design》[4]中也闡述了他對Hadoop設計和架構的建議。在國內,對于Hadoop的設計應用研究也是比較多的,這方面研究比較好的有何婕、朱珠,《基于Hadoop的數據存儲系統的分析和設計》和《基于Hadoop的海量數據處理模型研究和應用》[5]都是比較好的研究著作。
Hadoop平臺由兩部分組成:Hadoop分布式文件系統(HDFS)和MapReduce計算模型[2]。HDFS采用M/S架構,它包含一個Master管理節點和多個Slave數據節點。MapReduce是處理大量半結構化數據集合的編程模型,它大大簡化了復雜的數據處理計算。
1 主要技術簡介
1.1 分布式算法簡介
分布式算法,簡而言之就是對一系列底層分布式算法(Low-Level Heuristics,LLH)進行管理和操作的一種高層次分布式方法。由圖1的模型可知,分布式算法管理操作了一組LLH,提供了一種高層次的分布式方法;尋找一個最優的算法是分布式算法的目的所在。
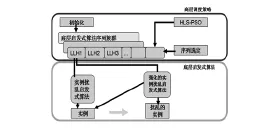
圖1 分布式算法的架構
目前的分布式算法[6]一般都有兩個階段,分別為算法構造階段和實例(問題)求解階段:前者采用的方法是對一系列LLH組合,以產生新的分布算法,后者就是運行新產生的分布式算法對問題或者實例求解。依據分布式方法不同的機制,目前的分布式算法大致有4種類型,分別為基于隨機選擇、貪心策略、元分布式算法、學習的分布式算法。
1.2 MapReduce模型
MapReduce[7]是一款高效的用于數據處理的編程模型,它將數據處理分為兩個過程,即map過程和reduce過程。MapReduce模型各個階段的工作流程如圖2所示:
(1)Input:這個階段進行的主要工作就是對Map和Reduce函數的輸入、輸出位置以及一些運行參數進行錄入,此外還會把輸入目錄下的大數據文件劃分為若干獨立的數據塊。
(2)Map:在Map這個階段,對(key,value)鍵值對進行處理,因為MapReduce框架把應用的輸入當作鍵值對,同時會產生新的中間(key,value)鍵值對,兩組鍵值對類型可能不一致。
(3)Shuffle:這個階段的作用是為了確保Reduce的輸入有序,按照Map中排好的輸出次序,MapReduce框架采用HTTP機制,為Reduce獲取所有與Map輸出的與之相關的(key,value)鍵值對,然后按照key值對Reduce階段的輸入進行分組。
(4)Reduce:這個階段主要是對中間數據進行遍歷,對每一個唯一的key都會采取相關操作。執行用戶自定定義的Reduce函數。輸入參數是(key,{listof values}),輸出是新的(key,value)鍵對。
(5)Output:此階段會把Reduce輸出的結果寫入到輸出目錄指定的位置。這樣,一個典型的MapReduce過程就完成了。
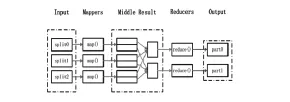
圖2 MapReduce的處理過程
2 解決的關鍵問題
在分布算法運行時,LLH的迭代不僅僅是由HLS輸送的局部解,并且為了平衡LLH算法[8]運行時間差異,我們并不放棄LLH自身的迭代,因為有可能在第N次迭代時結果不是最優解而在N+1次時卻會產生最優解。所以每個LLH在運行結束后會產生2N-1個HLS因子而不是N個,這樣會進一步擴大粒子群算法的粒子數,依據粒子群算法的特征,會進一步優化其最終結果。且由于粒子群算法本來就是一個分布式算法,所以這種迭代因子的輸入方式不會大幅拉低其時間性能。
與單機相比,本實驗體系的時間復雜度為:MAX(O(Ln))+O(HLS)而不是單機運行時的乘法級。這樣就可以解決優化分布算法的時間效率與結果優劣的矛盾。
3 實驗設計及運行結果
3.1 實驗設計
本次實驗采用對比實驗,即在Hadoop平臺與Windows平臺在同等環境壓力及其他條件下運行分布式算法,以對比其時間開銷和空間開銷。分布式算法設計如圖3所示,低層分布式算法由貪心算法、模擬退火算法、禁忌搜索算法組成。
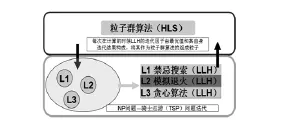
圖3 分布式算法實驗架構圖
3.2 實驗的部分關鍵實現代碼
public class MPGreedyAlgorithm {
static int cityNum;// 城市數量
static int[][] distance;// 距離矩陣
static int[] colable;//列,表示是否走過,走過置0
static int[] row;//行,選過置0
Static class MyMapper extends Mapper〈KEYIN,VALUEIN,KEYOUT,VALUEOUT>{
private static IntWritable one=new IntWritable(1);
private Text word=new Text();
@Override
protected void map() throws IOException,InterruptedException{
// 讀取數據
int[] x,y;
String strbuff;
distance = new int[cityNum][cityNum];
x = new int[cityNum];
y = new int[cityNum];
for (int i = 0;i 〈 cityNum;i++) {
// 讀取一行數據,數據格式1 6734 1453
strbuff = data.readLine();
String[] strcol = strbuff.split(“ “);
x[i] = Integer.valueOf(strcol[1]);// x坐標
y[i] = Integer.valueOf(strcol[2]);// y坐標
}
data.close();
// 此處用att48作為案例
for (int i = 0;i 〈 cityNum - 1;i++) { distance[i][i] = 0;// 對角線為0
for (int j = i + 1;j 〈 cityNum;j++) {
double rij = Math.sqrt(((x[i] - x[j]) * (x[i] - x[j]) + (y[i] - y[j]) * (y[i] - y[j])) / 10.0);
int tij = (int) Math.round(rij);
if (tij 〈 rij) {
distance[i][j] = tij + 1;
distance[j][i] = distance[i][j];
} else {
distance[i][j] = tij;
distance[j][i] = distance[i][j];
}
3.3 實驗過程與結果
本實驗先對att48數據集的48個城市坐標信息進行運算生成48城市之間的距離矩陣,其結果如圖4所示:

圖4 att48數據集距離矩陣
然后再對初始化的距離在Windows平臺通過分布式算法進行求解,得出本次的最佳路徑,Windows運行結果如圖5所示:

圖5 Windows環境下TSP問題尋優結果
最后再對上述的距離矩陣在Hadoop環境下通過分布式算法進行求解法進行求解,其運行結果如圖6所示:

圖6 在Hadoop平臺的運行結果
4 總結
本次實驗通過java編程和MapReduce編程分別在Windows下和Hadoop下實現了分布式算法,并使用它們處理運算了att48數據集,然后進行了對比實驗。本實驗體系時間復雜度為:MAX(O(Ln))+O(HLS),而不是單機運行時的乘法級,進而解決優化分布算法的時間效率與結果優劣的矛盾,最終找到兩城市間最佳路徑。
[1]Kendall G.,Mohamad M.Channel assignment in cellular communication using a great deluge hyper-heuristic.In:Proceedings of IEEE International Conference on Network (ICON2004),2004:769-773.
[2]Ayob M.,Kendall G.A Monte Carlo hyper-heuristic to optimise component placement sequencing for multi.
[3]楊宸鑄.基于Hadoop的數據挖掘研究[D].重慶:重慶大學,2010.
[4]丁寧.多關系關聯規則挖掘研究[D].合肥:安徽大學,2010.
[5]劉淑英.一種基于MapReduce的最近似k對數據搜索方案[J].計算機與現代化,2014,211(08):36-40.
[6]何軍,劉紅巖,杜小勇.挖掘多關系關聯規則[J].軟件學報,2007,311(11): 1062-1068.
藺俊強(1987—),男,河南許昌人,碩士,主要研究方向:分布式系統。
張長煒(1991—),男,河南臨潁人,大學本科,主要研究方向:電氣工程及其自動化。
孫希鵬(1990—),男,山東青島人,碩士,主要研究方向:大數據技術數據挖掘。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
